
引入差分约束和对抗训练策略的虚拟试衣方法
2022-11-16 02:24陈玥芙蓉
计算机工程与应用 2022年21期
陈玥芙蓉,李 毅
四川大学 计算机学院,成都 610065
随着互联网的快速发展,电子商务也逐渐从萌芽阶段发展至成熟阶段。其中,发展势头最迅猛的就是服装销售,它不再拘泥于线下的销售,更多的是在淘宝、抖音等电子商务平台上进行直播销售。但是,线上的服装销售相比线下,缺少了客户实际上身试穿的效果,往往只能在收到具体货物后,再进行试穿,这也使得线上销售的退单率远远高于线下。退单一方面延长了客户购物的时间,另一方面也加大了商户和客户各自的花销。那么,如何根据用户的具体身型实现虚拟试穿服装的功能,也成为计算机视觉中一个极具挑战性的课题。
近几年来,基于深度学习的二维图像虚拟试衣方法取得了较好的成果。生成对抗网络(generative adversarial networks,GAN)[1]是由Goodfellow 等人提出的非监督式机器学习架构。受到原始GAN 网络的启发,Jetchev等人提出了CAGAN(conditional analogy GAN)[2]来解决虚拟试穿问题。随后,Pandey 等人提出了Poly-GAN[3],该方法尝试用一个网络来实现虚拟试穿中的形变和融合问题,虽然降低了模型的整体复杂度,但仍存在局限性。二维虚拟试穿网络(virtual try-on network,VITON)[4]由Han 等人提出,该论文设计了U 型的编码-解码生成器网络结构,用于生成粗略的合成图像,然后利用形状信息预测形变参数,最后通过融合网络进一步扩大最初的服装模糊区域;同年,Wang等人提出了特征保留的虚拟试穿网络(characteristic-preserving virtual try-on network,CP-VTON)[5],该论文在VITON 的基础上进行了改进,使用几何匹配模块(geometric matching module,GMM)和试穿模块(try-on module,TOM)来完成虚拟试衣。但因为不正确的人体解析结果和学习预测的薄板样条变换(thin-plate spline,TPS)[6]参数过拟合导致服装发生不规则形变;其次试穿模块仅由生成网络组成,缺少与真实试穿结果的对比,融合后服装纹理较模糊。算法[7-8]分别针对上述问题做了改进,解决了部分问题,但整体效果仍然缺少真实感。为了解决上述问题,本文在CP-VTON的基础上进行了以下四个方面的改进:
(1)增加人体解析矫正模块,用于修正人体解析中划分不正确的区域,运用肤色检测算法从背景中识别并分离出脖子的区域,进行重新标记。
(2)几何配准模块采用回归网络预测TPS 参数,并增加差分约束项约束形变过程。
(3)试穿模块引入生成对抗网络的训练策略,使用编码器-解码器结构的类U-Net[9]网络作为生成器,改进的卷积神经网络作为判别器。
(4)增加区域特征重构模块,根据换装类型的不同,采用不同的方法恢复手臂区域的分辨率,提升虚拟试衣的真实效果。
1 相关工作
1.1 VITON和CP-VTON
VITON 首次提出使用人体量化表征以及服装信息,通过多任务的编码-解码生成器,实现服装到人体中相应区域的重构,生成粗糙的试穿服装的人像以及服装蒙版;利用形状上下文估计服装形变的薄板样条变换,使服装产生符合人体姿态和身体形状的形变;最后将生成的形变服装和粗糙的试穿人像输入细化网络,进一步生成服装的细节信息,得到最终的试穿结果。
CP-VTON在VITON的基础上进行了改进,其模型结构图如图1所示,首先不再像VTION中计算兴趣点的对应密度,而是通过几何匹配模块完全自主地学习如何预测薄板样条变换参数,使目标服装产生适合目标人群身型的形状;第二步输入形变后服装和人体特征信息,通过试穿模块完成形变服装和人体的融合,渲染图像保证平滑度,生成虚拟试衣的效果图。该方法较VITON,能够预测更准确的TPS参数,解决了部分图片试衣后出现小范围服装没有覆盖,裸露肤色的问题,但对于有头发和手臂遮挡的数据,实验效果较差。其次,处理服装纹理复杂的数据,都出现了试衣后服装图案模糊的情况,并且肤色、裤子等其他区域颜色有明显变化,生成的结果整体较模糊,缺乏真实感。
1.2 GAN和DCGAN
受博弈论中的零和博弈启发,生成对抗网络将生成问题视作生成器和判别器这两个网络的对抗和博弈:生成器从给定均匀分布或者正态分布的噪声中产生具有和训练样本分布一致的“假样本”,判别器主要用来判别该样本是来自真实样本,而不是生成器生成的“假样本”的概率。在训练过程中,生成器试图产生与真实样本更相似的样本数据“欺骗”判别器,相应地,判别器试图对真实数据与生成数据产生更准确的判断。因此,生成器在对抗中不断提高自己的“造假能力”,判别器不断提高自己分辨真伪的能力,最终生成网络生成的数据也就越来越逼近真实数据。
因为生成对抗网络是由初级的多层感知机模型构成,所以导致原始的生成对抗网络并不稳定。针对这一问题,Radford 等人提出了深层卷积生成对抗网络(deep convolutional generative adversarial networks,DCGAN)[10]。较传统的生成对抗网络,DCGAN 进行了下面几个方面的改进:(1)使用步长为1 的卷积层代替池化层,并移除所有的全连接层。(2)每进行一次卷积操作就使用批处理归一化。(3)对于生成器使用ReLU 激活函数替换传统的Sigmoid函数,并对输出层使用Tanh函数激活;对于判别器使用LeakyReLU 进行激活。该方法将卷积神经网络和生成对抗的思想融合起来,从一定程度上解决了网络不稳定的问题。
2 本文方法
本文提出的虚拟试衣模型共包含四个模块,整体结构如图2所示。首先,人体解析区域矫正对解析结果中错误的人体特征表示进行识别并标记;然后几何配准学习并预测TPS参数,利用薄板样条插值函数生成符合目标人物身型的形变服装;接着由基于对抗训练策略的虚拟试穿完成形变服装和目标人物的融合;最后通过区域特征重构对试穿结果I0进行人体解析区域重识别,计算手臂公共感兴趣区域,从原始图中获取手部特征信息并填补,生成最终的试衣结果图I。
2.1 人体解析区域矫正
CP-VTON中几何匹配模块的人体特征表示由三部分组成:姿势热图(pose heatmap)、身体形状图(body shape)和保留区域图(reserved regions)。姿势热图由Cao 等人[11]设计并开源的人体姿态检测和分析工具OpenPose 提供的25 个人体关节点构成,为了扩大表示范围,以关节点坐标为中心绘制成11×11 的白色矩形。身体形状图和保留区域图由Gong等人提出的自我监督的敏感学习结构的人体解析器[12]解析和再处理后得到。该模型将人体划分为18 个区域,并用不同颜色标识不同区域,因为缺少“脖子”区域标签,导致错误地将脖子区域划分为背景,不正确的人体特征信息造成试衣结果中领口部分形变过度且服装不贴合人体。针对该问题,本文提出使用基于椭圆模型的肤色检测,旨在分离出背景中遗漏的脖子区域,并用新的标签对该区域进行标识。
大量研究表明,人的肤色在外观上的差异主要受到亮度影响,在不考虑亮度Y时,皮肤像素点在Cr-Cb二维空间中近似成一个椭圆。本文采用高建坡等人提出的基于KL变换的椭圆模型肤色检测方法[13]。通过以下几个步骤引入新的肤色判别准则。
步骤1 对所有肤色样本进行分布均匀化处理,计算样本集的均值M及协方差C,然后求解协方差矩阵的特征向量P1和P2。以O点为新的坐标系原点,P1P2所在直线为坐标轴形成的坐标系就是趋近于肤色分布区域中心的理想坐标系。如图3所示。
步骤2 取基向量P1所在直线端点处两个样本点A1、A2,分别计算A1、A2到O点的距离D1和D2,椭圆的长半轴a的长度可以表示为D1和D2的最小值:
a=min{D1,D2} (1)
步骤3 用同样的方法在基向量P2所在直线上选取B1和B2,可得到椭圆的短半轴长度b。
步骤4 原始色度坐标向量P=(Cb,Cr)在新坐标系中表示为:
利用椭圆边界方程对背景区域进行肤色分割,逐个像素点判断是否在重新定义的椭圆边界区域内,得到肤色分割后的二值化图像,最后对脖子区域用RGB(189,183,107)进行标注,矫正后结果如图4。
2.2 几何配准
薄板样条变换是用于两幅待配准图像进行空间变换的模型,它对两幅图像中若干对控制点进行二维插值计算,使两张图像的控制点能够完全重合。根据实验数据的大小,使用了固定控制点12×16的网格,如图5左图所示。将原始网格中的控制点和发生形变后的对应控制点设置为一组控制点,因此仅通过图像中的192组控制点位置对TPS变换参数进行设置和估计。
受到卷积神经网络实现几何配准[14]的影响,本文中几何配准使用特征提取网络和回归预测网络完成薄板样条变换模型中参数的估计。特征提取网络包含四个步长为2 和两个步长为1 的下采样卷积层,用来提取人物和服装的高层次特征信息,并结合成一个张量输入回归网络。回归预测网络包含两个步长为2的卷积层、两个步长为1 的卷积层和一个全连接的输出层。该网络估计了一个384维的向量θ,该向量由每幅图像中控制点的12个横坐标x和16个纵坐标y组成。最后,使用预估参数θ进行薄板样条变换,生成形变服装,并将形变服装和真实形变服装的L1距离作为回归预测网络的损失函数。
但是,从CP-VTON的已有结果中可以发现,输出的形变服装总是出现形变过度或者和目标人物原始服装高度相似的情况,出现该情况可能与预测的TPS参数过拟合有关,因此使用差分的方法约束不规则的形变。
根据实际网格定义了差分约束项来平滑形变过度的区域。如图5右图所示,左图为薄板样条变换模型中使用的12×16固定控制点网格线。右图为放大的2×2的网格上定义的控制点。对于实际网格中任意中心采样点p(x0,y0),取距离中心采样点长度为d的上、下、左、右四个相邻采样点p(x1,y1)、p(x2,y2)、p(x3,y3)、p(x4,y4),使用公式(4)分别计算相邻采样点到中心采样点的斜率Si:
最终,几何配准的损失函数由生成的形变服装和真实形变服装的L1距离和差分约束项Lr组成:
图6为本文方法和CP-VTON的形变网格结果对比图,CP-VTON易产生未对准和纹理扭曲的形变结果,而定义的差分约束项能够产生更合理的形变,特别在处理带有复杂纹理和丰富色彩的服装时,整体效果更好。
2.3 对抗训练的虚拟试穿
为解决除上衣区域外的其他区域出现的清晰度下降和颜色变化的问题,修改了试穿模块保留区域图中包含的身体部位,除了头发和面部外,将脖子、裤子、短裙等5个标签区域加入保留区域。
针对CP-VTON中存在的服装模糊和纹理缺失的问题,引入了对抗训练策略来训练虚拟试穿部分的生成器。对抗训练策略一方面能够通过生成器和判别器的博弈,促使生成器生成与真实数据分布高度相似的数据;另一方面判别器对生成数据和真实数据的辨别,为生成器提供梯度,增强了数据间的相似度,使得最终生成的图像更加清晰真实。
该模块的生成器依然沿用原始论文中类U-Net 的网络结构,具体参数如表1所示。该网络包括收缩路径和扩展路径:收缩路径使用卷积核为3,步长为2的下采样卷积层,每进行一次下采样,特征通道数增加一倍,共进行5 次;扩展路径是加入了跳跃连接的上采样过程,每个上采样过程包括一个卷积核为3,步长为1 的卷积层,在每个卷积层后连接一个IN(InstanceNorm)层[15]和跳跃连接模块,并用ReLU进行激活。利用跳跃连接可以解决网络层数较深引起的梯度下降问题,有助于梯度的反向传播,加快整个训练过程。

表1 虚拟试穿的生成器具体参数Table 1 Generator network structure of try-on module
受到GAN 和DCGAN 的启发,在虚拟试穿模块加入的判别器是改进的卷积神经网络,该网络结构如图7所示。判别网络共包含5 个卷积层,前3 个卷积层步长为2,其余步长为1,在中间三个卷积层后分别加入一个IN 层,用于完成归一化,并用LeakyReLU 进行激活,最后一层则选用Sigmoid 激活函数完成二分类,其网络具体参数如表2所示。
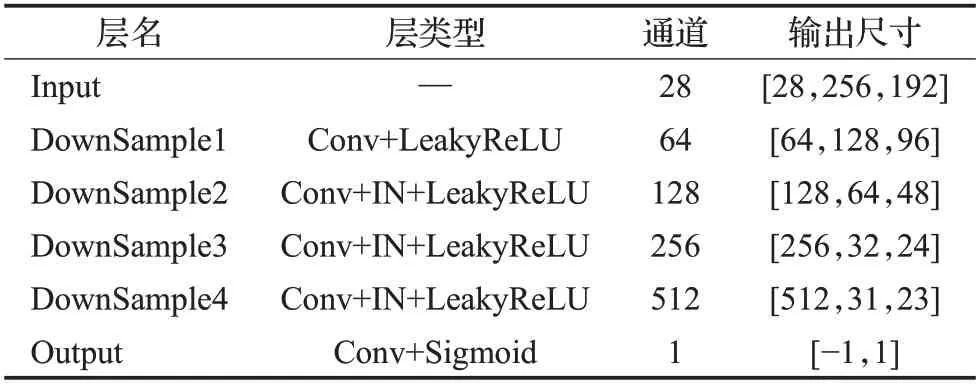
表2 虚拟试穿的判别器具体参数Table 2 Discriminator network structure of try-on module
将几何配准生成的形变服装和人体特征表示作为虚拟试穿的输入,用于生成虚拟试衣结果。在训练生成器和判别器的过程中,使用了随机裁剪的方法,将生成的图像进行任意尺寸的裁剪,并分别对原始生成图像和裁剪生成图像进行判别。这一方法在增加数据量的同时,也弱化了数据噪声,提高了模型的稳定性。
为了保证更真实的试穿效果,使用了L1损失函数、VGG感知损失函数和对抗损失函数。L1损失函数用于计算模型生成试穿结果I0与真实试穿结果Ig之间绝对值误差的平均值;VGG感知损失[16]则计算了生成试穿结果I0与真实试穿结果Ig在每一层特征图的L1 距离之和;对抗损失分别对生成试穿结果I0、真实试穿结果Ig和裁剪结果Ic进行判别,它们的损失函数定义如下:Data
公式(10)中的A是结合了姿势热图、身体形状图和保留区域图的人体特征信息,C是服装信息,Pdata代表实际数据分布,G(A,C) 是生成的试穿结果,G*(A,C)是随机裁剪后的试穿结果。最终,虚拟试穿模块的损失函数由λ1、λVGG和λGAN加权表示:
LTOM=λ1L1+λVGGLVGG+λGANLGAN(11)
2.4 区域特征重构
对于手臂交叉在前的目标人物图,往往试衣效果较差,因为手臂对服装有部分遮挡,导致在网络处理后手臂信息部分丢失,甚至完全无法辨别。为了解决这一问题,本文提出一种手臂区域特征重构的方法,具体流程如图8所示。
首先,对虚拟试穿模块生成的试衣结果使用人体解析模型重识别手部区域,将原始图和虚拟图手部区域的公共蒙版部分作为感兴趣区域ROI(region of interest),并从原图中获取对应区域的像素作为前景,将网络生成的虚拟试衣图片作为背景,对前景和背景使用泊松融合算法[17]进行融合。具体步骤如下:
步骤1 计算感兴趣区域的梯度场。计算梯度场选用拉普拉斯算子,得到感兴趣区域的X方向的梯度Rx和Y方向的梯度Ry。
步骤2 用同样的方法计算生成的虚拟试衣图片的梯度场。得到背景图像的X方向的梯度Sx和Y方向的梯度Sy。
步骤3 计算融合后的图像的梯度场。就是直接将感兴趣区域的梯度场替换背景图像中对应位置的梯度场,最终得到融合后图像X方向的梯度Lx和Y方向的梯度Ly。
步骤4 通过上一步的计算,可以获得待重建图像的梯度场,然后通过公式(12)对梯度求偏导,从而获得图像的散度divA。
步骤5 利用公式(13)中的泊松重建方程求解融合后图像x。其中A为N×N的系数稀疏矩阵,N为要融合像素的数量,根据拉普拉斯算子,该系数稀疏矩阵定义为一个主对角线元素全为-4,相邻像素位置为1,其余为0的矩阵。
本文使用的泊松融合算法,既保留了前景的纹理特征,又解决了拼接造成的边界明显的问题。在经过区域特征重构后,虚拟试穿结果中手部区域像素得到了最大化的还原。
3 实验
3.1 实验设置
本文使用了Hen 等人的数据集进行了实验。该数据集包含16 253 对女性半身彩色图片和对应的服装平铺图片,这些图片的分辨率均为192×256。在本次实验中,设置训练集14 221对,测试集2 032对。
实验选用Pytorch 作为深度学习框架,在NVDIA GeForce RTX 2060上进行。实验过程中的优化器全部选用Adam,其中优化器参数β1=0.5,β2=0.999,学习率=0.000 1,λ1=λVGG=λGAN=1,λr=0.45,batch大小设置为4。
3.2 定量分析
因为本文的方法是基于CP-VTON 改进的,所以实验结果均与CP-VTON进行对比。对实验结果使用结构相似性SSIM(structural similarity)指标进行定量评价。SSIM通过亮度、对比度和结构三个方面对样本X和样本Y两幅图像的相似度进行评价。计算公式如下:
其中,μx、μy分别表示样本X和样本Y的均值,σ2x、σ2y代表方差,σxy表示X和Y的协方差,c1和c2为两个常数,由像素值L和系数k1和k2表示。每次计算时选取N×N的滑动窗口,最后取平均值作为全局的SSIM。随机选取2 032对测试数据中的50%,计算其SSIM平均值,结果如表3。实验结果表明本文的方法较CP-VTON有很大提升。

表3 本文方法和CP-VTON的定量比较Table 3 Quantitative comparison between proposed method and CP-VTON
3.3 定性分析
针对服装形变过度的问题,本文提出的方法在一定程度上降低了形变过度的可能性,能生成更符合目标人物身型的形变服装。如图9所示,对比A组和C组数据,因遮挡或解析不正确造成上半身区域不完整,CP-VTON方法生成的服装肩部翘曲过度,与目标人物肩部轮廓图严重不符,而本文方法产生的形变结果领口区域的没有产生过度形变,肩部也更贴合目标人物身型。而针对人物上身无遮挡的数据,例如B 组,实验结果基本与CP-VTON相同,试穿效果较好。
最终试衣结果如图10 所示,第一行为手臂区域对比,第二行为换装区域纹理对比,第三行为保留区纹理对比。提出的方法在服装贴合度、服装细节和整体清晰度上都有明显提升。在第1组数据中,CP-VTON方法产生的试衣结果肩膀处衣服模糊,甚至裸露出原本肤色,换装后的短袖形状更接近原始的吊带形状,而本文方法依然保留短袖形状;在处理服装纹理较复杂的数据时,如第2组,可明显看出本文方法对服装上的标志和文字保留情况更好;在所有的实验结果中,本文方法的结果图中重塑的手部信息与原始图近似,而CP-VTON 的手部特征几乎是全部模糊的,尤其是手部遮挡服装时。
4 结论
本文在CP-VTON的基础上提出一种改进的虚拟试衣方法。该方法使用基于KL变换的椭圆模型肤色划分新规则,对人体特征信息中错误的信息重划分,并对几何配准模块预测的TPS参数,设置差分约束规则进行约束,降低服装形变过度的可能性。引入生成对抗策略训练试衣模块生成器,提高了形变服装和目标人物的融合和服装纹理图案保留效果。扩大保留区域,增加区域特征重构模块,提高非换衣区域和手部区域清晰度。通过上述定量和定性分析,本文提出的方法较CP-VTON 有明显的提升,且试衣效果较真实。
猜你喜欢
中国设备工程(2022年19期)2022-10-12
九江学院学报(自然科学版)(2022年2期)2022-07-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
客联(2021年4期)2021-09-10
表面工程与再制造(2019年6期)2019-08-24
电子制作(2019年11期)2019-07-04
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
智族GQ(2019年1期)2019-05-14
北京航空航天大学学报(2018年1期)2018-04-20
