
基于改进SOLO网络的城市道路场景实例分割方法
2022-11-20 12:54徐博文卢奕南
吉林大学学报(理学版) 2022年6期
徐博文, 卢奕南
(吉林大学 计算机科学与技术学院, 长春 130012)
随着深度学习方法的快速发展, 计算机视觉任务中的实例分割方法也取得了较大进展. 实例分割在运输、 医学病变组织分割、 工业缺损分割等领域应用广泛. 以目标检测任务为例, 其目的是实现目标对象的准确定位和识别功能, 而使用检测框表示对象的方法并不准确, 因为框内包含了大量背景信息, 同时无法获得对象的准确边界信息. 实例分割可逐像素地分离目标对象, 并根据目标对象的实例类别进行聚类, 从而更准确地分离场景中的目标对象.
基于实例分割技术的发展, 无人驾驶技术也得到极大改进, 并开始应用于交通领域. 通过匹配识别算法[1]或改进实例分割方法[2]可以为无人驾驶技术获取更广泛而精确的环境信息, 如车辆、 行人和驾驶工具周围的障碍物等, 以实现更安全、 更可靠的导航和控制. 常见的目标检测方法有YOLO[3]和Faster R-CNN[4]等, 其多数使用边界框显示或分割检测结果, 但这种方法不能准确地表示目标在场景中的位置信息, 误差较大.
传统的实例分割方法有Mask R-CNN[5],Yolact[6]和PolarMask[7]等, 其多数先采用检测方法区分不同的实例, 再利用语义分割方法在不同的实例区进行逐像素地标记划分. 但这种方法在对高流量的车辆遮挡场景以及车辆远景的问题处理上, 通常效果较差. 针对上述问题, 本文提出一种基于改进SOLO[8]模型的分割方法, 由于SOLO模型具有根据实例的位置和大小为实例中每个像素分配类别的特点, 从而可将实例分割转化为一个单次分类问题. 但SOLO模型的设计机制会出现当两个实例的中心都投影到同一个网格中时, 只能识别出一个实例而忽略了另一个实例的问题. 针对该问题本文对其进行改进, 利用注意力机制可帮助模型过滤特征信息, 并提高模型处理实例分割问题的能力, 通过设计联合注意力模块提高模型对区域内相应对象的关注能力, 同时也提高模型对多层次特征的表达能力, 从而进一步过滤掉冗余或不相关的干扰信息, 提升模型对多尺度实例的分割性能. 模块采用串联的方式融合通道注意力和空间注意力, 从而更好地选择特征信息, 提高模型对细节信息的掌握能力. 同时, 注意力模块采用残差结构动态调整注意力模块的复杂度, 以保证模型的高效性能. 通过在数据集Cityscapes上的实验结果表明, 本文模块结构可显著提高模型的实例分割能力.
1 SOLO网络
在语义分割中, 目前主流的方法是使用全卷积神经网络(FCN)[9]输出N个通道的密集预测. 每个输出通道负责其中一个语义类别, 语义分割的目的是区分不同的语义类别. 而SOLO网络[8]进一步引入了实例类别的概念, 以区分图像中的物体实例, 即量化中心位置和物体尺寸, 使利用位置分割物体成为可能. 该网络首先将输入图像划分为S×S个网格, 得到S2个中心位置类别. 根据对象中心, 每个对象实例被分配到其中一个网格作为其中心位置的类别. 然后将中心位置的类别编码到通道轴上, 类似于语义分割中的语义类别. 每个输出通道是对每个中心位置类别的响应, 对应通道的特征图可预测属于该类别的实例掩码. 因此, 结构化的几何信息自然存储在空间矩阵中. 实际上, 实例类别类似于实例的对象中心位置. 因此, 通过将每个像素归入其实例类别, 即相当于使用回归方法由每个像素预测对象中心. 将位置预测任务转化为分类而不是回归任务的原因是, 在使用分类时, 用固定数量的通道对多个实例进行建模更直接、 更容易, 且不需要依赖分组或学习嵌入向量等后续处理.
在每个特征金字塔网络(FPN)特征层, 附加两个子网络, 一个用于类别预测, 一个用于掩码分割. 在掩码分支中, SOLO网络连接了横纵坐标和原始特征编码空间信息. 这里数字表示空间分辨率和通道. 图1为假设了256个通道的头部结构, 其中箭头表示卷积或插值, Align表示双线性插值. 在推理过程中, 掩码(mask)分支输出进一步向上采样到原始图像大小.

图1 头部结构
为区分实例, SOLO模型采用了按位置分割对象的基本概念. 输入图像在概念上划分为S×S个网格.如果一个对象的中心落入一个网格单元, 则网格单元负责处理该对象的mask.因此, 如图2所示, 模型最后会输出S2个mask. 而第k个通道负责在坐标(i,j)位置分割实例, 其中k=iS+j.

图2 网络结构示意图
SOLO模型的训练损失函数由分类损失与mask预测损失组成:
L=Lcate+λLmask,
(1)
其中Lcate是针对语义类别分类的传统焦点损失(focal loss),Lmask是掩码预测的损失:

(2)
掩码预测损失中的i=k/S,j=k%S, 按从左到右和从上到下的顺序索引网格单元格;Npos表示正样本数量;p*和mask*分别表示类别目标和mask目标; sgn是阶跃函数, 如果pi,j>0, 则其为1, 否则为0;dmask使用Dice损失, 定义为
LDice=1-D(p,q),
(3)
式中D是骰子系数, 定义为

(4)
这里px,y,qx,y为预测软掩码p和ground truth掩码q中位于(x,y)处的像素值.
SOLO方法由于其快速、 高效、 精准的特点, 作为当前性能表现强大的实例分割方法, 已广泛应用于自动驾驶、 增强现实、 医学图像分析和图像视频编辑等领域.
2 基于SOLO网络的联合注意力分割方法
由于SOLO方法采用划分网格的方式, 通过中心点采样将各实例分配至各网格, 但在面对多个物体落在同一个网格的情形, 只简单地通过特征金字塔网络进行尺度分配. 因此, 为解决SOLO方法在面对多目标场景下目标重叠时处理效果较差的问题, 本文提出一种基于联合注意力机制的分割方法.
2.1 改进的SOLO网络
输入的图像首先按SOLO方法的设计划分为S×S个网格. 按照中心采样的原则, 如果一个对象的中心落在一个网格单元格中, 则该网格负责对应于该对象的mask. 所以该网络模型会输出S2个mask, 第k个通道负责坐标(i,j)位置的分割实例, 整个网络模型将掩码分支分解为mask kernel分支和mask feature分支, 分别学习卷积核和卷积特征. 本文在特征金字塔后添加了本文设计的联合注意力模块, 相比SE(squeeze-and-excitation)注意力模块[10], 增添了额外的并行操作以提升对融合处理后特征所包含的信息. 改进的SOLO模型框架如图3所示.

图3 改进的SOLO模型框架
Mask kernel分支用于学习卷积核, 即分类器的权重位于预测头内, 与语义类别分支平行. 预测头在FPN输出的特征图上预测. 头部结构的2个分支均有4个卷积层提取特征, 最后一个卷积层做预测. 头部的权重在不同的特征图层级上共享. 通过在kernel分支上的第一个卷积内加入归一化坐标, 即在输入后加入两个额外的通道增加空间性. 对于划分的每个网格, kernel分支预测D维输出, 表示预测的卷积核权重,D表示参数的数量.生成的权重取决于网格所在位置.若输入图像划分为S×S个网格单元, 则输出空间将为S×S×D.若输入为H×W×C的特征F, 则输出为卷积核S×S×D, 其中C是输入特征的通道数,S是划分的网格数,D是卷积核的通道数.
Mask feature分支用于学习mask特征的表达能力, 如图3所示. 由图3可见, 首先通过骨干网络和特征金字塔将提取到的不同层级特征经过本文联合注意力模块处理后, 作为分支的输入, 输出是H×W×C的特征掩码. 整个SOLO框架中一个重要的设计就是采用了FPN应对不同的尺寸. 将不同层级的特征融合得到特征掩码是一个重要的部分. 生成的特征图是H×W×C, 再与kernel分支的结果相乘, 得到的输出结果是H×W×S2.
经过前两个分支的输出, 生成具体的mask: 对于在坐标(i,j)处的每个网格, 先获得卷积核G, 然后将其与特征F卷积得到实例mask, 最多生成S×S个mask; 然后使用矩阵非极大值抑制(NMS)方法得到最终的实例分割结果.
在前向预测过程中, 图像通过骨干网络和特征金字塔得到网格位置的类别分值P(i,j)后, 先用较低的置信度阈值(0.1)筛选一遍结果, 再进行卷积提取mask特征. mask特征与预测得到的卷积核进行卷积, 再经过一个Sigmoid操作, 然后用0.5的阈值生成双极型掩码, 最后使用矩阵NMS, 得到结果.
2.2 联合注意力模块
注意力机制方法[10]通过关注重要的特征, 抑制不重要的特征, 广泛应用于目标检测任务中. 其中, 通道注意力旨在关注有意义的输入图像, 为有效计算通道注意力, 需对输入特征图的空间维度进行压缩, 对于空间信息的聚合, 常用的方法是平均池化. 而最大池化收集了物体的独特特征, 可推断在更细通道上的注意力. 所以同时使用平均池化和最大池化的特征效果更好. 而空间注意力机制旨在关注最具信息量的部分, 是对通道注意力机制的补充. 为计算空间注意力, 会沿通道维度进行平均池化和最大池化操作, 然后将其连接生成一个有效的特征描述符, 再通过卷积层生成空间注意力图. 受两种注意力机制[11]的启发, 本文采用一种串联形式的联合注意力机制, 设计一个联合注意力模块, 融合空间注意力和通道注意力引导mask分支聚焦有意义的像素信息, 抑制无意义的像素信息.
本文设计的联合注意力机制引导的mask头, 是一种将通道注意力与空间注意力串联的设计. 通道注意力模块结构如图4所示. 由图4可见, 输入一个H×W×C特征, 首先分别执行全局最大池化和平均池化的操作以获得两个通道的池化特征; 然后将其输入到一个两层的多层感知机(MLP)神经网络, 第一层用ReLU作为激活函数, 两层神经网络共享系数; 再将得到的两个特征相加, 用Sigmoid作为激活函数, 得到权重系数MC; 最后用MC乘以输入特征F得到缩放后的新特征. 整体计算过程如下:

图4 通道注意力模块结构
MC(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F))).
(5)
本文对空间注意力模块的设计是先通过提取预测的特征信息后, 再将这些特征输入到4个卷积层和空间注意力模块, 如图5所示. 由图5可见, 空间注意力模块首先沿通道轴分别通过平均池化和最大池化生成对应的池化特征Pavg,Pmax∈1×W×H, 用拼接函数对二者进行聚合, 然后输入一个3×3的卷积层, 再用Sigmoid函数进行归一化处理, 得到权重系数MS, 最后用MS乘以输入特征F得到新特征.整体计算过程如下:

图5 空间注意力模块结构
MS(F)=σ(f3×3(AvgPool(F),MaxPool(F))).
(6)
对于通道注意力机制与空间注意力机制的排列顺序问题, 在空间的角度, 通道注意力是全局的, 而空间注意力是局部的.对比研究表明, 按顺序生成注意力图比并行生成注意力图更好.所以本文设计的联合注意力模块采用串行的方式排列通道注意力模块与空间注意力模块.联合注意力机制中的通道注意力子模块和空间注意力子模块的串行连接可表示为
F′=MS(MC(F)).
(7)
经过特征金字塔融合后的特征F首先使用残差结构将特征F与通道注意力模块处理后的MC(F)逐个元素相乘, 然后用残差结构将通道注意力特征与空间注意力模块逐个元素处理.这里使用残差结构可动态地调整网络结构的复杂度, 优化了模块的结构.最后得到串行连接的注意力特征F′.
3 实 验
3.1 数据集
针对城市道路场景的实例分割任务, 本文采用更具代表性的数据集Cityscapes. 与研究实例分割的通用数据集COCO相比, 数据集COCO针对道路环境的数据较少, 对于自动驾驶和移动机器人的应用并不适合. 而数据集Cityscapes应用较广, 数据质量较高, 其含有5 000张在城市环境中驾驶场景的图像, 有19个类别的密集像素标注, 其中8个具有实例标注. 数据集Cityscapes是一个大规模数据集, 其中包含一组不同的立体视频序列, 记录了50个不同城市的街道场景. 该数据集包含来自50个不同城市街道场景中记录的多种立体视频序列, 除2万个弱标注外, 还包含5 000帧高质量标注. 因此, 该数据集的数量级较大. 数据集Cityscapes共有fine和coarse两套测评标准, 前者提供了5 000张精细标注的图像, 后者提供了5 000张精细标注和2万张粗糙标注的图像.
为方便处理, 本文将数据集Cityscapes转换成数据集COCO的格式. 数据集Cityscapes提供的标注信息有彩色语义图、 实例ID单通道图、 语义ID单通道图以及所有语义Polygon的文本描述. 而数据集COCO标注文件中包含了info,licenses,categories,images和annotations, 本文代码预先设定前三项, 将categories根据需要进行了修改, 保留了5个类别, 分别是car,pedestrian,truck,bus,rider, 对应数据集Cityscapes中原类别ID的24~28.
3.2 评价指标
本文使用AP(平均精度)和mAP(全量平均精度)作为在数据集Cityscapes上衡量模型实例分割性能的指标, AP和mAP的计算公式分别为

(8)
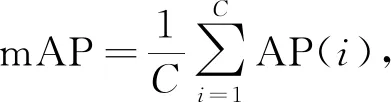
(9)
其中p(r)表示P-R曲线与横纵坐标轴围成的面积,C表示类别数量.P-R曲线是一个表示预测率与回归率关系的曲线, 通过将样本按预测为正例的概率值从大到小排序, 从第一个开始, 逐个将当前样本点的预测值设为阈值, 确定阈值后, 即可得出混淆矩阵各项的数值, 然后计算出P和R, 形成以R为横坐标、P为纵坐标的曲线.
除AP和mAP外, 本文衡量指标还包括AP50,AP75,APS,APM和APL, 其中AP50和AP75分别表示0.5和0.75不同的IoU阈值, APS,APM和APL分别表示对于小、 中、 大不同尺度目标的AP值. 这种设置可充分评估模型的分割性能.
3.3 实验分析
本文使用detectron2工具搭建模型框架, 在数据集Cityscapes上评估改进SOLO模型的性能, 将模型在其上进行训练、 测试和消融研究. 使用掩码的平均精度AP(平均超过IoU阈值),APS,APM和APL(不同大小的AP)作为衡量模型分割效果的指标. 所有消融研究均使用本文的改进模型和ResNet-101进行. 模型的分割结果如图6所示.

图6 模型分割结果
将本文模型与Mask-RCNN,Centermask,Yolact和SOLO模型在数据集Cityscapes上进行对比实验, 实验结果列于表1. 实验结果表明, 本文模型在精准度上得到了提升. 由表1可见, 本文模型在小尺度目标上的分割效果优于其他模型, 同时平均性能也有提升. 表2列出了本文模型对注意力机制的对比实验结果.

表1 不同模型的分割结果

表2 注意力引导模块对比结果
由表2可见, 联合注意力这种通道注意力在前、 空间注意力在后的排列比单独的通道注意力和空间注意力取得的效果更好. 图7为本文方法的收敛趋势, 其中loss_ins表示Lmask, loss_cate表示Lcate, total_loss表示总损失, lr表示学习率.

图7 损失收敛曲线
综上所述, 针对SOLO网络特征在多尺度场景下目标以及遮挡目标分割效果较差的问题, 本文提出了一种基于SOLO实例分割和联合注意力机制的方法, 提高了视觉特征信息处理的效率与准确性, 从而有效提高了面向城市道路复杂场景的分割精度.
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
计算机应用(2022年9期)2022-09-25
软件导刊(2022年3期)2022-03-25
微处理机(2021年5期)2021-11-02
通信学报(2019年5期)2019-06-11
计算机技术与发展(2019年1期)2019-01-21
通信技术(2018年3期)2018-03-21
浙江大学学报(工学版)(2015年4期)2015-03-01
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
