
协同过滤算法在学业预警系统中的应用研究
2022-11-22 09:45蔡朝晖王嘉鑫
大庆师范学院学报 2022年6期
蔡朝晖,王嘉鑫
(大庆师范学院 计算机科学与信息技术学院,黑龙江 大庆 163712)
0 引言
“学业预警”一词于2007年8月由教育部公布为171个汉语新词之一,经过十几年的研究发展,学业预警机制在高校教学管理体系中日趋完善。与此同时,随着大数据应用技术的发展,越来越多的学业预警系统中融入了数据挖掘和机器学习技术,这使得学业预警更具智能化和个性化特点,即在以学生发展为中心的理念下,加强分级和个性化指导。(1)参见百度百科:《学业预警》,2007年8月,https://baike.baidu.com/item/学业预警/6874109,2021年9月23日。结合机器学习的学业预警方法研究中,主要基于两类数据:一类是基于成绩或学分的,一类是基于行为分析的。
本文依据某校人才培养方案,以计算机类相关专业为例,在前期的个性化学业预警方法研究基础上,重点对通识教育的学业警示方法进行探讨,深入研究通识课程选修的推荐模型,以期达到“先防范再警示”的目的。
1 通识学业警示需求
我国内地的大学通识教育,发展于20世纪90年代原国家教委倡导的大学生文化素质教育试点。(2)参见姚震宇:《我国内地大学通识教育改革评析》,《高教论坛》2019年第7期。到2015年后通识教育改革得到官方承认并在更多大学发展深化,中国大学通识教育改革经历了从模仿借鉴到独立生成的发展过程。(3)参见陆一、杨曈:《高教大众化视野下中国大学通识教育发展的理论分析》,《清华大学教育研究》2020年第4期。
目前,某校各学科的人才培养方案中,文科和理工科对通识课程修得的学分比例要求整体上大致相同,要求至少修得6个学分,其中:1学分艺术、2学分文学、3学分自然。
由于通识课程分散到各个学期,以选修为主,且对修得学分的课程分类要求严格,因此,早期总有对要求了解不充分的学生,因有遗漏而匆忙补修,甚至影响毕业;后期随着警示系统的完善,类似情况虽然有所改善,但从学生角度出发的选课过程和形式还是不够直接和个性化。所以,通识课程推荐功能的设计,最直接的作用便是使得学生选课更具个性化,提高选课效率,进一步防范多选、错选或漏选的情况发生。
2 基于通识课程的推荐模型设计
协同过滤算法(Collaborative Filtering)是近些年最为流行的推荐系统所应用的算法,其应用于学业预警的研究较少。此算法最早应用于电子商务,常用的有两种推荐形式:基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。
2.1 标准推荐模型分析
个性化推荐系统,其数据模型的标准结构格式为:用户id、产品id、评分,即使用推荐系统的数据集至少包括以上三列数据。
说明:机器学习的协同过滤推荐算法是通过观察所有用户给产品的评分来推断每个用户的喜好,并向用户推荐合适的产品。
缺点:此模型中的用户数据因具有个人属性,属于隐私数据,基于隐私权限的原因,大多的推荐模型实际应用中,很难搜集到正确的个人属性数据,同时相同属性的用户未必会有相同的喜好,所以无法真正做到个性化推荐。(4)参见林大贵:《Python+Spark2.0+Hadoop机器学习与大数据实战》,北京:清华大学出版社,2018年,第282—283页。
2.2 课程推荐模型设计

图1 基于用户(学生)的过滤
依照上述标准模型,设计了课程推荐数据模型学号、课程编号、学分,使用学号标识学生、课程编号标识课程,学生个体与所选修课程的联系是多对多的。
学分代表了学生所选修课程的直接属性,从选课角度考虑,学分越高表示此课程被选的可能性越大,所以从一定程度上可以代表学生对课程的喜爱程度。由于通识课程的学分分值通常都不超过2学分,且多为1学分,此外学生选课还常常受到线下课程资源及上课人数等客观因素限制,所以即使是按喜爱程度推荐,学生也不一定能“抢”得上。相对地,线上的课程资源往往没有人数限制,但其评分数据的获得仍然存在着一定的难度,所以“学分”依然被放在此模型中对应了标准模型中的“评分”。
用协同过滤算法来分析和解释课程推荐模型的预期效果,如图1所示。
学生1选过课程1、2、4,学生2选过1、4,此时向学生2推荐课程2的做法,便是基于用户的协同过滤法。而基于商品的协同过滤则是利用用户评价的相似性推荐商品,对课程推荐模型则解释为:学生1与学生2都选修了课程1和4,那么此时便认为,学生3也会选课程1和4。
3 课程推荐模型训练数据预处理
3.1 源数据说明
学生成绩数据为某校教务系统教学秘书权限下的导出数据,文件类型为.xls,可以直接用做关系模型的结构化数据,或者转换为.csv类型的结构化数据使用。目前使用的数据来自三个表,其中2013级25466行,2014级18903行,2015级18254行,为计算机科学与信息技术学院三届学生的大学4年所修课程成绩全数据。全部列名分别是:学号、姓名、学制、开课学期、上课院系、培养层次、班级名称、课程编号、课程名称、总成绩、成绩标志、课程性质、课程属性、学时、学分、开课单位、录入人、考试性质、补重学期、学位课程、辅修课程、备注,共22列。
学生成绩数据的一般性特点:①本科学制四年,毕业修得学分分布在8个学期;②通识课程主要包括通识必修课程和通识选修课程两部分,通识必修课程学分分布在1~4学期,通识选修课学分分布在2~7学期。
目前,某校通识课的课程来源主要是两部分:校内教师开设和慕课平台提供。
3.2 数据预处理
学业警示系统包括两大功能模块:基于学分统计的学业警示模块和基于通识课的课程选修推荐模块,后台数据围绕这两个模块进行数据模型设计。
数据预处理大致有4个过程生成了4个工作表:①合并三个.xls文件作为学生成绩源数据(score_source.sheet),表中数据可以用学号前4位进行学生所在年级标识;②复制源数据到新工作表学分统计(credit_count.sheet),删除冗余、隐私、敏感及不相关数据16列,保留需求相关数据6列,这6列数据项分别是:学号、开课学期、课程编号、成绩标志、学分、补重学期;③抽取通识选修课程相关数据项(课程编号、课程名称、学分)到新工作表(gengral_course.sheet),抽取用于课程推荐相关数据项(学号、课程编号、学分)到新工作表(recommend1.sheet);④对相关数据项进行数值化处理或填充,即用整数1~8替换开课学期,用整数0填充成绩标志列空白项,用1替换补重学期列非空白项等。
3.3 训练数据集准备
Spark MLlib的推荐模型(用户、商品、评分)对数据类型的要求比较单一,即要求用户和商品的数据都是数值整型,在实际应用中,一般都由用户和商品的整数编号表示。
在数据库中,设计创建了3个基本表和2个视图。基本表有:通识课程表、选课表、学号自然序号表;视图有:模型训练数据集导出视图、真实选课情况导出视图。所有数据皆来自2015级学生成绩源文件,之所以用同一届学生做训练数据源,是因为在同届学生间进行课程推荐会使得推荐更具有个性化,即用户最大程度的预分类使得学生间的相似性判断效率更高。以下对基本表结构及数据进行说明。
1)课程表(course)
课程表数据主要包括为2015级学生开设的通识选修课学分等课程设置信息,如表1所示。
表中添加了一列“自然序号cid”,其值由自然数列填充,意在为训练推荐模型生成数值型的课程编号,其中人文类(编号RW开头)课程的自然序号为1~49、艺体类(编号YT开头)课程的自然序号为50~65、自然类(编号ZR开头)课程的自然序号为66~99,即按课程编号排序的自然序号编码使得同类课程间相似性判断效率更高。

表1 course表
2)选课表(elective)
选课表主要包括2015级学生的通识课的选修学分情况,如表2所示。将此表中的学号值替换为自然序号后,即可以导出为课程推荐模型(学号、课程号、学分)的训练数据集。
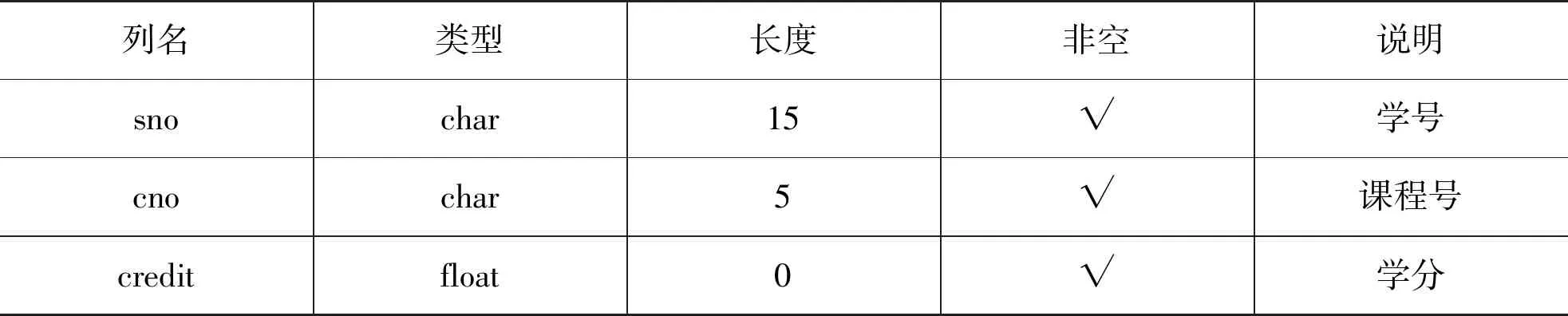
表2 elective表
3)学生自然序号对照表(sid_sno)
学号自然编号表将2015级所有学生进行自然序列编号,即所有学生按学号排序后,对应进行了自然数编号。如表3所示。

表3 sid_sno表
4 课程推荐模型测试与评估
4.1 ALS算法
ALS算法(Alternating Least Squares交替最小二乘法),是一种求解矩阵分解问题的优化方法,被用在求解Spark中所提供的推荐系统模型的最优解。如表4中列出了Spark平台下推荐模型中常用的功能包。

表4 ALS算法实现的常用功能
4.2 模型训练测试
Spark-MLlib的训练数据集文件格式要求为.csv或.txt。课程推荐模型的训练测试采用离线方式,所以其训练数据集为数据库视图导出数据,具体执行时模型训练的输入数据文件为elective_train.txt。
模型测试程序采用Java语言编码,编译环境为IntelliJ IDEA,程序功能主要包括三部分:训练数据文件读取、显示/隐式评分训练、推荐结果输出。
1)关键代码功能解析
(1)MatrixFactorizationModel model=ALS.train(ratingRDD, rank,iter)。
原型功能:显式评分训练
参数解析:
①ratingRDD:训练集,数据格式(学生id、课程id、学分(0~2));
②rank:ALS矩阵分解因子,值太小拟合度不够误差大,值太大会导致模型泛化能力较差,建议值10~1000;
③iter:ALS算法重复计算次数,值越大越精确,过大则太耗时,建议值10~20。
(2)Rating[] predictProducts=model.recommendProducts(userID, N)。
原型功能:向指定用户id推荐topN商品
参数解析:
① userID:指定的学生号sid,每次只能指定一个值。
②N:向学生推荐的课程门数,此值越大准确率越高,但也不宜过大;按每门课程1学分来累计并推荐课程门数,通常需要推荐6门课,但由于有课程类别限制以及推荐模型的冷启动问题,所以建议N值取6~10。
2)模型测试结果
将train函数参数rank和iter分别设置为20、20,将recommendProducts函数参数N值设置为10,userID分别设置为52、146、239进行三次测试,各参数测试结果及推荐评价如表5所示。
4.3 评估指标说明
表5中,精确率、召回率以及调和平均数是根据以下列出的公式(1)~(3)计算得出的。(5)参见刘强:《构建企业级推荐系统:算法、工程实现与案例分析》,北京:机械工业出版社, 2021年,第214—226页。

表5 模型测试结果对照表
1)精确率(precision):指为学生推荐的候选集中有多少比例是学生真正感兴趣的,即学生真正选修过的课程。
设U是所有提供推荐服务的学生全体的集合,针对其中的学生个体,Pu表示推荐的精确率,其计算公式如下:
(1)
其中Ru(N)是通过算法模型为学生u推荐的候选集,其中N是推荐的数量;学生真正选修的“课程”集即是Au。
2)召回率(recall):指学生真正选修的课程中有多少比例是推荐系统推荐的。设为针对学生u的召回率,其计算公式如下:
(2)
一般来说N越大,召回率越高,精准度越低,当N为所有“标的物”时,召回率为1,而精准度接近0。
3)调和平均数(F-measure):在实际构建模型时需要权衡召回率和精确率,可以用两者的调和平均数F1u来衡量推荐效果,具体计算公式如下:
(3)
对表5中列出的三个学生的推荐结果和相应的评估参数,可以分析总结为以下三点:①学生所选课程中,有学分较高课程,则其推荐的召回率较高,这是因为推荐的topN是按学分从高到底排序的;②推荐精确率较低的主要原因是N值的设置大于总选课门数,从而导致F1的值也较低,后续研究建议用训练的方式寻找合适的N值;③建议推荐的候选集能够进行差集或分类筛选,即针对学生还没有选的课程进行各自类别内topN推荐。
只选部分数据做测试评估是不够的,通常需要针对模型进行整体评价,上述三个评估参数可以采用所有用户的加权平均得到,即整体评价的精确率、召回率以及调和平均数的计算公式如下:
(4)
(5)
(6)
在使用Spark-MLlib的推荐系统时,既可以使用公式(4)~(6)评估模型,也可以使用其提供的内置函数进行模型评价,具体包括均方差(MSE)、均方根误差(RMSE)、K值平均准确率(MAPK)等评估指标,此部分的评估方法计划在优化后的模型测试中应用。
5 结语
本文研究的课程推荐模型面向高校通识课程的选修过程,在生成训练数据集时给出了数据库基本表结构,可以作为平移到分布式数据库中的表结构参考。鉴于模型评价指标总体不超过50%,建议在后期能够采集到课程评分的条件下,考虑采用将学分与评分加权联合的方式使用。
猜你喜欢
红蜻蜓·高年级(2022年6期)2022-06-16
甘肃教育(2020年18期)2020-10-28
甘肃教育(2020年8期)2020-06-11
疯狂英语·新悦读(2019年12期)2020-01-06
今古传奇·故事版(2017年24期)2018-02-07
探索科学(2017年4期)2017-05-04
探索科学(2017年3期)2017-05-03
探索科学(2017年1期)2017-03-03
探索科学(2016年11期)2017-01-17
郑州大学学报(医学版)(2015年1期)2015-02-27
