
混响环境下目标声场稀疏分解多域声场重放方法*
2022-11-23 10:49杜博凯曾向阳
应用声学 2022年6期
杜博凯 曾向阳 洪 汐
(西北工业大学航海学院 西安710072)
0 引言
声场重放(Sound field reproduction,SFR)是一种使用扬声器阵列在指定区域创造满足听众需求的虚拟声环境的技术。在虚拟声环境中,期望的声场内容及其空间特性被精准复制。由此发展而来的多域SFR技术可以使同一空间中的不同位置的听众感受不同的声环境而避免互相干扰。相对于自由场条件,混响环境的复杂性对SFR产生了明显的影响,考虑到自由场环境在实际应用中较难获取,因此在混响条件下实现多域SFR是一个重要的研究问题。例如在为主动噪声控制提供算法验证虚拟声环境时,可以在一个区域上验证而避免其余区域的工作人员受到噪声污染;又或者在汽车中使不同区域乘客享受不同类型的娱乐内容。
在房间中的避免混响干扰并且实现SFR的方法有不同类型。直接声压匹配方法[1-3]对扬声器阵列到重放区域之间的声传递函数进行空间采样,并计算出重放扬声器的权重。但是随着频率的升高,声压匹配方法仅仅在控制点取得良好的效果,在控制点之间的位置存在性能下降的问题。高阶Ambisonics(Higher order Ambisonics,HOA)[4]是实现房间中SFR的另一种重要方法。这种方法能够控制连续区域和宽频率范围内的声场。但是,目标声场的录制以及扬声器传递函数的测量都需要球形传声器阵列以获得对应的球谐域系数。在封闭空间中,Betlehem等[5]提出了一种利用房间反射重放声场的方法,利用圆柱谐波模拟重放系统及其反射,得到了一种补偿解码器来消除壁面反射引起的影响。随后,Lecomte等[6]将这项工作扩展到三维情况,并在解码之前将补偿过程作为一个单独的步骤执行,这使得混响环境下的重放系统设计可以使用在自由场中得到的许多解码结论。对于一个时变的环境,房间脉冲响应(Room impulse responses,RIRs)易受温度变化、人员运动、开门等因素的影响。主动补偿方法[7]考虑了房间环境的变化性。这些方法要求在一个或多个不同的“听音室”的位置测量扬声器的RIRs,为实现数字滤波器的补偿,将会进行多次测量。此外,还可以使用具有一定指向性的扬声器[8],与单极子扬声器相比,它抑制了混响场的能量。此外,可以将可变指向性扬声器[9]、双层扬声器[10-11]和高阶扬声器[12]用于扬声器阵列内重放声场,同时减少外部能量辐射。这意味着来自壁面的反射能量更少,可以获得更高的直达混响比。然而,这些方法需要复杂的扬声器单元,并且外部能量辐射的抑制会随着频率的增加而降低,在扬声器阵列的空间奈奎斯特频率以上性能下降更为明显。
直接使用传统的多点声压匹配方法,重放精度将受限于目标声场采样传声器数量。本文提出基于目标声场分解的重放方法,首先计算的重放不同位置点声源声场的扬声器阵列权值,然后将目标声场分解为一组点声源声场的叠加,通过加权求和获得扬声器阵列的驱动信号。与传统的多点方法相比,重放性能得到了提升。在SFR中,待重放的声学场景可能是由不同声源分布产生的。有时,声场景可能由大量声源组成,并且分布于接收位置的各个不同的方向,例如嘈杂的宴会、火车站大厅这类声场景。但还有一些情况,例如飞机飞临头顶、汽车从旁边经过等这类声源比较单一的声场景,此时相对于整个空间,只有单个或比较集中的几个方向有声源,而整个空间可以被离散成很多个方向。在这众多的方向中,只有少量方向上有声源,当测量阵列固定时,利用稀疏分解算法可以获得更好的重放性能。本文所做工作是基于目标声场的稀疏分解,在应用中只需要预先知道目标声场是由少量声源组成,或声源分布比较集中这一基本信息就可以使用本方法,重放环境的混响强弱不在本文讨论范围,因为重放环境的混响已经在随后介绍的点声源发生器中进行了补偿。
1 多区域SFR理论
首先对基于声压匹配(Pressure matching,PM)的多区域SFR方法和传统的多点空间补偿方法进行简要的回顾。假设用于SFR的是一个由L个均匀分布的扬声器组成的圆形阵列,扬声器阵列的半径为RL,重放的目标声场由M个传声器进行采样。
1.1 PM方法
本文研究的多域重放问题的示意图如图1所示。首先使用传声器阵列录制目标声场,记为pdes。随后选择扬声器阵列内部的传声器包围的区域,称为亮区,亮区内的声场在振幅与相位上应当与目标声场相同。扬声器阵列外传声器阵列包围的区域为暗区,其声场能量应尽可能低。
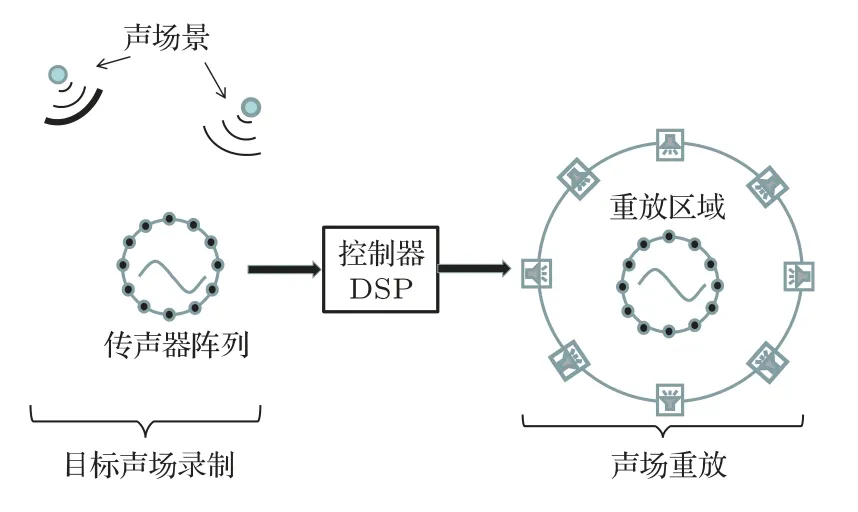
图1 多区域SFR系统示意图Fig.1 The schematic of the mutizone SFR system
假设扬声器阵列在这两个区域上产生的声压分别用M个传声器采样,那么多区域重放问题可以表示为两个优化问题的加权组合,也就是亮区上的SFR和暗区内的声场能量控制,该问题可以表示为
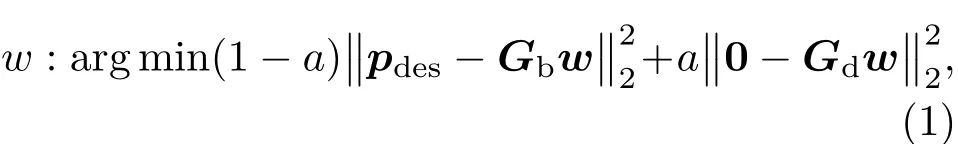
其中,Gb是一个M×L的矩阵,表示扬声器阵列与亮区中的控制点之间的声传递函数矩阵;Gb的第m行l列元素,表示位于rl处的第l个扬声器到亮区上位于rm处的第m个传声器之间的传递函数,在自由场中其中k=2πf/c为波数。在本文的剩余部分中,重放在频域进行,因此除特别说明外,声压和传递函数等变量均表示其频域值。类似的,扬声器阵列与暗区控制点之间的传递函数矩阵被表示为Gd,参数a是决定系统对亮区重放精度和暗区声场能量控制的相对程度的加权因子。符号w表示L×1的扬声器权重向量:
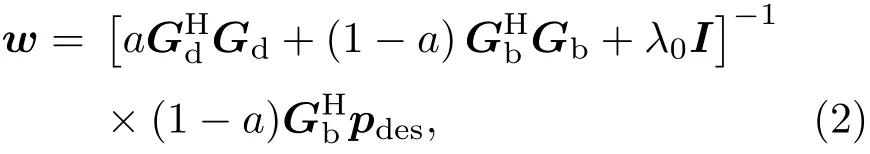
其中,λ0是限制扬声器输入总能量的正则化参数,选择方法参考文献[13]和文献[14–15];H表示共轭转置,I表示单位矩阵。
1.2 混响环境下的多点控制方法
在1.1节中,多区域重放问题是在自由场条件下进行,并且用于重放声场的扬声器被假定为完美单极子模型,这两个假设被用于许多文献中。然而在实际情况下,重放系统通常被放置于有混响的空间中。此外,扬声器在频率响应和指向性方面通常与理想的单极子不同。因此,在处理房间中的真实重放系统时,应考虑到混响、扬声器的响应及其位置误差影响。
图2展示了传统的房间SFR的多点方法的过程。当重放系统被放置于真实房间中,从扬声器到传声器的声传递函数与自由场中不同。对于传统的基于多点方法的房间补偿,假设测量获得的扬声器阵列与亮区中控制点之间的声传递函数矩阵为Gbr,扬声器阵列与暗区中控制点之间的声传递函数矩阵为Gdr,可以直接计算扬声器阵列的补偿后权重:
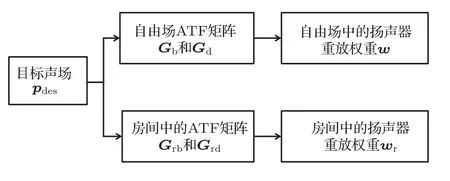
图2 自由场重放与传统的多点房间补偿方法Fig.2 Free field reproduction and the conventional multi-point compensation method
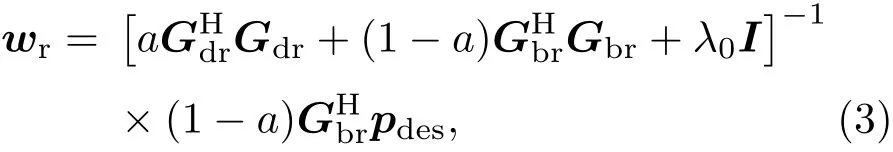
式(3)中描述的传统多点补偿方法在本文以下部分中被称为Cov-PM。该方法的局限性是,当目标声场传声器阵列的数量固定时,只能对有限数量的测量点进行控制。将在第2节提出基于等效源分解的房间SFR方法。
2 基于目标声场分解的重放方法
本节提出了一种基于目标声场稀疏分解的SFR方法。首先,假设一个房间中的多区域重放系统的点声源发生器可预先获得。点声源发生器是指一个扬声器权重向量,它在亮区中产生点声源声场,同时控制暗区中的声场能量。本文的方法由分解阶段和重放阶段组成,相关步骤如图3所示。在分解阶段,目标声场被分解为一组点声源声场的叠加,同时重放系统的点声源发生器在前期校准与计算中获取,最后的重放阶段将二者加权组合即可获取扬声器的驱动信号。
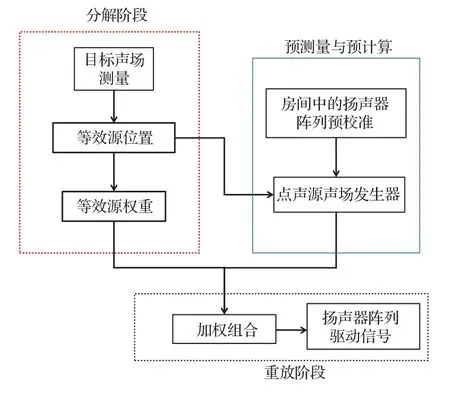
图3 基于等效源分解的重放过程Fig.3 Steps of the reproduction method based on equivalent source decomposition
2.1 目标声场等效源分解
假设重放的目标声场使用一个固定的传声器阵列rm(m=1,2,···,M)测量,使用等效源法对测量获得的声压进行等效源分解可以将目标声场表示为一组预先选择的点声源声场的加权求和。等效源方向分布如图4所示。
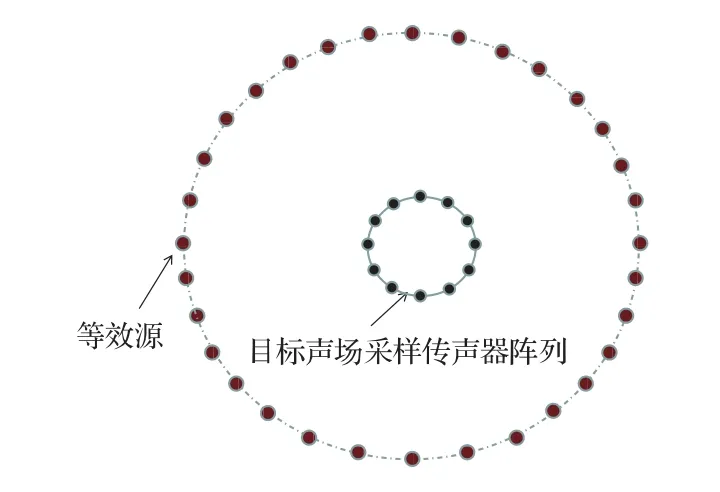
图4 传声器阵列周围等效源的分布Fig.4 Distribution of the equivalent sources around the microphone array
假设使用LE个等效源来进行目标声场分解,传声器阵列rm点处的声压可写为
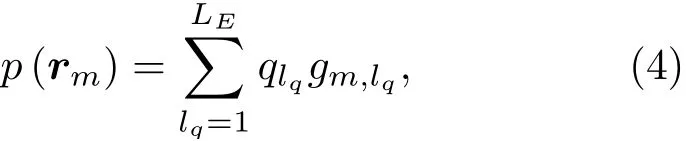
其中,符号qlq是第lq个等效源的强度,gm,lq=是位于rq的第lq个等效源和控制点rm之间的声传递函数。对于所有M个传声器,传声器声压与等效源强度之间的关系以矩阵形式写为

其中,GM,LE是等效源和传声器之间的声传递函数矩阵,p是由传声器阵列获取的目标声场声压向量,q表示等效源强度向量。式(5)可以用最小二乘法求解:
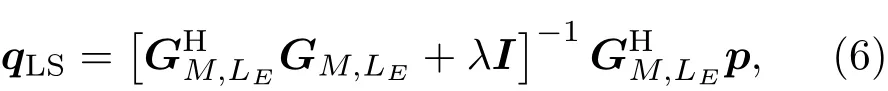
其中,符号λ表示正则化参数,选取方法参照式(2)。
2.2 稀疏分解方法
当声学场景由少量的声源组成时,可以对目标声场进行稀疏点声源分解,也就是可以用少量球面波来表示目标声场。对于稀疏等效源分解,式(5)求解方法是
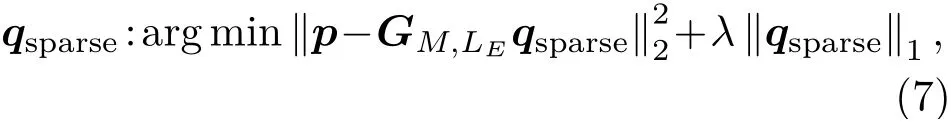
qsparse中将只有少数元素为非零元素,符号λ为解的稀疏度控制参数。
2.3 重放阶段
在重放阶段,根据在第2.1节中获得的等效源权重q来计算扬声器阵列的驱动信号。假设在房间中可以产生的第lq个等效源声场的点声源发生器为xlq,则扬声器阵列驱动信号可以表示为

在房间SFR的过程中,X与需要重放的目标声场无关。这意味着,当扬声器阵列与房间环境确定时,可以提前计算出X。在控制暗区的声场能量的同时,可以使整个亮区上xlq重放的声场与第lq个等效声源产生的声场之间的误差最小化。这可以表示为
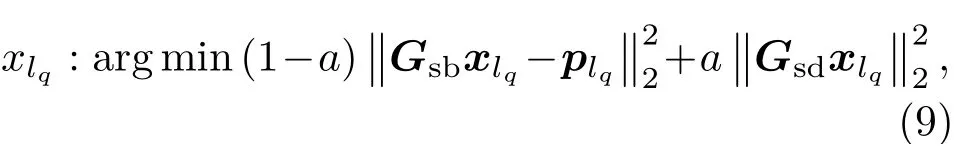
其中,plq表示第lq个等效源在亮区控制点处产生的声压,Gsb是从扬声器阵列到亮区控制点测量的声传递函数矩阵。因此,xlq的解被表示为
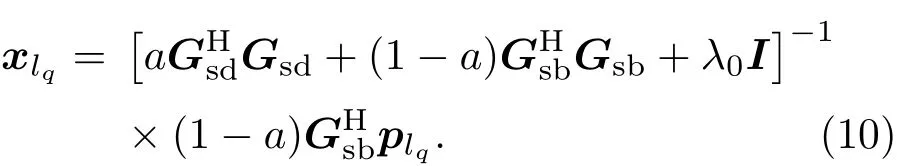
重复从式(9)到式(10)的过程,可以得到等效源发生器权重矩阵X。本文将式(10)中的加权参数a设置为0.5。
综上所述,基于目标声场分解的扬声器阵列重放驱动信号d的计算方法包括最小二乘等效源分解方法(Least squaresequivalent source method,LS-ESM)和稀疏等效源分解方法(Sparseequivalent source method,Sparse-ESM):
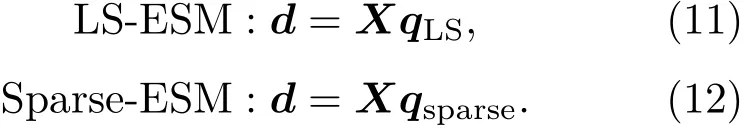
3 数值仿真
本节将对所提及的3种方法进行两方面的评价:亮区的相对重放误差以及亮区和暗区之间的声对比度。亮区的相对重放误差定义为整个目标声场pdes与重放声场pre之间的平均能量误差,相对重放误差(RE)表示为dB的形式:
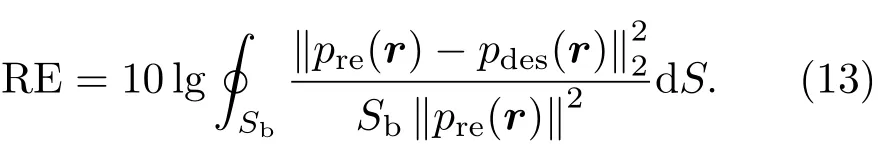
此外,声对比度(Acoustic contrast,AC)定义为亮区和暗区之间的平均声场能量比:
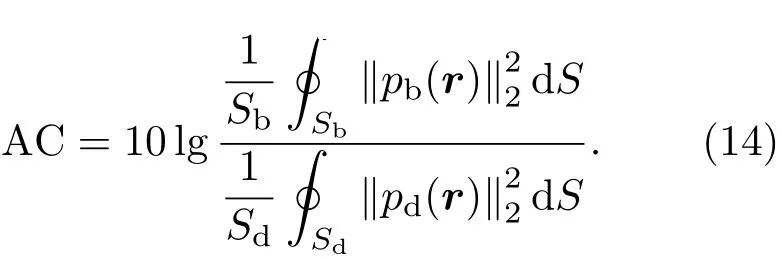
在式(13)和式(14)中,积分范围在整个亮区和暗区上,Sb表示亮区的面积,Sd表示暗区的面积,r表示位置向量。
3.1 仿真设置
为了研究本文方法的重放性能,进行了数值仿真验证。假设一个均匀分布的半径为0.5 m的16阵元圆形扬声器阵列放置在尺寸为6 m×5 m×3 m的虚拟房间中,扬声器阵列位于房间的中心所在的水平面内,阵列中心设置为坐标的原点。RIRs由Allen等[16]提出的虚声源方法获得。目标声场设置为[1.2 m,0.2 m,0 m]处的点声源辐射的声场,使用8个传声器进行记录,考虑到扬声器阵列的奈奎斯特频率为857 Hz,仿真的频率范围限制在300~1000 Hz之间。亮区和暗区的几何形状是正方形区域,大小都为0.5 m×0.4 m。另外,传声器测量数据以及脉冲响应中均加入了信噪比为30 dB的高斯白噪声。点声源发生器用30个均匀分布的传声器阵列测量并进行计算。
3.2 仿真结果
本节比较了Cov-PM、LS-ESM和Sparse-ESM的性能。首先给出了这些方法在800 Hz的重放声场波形、亮区的相对误差和声场能量分布。在Cov-PM中使用的加权参数a为0.5,使用Fernandez-Grande等[17]的方法求解了式(7)中的1-范数优化问题。图5中展示了在不同频率下3种方法的声场重放的结果,其中*表示扬声器,扬声器阵列内外的虚线分别表示亮区和暗区的边界。图5(a)、图5(d)和图5(g)的数据单位为Pa,图5(b)、图5(e)和图5(h)的数据单位为dB,图5(c)、图5(f)和图5(i)的数据单位为dB(原点的声场能量为0 dB)。使用不同方法重放的声场波形展示在图5(a)、图5(d)与图5(g)中。在所有方法的结果中,亮区内重放的声场波形都大致接近球面波。为了清楚地展示这些方法在亮区上的重放性能,不同方法的亮区SFR误差展示在图5(b)、图5(e)和图5(h)中。在整个亮区内,Sparse-ESM的重放误差明显低于LS-ESM和Cov-PM,对应的平均重放误差分别为-14.7 dB,-9.2 dB和-8.4 dB。最后,这些方法的声场能量分布也展示在图5(c)、图5(f)和图5(i)中,相应的声对比度分别为
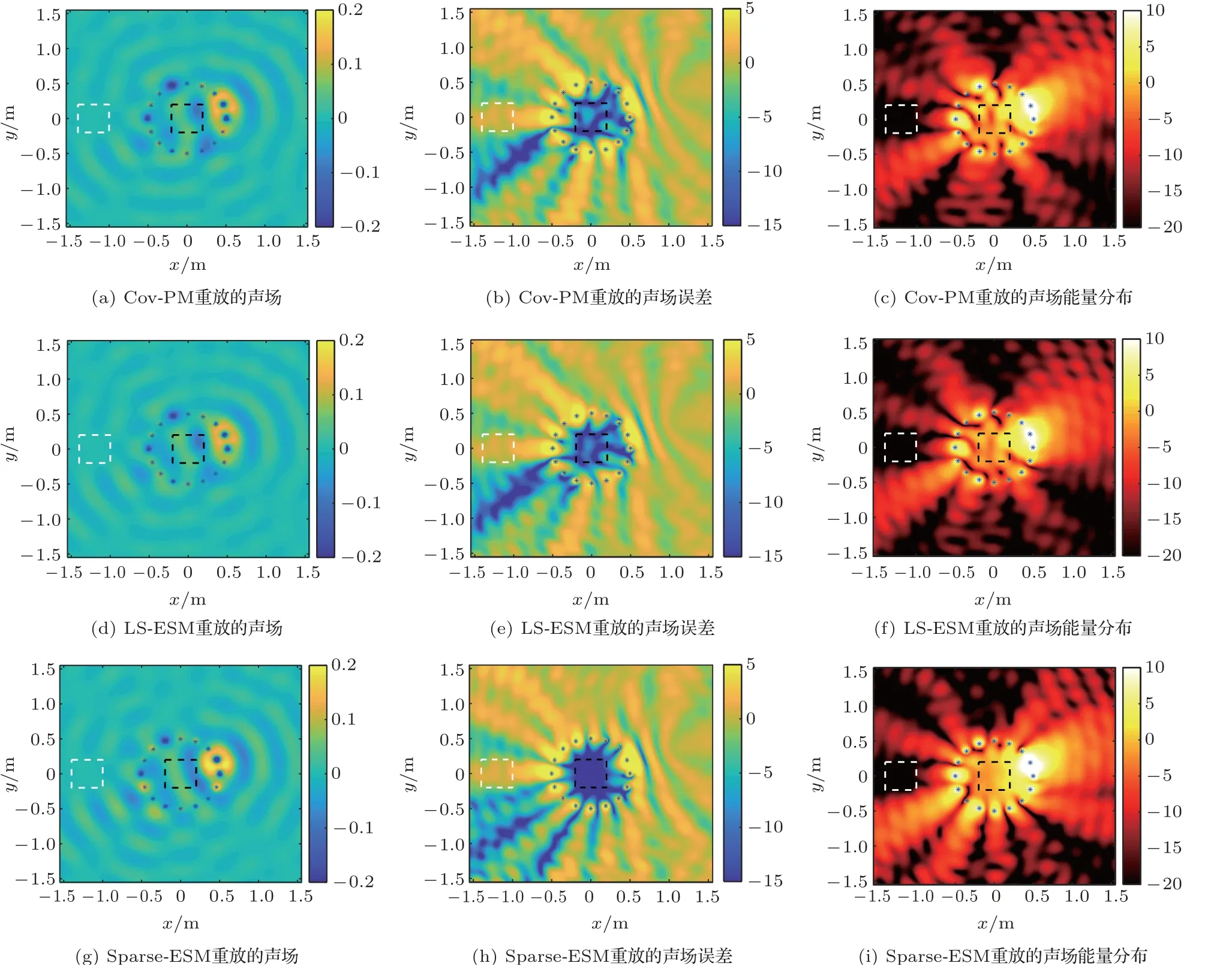
图5 在800 Hz时的SFR结果Fig.5 SFR results at 800 Hz
21.0 dB、21.5 dB和21.7 dB。
为了进一步对所有方法在宽频带上的性能进行详细的比较,图6中展示了300~1000 Hz,Cov-PM、LS-ESM和Sparse-ESM三种方法的SFR误差和声对比度。从图6(b)可以观察到,所有的方法都能在800 Hz下实现相近的声对比度。但是在SFR误差这一性能上,基于目标声场分解的两种方法在研究的频率范围内取得了更好的结果。在低频部分,Cov-PM的重放性能出现了较大波动,这是由于在这个多区域声场控制问题中,存在SFR误差与声对比度性能之间的平衡。例如,与320 Hz频点上的结果相对比,340 Hz处的SFR误差显著变大,但是声对比度性能也显著增强。这两个性能指标之间的调节可以通过改变参数a实现。在本文中,参数a固定为0.5,因此在低频处Cov-PM性能出现了波动。最后,对基于目标声场分解的方法的重放误差进行比较,二者重放误差性能在低于600 Hz时相近,随着频率的增加,它们的重放误差性能均出现了下降。然而,Sparse-ESM总是能取得更高的亮区SFR精度,考虑到这两种方法在关注的频率范围内获得几乎相同的声对比度,因此与LS-ESM相比,提出的Sparse-ESM在多区域重放问题上性能更优。
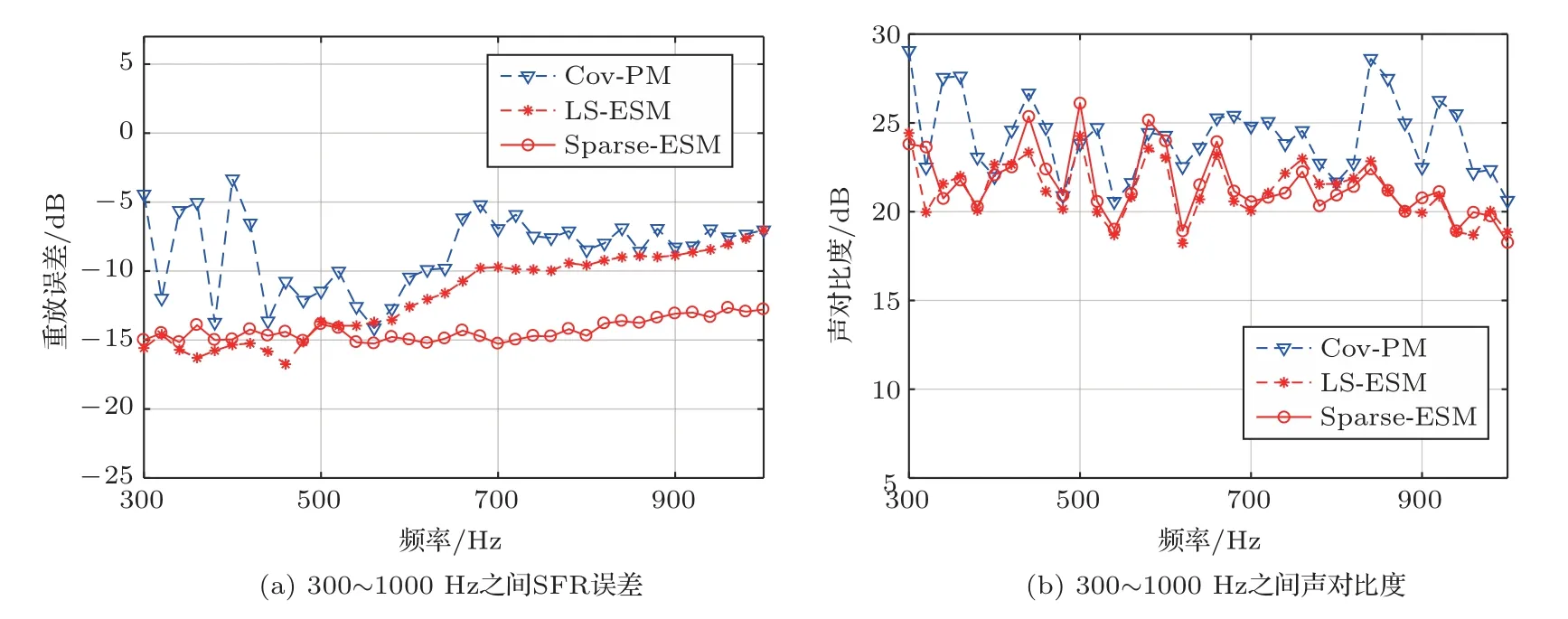
图6 不同方法的SFR误差与声对比度仿真结果Fig.6 Simulated reproduction error and acoustic contrast results of different methods
接下来,检验不同算法重放来自不同方向的目标声场的重放误差和声对比度性能,结果如图7所示。目标声场虚拟源的方向从-π到π变化,共20个均匀间隔。在400 Hz时,不同方法的性能随着虚拟源方向的变化而有所波动,波动的原因已在文献[18]中讨论过。但是两种基于目标声场分解的方法在亮区上都取得了更好的重放性能,同时与Cov-PM保持了几乎相似的声对比度性能。在800 Hz时,基于目标声场分解的方法在所有虚拟源角度上实现了更好的重放误差性能,更为显著的是Sparse-ESM相对于LS-ESM在所有虚声源角度上实现了更好的重放误差性能。观察声对比度结果,在所有角度上,Sparse-ESM的性能比Cov-PM下降了3~5 dB,但是Sparse-ESM的重放误差性能提高了超过5~10 dB。考虑到两个评价指标的总性能,Sparse-ESM方法性能超过了Cov-PM。在1000 Hz时,LS-ESM的重放误差性能下降得略好于Cov-PM,而Sparse-ESM的性能仍显著优于Cov-PM。因此可以得到一个初步结论,本文提出的Sparse-ESM具有最佳的重放性能。
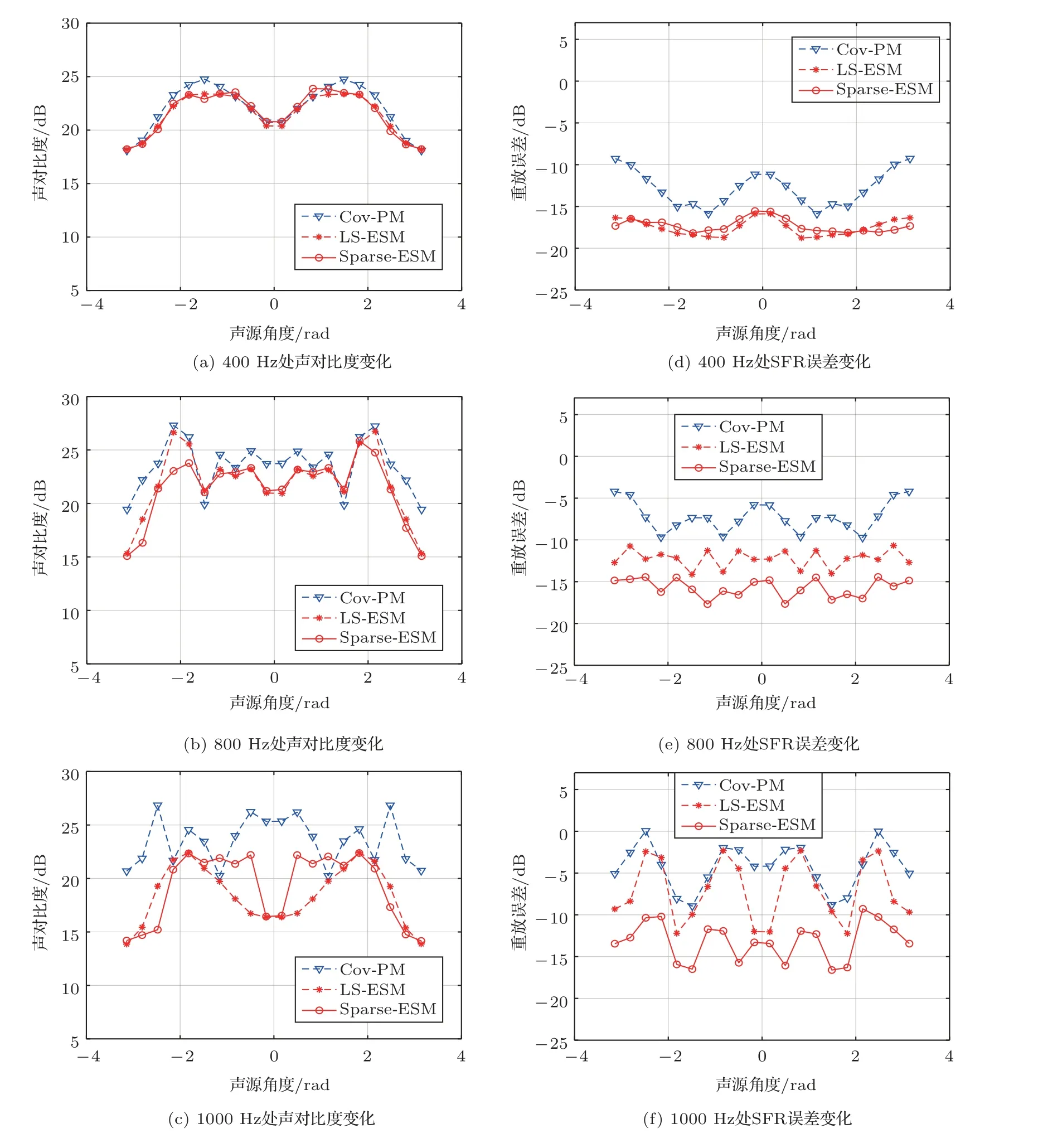
图7 不同频率下重放误差和声对比度随虚拟源方向的变化结果Fig.7 Reproduction error and acoustic contrast results at different frequency under different target source directions
4 实验结果
在本节中,比较了基于目标声场分解的方法和Cov-PM在混响室内的性能。整个系统被放置于亚琛工业大学的VR实验室。本实验的目的是验证所提出的Sparse-ESM在研究案例中更加适用于多区域重放问题。
4.1 实验环境与设置
如图8所示,使用由16个扬声器组成的均匀分布的圆形扬声器阵列,其半径为0.5 m。所有扬声器保持在距离地面1.3 m的水平面内,亮区设置为扬声器阵列平面中心的矩形区域,尺寸为0.5 m×0.4 m,暗区的大小和形状与亮区相同,但其中心位于[0 m,15 m,0 m]。此外,用于计算点声源发生器的脉冲响应测量传声器阵列是一个均匀分布的阵列,由30个传声器(森海塞尔KE4)组成,间隔10 cm。在重放阶段使用由60个传声器组成的更加密集的阵列来测量亮区和暗区重放声场。这些测量结果用于评估方法在两个相同方面的性能:重放误差和声对比度。在实验准备阶段,使用扬声器逐个发声来测量从扬声器阵列到传声器阵列的脉冲响应。驱动信号是一个在ITA-toolbox[19]中的e-扫频激励信号,长度为1.5 s。
在本实验中,目标声源的位置与仿真中相同,其方向与阵列中的任何扬声器都不一致。对目标声场进行分解,随后与点声源发生器进行加权计算获得扬声器权重。之后,对目标声场进行重放,并再次由传声器阵列进行测量。本文使用ITAtoolbox工具箱控制整个测量、重放和记录过程。实验环境和扬声器阵列如图8(a)所示。房间尺寸为6 m×5 m×3 m,房间混响时间见图8(b)。
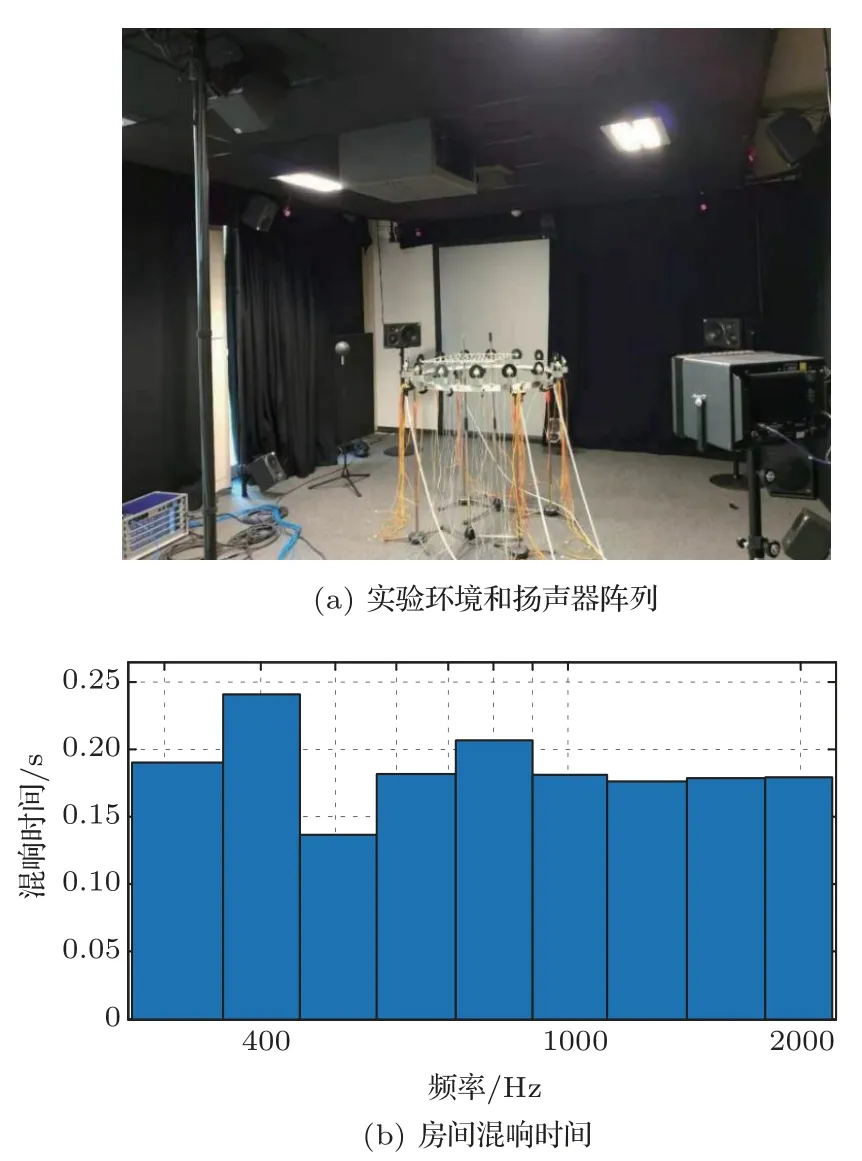
图8 实验系统与房间环境Fig.8 Experiment system and the environment
4.2 重放实验结果
图9中展示了多区域SFR问题的实验结果,基于目标声场分解的方法在研究频率范围内都表现出相似的声对比度。然而,不同方法在亮区上的重放精度不同。观察图9(a)所示的重放误差性能,Cov-PM在整个研究频率范围内的重放误差比基于目标声场分解的方法的结果要高许多。在500~1100 Hz之间的Cov-PM的重放误差甚至高于0 dB,这意味着该方法几乎完全无法在亮区上重放目标声场。在1200 Hz以上Cov-PM的声对比度比另外两种方法高5 dB左右,然而亮区重放误差相对于Sparse-ESM高8 dB左右。而对于基于目标声场分解的方法,随着频率的增加,两种方法的重放误差都逐渐增加(尽管有一些波动),但是均低于Cov-PM。在800 Hz之后,Sparse-ESM的效果明显优于LS-ESM,在1500 Hz下实现了6 dB的提升。综合考虑到所有方法的声对比度在研究的频率范围内都很接近,Sparse-ESM在亮区上重放的声场总是比其他方法好。该实验结论与从仿真结果中得出的结论一致。
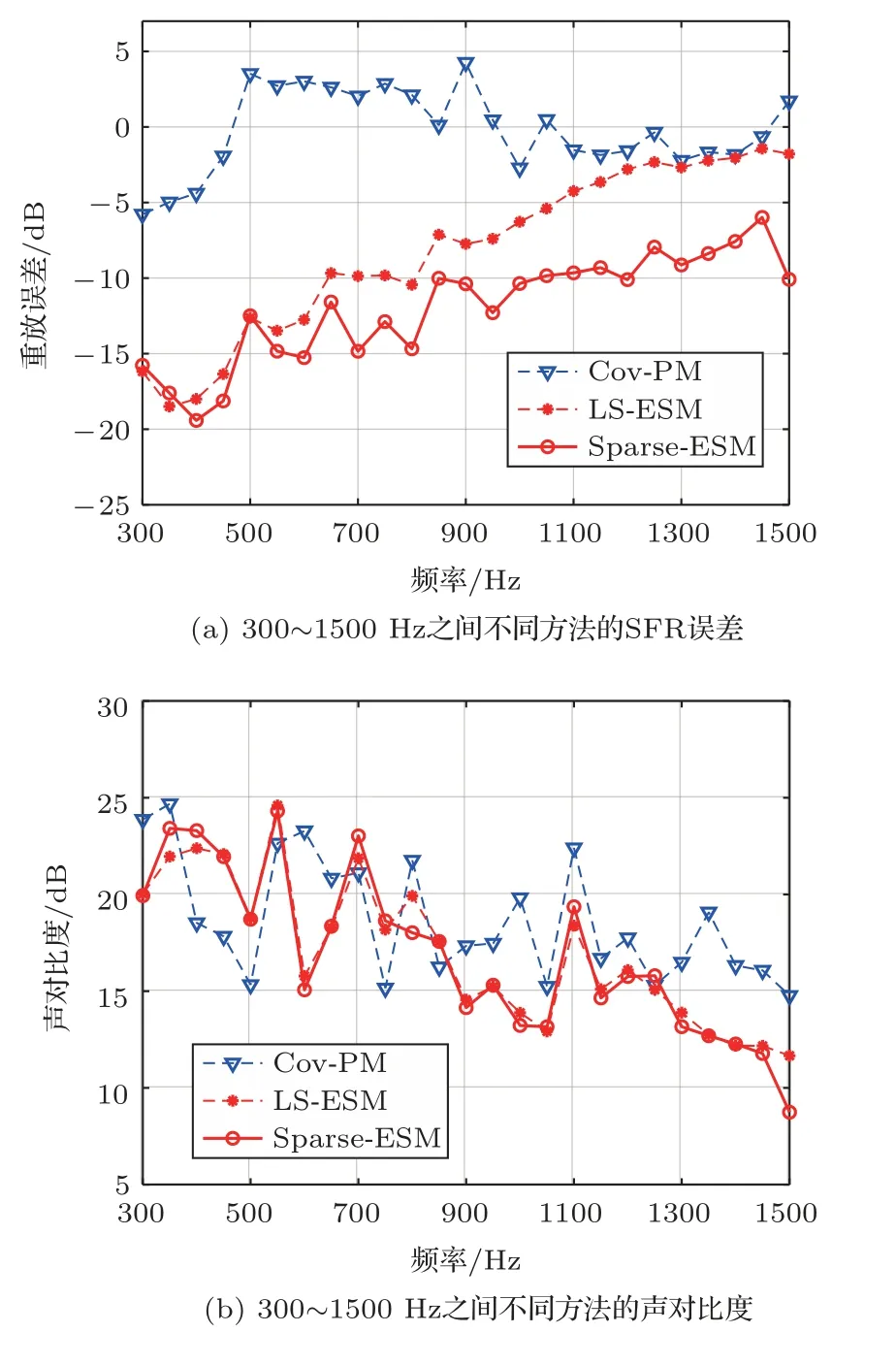
图9 声对比度和SFR误差的实验结果对比图Fig.9 Experimental reproduction error and acoustic contrast results
最后,比较了这些方法在目标声场虚声源在不同方向时在混响室中的SFR性能,虚声源设置与仿真中相同。在400 Hz时,声对比度和重放误差如图10(a)和图10(d)所示。重放结果随虚拟源方向的变化而波动。然而,基于目标声场分解的方法的重放误差总是明显优于Cov-PM,而基于目标声场分解方法的声对比度大致接近Cov-PM的值。在800 Hz和1200 Hz时,Cov-PM的声对比度性能在某些角度上优于基于目标声场分解的方法,但Cov-PM的重放误差性能要差得多。此外,所有基于目标声场分解的方法都在不同频率下获得相近的声对比度性能,而两者的重放误差性能不同。与LSESM相比,Sparse-ESM在不同的虚声源方向上总是表现出更好的SFR误差性能,这与仿真结果一致。总之,本文所提出的Sparse-ESM方法在所研究的多区域重放问题上表现出更好的性能。
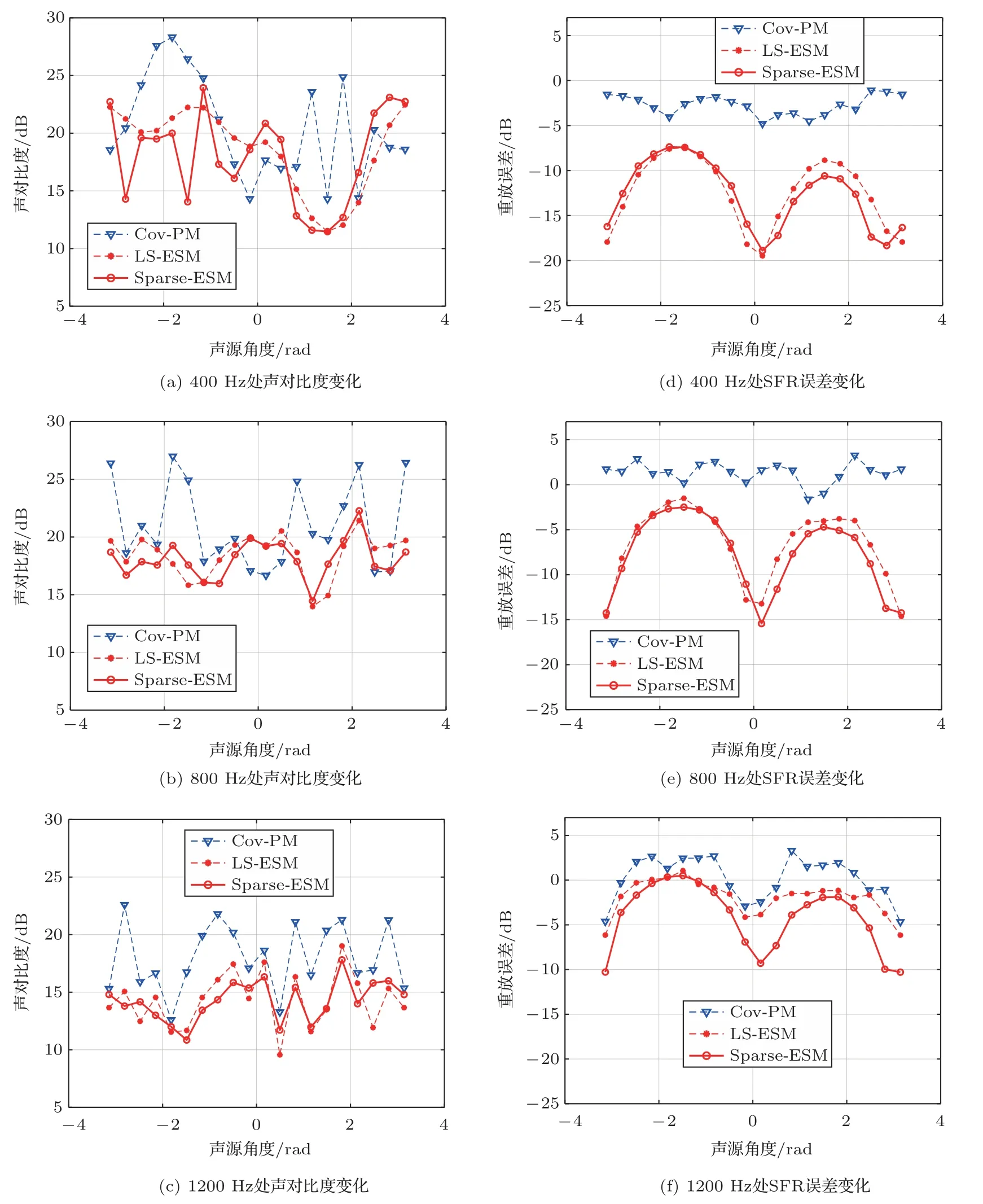
图10 不同频率下重放误差和声对比度随虚拟源方向的变化实验结果Fig.10 Reproduction error and acoustic contrast results at different frequency under different target source directions
对于传统的Cov-PM方法,受限于有限的目标声场测量点,因此只能控制在混响环境中少量的测量点上的声场。这意味着在测量点之外的位置处的声场无法被考虑到优化问题中。这也是Cov-PM的SFR误差相对于仿真中结果差异较大的原因。而本文中使用的基于目标声场分解的方法,首先获取了一组点声源发生器权系数,因此可以实现整个重放区域上的声场控制,这也是本文方法相较于Cov-PM方法性能提升的根本原因。本文使用的Sparse-ESM方法适用于具有稀疏性的目标声场,对于更复杂的声场则不具有明显性能优势。
5 结论
对于一类特殊的声场景,也就是目标声场由少量声源组成时,本文提出了基于稀疏等效源分解的Sparse-ESM对多区域SFR进行房间补偿的方法。通过进行数值仿真和在真实的房间中进行实验,将所提出的方法与Cov-PM、LS-ESM进行了详细的比较。与LS-ESM相比,本文方法在亮区上的性能提升,降低了重放误差,同时在所设置的暗区上保持了相近的安静程度。在仿真过程中,以不同的虚拟源方向研究了该方法的性能。重放误差随着虚拟源方向的变化而波动。然而,与LS-ESM方法相比,本文所提出的Sparse-ESM在亮区上总是实现较好的SFR效果,并保持了相近的声对比度。最后,在一个真实的房间里进行了实验,从实验得到的结果中也可以得出同样的结论。虽然Cov-PM实现了更高的声对比度,但在亮区上的SFR几乎失败。综上所述,当目标声场是由少量声源产生时,本文提出的方法更适用于混响环境下的多区域重放。
致谢感谢亚琛工业大学声学技术研究所(ITA)提供的实验设备与场地,感谢Michael Vorlaender教授提供的帮助。
猜你喜欢
青少年科技博览(中学版)(2022年9期)2022-11-01
家庭影院技术(2021年7期)2021-08-14
五金科技(2020年3期)2020-06-28
海洋信息技术与应用(2020年1期)2020-06-11
铁道通信信号(2020年12期)2020-03-29
家庭影院技术(2019年8期)2019-08-27
家庭影院技术(2018年11期)2019-01-21
中国医学影像学杂志(2018年9期)2018-10-17
中国医药指南(2017年16期)2017-01-15
中国设备工程(2016年8期)2016-08-31
