
一种用于大数据内容安全监测的快速相似匹配并行算法
2022-11-25 04:38王晓霞孙德才
现代计算机 2022年17期
王晓霞,孙德才
(渤海大学信息科学与技术学院,锦州 121013)
0 引言
随着互联网的高速发展,人们可以利用各种新媒体工具在网络上发表自己的观点,由此也使一些话题迅速成为网络焦点话题。面对数量庞大的网络言论,网络信息安全监测领域的研究需要引入海量大数据分析技术[1]。大数据信息安全是为适应大数据时代的舆情和服务而发展起来的,是专注于海量信息采集、监测和分析等技术的一个新的研究领域。
如何从巨大的数据集中快速找出满足要求的信息,是信息安全监测研究中需要解决的一个基本问题。在大数据清洗中,为去除相似信息,常采用相似连接[2-6]技术。当前的相似连接算法主要有单机算法和并行算法。单机算法因单节点计算能力有限导致其横向扩展能力不强,并行算法因其运行在分布式集群的多节点上,横向扩展能力较强,渐渐成为一种主流技术。MapReduce框架是一种高效的分布式编程框架,基于MapReduce框架的相似连接并行算法[4-10]在大数据处理中被广泛采用。它的主要研究内容包括V-SMART-Join[7]、PassJoinKMR[8]、Mass-Join[9]、SAX[10]和FS-Join[11]等。
大数据内容安全监测的快速相似匹配并行算法是大数据处理中的热点问题,对应出现了很多先进的算法,MassJoin算法是一个支持多数据集的相似连接算法,能快速找出文本集间编辑距离[8]满足要求的文本对,算法分为四个阶段:统计阶段、过滤阶段、验证阶段1和验证阶段2。然而该算法在匹配速度上稍显不足。
本文将改进MassJoin算法[9]中的过滤和匹配技术,并提出一种新的基于MapReduce框架的并行算法MQSM(MapReduce and Q-gram based Similarity Match),拟解决信息安全监测中的快速相似匹配问题。
1 内容相似匹配及新过滤方案
1.1 基于内容的相似匹配的问题定义
基于内容的相似匹配是从一个已知的文本集中找出与给定查询集中匹配度达到要求的所有文本,匹配度定义如下:
定义1给定两个文本s和d,称s为查询串,d为文本串,两串间的q元匹配度定义为
式(1)中,simq(s,d)为两串间的q元匹配度,|s|为串长,[s]q为文本s拆分得到的连续且重叠q-1个字符的q-gram[12]的总数目(q-gram是一个长度为q的子串),即[s]q=|s|-q+1,Sq(s,d)为文本s拆分得到的[s]q个q-gram在文本d中出现的个数,Cq(s,d)为s的[s]q个q-gram构 成 的 子串在d中匹配到的最长子串长度。当q=1时为字符级别的匹配度,当q>1时为多元匹配度。在该匹配度公式中,前半部分描述的是q-gram的覆盖情况,后半部分描述的是q-gram的连续情况。如:s为“thirty”,d为“thirsty”和q=2,则|s|=6,[s]2=5,Sq(s,d)=4,Cq(s,d)=4(th,hi,ir三个连续且重叠q-gram构成的子串为最长匹配子串),最终sim(2“thirty”“,thirsty”)=0.73。这里的匹配度不同于编辑距离[7],编辑距离描述的是两个串间的近似情况,而本文的匹配度描述的是一个串在另外一个串中匹配的情况。
在内容信息安全监测系统中,给定一个查询集和一个大文本集,系统要在大文本集中快速发现与查询集中匹配度达到要求的文本,这里查询集通常是一个由关键词(词或句子)构成的集合。设某个查询总共有N个关键词,则此时公式(1)中
定义2基于内容的相似匹配问题:给定查询集Q、大文本集D和q元匹配度参数τ,基于内容的相似匹配问题是在Q和D间找出所有满足simq(si,dj)≥τ,si∈Q,dj∈D的所有匹配对。
如给定查询集Q和文本集D如表1,在每个集合中“#”号前面的是查询编号或文本编号,后 面 的 是 内 容。如τ=0.9,q=2,则sim2(s1,d1)=1≥0.9是 一 个 匹 配 对;而sim2(s2,d2)=0.85<0.9,则不是匹配对。

表1 查询集和文本集例子
1.2 基于内容的相似匹配过滤方案
因给定的大文本集D中含有大量的文本串,查询集Q中也有一定数量的查询串,因此潜在串对是海量的。而计算所有可能串对的匹配度需要花费大量的时间,因此本文拟采用过滤器先过滤掉那些不满足要求的串对,然后再对通过过滤的候选对进行计算。为实现快速过滤,新算法提出了一种基于分割子串的过滤方案。
定理1给定查询串s、文本串d和q元匹配度参数τ。设串s中共有N个关键词,把每个关键词si都分割成||si-q+1个连续且重叠的长度为q的q-gram,设文本d中含有这[s]q个q-gram中 的Sq(s,d)个,此时如则一定有simq(s,d)<τ,即s,d一定不是匹配对。
证明:设因N≥1,q-1≥0则因文本d共享了Sq(s,d)个q-gram,则能构成的最长匹配子串长度和不超过Sq(s),d+N(q-1),即Cq(s,d)≤Sq(s,d)+N(q-1),则即
2 MQSM相似匹配算法
给定查询集Q、大文本集D和匹配度参数τ,相似匹配算法需要快速找出满足匹配度要求的查询/文本对。本文提出的新算法MQSM采用MapReduce框架来实现相似匹配的并行计算,算法包括三个阶段:配对阶段、过滤阶段和验证阶段。每个阶段又包括Map过程、Shuffle过程和Reduce过程。其中Shuffle过程会将Map过程中生成的所有键/值对按键值进行混淆、排序,并把具有相同键的键/值对送到同一个Reduce节点,作为Reduce过程的输入,以后各阶段中的Shuffle过程因原理相同不再描述。MapReduce是一个分布式编程框,因此程序在集群中运行时各数据节点会开启众多的Map任务和Reduce任务进行并行计算。
2.1 配对阶段
由1.2节可知,定理1是一个无关对过滤条件,使用定理1能抛弃那些共享q-gram数目达不到要求的查询/文本对。为方便地使用定理1进行快速过滤,需要对输入的查询和文本进行字符串分隔,然后才能根据查询串和文本串间共享子串的情况进行过滤。
2.1.1 Map过程
每个Map任务处理的数据是一个键/值对n,c,其中n是数据分片号(内容的偏移量),而数值c则是查询集Q或文本集D中的一行内容。此时需根据内容来源不同进行分别处理。为进行相似匹配,新算法针对内容c生成索引子串或匹配子串,具体过程如下。
生成匹配子串:如分片来源于查询集Q,从内容c中提取出查询编号sid和查询内容s(“#”分隔)。因为查询s是一个关键词(词或句子)集合,首先提取出所有关键词。为使每个关键词都能在容忍一定量错误的情况下匹配到文本集中的文本,需把每个关键词都拆分成连续且重叠q-1个字符的q-gram。设sji表示关键词si第j个q-gram,0≤j<|si|-q+1,则输出一个作为匹配子串的键/值对,即
生成索引子串:如分片来源于文本集D,则提取c中文本编号did和文本内容d。为使查询中拆分得到的q-gram能够匹配到该文本,新算法把d也拆分成连续且重叠的q-gram,设dk表示d的第k个q-gram,0≤k<|d|-q+1,则输出一个索引子串的键/值对,即
2.1.2 Reduce过程
每个Reduce任务将处理Shuffle结果中的一个键/值对,即
2.2 过滤阶段
配对阶段的输出结果是所有候选对的集合,由大量的键/值对
2.2.1 Map过程
因该阶段的输入来源是配对阶段的输出结果和文本集Q,这里根据来源分别进行处理。如键/值对
2.2.2 Reduce过程
每个Reduce过程的输入是Shuffle过程输出的一个键/值对,即其中sid键为查询编号。新算法先遍历值列表list(list(did)/(#s))内的所有项,如该项以‘#’开头,则该项是查询的内容,内容保存到s中;否则,该项是与该查询候选的文本编号列表list(did),则循环list(did)中的每个did,并把各文本的q-gram命中数组H[did]增1,直到list(list(did)/(#s))处理完毕。此时发现如list(list(did)/(#s))中无文本did,则该查询无匹配;否则,先拆分查询内容s并统计关键词总数tn、查询总长tl,然后检查命中数组中每个H[did]。
2.3 验证阶段
验证阶段的主要任务是计算每个候选对的真实匹配度,并输出达到要求的真实匹配对。过滤阶段结束后输出了所有候选对,此时候选对已有查询串内容但缺少文本串的内容。因此验证阶段除需要读取过滤阶段的输出结果外,还需要读取文本集D。
2.3.1 Map过程
每个map任务的输入是键/值对
2.3.2 Reduce过程
每个Reduce任务处理的是一个键/值对,即
3 实验分析
3.1 实验配置及环境
本文采用Java语言在Hadoop平台上实现了新算法MQSM。为对比集群分布式算法和单机算法的性能差别,实验中还实现了一个单机多线程算法,记为MTSM。本实验的数据来源于Sogou实验室的Sogou新闻语料库(http://www.sogou.com/labs/),处理后的文本集和查询集详情见表2。本次实验中配置的Hadoop集群环境共包括5个节点,其中主节点1个;节点硬件条件为8 G内存+处理器i5 4590。MTSM算法设置线程数为4,运行在单一节点上。因中文的特殊性,一般单字不具含义,而两字以上的词才有意义,因此后面实验中都设置q=2。
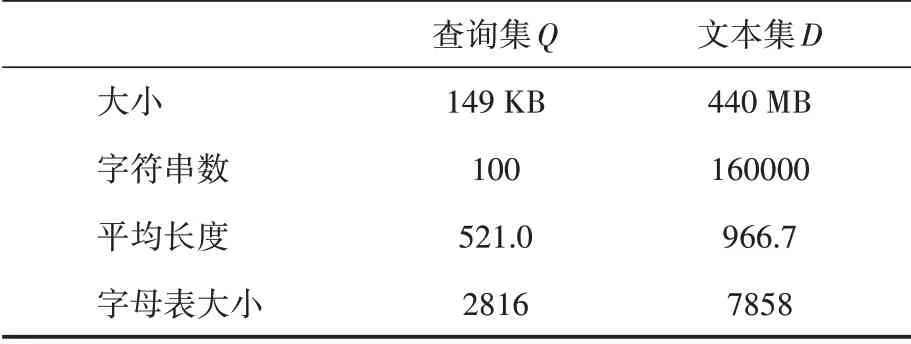
表2 实验数据集信息
3.2 实验结果分析
评价一个算法的优劣主要有两方面指标,一是时间消耗,二是空间消耗,显然在相似匹配算法中匹配速度更重要。给定不同大小的文本集,算法的匹配速度则不同。为衡量文本集大小对算法匹配速度的影响,本次实验中使用参数配置q=2,τ=0.7,查询集如表2所示,文本集中字符串数目分别为40000、80000、120000和160000。参与实验的算法包括分布式集群算法MQSM和单节点多线程算法MTSM。实验结果对比如图1所示。
由图1可知,MTSM算法在文本集较小时的匹配速度要快于MQSM算法。但随着文本集的不断增大,MQSM算法的并行优势不断提高,最后匹配速度超过了MTSM算法。这主要是因为MTSM算法是一个单机内存多线程算法,随着文本集的增大处理能力逐渐不足,而新算法MQSM是一个基于MapReduce框架设计并运行在多节点集群上的并行算法,更适合大数据集的处理。从图1中曲线的变化趋势可知,MQSM算法和MTSM算法的匹配时间与测试文本集的大小总体上呈线性关系。
匹配度参数变化对算法性能的影响称为算法的敏感度。为测得新算法MQSM对匹配度的敏感度,在文本集(160000条)上分别采用不同的匹配度参数(τ=0.7,0.8,0.9,1.0和q=2)进行了相关实验,随着匹配度参数的变化,新算法的性能表现如图2所示。
由图2可知,匹配度参数的变化对MQSM算法的影响不大。随着匹配度的增大,算法的匹配速度稍有提高。这是因为算法的主要时间花费在配对阶段和过滤阶段,而匹配的验证阶段因结果较少而消耗时间较少。因MQSM算法中的配对阶段和过滤阶段受匹配度的影响较小,所以当匹配度增大,过滤条件变严,输出候选对相对少些,只是稍微减少了一点验证时间。因此,MQSM算法对匹配度的变化敏感度较小,较适合匹配度变化范围较大的应用场景。
4 结语
本文研究的主要内容是用于大数据内容安全监测的相似匹配技术。文中先给出了相似匹配相关问题的定义。为能在算法中快速过滤掉那些一定不存在真实匹配的无关对,文中总结出了基于q-gram命中数特征的候选对过滤定理。最后提出并实现了一种用于大数据内容安全监测的快速相似匹配并行算法。文中通过实验证明本文提出的新算法,利用字符串分割和过滤技术加快了相似匹配的速度。作者将继续研究更加苛刻的过滤条件和非连续的q-gram拆分等技术,拟通过减少配对阶段子串的输出量来降低算法的配对时间和过滤时间。
猜你喜欢
科学与社会(2022年1期)2022-04-19
小学生学习指导(低年级)(2021年12期)2021-12-31
计算机应用与软件(2021年10期)2021-10-15
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
莫愁(2019年36期)2019-11-13
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
