
电力信息系统大数据的高效处理
2022-11-25 10:08林宇照
通信电源技术 2022年13期
林宇照
(广东电网有限责任公司茂名供电局,广东 茂名 525000)
0 引 言
随着大数据时代的到来,各行各业在数据处理方面的需求越来越大,电力企业亦是如此。电力系统信息化水平的提高,使得数据处理量逐步增加,进而导致企业无法合理、高效地获取信息。如此一来,既降低了业务应用系统的工作效率,导致海量数据统计分析性能下降,同时不能实时掌握业务生产动态,无法满足决策层需求。鉴于此,当前应重点做好大数据高效处理方法的深入研究,有效解决电力信息系统当前存在的各类问题。
1 电力信息系统概述
1.1 基本概况
总体而言,可以将电力信息系统的大数据处理分为两种类型,即联机事务处理与联机分析处理。一方面,对于联机事务处理而言,主要是针对交易的处理系统。具体应用期间,需要把相关客户的原始数据传输到计算中心,经过计算后得到相应结果,用户大多是管理人员或者是操作人员,可根据需求快速存取历史数据。高级管理人员或决策人员还可深入了解数据信息情况,便于管理、决策工作的开展。对于信息系统而言,其内部有着各种类型的统计业务需求,属混合应用场所。对于企业管理系统而言,操作人员可利用财务信息平台,开展实时查询、统计等工作,并且可借助财务流程监控系统实现对数据的监控。另一方面,利用生产管理系统中的状态检修评价平台,能够根据设备运行数据对设备运行状态做出评估,这属于第二种类型的应用场景。
1.2 高效处理原则
信息系统大数据的高效处理遵循如下原则。
(1)业务使用效率高。在开展大数据算法更新工作期间,应当满足现阶段电力系统业务发展需要,同时还应尽可能改善数据统计分析的性能。
(2)减少改造工作量。加强对现有系统的利用,尽量减少现有系统改造期间的工作量,并制定性价比较高的处理方案[1]。
(3)横向扩展能力强。随着电力行业的快速发展,电力信息系统涉及到的数据越来越多,因而在数据计算处理方面的需求越来越复杂。鉴于此,在开展电力信息系统大数据处理工作期间,应当考虑到用户需求与数据量的实际情况,提高横向扩展能力,并为系统的后期维护、升级提供帮助。
1.3 电力信息系统存在的问题
以某电力企业电能质量在线监测系统作为分析案例,对系统普遍存在的问题进行分析。
(1)系统运行相对较慢。当系统登陆之后,数据刷新速度较慢。同时,集成数据的确认、汇总明细查询等操作速度缓慢。
(2)用户体验差。在计算请求提交之后,需要等待几十分钟。在进行欢迎页面的刷新时,需要全页面同步加载,进而拉低了用户体验。系统应用期间,还经常出现月度分析报表导出失败等问题。
(3)应用服务宕机频繁。该系统的整体可靠性较差,并且数据库内存的使用率相对较高。其四,存在集成数据接入延迟等方面问题。
2 电力信息系统基本特征
上文中提到,大数据问题总体可以分为两种类型,即联机事务处理(On-Line Transaction Processing,OLTP)以及联机分析处理(On-Line Analytical Processing,OLAP)。首先,OLTP通常被称为面向交易的处理系统。通过该系统的应用,能够处理大量、简单并且规模小的相关日常事务,例如在12306火车票订购系统中就有相应的应用。该系统应用期间,有着较快的响应速度与较低的错误率。其次,OLAP可进行相对复杂的分析操作,查询过程更加直观、易懂[2]。此外,通过OLAP技术的合理使用,可以从不同的角度针对大量历史数据开展快速、交互存取等工作,进而对数据信息开展深层次的应用。对于电力信息系统而言,应当结合实际的数据统计业务需求,做好OLTP以及OLAP的混合应用OLTP与OLAP的关系如图1所示。
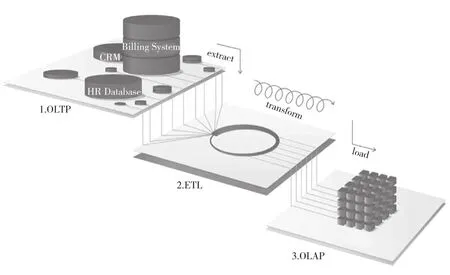
图1 OLTP与OLAP的关系
3 电力信息系统大数据的高性能处理方法
针对大数据处理工作的实际需求和特点,将某电力企业电能质量在线监测系统作为案例,在开展高性能处理工作期间,主要用到分布式技术等,下面结合实际情况做出分析。
3.1 分布式文件系统
为满足分布式存储等方面的要求,在开展数据资源处理工作期间,应重点做好分布式文件系统的研究与应用,并提供分布式以及扩容扩展文件系统。该系统的合理应用既能有效处理好数据访问等方面的问题,并且需要合理应用分布式文件系统,进而显著提高大数据处理水平和效率。同时,还可满足存储方面的需求。系统主要由主设备、从设备构成,其中主设备的功能是开展元数据信息的存储,从设备的功能主要以存储数据信息为主。利用主设备、从设备结构,可以实现对分布式文件系统的科学有效部署,使得系统功能得以改善,同时还能改善扩展系统的性能。当分布式文件系统发生故障时,应当借助文件副本进行相关数据、信息的快速恢复。
3.2 并行计算
(1)搭建分布式平台的过程中,利用Map Reduce等一系列软件,能够以大并行的方式,实现数据的快速、科学梳理。通过Map Reduce软件框架的合理使用,可以把任务发送到多个机器内,借助并行方式,同时开展大数据集的处理。(2)并行计算期间需要结合实际需求,简化处理流程,进而有效缩短数据的处理与分析时间。(3)Map以及Reduce均属独立性计算节点,可以达到同时运算的目的,进而改善大数据运算与处理工作的效率。(4)将计算节点进一步转化为存储节点,能够有效避免数据传输期间出现网络堵塞等各类问题。(5)分布式技术系统主要利用计算机服务器,实现对各类任务的准确分解,并实现计算结果的汇总。(6)单台计算机有着内存优先的特点,通过Hadoop思维方式的合理应用,能够将多台计算机组成集群,进而提高了任务完成过程中的效率。(7)采用分布式存储和计算,还能满足计算集群横向扩展性方面的要求,并且减少系统的成本。该框架主要由对象管理服务器组成,同时还包括客户端代理、对象服务器等相关设备。客户端代理可以实时地接收到不同用户的任务,之后借助管理服务器,提高任务分配期间的科学性。就对象管理服务器而言,需要合理应用任务服务器索引表,最终对各类任务进行合理的分配[3]。(8)在利用监控对象服务器的过程中,当计算工作完成之后,可以及时接收相应的计算结果,进而将计算结果提供给用户。
3.3 多维索引
基于大数据的多维索引,总体上囊括了以下几个不同的方面。(1)合理利用Filter阶段,可以对大数据候选集进行初步的过滤。(2)借助Refinement阶段能够确保相关的数据、信息得到更加详细化、全面化收集。(3)能保证信息数据有着良好的完整性。(4)把所需要的数据信息传输出去。通过索引技术的使用,可显著提升大数据信息查询的效率,并且能够改善分析工作的质量。除此之外,加之分布式平台转变传统Hadoop的合理应用,可显著提升信息查询过程的效率。另外,为全面改善应用支持效果,应积极做好分布式平台的建设工作,更好地支持二级索引和互补索引等,最终可以明显地提升索引效果。
3.4 内存优化
内存优化工作包括:(1)通过数据缓存技术的合理利用,既能够提升索引和访问效率,同时还能有效解决输入输出性能问题,并减少数据查询的时间。(2)通过内存计算技术的合理使用,可以在一定程度上提高数据读取的速率,进而改善计算期间的效率。
设计期间,要着力提高数据检索和存取的速度[4]。在检索内存数据的过程中,应当对分布式查询的描述进行简化,并做好数据块的定义。这一过程中,由于用户的需求与业务应用存在差异,用户可能需要多次的调用、查询结果。因此,应当根据用户的实际情况合理设置数据块的数量。在开展分布式查询工作时,结合本地数据查询的相关数据,通常将其称之为基础数据块;对于反馈给用户的相关数据,可以将其称之为结果数据块。为了可以在短时间内查找结果数据块,需要对基本数据块进行多次调用。为保证序列定位有着一定的准确性效果,设计人员应当采用二分法搜索明确二进制位置。除此之外,还应当在这一方法的支持下,插入位置能够准确的定位。在进行数据处理期间,应当结合具体情况,选用适宜的数据处理方法。对于本地查询方法而言,可以根据用户的查询条件,把满足要求的相关数据添加到BD,BD是有序序列,新添数据采用改进二分法排序。如此一来,便能显著提升插入位置搜索的准确性效果。同时,还可以将其插入到BD中。需要注意的是,一旦BD数据大于N时,那么要及时地对首尾元素进行清除,以便获得局部结果。在插入操作过程中,可以采用改进二分法,对相关位置进行准确的查找。
4 实例分析
在进行分布式平台的搭建时,应当注重多种处理方法的应用,进而提高电力信息系统的稳定性效果,并满足海量数据存储要求。平台搭建期间还要考虑到复杂计算以及高效查询等方面的要求。图3为分布式并行计算平台应用框架示意图。

图3 分布式并行计算平台应用框架示意
4.1 分布式平台组成
从图3分布式平台应用框架示意图可以看出,这一平台的应用,既能够实现终端信息的接收,同时还能实现档案、关系、设备信息等数据的采集。首先,合理利用业务算法,能够满足大数据并行计算方面的要求[5]。借助业务应用服务接口,还能对相关结果进行及时的反馈。除此之外,合理使用业务应用系统,可以及时进行标准化指令的传输。对于存储环境来说,该系统能够在Hadoop架构上进行存储。除此之外,利用关系型数据库,及时获取相关的档案数据。此外,对开发工具集的合理使用,能够提供多种不同的服务功能,该系统还能完成相应的管理工作。借助Map Reduce开展相应的并行计算工作,进而提升数据的处理效率,并进行数据的快速计算。另外,监控工具的使用可实现对系统运行状态的监控,并为后期的检修、养护工作提供帮助,使得系统运行期间的安全性、稳定性大大提升。最后,运行调度工具利用Map Reduce任务,能够有效提升任务关联性、依赖性水平,进而保证了任务执行期间的准确效果。借助于业务应用服务接口,可以提供完善的数据结构。如此一来,既能够提高外部服务系统日常运行的效率,同时还可以改善运行效果与水平。
4.2 典型应用场景分析
通过对某地区电力企业开展调研等工作可以发现,该企业生产运营数据量达到了7.28×108条。通过Oracle数据库平台的合理利用,实现终端通信流量的统计以及低压数据表底电量计算等工作。通过对统计与计算结果的对比,发现该系统平台的应用,可以显著改善大数据的处理性能,与系统原有性能相比,效率至少提高了7倍以上。
5 结 论
国内经济社会的迅猛发展使得居民在生产、生活期间对于电力资源的需求量急剧增大,同时使得用电数据量不断增加,进而增大了电力信息系统数据处理与分析工作的难度。在本文的研究中,开展电力信息系统平台搭建工作期间,首先应当合理利用分布式技术,并借助构建算法与模型的方式使得大数据存储、计算、查询等方面的难题得到了有效的解决。对于技术人员而言,日常工作中应重点加强对大数据技术的研究与应用,同时还要对其内在价值信息做出全面和深度的挖掘,进而有效改善数据应用水平,促进该行业的长远稳定发展。
猜你喜欢
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
管理科学(2021年1期)2021-06-02
军事运筹与系统工程(2020年1期)2020-09-11
电子制作(2019年22期)2020-01-14
电子制作(2019年22期)2020-01-14
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
制导与引信(2017年3期)2017-11-02
