
基于注意力消息共享的多智能体强化学习
2022-11-30 08:39臧嵘王莉史腾飞
计算机应用 2022年11期
臧嵘,王莉*,史腾飞
基于注意力消息共享的多智能体强化学习
臧嵘1,王莉1*,史腾飞2
(1.太原理工大学 大数据学院,山西 晋中 030600; 2.北方自动控制技术研究所,太原 030006)(∗通信作者电子邮箱wangli@tyut.edu.cn)
通信是非全知环境中多智能体间实现有效合作的重要途径,当智能体数量较多时,通信过程会产生冗余消息。为有效处理通信消息,提出一种基于注意力消息共享的多智能体强化学习算法AMSAC。首先,在智能体间搭建用于有效沟通的消息共享网络,智能体通过消息读取和写入完成信息共享,解决智能体在非全知、任务复杂场景下缺乏沟通的问题;其次,在消息共享网络中,通过注意力消息共享机制对通信消息进行自适应处理,有侧重地处理来自不同智能体的消息,解决较大规模多智能体系统在通信过程中无法有效识别消息并利用的问题;然后,在集中式Critic网络中,使用Native Critic依据时序差分(TD)优势策略梯度更新Actor网络参数,使智能体的动作价值得到有效评判;最后,在执行期间,智能体分布式Actor网络根据自身观测和消息共享网络的信息进行决策。在星际争霸Ⅱ多智能体挑战赛(SMAC)环境中进行实验,结果表明,与朴素Actor‑Critic (Native AC)、博弈抽象通信(GA‑Comm)等多智能体强化学习方法相比,AMSAC在四个不同场景下的平均胜率提升了4 ~ 32个百分点。AMSAC的注意力消息共享机制为处理多智能体系统中智能体间的通信消息提供了合理方案,在交通枢纽控制和无人机协同领域都具备广泛的应用前景。
多智能体系统;智能体协同;深度强化学习;智能体通信;注意力机制;策略梯度
0 引言
深度强化学习(Deep Reinforcement Learning, DRL)[1-2]在无人机编队、自动驾驶和游戏等场景表现出优异的性能。将DRL引入多智能体系统[3],形成了多智能体强化学习(Multi‑ Agent Reinforcement Learning, MARL)[4-5],MARL领域的一大挑战是:在非全知环境下对于复杂且协作要求高的任务,智能体需要密切配合才能实现团队利益的最大化。
沟通是相互理解的基础,良好的信息交流能确保合作的顺利开展。通信策略的有效学习对智能体准确感知外在环境、提升决策质量具有重要的支撑作用。利用MARL学习智能体间的通信策略以促进合作成为近年来研究进展迅速的课题,涌现出了通信神经网络(Communication Neural Net, CommNet)[6]、双向协调网络(Bidirectionally‑coordinated Net, BicNet)[7]、针对性多智能体通信(Targeted Multi‑Agent Communication, TarMac)[8]、个性化可控连续通信网络(Individualized Controlled Continuous Communication Net, IC3Net)[9]、博弈抽象通信(Game Abstraction Communication, GA‑Comm)[10]、双注意力Actor‑Critic消息处理器(Double Attention Actor‑Critic Message Processor, DAACMP)[11]等一系列代表性研究成果。
本文聚焦于通信机制下较大规模多智能体系统的消息处理。通常,通信消息越多,意味着智能体获知的状态信息越多,学习效果会获得提升。然而,在MARL设置下,共享通信消息中并非所有的消息都是有用的;对所有通信消息进行统一处理,往往会造成重要信息的丢失。因此,对智能体通信消息有效识别并进行处理是多智能体协作的一个关键。
本文提出一种基于注意力消息共享的多智能体强化学习算法AMSAC(Attentional Message Sharing multi‑agent Actor‑Critic)来解决上述问题。首先,针对单个智能体观测具有局限性,执行期间协作能力有限的问题,AMSAC以Actor‑Critic架构为基础设计了消息共享网络,智能体通过对通信消息的读取和写入操作完成通信消息共享,提升Actor网络在决策时利用附加状态信息的能力;其次,为了有效处理大量通信消息,AMSAC在消息共享网络中设计了一种注意力消息处理机制,以增强智能体自适应识别并处理重要通信消息的能力;最后,在集中式Critic网络,AMSAC引入时序差分(Temporal Difference, TD)优势策略梯度[12]更新Actor网络参数,采取有效的方式充分利用全局信息对智能体动作进行评估。在AMSAC决策的过程中,智能体能有效识别重要信息并从大量通信消息中选择真正有价值的信息进行学习,同时集中式Critic网络能为智能体提供良好的指导。因此,AMSAC能成功解决上文提到的关键问题。
本文在多智能体协作环境:星际争霸Ⅱ多智能体挑战赛(StarCraft Multi‑Agent Challenge, SMAC)[13]的四个不同场景下进行实验,所有场景都具备较多数目的智能体。结果表明:本文算法AMSAC能有效识别并处理智能体的通信消息,在所有场景中展示出优于其他基线方法的性能。同时,实验结果表明通过简单的通信架构来增加智能体决策时的附加状态信息并不能稳定获得良好的性能表现,这种结果也印证了本文提出的注意力消息共享机制的有效性。
本文的主要工作包括:1)针对单个智能体只接收局部观测,训练协作行为的能力有限的问题,基于Actor‑Critic架构设计了消息共享网络,增强智能体沟通交流的能力;集中式Critic网络采用TD优势策略梯度,充分利用全局状态动作信息,对智能体执行动作的价值进行合理评估。2)针对智能体数量较多时存在无法有效识别并处理消息的问题,建立注意力消息共享机制有侧重地选择重要消息进行学习,提升智能体自适应学习有效信息的能力。3)在多智能体协作环境SMAC上与基线模型比较,本文算法AMSAC在四个场景下均优于基线模型。
1 相关工作
根据多智能体系统中消息传递是否存在明确的通信信道,相关研究可分为基于显式通信的方法和基于隐式通信的方法。本章首先对MARL通信机制的相关研究进行论述,然后介绍注意力机制(attention mechanism)在MARL领域的相关工作。
1.1 通信方法
基于显式通信的方法是在智能体之间建立明确的通信机制,基本框架是采用深度神经网络(Deep Neural Network, DNN)建立通信渠道以帮助智能体进行沟通并完成决策,在此类方法中,DNN是端到端进行训练的,其隐藏层信息被视为消息[6],智能体可以在进行策略学习的同时学习如何将这种消息传输到其他智能体,以及如何处理从其他智能体接收的消息以更好地优化自身决策促进合作。
CommNet是这类研究的一个代表工作,它使用DNN来处理全局所有智能体发送的所有消息,并将处理后的消息统一用于指导所有智能体合作。IC3Net通过在消息聚合步骤中应用门控机制,在通信过程中主动选择或屏蔽来自其他智能体的消息。GA‑Comm设计了一种图注意力机制,在策略网络进行博弈抽象,简化多智能体学习的复杂度,加快学习速度。基于显式通信的方法通常采用REINFORCE (REward Increment Nonnegative Factor Offset Reinforcement Characteristic Eligibility)[14]范式训练策略网络,依据回合制对网络参数进行更新;但是,由于它不具备集中式Critic网络,使得这种训练方法无法充分利用全局信息对智能体动作进行评价。
基于隐式通信的方法不设计明确的通信模块,通常采用集中式Critic网络和分散式Actor网络相结合的框架,利用Critic网络得到的全局信息评判Actor网络决策的动作价值,每个智能体的Actor网络独立执行动作决策。多智能体深度确定性策略梯度(Multi‑Agent Deep Deterministic Policy Gradient, MADDPG)[15]是基于隐式通信方法的一个代表工作,它将深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)[16]扩展到多智能体设置,其集中式Critic隐式地收集并利用其他智能体的状态和动作信息,能适应混合合作竞争的环境。反事实多智能体策略梯度(COunterfactual Multi‑Agent policy gradient, COMA)[17]构造一个集中式Critic网络利用隐式通信信息并计算特定于智能体的反事实优势策略梯度以指导Actor网络训练。完全分散的多智能体强化学习算法(Fully Decentralized Multi‑Agent Reinforcement Learning, FD‑MARL)是一种分布式学习算法,通过智能体使用其个体奖励和从网络相邻智能体传递来的Critic网络参数作为隐式信息来学习合作策略。这类方法在训练过程中利用全局信息对智能体动作进行评估,但在执行过程中Actor网络独立执行决策,缺乏智能体间的沟通,可能导致算法在面对复杂、协作要求高的场景下难以有效合作。
1.2 MARL中的注意力机制
注意力机制有利于选择重要信息,近几年被引入MARL领域,在一定程度上促进了智能体的学习效果。例如,注意力通信(ATtentiOnal Communication, ATOC)模型[19]提出带有注意力层的双向长短期记忆(Bi‑directional Long Short‑Term Memory, Bi‑LSTM)通信通道,其注意力机制使每个智能体可以根据其状态相关的重要程度有侧重地处理来自其他智能体的消息。多智能体注意力Actor‑Critic(Multi‑Actor‑ Attention‑Critic, MAAC)[20]使用注意力机制对集中式Critic网络进行建模,使用SAC(Soft Actor‑Critic)评估Actor网络的决策价值。DAACMP在Actor和Critic网络都使用注意力机制进行显式信息处理,以获得更好的性能表现。TarMac提出一种有针对性的通信协议来确定与谁通信以及使用注意力网络传输什么消息。
基于以上工作的启发,本文提出了基于注意力消息共享的多智能体强化学习算法AMSAC。但与已有方法的区别在于,本文算法AMSAC有效结合显式通信和隐式通信的方法,基于Actor‑Critic架构建立消息共享网络,利用注意力机制自适应处理消息,提升智能体识别有价值信息的能力;同时,利用集中式Critic网络基于全局状态信息评估智能体的动作价值,以此提升算法的性能。
2 背景知识
2.1 问题定义
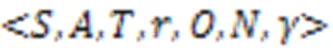
2.2 策略梯度算法

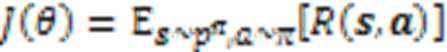
与策略参数相关的梯度表示为:
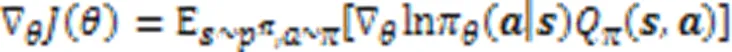
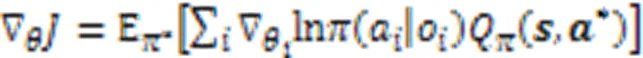
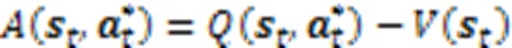
2.3 注意力机制


3 AMSAC算法
本文算法AMSAC的整体架构如图1所示:每个智能体具备负责自身决策的Actor网络,所有智能体共享集中式Critic网络和消息共享网络。在训练期间,智能体通过自身观察和通信消息进行决策,集中式Critic网络评判智能体执行动作的价值并端到端地更新Actor网络和消息共享网络。集中式Critic网络只在训练期间使用。

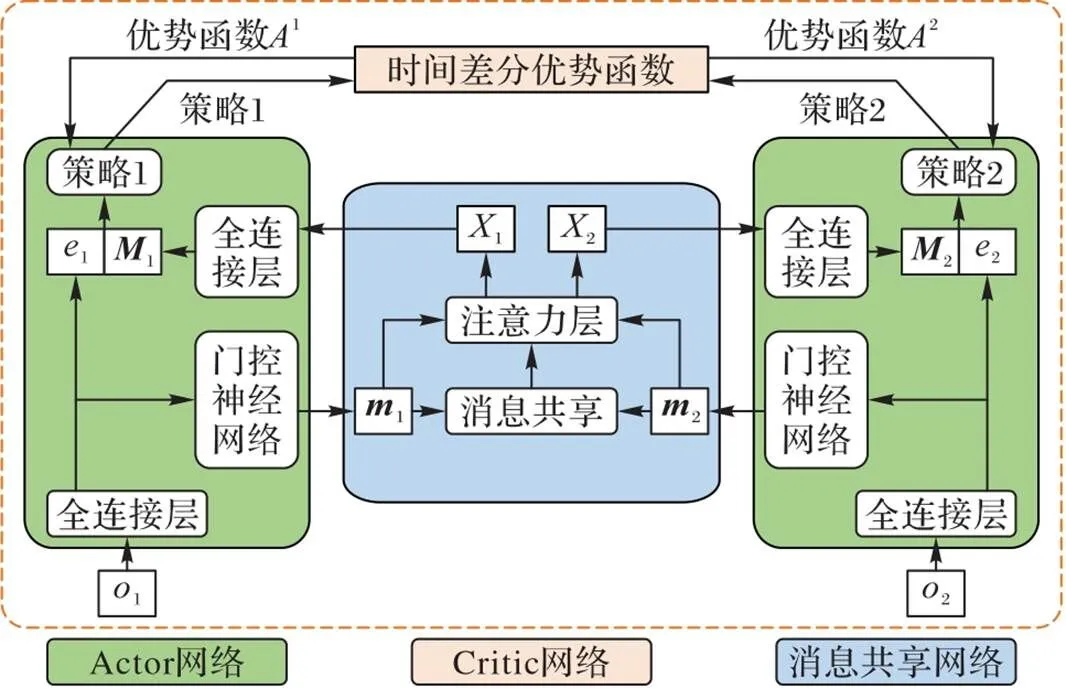
图1 AMSAC的整体架构
3.1 Actor网络
3.2 注意力消息共享网络
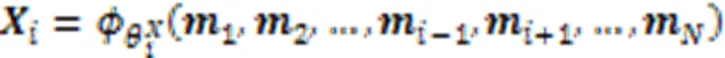
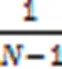

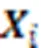

图2 AMSAC的注意力消息共享网络结构
3.3 Critic网络
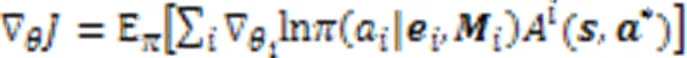
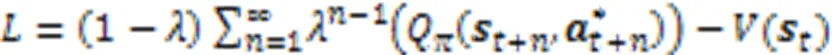

本文认为遵循TD优势策略梯度更新Actor网络参数,能充分利用全局状态信息,准确衡量智能体执行动作的价值。为了验证这一想法,本文结合Native Critic与COMA的分散式Actor网络,称之为朴素Actor‑Critic(Native Actor‑ Critic, Native AC),在实验中作为消融模型与COMA的反事实策略梯度进行了性能比较。
4 实验与结果分析
4.1 实验环境
本文在星际争霸Ⅱ多智能体挑战赛SMAC上进行了性能测试。SMAC由一系列星际争霸Ⅱ微管理游戏组成,旨在评估智能体在解决复杂任务时的协作能力。图3显示了SMAC中的两种场景截图。每个场景中,算法控制的友方单位与内置游戏AI控制的敌方单位作战,当任何一支队伍的所有单位都阵亡,或者当这一回合达到最大时间限制时,就标志着回合结束;只有当敌人单位被全部消灭时,游戏才能胜利;对战目标是最大化游戏胜率。星际争霸Ⅱ经过了版本迭代,不同版本之间性能存在差距,本文采用的是星际争霸Ⅱ的5.0.5版本。
实验中使用SMAC的所有默认设置,包括:游戏难度设置为7级:非常困难;射击范围、观察范围等与默认设置一致;智能体的动作空间由移动、攻击、停止和不操作共四种离散动作组成;智能体只能朝上、下、左、右四个方向移动;攻击动作需要指定敌方ID,只有当敌人在其射程内时才能攻击;选取2s3z、3s5z、1c3s5z和8m共四个具有挑战性的场景对算法进行性能测试。表1展示了SMAC不同地图的场景细节。不同游戏角色具有不同的生命值、攻击力以及攻击范围。

图3 SMAC中的两种不同场景截图

表1 SMAC地图细节
4.2 算法及实现细节
为验证AMSAC的有效性,引入以下消融模型进行比较:
MSAC:在消息共享网络采用全连接网络对通信消息进行处理。Critic网络沿用TD优势策略梯度更新网络参数,命名为MSAC。
Native AC[12]:在Actor网络采用了与COMA算法相同的网络架构,移除消息共享网络,在Critic网络沿用了TD优势策略梯度更新。
还与AMSAC最相关、性能最好的多智能体Actor‑Critic方法和通信学习方法进行比较:
CommNet[6]:是一种显式通信的MARL算法,通过平均处理其他智能体的消息进行通信,智能体对所有消息投入相同的注意力权重。本文利用REINFORCE算法训练策略网络。
COMA[17]:是与本文算法结构、原理最为接近的Actor‑Critic算法,它在Actor网络未使用通信机制,Critic网络则利用反事实策略梯度进行参数更新。
GA‑Comm[10]:一种显式通信的MARL算法,通过图注意力机制对智能体之间传递的消息进行博弈抽象。本文利用REINFORCE算法训练策略网络。
通过AMSAC与MSAC的比较,可以获悉本文提出的注意力消息处理机制应用在消息共享网络的效果;通过MSAC与Native AC的对比,可以了解本文提出的消息共享通信方式与不进行通信的方法的性能区别;同时,引入基线CommNet是为了获悉单纯地将所有消息输入网络并输出所有智能体动作的显式通信方式在性能上与AMSAC的差距;而通过COMA与本文算法的比较可以获悉Native Critic的性能优势以及消息共享网络的有效性;通过GA‑Comm与AMSAC的比较,可以获悉显式通信的集中式控制方案中的图注意力机制与集中训练分布执行的注意力消息共享机制的区别,也能反映集中式Critic与并未充分利用集中训练条件的REINFORCE训练范式的性能差距。
本文的实验结果是在Nivida Geforce RTX 3090,Inter i9‑ 10900k的计算机上运行获得的,每次独立运行需要5~10 h,具体取决于智能体规模等因素。每次运行对应一个随机种子,该种子的网络参数在开始训练时进行随机初始化。

AMSAC和MSAC具备相同的体系结构,除了消息共享网络将64维的全连接层替换为64维的注意力层,其后的全连接层将读取的消息维度固定在32维。Critic网络均设置为每200局游戏进行一次目标网络更新。
4.3 实验结果

图4 独立运行5次后的平均胜率
从图4中可以看出,CommNet在任意场景下都没有学会一种持续击败敌方的策略。这表明,单纯地将所有通信消息不做处理直接输入策略网络并不能学习到有效策略;同时也说明Critic网络对于策略优化具有积极作用。GA‑Comm在大部分场景下表现出优于CommNet的性能,表明其图注意力机制对于集中式消息的处理比单纯的全连接网络更为有效。但两种显式通信方法都不能很好地适应部分难度较大的场景,本文认为这主要是由于缺乏集中式Critic难以充分利用全局信息,使智能体决策得不到良好指导。COMA在四个场景中的三个场景下学习效果不好,这种结果印证了反事实策略梯度与TD优势策略梯度在指导Actor网络上存在性能差距。此外,在部分场景下,MSAC的表现与Native AC相当甚至不如Native AC,这表明对于通信消息的单纯全连接结构并不能准确把握通信消息中的有效信息。
AMSAC在所有任务中获得了最佳性能,表明本文提出的注意力消息共享机制是有效的。此外,在较为简单的场景如8m下,实验中的所有算法都表现出不错的性能,即便是综合表现最差的CommNet也能在训练后期取得60%以上的胜率,在该场景下AMSAC收敛到稳定胜率的速度比MSAC和Native AC慢,我们认为这是因为注意力消息共享机制的架构更加复杂造成的。
在2s3z和1c3s5z等难度提升的场景下,只有少数算法能够学习到有效的获胜策略。在综合难度最大的3s5z场景下,其他基线和消融算法基本完全无法取胜,但AMSAC却能通过其特殊设计的通信架构学习到对于智能体决策真正有价值的信息,在3s5z场景下获得突破性地超过12.5%的平均胜率。
4.4 注意力消息共享机制分析
为了更细粒度地显示消息共享网络的注意力机制如何工作,对2s3z环境中特定智能体对其他智能体消息的注意力权重进行可视化分析。如图5所示,选取一局对局的录像进行分析,同时输出智能体①对于其他智能体消息的注意力权重。可以看出,影响注意力权重的最主要因素是智能体①与其他智能体的距离。例如,由于智能体②和智能体①在本回合中始终保持较近的距离,并且两者均为追猎者角色,因此智能体①始终对智能体②传输的消息抱有较大的注意力权重。此外,智能体③先是远离①而后又接近①,智能体①对于③的注意力权重经历了先减小后增大的过程。最后,智能体①对于对战阵亡的智能体则取消对其消息分配注意力权重。
除此以外,根据输出的注意力权重值,我们认为智能体①对其他智能体投入的关注度还与智能体的角色或种类有关,这是由于相同角色或种类的智能体具备相同的观测能力,因此得到的观测向量在生成消息后有更大地具备高相似度的可能性。图中战斗的最后智能体①对于相近距离的智能体②和智能体⑤投入的注意力权重差距明显也印证了本文的想法。
上述结果与人类的直接认知是一致的:附近的智能体或相同角色的智能体通常对当前智能体有更大的影响,因此通信消息更重要,并且当前智能体已经学会将更多的注意力放在与其更相关的智能体传输的消息上。因此,这种结果支持本文的想法,AMSAC的注意力消息共享机制可以自适应地关注更重要的信息,加快智能体学习到对于其决策真正有价值信息的速度。

表2 单次独立实验的平均胜率 单位: %
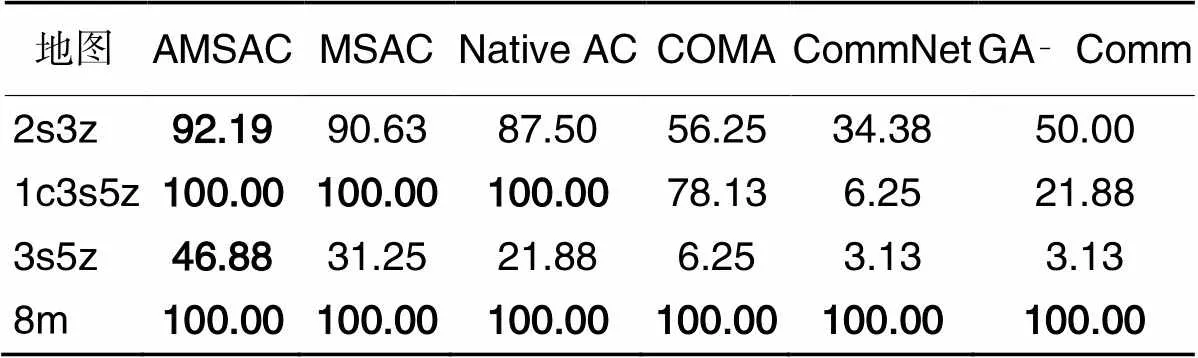
表3 独立实验获得的单次评估最高胜率 单位: %

图5 注意力消息共享机制分析的对战过程截图
5 结语
本文提出了一种注意力消息共享的多智能体强化学习算法AMSAC来自适应识别和处理多个智能体间的大量通信消息。首先设计了消息共享网络,负责对智能体通信的消息进行写入和读取;同时,为了提高智能体对通信消息的处理能力,本文提出了一种注意力消息共享机制,对消息进行有侧重的识别和处理,使智能体学习到真正有价值的信息。此外,AMSAC在Critic网络通过TD优势策略梯度更好地利用全局状态信息评判执行动作的价值。在星际争霸Ⅱ多智能体挑战赛SMAC的四个场景下进行实验,结果表明本文方法性能优于基线模型。同时,消融模型对比表明,本文提出的注意力消息共享机制对于实现更好和更稳定的性能是必要的;对注意力机制的分析表明,AMSAC确实掌握了自适应处理消息的方式。
下一步将考虑应用多头注意力机制或图注意力机制关注来自不同相关智能体和不同消息表征子空间的通信消息。本文关注的智能体数量大多集中在8~10的较大规模,未来也可以考虑将MARL通信方法引入更大规模的多智能体系统,当前的大规模智能体通信方法均包含一系列假设前提,研究如何处理大规模多智能体系统的通信消息,仍然存在极强的必要性。
[1] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human‑level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[2] 刘全,翟建伟,章宗长,等. 深度强化学习综述[J]. 计算机学报, 2018, 41(1):1-27.(LIU Q, ZHAI J W, ZHANG Z Z, et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018, 41(1):1-27.)
[3] TROITZSCH K G. Multi-agent systems and simulation: a survey from an application perspective[M]// UHRMACHER A M, WEYNS D. Multi-Agent Systems: Simulation and Applications. Boca Raton: CRC Press, 2009: 53-76.
[4] HERNANDEZ‑LEAL P, KARTAL B, TAYLOR M E. A survey and critique of multiagent deep reinforcement learning[J]. Autonomous Agents and Multi‑Agent Systems, 2019, 33(6): 750-797.
[5] 孙长银,穆朝絮. 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020, 46(7):1301-1312.(SUN C Y, MU C X. Important scientific problems of multi‑agent deep reinforcement learning[J]. Acta Automatica Sinica, 2020, 46(7):1301-1312.)
[6] SUKHBAATAR S, SZLAM A, FERGUS R. Learning multiagent communication with backpropagation[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 2252-2260.
[7] PENG P, WEN Y, YANG Y D, et al. Multiagent bidirectionally‑ coordinated nets: emergence of human‑level coordination in learning to play StarCraft combat games[EB/OL]. (2017-09-14)[2021-02-12].https://arxiv.org/pdf/1703.10069.pdf.
[8] DAS A, GERVET T, ROMOFF J, et al. TarMAC: targeted multi‑ agent communication[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 1538-1546.
[9] SINGH A, JAIN T, SUKHBAATAR S. Learning when to communicate at scale in multiagent cooperative and competitive tasks[EB/OL]. (2018-12-23)[2021-02-12].https://arxiv.org/pdf/1812.09755.pdf.
[10] LIU Y, WANG W X, HU Y J, et al. Multi‑agent game abstraction via graph attention neural network[C]// Proceedings of the 34th Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 7211-7218.
[11] MAO H Y, ZHANG Z C, XIAO Z, et al. Learning multi‑agent communication with double attentional deep reinforcement learning[J]. Autonomous Agents and Multi‑Agent Systems, 2020, 34(1): No.32.
[12] SU J Y, ADAMS S, BELING P. Value‑decomposition multi‑agent actor‑critics[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2021: 11352-11360.
[13] SAMVELYAN M, RASHID T, SCHROEDER DE WITT C, et al. The StarCraft multi‑agent challenge[C]// Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. Richland, SC: International Foundation for Autonomous Agents and MultiAgent Systems, 2019: 2186-2188.
[14] WILLIAMS R J. Simple statistical gradient‑following algorithms for connectionist reinforcement learning[J]. Machine Learning, 1992, 8(3/4): 229-256.
[15] LOWE R, WU Y, TAMAR A, et al. Multi‑agent actor‑critic for mixed cooperative‑competitive environments[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6382-6393.
[16] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-05)[2021-02-12].https://arxiv.org/pdf/1509.02971.pdf.
[17] FOERSTER J N, FARQUHAR G, AFOURAS T, et al. Counterfactual multi‑agent policy gradients[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 2974-2982.
[18] ZHANG K Q, YANG Z R, LIU H, et al. Fully decentralized multi‑agent reinforcement learning with networked agents[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 5872-5881.
[19] JIANG J C, LU Z Q. Learning attentional communication for multi-agent cooperation[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 7265-7275.
[20] IQBAL S, SHA F. Actor‑attention‑critic for multi‑agent reinforcement learning[C]// Proceedings of the 36th International Conference on Machine Learning. New York: JMLR.org, 2019: 2961-2970.
[21] BERNSTEIN D S, GIVAN R, IMMERMAN N, et al. The complexity of decentralized control of Markov decision processes[J]. Mathematics of Operations Research, 2002, 27(4): 819-840.
[22] SUTTON R S, McALLESTER D, SINGH S, et al. Policy gradient methods for reinforcement learning with function approximation[C]// Proceedings of the 12th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 1999: 1057-1063.
[23] KONDA V R, TSITSIKLIS J N. Actor‑critic algorithms[C]// Proceedings of the 12th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 1999: 1008-1014.
[24] MNIH V, HEESS N, GRAVES A, et al. Recurrent models of visual attention[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2014: 2204-2212.
[25] CHO K, MERRIËNBOER B van, GU̇LÇEHRE Ç, et al. Learning phrase representations using RNN encoder‑decoder for statistical machine translation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1724-1734.
[26] XU K, BA J, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 2048-2057.
[27] CHUNG J, GU̇LÇEHRE Ç, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[S/OL]. (2014-12-11)[2021-10-25].https://arxiv.org/pdf/1412.3555.pdf.
[28] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
Multi‑agent reinforcement learning based on attentional message sharing
ZANG Rong1, WANG Li1*, SHI Tengfei2
(1,,030600,;2,030006,)
Communication is an important way to achieve effective cooperation among multiple agents in a non‑ omniscient environment. When there are a large number of agents, redundant messages may be generated in the communication process. To handle the communication messages effectively, a multi‑agent reinforcement learning algorithm based on attentional message sharing was proposed, called AMSAC (Attentional Message Sharing multi‑agent Actor‑Critic). Firstly, a message sharing network was built for effective communication among agents, and information sharing was achieved through message reading and writing by the agents, thus solving the problem of lack of communication among agents in non‑omniscient environment with complex tasks. Then, in the message sharing network, the communication messages were processed adaptively by the attentional message sharing mechanism, and the messages from different agents were processed with importance order to solve the problem that large‑scale multi‑agent system cannot effectively identify and utilize the messages during the communication process. Moreover, in the centralized Critic network, the Native Critic was used to update the Actor network parameters according to Temporal Difference (TD) advantage policy gradient, so that the action values of agents were evaluated effectively. Finally, during the execution period, the decision was made by the agent distributed Actor network based on its own observations and messages from message sharing network. Experimental results in the StarCraft Multi‑Agent Challenge (SMAC) environment show that compared with Native Actor‑Critic (Native AC), Game Abstraction Communication (GA‑Comm) and other multi‑agent reinforcement learning methods, AMSAC has an average win rate improvement of 4 - 32 percentage points in four different scenarios. AMSAC’s attentional message sharing mechanism provides a reasonable solution for processing communication messages among agents in a multi‑agent system, and has broad application prospects in both transportation hub control and unmanned aerial vehicle collaboration.
multi‑agent system; agent cooperation; deep reinforcement learning; agent communication; attention mechanism; policy gradient
This work is partially supported by National Natural Science Foundation of China (61872260).
ZANG Rong, born in 1997, M. S. candidate. His research interests include reinforcement learning, multi-agent system.
WANG Li, born in 1971, Ph. D., professor. Her research interests include data mining, artificial intelligence, machine learning.
SHI Tengfei, born in 1990, M. S., engineer. His research interests include deep reinforcement learning.
1001-9081(2022)11-3346-08
10.11772/j.issn.1001-9081.2021122169
2021⁃12⁃21;
2022⁃01⁃14;
2022⁃01⁃24。
国家自然科学基金资助项目(61872260)。
TP181
A
臧嵘(1997—),男,山西太原人,硕士研究生,主要研究方向:强化学习、多智能体系统;王莉(1971—),女,山西太原人,教授,博士,CCF高级会员,主要研究方向:数据挖掘、人工智能、机器学习;史腾飞(1990—),男,山西晋城人,工程师,硕士,CCF会员,主要研究方向:深度强化学习。
猜你喜欢
中国设备工程(2022年19期)2022-10-12
九江学院学报(自然科学版)(2022年2期)2022-07-02
通信产业报(2020年43期)2020-01-15
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
东坡赤壁诗词(2018年3期)2018-07-16
汽车零部件(2017年4期)2017-07-12
北京航空航天大学学报(2017年12期)2017-04-23
现代经济信息(2016年4期)2016-06-20
中国当代医药(2015年25期)2015-10-21
