
基于集成学习的冲击载荷识别与定位方法
2022-12-02 09:12阳志光郭晨宇杨帆蒋亮亮王斌
强度与环境 2022年5期
阳志光 郭晨宇 杨帆 蒋亮亮 王斌
(北京宇航系统工程研究所,北京 100076)
0 引言
结构在设计阶段因为不了解真实冲击载荷,往往会采用很高的冗余度。获取冲击载荷的大小,有助于优化结构设计,同时对结构可靠性分析、健康监测提供重要的信息[1]。但是作用在结构上的冲击载荷往往难以直接测量,比如火箭发动机点火瞬间对箭体结构的冲击[2]、星箭分离时的冲击载荷[3]。尤其是航空航天结构的设计以重量和体积为重要指标[4,5],安装力传感器会带来很大的负担,改变结构的整体特性,甚至在一些特殊的结构部位和载荷工况下,无法安装力传感器来直接测量冲击载荷。由于加速度或应变响应易于测量,且响应传感器灵巧轻便,更易于布置,因此通过动态响应来逆向识别载荷是一种更实用的方法。
目前已有许多载荷识别方法被提出,主要可以分为频域法[1]和时域法[4]。基于频域法的载荷识别技术发展较早,相对更加成熟,但是要求信号样本具有一定的长度,通常只适用于稳态载荷的识别[6]。在时域内识别载荷因结果更加直观,且适用于瞬态载荷,近些年也得到了发展[7]。动态载荷逆向识别面临的一个主要问题是传递函数矩阵秩不足或者条件数过大,导致解的不唯一或不稳定的病态性问题[8]。目前可以采用奇异值分解方法[9]、正则化方法[10]以及基函数展开式[11]等方法,通过引入额外的超参数,增加约束,来解决病态问题。其中超参数的选取,对于克服病态问题,准确逆向识别载荷至关重要[12]。实际工程结构往往因载荷量级大、极致轻质化、连接部件多等原因而在力学行为上呈现明显的非线性,并且环境噪声也会给结构系统带来不确定性影响[13],导致难以根据结构建立一个准确的模型。近些年随着人工智能的发展,以及计算能力的迅速提升,基于数据驱动的机器学习方法在载荷识别中得到应用[14]。Wang[15]通过支持向量机识别作用在圆筒结构上的多源随机动载荷;Zhou[16]利用深度循环网络识别非线性复合材料板上的冲击载荷。通过结构试验或者建模仿真生成充足的训练数据,并结合领域知识从数据中提取合适的特征,进行监督式学习,训练得到机器学习模型作为代理模型,可以取代冲击载荷和响应之间难以求解的卷积映射关系;并且随着训练数据量增加,涵盖的情况更加丰富,模型对噪声、非线性情况的鲁棒性也越强。
实际上在大多数情况下,冲击载荷作用在结构上的位置是随机的,识别冲击载荷作用位置,也是载荷识别问题的重要组成部分。通过应力波传播的路径和时间,可以定位冲击载荷的位置,但只适用于梁、板等简单的结构[17]。另一种定位冲击载荷的方法是通过残差优化处理[18]来最小化模拟响应和测量响应之间的误差函数,相较于第一种方法,在实际应用中稳定可靠,但在连续结构中计算的时间会随着自由度数的增加而增加[19]。基于机器学习的冲击载荷定位方法,可以快速甚至实时识别载荷大小并且定位冲击载荷的位置。Qiu[20]基于结构应力响应的余弦相似度,提出一种结合相似性度量的模式识别方法快速定位随机作用的冲击载荷,并通过在平面钢板上试验得到了计算效率高、识别准确的结果,但方法是否适用于更复杂的结构形式,还有待进一步研究。
目前冲击载荷识别难以在工程结构中得到大规模应用,主要是受到结构非线性力学行为和环境噪声带来的难以建立模型问题和逆向求解时的病态问题,并且仅通过波的传播过程或者残差优化方法来定位冲击载荷,难以建立准确、适用性广泛、计算量少的公式,因此以响应输入和载荷输出为数据驱动的机器学习方法更具有应用前景。
考虑到单个机器学习模型所面临的欠拟合和过拟合的风险,而深度学习模型参数众多,训练时间长且难以收敛。本文采用集成学习方法识别冲击载荷,基于数据驱动免去了建立模型和逆向求解的问题,直接建立冲击载荷和结构响应之间的映射关系。通过试验获取“载荷-响应”数据集,训练以决策树为基础预测器进行集成学习的自适应提升AdaBoost模型,根据结构响应对冲击载荷做出预测,并在真实的薄壁圆筒结构上对方法进行验证。
1 载荷识别原理
1.1 逆向识别问题
假设一个力学结构为线性定常系统,并且初始条件为 (0) 0y= 和 (0) 0y=˙ ,则载荷和响应之间的关系可以通过如下卷积关系表示:
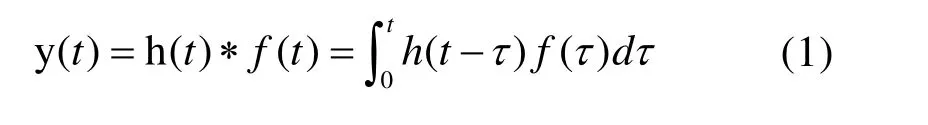
其中h(t)代表在t时刻结构的冲击响应函数,f(t)代表冲击载荷在t时刻的幅值,符号*代表卷积运算,延迟时间算子τ满足t≥τ。
结构响应y(t)是通过对应时刻的冲击f(t)和系统传递函数h(t)卷积运算得到。卷积运算通过傅里叶变换,可以转换为频域内频响函数H(ω)和载荷F(ω)的乘积运算。假设结构系统上响应自由度数为i,载荷自由度数为j,则频域内离散化推导如下:
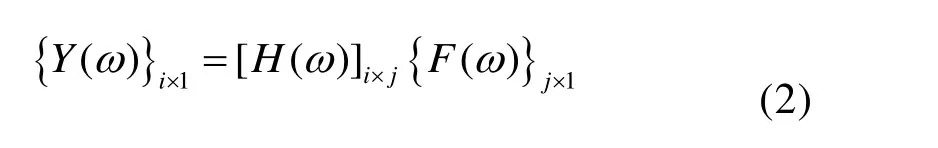
其中{Y(ω)}i×1和{F(ω)}j×1分别为包含i和j个分量的一维响应向量和载荷向量,ω为角频率。
载荷作为激励,引起结构系统的响应,是一个正向过程。通过响应结果来推导载荷激励,即载荷识别,是一个逆向问题。最直接得到载荷的方法是对频响函数矩阵求逆矩阵并与响应向量相乘:
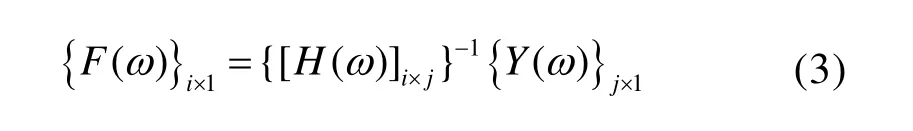
但实际上传递函数矩阵求逆时往往面临着秩亏损、条件数过大等问题,导致逆向求解载荷的结果不唯一或者对噪声非常敏感。虽然可以通过改善响应测点布局、正则化约束方法等提升逆向计算的准确度,但这又面临着测点布局选取和正则化基函数、参数的优化问题,并且随着结构的复杂程度增加,优化难度也大大增加。更重要的是,许多实际的大型复杂结构由于不满足线性或定常假设,其材料参数、几何特征、边界条件无法准确的知道,难以从力学基理上构建结构系统的传递函数。但是,一定存在函数,ijF可以描述结构上载荷输入和响应输出之间的关系:
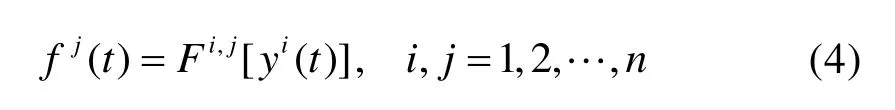
函数,ijF描述了在t时刻作用于结构上j点处的冲击力fj(t)与结构上i点处动态响应yi(t)之间的关系,n为结构的自由度数。
由前面的分析可知,从力学基理上构建系统模型,并逆向求解得到冲击载荷和响应之间的传递函数是十分复杂困难的。采用机器学习方法进行监督式学习,可以直接构建冲击载荷和动态响应之间的映射函数来替代力学模型,实现由动态响应识别冲击载荷。
1.2 集成学习原理
目前机器学习方法已经发展出多种成熟的学习模型。线性模型、支持向量机[21]原理清晰,结构形式简洁,但是学习性能有限,难以建立复杂的映射关系;决策树[22]、神经网络[23]随着模型内部复杂度的增加,可以极大地提升学习能力,但是单个模型容易受极端样本的影响,陷入局部最优。集成学习针对单个机器学习模型所面临的欠拟合和过拟合的风险,同时训练多个基础模型,综合给出判断,同时保证预测结果较低的偏差与方差。其中决策树模型[22]因其决策原理清晰、训练迅速,适合作为集成学习模型的基础预测器。
1.2.1 决策树
决策树算法整体形状类似于树状结构,数据实例从根节点出发,通过对某个特征属性判断决策,分类到相应地子节点后,再次选取对某个特征属性进行决策,不断决策分类直到延伸至叶节点。叶节点根据其包含样本数量中最多的类别,对应一个类;在回归预测任务中叶节点对样本数量值取平均值给出预测。
决策树模型在分类任务的训练过程中,通过CART算法在某个节点处,选取用于决策的特征k和进行分类的阈值tk,算法尝试最小化分类成本函数:

其中G1、G2代表左、右子集的不纯度,通常是计算基尼不纯度,m、m1、m2分别是当前节点实例数量和左、右子集的实例数量。
根据动态响应来预测具体的载荷数值在机器学习中数据回归任务,CART算法分裂训练集的方式由最小化纯度转变为最小化均方误差MSE:
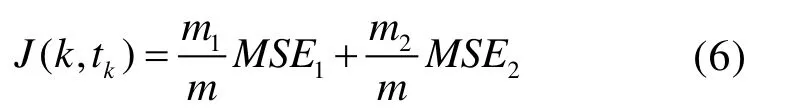
其中节点处分裂子集的均方误差计算公式如下:
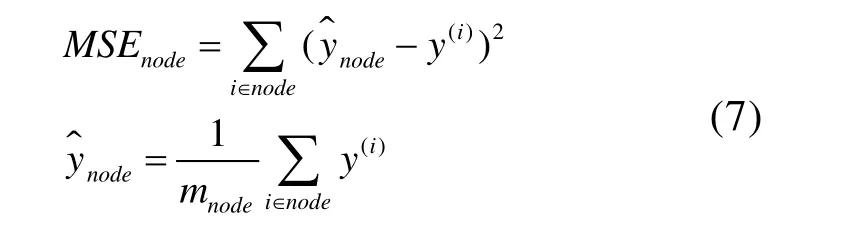
决策树极少对数据做出假设,因此适用于多种数据模型。但是如果不加以限制,决策树结构将一直分裂生长直至严密拟合训练数据,反而会导致在面对全新的数据进行泛化时效果不佳,出现过度拟合。为避免过拟合,通过设置正则化超参数来限制树的生长,降低决策树的自由度。比如超参数“最大深度”控制决策树的最大生长深度,“叶节点最小样本数”控制决策树末端节点所必须有的最小样本数量。
1.2.2 自适应提升法
提升法是指将多个较弱的预测器结合成一个强学习器的任意集成方法,目前常用的提升法有自适应提升法(AdaBoost)和梯度提升法(Gradient Boost)[22]。以决策树为基础预测器,AdaBoost依次训练多棵决策树,每棵决策树都是对之前决策树的预测进行纠正,针对前序决策树拟合不足的训练实例给予更多关注,从而使新的决策树越来越专注于难缠的问题,预测效果逐步提升。
基于AdaBoost算法训练模型时,每个样本的权值w(i)最初设置为1/m,其中m为样本实例数量。第一个预测器完成训练后,计算其加权误差率r1,公式如下:
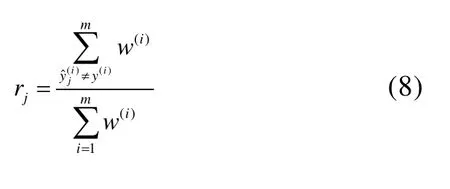
第j个预测器的权重αj的计算如公式(9),其中η为学习率超参数。预测器的准确率越高,则该预测器的权重就越高。当前预测器完成训练后,对实例的权重进行更新,更新规则如公式(10)所示,然后将左右样本实例的权重归一化。
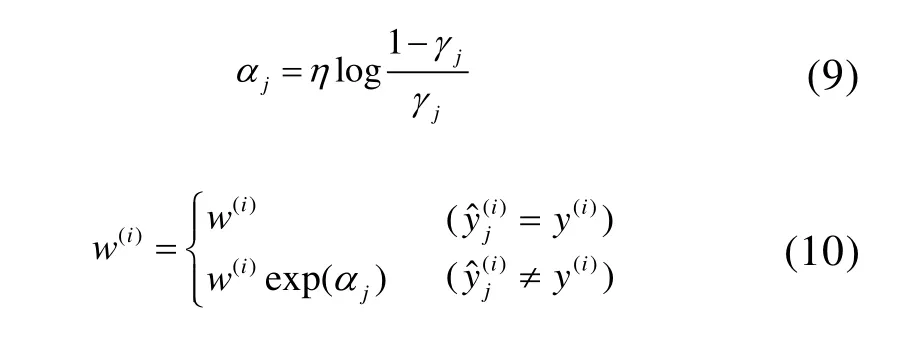
在更新权重后的样本实例上重新训练预测器,如此重复,直至达到所需数量的预测器或者得到满意的预测效果,算法停止。在预测的时候,AdaBoost计算所有预测器的预测结果,并使用每个预测器的权重αj对它们进行加权。
2 冲击载荷识别与定位方法
以决策树为基础预测器,采用自适应提升法训练多棵决策树得到集成学习模型,实现冲击载荷的逆向识别与定位。模型的训练依赖于大量的动态响应与载荷标签的数据集。结构受冲击后采集的动态响应数据量庞大,并且往往受噪声影响,如果直接输入给机器学习模型会严重拖慢学习效率,需要对响应数据滤波去噪,并提取数量少但信息熵高的特征。
2.1 数据预处理与特征提取
为充分获取结构受冲击后的动态响应信息,通常将多个高频应变或加速度传感器布置在结构上。在弹性假设范围内,结构受冲击后的动态响应数据呈现出在基线附近上下振荡并且幅值逐渐衰减的时间序列模式,振荡的周期和衰减的快慢与结构的模态和阻尼相关。然而由于外界环境干扰、采集电信号不稳定等因素,实际测量的响应数据往往会出现基线漂移、噪声混杂的情况。
采用中值滤波方法处理基线漂移问题,其基本原理是将时间响应序列中某一时刻的点用该点邻域中各点值的中值代替。选用较大尺寸的窗口,中值滤波得到初始漂移的基线轮廓,用序列数据减去漂移的基线,就得到了以零值为基线振荡的响应数据。
实际结构的动态响应经过中值滤波后,采用小波变换方法进行降噪。选用‘sym8’小波函数对响应信号进行小波变换后,信息被储存在变换后的小波系数中。其中响应信号的小波系数较大,噪声的小波系数较小。通过选取合适的阈值,认为小于此阈值的小波系数是由噪声产生,将其置为零从而到达去噪的目的,然后还原响应信号。
工程上关注冲击力的大小和冲击作用的位置是否会对结构产生破坏,因此提取每个冲击工况下冲击力的峰值和位置坐标作为监督式学习的标签。接着对初始响应数据进行特征提取,得到与冲击载荷密切相关、信息熵高并且数量尽可能少的输入特征。
根据定性的动力学理论分析,结构受冲击载荷作用会发生振动,冲击力越大,振动得越剧烈,因此将响应的振荡峰值作为特征之一;冲击通过波的形式在结构上传播,先后被结构上的传感器感受到,距离近的传感器更早感受到冲击作用,数据波动也更剧烈,因此将到达振荡峰值的时间作为特征之一;响应初始振荡的脉宽也与冲击相关,将其作为提取的特征之一。至于振荡的周期、衰减率,与结构自身的模态相关,而与外部冲击无关,因此不作为提取的特征。在发生冲击后的前一小段时间内,结构响应与冲击载荷密切相关,其后主要与结构自身的模态信息相关,提取的特征包括响应传感器记录到的最大峰值、到达峰值时间、峰值脉宽,以及自冲击后前5个振荡的峰值、到达峰值时间和峰值脉宽。假设结构上共布置有nx个高频应变传感器,则提取的特征数nf为:

2.2 集成学习模型训练
采集多个冲击工况的数据,以冲击力峰值和冲击位置为标签,对响应数据滤波降噪并提取特征,采用监督式学习训练机器学习模型。数据集按照4:1的比例被分割为训练集和测试集,训练集用来训练集成学习模型,测试集用于对完成训练的模型的载荷识别效果进行评估。
以决策树为基础预测器的AbaBoost模型,其学习效果受模型超参数设置的影响,采用网格筛选结合交叉验证的方法,将训练集进一步分割为新的训练集与验证集,来对模型超参数:叶节点最小样本数min_samples_leaf、集成决策树数量n_estimators和学习率η进行筛选。计算不同参数组合下模型在验证集上的均方根误差RMSE,筛选得到最优参数组合,进一步提升模型的学习性能。
采用3折交叉验证,在初步筛选得到min_samples_leaf=2,对超参数n_estimators和η进一步筛选的结果如图 1。可见在n_estimators=200,η=0.2时,AdaBoost模型可以达到最佳预测效果。完成训练的模型被部署到结构系统上,用于识别冲击载荷。
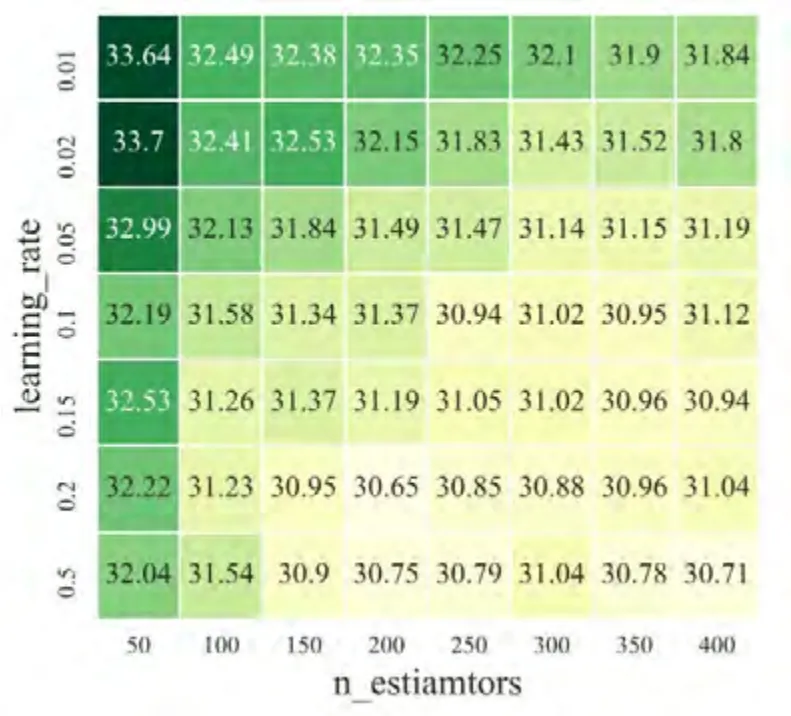
图1 采用3折交叉验证网格筛选的均方根误差Fig.1 Rmse of Grid-search with 3-fold cross-validation
2.3 载荷识别步骤
训练用于识别冲击载荷的Adaboost模型的主要步骤如下:
Step 1:数据采集。在机械结构上作用随机冲击载荷,记录冲击力峰值和冲击位置,采用高频传感器采集响应数据;
Step 2:数据预处理。对响应数据中值滤波和小波变换降噪,提取响应数据中多个振荡峰值、到达峰值时间、峰值脉宽,作为特征;
Step 3:模型训练。提取特征作为输入,冲击力和冲击位置作为输出,采用网格筛选结合交叉验证的方法优化模型超参数,训练得到AdaBoost模型;
Step 4:模型部署。将数据降噪、特征提取、AdaBoost模型集成为系统,实现输入原始响应数据,识别输出冲击载荷的峰值与位置。
将完成训练的AdaBoost模型部署到结构上进行载荷识别的流程如下:
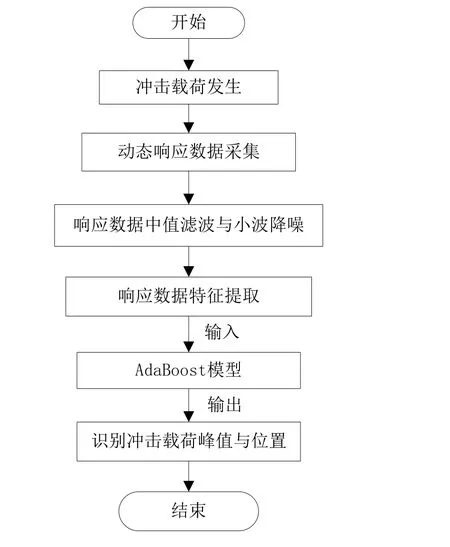
图2 冲击载荷识别与定位流程Fig.2 Process of impact load identification and localization
3 试验系统搭建
铝制薄壁圆筒具有密度低、承压能力强的优秀性质,在航天运载器中经常作为舱段结构,在该结构的缩比试验件上验证冲击载荷识别方法。圆筒结构高度为600mm,直径为1000mm,壁厚1.5mm,端框厚度为4mm。圆筒具有空间曲面构型和上下突出的端框,并且采用4个吊点的悬挂边界条件,具有明显的几何非线性,在承受冲击时结构响应复杂。
在圆筒内部各个象限均匀粘贴应变片,来记录结构应变响应。另外通过一个外表面粘贴的加速度传感器作为触发传感器。当加速度超过量程10%时,记录共计1.5s时长的冲击力和应变响应,其中前100ms为触发前的信号,目的是完整地记录冲击力过程。上述冲击力、应变和加速度均是通过DH5923高速动态数据采集系统进行采集,设定采样频率为5kHz。
考虑到圆筒为轴对称结构,通过轴向高度和周向角度两个坐标定位敲击的位置。沿着轴向均匀划分16行,周向划分64列,如图3所示。力锤敲击这些网格点,记录敲击点的高度和角度作为位置标签,用以监督式学习。最终总共采集了1684条敲击数据,每条数据包含冲击力的历程、冲击作用在圆筒表面的高度和角度,以及应变传感器的响应数据。其中记录到某个样本的冲击力和某个应变片的应变响应如图4所示,可见冲击力的形状比较复杂,应变响应变化迅速,数据量庞大,并且受噪声影响。
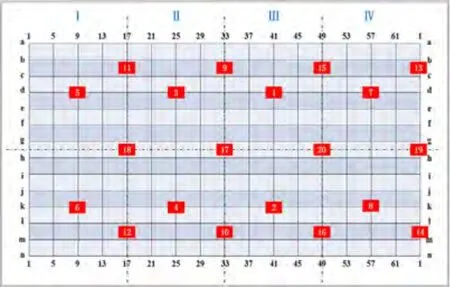
图3 圆筒外表面网格划分及内部应变片分布Fig.3 Distribution of grids and strain gaudes on the surface of the cylinder

图4 冲击载荷和动态响应Fig.4 Impact load and dynamic strain response
4 试验结果与讨论
采用平均绝对误差MAE和相对误差RE作为载荷识别效果的评价指标,计算公式如下:
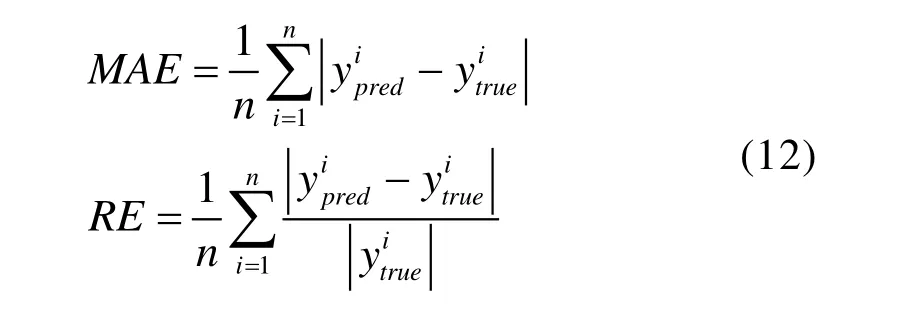
4.1 冲击载荷识别与定位
将采集到动态响应数据进行中值滤波,并选用选用‘sym8’小波函数进行去噪。下图是在某个冲击工况下的应变响应数据以及滤波后的响应数据。可见经过滤波降噪,应变响应数据中基线漂移和噪声问题被很好地解决。
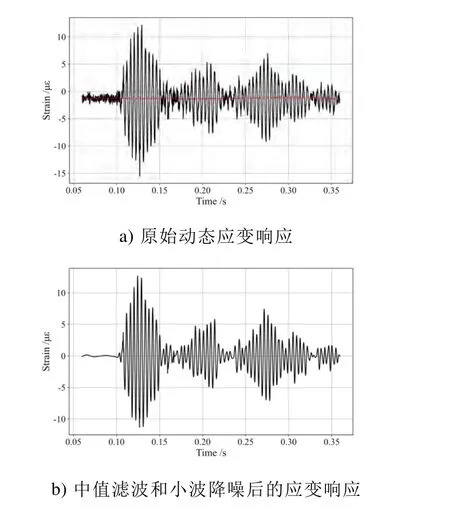
图5 动态应变响应滤波和去噪Fig.5 Filtering and denoising on original strain response
从滤波去噪后的应变响应数据中提取峰值、到达峰值时间和脉宽作为特征,训练AbaBoost模型分别用于识别冲击力的峰值和冲击位置的高度和角度。
训练用于识别角度的模型时,0°和360°在数值上差异最大,但实际上是在同一位置,误差梯度为零,导致在0°识别角度偏大,在360°识别角度偏小。解决办法是对角度标签进行三角函数转换,从而得到在0°和360°处连续一致的标签。但由于单个三角函数在2π周期内的映射不唯一,将角度标签分别进行sin和cos三角函数转换,训练两个模型,根据两个识别结果判断角度范围,从而逆向识别出唯一的角度。角度所在范围与sin、cos函数转换后正负号如下表所示:
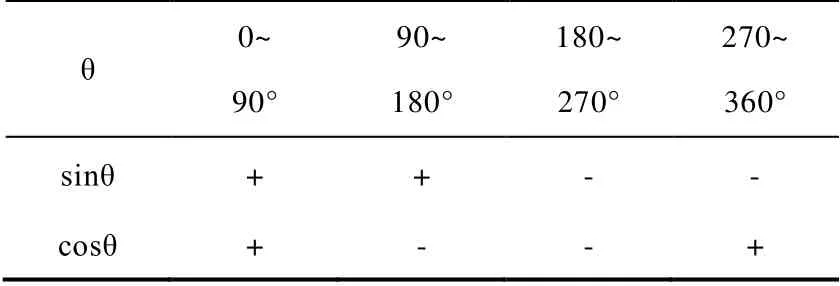
表1 三角函数转换区间Table1 positive and negative signs of the range of angles
下图为在测试样本上,AdaBoost模型对冲击峰值、位置高度和角度的识别结果对实际值的拟合效果。由力锤敲击产生的冲击力分布在0~550N的范围内,从图6 (a)可见识别冲击力峰值对实际峰值的拟合性较好,但是对于峰值较大和较小的样本,拟合稀疏发散,识别误差较大。这主要是因为在手动敲击圆筒时,冲击力样本分布类似于正态分布,导致机器学习在训练时更关注数量上占优势的中段冲击力样本。在图6 (b)中可见,模型对冲击力作用点的拟合效果良好。

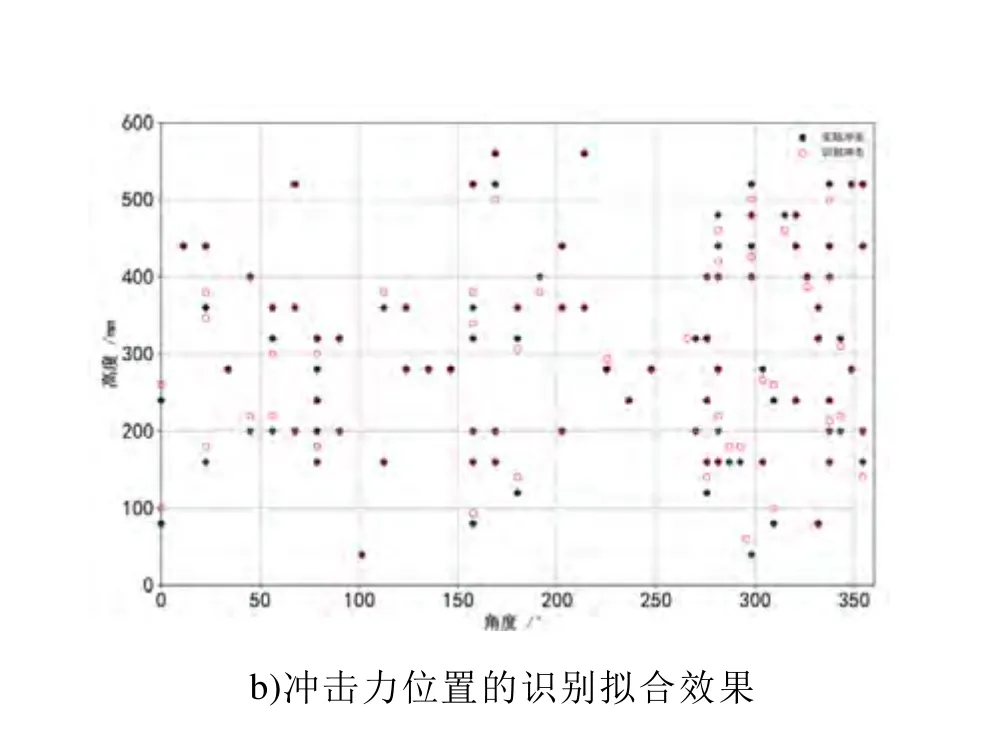
图6 AbaBoost模型的识别结果Fig.6 Identification and loaclisation of impact load using AdaBoost model
AdaBoost模型识别冲击载荷的平均绝对误差MAE和相对误差RE及95%置信区间半径如表 2所示,识别冲击力峰值的MAE=20.56±2.49,MRE=13.44%±1.30%;识别高度的绝对误差MAE=47.05±1.72,以圆筒高度 600mm 为基数的相对误差MRE=7.84%±0.79%;识别角度的绝对误差MAE=1.45±0.49,以圆筒环向一周360°为基数的相对误差MRE=0.40%±0.14%。可见采用Adaboost模型可以较好地识别冲击力大小,并准确定位冲击的位置。

表2 AdaBoost模型识别冲击载荷的误差Table2 Impact load identification error of AdaBoost Model
4.2 边界条件影响
圆筒为空间曲面结构,并且上下两端边界为突出的端框,具有几何非线性。当圆筒承受冲击载荷时应力波从冲击区域四散传播,到达端框边界时发生反射交汇,导致此区域处应力应变响应复杂。从上一节的载荷识别结果可见,在靠近上下端框的边界区域识别误差较大。探讨去除靠近边界的样本,是否能改善载荷识别的准确度。将下端框0~100mm和上端框500~600mm区域定义为边界区域,表3是从测 试集中剔除边界区域内样本后,在中段区域内各个模型识别冲击载荷峰值以及位置与全筒段区域上识别相对误差的对比。

表3 非边界区域冲击载荷识别误差Table3 Impact load identification error in the middle area
在远离端框边界的中段区域,冲击峰值识别的相对误差从13.44%降低到了11.88%,冲击位置高度和角度识别的相对误差分别从7.84%、0.40%降低到了7.03%、0.26%。从图7可见,在远离边界的区域,模型对冲击载荷的识别效果与是实际载荷的拟合效果也更好。边界区域应力环境复杂,非线性程度高,会导致较大的识别误差,因此使载荷作用在远离边界的区域可以改善载荷识别与定位的准确度。
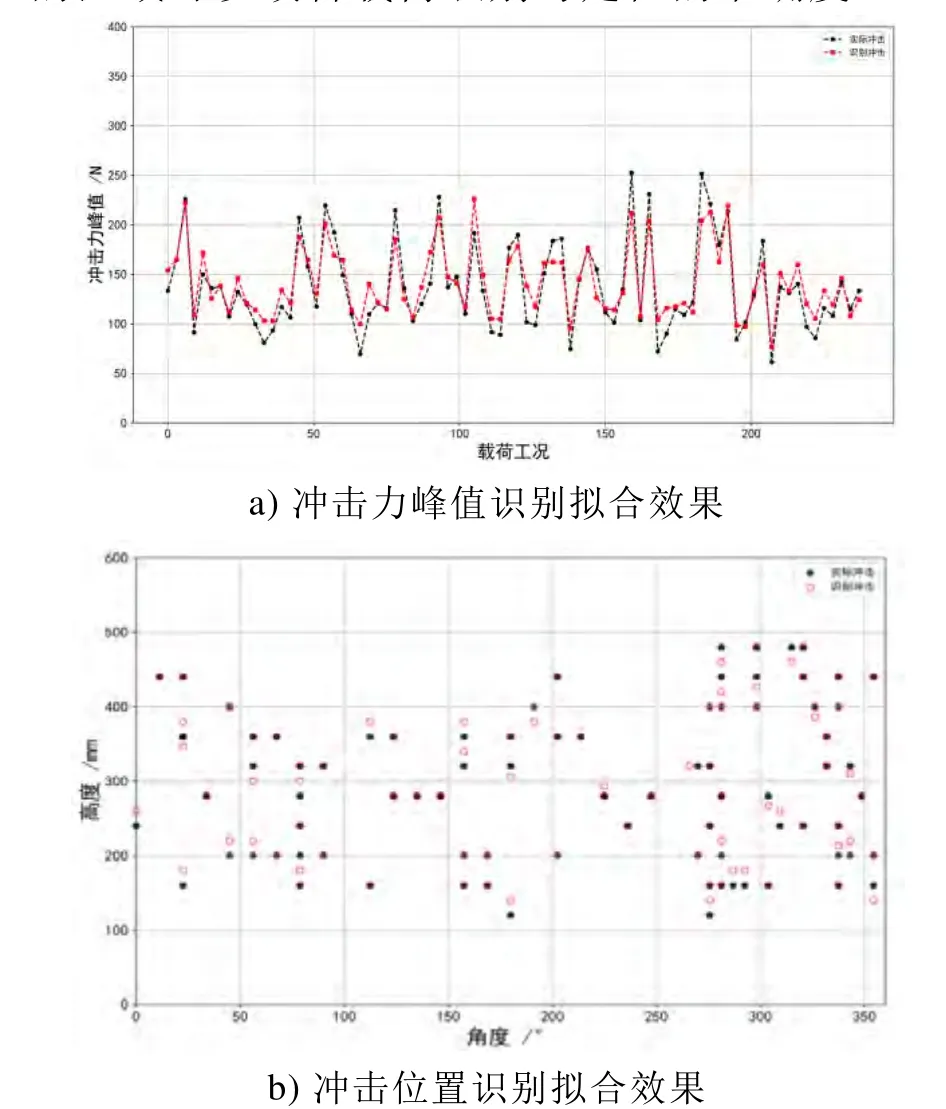
图7 在远离边界区域冲击载荷的识别拟合效果Fig.7 Fitting effect of predicted impact load to actual impact load
5 结论
本文提出基于集成学习识别复杂结构上冲击载荷并定位载荷作用位置的方法。以决策树 为基础预测器,采用自适应提升方法进行集成,通过冲击试验获取“载荷-响应”数据集,进行监督式学习,训练得到AdaBoost模型,实现由动态响应逆向识别冲击载荷,并在薄壁圆筒结构上进行验证,结果表明:
1)集成学习方法可以根据基础预测器的学习效果给予相应的权重,利用群体的智慧提升载荷识别的效果,并有效避免陷入局部最优的过拟合风险;
2)模型的训练依赖于数据的支持,从原始动态响应中去除噪声干扰,并提取数量少、信息熵高的特征,可以提升训练效率和载荷识别的准确度;
3)在靠近结构边界的区域,应力环境复杂,容易产生较大的识别误差,因此设计结构使载荷作用在远离边界的区域可以改善逆向识别的效果。
本文提出的集成学习方法可以识别并定位复杂结构上的冲击载荷,其接近于10%的识别误差满足工程应用需求。但从动态响应中提取合适的特征依赖于工程经验和大量的试验,后续将针对动态响应特征提取和提升载荷识别准确度开展进一步研究。
猜你喜欢
河北大学学报(自然科学版)(2022年3期)2022-06-16
辽宁工业大学学报(自然科学版)(2020年1期)2020-01-07
VOGUE服饰与美容(2019年10期)2019-12-02
成都信息工程大学学报(2019年3期)2019-09-25
重型机械(2019年3期)2019-08-27
电子制作(2018年16期)2018-09-26
微型小说选刊(2016年6期)2016-12-08
体育科研(2016年5期)2016-07-31
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
