
高随机化IPv6地址集合的地址模式过滤方法
2022-12-03 02:03邓裕立王轶骏
计算机应用与软件 2022年11期
邓裕立 王轶骏 薛 质
(上海交通大学电子信息与电气工程学院 上海 200240)
0 引 言
欧洲网络资源协调中心(RIPE NCC)于2019年11月25日宣布最后的IPv4地址空间储备耗尽[1]。一方面是IPv4地址资源的枯竭,另一方面是国内外对IPv6部署的大力推进。《中国IPv6发展状况》白皮书显示,截至2019年6月,国内的IPv6活跃用户数已达1.30亿,基础电信企业已分配IPv6地址的用户数达12.07亿[2]。根据Cisco全球IPv6部署统计数据[3],不少国家的IPv6网络用户比例在最近几年稳步上升。
随着互联网向着IPv6逐步过渡,IPv6环境下的网络测绘引起了一些研究者的关注。然而,长度为128位的IPv6地址相比32位的IPv4地址拥有更加庞大的地址空间,这导致活跃IP地址在网络中的分布显得十分稀疏。如果沿用以往在IPv4网络测绘时所采用的地址空间遍历扫描方法,不仅无法在可接受的时间内完成扫描工作,还难以发现活跃的IPv6地址。因此,IPv6环境下需要合理地选择扫描的目标地址,针对这一问题研究者们提出了多种解决方案:(1) 从各种包含IPv6地址的数据集中采集目标地址[4-5];(2) 借助DNS特性遍历DNS反向域从中收集注册的IPv6地址[6-7];(3) 通过启发式算法挖掘IPv6地址集合中可能存在的模式并生成符合相应模式的目标地址[8-11]。与前两种方法相比,方法3更加灵活,能够发现未被现有数据集记录和不在DNS反向域中的新地址。不过,文献[12]指出这些启发式算法缺乏处理随机化地址集合的能力。当地址集合中包含了较多的没有明显模式特征的随机地址时,地址集合在整体上将呈现出高随机性,算法会受到这类地址的干扰,很难甚至无法发现集合中其他地址存在的模式。
针对上述问题,本文提出一种从呈现高随机化特点的IPv6地址集合中过滤具有潜在模式地址的方法,减少地址集合的随机化程度,方便启发式算法对地址集合进行处理。该方法通过比较地址集合与子集合的信息熵,利用熵值差异发现涉及地址模式的比特位和相应取值,然后根据这些信息从地址集合中过滤出符合条件的地址。
1 背景知识
1.1 IPv6地址
1.1.1IPv6地址类型
IPv6地址类型可以分为3类:
(1) 单播地址。用来唯一标识一个接口,单播地址具体类别如表1所示。
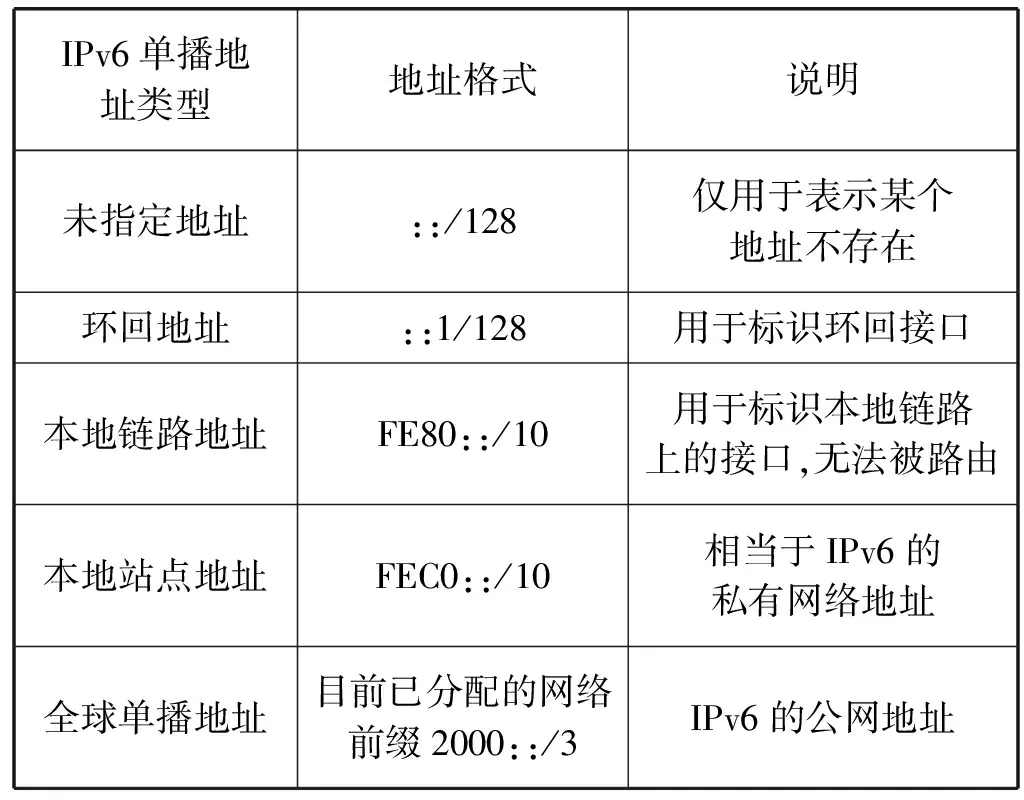
表1 IPv6单播地址类型
(2) 组播地址。用来标识一组接口,发送到组播地址的数据报文会到达此地址对应所有接口。
(3) 任播地址。用来标识一组接口,发送到任播地址的数据报文会到达此地址对应的某个接口,该接口是由相应路由协议计算出的距离源节点最近的一个接口。
在IPv6网络测绘中,主要关注IPv6单播地址中的全球单播地址。根据文档RFC3587[13],全球单播地址由全球路由前缀、子网ID和接口ID三部分组成。全球路由前缀与子网ID通常由地址前64位表示,用于标识一个网段,接口ID由后64位表示,用于标识网段中的一个设备。
1.1.2IPv6地址分配策略
这部分介绍IPv6地址分配策略,主要关注单播地址后64位,即接口ID部分的分配方式。接口ID的分配并没有统一固定的方式。有些分配方式具有规律性,能体现出地址模式特征,而另一些分配方式意图消除模式特征,分配的接口ID呈现很高的随机性。
RFC7707[14]总结了一些具有规律的接口ID分配方式,如表2所示。Modified EUI-64形式的接口ID分配方式是早期IPv6无状态地址自动配置 (SLAAC) 采用的方案,后面几类接口分配方式属于人工配置IPv6地址的手段。表2列出的地址模式特征只是一部分,事实上,正因为接口ID分配没有统一的标准,网络管理员可以灵活地选择分配方式,因此必然存在许多未公开的地址模式。文献[11]的实验也表明网络中有大量不在表2之中的地址模式。大部分地址模式的共同点就是地址中某些比特位的值是恒定不变的,这也是目前的启发式算法能够挖掘的主要地址模式。

表2 一些具有规律的接口ID分配方式
出于安全和隐私保护方面的考虑,一些不体现任何地址模式特征的接口ID分配方式被提出,它们包括:
(1) 临时地址。针对Modified EUI-64分配方法存在的MAC信息泄露、IP追踪等安全问题,RFC4941[15]对SLAAC进行了扩展,该方案下SLAAC产生的地址接口ID为随机生成,并且会随着时间改变。
(2) 恒定且语义模糊的接口ID。Windows系统对RFC4941的一种实现,接口ID随机生成,但不会随着时间改变,并且该接口ID像Modified EUI-64产生的接口ID一样,在设备迁移至另一个网段时不会发生改变。
(3) 稳定且语义模糊的接口ID。IETF在RFC 7217[16]中提出的另一种SLAAC方案,接口ID随机生成,但不会随着时间发生改变,但当设备迁移至另一个网段时,接口ID会发生变化。
(4) DHCPv6随机生成。一些DHCPv6服务器从地址分配范围内按顺序分配IPv6地址,导致IPv6地址的生成容易被预测,因此RFC5157[17]建议DHCPv6服务器从一个很大的地址池中随机选取地址进行分配。
这些随机分配接口ID的方式本身就是为防止地址扫描而设计,即使掌握由这些方式生成的接口ID,也难以从中发现地址规律。因此随机生成的接口ID对启发式算法几乎不起作用,并且还会对启发式算法挖掘地址模式造成干扰,影响算法效果。
1.2 信息熵
熵是对信息不确定度的一种度量,一些研究者借助信息熵来研究IPv6地址结构,包括挖掘地址模式[9]、对IPv6网段进行分类[7]以及预测活跃网络前缀[18]。对离散随机变量X而言,如果X所有可能取值为{x1,x2,…,xn},每种取值出现概率为p(xi)(1≤i≤n) ,那么X的信息熵H(X)为:
(1)
如果将IPv6地址按照m比特为一个单元进行划分,每个单元的取值就是[0,2m-1]范围内的整数。在地址集合中,某一个单元的熵值Hm(X)计算方式如下:用各个取值在地址集中出现频率f(xi)(1≤i≤2m)替代式(1)中的概率p(xi),并进行归一化处理,如式(2)所示。显然,熵值Hm(X)的取值范围为[0,1]。
(2)
2 基于信息熵的地址模式过滤方法
2.1 基本假设
这部分介绍过滤方法涉及的一些基本假设:
(1) 地址集合。假设地址集合中的地址同属于一个/64网段。因为地址的模式特征和随机性均体现在接口ID的后64位,所以后文主要关注地址的接口ID部分。
(2) 地址模式。这里的地址模式仅指地址在某些位取值恒定不变的接口ID分配方式,并且恒定不变的比特位数目超过一定数量。根据地址模式生成的地址可以在非恒定地址位上任意取值。
(3) 随机地址。随机地址的设计初衷是为了消除地址呈现的语义特征,因此假设随机地址的接口ID各个比特位之间为相互独立关系,并且每个比特位取0和1的概率是相同的。
2.2 地址集合的随机化
在介绍本文提出的过滤方法之前,先就随机生成的IPv6地址对地址集合整体随机性的影响进行说明。假设地址集合中一部分为具有某一共同地址模式的地址,其余的均是随机生成的地址。将地址集合中地址的接口ID部分按照半字节 (即4比特) 进行划分,从左至右依次编号为1,2,…,16。如果地址模式在编号为i(1≤i≤16)的半字节上保持恒定,那么地址集合在该半字节上的熵值Hm与随机地址所占比例的关系如图1所示,熵值通过式(2)计算得到。
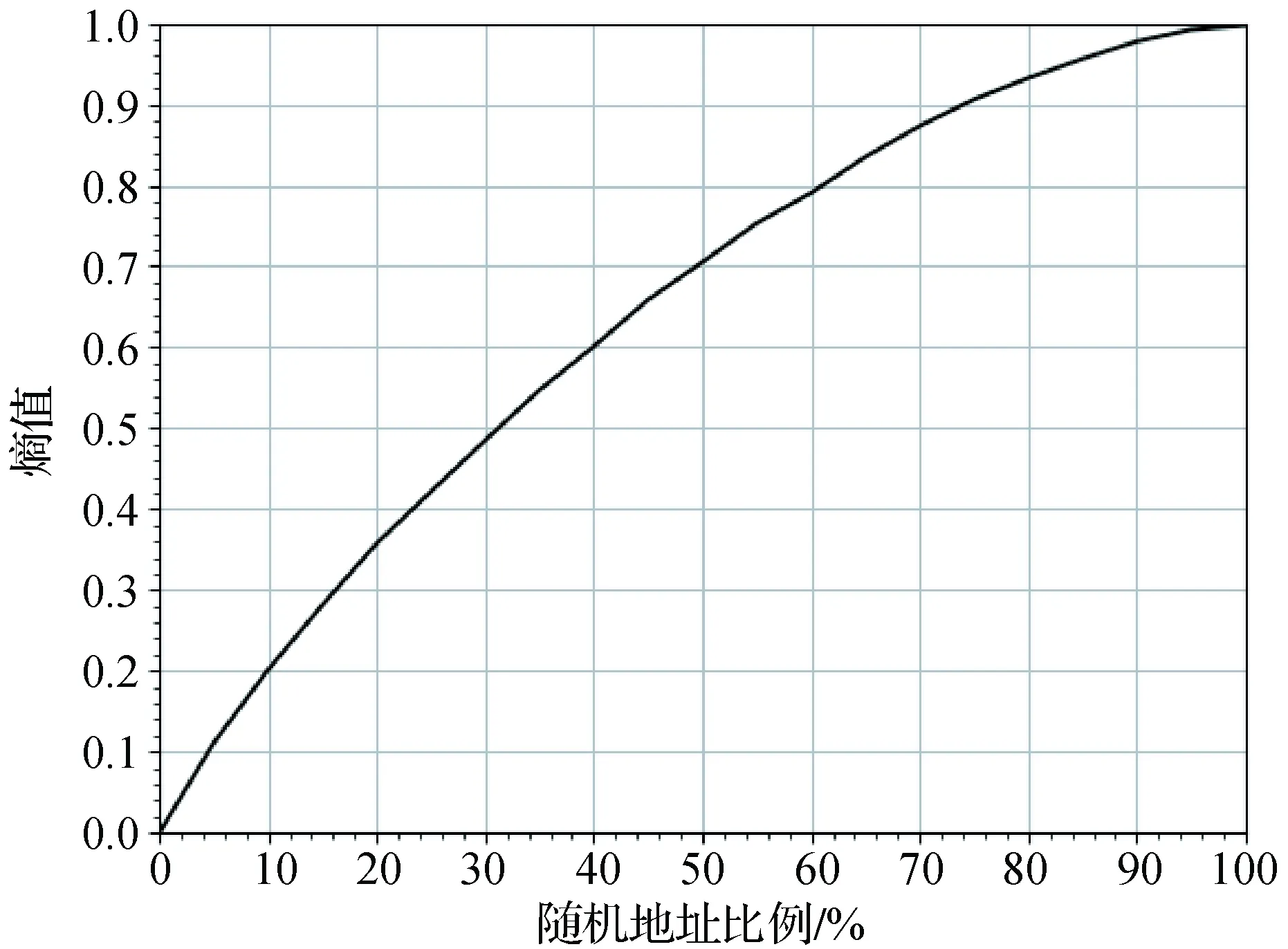
图1 不同随机地址比例下的熵值
由图1可以看出,随机地址对地址集合整体表现出的随机性影响十分明显,当随机地址比例达到60%时,半字节上的熵值Hm就已经达到了0.8,地址集合表现出很高的随机性,目前的挖掘地址模式的启发式算法面对这种情况很难发挥出效果。
2.3 过滤方法原理
本文提出的过滤方法基于地址集合与子集合的熵值差异,识别地址模式可能涉及的地址比特位以及比特位的取值,进而从地址集合中过滤出符合相应模式的地址。下面将从地址集合中只有一种地址模式和有多种地址模式两种情况进行说明。
2.3.1单地址模式
首先将接口ID按照若干个比特位为一个单元进行划分,并对划分后形成的单元从左至右进行编号。为方便说明,这里以半字节进行划分。地址模式表现为在若干个半字节上取值恒定,地址集合中一部分地址由某个地址模式生成,其余均为随机生成的地址。将地址集合根据某个半字节上的取值不同划分为多个子集合,每个子集合中的地址在划分的半字节上取值相同,得到的子集合有3种类型:(1) 划分的半字节不属于地址模式;(2) 划分的半字节属于地址模式但取值不匹配;(3) 划分的半字节属于地址模式且取值匹配。
地址集合各个半字节的熵值根据式(2)计算得到。设地址模式对应地址在原始集合所占比例为p,地址集合在与地址模式无关的半字节上熵值为HN,与地址模式相关的半字节上熵值为HR。原始集合与不同类型的子集合的HN和HR随比例p的变化曲线分别如图2、图3所示,其中origin表示原始集合,type1-type3分别表示3种类型的子集合。可以看出,不同类型的子集合与原始集合的HN差异都不大,熵值差异主要体现HR上。
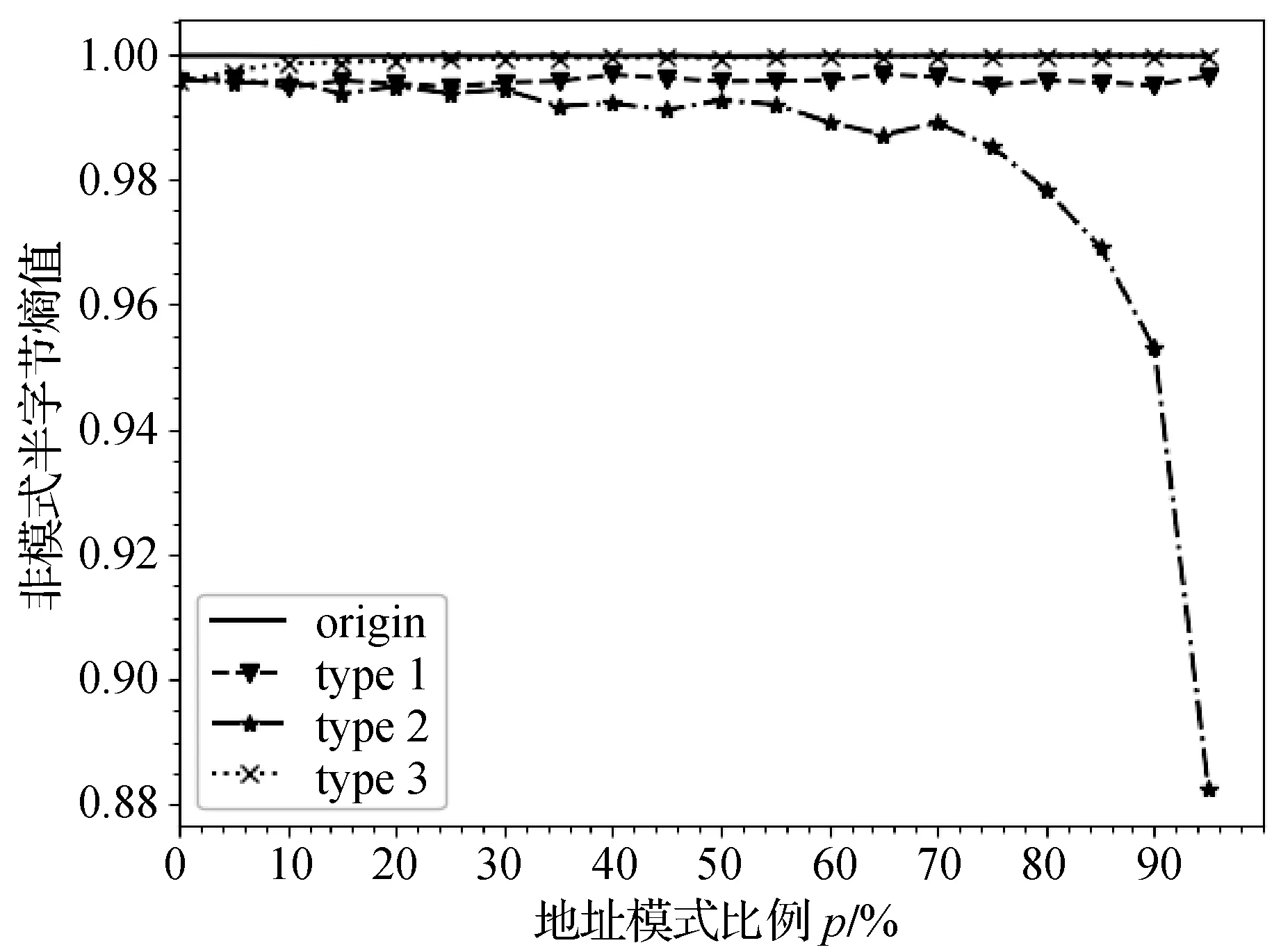
图2 与地址模式无关的半字节熵值HN随比例p变化曲线
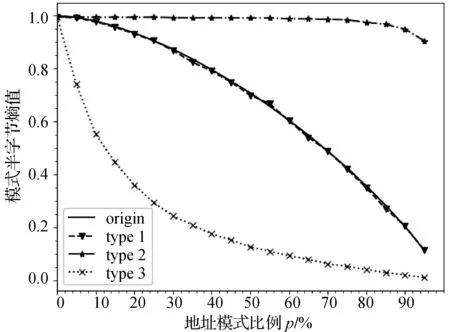
图3 与地址模式相关的半字节熵值HR随比例p变化曲线
3种子集合的HR熵值特征分别为:
(1) 划分的半字节不属于地址模式。子集合HR熵值与原始集合的HR熵值几乎一致,因为划分子集合的半字节与地址模式无关,所以子集合中包含地址模式的地址比例相比原始集合不会发生明显变化。
(2) 划分的半字节属于地址模式但取值不匹配。子集合的HR熵值始终处于较高水平,因为原始集合除了一种地址模式生成的地址外,其余均为随机地址。如果划分子集合的半字节属于地址模式,但子集合在该半字节上的取值与地址模式取值不匹配,就意味着子集合中几乎全是随机地址,因此会表现出较高的熵值。
(3) 划分的半字节属于地址模式且取值匹配。子集合的HR熵值明显比原始集合的HR熵值小,因为这类子集合包含了所有通过地址模式生成的地址,随机地址只在其中占很小一部分,造成HR熵值相比原始集合出现明显下降。这类子集合与原始集合HR熵值之差与比例p的关系如图4所示。由图4可知,当比例p在4%~88%之间时,熵值差均不低于0.2。
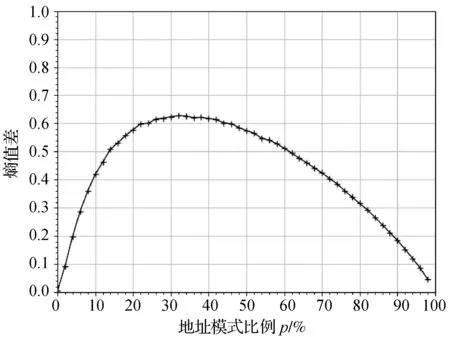
图4 第3类子集合HR熵值差随比例p变化曲线
综上,3种子集合与原始集合之间的不同熵值差异特征可以用来判别地址中哪些比特位可能属于地址模式,并且可以进一步确定地址模式在相应位置上的取值。
2.3.2多地址模式
如果地址集合中包含多种地址模式,这些地址模式按照当前划分子集合的半字节可以分为两类:一类是与划分子集合的半字节相关的地址模式,记为P1型模式;另一类是无关的地址模式,记为P2型模式。划分的半字节不同,分类得到的P1型模式和P2型模式也不同。通过划分得到的子集合会有以下4种类型:
(1) 划分的半字节不属于任何地址模式。这种情况与单字节模式的子集合类型(1)类似,由于划分的半字节不属于任何地址模式,子集合中各种地址模式所占比例不会出现明显变化,从而表现为子集合与原始集合的熵值没有明显差异。
(2) 划分的半字节属于地址模式但取值与所有P1型模式都不匹配。该情况与单字节模式的子集合类型(2)类似。P1型模式地址都不会出现在子集合中,子集合中只有P2型模式地址和随机地址,会导致子集合的熵值相比原始集合的熵值更大。
(3) 划分的半字节属于地址模式且取值仅与1个P1型模式匹配。该情况与单字节模式的子集合类型(3)类似。匹配的P1型模式地址会全部出现在子集合中,使得子集合中P2型模式地址和随机地址的比例减小,造成与所匹配的P1型模式相关的半字节上熵值降低。
(4) 划分的半字节属于地址模式且取值与多个P1型模式匹配。子集合中会包含匹配的多种P1型模式地址,因为这些P1型模式各自相关的半字节和半字节上取值不全相同,可能会导致子集合在各个与模式相关的半字节上熵值减少量降低,特别是当这些匹配的P1型模式在集合中所占比例相近的时候,熵值减少程度会变得十分微小。不过这类子集合不会对地址模式过滤产生明显影响,因为一个地址模式往往会关联地址中多个半字节,只要不是所有半字节上都存在(4)这种情况,就可以区分出该地址模式。
通过以上分析可以认为地址模式过滤方法不仅适用于单地址模式的地址集合,也能应用于多地址模式的地址集合。
2.4 过滤方法实现
假设每个地址的接口ID部分按m比特划分后形成的单元共有n个,从左至右依次编号为1,2,…,n。过滤方法中涉及3个临界值,分别为:
(1) 子集合最小大小min_size。如果划分得到的子集合大小小于min_size,则跳过该子集合与原始集合的熵值比较。当子集合过小时,各个取值的频率很难反映出实际出现的概率,式(2)不再适用。
(2) 地址模式的最小熵值差D。如果原始集合与子集合在某个地址单元上的熵值之差不小于D,则认为该地址单元可能与地址模式相关。否则认为原集合与子集合在该地址单元上熵值差异不大。
(3) 一个地址模式中包含的最少地址单元数N。假设在子集合中,除划分得到该子集合的地址单元外,有k个熵值差不小于D的地址单元。只有当k+1≥N时,才认为这k个地址单元加上划分单元可能构成一个地址模式。
过滤方法的流程如图5所示。
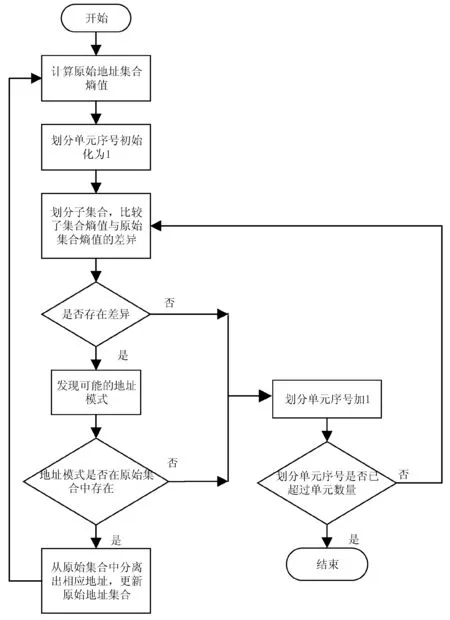
图5 过滤方法流程
详细步骤如下:
(1) 首先计算原始地址集合在各地址单元上的熵值,然后按照左至右的顺序选取划分的地址单元,根据每个地址在该地址单元上的不同取值将原始地址集合划分为若干个子集合。
(2) 每次划分后,对于所有大小不小于min_size的子集合,计算各自在非划分地址单元上的熵值,并依次比较每个子集合与原始集合在非划分地址单元上的熵值差异。对于一个子集合,如果熵值差超过D的非划分地址单元数目不小于(N-1),则可以构建出一个可能的地址模式。构建方法为,在划分单元上取子集合对应的值,在熵值差超过D的非划分地址单元上取子集合中出现频率最高的值。一次划分后,可能有不止一个子集合构建出地址模式。
(3) 如果一次划分后得到至少一个可能的地址模式,则对这些地址模式进行验证,否则进入下一步。验证方法为在原始地址集中查找是否有符合相应模式的地址,如果存在就认为该地址模式有效。如果所有地址模式均无效,则进入下一步;如果至少有一个地址模式有效,则从原始集合中过滤出所有符合有效地址模式的地址,剩下的地址组成新一轮的原始地址,回到步骤1,寻找地址集合中可能存在的其他地址模式。
(4) 判断进行划分的地址单元序号是否为n,如果是则过滤过程结束,否则选择下一个地址单元进行下一轮划分,回到步骤(2)。
3 测试与分析
测试实验采用模拟方法,包含以下3步:
(1) 地址集合生成。通过模拟程序生成测试的地址集合,由于集合中的地址同属一个/64网段,因此只用生成后64位的接口ID部分。集合包含一个或多个随机选择的地址模式,除由地址模式生成的地址外,其他地址均是随机地址。由地址模式生成的地址在地址模式相关地址单元上取值恒定,其他地址单元取值随机,而随机地址的每个地址单元上的取值都是随机的。
(2) 地址模式过滤。用过滤方法从生成的地址集合中过滤出可能具有地址模式的地址。
(3) 过滤结果验证。用生成阶段选择的地址模式对过滤结果进行验证,分别记录过滤结果中与生成时所用模式匹配的地址数Tm,和不匹配的地址数Tu。如果生成的地址集合中根据地址模式生成的地址数为Tg,则评价过滤结果的指标为:漏报数(Tg-Tm)、漏报率(Tg-Tm)/Tg、误报数Tu、误报率Tu/(Tm+Tu)。
测试情形分为3种:单地址模式、多地址模式且各地址模式比例相同、多地址模式且各地址模式比例不同。每次测试时,生成的地址集合中地址总数为10 000,划分的地址单元为半字节,地址模式随机确定。过滤方法的3个临界值分别设为如下值:子集合最小大小min_size为30,熵值差阈值D为0.2,模式中最小地址单元数N为4。
3.1 单地址模式
生成地址集合时,地址模式对应地址在集合中所占比例p为1%~95%,变化梯度为1%。每种比例下各进行3次测试,每次测试随机选择一种地址模式,每个地址模式涉及的地址单元数4~10不等。
测试结果发现,当比例p在4%~89%之间时,过滤方法能成功过滤出所有具有模式的地址,漏报数和误报数均为0;当比例p小于4%或者大于89%时,过滤出地址数量为0,漏报率为100%,这个现象符合图4曲线,因为比例在这个范围内引起的熵值差小于0.2。
将熵值差阈值D降低为0.15,检出的比例范围在4%~92%之间,表示对于随机化程度极高的地址集合而言进一步减少D提升的过滤效果并不显著,因此可以认为0.2是一个比较合适的熵值差阈值,在单地址模式情形下能够从大部分高随机化地址集合中过滤出与地址模式相关的地址。
3.2 多地址模式(比例相同)
在该项测试中,每次测试随机选择的地址模式数量为2~10不等,地址模式的总比例在5%与90%之间随机选取,各个地址模式所占比例相同,测试共进行200轮。
在200轮测试中,有164轮成功过滤出所有具有模式的地址,其余36轮大部分过滤出的地址数量为0,少部分能过滤出一部分地址。在这些出现漏报的轮次中每个地址模式所占比例均小于4%。200轮测试里出现误报的次数仅有3次,且误报数均为1。因此对于比例相同的多地址模式这一情形,过滤方法的效果和单地址模式情形下一致。
3.3 多地址模式(比例不同)
以上两种测试设定的条件都比较理想,实际上多种地址模式所占的比例一般是不同的,因此该项测试在测试2的基础上,将各个地址模式所占比例更改为随机确定,测试共进行200轮。测试结果的漏报率统计如表3所示。
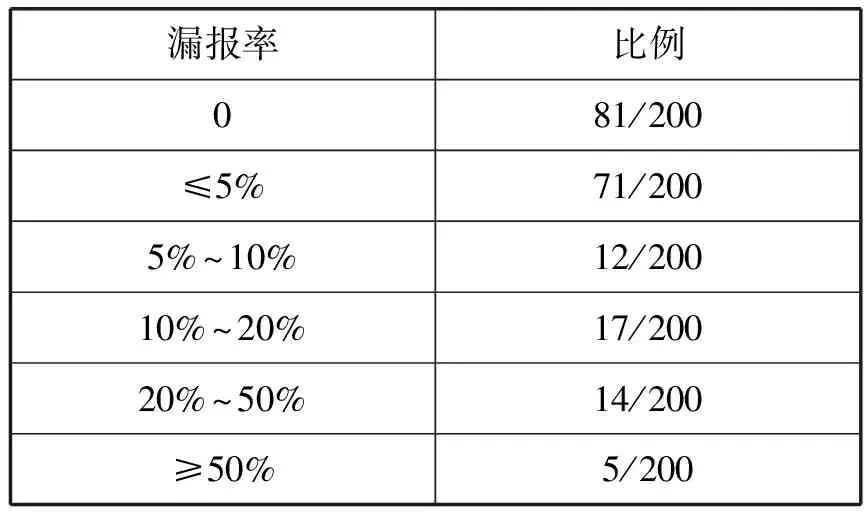
表3 测试结果漏报率统计
在所有出现漏报的测试轮次中,漏报的地址模式在地址集合中所占比例基本上小于4%,比例在4%以上的漏报地址模式仅有3个,它们对应的漏报数量均在2以下。同时,200轮随机测试中,出现误报的测试轮次仅有2次,且误报数均为1。所以可以认为在多地址模式情形下,该过滤方法能够准确过滤出高随机化地址集合中所占比例不低于4%的地址模式。
4 结 语
本文提出一种基于熵的从高随机化IPv6地址集合中过滤地址模式相关地址的方法,该方法通过将地址集合划分为子集合,比较原始集合与子集合的熵值,从而根据熵值差异识别出地址中可能与模式相关的部分以及相应取值,并以此为条件过滤出相关地址,达到降低地址集合随机化程度的目的,方便启发式算法进行具体的地址模式挖掘工作。实验表明,该方法能够从大部分高随机化地址集合中过滤出与模式相关的地址,并且几乎不会挑选出集合中的随机地址,可见该方法具有良好的地址模式过滤能力。
猜你喜欢
销售与市场(营销版)(2021年10期)2021-11-21
铁道通信信号(2020年9期)2020-02-06
销售与市场(营销版)(2019年6期)2019-06-21
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
中小企业管理与科技(2018年11期)2018-11-06
中国医药指南(2017年20期)2017-09-03
中国质量监管(2016年10期)2016-07-10
中国当代医药(2015年8期)2015-03-01
中共党史研究(2013年9期)2013-04-27
