
基于时程深度学习的复杂流场流动特性表征方法*
2022-12-05 11:13战庆亮白春锦葛耀君
物理学报 2022年22期
战庆亮 白春锦 葛耀君
1)(大连海事大学,交通运输工程学院,大连 116026)
2)(同济大学,土木工程防灾国家重点实验室,上海 200092)
流场的特征分析与表征研究对流动机理的明确具有重要意义.然而湍流流场具有复杂的非定常时空演化特征,对其流场数据的低维表征有一定困难.针对此问题,本文提出了基于流场时程数据深度学习方法的湍流低维表征模型,实现了复杂流动数据的降维表征.分别建立了基于一维线性卷积、非线性全连接和非线性卷积的自动编码方法,对非定常时程数据进行降维并得到了低维空间到时域的解码映射关系,实现了特征提取与压缩.通过Re=2.2×104的方柱绕流场进行了研究与验证,结果表明:时程深度学习方法可以有效地实现流场的低维表征,适用于复杂湍流问题;非线性一维卷积自编码器对复杂流场的表征准确性优于全连接和线性卷积方法.本文方法是无监督训练方法,可应用于基于一点的传感器数据处理中,是研究复杂流场特征的新方法.
1 引言
高分辨率的湍流流场信息对于湍流的细观结构研究等问题至关重要,然而受限于传感器尺度等因素,在实验中直接获得高分辨率的湍流数据较为困难.同时,湍流的直接数值模拟依赖于更多的计算网格,完整地保存和分析时-空高分辨率的数据难度大.针对这些问题,本文提出了一种基于时程深度学习的湍流流场数据表征与降维的研究方法.
对复杂流场数据进行降维分析是一种有效的研究方法,其优势在于可以挖掘到流场时程潜在的流动特征与规律.例如本征正交分解方法[1,2]可以依据能量的大小将流场时程分解为多阶模态,且每一阶模态都可以表征流场的部分特征,实现流场的降维分析.动态模态分解法[3,4]在处理多元时序模型时,可以将下一个时刻的某个特征值看作上一个时刻所有特征值的线性组合,把一个高维动态的系统降低至低维以简化计算分析.然而湍流流场具有很强的非线性,此类基于矩阵分解的方法均采用线性变换无法完整地描述湍流的非线性特征,因而难以应用于湍流问题的研究中.随着计算机的发展,深度学习凭借其处理数据的高效性,已经广泛应用于湍流问题的研究中[5].如嵌入流场不变性的高精度湍流模型[6]、流场特征的自动识别[7]、以及基于深度学习的物理控制方程驱动的流场求解[8]等.
另一方面,也有大量的学者对深度学习应用在流场的表征模型进行了研究[9],例如基于卷积神经网络的流场模态分解[10]和基于深度自编码器的流场时域特性研究[11].这些研究都实现了通过低分辨率或者部分流场数据重构出高精度、高分辨率的流场数据,例如下采样多尺度重构模型[12],多通道路径卷积模型[13]等.还有一些学者建立低维模型来表征少量信息点的物理信息与流场瞬态云图之间的映射关系,进而实现稀疏数据点的高分辨率重构[14],例如泰森多边形辅助重构方法[15],浅层神经网络重构方法[16].同时,也有部分学者认为长短期记忆人工神经网络可以更好地预测流场的非定常问题[17,18].然而,这些方法都是通过高分辨率的流场快照作为神经网络模型的输入来实现复杂流场数据的低维表征,训练过程中都需要流场快照作为输入样本[19],进而建立稀疏数据点与整场快照之间的联系.
上述基于瞬态的流场快照数据的分析方法难以直接应用到基于测点的传感器数据处理中,其中文献[20−22]提出了基于时程数据深度学习的方法,对流场特征提取进行研究,对较低雷诺数情况下的测点时程进行了有效的特征提取.在此基础上,本文从时程数据的重构角度出发,提出了基于深度学习的湍流流场低维表征方法.通过一维卷积模型获得时程数据的抽象特征,并通过全连接网络实现特征压缩,得到湍流数据的低维表征模型,可用于直接处理测点的时程数据,而不需要流场快照信息,比传统基于快照的表征方法具有重大优势.
2 流动系统的表征方法
2.1 数据类型
目前主流的基于数据驱动的流动系统表征模型均基于流场的时程数据进行特征提取与建模,采用基于图像处理的深度学习方法对流场快照进行特征的抽象与提取,进而可对包含瞬态整场信息的低维模型进行时变特征分析,得到其时间的演化规律.而本文采用了基于时程数据的特征提取方法(见图1 所示),即面向不同测点位置处的时程样本集,获取时程特征随空间位置的分布情况,进而得到表征整个流场域的数据驱动表征模型.
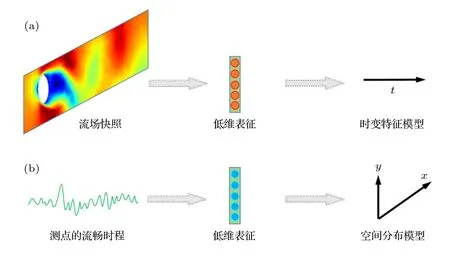
图1 数据示意图Fig.1.Data type for modeling.
流体计算区域如图2 所示,流向长度Lx=40D,横向长度Ly=20D,其中D为方柱边长.上游来流区域长度10D,下游区域长度30D.x-y平面内共计约11000 个网格,底层网格高度约为8×10–4.将平面网格展向拉伸30层,每层高度0.1,展向长度Lz=3D.入口边界条件为速度入口,出口边界条件为压力出口,横向两界面设置为对称边界.来流速度U∞=0.33 m/s,Re=2.2×104,在远离方柱的流场区域采用较稀疏的网格,而近尾流区采用较密的网格保证模拟结果的可靠性,并可捕捉到较大尺度的尾流结构特征,反映测点的流场时变特征.

图2 整体计算域及平面网格划分(a)整体计算域;(b)局部网格Fig.2.Global computational domain and plane grid settings:(a)Global computing domain;(b)local mesh.
使用数值模拟获得流场中各测点的时程作为样本数据集,流场的数值模拟采用自主开发的三维非结构网格的流体计算程序zFlower 实现[23],采用三维非结构化网格对空间进行离散,使用有限体积方法离散不可压缩流动控制方程,保证空间与时间的离散具有二阶精度.所得到的方柱升力、阻力系数时程和瞬态流场图如图3 所示.

图3 数值模拟结果(a)升力与阻力系数;(b)z=0 切面瞬时速度矢量图;(c)y=0 切面瞬时速度矢量图;(d)x=2 切面瞬时速度矢量图Fig.3.Partial results of simulation:(a)Lift and drag coefficient;(b)sectional instantaneous velocity vector diagram at z=0;(c)sectional instantaneous velocity vector diagram at y=0;(d)sectional instantaneous velocity vector diagram at x=2.
在流体模拟计算过程中进行了同步的流场数据采集,嵌入时程提取模块将计算中各时间步的流场压力与速度值分类保存,形成了各测点的压力时程与速度时程集参数.由于方柱尾部的时程更加丰富,在展向一层范围内选取7000 个测点随机分布在流向距离棱柱–2D—+8D范围内、横向–3D—+3D范围内,分布如图4(a)所示.
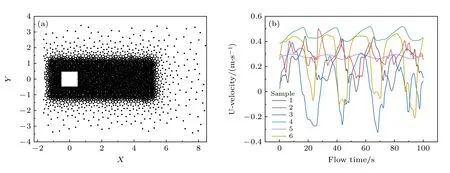
图4 测点分布及时程结果(a)测点布置位置;(b)部分测点的流向速度结果Fig.4.Distributions of monitoring points and time history results:(a)Layout position of measure points;(b)flow velocity of some measure points.
为直观地展示待训练样本的数据特征,在压力样本集中随机选取了6 条待训练的物理量时程进行展示,如图4(b)所示.由于测点位置不同,因而同一样本集中的时程信号特征各异,这种具有复杂特征的流场时程数据特征的提取与识别难以通过传统方法实现.
2.2 模型原理
采用的流动表征模型原理如图5 所示.对于复杂非线性动力系统,其样本u(t)在空间的分布无规律可循且难以识别其特征.采用编码器获得从物理空间到“编码空间”的变换关系,使得在新的编码空间中,所有流场数据都可以通过相同的变化从编码空间重构到物理坐标空间.这里的坐标变换和数据重构是通过时程数据的深度学习方法获得的,分别对应与自动编码的编码器和解码器.

图5 表征模型的原理Fig.5.Methodology of the representation model.
基于深度学习的表征模型中,核心是对复杂系统的样本数据进行准确地降维表征与还原.本文面向的是一维流场时程数据,采用三种不同的方法实现特征的提取与低维表征,分别是全连接模型(multilayer perceptron autoencoder,MLP-AE)、线性卷积(linear convolutional neural autoencoder,LCN-AE)和非线性卷积(nonlinear convolutional neural autoencoder,NCN-AE)模型.不同模型对数据进行特征提取的运算方式不同,通常输入与输出的变换关系可表示为
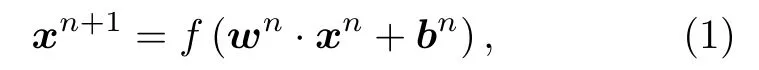
其中xn为模型中第n层的时程输出;wn与bn为第n层变换权重矩阵和偏移矩阵.具体地,对于全连接模型,其变换权重矩阵的特点是与上一层的所有神经元都是相连的,而对于一维卷积模型,其变换权重矩阵是一个稀疏矩阵,单个节点仅同与其相邻的上层神经元的联系的权重为非零值.特征解码器的模型结构与编码器相同、顺序相反,具体参数见表1和表2.需要指出的是,LCN-AE 模型与NCN-AE 模型的网络参数相同,但各层未使用激活函数与偏移矩阵bn.
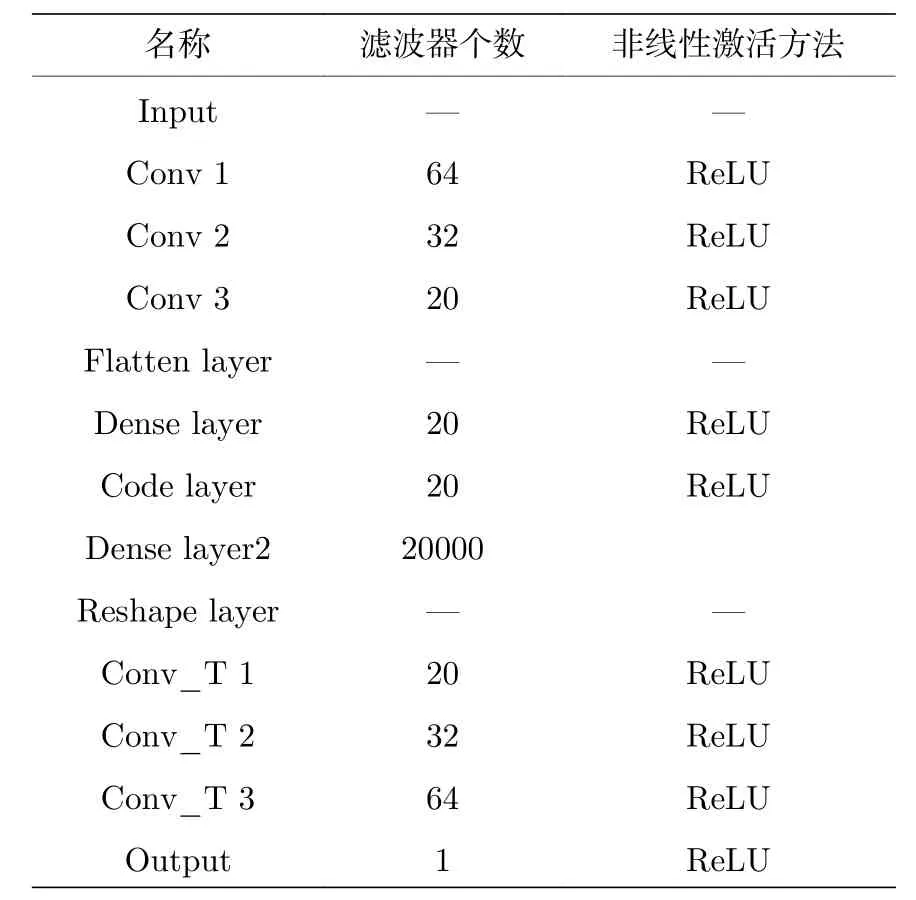
表1 非线性卷积自动编码模型参数Table 1.NCN-AE model parameters.
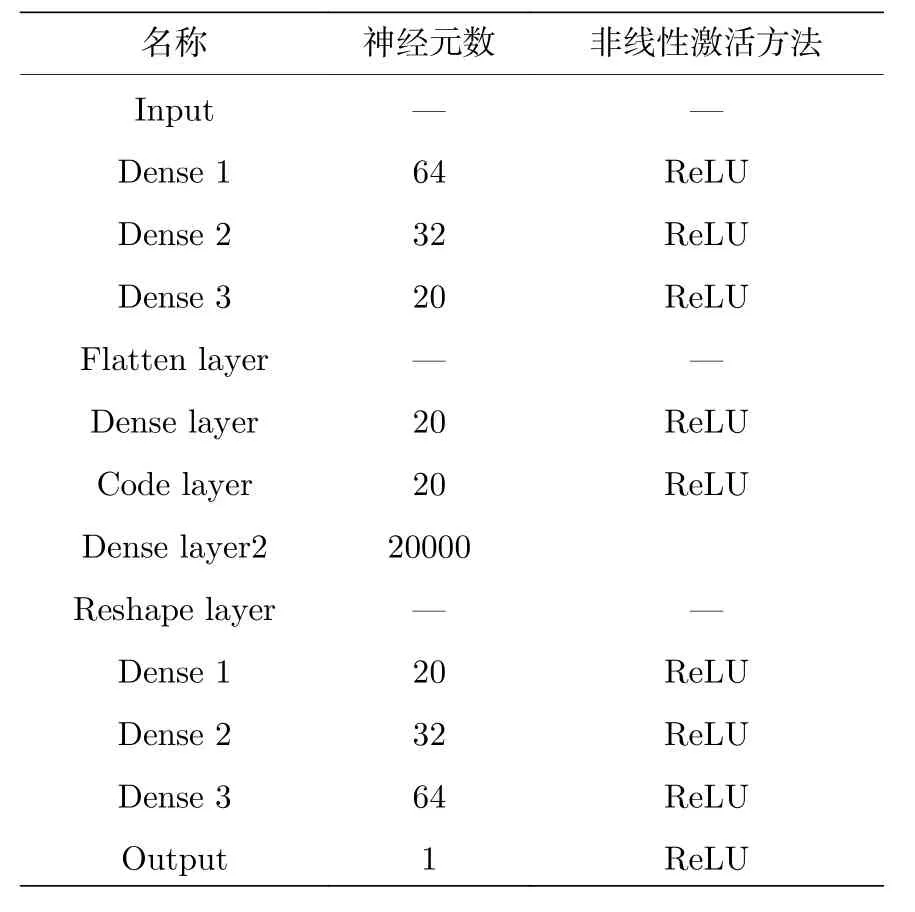
表2 全连接自动编码模型参数Table 2.MLP-AE model parameters.
3 结果与分析
以Re=2.2×104的方柱湍流流场时程数据为研究对象,建立输入时程的自编码降维模型,得到了物理空间坐标的编码,进而通过编码与解码器实现湍流场时程的重构.
3.1 模型损失函数结果
在训练模型时,以均方误差函数(MSE)为损失函数,该函数对模型预测值与样本真实值的误差求平方并取平均值.误差值越小,说明预测模型描述实验数据具有更好的精确度.训练时采用学习率为0.001的Adam 优化器;设置批处理大小为16,训练次数为3000,同时当50 步之内误差不下降时自动停止训练.经过迭代训练,得到了3 种深度模型在训练过程中的计算残差曲线,如图6 所示.
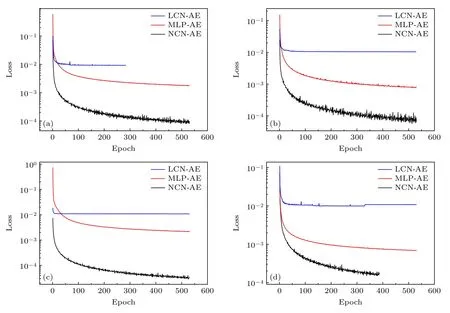
图6 训练集的模型损失值(a)流向速度;(b)横向速度;(c)展向速度;(d)速度绝对值Fig.6.Loss function of different models on training set:(a)Flow velocity;(b)lateral velocity;(c)spanwise velocity;(d)absolute value of velocity.
四组不同流场参数的结果均表明,非线性卷积模型的损失值最小,非线性多层感知网络次之,而线性卷积模型的损失值最大.说明相同模型层数和结构情况下非线性卷积模型精度最高,同时说明对于复杂的湍流流场,使用非线性激活函数是有必要的,深度学习模型的流场表征精度要远高于线性理论的结果.
3.2 模型的误差分析与时程重构
为了直观地展示不同方法的降维准确度,同时找出流场中模型降维准确度较低的局部区域,提出了一种无量纲化的误差计算方法.误差计算公式如下:

其中yi为原始样本曲线;为重构样本曲线;Ai为样本时程曲线的最大值与最小值相差的绝对值.由于流场中的时程曲线特征各异,该残差可以评价不同流动特征的样本时程,更适合本文方法的验证.
将样本的物理坐标与该误差相结合,并使用不同的颜色对误差范围进行划分:绿色表示无量纲后的误差值小于1%,用蓝色表示误差为1%—5%之间,黄色表示误差为5%—15%之间,橘黄色表示误差为15%—30%之间,红色表示误差为30%—100%之间,得到误差可视化结果如下.
由图7—图9 可知,本文方法对四种物理量均实现了较高精度的表征.本文所研究的高雷诺数方柱绕流中包含了层流流动(远场和上游)、湍流尾流和不稳定的流动分离区,验证了本文深度学习方法对复杂流动过程的适用性.
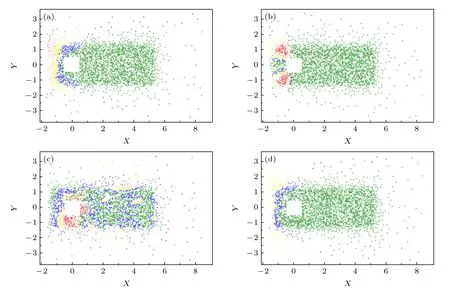
图7 线性卷积模型的误差分布(a)流向速度;(b)横向速度;(c)展向速度;(d)速度绝对值Fig.7.Distributions of relatively error using LCN-AE:(a)Flow velocity;(b)lateral velocity;(c)spanwise velocity;(d)absolute value of velocity.
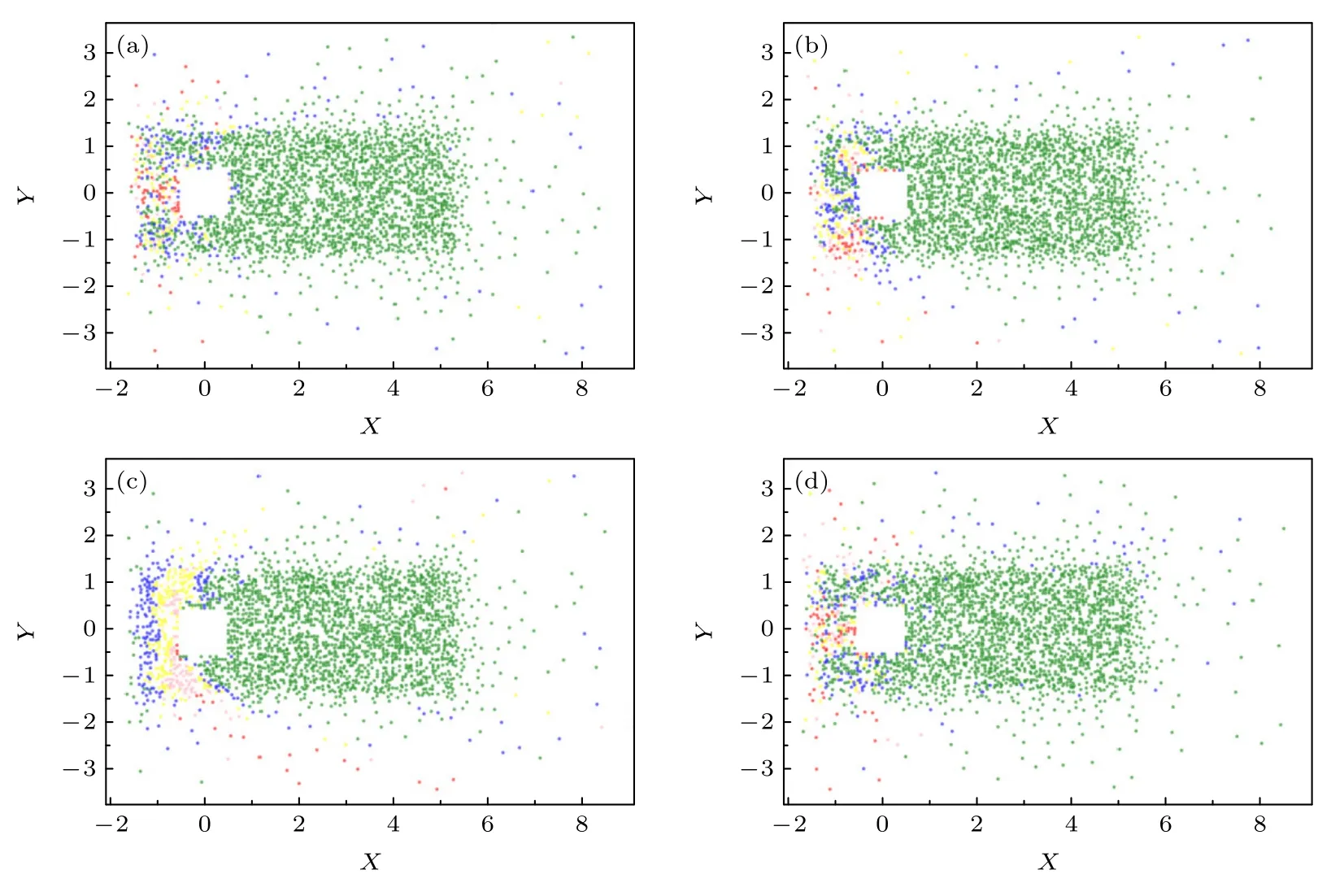
图8 全连接模型的误差分布(a)流向速度;(b)横向速度;(c)展向速度;(d)速度绝对值Fig.8.Distribution of relatively error using MLP-AE:(a)Flow velocity;(b)lateral velocity;(c)spanwise velocity;(d)absolute value of velocity.
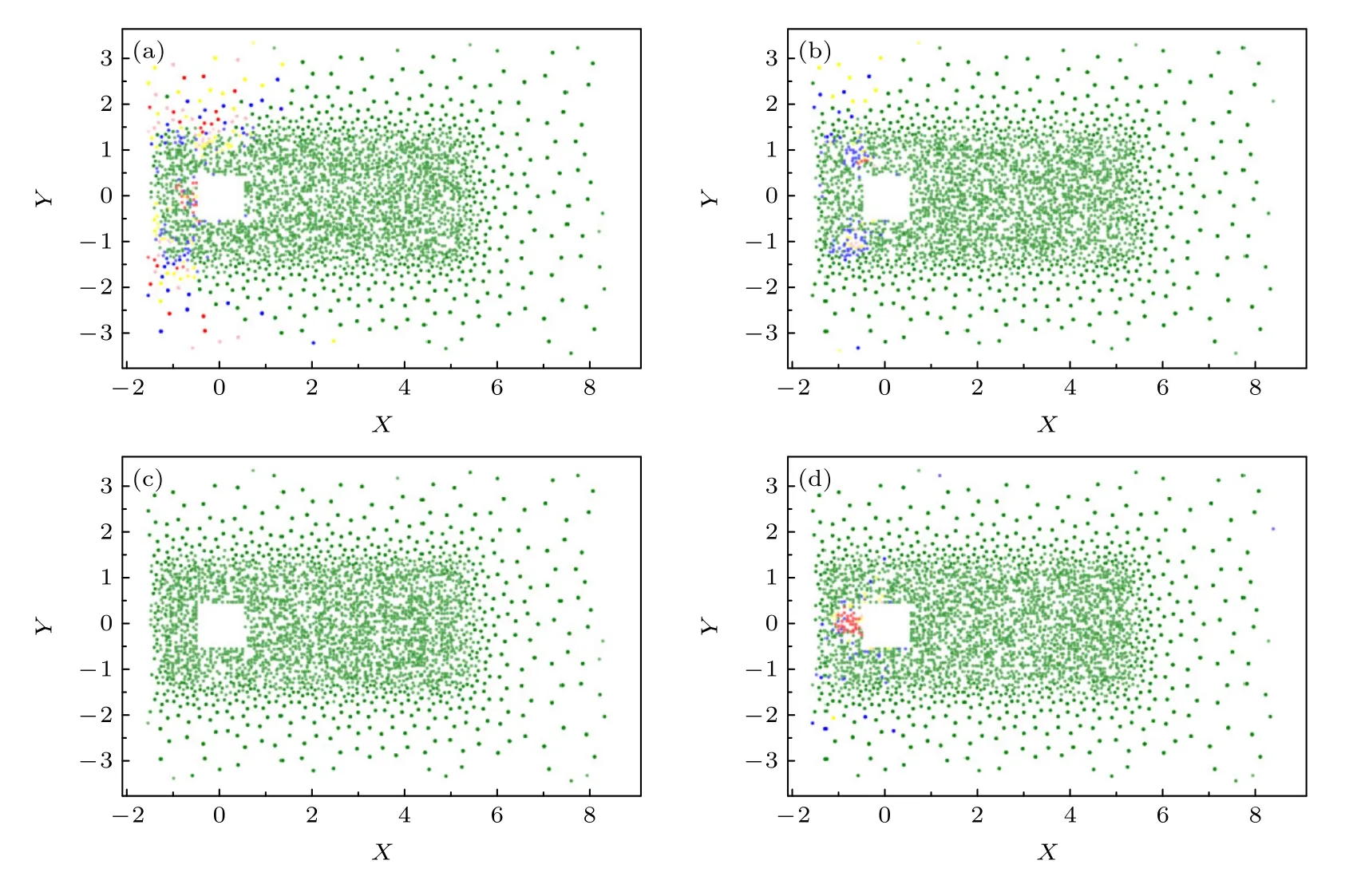
图9 非线性卷积模型的误差分布(a)流向速度;(b)横向速度;(c)展向速度;(d)速度绝对值Fig.9.Distributions of relatively error using NCN-AE:(a)Flow velocity;(b)lateral velocity;(c)spanwise velocity;(d)absolute value of velocity.
通过三种模型的误差分布图可以发现,误差较高的区域大多分布在流场的来流方向.这是因为在上游区域中流体几乎不受柱体扰动,从而使得该区域内测点的时程曲线振幅很小近似为直线,进而导致上游区域的相对误差较大.同时,比较三种特征提取方法可以发现,线性卷积模型的还原精度不如其余两种方法,这也说明了对于复杂的湍流流动,采用非线性变换实现数据降维是有必要的.全连接方法略优于线性卷积而差于非线性卷积方法,说明卷积层可以逐层提取输入数据中所蕴含的特征,对复杂流场时程特征提取具有更高的准确性及训练的有效性.这与文献[22]关于特征提取运算的结论是一致的,各模型对不同流场变量计算的相对误差平均值见表3 与图10.
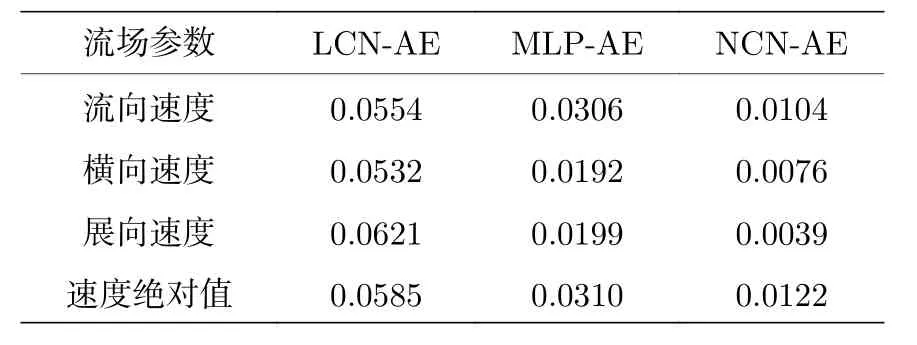
表3 不同模型的误差散点图均值Table 3.Mean relatively error of different models.
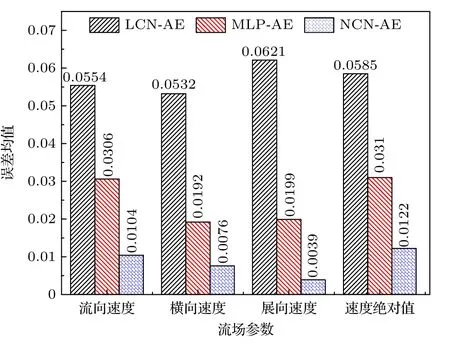
图10 不同模型的误差散点图均值Fig.10.Mean relatively error of different models.
对表征模型精度最好的非线性卷积模型,在各物理参数测点中随机选择6 条时程,与模型的重构结果进行比较,如图11 所示.
由图11 可以看出,湍流场中的时程曲线无法找到共同的流动特征,但非线性卷积模型建立的表征模型依然可以准确地还原复杂湍流的流场时程信息,说明该表征模型提取的低维特征是有效的,可以将复杂的湍流时程压缩为低维的编码表征,并通过解码器进行时程的还原.
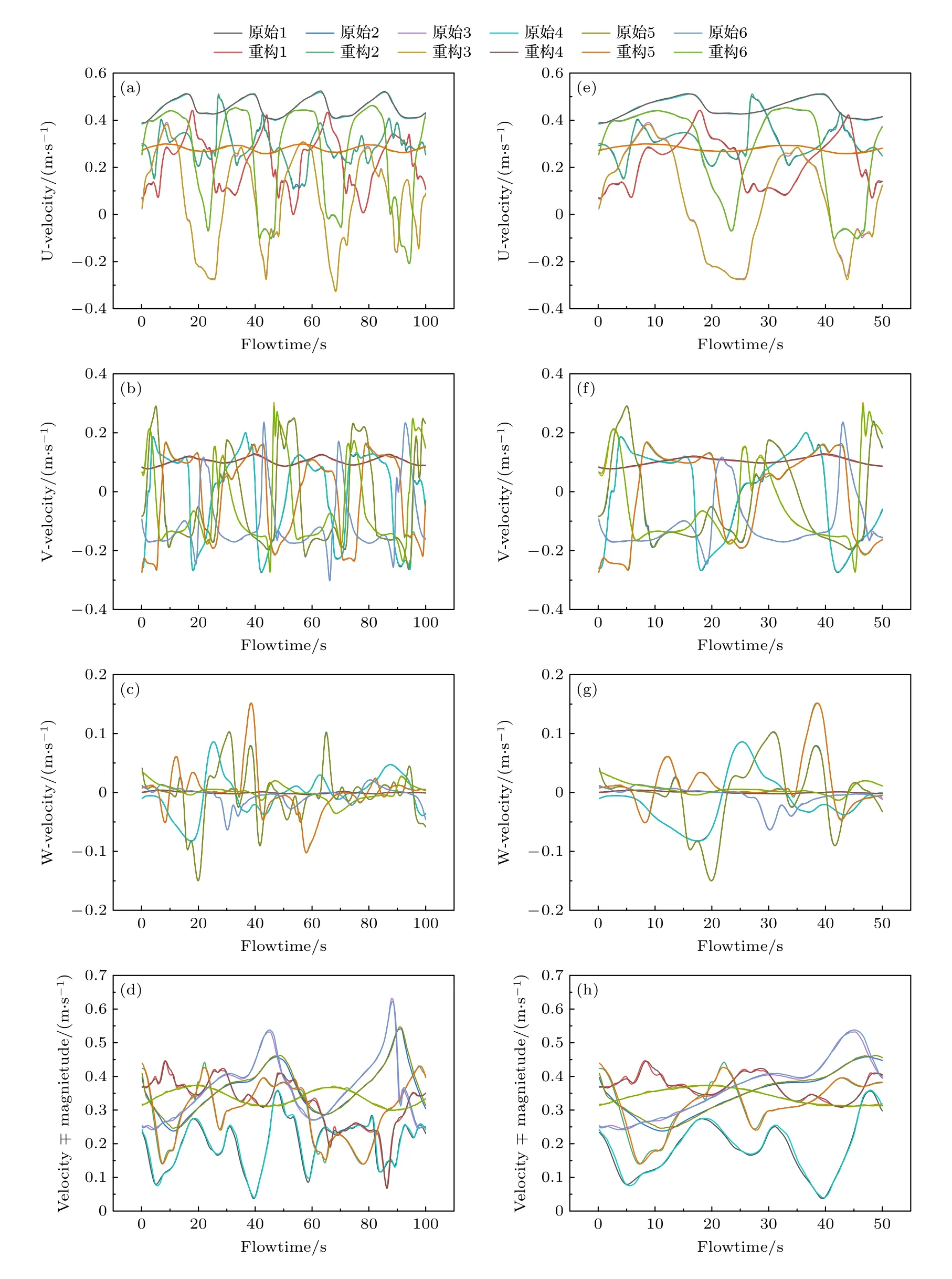
图11 原始时程与重构时程的比较(a)流向速度;(b)横向速度;(c)展向速度;(d)速度绝对值;(e)流向速度的局部视图;(f)横向速度的局部视图;(g)展向速度的局部视图;(h)速度绝对值的局部视图Fig.11.Comparision of original and reconstructed flow time history samples:(a)Flow velocity;(b)lateral velocity;(c)spanwise velocity;(d)absolute value of velocity;(e)partial view of flow velocity;(f)partial view of lateral velocity;(g)partial view of spanwise velocity;(h)partial view of absolute value of velocity.
4 结论
本文采用了时程深度学习方法建立了高雷诺数湍流场的低维表征模型,分别采用了三种不同的时程特征提取方法实现数据降维,对四种流动数据进行了分析,结果表明,1)基于非线性卷积的深度学习模型对流场特征的识别精度高并且优于其他两种模型,可以准确的提取到流场不同区域的流动特征;2)基于线性卷积的深度学习模型对流场特征识别精度不如其他两种模型,说明在复杂时程的数据降维中非线性变换是一种非常有效的方法;3)基于全连接方法的深度学习模型精度不如非线性卷积模型,难以准确提取流场时程的特征.本文通过深度学习方法对流场时程数据进行了特征提取与时程重构,证明了该方法适用于湍流场,可以有效的对流场进行低维表征,是流场特征研究的新方法.
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
舰船电子工程(2021年4期)2021-05-25
空气动力学学报(2020年1期)2020-11-29
地震研究(2020年1期)2020-05-01
地震研究(2019年4期)2019-12-19
北京航空航天大学学报(2017年8期)2017-12-20
汽车实用技术(2015年8期)2015-12-26
专用汽车(2015年8期)2015-03-01
国外科技新书评介(2014年12期)2015-01-05
国外科技新书评介(2014年5期)2014-12-17
