
面向语义片段结构化自注意力的目标情感分析
2022-12-06 10:08赵容梅琚生根
小型微型计算机系统 2022年12期
邓 航,陈 渝,赵容梅,琚生根
1(四川大学 计算机学院,成都 610000)
2(四川民族学院 理工学院,四川 康定 626000)
1 引 言
目标情感分析(Targeted Sentiment Analysis,TSA)是方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)的子任务,其主要任务是判断在句子中出现的特定目标的情感极性(积极、中性和消极),其中目标可以是一个词语或者一个词组.如图1所示,“Comfortable bed but the ornament is really ugly.” 就目标“bed”而言,情感极性是积极的;而对于目标“ornament”而言,情感极性却是消极的.目标情感分析的研究方法主要包括传统的机器学习方法和基于神经网络的深度学习方法.

图1 目标情感分析例子
传统的机器学习方法将情感分析问题看作为一个文本分类问题,通过构造特征工程来分析文本情感(Jiang等人[1];Kiritchenko等人[2];Ding等人[3]).这些方法通过人工可以获得丰富的情感特征,在特定领域的数据集上获得了比较好的分类效果,但构建特征工程会花费比较高的人力成本和时间成本.
随着深度学习技术的发展,机器学习方法已逐步被基于神经网络的深度学习方法超越和取代.其中,循环神经网络RNN(Recurrent Neural Network)被广泛用于从目标和上下文中自动学习语义特征,提取嵌入层的隐状态.(Dong等人[4];Tang等人[5];Chen等人[6];Lin等人[7]).尽管RNN模型大多数情况下效果都较好,但它们很难进行并行化计算,此外,RNN模型基本上每个训练算法都是随时间增加的截断的反向传播,这会影响到模型在较长时间尺度上捕获依赖关系的能力[8].目标情感分析的最新进展得益于注意力机制,注意力机制能成功捕捉特定目标与句子中每一个词的相关性(Wang等人[9];Yang等人[10];Ma等人[11];Song等人[12]).但由于注意力机制注重词与词之间的关系,容易造成目标与上下文中其他词语的错误搭配,影响最终的精确度,如图2所示,对于目标“ornament”而言,词语“good”、“comfortable”、“ugly”的权重是一样的,并不能确定哪个词对目标的情感分析影响力更大.

图2 现有模型的注意力权重分配
由此,本文提出一种融合注意力编码和结构化自注意力的目标情感分析方法来解决上述问题.首先通过注意力编码网络作为编码器来提取句子、上下文和目标三者的隐状态,通过多头注意力机制获得目标与上下文的融合语义特征,并通过结构化自注意力机制来提取句子语义片段的特征,最后融合各个语义特征,以实现目标情感分析.
本文的主要贡献如下:
1)使用注意力编码网络作为编码器提取嵌入层的隐藏状态,解决了RNN模型作为编码器存在的问题.
2)融入结构化自注意力,该结构可以将句子表示为多个语义片段,注重目标词与语义片段的关系,解决了注意力机制注重词与词之间关系的问题,减少了与目标情感分析无关的噪声.
2 相关工作
目标情感分析是当前自然语言处理领域中的研究热点之一,它是方面级情感分析的子任务,其主要任务是判断在句子中出现的特定目标的情感极性.早期工作主要通过基于特征工程的机器学习或构建情感词典的方法来进行情感分类.Jiang等人[1]通过基于句子的语法结构来创建多个与目标相关的特征来识别情感极性.Kiritchenko等人[2]使用支持向量机方法,结合n-gram和字典等特征,在SemEval 2014数据集中实现了较好的性能.然而传统的机器学习方法识别情感极性严重依赖于所构建的特征工程的质量,不能充分捕捉文本的情感信息,并且需要通过人工对文本进行预处理和特征提取,工作量十分庞大.
近年来,传统机器学习方法已逐步被深度神经网络的方法超越和取代.Dong等人[4]首次将自适应循环神经网络用于目标情感分析,通过语法分析来获取句子和方面词的特征.但该方法强烈依赖于句法关系、依存树等外部知识,网络结构过于复杂.Tang等人[5]提出TD-LSTM来扩展LSTM模型,使用两个单向的LSTM模型分别对目标词的左半部分上下文、右半部分上下文进行建模,并叠加两部分的编码信息,以获得整个句子的语义特征.Wang等人[9]提出了一种TAE-LSTM,它将目标嵌入与单词表示连接起来,并让目标参与计算注意力权重.Chen等人[6]提出RAM,该RAM在双向LSTM构建的记忆上采用多重注意力机制,并将注意力结果与门控循环单元(GRU)非线性结合.Ma等人[11]提出IAN模型,它通过两个注意力交互网络学习目标和上下文的语义信息.以上大部分研究都依赖于循环神经网络(RNN)作为序列编码器来计算文本的隐藏语义.然而,RNN模型很难进行并行化计算,且由于RNN模型在较长时间尺度上捕获依赖关系的能力较低,这种基于RNN的方法会忽略远处的单词对目标情感的影响.为此,Song等人[12]利用多头注意力机制和点卷积变换提出了注意力编码网络来代替循环神经网络作为编码器,解决了上述循环神经网络存在的问题.但注意力机制关注的是词与词之间的关系,而不是目标与语义片段之间的关系,难免会将更大的注意力权重分配给不相关的单词.为此,Zhang等人[13]提出模型分析(如注意力机制)的基本单位应该是语义片段而非单词,提出了针对对象的语义片段注意力机制,来提升目标情感分析的效果.
3 本文方法
给定句子的序列S={w1,w2,…,wt-1,wt,…,wt+m,wt+m+1,…,wn},目标的序列为T={wt,…,wt+m},上下文的序列为C={w1,w2,…,wt-1,wt+m+1,…,wn}.本文的任务是给定特定的目标T,根据其上下文C和句子S来判定目标T的情感极性p,其中p∈Q,Q={-1,0,1},分别代表消极情绪、中性情绪和积极情绪.
图3展示出了本文模型的整体架构,它主要由嵌入层、注意力编码层、注意力交互层和输出层组成.

图3 模型整体框架图
3.1 嵌入层(Embedding Layer)

3.2 注意力编码层(Attentional Encoder Layer)
在目标情感分析领域,大多数研究都使用循环神经网络(RNN)模型对文本进行建模,以获得输入文本的隐藏状态.受Song等人[12]的启发,本文采用其提出的注意力编码网络用于提取文本的隐藏特征,注意力编码网络包括两个子模块:多头注意力(Multi-Head Attention,MHA)和逐点卷积变换(Point-wise Convolution Transformation,PCT).注意力编码网络是RNN作为编码层的一种可并行化计算的替代方案,可应用于计算嵌入层输入的隐藏状态.
3.2.1 多头注意力(Multi-Head Attention,MHA)
注意力机制在机器翻译任务中得到了广泛的应用,其定义如式(1)所示.
(1)

多头注意力机制是利用多个查询,来并行化执行多个注意力函数,最早由Vaswani等人[15]提出,如图4所示.多头注意力机制是指对Query,Key,Value进行不同的线性变换,每次线性变换使用的是不同的参数矩阵W,然后计算Query和Key之间的相似性,这是一个重复多次的过程,最后将结果拼接起来.多头注意力机制的计算公式如式(2)、式(3)所示.
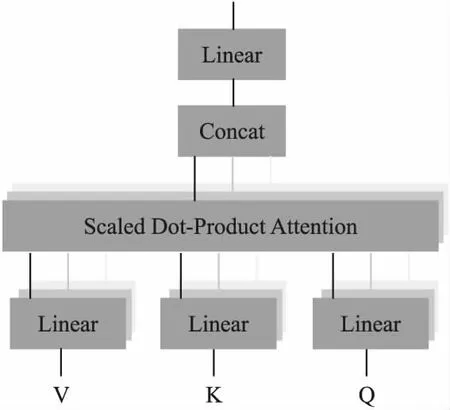
图4 多头注意力机制的结构图
headi=attention(QWq,KWk,VWv)
(2)
MHA(Q,K,V)=concat(head1,…,headh)
(3)
其中,W是权重参数矩阵,Wq∈dh×dq,Wk∈dh×dk,Wv∈dh×dv,h表示的是多头数量.
Intra-MHA:是一种多头的自注意力机制.自注意力机制是一种特殊的注意力机制,自注意力机制是对序列本身的注意力处理,即Query=Key.在得到嵌入层输出的句子词向量es、上下文词向量ec的基础上,通过多头自注意力机制,可分别得到句子和上下文的语义特征表示.计算过程如式(4)和式(5)所示.
(4)
(5)

Inter-MHA:是一种通用的多头注意力机制,与Intra-MHA不同,Inter-MHA的Query并不等于Key.在此模块中,Query是上下文词向量ec,而Key是目标词向量et.上下文和目标的融合语义特征可以通过公式(6)计算获得.
(6)

3.2.2 逐点卷积变换(PCT)
序列神经网络模型(例如RNN)下一时刻的输出依赖于前一时刻的输出,全局信息可以被逐步捕获.注意力机制虽然可以捕获全局文本信息,并直接成对比较文本序列,然而注意力机制没有考虑文本的顺序关系.逐点卷积变换(Point-wise Convolution Transformation,PCT)可以转换多头注意力机制收集的上下文信息.逐点意味着卷积核大小为1,并且对输入的每个特征都做同样的转换.给定输入序列h,PCT的公式如式(7)所示.
(7)

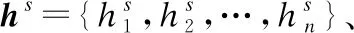
hs=PCT(cs)
(8)
hc=PCT(cc)
(9)
ht=PCT(ct)
(10)
3.3 注意力交互层(Interactive Attention Layer)
在编码层中分别得到了句子隐状态hs、上下文隐状态hc和目标词隐状态ht.注意力交互层包含两个子模块,一个是上文提到的多头注意力(MHA),其作用是获得目标特定的上下文语义特征.另一个是结构化自注意力(Structured Self-Attention,SS),结构化自注意力的目标是提取句子中与目标相关的不同语义片段.

(11)
结构化自注意力(SS):Lin等人[16]提出了一种结构化的自注意力机制,可以将一个句子表示为多个语义段,将注意力机制的权重放在语义片段上而非词语上,减少引入对目标词情感无关的噪声.因此,本文通过引入结构化自注意力机制来捕获句子中的语义特征片段,作为判断目标情感极性的基础.SS的公式如式(12)、式(13)所示.
(12)
SS(h)=As(h)·h
(13)

(14)
3.4 输出层(Output Layer)

(15)
x=(Wo)T·so+bo
(16)
(17)
其中Wo∈1×C是权重参数,bo∈C是偏置项,C是情绪极性的类别数,y∈C是预测情感极性的分布.
该模型优化函数是L2正则化分类交叉熵损失函数,定义如式(18)所示,并采用反向传播算法更新模型的参数和权重.
(18)
4 实 验
4.1 数据集和实验设置
本文提出的模型基于3个通用基准数据集进行评估:SemEval 2014 Task4[17]中的餐厅(14Rest)和笔记本(14Lap)评论数据集、SemEval 2015 Task12[18]中的餐厅(15Rest)评论数据集.数据集中的每条数据由句子、目标词和目标词的情感极性构成,情感极性分为消极、中性和积极,关于3个数据集的详细统计信息如表1所示.
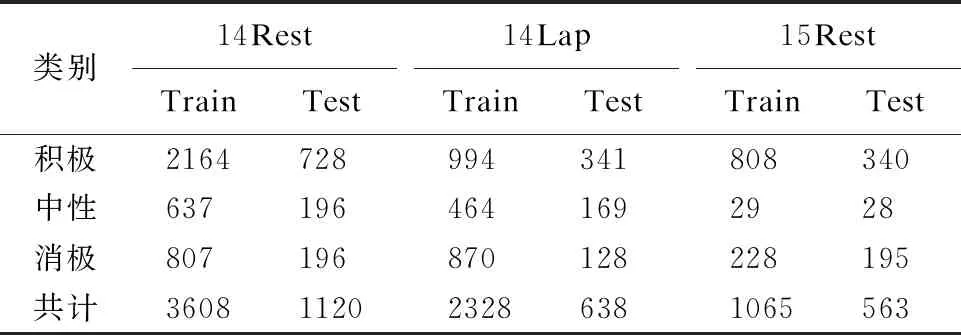
表1 实验数据集统计信息
本文采用pytorch深度学习框架进行实验,编程语言是Python 3.6,操作系统是Ubuntu,用于训练模型的GPU是GeForce RTX3090.本文利用预训练模型BERT[14]来获得句子、上下文和目标词的嵌入词向量,嵌入向量维度设置为ddim=768.隐状态dhid的维度设置为300,学习率设置为2×10-5,batch-size设置为16,dropout率设置为0.3,并使用Adam[19]作为模型的优化器来更新模型的参数.
4.2 模型对比实验
4.2.1 实验对比模型介绍
为了评估本文提出的模型在这3个数据集上的分类效果,本文采用准确率(accuracy)和宏平均F1值(macro-F1)作为情感预测的评测指标.为了进一步说明该模型的优越性,本文将模型与几种典型的Baseline模型和近几年的主流模型进行了比较.下面将详细描述所有比较模型.
Feature-based SVM[2]:将情感分析视为一个文本分类问题,提出了基于人工特征的支持向量机方法.
ATAE-LSTM[20]:是一种基于LSTM的模型,直接对句子进行编码,获取句子特征进行情感分类.
MemNet[21]:引入了一个深度记忆网络来实现注意力机制,以学习上下文单词与方面的相关性.
IAN[11]:利用两种基于LSTM的注意力模型以交互方式学习上下文和方面特征表示.
TNet-LF[22]:实现了一种上下文保护机制,提出了一个特征变换组件来将实体信息引入到单词的语义表示当中.
TNet-ATT[23]:是TNet-LF的一个扩展,它提供了一种注意力监督挖掘机制来改进先前的模型.
ASCNN、ASGCN[24]:使用卷积神经网络和图卷积网络来捕获长期依赖关系和语法信息.
MCRF-SA[25]:提出了一个简洁有效的基于多重CRF的结构化注意力模型,该模型能够提取特定方面的观点跨度,并根据提取的意见特征和上下文信息对目标的情感极性进行分类.
TG-SAN[13]:提出模型分析(如注意力机制)的基本单位应该是语义群(片段)而非单词,并基于这个想法构建了针对对象的语义群注意力机制.
BERT-SPC[12]:在目标情感分析中使用了基本的预训练模型BERT.
AEN-BERT[12]:提出了一种注意力编码网络来解决RNN不能并行处理的问题,并使用标签平滑规则技术来解决标签不可靠的问题.
BERT-WD[26]:该论文采用记忆网络的形式将句子的依存句法信息加入到情感分析中,使得模型能够学习依存句法中有用的信息.
4.2.2 实验对比分析
表2显示了本文模型与其它基线模型的总体性能比较,在14 Rest、14Lap和15Rest数据集上,本文模型所得到的准确率(Accuracy)分别为84.91%,80.88%,84.37%,宏平均F1值(Macro-F1)分别为78.02%,77.04%,67.60%,该模型的准确率在14Lap和15Rest数据集上取得了最好的结果,Macro-F1值在14Rest和14Lap数据集上取得了最好的结果.一方面原因是本模型通过注意力编码网络代替常规的RNN模型对句子、上下文和目标词三者的语义特征进行编码.另一方面原因是本模型并引入了结构化自注意力机制,将注意力机制的权重集中在语义片段上,充分挖掘出了与目标词相关的情感特征.对比实验的结果证实了本文提出的模型的有效性,可以总结为如下几点:

表2 模型总体性能对比表(%)
1)本文采用注意力编码网络作为编码层,比采用RNN模型作为编码层的方法性能较好.表2中ATAE-LSTM、IAN和ASGCN模型都是基于RNN的模型,其中ASGCN模型用LSTM模型捕获有关单词顺序的上下文信息,并在LSTM输出的顶部实现了多层图卷积结构.但RNN模型编码器获取嵌入词向量的隐状态必须同时保持在内存中,所以此类基于RNN的模型在内存优化上存在着困难.在14 Rest、14Lap、15Rest数据集上,本文模型比ASGCN模型的准确率分别提高了4.05%,6.74%和5.03%,宏平均F1值分别提高了5.83%,7.8%和6.82%.因此,本文采用的注意力编码网络适合于获取词向量的隐状态.
2)本文采用了结构化自注意力机制,将注意力机制的权重集中在语义片段上,相比于采用普通注意力机制的方法性能较好.采用注意力机制的模型中,TNet-LF和TNet-ATT模型的表现是比较好的,这是因为它们努力减少了使用单层注意力机制产生的噪声,这表明了减少注意力机制产生的无关噪声有助于情感分类.如表2中所示,本文提出的模型性能均高于TNet模型,这说明了结构化自注意力能较好地减少与目标词无关的情感噪声.
3)在14Rest上的准确率指标和15Rest上的宏平均F1值指标上,本文提出的模型略低于BERT-WD模型,这是因为BERT-WD模型引入了外部依赖解析信息,将句子的依存句法信息加入到了情感分析中来.但本文的模型在其他四个指标上都高于BERT-WD模型,说明本文模型依然有较高的竞争力.
4)与提出注意力编码网络的AEN-BERT模型相比,该模型的准确率和Macro-F1值也有显著的提高,在14Rest、14Lap的数据集上,准确率分别提高了1.79%,0.95%,Macro-F1值分别提高了4.26%,0.73%.与提出模型分析(如注意力机制)的基本单位应该是语义片段的模型TG-SAN相比,在14Rest、14Lap的数据集上,准确率分别提高了3.25%,5.61%,Macro-F1值分别提高了5.43%,5.86%.
综上所述,对比实验的实验结果证实了本文模型的有效性.
4.3 消融实验
为了揭示本文模型中组成成分的有效性,本文设计了一个消融模型:w/o SS(Structured Self-Attention).该消融模型去除了本文模型中对句子隐状态编码的结构化自注意力机制,以此模型来验证结构化自注意力机制的有效性.表3中的Ablations栏报告了消融模型的结果.

表3 模型消融实验对比表(%)
消融模型在3个数据集上的准确率分别为(84.82%,78.37%,82.13%),Macro-F1值分别为(77.15%,73.55%,55.74%),都低于本文模型的准确率和Macro-F1值,准确率分别降低了0.09%,2.51%和2.24%,Macro-F1值分别降低了0.87%、3.49%和11.86%.w/o SS消融模型表明了本文使用的结构化自注意力机制能有效降低与目标情感无关的噪声,能有效增强模型的性能,提高目标情感分析的效果.
4.4 实验过程分析
本文模型在14Rest、14Lap和15Rest 3个数据集上的训练过程如图5、图6所示,图5是模型在验证集上的准确率曲线图,图6是模型在验证集上的Macro-F1值曲线图.
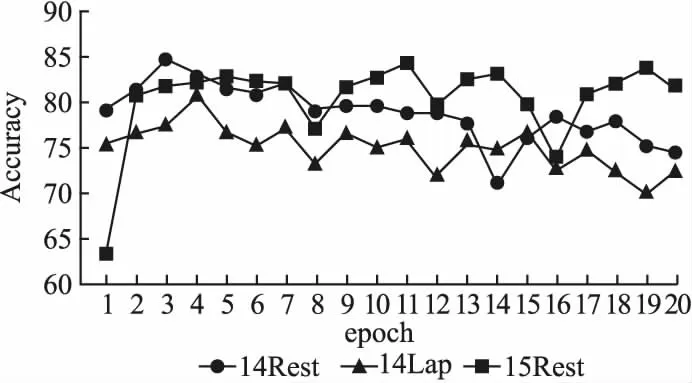
图5 验证集上的准确率曲线图

图6 验证集上的Macro-F1值曲线图
从图5和图6中可以看出,模型训练前期的准确率值和Macro-F1值提升较快,然后不断地波动寻找局部最优值.
4.5 多头注意力head个数选择实验
多头注意力机制(MHA)中包含了多个head的注意力权重,为了研究不同head数对多头注意力机制的影响,本文分别在14Rest、14Lap和15Rest 3个数据集上测试了本文模型在参数head={2,3,4,5,6,7,8,9,10}时的性能,评价指标为准确率.实验结果如图7所示.

图7 不同head下模型的准确率
从图7中可以观察出,当head=8时,模型分别在14Rest和14Lap数据集上能得到最高的准确率(84.91%,80.88%);当head=4或者head=5时,模型在15Rest数据集上可以得到最高的准确率84.9%.但head个数越多并不一定能得到更高的准确率,在14Rest数据集中head数为9时,模型的准确率并没有head数为8时高,因为随着head个数的增加,模型也会变得更加复杂,模型的泛化能力会降低.因此本文选取head=8时的模型,其在3个数据集上的整体性能相对更好.
4.6 案例研究
本文通过注意力热力图来可视化本文模型和消融模型(w/o SS)产生的注意力结果,单词的阴影越深,对应模型给予的注意力权重就越高.本节选取了两个句子来作为测试实例,第1个句子为“The[bed]is so good and so comfortable but[ornament]of this room is really ugly”,该句子包括了两个目标词,分别是“bed”和“ornament”.第2个句子为“The[menu]is interesting and quite reasonable priced”,该句包括了一个目标词“menu”.图8、图9和图10分别展示了本文模型和消融模型在3个不同目标词上的注意力热力图.

图8 目标词“bed”上的注意力热力图

图9 目标词“ornament”上的注意力热力图
如图8所示,对于目标词“bed”而言,本文模型识别了“so good”和“so comfortable”语义片段,并给予了其较高的权重,消融模型只给了“good”较高的权重.如图9所示,对于目标“ornament”而言,本文模型给予了“really ugly”较高的权重,而消融模型不能准确地确定每个词与目标之间的相关性,会导致模型对目标词产生错误的情感极性预测.如图10所示,本文模型给予了“is interesting”和“reasonable priced”较高的权重,消融模型只给予了“interesting”较高的权重.可视化热力图的结果表明,消融模型具有较差的发现语义片段的能力,在注意力分配上也产生了较高的噪声.本文提出的模型有较强的发现语义片段的能力,能有效降低与目标情感无关的噪声,增强了模型的情感分析能力.

图10 目标词“menu”上的注意力热力图
5 总结与展望
本文提出了一种面向语义片段结构化自注意力的模型,用于对目标进行情感分析.该模型首先使用注意力编码网络对句子、上下文和目标3个语义特征进行编码以获得隐状态,解决了上文提到的RNN模型作为编码器存在的问题.再通过结构化自注意力机制将注意力权重集中在语义片段上,减少了无关噪声的产生,因此可以更好地获得跟目标相关的情感特征,最终通过输出层对目标情感进行分类.为了验证本文提出的模型的有效性,将本文模型在14Rest、14Lap和15Rest数据集上进行了实验,在这3个数据集上的准确率分别达到了84.91%,80.88%,84.37%,宏平均F1值(Macro-F1)分别为78.02%,77.04%,67.60%.实验结果表明,对比基线模型,本文提出的模型中取得了较好的结果,具有一定的应用价值.在未来的工作中,针对目标情感分析任务,希望能将对比学习融入到此模型当中来,以此提高模型预测目标情感极性的效果.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
四川大学学报(自然科学版)(2021年6期)2021-12-27
开放教育研究(2020年2期)2020-03-31
唐山师范学院学报(2018年6期)2018-12-25
传媒评论(2017年3期)2017-06-13
中国修辞(2017年0期)2017-01-31
第二课堂(课外活动版)(2016年2期)2016-10-21
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
文苑(2015年9期)2015-09-10
