
基于粗糙集理论的自动机器学习算法
2022-12-07 04:01张雪峰林晓飞
沈阳大学学报(自然科学版) 2022年6期
张雪峰,林晓飞
(东北大学 理学院,辽宁 沈阳 110819)
随着大数据时代的到来,各种各样的数据层出不穷,每组数据又有着繁多的特征,这使得数据处理成为当下的热点问题。粗糙集理论是一种处理模糊和不确定性数据的数学工具,其主要思想就是在保持分类能力不变的前提下,通过知识约简导出问题的决策或分类规则。目前,粗糙集理论已经被成功地应用于机器学习、决策分析、过程控制、模式识别与数据挖掘等领域[1]。文献[2]对信用卡欺诈检测系统中持卡人行为进行了分析,使用粗糙集理论进行特征选择、模糊逻辑决策和规则生成,使得到的结果更具有说服力。
粗糙集在属性约简上虽然有不错的效果,但是弊端还是存在的,针对粗糙集的改进理论模糊粗糙集已成功地应用于属性约简、规则提取、分类树归纳[3]等领域。文献[4]首先基于加权邻域关系构建加权邻域粗糙集(WNRS);然后定义基于WNRS的依赖关系评估属性子集,并通过贪心搜索算法选出相应子集,使用等距搜索找到最佳邻域阈值;最后使用数据库中的数据对比此模型与其他模型的性能。实验表明,WNRS是可行且有效的,并且具有很高的分类精度和压缩率。
粗糙集理论虽然成果显著,但是还不足以作为一个分析数据建立模型的工具,而粗糙集和机器学习的有效结合在数据科学领域取得了更好的成绩。文献[5]提出了基于粗糙集理论、神经网络和遗传算法的乳腺癌诊断系统。该系统首先通过训练SOM神经网络对乳腺癌医疗数据进行离散化,然后通过遗传算法对条件属性进行约简,最后从决策表中归纳出诊断规则。利用这些规则作为分类器来评价诊断系统的性能。实验表明,与传统的诊断方法相比,诊断准确率大幅度提高。文献[6]考虑传统的粗糙集理论不能处理连续属性,而且得到的分类规则大多比较复杂;又考虑支持向量机理论能够得到简洁的分类规则,也能处理连续属性,但仅适用于小样本,对大样本数据集有一定的局限性。基于上述理论以及支持向量机分类方法仅与支持向量有关的特性,提出了一种先由粗糙集进行预处理的支持向量机分类方法。实验表明,该方法在缩短训练时间的基础上保留了支持向量机方法所需分类信息,提高了分类精度,克服了其应用瓶颈。
机器学习的模型建立、参数调整等需要大量的人力和物力,所以可以实现从模型构建到应用的全程自动化的自动机器学习应运而生。文献[7]提出了基于自动机器学习的水族文字识别,在缩短选择模型时间的同时获得了很高的识别精确率。文献[8]提出了基于自动机器学习的迁移学习方法,它使用来自先前任务的知识来加速网络设计,通过扩展基于迁移学习的架构搜索方法以支持多个任务的并行训练,然后将搜索策略转移到新任务。在语言和图像分类数据上,基于自动机器学习的迁移学习将单任务训练的收敛时间缩短了1个数量级以上。同时粗糙集也成功应用于图像分割领域并取得了显著的成果[9-10]。
本文将粗糙集和自动机器学习2种数据处理方法结合,该方法的优势在于既可以展示出粗糙集在数据降维上的作用,又充分展示了自动机器学习在参数调整方面的高效性。将粗糙集中的属性约简用于数据的预处理之上,通过数据降维剔除冗余指标,尽可能多地保留有用信息的同时也尽可能多地剔除冗余信息。而后续自动机器学习的准确调参也使得模型的分类准确率更高,模型的运行时间更短,同时自动机器学习根据当前模型会集成一个更优的模型,将精确率再次提高。
1 相关算法
1.1 K均值聚类
由于粗糙集约简只适用于离散数据,本文选择实验数据为连续数据,所以需要对连续数据进行离散化处理,而K均值聚类便是常用的离散化数据的聚类方法。
K均值聚类是基于样本集合划分的聚类算法。K均值聚类将样本集合划分为k个子集,构成k个类,将n个样本分到k个类中,使得每个样本到其所属类的中心距离最小,其中每个样本仅属于1个类,这就是K均值聚类,同时根据1个样本仅属于1个类,也表示了K均值聚类是一种硬聚类算法。
K均值聚类可归结为样本集合X的划分,或者从样本到类的函数的选择问题。K均值聚类的策略是通过损失函数的最小化选取最优的划分或函数C*。
首先,采用欧氏距离平方作为样本之间的距离,
然后,定义每个样本与其所属类的中心的距离和为损失函数,即
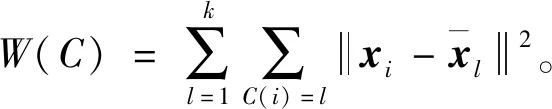
(1)
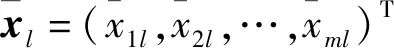
K均值聚类就是如何求解此优化问题,
相似的样本被聚到同类时,损失函数值最小,这个目标函数的最优化能达到聚类的目的。但是,这是一个组合优化问题,n个样本分到k类的所有可能分法的数目是
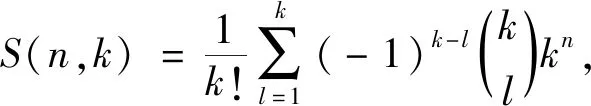
(2)
这个数字是指数级的。事实上,K均值聚类的最优解问题是NP(non deterministic ploynomial)困难问题,现实中采用迭代的方法求解。
K均值聚类算法[11]:
输入:n个样本的集合X和正整数k。
① 初始化。随机选择k个样本点作为初始聚类中心。
② 对样本进行聚类。针对初始化时选择的聚类中心计算所有样本到每个中心的距离,默认欧氏距离,将每个样本聚集到与其最近的中心的类中,构成聚类结果。
③ 计算聚类后的类中心,计算每个类的质心,即每个类中样本的均值作为新的类中心。
④ 如果迭代收敛或符合停止条件,输出C*=C(t)。重复执行②,③直到聚类结果不再改变。
输出:样本集合的聚类C。
均值聚类算法的复杂度是O(mnk),其中m是样本维数,n是样本个数,k是类别个数。
1.2 粗糙集约简算法
由于粗糙集方法在处理不确定信息时,具有不需要提供任何先验信息的特点,因而在针对不确定性问题的描述和处理时较常规方法更具客观性[12]。粗糙集约简理论可以把图1(a)的不规则图形用图1(b)规则的小矩形表示。
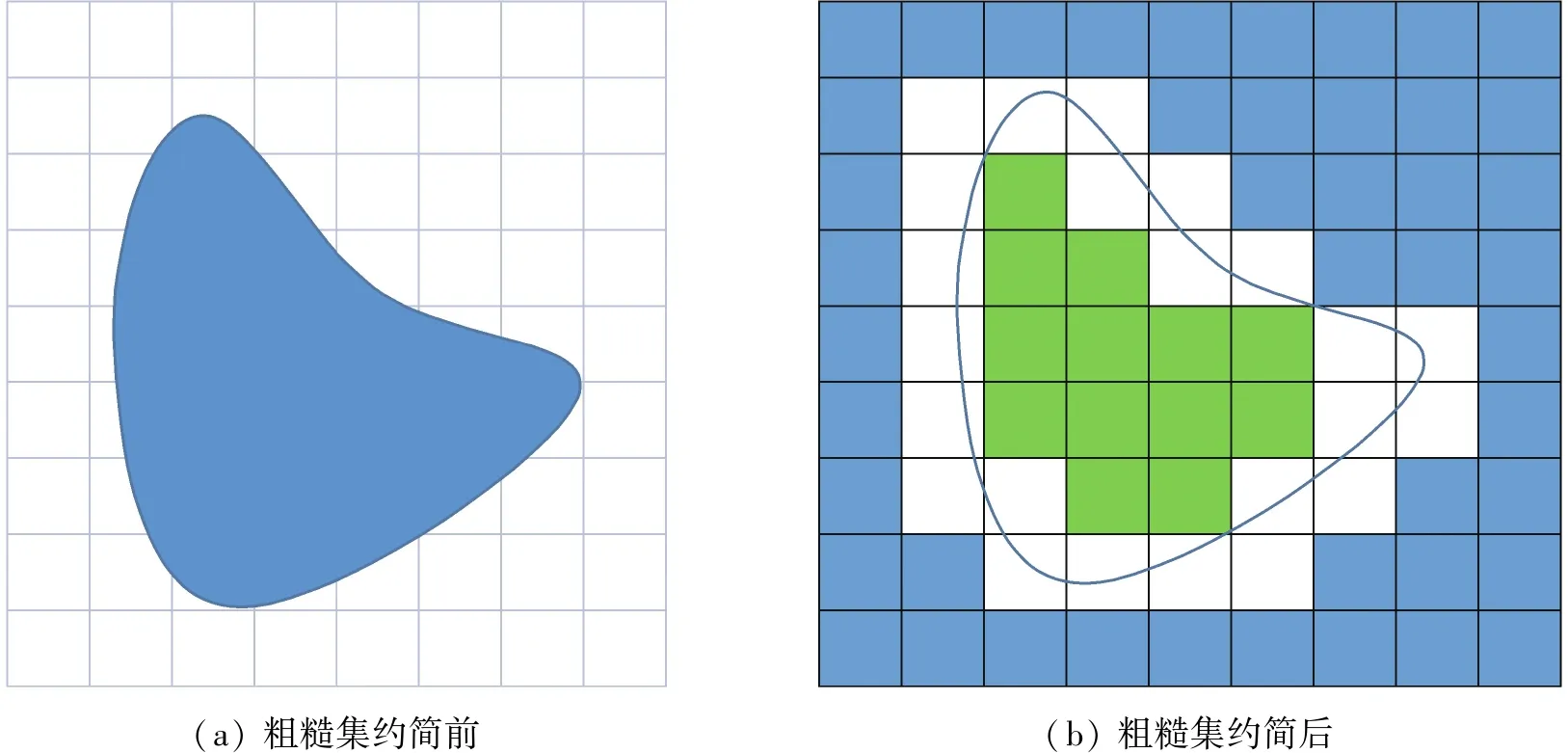
图1 粗糙集约简前后对比Fig.1 Comparison before and after rough set
定义1[1]知识和知识库。设U≠∅是感兴趣的对象组成的有限集合,称为论域。任何子集X∈U,称为U中的一个概念或范畴。为了规范化起见,认为空集也是一个概念。U中的任何概念族称为关于U的抽象知识,简称知识。对于那些在U上能形成划分的知识再进行一次划分,定义为:g=(X1,X2,…,Xn)。则U上的一族划分称为关于U的一个知识库。
定义2[1]知识约简是粗糙集理论的核心内容之一,众所周知,知识库中的知识(属性)并不是同等重要的,甚至其中某些知识是冗余的。所谓知识约简,就是在保持知识库分类能力不变的条件下,删除其中不相关或不重要的知识。
结合粗糙集理论及K均值聚类算法便可以实现粗糙集的属性约简。
粗糙集约简算法:
输入:原始离散决策表,决策表条件属性个数为K,令n=1且n∈。
① 固定条件属性,保持其中K-1个条件属性值不变。
② 改变条件属性,改变剩余一个条件属性值。
③ 判断决策属性值是否变化。
④ 若决策属性值发生变化,保留此条件属性;若决策属性值未发生变化,剔除此条件属性。
⑤ 令n=n+1。
⑥ 改变固定条件属性组合并重复执行②,③,④直到所有组合均作出判断。
输出:相对约简属性集。
在算法第③步中,判断决策属性值是否变化的依据进一步说明如下。
由于固定不同条件属性筛选到的数据表个数不同,所以此处用n来表示根据筛选条件筛选到的数据个数。如果固定条件属性X2,X3,X4,X5,X6,X7,X8,X9,X10,X11,X12,X13,X14,X15,X16时,无论X1的值取0还是2,决策属性的值始终是1,说明变量X1的改变不会影响分类结果,也就说明变量X1是冗余变量。如果固定条件属性X1,X2,X3,X4,X5,X6,X7,X8,X9,X10,X11,X12,X13,X14,X15时,无论X16的值取0还是1,决策属性的值始终在变化,说明变量X16的改变会影响分类结果,也就说明变量X16是有效变量。
1.3 自动机器学习方法
机器学习总的目标就是考虑如何学习模型和学习什么样的模型,以使模型能对数据进行准确的预测和分析,同时也要考虑尽可能地提高效率。数据准备、算法选择和超参数调整这些任务是机器学习任务最耗时的阶段,调参和搜索网络结构被认为是一项极其烦琐并且耗费人力的工作,但是这项工作又极其重要,因为参数的好坏会直接影响到网络的性能。
经验而言,只要有足够多的时间并且尝试足够多的算法和参数组合之后,都会达到一个预期的效果,但是缺点就是费时费力。这也是之前的机器学习所做的任务。思考人类发明计算机的初衷,就是让计算机来完成那些重复且烦琐的任务,所以这项工作理论上来说也可以交给计算机来完成,在解放了人的同时,在模型的准确率上甚至会有更大的提升,因而,自动机器学习技术便应运而生。自动机器学习技术包含自动调节超参数、自动调整网络结构等,在深度学习领域已取得了不错的成绩。

图2 使用2个叠加层和基础学习器的多层叠加策略Fig.2 Multi-layer overlay strategy using two overlay layers and basic learner
由于自动机器学习有着巨大的潜力,在这个领域已经开发了很多的框架,本文所采用的框架是由亚马逊公司开发的AutoGluon框架[13]。该框架的优点在于能够自动管理端到端的机器学习流程,融合了机器学习的众多模型,而且它是一个处理异构数据集、神经网络以及基于多层叠加和重复K折叠组合的强大模型集成。AutoGluon相较于其他框架而言,优势在于寻找超参数的策略是自动设置固定的默认值,能够使它在寻找超参数的过程中加快速度,同时也不会错过最优的超参数。
AutoGluon框架相比于其他框架的最大优势在于模型集成。将多个模型的预测结合起来的整体效果比单个模型的效果要好很多,这通常会大大降低最终预测的方差,不仅可以改进单个基础预测的缺点,而且可以利用基础模型之间的相互作用提供增强的预测能力。
1.4 决策树模型
决策树是一种基本的分类与回归的树形结构,表示基于特征对实例进行分类的过程,如图3所示。决策树通常是基于不同特征的信息增益生成的,设X是一个取有限个值的离散随机变量,其概率分布为P(X=xi)=pi,i=1,2,…,n,则随机变量X的熵定义为
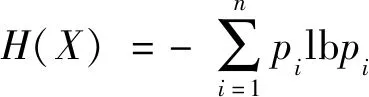
(3)
这时熵的单位分别称为比特或者纳特。随机变量X给定的条件下随机变量Y的条件熵定义为
特征A对训练数据集D的信息增益定义为
g(D,A)=H(D)-H(D|A),
则信息增益大的特征具有更强的分类能力。
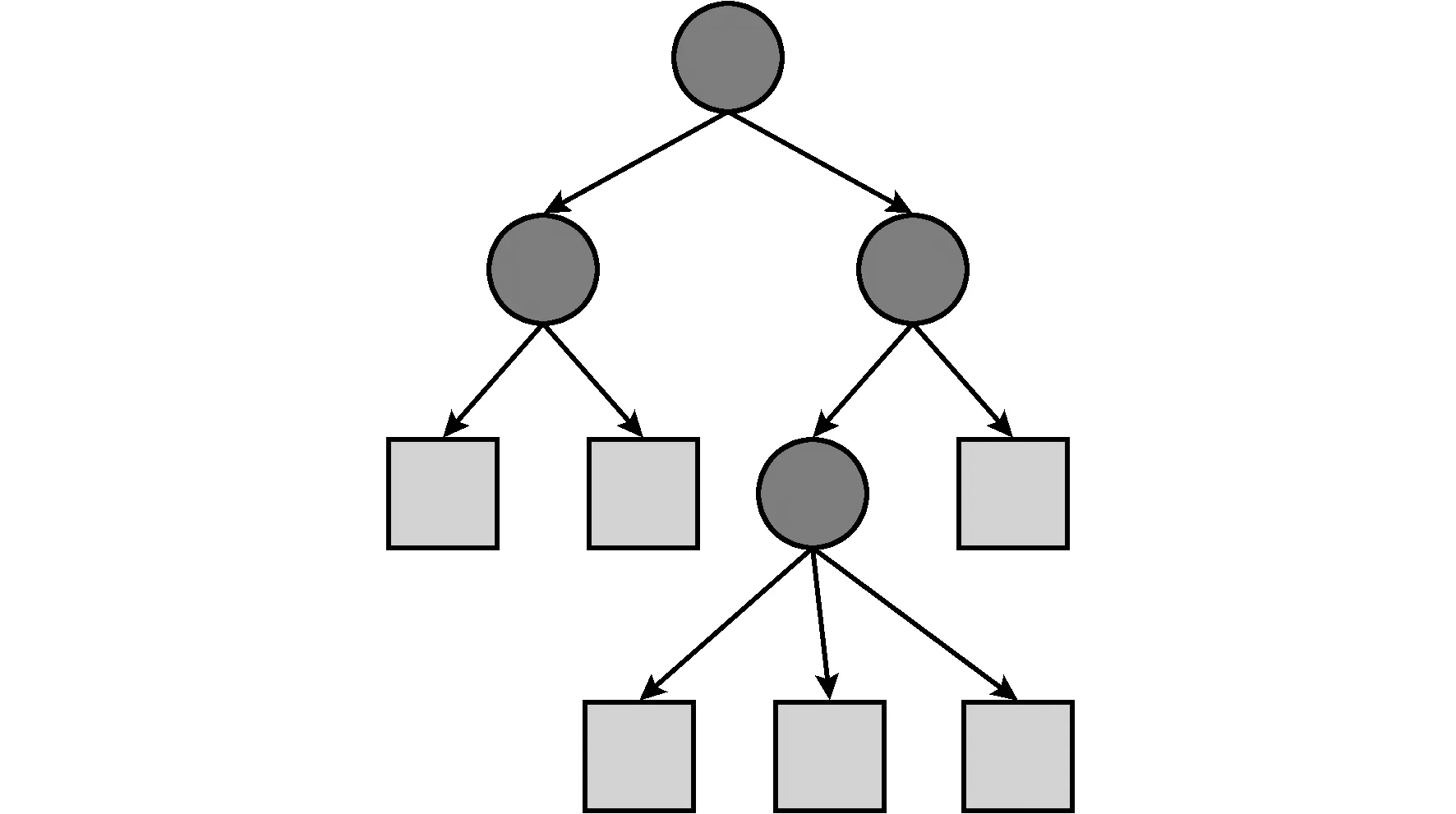
图3 决策树模型Fig.3 Decision tree model
图3中圆和方框分别表示内部结点和叶结点。用决策树分类,从根节点开始对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点,这时,每个子结点对应着该特征的一个取值。如此递归地对实例进行测试并分配,直到达到叶结点,最后将实例分到叶结点的类中。
本文采用的决策树模型是LightGBM[14],这是一种梯度增强决策树(gradient boosting decision tree,GBDT)。LightGBM包含2种新技术:基于梯度的单边采样(gradient-based one-side sampling,GOSS)和互斥特征捆绑(exclusive feature bundling,EFB)。
使用GOSS可以排除很大一部分具有小梯度的数据,而只使用其余的数据来估计信息增益。试验证明具有较大梯度的数据实例在信息增益计算中起着更重要的作用,GOSS可以在较小的数据量下获得相当精确的信息增益估计。
通常实际应用的中高纬度数据是稀疏数据,使用EFB可以设计一种几乎无损的方法来减少有效特征的数量,尤其是在稀疏特征空间中许多特征互斥的情况下。这可以安全的将互斥特征绑定在一起形成一个特征,从而减少特征维度。由于需要将特征划分为更小的互斥捆绑数量,但是在多项式时间内不可能去找到准确的解决办法,所以EFB使用了一种近似的解决办法,即特征之间允许存在少数的样本点并不是互斥的,允许小部分的冲突可以得到更小的特征捆绑数量,更进一步提高计算的有效性。
1.5 BP神经网络模型
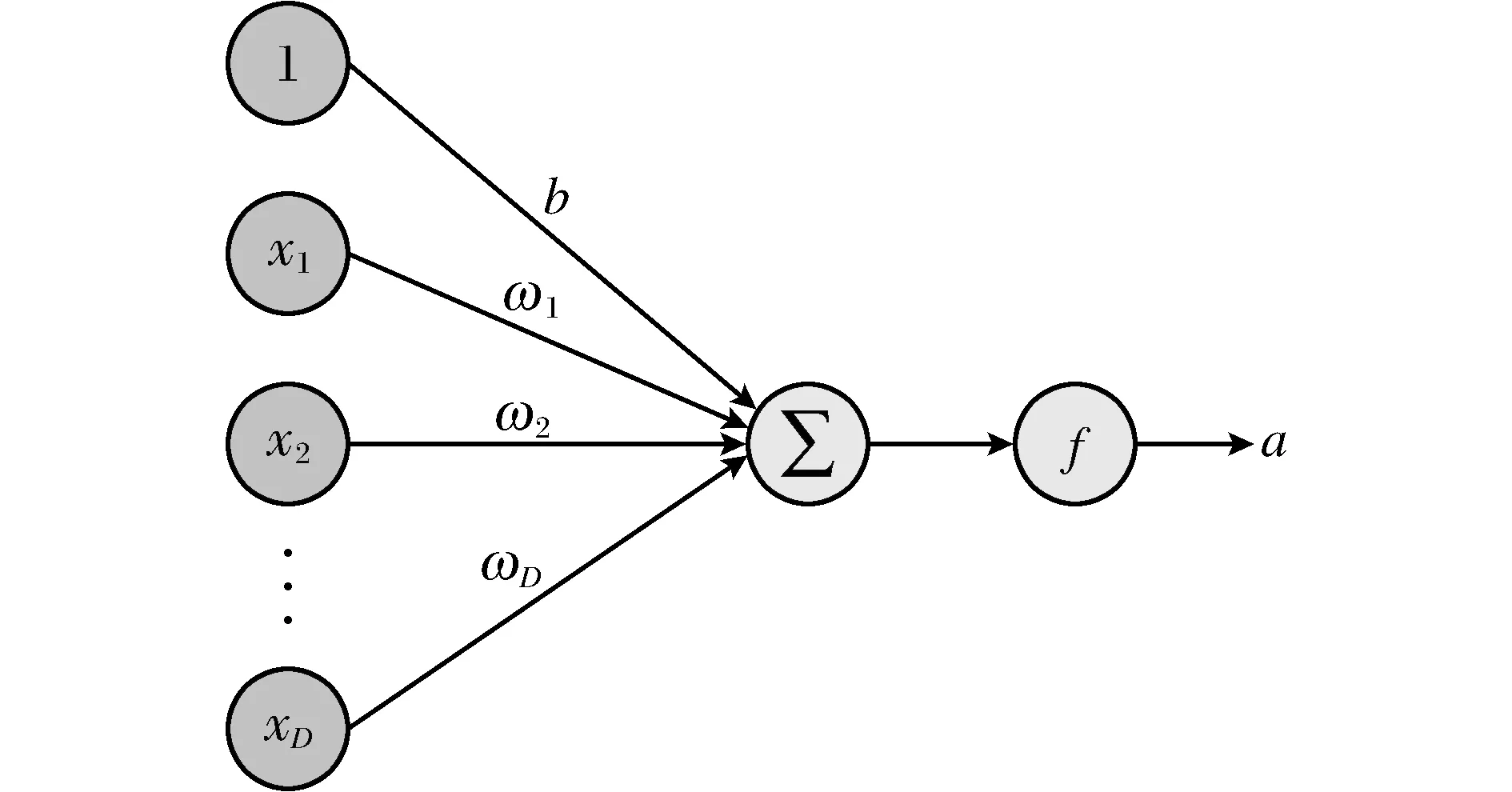
图4 神经元Fig.4 Neuron
神经网络一般可以看作一个非线性模型,其基本组成单元是具有非线性激活函数的神经元,通过大量神经元之间的连接,使得神经网络成为一种高度非线性的模型,如图4所示。
假设一个神经元,接收D个输入x1,x2,…,xD,令x=(x1,x2,…,xD)T表示这组输入,并用净输入z∈表示一个神经元所获得的输入信号x的加权和,
式中,ω=(ω1,ω2,…,ωD)T∈D是D维的权重向量,b∈是偏置。
净输入z经过一个非线性函数f后,得到神经元的活性值a,
a=f(z)。
其中,非线性函数f称为激活函数,一般选择如下函数作为激活函数,
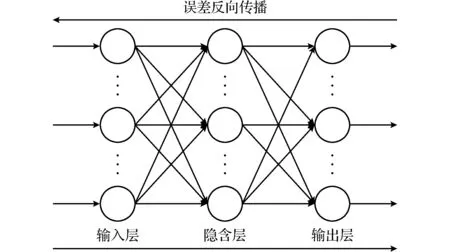
图5 BP神经网络Fig.5 BP neural network
反向传播神经网络(BP神经网络)是目前在分类问题上应用最多的一种神经网络,它是一种单向传播的多层前向网络。其学习算法遵循“误差反向传播原理”,学习的本质是对各连接权重的动态调整,当一组学习样本提供给网络后,神经元的激活值从输入层经各中间层向输出层传播,在输出层的各神经元获得网络的输入响应,进而按照减少目标输出与实际误差的方向,从输出层经过各中间层逐层修正各连接权值,最后回到输入层,这样完成一次权值修正。最终使误差函数减小到极小值,得到最优拟合结果[15]。图5便是一个含有输入层、隐含层和输出层的BP网络。
训练一个BP神经网络,实际上就是调整网络的权重和偏置这2个参数,分为前向传输和逆向反馈。前向传播时,输入样本从输入层传入,经各隐层逐层处理后传向输出层。若输出层的实际输出与期望的输出不符,则转入误差的反向传播阶段。反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
FastAi[16]和MXNet[17]都是目前非常流行的神经网络训练框架,本文采用这2种框架实现数据的分类,并比较2种框架下的运行时间和分类准确率,从而作出更加客观的判断。
2 算法设计
考虑到数据维度大,直接使用数据进行分类会大大影响效率,所以先进行粗糙集属性约简。由于粗糙集属性约简需要使用离散化数据,所以使用K均值聚类算法对数据先进行离散化,得到离散化决策表,然后使用粗糙集属性约简得到约简属性集。利用引导聚集算法(Bagging)对样本进行随机采样,得到多个样本集,分别训练多个样本集得到多个弱分类器,针对弱分类器的分类结果投票得到强分类器作为预测模型之一,进行多次引导聚集算法得到多个预测模型。最后进行模型集成,将多个优秀模型集成为一个模型,根据不同模型的不同分类准确率分别赋予不同的权重,得到最终的集成模型。
基于粗糙集和自动机器学习的分类算法:
输入:原始数据(X,Y),分类模型个数M,分类聚集算法选取子集个数k。
① 对数据集的特征进行K均值聚类,得到离散的条件属性。
② 对得到的条件属性进行粗糙集数据约简,筛选出重要特征。
③ 将筛选后的数据集随机分成k个子集。
④ 用k个子集分别对M个分类模型进行训练,得到多个模型参数φm,i。
⑤ 使用自动机器学习进行模型的参数调整得到最优模型。
⑥ 对模型参数加权,得到集成模型f(x)=∑ωm,iφm,ix。
输出:模型准确率,运行时间,M个分类模型权重,集成模型。
算法流程如图6所示。
3 实验结果与分析
3.1 数据选择
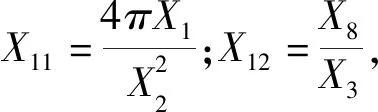
原始数据如表1所示,数据量大导致无法展示全部数据,所以省略其中的一部分。通过K均值进行离散化后的数据如表2所示。选择干豆种类分别是:BARBUNYA、CALI、BOMBAY、SEKER,如图7所示。

图6 算法流程Fig.6 Schematic diagram of algorithm flow
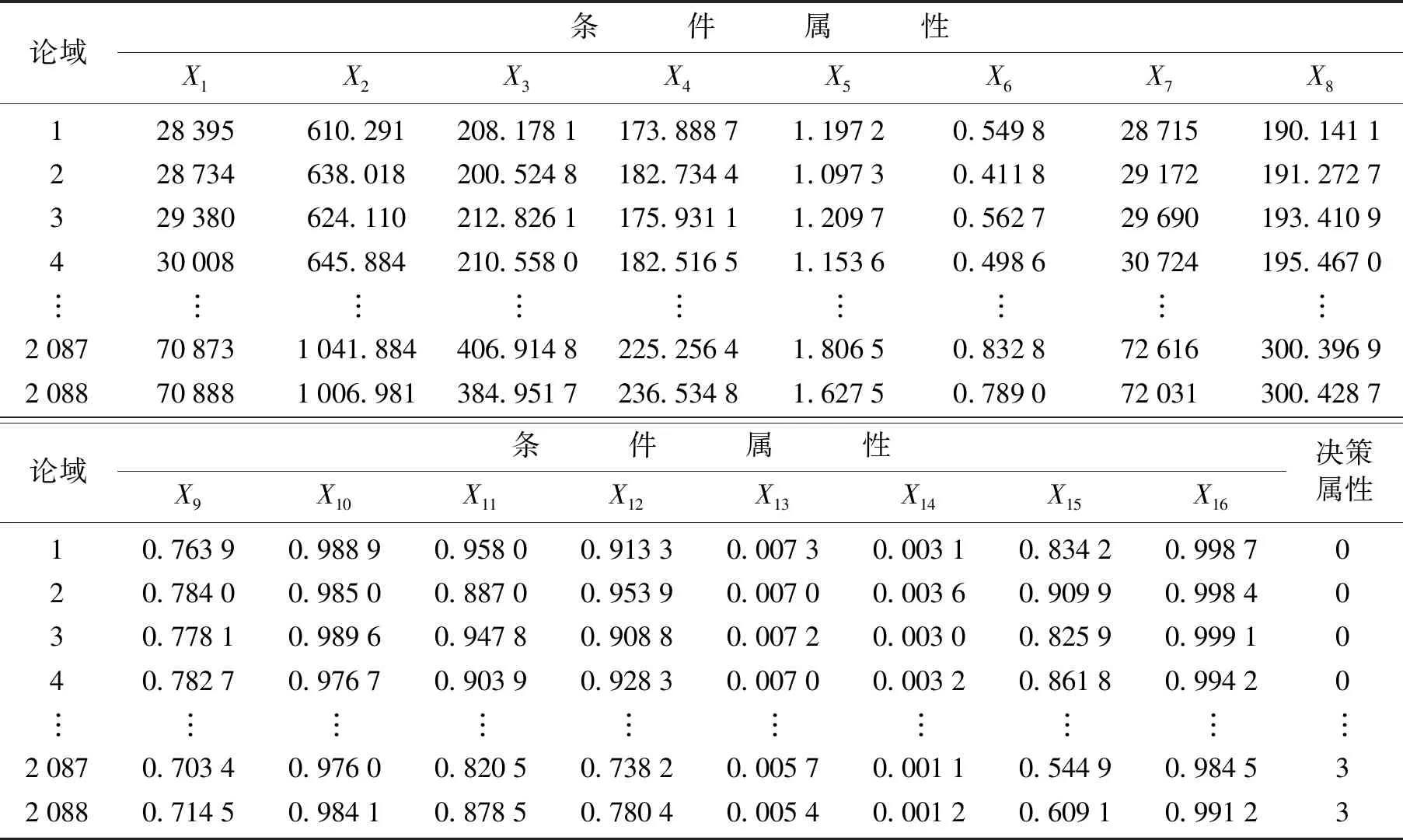
表1 原始数据Table 1 Raw data
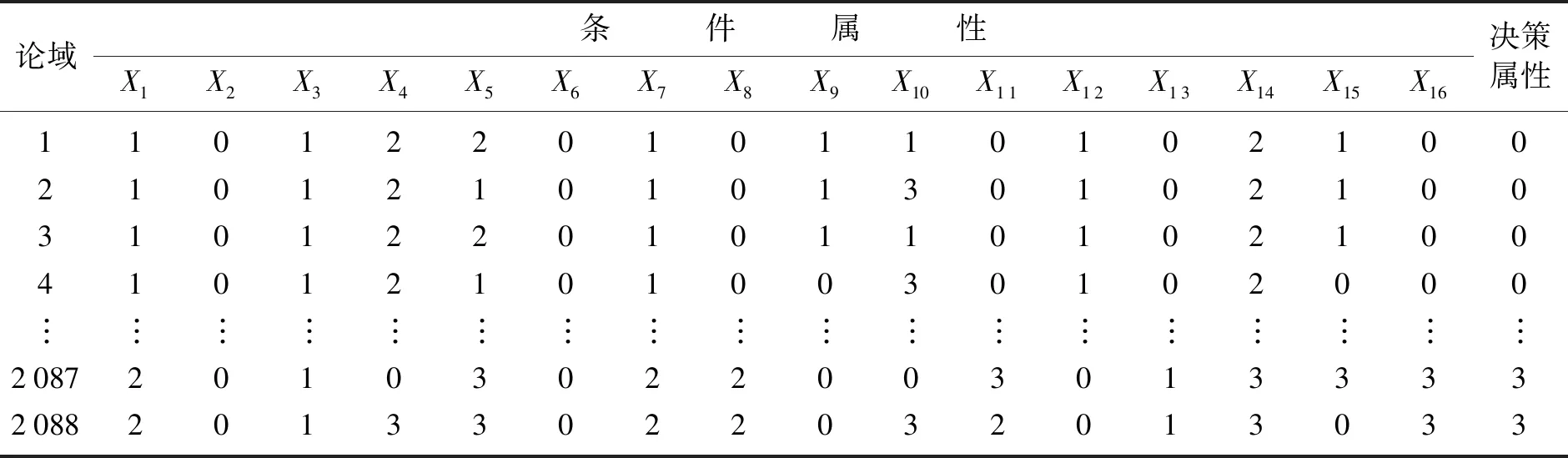
表2 离散化原始数据Table 2 Discrete raw data

图7 不同干豆Fig.7 Different dried beans
3.2 数据处理
选择样本的原则是在7类干豆中随机选择4个种类,依据后续的K均值聚类分成4类。把这4类干豆中数量最少的干豆作为每组干豆的样本量,除最少的一组干豆需要全部选择之外,其他组干豆选择遵循随机原则。即4种干豆之中数量最少的为BOMBAY,数量是522,其他干豆也随机抽取522个样本,得到的数据维度是2 088×16,其中2 088是样本数,16是样本的特征。使用K均值聚类的方法对数据做离散化处理,之后使用粗糙集的知识约简算法对数据进行冗余属性的剔除,利用分类聚集算法进行模型选择,得到2种框架下的神经网络模型,分别用FastAi模型和MXNet模型表示,同时选择LightGBM模型。接下来使用自动机器学习进行参数调整和模型集成,得到模型运行时间、分类准确率和模型损失率。
3.3 实验结果
决策属性D对应于4类干豆,分为0,1,2,3,属性约简之后的条件属性由原来的16个变成了8个,见表3。为了验证粗糙集属性约简的有效性和自动机器学习调参的准确性,分别在3种条件下进行测试:①不进行粗糙集属性约简,同时也不使用自动机器学习进行参数调整(no_tune);②使用自动机器学习进行参数调整,但不使用粗糙集进行属性约简(AutoML);③既使用粗糙集属性约简,又使用自动机器学习进行参数调整(AutoML+RS)。结果如图8所示。自动机器学习给出的集成模型WeightedEnsemble根据3个模型的分类准确率分别赋予FastAi、MXNet、LightGBM 3个模型0.3、0.3、0.4的权重。不同条件下模型准确率见表4,运行时间见表5。从图8(a)及表4、表5中可以看到FastAi模型的准确率从高到低的条件分别是AutoML+RS、AutoML、no_tune,运行时间从低到高的条件分别是AutoML+RS、AutoML、no_tune。随着迭代次数的增加,AutoML+RS的准确率可以达到98.91%,运行时间可以缩短到9.50 s。从图8(b)及表4、表5中可以看到MXNet模型的损失率从小到大的条件分别是AutoML+RS、AutoML、no_tune,运行时间从低到高的条件分别AutoML+RS、AutoML、no_tune。随着迭代次数的增加,AutoML+RS条件下的MXNet模型损失率可以下降到1.4%,运行时间可以缩短到17.32 s。从图8(c)及表4、表5中可以看到LightGBM模型的准确率从高到低的条件分别是AutoML+RS、AutoML、no_tune,运行时间从低到高的条件分别AutoML+RS、AutoML、no_tune。随着迭代次数的增加,AutoML+RS的准确率可以达到98.55%,运行时间可以缩短到1.52 s。
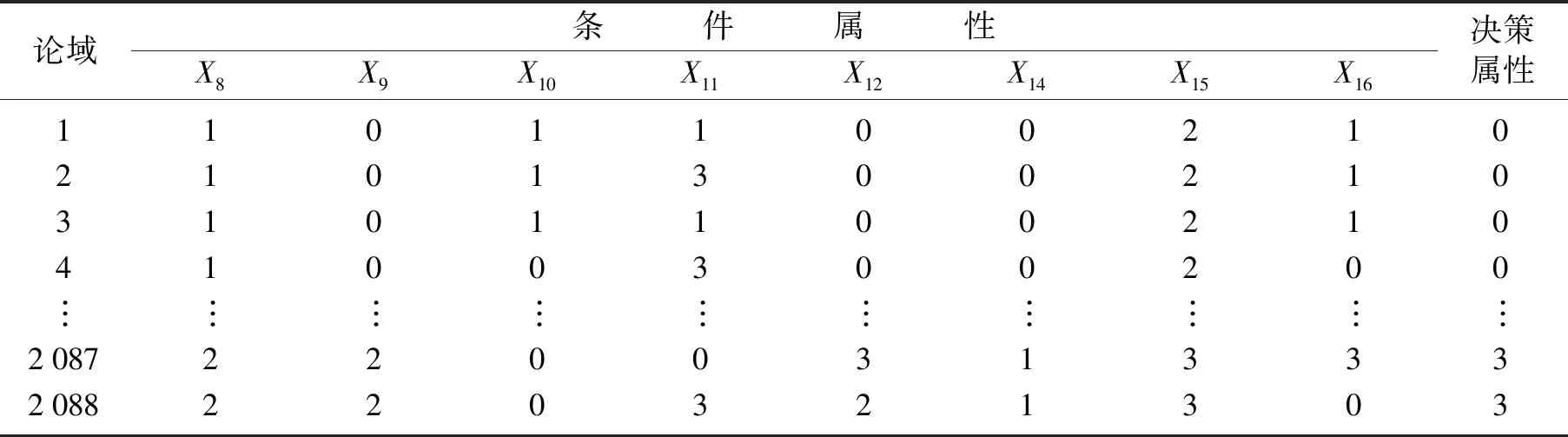
表3 离散化并约简后数据Table 3 Discrete and reduced data
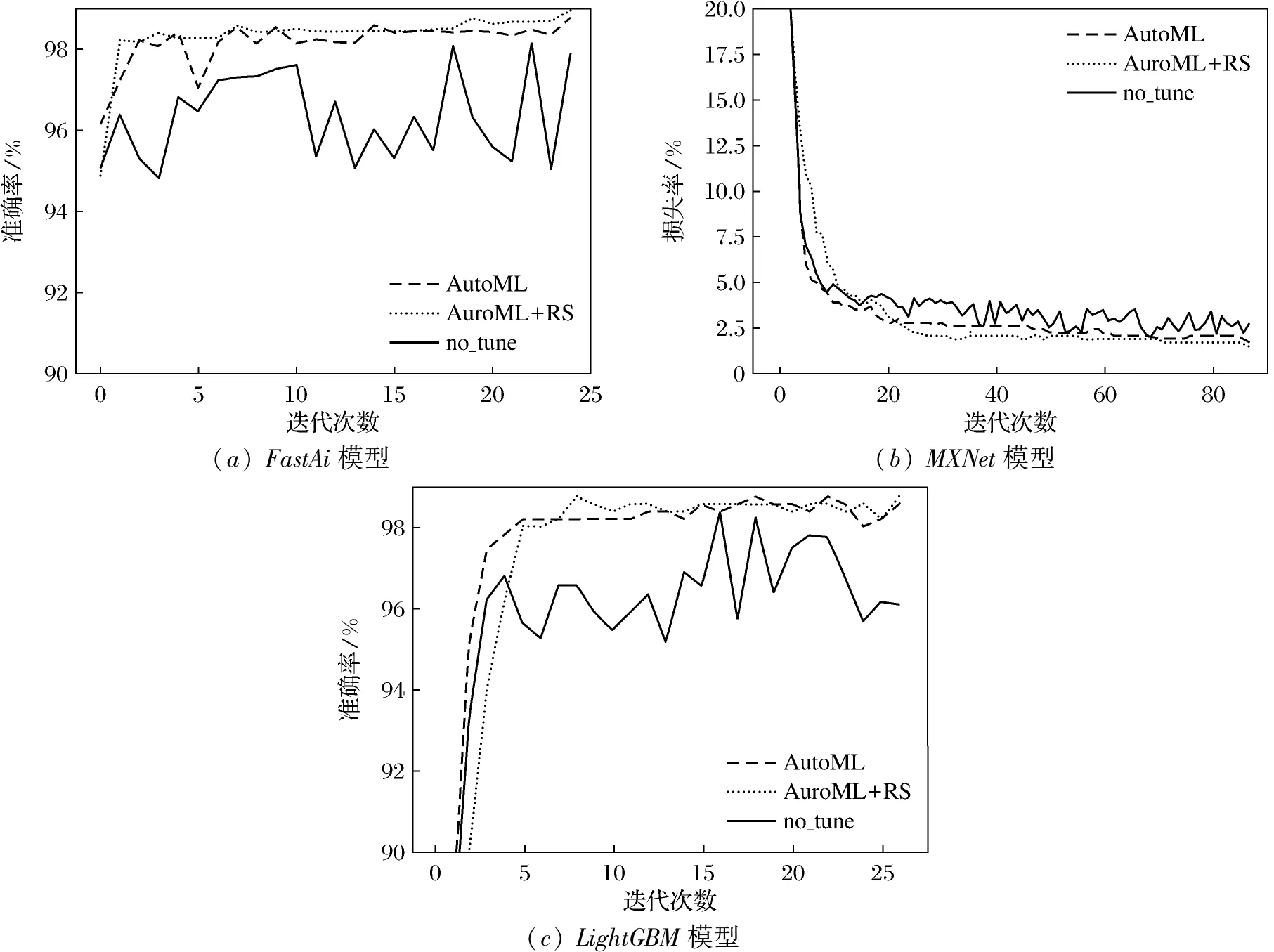
图8 不同模型结果Fig.8 Results of different models
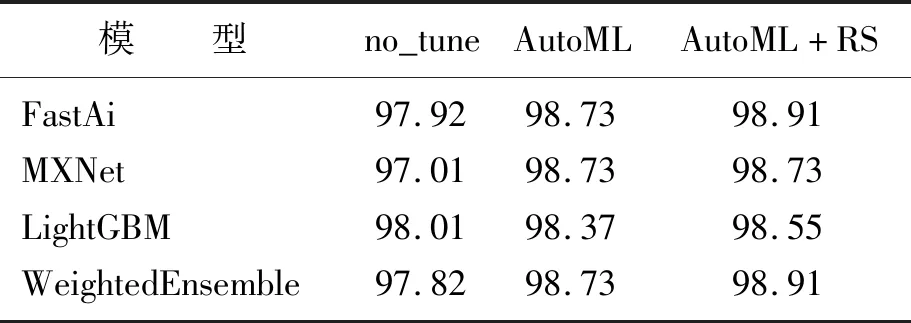
表4 不同条件下模型准确率Table 4 Accuracy rate of models under different conditions 单位:%
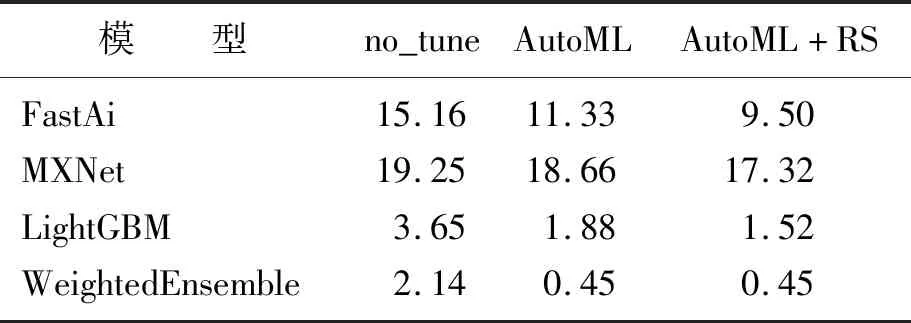
表5 不同条件下模型运行时间Table 5 Running time of models under different conditions 单位:s
4 结 论
分别将不使用粗糙集约简的数据和使用粗糙集约简的数据应用3种模型在不同条件下进行了实验。得出结论:使用自动机器学习进行调参之后,几乎所有模型的准确率都有大幅度的提升,同时使用粗糙集约简和自动机器学习进行调参之后,模型的准确率有了更大幅度的提升,模型损失率也大幅下降;从运行时间上,几乎所有模型的运行时间都显著缩短,也证明了粗糙集的属性约简确实有助于缩短建模时间;自动机器学习不仅对模型进行了参数调整,而且还对模型进行了集成,自动机器学习分别给出了3个模型不同的权重得到的集成模型,集成模型的准确率比其他模型更高,运行时间比其他模型更短。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
科教导刊·电子版(2021年6期)2021-05-06
成都信息工程大学学报(2019年2期)2019-08-28
电影(2018年8期)2018-09-21
系统管理学报(2018年3期)2018-08-13
自动化学报(2018年2期)2018-04-12
智能系统学报(2017年3期)2017-08-01
厦门理工学院学报(2016年3期)2016-11-10
