
D2SE-CNN:改进的SAR图像相干斑抑制算法
2022-12-14 08:25张一铭赵生福王艺博
兵器装备工程学报 2022年11期
张一铭,赵生福,郑 鑫,王艺博,丁 辉,2
(1.首都师范大学信息工程学院,北京 100048; 2.高可靠嵌入式系统技术北京市工程研究中心, 北京 100048)
1 引言
SAR(synthetic aperture radar),即合成孔径雷达,是一种主动式的对地观测系统。与可见光、红外遥感等观测系统相比,SAR拥有多种工作方式、受天气影响较小、并且可以实时产生高分辨率图像等优点。因此其在森林监测、城市规划、灾害评估等众多领域得到了大范围的应用。然而,由于物体表面粗糙,各基本散射体和传感器之间的距离不同导致各个散射体的回波相位不一致。结果是回波强度逐像素变化,在模式中呈颗粒状,从而产生了相干斑(Speckle)。SAR图像中相干斑噪声的存在往往会给计算机视觉系统的处理带来困难[1]。因此,去除SAR图像中的噪声对于提高分割、检测和识别等各种计算机视觉算法的性能具有重要意义。
通常根据相干斑特点的去噪算法大体可以分为:基于空域滤波的去噪算法、基于变换域滤波的去噪算法以及近年来逐渐流行的基于深度学习的去噪算法[2-3]。基于空域滤波的代表性算法有Lee滤波器[4]、Kuan滤波器[5],非局部均值(non-local mean,NLM)去噪[6]等,基于变换域滤波的代表性算法有:小波域SAR图像去噪[7]、轮廓波域SAR图像去噪[8]和剪切波域SAR图像去噪[9],以及基于块匹配的3D协同滤波算法BM3D[10](block matching and 3D collaborative filtering)等。
在SAR图像相干斑抑制中,也出现了一些比较有代表性深度学习的算法。基于卷积神经网络(convolutional neural networks)的去斑点网络SAR-CNN[11],该网络通过斑点SAR图像除以估计的噪声来获得去斑点图像。Wang等[12]提出ID-CNN模型,将原始带噪声的SAR图像转换到对数域进行去噪分析,并最终通过指数处理获得去斑后SAR图像。基于卷积的降采样FFDNET[13]模型对不同程度的噪声有较好的去除效果,但需要用户输入参数为生成的噪声水平图像。随着变压器(Transformer)在自然语言处理方面的成功,Malsha等[14]提出了一种基于变压器的SAR图像去相干斑网络等。
由于ID-CNN是基于乘性噪声特点进行处理,更适用于SAR图像的相干斑噪声特性。因此,本文基于ID-CNN的网络结构,并结合SE(Squeeze-and-Excitation)注意力提出了一种改进的模型D2SE-CNN,在合成图像数据集和真实SAR图像上进行实验分析,取得了较好的图像增强的效果。
2 基本原理
SAR图像通常会受到被称为乘性噪声的相干斑噪声污染。相干斑噪声是由每个分辨率单元内的电磁波的矢量叠加造成的。接下来分析雷达噪声的数学模型和ID-CNN基础网络。
2.1 雷达噪声数学模型
SAR图像真实强度通常可用乘积模型中的2个不相关的变量描述[15]:
Y=FX
(1)
式中: Y∈RW×H是观察到的图像强度;X∈RW×H为无噪声图像;F∈RW×H为散斑噪声,其中W和H分别是图像像素的横纵坐标[15]。
其中F是归一化衰落散斑噪声随机变量。关于F的一个常见假设是,它遵循单位均值为1、方差为1/L的伽马分布,其概率密度函数为[16]:
(2)
目前,该模型已经广泛应用在SAR图像中,被称为乘性斑点噪声模型。
2.2 ID-CNN模型介绍
ID-CNN(image despeckling convolutional neural network)是直接基于SAR图像乘性噪声进行处理的卷积神经网络。
ID-CNN结构分为3部分,多组卷积层以及批量归一化和修正线性单元(ReLU)激活函数。所有卷积层两端使用残差连接来估计斑点,最后使用损失和总变化(TV)损失的组合以端到端的方式进行训练。所提出的图像去斑点卷积神经网络(ID-CNN)结构如图1所示。
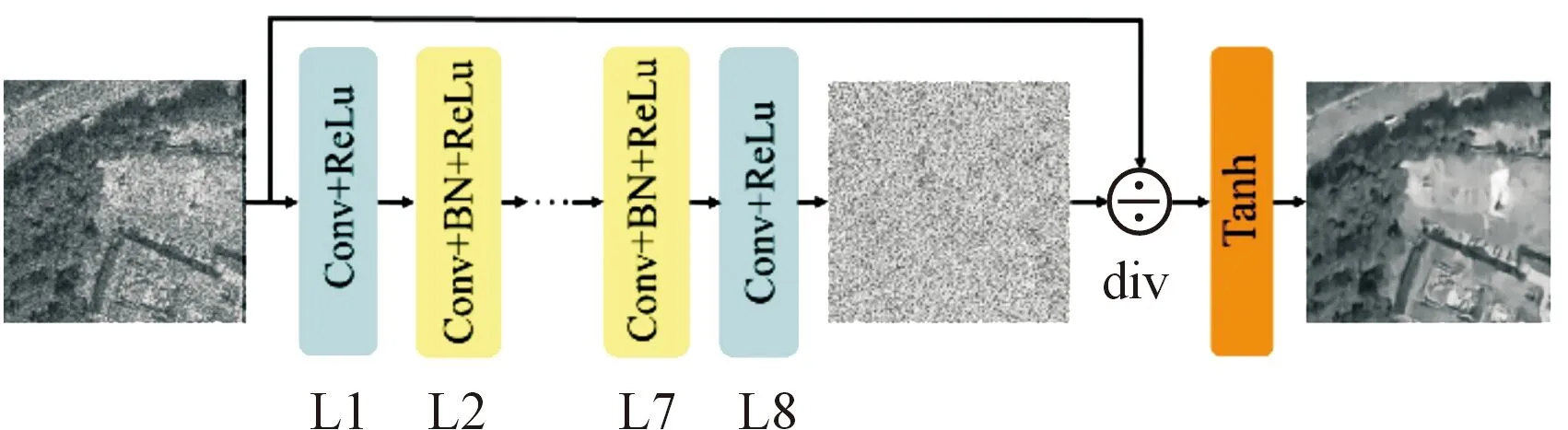
图1 ID-CNN结构示意图
与传统卷积神经网络(CNN)不同的是,ID-CNN没有使用同态变换[17],而是使用了基于雷达图像噪声模型(1)的输入图像直接估计斑点噪声,即在残差连接时使用除法而并非加法。相较于Lee、Forst等传统滤波器和传统卷积神经网络(CNN),ID-CNN在雷达图像相干斑抑制中具有更好的效果。
2.3 通道注意力介绍
注意力机制是20世纪90年代,认知科学领域发现的一种信号处理机制。目前,注意力机制已经成为深度学习领域的一个重要概念。Jie Hu等[18]提出了挤压与激励 “Squeeze-and-Excitation”(SE)注意力模块,其作用是通过计算模型特征通道间的相互依赖性,有选择性地增强有用的特征通道,抑制相对无用的通道,从而达到增强网络代表能力的目的。SE块的基本结构如图2所示。对于任何给定的变换Ftr∶X→U,X∈RH′×W′×C′,U∈RH×W×C(例如一次卷积或一组卷积操作),其中H和W是图像的大小尺寸,C是通道数,可以使用一个SE块对特征通道的权重进行重新校准。
具体步骤为,特征U首先进行挤压操作,将每个通道内空间维度H×W的特征挤压为1×1通道描述符(Fsq),然后通过基于通道相互依赖性的自选机制学习对每个通道的样本进行激活(Fex),最后对特征映射U进行重新加权(Fscale),生成SE块的输出。

图2 Squeeze-and-Excitation结构示意图
3 D2SE-CNN模型
卷积神经网络(CNN)能够在每一层的局部感受野内融合空间和通道信息来构建信息特征。最近的研究表明,可以将注意力机制集成到网络中来增强CNN的性能,对特征通道间的相关性进行建模,把重要特征进行强化来提升准确率。对图像进行下采样可以加快训练和测试速度,同时也扩大感受野,能够在速度和去噪性能上达到较好的平衡。本文基于ID-CNN模型,结合下采样和SE块的优点进行改进。
3.1 模型结构
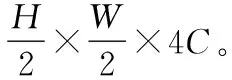

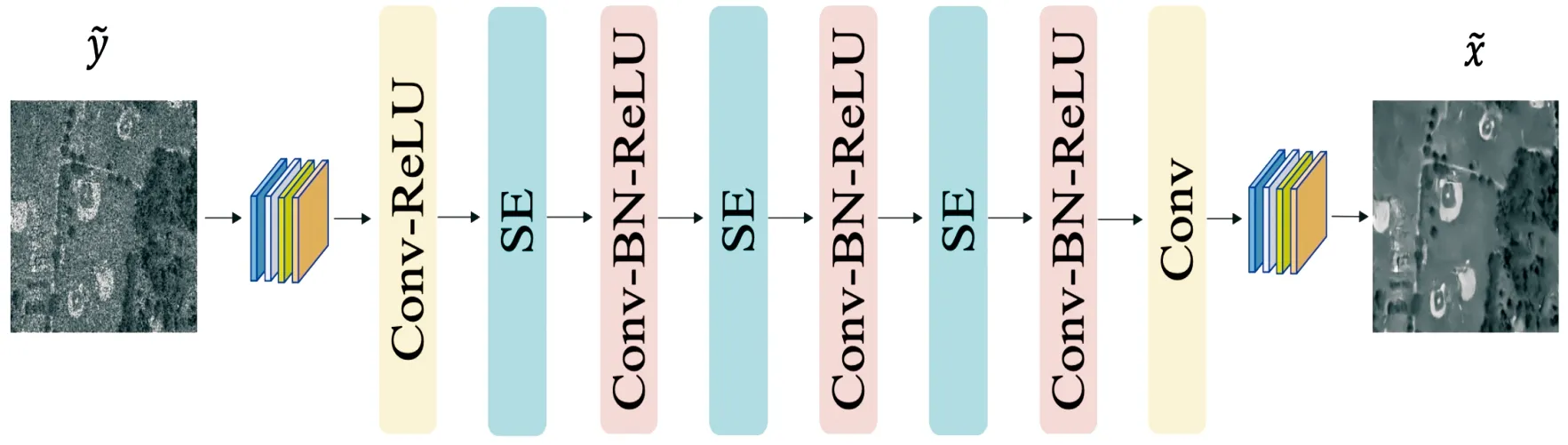
图3 D2SE-CNN模型结构示意图
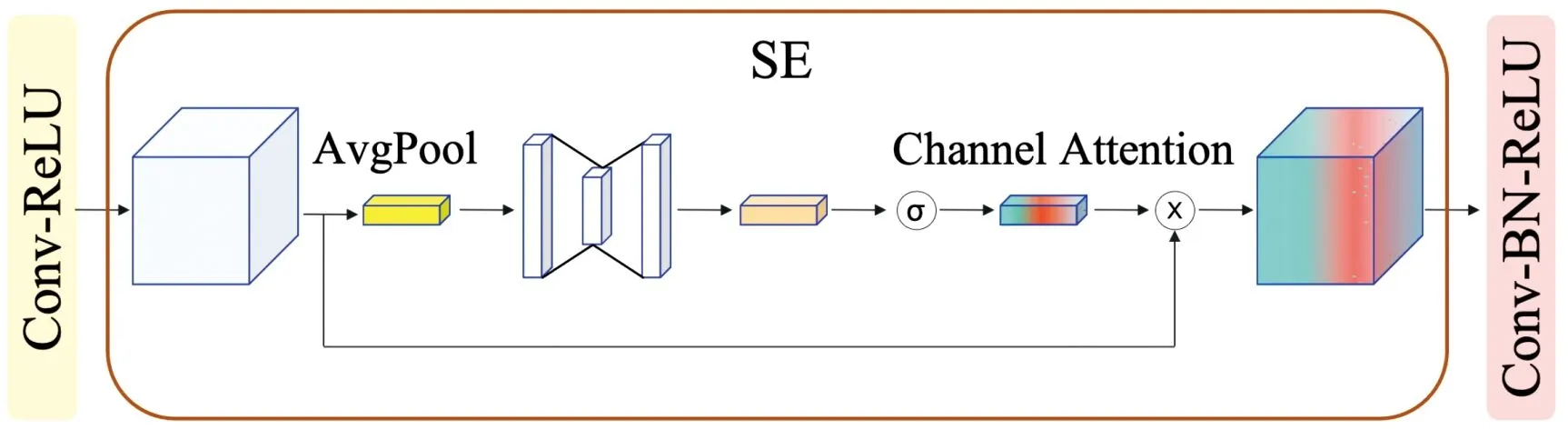
图4 SE模块结构示意图
与ID-CNN不同,提出的模型不预测噪声,这也为同时去除乘性和加性噪声提供了可能。文献[21]指出CNN残差学习和批量归一化的集成有利于去除噪点,因为它简化了训练并能够提供更好的性能。主要原因是残差(噪声)输出遵循高斯分布,有利于批量归一化和高斯归一化步骤。根据实验结果,批量归一化始终可以加快网络训练的速度。同时在批量归一化的情况下,残差学习尽管有更快的收敛速度,最终性能却弱于非残差学习。根据提出的训练策略来看,当网络深度适中时(例如小于20),通过残差或非残差学习策略训练网络都是可行的。为简单起见,不使用残差学习进行网络设计。此外,根据实验结果,ID-CNN采用的除法残差策略在损失函数上表现为收敛较慢,且易出现因除数较小而产生非数字(NaN)的情况。
3.2 损失函数
在CNN去噪任务中,损失函数是模型学习过程中的重要组成部分。目前在图像超分辨率[22]、语义分割[23]和图像风格迁移[24]等任务中已经探索出不同的有效损失函数及其组合。实验采用了2种常见的损失函数L1范数、L2范数(欧几里得损失函数),在预测图像和真值图像之间使用L1范数进行优化,在消融实验中采用L2范数与TV损失进行对比。
对于给定的一个图像对{X,Y},其中Y是有噪声的输入图像,X是相应的真值,采用的L1范数损失函数L1和欧几里得损失函数LE分别定义为以下公式:
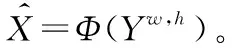
与ID-CNN不同的是,D2SE-CNN模型没有使用TV损失函数,根据消融实验结果,加入TV损失并没有使图像质量得以提升,反而有所下降。
4 实验结果
实验使用开源的旷视天元MegEngine开放平台[25],框架版本为1.9,Python版本为3.7,在旷世MegStudio环境下GPU服务器上进行。
4.1 数据集生成和评价指标
本文实验数据集选取了BSD500数据集[26]以及由西北工业大学发布的NWPUVHR-10数据集[27]。BSD500数据集包含200张训练图,200张测试图和100张验证图。NWPUVHR-10数据集中的图像裁切自Google Earth 和Vaihingen 数据集,并由专家手动注释。该样本库包含飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车10个类别共计800张图片。图5是数据集样本图,其中第1和2行来源于NWPUVHR-10数据集,第3和4行来源于BSD500数据集。

图5 数据集样本图
本次实验训练集,验证集,测试集比例划分为6∶2∶2。训练前统一将图片的大小设置为256×256。数据集配置信息见表1。网络训练过程中采用了ADAM算法[28],对于ADAM的超参数,学习率设置为0.000 2,权重衰减设置为0.000 01。其余超参数使用的是默认值。批处理大小设置为16,训练阶段,在图片预处理时,对输入进行正则化处理,并设置均值为0.456,方差为0.224,以此来增强原灰度图片数据。
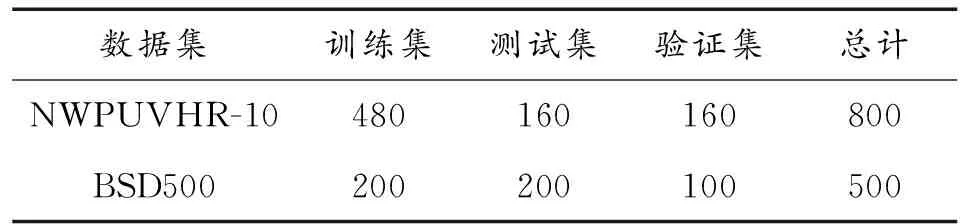
表1 数据集配置
由于不同天气或采集设备等导致SAR图像采集中会得到不同强度的噪声图像,为进一步讨论算法对不同强度的相干斑的抑制作用,实验前对数据集添加了3种不同程度的乘性噪声,其方差分别为0.8、1.0、1.2,在这3个不同的噪声级别的图像上评估模型性能。
本文采用常采用的5个图像质量评价指标包括峰值信噪比(peak signal to noise ratio,PSNR)、结构相似指数(structural similarity index measure,SSIM)[29]、均方误差(mean squared error,MSE)、等效外观数(ENL)[30]和变异系数(Cv),ENL和Cv的公式如下:
(5)
(6)
其中,μ和σ分别表示SAR图像中匀质区域的均值和标准差。
4.2 消融研究
为证明SE模块、下采样,以及不同损失函数对模型性能的影响,本实验在NWPUVHR-10数据集,方差为0.8的样本上进行了消融研究。表2所示为消融研究中各模块的有效性对比。
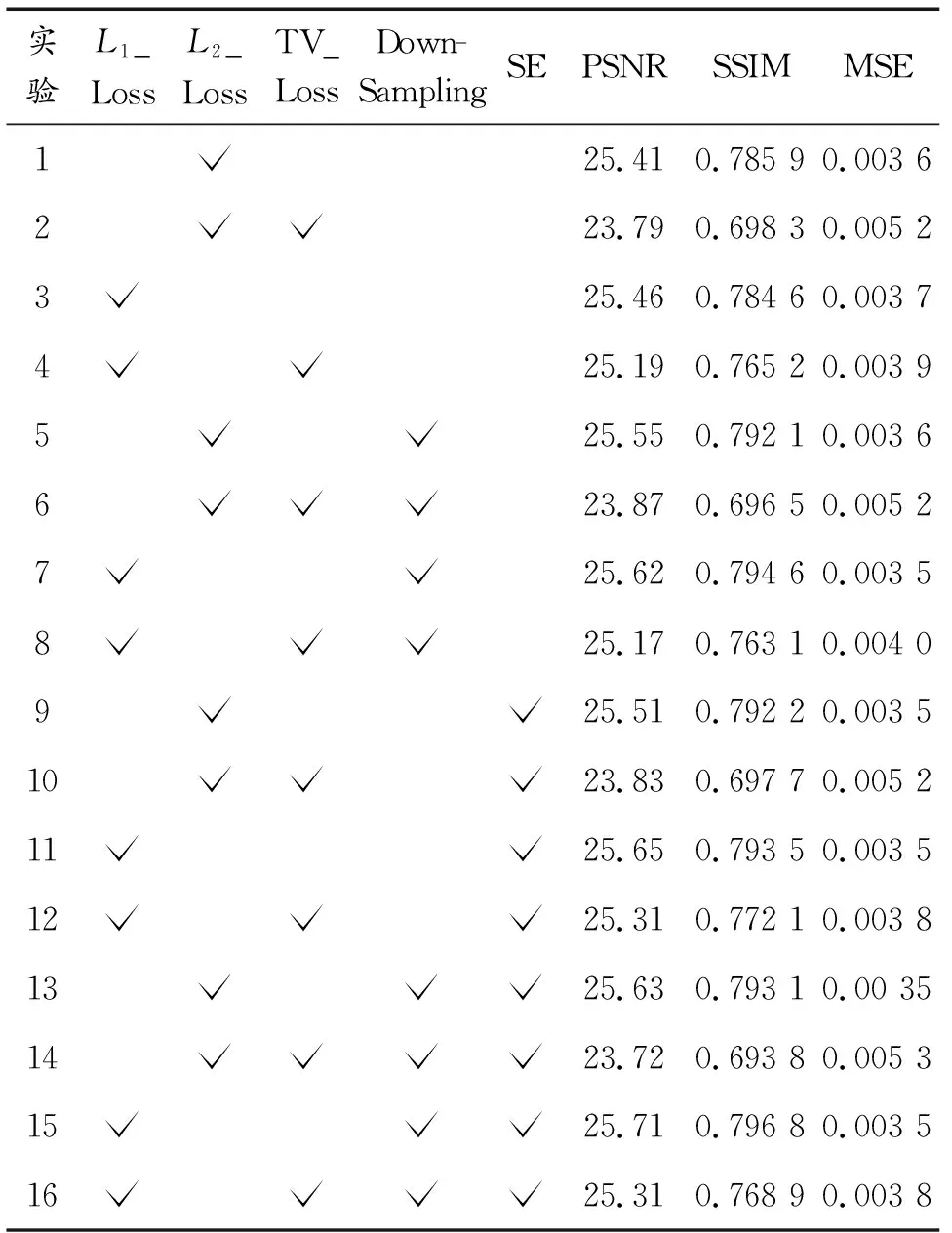
表2 数据集NWPUVHR-10上不同模块评价指标
在表2中,首先对损失函数进行消融实验,单独对比L1范数损失函数和L2范数损失函数以及分别与TV损失函数组合,其中L1范数损失函数情况下PSNR的指标更好,而L2范数损失函的SIMM指标偏好,但两者与TV损失函数组合后,指标均有下降。结合16组实验的综合情况,加入SE模块和下采样时与L1范数损失函数组合,指标均有提高。其次,分别对下采样和SE模块进行消融实验,通过对比实验3、7和实验3、11的PSNR、SSIM、MSE,可以看出仅添加下采样或SE模块对模型的性能均有提升。
实验15为同时使用L1范数损失函数、SE模块和下采样的结果,可以看到实验15的PSNR、SSIM、MSE均优于所有其他实验,说明同时使用L1范数损失函数、SE模块和下采样的模型有最佳的性能。该实验表明了使用L1范数损失函数、下采样和SE模块进行图像去斑的重要性。
4.3 合成图像的结果
为更清晰的分析D2SE-CNN模型效果,本文与7种去噪方法进行了比较。包括传统算法与深度学习算法:Lee滤波器[4]、Kuan滤波器[5]、小波变换[7](wavelet transform,WT)、非局部均值滤波[6](non-local means,NLM)、基于块匹配的3D协同滤波[10](BM3D)以及变压器(Transformer)[14]模型,实验结果如表3、表4所示。
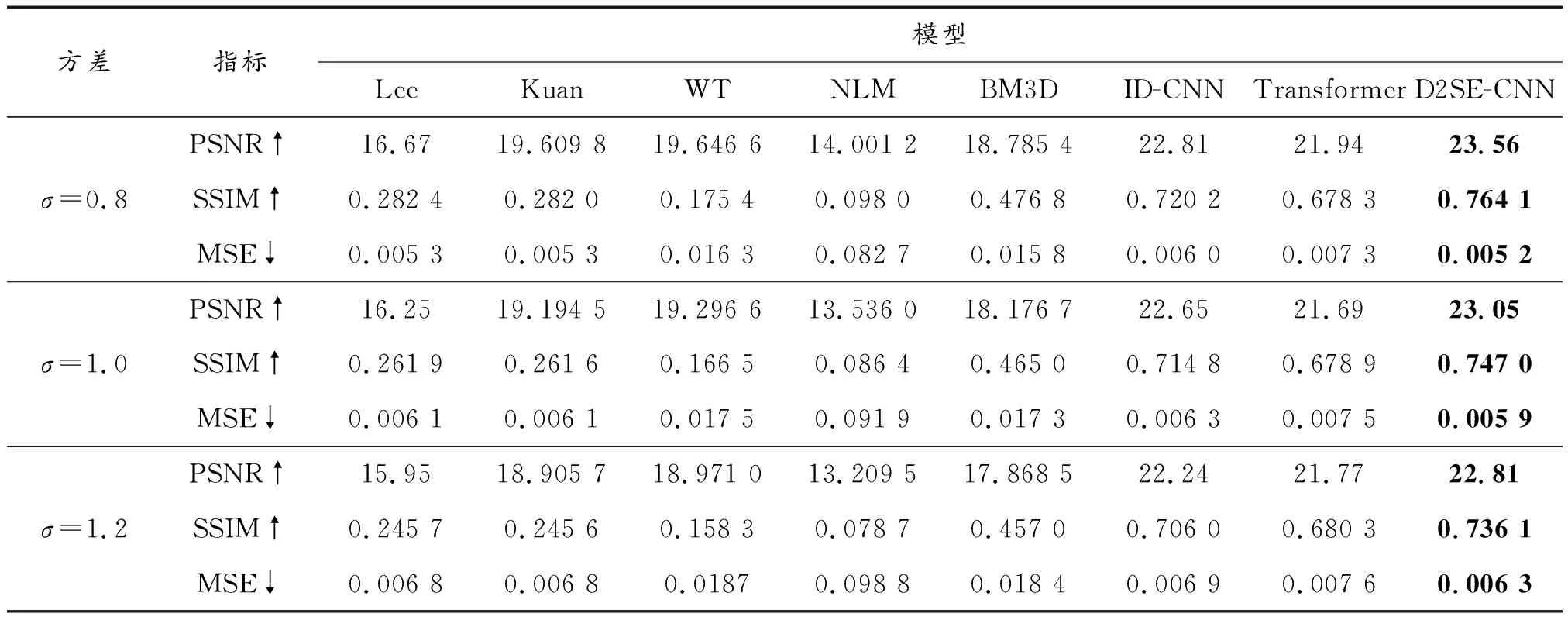
表3 数据集BSD500上不同模型评价指标差异
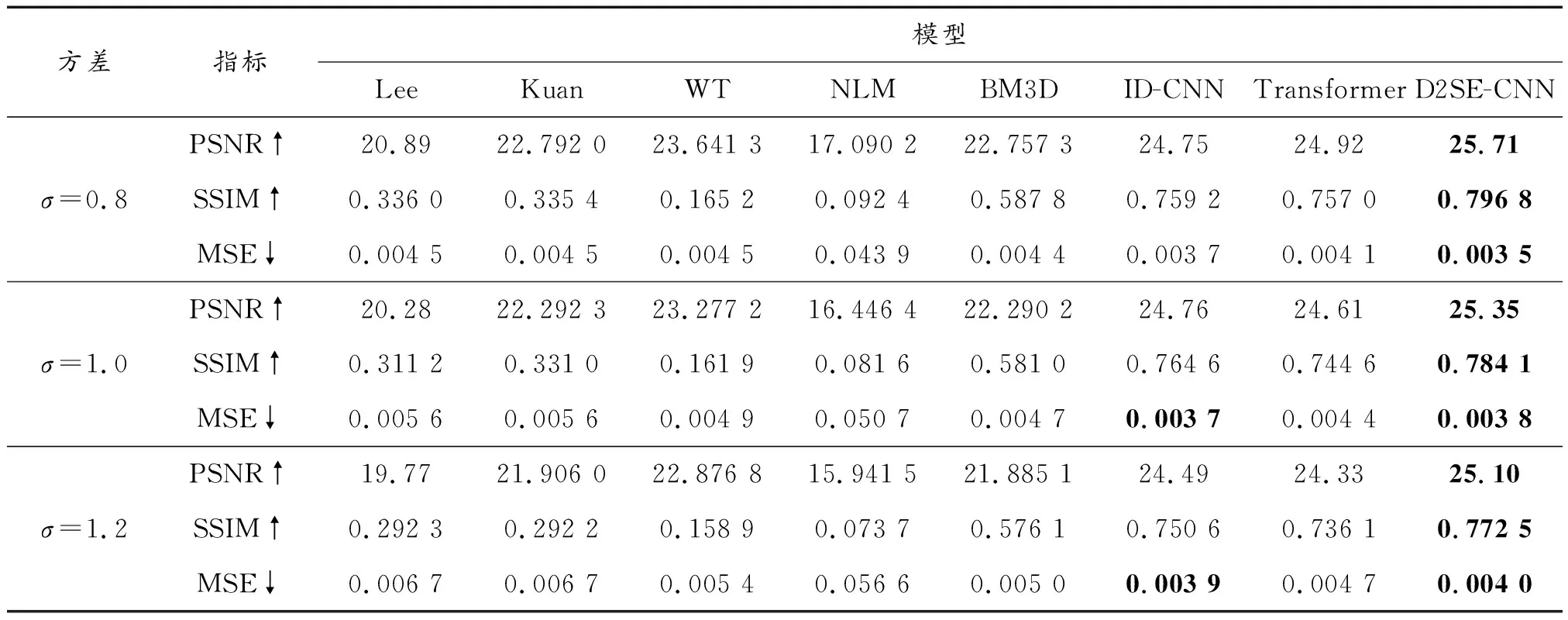
表4 数据集NWPUVHR-10上不同模型评价指标差异
对于所有比较的方法,参数都按照相应论文中的建议进行设置,图像乘性噪声方差分别为0.8、1.0以及1.2。在评估图像质量方面,采用峰值信噪比(PSNR)、结构相似指数(SSIM)、均方误差(MSE)来衡量不同方法的去噪性能。峰值信噪比(PSNR)用来衡量去噪图像与真值图像之间的差异的指标,数值越高越好。结构相似指数(SSIM)是一种衡量2幅图像相似度的指标,数值越高越好。
每个噪声级别的最佳指标结果均以红色粗体突出显示,次优指标加粗显示。从表3和表4中可以看出,在不同的噪声强度下,D2SE-CNN在PSNR和SSIM方面优于ID-CNN、变压器(Transformer)算法,也优于其他的传统方法,MSE指标也取得最优或次优的结果。
选取噪声方差为1.2时,本文算法与其他7中算法的去噪效果对比如图6和图7所示。其中图6来自BSD500数据集,图7来自于NWPUVHR-10数据集。从图中可以看出,本文算法在图像的平滑性和边缘保持上都具有更好的效果。
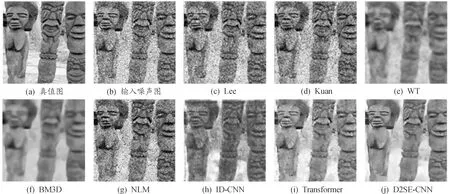
图6 BSD500数据集中不同算法的实验效果图,σ=1.2

图7 NWPUVHR-10数据集中不同算法的实验效果图,σ=1.2
4.4 真实雷达图像的结果
除此之外,在真实SAR图像[30]上也进行了实验对比。测试图像由2个真实的SAR图像组成,大小均为512×512。测试场景不是训练场景的一部分,但与它们相似。在测试过程中,不进行图像裁剪和缩放,而是将整个图片作为输入,从而得到预测输出。由于真实的SAR图像没有干净的真值,因此使用等效外观数(ENL)和变异系数(Cv)来衡量不同的图像去噪方法的性能。ENL值是从匀质区域估计的(如图8真实SAR图像中的红框所示,第一张SAR图片中的匀质区域为Region1、Region2,第二张SAR图片中的匀质区域为Region3、Region4),是匀质区域的平均值与方差比值的平方,而Cv值是匀质区域的标准差与平均强度的比值。

图8 真实SAR图像上不同去噪算法效果

图9 真实SAR图像上4个区域块的细节
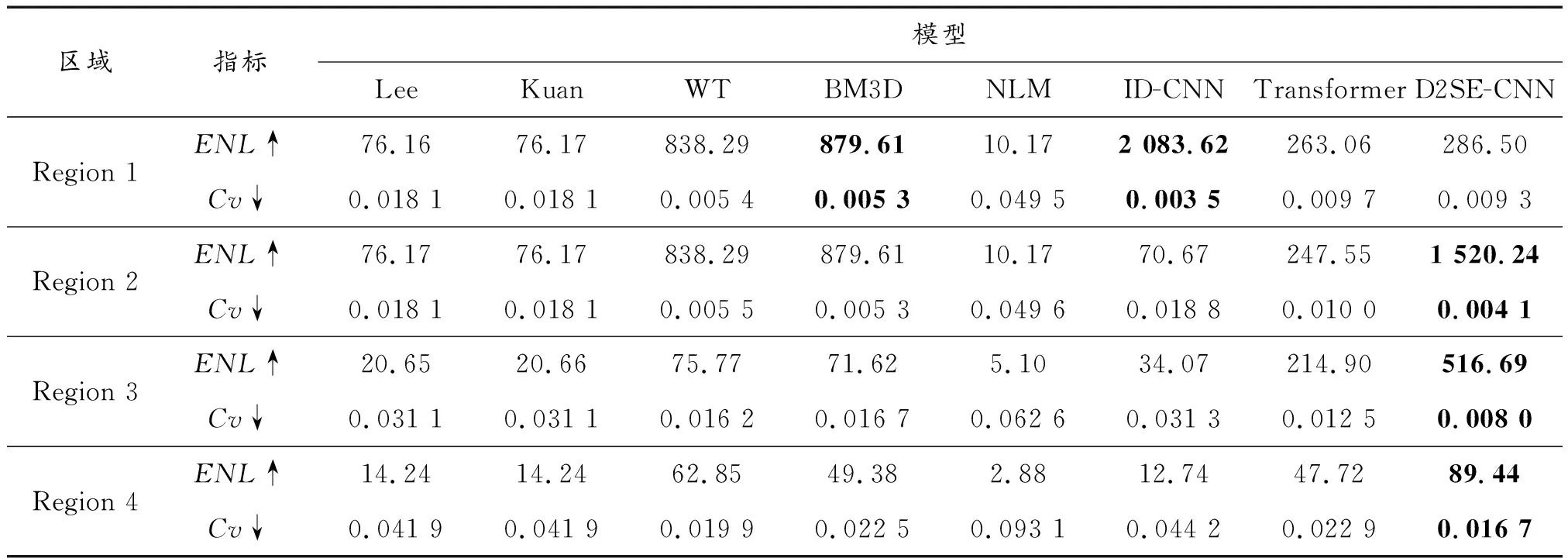
表5 真实雷达图像和评价结果
图8和图9显示了较好的五种方法NLM、BM3D、ID-CNN、Transformer和本文算法在真实SAR图像上处理的结果。从图中可以看出,对于真实的SAR图像,在BM3D算法的平滑效果最好,但是图像的纹理也同时被平滑了。基于深度学习的算法在不仅能够对噪声进行平滑,同时可以较好的保留纹理特征。本文提出的D2SE-CNN处理结果,不仅具有较好的平滑性和纹理保持,同时具有较为清晰的边界特征。
表5为具体的真实SAR客观评价结果。ENL值越高表明去噪效果越好,而Cv值越低表明能够更好的保存图片的纹理,最好的结果用红色粗体突出显示。从表5可以看出D2SE-CNN在所有4个匀质块上,对于相干斑噪声的抑制具有最优的综合效果。
5 结论
基于ID-CNN模型,本文提出的改进新模型D2SE-CNN,在网络的结构设计中使用下采样来提高训练效率,同时增大感受野;增加注意力机制重新校准通道的权重。在BSD50和NWPUVHR-10数据集上,对不同噪声强度的图像进行了实验对比分析,同时也在真实SAR图像上进行了验证。综合实验结果表明,该模型不需要输入噪声图像,也可以有效地实现SAR图像增强。D2SE-CNN模型无论在灵活性、效率和有效性上都有一定优势,为后续的雷达解译提供了实用的解决方案。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
安阳工学院学报(2020年4期)2020-09-11
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2018年1期)2018-04-20
中国校外教育(下旬)(2017年8期)2017-10-30
自动化学报(2016年3期)2016-08-23
共产党员(辽宁)(2015年2期)2015-12-06
