
基于Q-Learning算法的能量获取传感网络自适应监测能效优化方法
2022-12-18 07:19卞佩伦包学才谭文群康忠祥
南昌工程学院学报 2022年4期
卞佩伦,包学才,谭文群,康忠祥
(南昌工程学院 1.信息工程学院;2.江西省水信息协同感知与智能处理重点实验室,江西 南昌 330099)
生态环境监测是生态文明建设的基础,当前图像监测已成为促进治理生态环境的重要技术手段。但由于图像监测的能量消耗大,传统基于有限容量电池供电的监测传感网络时常造成图像监测中断,而对于偏远地区,频繁更换电池人工成本高且不切实际,如何解决偏远地区持续性图像监测是目前需要解决的重要问题之一。近年来,基于外部获取能量(如太阳能、风能等)的能量获取传感网络技术为偏远地区图像监测提供了解决方案。然而,太阳能获取随气候环境变化,能量到达具有一定的随机动态特性,导致传统基于固定电池供电的传感网络优化方法不适用于能量获取传感网络。因此,提出有效的能量获取传感网络自适应能量管理技术对解决偏远地区持续性图像监测具有重要作用和意义。
目前,国内外许多学者针对上述能效优化问题提出了许多创新的解决方案。文献[1]以最小化非目标接收基站的平均旁瓣幅值为优化目标,提出了基于改进蚁群算法的图像压缩传输波束成形节点选择算法,提出算法中的启发函数不仅考虑到获取能量和图像压缩中的传输能量,而且在信息素更新公式中也结合剩余能量和非目标接收基站的平均旁瓣性能,从而进一步改善传感网络中图像监测与压缩传输中的能效性能。文献[2]在各类经典路由协议的基础上,综合考虑到节点的密集程度以及能量平衡等因素,提出了一种基于能量供给的分簇单跳路由协议,旨在平衡传感网络中的能量消耗,从而延长网络的寿命。文献[3]提出的REC算法通过采用动态分区的方法来降低重新成簇所造成的能量损耗,从而提升数据传输效率和网络生存周期。文献[4]基于网络节点的角色划分,采用了一种多跳分层路由方案来平衡每个节点的能耗以传输图像。而文献[5]从网络拥塞的角度出发,考虑到簇头节点的最大利用率,提出了一种基于簇结构的路由协议,通过平衡每个簇的节点数量,从而减少网络中可能出现的拥塞并降低能耗。除却路由协议自身的创新,越来越多的研究人员在开始采用强化学习来优化传感节点的能量管理,并基于仿真实现了一定的结果。文献[6]采用由电池供电的传感器来指导强化学习系统采取相关操作,其方案运用基于固定策略的SARSA算法研究天气、电池退化和硬件对系统的影响。文献[7]和文献[8]则是将强化学习用于维持永久运行并满足能量收集型传感器的吞吐量需求。文献[9]采用强化学习来优化能量收集节点的采样工作,但是,这一算法是针对室内环境下构建和测试的,该环境在一天中的光照强度基本保持一致且富有规律性。文献[10]则是基于5个传感器节点在5 d内收集的数据来优化能效,但是,其设计的奖励函数不取决于电池电量或消耗的能量,因此无法捕获实际情况。文献[11]提出了RLMAN系统,该系统采用了具有线性函数逼近作用的actor-critic算法,并使用现有的室内和室外光照数据进行模拟,但并未说明其内存和计算要求。
由上述研究分析可知,当前研究主要针对无线传感网络中节点的能量管理问题,提出了各类能效优化方案和路由改进协议,但在环境模拟方面,还存在一定的局限性,主要体现在两个方面:一是对太阳能获取量白天昼夜交替考虑不足,忽略夜间的太阳能获取量几乎为零情况。二是对于连续长时间阴雨天气情况的优化性能也没有进行系统研究和分析,对保证持续有效的监测还需进一步分析。
为此,针对偏远地区的水生态环境图像监测需求,即昼夜以及连续长时间阴雨天气期间的持续有效监测,利用强化学习中的Q-Learning算法,设计有效奖励函数,力图提出针对不同季节不同气候环境下的能量获取传感网络自适应监测能效优化方法,方法基于时间差分预测,不仅实现学习速度更快,而且能快速寻找最优策略和最优动作值函数,从而实现监测的持续有效性和稳定性。
1 相关模型及问题描述
1.1 网络模型
目前传感网络主要以网状结构和簇结构模型为主,对于偏远区域水环境图像监测,监测区域需要内各节点之间的协同完成监测任务的特点,相比之下,基于簇的网络拓扑结构更适合区域多节点的管理和协作。因此,本文采用基于簇结构模型进行监测和传输建模。如图1所示,监测节点对周围水环境进行图像监测并将图片传输给周围的普通节点。之后,普通节点将监测图像进行压缩处理并传输给簇头节点。最后,簇头节点将收集到的压缩图像发送给基站,由基站进行评估与处理,性能评估主要基于3项指标,分别是平均效用、中断率以及能量溢出率,其中平均效用以长期的平均奖励值来近似表示。
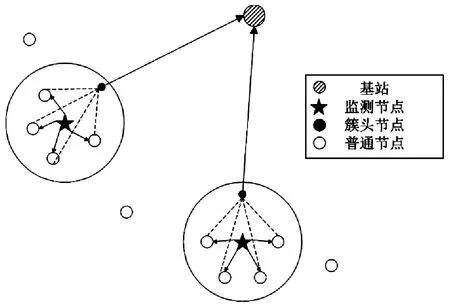
图1 网络模型
1.2 能量消耗模型
结合文献[12]提出的传感网络能量模型描述可知,传感节点监测与传输能量消耗主要由监测一次能耗、监测频率以及传输能耗等组成,具体如下所示:
EC=EM+ET,
(1)
EM=Em*Ms*Tm,
(2)
ET=ED*l.
(3)
式(1)中EC表示监测与传输的总能耗,EM表示监测能耗,ET表示传输能耗。式(2)基于文献[13]提出的能耗模型做出更改,其中Em代表节点每次监测所消耗的能量,为固定值,Ms表示每个时隙的监测次数,Tm代表监测所需的总时隙。所以,环境监测的总能耗基本与监测频率成正比,随着监测频率的提高,传感节点的能耗也会随之增大。而式(3)的传输能耗参考文献[14]和文献[15]提出的一阶无线通信模型,ED表示传输每比特数据所消耗的能量,l为比特数。而本文着重研究传感节点的监测优化,故总能耗近似为监测能耗。
1.3 能量获取模型
在本研究中,监测节点供电模块由蓄电池和太阳能电池板组成,节点可以根据这些太阳能板来获取能量为蓄电池充电,蓄电池通过能量管理芯片为监测节点提供能量。太阳能能量获取模型采用基于文献[15]提出的能量到达模型,如下式(4)所示:
EH=PS*SI*TS,
(4)
式中EH、PS分别表示获取的总能量和太阳能发电量,SI表示光照强度,TS表示持续时间。根据SANIO公司生产的太阳能电池板数据显示,发电量PS为0.23 μW/lux,则100 lux的光照持续600 s所产生的能量为13.8 MJ。所以,获取能量的多少主要取决于当前时间段的光照强度。
除此之外,能量获取与季节变换也存在一定联系。图2展示了南昌市太阳辐射强度的监测数据,假设3-5月代表春季,6-8月代表夏季,依此类推。则如图2所示,夏季的太阳辐射强度最高,即相对获取的能量最多,春秋两季近似,而冬季的太阳辐射强度最低,相对获取的能量也最少。
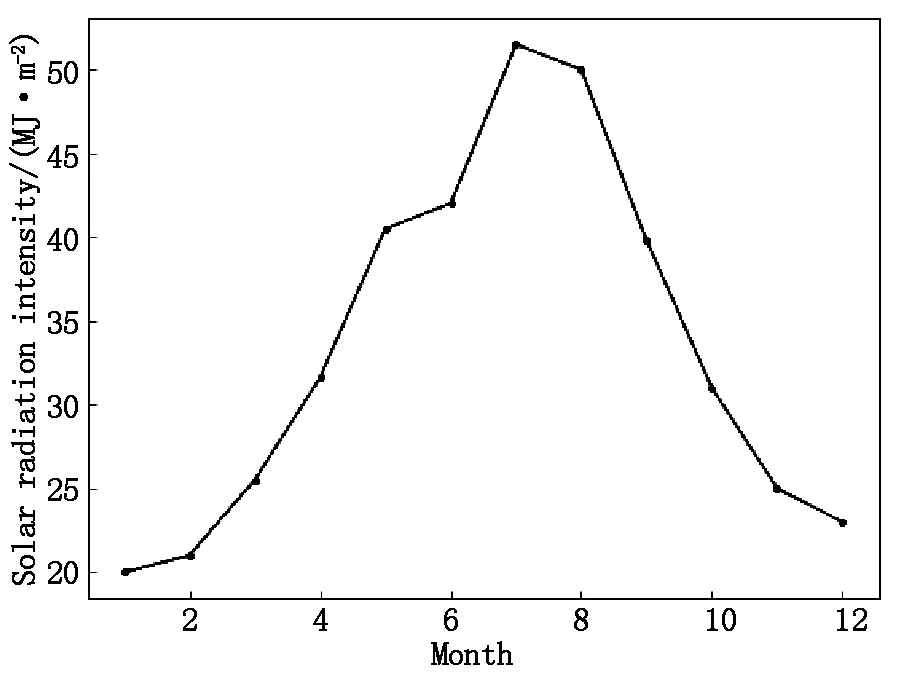
图2 太阳辐射强度监测数据
1.4 优化模型
本文在建立网络模型和能量模型的工作上,综合考虑了节点协作和能量均衡等因素,目的是为了改进不同季节不同气候环境下无线传感网络持续性长期监测的能量管理问题。但是,现阶段部分优化方案往往着重于改善当前时刻或时隙的能量优化管理,忽略传感网络的长期能效。因此,针对上述问题,本文提出了如式(5)~(9)所示的优化模型。
(5)
s.t.EH+ER-EC≤Ebc,
(6)
EH≥0,
(7)
0≤ER≤Ebc,
(8)
0≤EC≤ER.
(9)
式(5)表示优化目标为最大化一段时间内的累积奖励值,其中ri表示节点在时隙i时间段内监测所获得的即时奖励值;约束条件式(6)为节点获取能量与剩余能量的总和再减去监测能耗不超过当前节点的总电池容量,其中,EH表示节点的获取能量,ER表示节点当前剩余能量,EC表示节点图像监测一次的能耗,Ebc表示节点的总电池容量。
由上述优化问题可知,每个时隙的能量获取是随机动态到达,且优化目标是要T个时隙的长期效用,传统最优化方法难以解决此优化问题。但从现有文献[9]和[16]可知,目前强化学习中Q-Learning算法在解决长期效用方面取得很好效果。为此,在本研究中,将采用Q-Learning算法对能量获取条件下传感节点持续性监测的长期效用进行建模优化,进而实现昼夜以及长时间阴雨环境下的网络节点长期能效性能的同时,延长了整个网络的寿命。
2 基于Q-Learning算法的自适应监测能效优化方法
2.1 Q-Learning 算法原理
在一个典型的强化学习问题中,一个智能体开始处于一种状态s,通过选择一个动作a,它会收到即时奖励r并转移到一个新的状态s’,这一过程称为一个经验轨迹。不断循环此过程,直到在有限时间内达到最终状态。智能体在每种状态下选择动作的方式称为其策略π,如式(10)所示。智能体的目标就是基于经验轨迹学到的数据找到最优策略,以最大化长期奖励R。
(10)
对于每个给定的状态s和动作a,定义一个函数Qπ(s,a)称为动作值函数,该函数返回从状态s开始,采取动作a然后遵循给定的策略π直到最终状态所获得的累积奖励的估计值,如式(11)所示:
Qπ(s,a)=r0+γr1+γ2r2+γ3r3…,
(11)
其中γ≤1被称为折扣因子,它定义了未来奖励的重要性。值为0意味着只考虑短期奖励,值为1则更重视长期奖励。
由于Q-Learning算法是基于时间差分预测的强化学习算法,通过贝尔曼方程的递推重写以及时间差分预测的更新公式,就可以得到Q-Learning算法的更新公式,即整个算法的核心,如式(12)所示:
newQ(s,a)←Q(s,a)+α[r+γmaxQ′(s′,a′)-Q(s,a)].
(12)
从式(12)可以看出,除折扣因子γ外,Q-Learning算法还有一个重要的参数,即学习率α,它定义了一个旧的Q值将从新的Q值那里学到的新知识占自身的比重关系。值为0意味着代理不会学到任何东西,值为1意味着新发现的信息是更为重要的信息。
除此之外,本方案采用的Q-Learning算法遵循ε-贪婪策略,如式(13)所示:
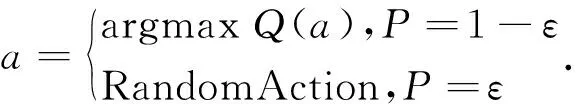
(13)
该策略的具体含义就是以ε的概率选择随机动作,否则以1-ε的概率在一定范围内选择使Q值最大的动作。
2.2 基于Q-Learning算法自适应监测能效优化方法
为解决监测能效优化问题,建立了基于Q-Learning算法的优化框架图(如图3所示)。图3中传感器节点通过太阳能电池板收集能量,然后对周围水环境进行图像监测并将相应数据发送到基站。基站基于设计Q-Learning算法优化策略,并根据节点所反馈的状态、环境等数据确定之后的监测频率,具体优化过程阐述如下:

图3 基于Q-Learning算法的通信框图
智能体:本方案中,智能体是负责与传感器节点通信的基站程序,它通过收集传感器节点监测到的图像数据,并向其输出相应的监测频率以此不断获取奖励并更新Q值表。
环境:本方案中的环境相当于与外部真实环境进行交互的传感器本身。其发送的数据主要包括光照强度(即获取到的能量)、天气、季节等。
状态:本方案中,状态设定为节点当前的剩余能量。这里对传感节点的最大储能进行离散化处理并由高到低依次缩放为N个能量单元,节点在每个时隙内进行一次监测就会消耗1个能量单元,当状态降至0时,传感节点的能量耗尽。离散化的作用在于减少了状态、动作空间,因此可以减少Q-Learning算法的收敛时间。
动作:传感器节点在每个时隙的时间段内都会进行一定次数的环境监测。因此,本文将每个时隙中的监测次数设置成相应的动作。假定共有A个动作,即{0,1,2,…,n,…,A-1},其中0表示节点进入休眠,n表示节点每个时隙监测n次。对于每个反馈到的动作指令,传感器会分配时隙供节点进行对应次数的环境监测,并且每次监测均会消耗1个能量单元。例如,动作2对应每个时隙的时间段内监测2次,即当前时隙内共消耗2个能量单元。
奖励:本方案中奖励函数的设定需要从两方面进行考虑:一是最大化传感器节点的动作选择,即通过尽可能提升每个时隙内的监测次数从而提高长期效用;二是最小化节点状态为0的情况,即尽量避免出现节点能量耗尽的情况来保证传感网络的正常工作。奖励函数的设置能够更好地优化节点的动作决策,而由2.3节可知,不同环境下的能量获取有所不同,节点的动作选择也会有一定区别,所以需要奖励函数对不同环境下的动作决策进行调节。本方案基于文献[16]提出的三段式能量管理策略对节点状态进行划分,用sigmoid曲线函数和墨西哥帽子曲线来定性地表示白天和夜晚两种环境下的奖励函数,并针对不同范围的能量状态设置了对应的奖励函数,以便节点做出最优选择。具体如式(14)~(16)所示:
(14)
(15)
(16)
式中a表示动作;s表示节点状态,即当前剩余能量;c和b分别代表对函数幅度和斜率的控制,参考文献[16],这里分别取2和1;EH表示节点的获取能量;Ebc表示节点的总电池容量;rc和rs都表示智能体在白天所获得的即时奖励值,其中,rc表示阴雨环境下所获得的即时奖励值,智能体会根据获取能量、剩余能量的占比等信息来获得不同大小的奖励值;rs表示晴天环境下所获得的即时奖励值,智能体所收到的奖励值大小主要依赖于获取能量以及动作等因素。而rn则表示夜晚环境下所获得的即时奖励值,评判标准仅依靠所选择的动作大小,动作越大,智能体最后得到的奖励值会相应降低,节点会收到负向反馈以节约能量。而当节点的状态s为0时,为了后期减少节点出现能量耗尽的状况,故还需要设置惩罚函数以协助节点对3种不同环境下的动作决策进行约束。式中rmax表示当前环境下最大的即时奖励值,因为惩罚函数的设定应该使得当前环境下,每个时隙内最大化监测次数所获得的即时奖励不超过监测中断所带来的损害。
根据上述优化过程以及设计奖励函数,设计了基于Q-Learning的自适应持续监测优化方法,步骤如下:
Step1:初始化Q值表为0,同时设置初始化状态s、动作a、即时奖励r、获取能量EH、总电池容量Ebc、季节W、气候C、时间T、折扣因子γ、学习率α、经验轨迹等相关参数。
Step2:设置贪婪系数ε∈(0.1,1),引用式(14),传感节点会遵循贪婪策略选择动作a。由于ε是处于0.1~1之间的参数,若初始化为1,该算法会在学习阶段选择随机动作;若初始化为0.1,其会更倾向于选择使得Q值最大的动作序列。
Step3:节点依据学习到的策略和自身的状态s在时间T内与环境进行交互。其中,白天和夜晚均会分配一定数量的时隙供节点进行监测。且每当昼夜交替时,气候C会依据当前季节W下的气候分布规律按照一定概率在晴天和阴雨天之间进行切换。具体操作如下:
若检测到当前环境为白天且自身状态s>0,首先判断所处气候,若C=1,即阴雨天,节点会选择某一动作a消耗对应能量得到下一状态s′,并根据式(14)收到即时奖励rc。若C=2,即晴天,节点则需要根据式(15)以获取即时奖励rs。
若检测到当前环境为夜晚且自身状态s>0,引用式(16),在选择完某一动作a消耗能量后得到下一状态s′和即时奖励rn。
若判断当前状态s=0,节点会强制进入休眠并受到惩罚,即时奖励r=-rmax。
Step4:引用式(12),利用交互得到的即时奖励r和新的节点状态s′对Q值表进行更新。其中,r+γmaxQ′(s′,a′)是采取动作a后得到的即时奖励r加上通过选择具有最高Q值的动作获得的奖励,而Q(s,a)是当前Q值表中状态动作对的值,它们之间的差值由学习因子α缩放。
Step5:能量获取。节点依据能量获取模型从环境获得能量EH,结合当前状态s′相加得到新的状态s″。
Step6:当前经验轨迹在时间到达最大值T后结束。新的经验轨迹中,节点初始状态s被赋予上一轨迹的最终状态s″。若经验轨迹未到达阈值,跳转至step2;反之算法结束。
3 仿真及性能评估
3.1 仿真环境及模型配置
为了验证基于Q-Learning的自适应监测能效优化算法的性能,本文从阴雨以及昼夜等环境下进行分析。由于目前针对阴雨以及昼夜交替环境下的长期持续性自适应算法较少,为验证提出算法能有效改善目前监测能效和提升监测持续性,下面将提出方法与传统监测节点随机选取监测次数方法(Random方法)以及基于文献[17]提到的贪婪算法的最大化监测次数方法(Greedy方法)进行比较。对比均基于相同能量收集的情况下进行,且分别从3个方面评判提出方法与其余两种方法的性能:平均效用、中断率和溢出率。
同时,本次实验基于python3.0仿真环境来评估整套方案。考虑到算法的收敛速度以及仿真结果的展示,在仿真之前需要对状态、动作以及能量获取进行离散化设置。首先将节点状态s设定为0~72共73个能量单元,即电池总容量Ebc;动作a设定为0~3共4个动作,即节点每个时隙监测0~3次;每个时隙设定为1 h,且系统会在白天和夜晚平均分配共16个时隙供节点进行监测。而在能量获取方面,由于晴天的实际室外光照强度较大,故所获取的能量区间EH为3~6个能量单元;阴雨天的实际室外光照强度较小,故所获取的能量区间EH为0~2个能量单元;而夜晚几乎没有光照,故所获取的能量单元EH设置为0。最后,表1列出了本次仿真所需要的其他相关参数。
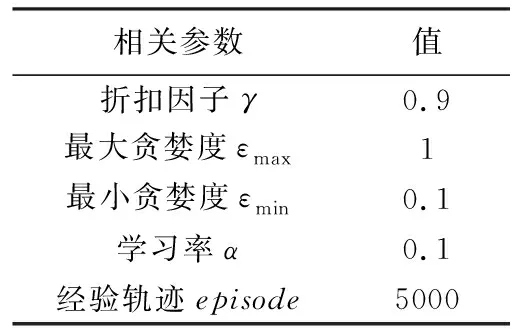
表1 仿真参数设置
下面将结合阴雨环境和昼夜交替环境对3种算法的性能进行对比分析,具体如下。
3.2 综合对比与结果分析
按照上述仿真环境,模拟阴雨天气以及昼夜交替的环境特点,研究基于Q-Learning的能效优化算法配置下的传感节点在阴雨天气占比不同的情况下其状态和动作变化过程,并结合其他算法分析其性能优势。其中,为了着重研究恶劣天气下的算法性能,故不会出现阴雨天气占比较低的情况。
3.2.1 阴雨天气占比70%情况下基于Q-Learning的能效优化算法性能及对比分析
在阴雨天气占比约70%的情况下,图4是基于Q-Learning的能效优化算法经过15 d的节点状态-动作仿真图,季节设置为雨季分布更为密集的春季。如图4所示,图中的3类曲线分别代表离散化后的获取能量EH、节点状态s和动作a这3项要素。在这15 d时间里,由于大概率阴雨环境下能量获取相对匮乏,传感节点在动作的选择方面需要考虑到最大化节点长期效用与最小化能量耗尽情况的总体目标。所以在初期,节点剩余能量充足,倾向于选择高能耗动作以获取更高的奖励值。随着天数递增,剩余能量逐渐减少,节点会根据奖励函数的反馈来优化自身的动作选择,在保证白天能够稳定工作的情况下尽可能减小监测次数以避免能量耗尽,从而使得夜晚环境下节点依然拥有充足的能量来维持环境监测,剩余能量匮乏的情况也会得到相应改善,说明了基于Q-Learning的算法在提升节点的长期效用的同时也有利于维持节点的长期生存。
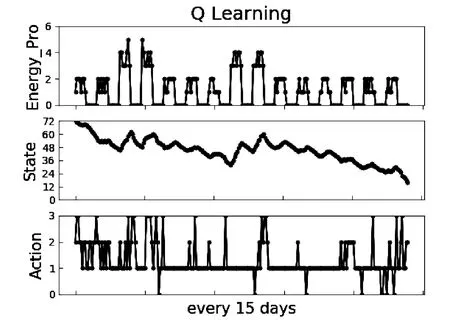
图4 混合环境下的节点状态-动作图(15 d)
为了进一步验证基于Q-Learning的能效优化算法在平均效用、中断率以及溢出率三方面的性能表现,故基于相同环境并结合上一节提到的两种方法进行对比,结果如图4所示。总时间设置为150 d,每15 d计算并统计10次数值取平均。

图5 三种算法的性能指标对比(混合环境)
首先,在平均效用方面,由于Q-Learning擅长考虑序列问题和长期回报,从而提升节点长期效用。所以,如图5(a)所示,基于Q-Learning的能效优化算法配置下的节点效用能够大幅度领先其余两种方法,并一直稳定在0.8左右。其次,在中断率方面,由于Q-Learning对环境具有强大的适应能力,能够及时调整节点的工作模式。所以,在保证可用能量足够的情况下,如图5(b)所示,优化后的节点中断率对比其余两种方法有明显的降低,并一直稳定于5%以下,这说明基于Q-Learning的能效优化算法能够有效延长传感网络的生命周期。最后,在溢出率方面,从图5(c)可以看出,由于Greedy方法擅长最大化监测次数来提升短期效用,所以节点几乎不会出现剩余能量溢出的情况。而本文提出的方案在保证节点能量耗尽的前提下,同样能够自适应调整动作能级来消耗多余的可用能量。

图6 混合环境下的节点状态-动作图(15 d)
3.2.2 阴雨天气占比50%情况下基于Q-Learning的能效优化算法性能及对比分析
在阴雨天气占比约50%的情况下,图6是基于Q-Learning的能效优化算法经过15 d的节点状态-动作仿真图,季节设置为雨季分布相对平均的夏季。如图6所示,当晴天与阴雨天气下逐渐持平时,节点的能量获取会相应得到改善,传感节点在动作的选择对比上一节会更加灵活,在总体保持低能耗监测的基础上,会更倾向于选择较高能耗的动作以获得更多奖励值。除此之外,节点进入休眠状态的次数对比上一节也明显降低,其剩余能量水平也一直较为充足,同样验证了基于Q-Learning的能效优化算法能够有效维持传感网络的持续监测和长期生存。
为了进一步验证在阴雨天气占比约50%的环境下,基于Q-Learning的能效优化算法在平均效用、中断率以及溢出率三方面的性能表现。同样地,结合之前提到的两种方法进行对比,结果如图7所示。

图7 三种算法的性能指标对比(混合环境)
首先,在平均效用方面,如图7(a)所示,本方案优化后的节点效用依然能够在一定程度上领先其余两种方法,并于1.2上下浮动。其次,在中断率方面,由于仿真环境发生变化,可用能量相对充足,如图7(b)所示,优化后的节点中断率几乎为0,只会偶尔出现监测中断的情况。最后,在溢出率方面,与之前相似,基于Q-Learning的能效优化算法能够通过自适应调节动作能级以规避长时间能量溢出的情况。
综合来看,仿真实验分别从平均效用、中断率与能量溢出这三个方面对提出的方案和另外两种方法进行对比,从仿真结果可以看出,本方案基于Q-Learning算法能够有效适应复杂多变的环境,从而调整节点的动作决策,平衡节点能效,在满足能量最大化利用的同时显著延长了网络的生命周期,保证了太阳能获取传感网络的可持续运行。
4 结束语
实现水环境图像持续性监测是偏远地区迫切需求解决的关键问题,也是实现生态环境保护的基础。本文提出了一种基于Q-Learning算法的能量获取传感网络自适应监测能效优化方案,该方案在簇结构网络的基础上结合Q-Learning算法,利用获取到的能量特性来自适应调整节点的图像监测频率。通过设置大概率阴雨环境和昼夜交替结合下的混合监测环境,对提出方法进行验证对比分析,仿真结果表明基于Q-Learning算法配置的节点学会了如何适应变化的天气和日夜交替环境下的自适应监测,对通过与随机选取监测频率和基于贪婪算法的最大化监测频率两种策略的对比分析,在平均效用、中断率以及能量溢出率等方面,提出方法性能均优于后两种策略。特别在昼夜交替的环境下,考虑到阴雨天气和夜晚环境下光照匮乏,对比另外两种策略,能够大幅减少监测中断率,且保证传感节点长期生存。
猜你喜欢
传感技术学报(2022年7期)2022-10-19
今日农业(2022年15期)2022-09-20
锦绣·上旬刊(2022年2期)2022-05-16
防爆电机(2021年3期)2021-07-21
杂文选刊(2021年1期)2021-01-13
家用电器(2019年6期)2019-09-10
分析化学(2017年12期)2017-12-25
分析化学(2017年12期)2017-12-25
中华诗词(2017年4期)2017-11-10
都市丽人(2015年2期)2015-03-20
