
面向移动端的目标检测优化研究
2022-12-22 11:45韩晶晶刘江越公维军魏宏杨钱育蓉
计算机工程与应用 2022年24期
韩晶晶,刘江越,公维军,魏宏杨,钱育蓉
1.新疆大学 信号检测与处理重点实验室,乌鲁木齐 830046
2.新疆大学 软件学院,乌鲁木齐 830091
3.新疆大学 信息科学与工程学院,乌鲁木齐 830046
4.乌鲁木齐职业大学 实训中心,乌鲁木齐 830004
5.新疆大学 软件工程重点实验室,乌鲁木齐 830000
目前,受益于计算机运算性能的提升、神经网络模型的发展以及便捷的数据获取方式,目标检测技术在人脸识别[1]、智能监控、自动驾驶、游戏娱乐等领域都取得了突破性进展。小到日常的衣食住行,大到批量化工业生产,目标检测技术带来的影响无处不在[2]。目标检测已不满足于仅在云端进行复杂数据运算和推理,逐渐开始向有实时检测需求的移动端迁移,如智能手机、车载电脑、智能传感器等。
目标检测采用的深度神经网络[3](deep neural net‐works,DNN)虽然赋予了网络从大量数据中学习更高级特征的能力,但也使得检测模型结构越来越复杂,对硬件设备的运算能力和存储空间的依赖愈发严重[4]。因此,如何在保持模型较高精度的前提下对目标检测进行优化,降低其内存需求和计算成本,已成为将目标检测向移动端迁移时首当其冲的一大课题。
近些年来,在目标检测优化领域各种优化算法层出不穷,除了不同的解决思路外,每条解决思路也蕴含着无数种方案[5],这对移动端目标检测优化研究具有极大的借鉴意义。由此,本文从算法角度介绍了适用于移动端的目标检测优化方法,并对相关方法进行了分析,主要贡献可归纳如下:
(l)从卷积结构的设计入手,阐述了基于手工和AutoML的目标检测网络轻量化方法,并借助参数量、精度、时延等指标进行了性能对比。
(2)从压缩手段入手,按照压缩方法的不同阐述了三种目标检测模型压缩方法,并从不同维度讨论了每种压缩方法的特点与不足。
(3)从市场角度阐述了国内移动端目标检测的产业化现状,并就该领域优化研究的潜在问题和发展方向展开了讨论,为后续研究提供参考。
1目 标检测的研究现状及优化方向
1.1 目标检测的研究现状
纵观近年来的研究成果,目标检测主要有两个研究思路:一是手工提取特征,二是利用卷积网络自动提取特征。在深度学习出现之前,研究人员通常借助特征提取器手动进行特征提取以解决此类问题,但这些手工方法普遍操作繁琐且难以解决复杂的非线性映射问题。其后,Hinton等人[6]提出了深度学习这一机器学习的分支算法,引入多层映射的概念,极大地推动了目标检测的发展,在神经网络普遍不被看好的年代将这一技术带进了主流学术界。
基于手工提取特征的目标检测方法高度依赖于特定领域的先验知识,常见的特征有Haar[7]、SIFT[8]、LBP[9]、PCA-SIFT[10]、SURF[11]等,如图1所示。2004年,Viola和Jones[12]基于AdaBoost[13]借助Haar-like特征提出了影响深远的人脸检测器(V&J)。2005年,Dalal和Triggs[14]提出了基于支持向量机[15]统计局部图像的梯度方向信息的梯度直方图(histogram of oriented gradient,HOG)。2010年,Felzenszwalb等人[16]通过研究HOG特征提出使用可形变模型[17](deformable part model,DPM)解决物体形变问题,后续又提出了利用级联分类器[18]来加速检测的研究[19]。传统的检测方法主要依靠滑动窗口遍历来确定目标位置,时间复杂度与操作冗余度较高,且特征提取的鲁棒性较差,极易导致检测性能下降。随着深度学习理论的完善,传统检测算法逐渐被取代,但其滑动窗口等先进理论仍被保留了下来。
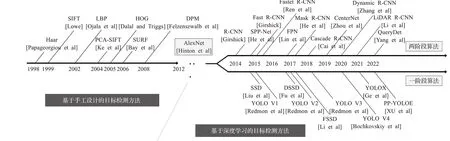
图1 目标检测方法的发展里程碑Fig.1 Development milestones of object detection methods
20世纪60年代,Hubel和Wiesel通过研究猫的视觉皮层提出了感受野的概念。此后,日本学者Fukushima基于感受野的概念提出了神经认知机,首次实现了利用卷积神经网络识别简单的图像,自此神经网络的思想逐步成熟。1998年,Krizhevsky等人[20]尝试将神经网络用于图像处理,但受到计算性能的制约而陷入了瓶颈。2012年,Hinton等人[21]在ImageNet比赛中提出了特征提取能力较强的AlexNet网络,卷积神经网络自此成为目标检测领域的核心算法。2015年,He等人[22]使用残差结构解决深度学习中的过拟合问题,使得卷积神经网络在目标检测任务中的优势愈加明显。经过长期发展,基于深度学习的目标检测方法逐渐衍生出两个流派:(1)R-CNN系列的两阶段算法;(2)YOLO系列、SSD系列的一阶段算法。
1.1.1 两阶段目标检测算法
最初被广泛接受的两阶段目标检测算法是由Girshick等人提出的R-CNN[23],通过在网络中引入统一大小的候选框来搜索感兴趣的目标区域,但其对候选区域进行固定尺寸缩放的过程极易导致图像的信息缺失。针对此类问题,2014年He等人[24]为能够任意比例地提取特征提出了在网络卷积与全连接层间加入空间金字塔池化(spatial pyramid pooling,SPP)结构的SPP-Net网络。尽管SPP-Net相比传统CNN算法来说检测精准度有所提高,但其利用候选框提取并存储特征占用的空间较大。之后,结合R-CNN与SPP-Net的特性,Girshick等人[25]提出了Fast R-CNN,在网络最后一层采用对感兴趣区域(region of interest,RoI)池化代替SPP-Net的金字塔池化来获取固定尺寸的特征,但其网络结构高度依赖选择性搜索生成候选区,性能耗费依然较高。为解决该问题,Ren等人[26]提出使用区域生成网络(region pro‐posal network,RPN)来代替选择搜索算法的Faster RCNN,并且针对目标物体尺寸不一的问题在特征图上使用了不同形状、不同大小的选框(anchor box)机制,但其对小目标的检测效果并不理想。基于Faster R-CNN,Lin等人[27]提出了一种多尺度特征金字塔(feature pyra‐mid network,FPN)网络,实现了自顶向下的特征图融合,有效提升了其对多尺度待测目标的检测效果。之后,He等人[28]提出了使用RoI Align代替RoI Pooling的Mask R-CNN,使特征感受野与原图感受野信息对齐,在分割和检测领域均取得了性能提升。
在上述方法基础上,近些年还涌现出了大量的两阶段目标检测算法,如Cascade R-CNN[29]、PANet[30]、Cen‐terNet[31]、Dynamic R-CNN[32]、LiDAR R-CNN[33]、Sparse R-CNN[34]、QueryDet[35]等,效果如表1所示。两阶段算法均需预先生成所有可能包含待检物体的候选框,再进行位置修正与分类,大量地重复了检测与分类流程。虽然相较于手工提取特征的传统目标检测方法的检测精度有所提高,但其两阶段结构依然严重制约着检测速度的优化[36]。
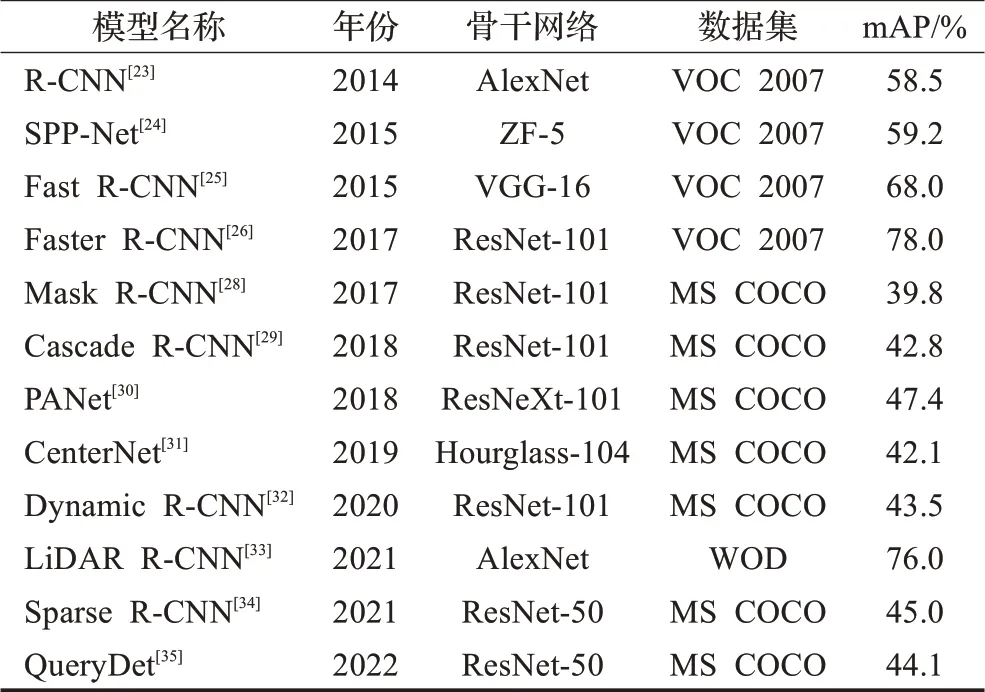
表1 经典两阶段目标检测算法Table 1 Classic two-stage object detection algorithms
1.1.2 一阶段目标检测算法
一阶段目标检测算法的训练相对简单,省去了两阶段方法中的区域建议及预分类流程,可直接得出物体位置与类别。2016年,Redmon等人[37]最先提出了一阶段目标检测算法(you only look once,YOLO),将输入的图像分割成多个网格来检测中心点落在其内的物体。YOLO的提出引起了学术界的极大关注,陆续出现了YOLO v2[38]、YOLO v3[39]、YOLO v4[40]、YOLO v5等改良模型。其中,YOLO v2采用k-means聚类算法对边界框进行聚类,并借助批量正则化和高分辨率分类器来平衡速度与精度。YOLO v3去除了池化层,使用更深层的骨干网络来提取图像特征,并且使用多标签分类以处理标签重叠的复杂数据。YOLO v4结合特征金字塔和聚合网络机制,借助Mish激活函数、Mosaic数据增强、DropBlock正则化等优化技巧获得了全方位性能提升。同年,Liu等人[41]结合YOLO检测速度和Faster R-CNN定位精度的优势提出了适于小目标物体检测的SSD模型。此后,DSSD[42]、FSSD[43]等基于SSD的模型陆续出现。其中,DSSD基于更深层的ResNet-101骨干网络进行特征提取,引入残差单元来优化检测分类,并借助反卷积模块进行特征图融合,在小目标检测上取得了性能提升。FSSD融合了SSD与特征金字塔的思想,将浅层的表象特征与高层的语义特征相融合,降低了重复检测同一目标或将多个目标检测为单个的概率。
除上述经典的一阶段目标检测算法外,近些年还涌现出了YOLOX[44]、YOLOF[45]、PP-YOLOE[46]等,效果如表2所示。一阶段算法不仅无须选框推荐,还可在同一阶段获取物体的位置与类别,在训练速度和推理速度上明显优于基于相同骨干网络训练的两阶段算法,常被用于移动端目标检测产品的落地。
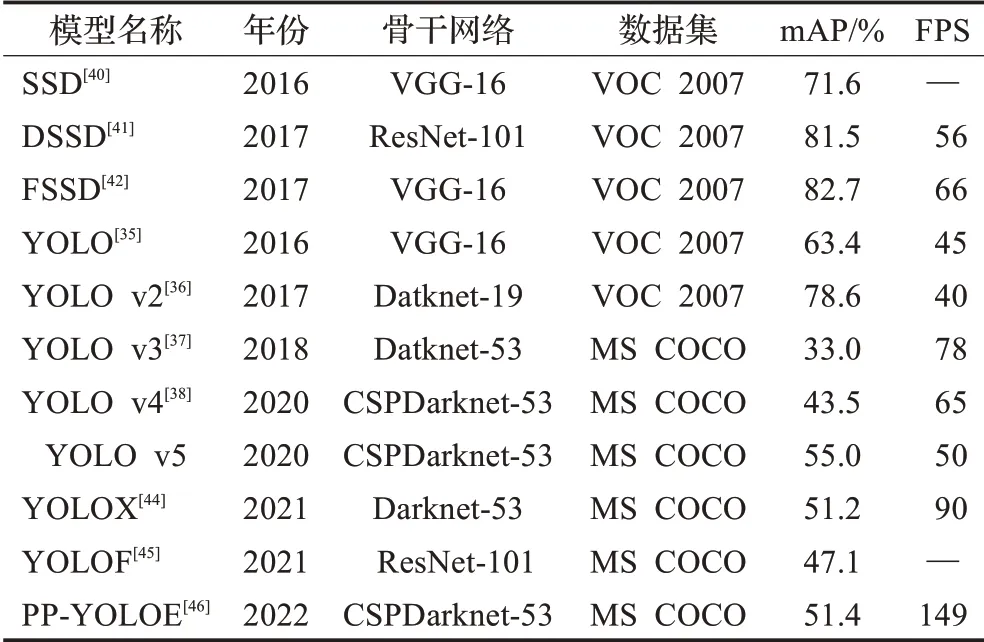
表2 经典一阶段目标检测算法Table 2 Classic one-stage object detection algorithms
1.2 目标检测的优化方向
在过去十几年间,目标检测技术已针对形变、遮挡[47]、光照、杂乱背景等挑战进行了大量的理论创新[48],并在智能安防、智慧城市、遥感侦测等目标检测任务上受到了热烈关注。然而,这些目标检测任务通常需要先在云端进行复杂的数据运算和模型推理,然后再将运算结果传输到移动端应用上,难以确保目标检测过程的实时性和推理结果传输的安全性。
为适应移动智能时代对实时目标检测的需求,大量研究学者针对现有的检测思路展开了优化研究。考虑到移动端设备的存储空间和算力有限,其优化方向可归结为以下两个角度(如图2所示):(1)采用轻量化思想在设计之初进行优化;(2)使用压缩手段对现有模型进行优化。其中,基于轻量化设计的优化方法可按其理论研究归结为手工设计和AutoML两类,将在本文第2章进行介绍;基于压缩的优化方法可按压缩手段的不同分为张量分解、模型剪枝和参数量化三类主要方法,将在本文第3章进行介绍。
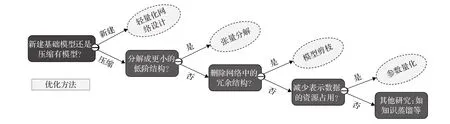
图2 目标检测方法的优化方向Fig.2 Optimization direction of target detection methods
2 基于轻量化设计的优化方法
轻量化设计是从根本上解决目标检测向移动端迁移时性能受限问题的手段之一,其基本思想是利用手工设计(如分组卷积(group convolution)、深度可分离卷积[49](depth-wise separable convolution,DSC)等)或自动化机器学习(如超参数优化、神经网络结构搜索[50](neural architecture search,NAS)等技术)在模型设计之初采用轻量化设计思想减少卷积运算量,降低模型训练与推理的环境需求。轻量化设计方法可按其研究理论分为两类:(1)基于手工设计的轻量化方法;(2)基于自动化机器学习的轻量化方法。
2.1 基于手工设计的轻量化方法
基于手工设计的轻量化方法需要人为针对卷积结构优化出更高效的网络从而减少参数量。2016年,由伯克利和斯坦福合作Iandola等人提出的SqueezeNet[51]模型大量采用1×1的卷积核替换3×3的结构对特征维度进行压缩。但该方法本质上还是使用更深的网络置换更少的参数量,推理时间反而被延长。
其后,Google团队的Howard等人[52]基于深度可分离卷积提出了适用于移动端的MobileNet系列轻量化模型。MobileNet V1使用深度可分离卷积来替换传统卷积核来提取特征,可将参数压缩为标准卷积的1/9,并且引入超参数来降低模型宽度,从而达到提升运算速度的目的。MobileNet V2[53]借鉴经典残差结构提出了先升维再降维的结构(inverted residual),并且引入线性瓶颈(linear bottleneck)以减少非线性层大量使用ReLU激活函数带来的损失。
同年,旷视科技Zhang等人[54]提出了基于分组卷积的轻量级网络(ShuffleNet),其核心是对组卷积得到的特征图采用通道变换(channel shuffle)进行打乱,有效对冲分组导致的组间特征信息不通的问题。2018年,Ma等人[55]基于上述研究提出了ShuffleNet V2,采用与输入特征通道数目相同的卷积核以及适量的组卷积来最小化资源占用,并且减少细碎的网络结构来增加数据并行,使得ShuffleNet V1输入输出维度不一、卷积分组数目过多等内存不友好的设计得到了改进。
但是手工设计的轻量化结构如组卷积、深度可分离卷积、通道变换等需要人为对模型大小、速度与准确度等指标进一步权衡,高度依赖基于手工设计的启发式搜索结构和基于规则的压缩策略,存在大量偶然的设计因素,因此难以得到搜索空间的最优解。
2.2 基于自动化机器学习的轻量化方法
基于AutoML的轻量化方法可以避免特征提取、模型选择与参数调整阶段的人工干预及偶然因素,将人工调整卷积的过程变为自动搜索最佳结构的过程。随着该领域神经网络结构搜索技术(NAS)研究的深入,基于此的轻量化网络逐渐被提出。NAS的基本流程是使用搜索策略在搜索空间内大量评估候选项,然后根据反馈不断搜罗满足条件的超参数来优化网络。
自此之后,基于神经网络结构搜索的轻量化网络设计在主流轻量化方法中占据明显优势。2018年,He等人[56]基于强化学习思想提出了自动化的轻量化压缩方法(automl for model compression,ACM),选用深度确定性策略梯度法(DDPG)确定网络的压缩比,通过限定约束值寻找最适用于当前硬件的方法。2019年,Google团队Howard等人[57]在MobileNet系列算法研究基础上,提出了一种利用NAS搜索最优配置的MobileNet V3,把基于硬件感知的网络架构搜索与NetAdapt算法相结合,采用互补方式来提高网络的整体效果,并且向残差中引入注意力机制的SE[58]结构。2019年,Tan等人[59]提出了依据设备的资源限制情况自动搜索最适宜网络结构的MnasNet,在搜索过程中采用移动设备进行模型推理以衡量最真实的延迟,对模型精度和延迟加以平衡以充分利用不同设备间的软硬件特性。2020年,Han等人[60]提出了Ghost模块,借助少量卷积核生成少量内在特征图,然后通过线性操作高效地生成Ghost特征图,并将其作为即插即用的组件来升级现有网络。2021年,Yu等人[61]意识到置换模块中重复使用的卷积结构是优化瓶颈,提出了Lite-HRNet网络,引入条件加权通道的轻量化单元来置换模块中计算代价昂贵的卷积结构,并从多个并行分支的学习信息权值,进行信息交换以补偿其带来的特征损失。2022年,字节跳动的Ma等人[62]基于Transformer提出了一种轻量化的移动卷积模型(MoCoViT),通过结合移动自注意力(mobile self-attention,MoSA)模块和移动前馈网络(mobile feed forward Net‐work,MoFFN)二者的优点,从而提高了在移动端运行时的性能和效率。
基于手工设计的轻量化方法高度依赖手工启发式搜索结构和基于规则的轻量化策略,其过程存在较多的偶然因素,难以直接得到最优解。而基于AutoML的轻量化设计则是借助强化学习来自动生成搜索空间,相较于传统方法有了质的提升,已成为目前主流的轻量化设计方法。为进一步总结剖析上述轻量化设计方法,表3列出了上述轻量化神经网络的模型机制、优点、局限性以及适用场景,表4详细展示了所涉及的轻量化神经网络在ImageNet数据集上的参数量、FLOPs、精度以及在安卓手机运行时的时延。
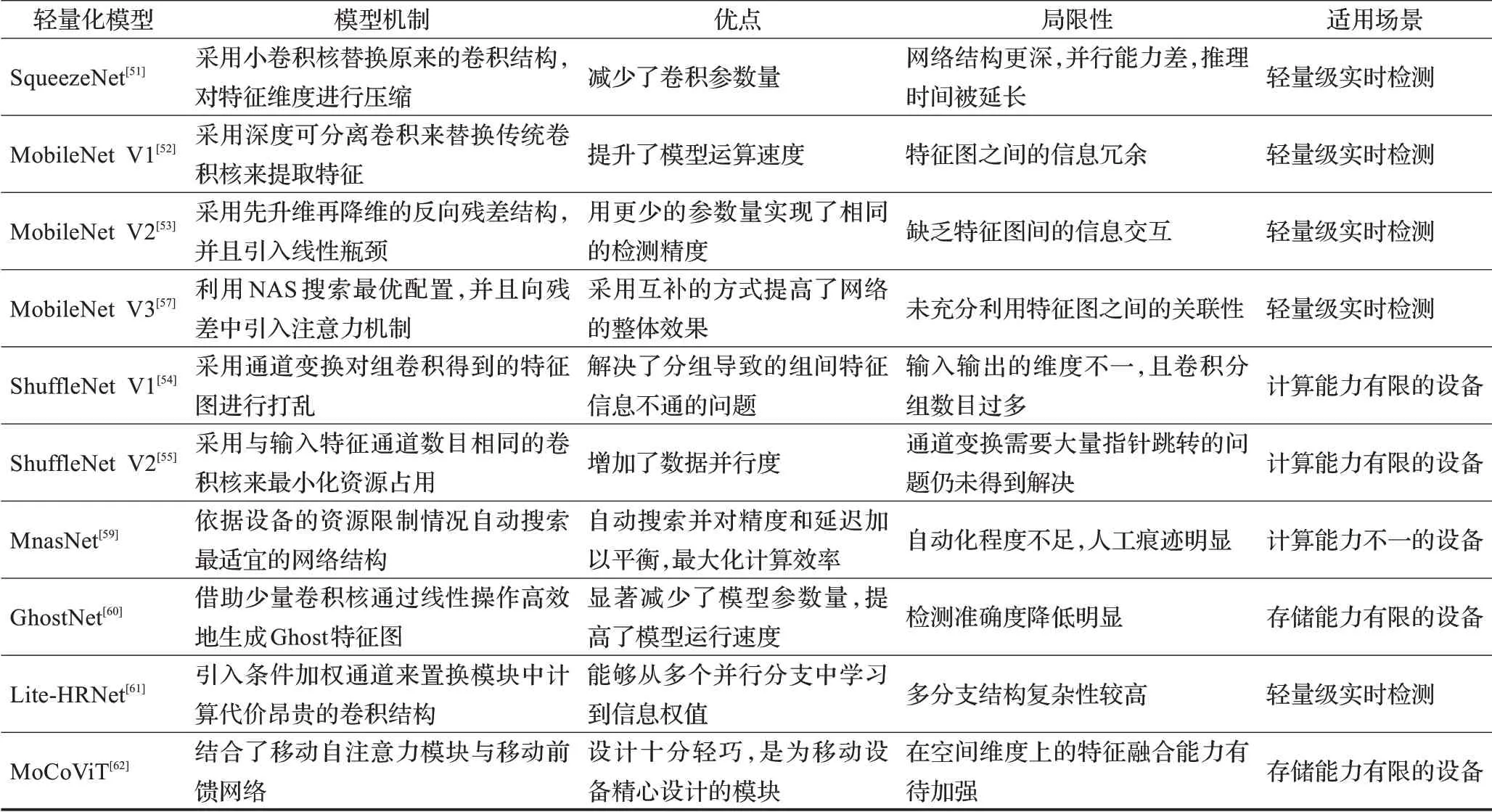
表3 轻量化神经网络对比Table 3 Comparison of lightweight neural networks
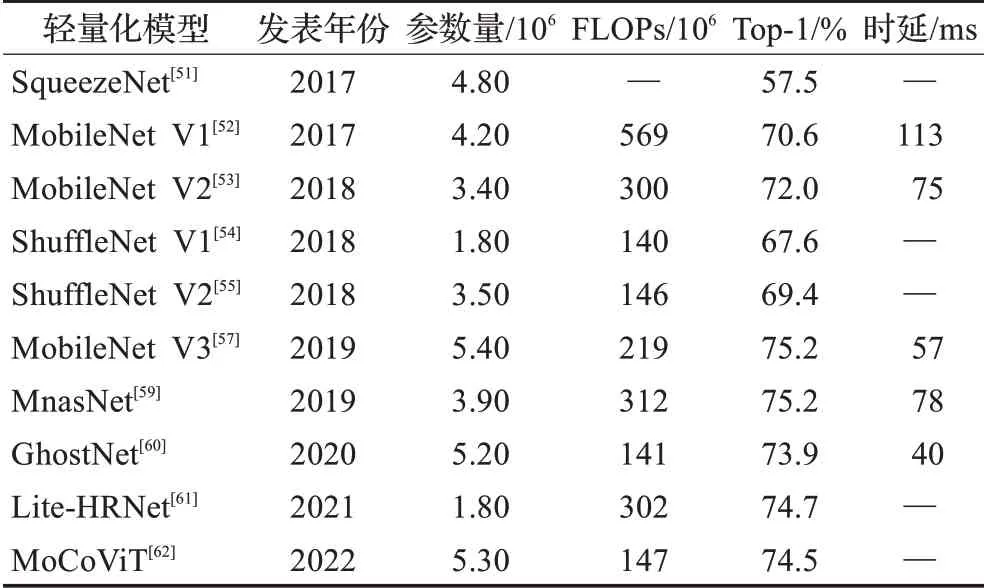
表4 基于ImageNet数据集的性能对比Table 4 Performance comparison based on ImageNet dataset
优势:基于轻量化设计的优化方法从根本上解决了资源有限的移动端环境对目标检测的性能制约,可以有效地减少网络参数、降低运行时延,对进一步提高目标检测方法的实时检测与处理性能至关重要,且具有轻量化、易部署、高性能等优势,适用于自动驾驶或汽车辅助驾驶等对实时性要求较高的任务。
局限性:基于轻量化设计的优化方法需要网络设计者具备较高的专业素养和娴熟的网络设计经验,设计难度较高且不易与其他优化方法结合使用。其中,基于手工设计的轻量化过程存在较多偶然因素,难以直接得到最优解,而基于AutoML的轻量化方法并非完全自行设计网络架构,人工痕迹太过明显,需要朝着更广泛的搜索空间和更高的自由度发展。
3 基于压缩的优化方法
基于压缩的优化方法常常在卷积层和全连接层借助张量分解、剪枝、量化等手段进行模型调整,其核心在于如何减少参数的内存占用和计算成本。通俗来讲,如果将网络中的原始张量拆分成更小的张量结构则称为张量分解;如果将原始网络中冗余的信息删除则称为模型剪枝;如果将原始网络的参数用更小的位宽表示则称为数据量化。考虑到不同压缩方法的发展规律不同且彼此之间有所关联,下文按照每种方法的特性采取了不同的介绍思路。
3.1 张量分解
数据的高维特征使得计算的时间和空间复杂度急剧增加。张量运算作为神经网络的基本计算单元,贡献了网络中绝大多数的计算任务,因此对张量进行分解可有效促进模型的压缩与加速。张量分解作为压缩高维数据的常用方法,其基本思想是利用多个低阶结构替换一个高阶结构,通过合并维数和施加低秩约束来稀疏化卷积矩阵。例如,滤波器就可看作一个四维张量,其权值主要分布在一些低秩子空间内,可以借助稀疏化矩阵进行信息删减。
张量分解存在多种分解方式,其中较为经典的分解方法有CP分解、Tucker分解[63]、SVD分解[64]、TT分解[65]和TR分解[66],其异同点和优缺点分析如表5所示。1927年,Hitchcock等人首次提出CP分解法(canonical poly‐adic decomposition,CP),将张量分解为多个秩为1的张量和。1966年,Tucker等人提出Tucker分解法,将张量分解为一个核张量与多个因子矩阵的线性乘积。1980年,Kilmer等人为了尽量保留张量的内在结构信息提出了奇异值(SVD)分解法,将张量分解为多个正交张量与其对角张量的乘积。从上述分解方法的原理来看(如图3所示),CP分解可以看作Tucker分解的一个特例,SVD分解是对CP分解和Tucker分解的高阶扩展。

表5 张量分解方法对比Table 5 Comparison of tensor decomposition methods
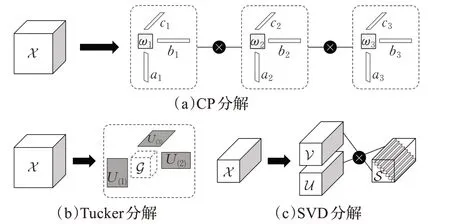
图3 三阶张量的分解Fig.3 Decomposition of third-order tensors
随着张量分解理论研究的成熟,许多分解方法被应用于目标检测。2014年,Denton等人[67]基于SVD分解提出了一种对网络中参数矩阵进行降维分解的方法,该方法依据奇异值对模型维度进行截断选择,以精度损失为代价获得了速度提升。2015年,Novikov等人[65]基于张量链分解(tensor train,TT)提出了将全连接层的权重矩阵转换为张量链的形式进行分解的分解方法,减少了参数的存储空间,类似的还有Garipov等人[68]对张量链分解的研究。
近年来,基于卷积神经网络对张量分解进行跨领域融合的研究取得了跨越式进展[69]。Chien等人[70]基于Tucker分解在全连接层使用伪逆矩阵的模积来表示权重,并将整个分解过程进行封装,类似的还有Huang等人[71]的研究。Chen等人[72]结合Tucker分解与CP分解的优点提出了一种引入块项分解[73](block term decompo‐sition,BTD)的残差结构(collective residual unit,CRU),通过在残差单元上共享张量分解的核心因子来提高残差网络的参数利用率并降低过拟合风险。2021年,加利福尼亚大学的Cai等人[74]基于CUR分解和交替映射法衍生出了鲁棒分解法(robust tensor CUR,RTCUR),与传统SVD分解法不同,RTCUR分解不受限于被离群值破坏的数据。之后,Yin等人[75]提出使用交替方向乘子法[76](alternating direction method of multipliers,AD‐MM)进行张量分解,利用ADMM技术以迭代的方式系统地解决张量分解中张量秩约束的优化问题。
从上述方法可以看出,当存在大规模数据时,尤其是当数据为非线性时,使用低秩矩阵的分解方法可以简化参数并提高网络的参数利用率。为进一步剖析上述张量分解方法的压缩效果,表6进一步罗列了上述研究所涉及的分解方法、压缩位置及其在各数据集下的压缩比和精度损失情况。
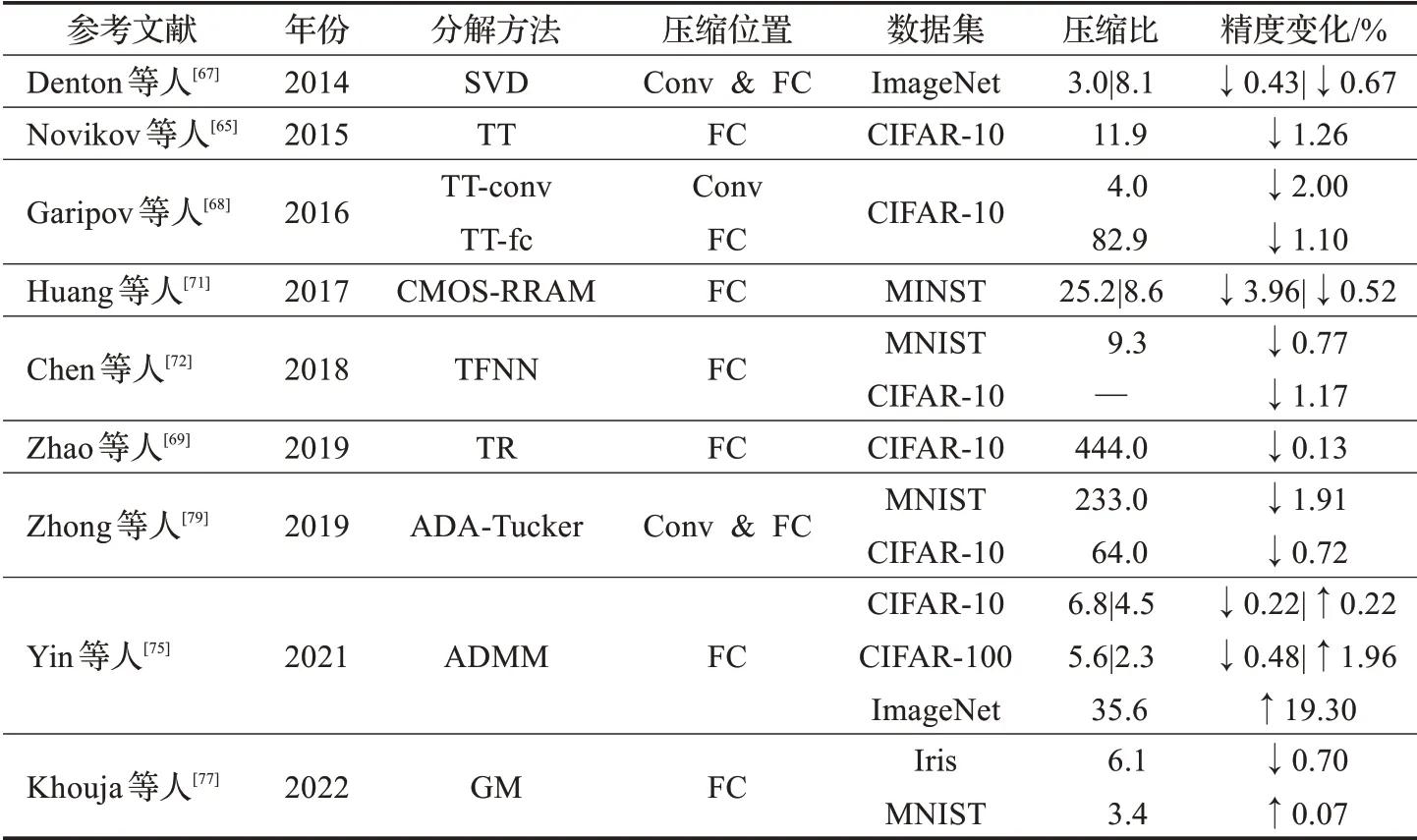
表6 张量分解方法对比Table 6 Comparison of tensor decomposition methods
基于上述对张量分解方法的介绍,对基于张量分解的目标检测优化方法的总结与展望如下:
(1)张量分解通过合并维数和降秩的方式稀疏化卷积核矩阵,其分解过程涉及的求奇异值等矩阵高级运算[77]的计算量极大、计算成本极高,并且需要大量的模型重训练才能实现收敛。
(2)目前流行的网络(如VGG、ResNet等)为了减少参数量常常通过叠加多个小卷积核来替代一个大卷积核,网络中大卷积核数目逐渐减少。而张量分解方法并不擅长于处理此类问题,因此张量分解相比于其他优化方法的研究进程略有滞后。
(3)现有的分解方法大多只针对规模相对较小的检测任务(如手写数据集等)进行实验,不足以完全证明张量分解方法的有效性,在未来还需在大规模任务上(如ImageNet等)进行压缩效果验证。
(4)随着数据维度的增加,网络中的卷积核可能会具有更高的阶数,因此更通用的、非固定张量维度的张量分解方法会是未来研究的一大方向,如Huang等人[78]针对3D加速的研究和Zhong等人[79]对任意阶张量进行自适应调整的研究。
优势:张量分解方法的分解机制较为简单,理论基础成熟,可以有效减少网络的参数量、降低模型体积,并且张量分解方法尤其适用于卷积核较大的网络,对高维特征数据的压缩效果十分明显。
局限性:张量分解操作中涉及的复杂高级矩阵运算的计算量庞大、计算成本极高、实现难度极大,在大规模数据任务上的压缩效果还有待研究。此外,由于不同网络层所含的特征信息不同,不能直接进行全局压缩,而需要逐层进行分解,因此需要大量的模型重训练才能重新实现原来的收敛效果。
3.2 模型剪枝
模型剪枝是模型压缩与加速的通用方法。模型剪枝即在网络训练过程中寻求一种评判机制来剪除网络中冗余的神经元、参数、通道、卷积等,如图4所示。常见的卷积神经网络从卷积层到全连接层都含有大量冗余的权重信息和神经元(输出为零),因此借助模型剪枝剔除这些冗余的、信息含量少的网络结构并不会影响特征的表达,能够在不影响模型检测性能的前提下加速模型推理速度[80]。
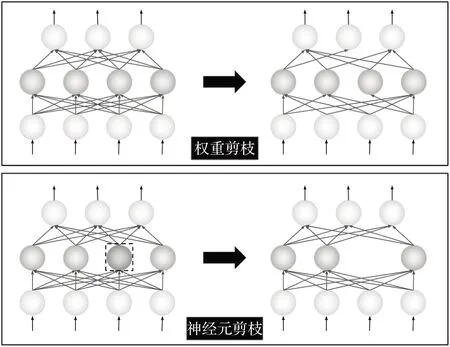
图4 模型剪枝示意图Fig.4 Schematic diagram of model pruning
早在20世纪80年代末90年代初,Hanson等人[81]就提出了对网络中的隐藏单元施加与其绝对值相关的权衰减来最小化神经元数量的剪枝方法。随后,Lecun[82]和Hassibi等人[83]先后提出了较为经典的OBD剪枝和OBS剪枝方法,借助损失函数相对权重的二阶导数来衡量权重的重要程度,删减网络中非重要的元素使网络结构稀疏化。虽然其研究受到了神经网络发展及算力的限制而停滞不前,但是其对于模型剪枝问题的梳理对后来的研究工作产生了深远影响。
自2012年来,随着ImageNet准确率屡创新高,模型剪枝才重回大众视野。2015年,Han等人[84]提出了“训练权重-模型剪枝-重训练”三步法,按规则去除冗余的零参,并微调模型使重新收敛。而后,Han等人[85]又提出通过权值量化来共享权重,并通过霍夫曼编码进一步对参数进行压缩。2016年,Lebedev等人[86]将脑损伤研究应用于加速卷积层,在网络训练中加入组稀疏正则化来修剪卷积核张量,将复杂的卷积操作转换为简单的稀疏矩阵乘法以提升运算速度。Zhou等人[87]通过在训练阶段向目标函数加入组稀疏正则项来剪除滤波器,得到较为紧凑的网络结构,从而在反向传播过程中绕过不易求导的稀疏限制项。
近几年来,基于模型剪枝的网络压缩方法逐渐丰富,考虑到手工设计剪枝方案的局限性,基于自动化机器学习(AutoML)的剪枝方案陆续被提出。2018年,He等人[88]借助修剪率和激励机制提出了与手工设计剪枝方案相比更具优势的方法,自适应地决定每层的压缩比例,将剪枝转化为了序列化决策的过程。2019年,Yu等人[89]依托轻量级网络提出了采用贪心搜索对给定配置选取各层最优网络宽度的方法(AutoSlim),通过训练轻量级网络来得到不同通道的重要程度,然后不断评估迭代训练后的模型进行贪婪剪枝。2020年,滴滴AI实验室的Liu等人[90]提出的自动剪枝框架实时使用交替乘子法来优化正则项,并利用基于经验的增强搜索自动化寻找模型剪枝中的超参数,从而满足移动端的实时性能需求。腾讯优图实验室的Meng等人[91]基于对滤波器剪枝与权重剪枝相融合的研究,提出了基于滤波器骨架的逐条剪枝算法(SWP),将每个滤波器视为多条滤波器的组合,逐条进行修剪。2021年,Wang等人[92]为缓解剪枝维度局限在单维的问题,提出了对三个最佳维度进行自动化剪枝,将剪枝问题按维度关系转换为多项式回归问题,最大化多项式即可获得最优解。Gao等人[93]考虑到用于剪枝的损失度量不匹配问题,直接通过最大化子网络的性能提出了一种新通道剪枝方法,通过最大化网络的输出来指导参数修剪,并且引入了事件记忆模块来沿着剪枝轨迹收集样本。2022年,Myung等人[94]提出了一种采用模型剪枝来进行迁移学习的简单有效PAC-Net模型,其基本思想是更新基本权重以对原先的任务进行微调,然后再通过更新冗余的剩余权重来进一步校准。
表7进一步列出了上述模型剪枝方法的模型机制及优缺点。从上述避免手工设计超参数的自动化剪枝的研究进展来看,基于自动化机器学习的模型剪枝展现出了巨大的发展潜力,将长期处于模型剪枝领域的主要研究方向。

表7 模型剪枝方法对比Table 7 Comparison of model pruning methods
从对剪枝方法的介绍来看,模型剪枝可按剪枝粒度的不同进行分类,如图5所示。结构化剪枝是在通道等整个维度进行剪枝,而非结构化剪枝则是单个元素进行剪枝。一般来说,剪枝粒度越细,对硬件的加速效果则越明显,剪枝效果则越好,但其权重矩阵趋于不规则分布,因此加速效果并不明显。
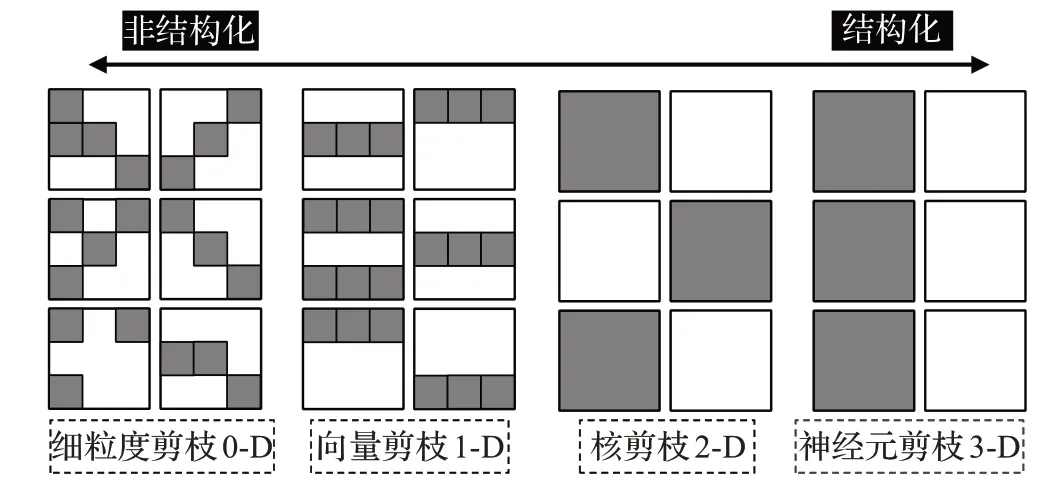
图5 模型剪枝方法的分类Fig.5 Classification of model pruning methods
目前,模型剪枝仍是一个动态的领域,多项理论研究清晰地定义了网络借助剪枝操作可以获得何种收益。剪枝的性能会随着网络模型的增大而得到提高,并且随着网络的增大,剪枝方法间的性能差异逐渐缩小,如Liu等人[95]在2022年的研究。通常来说,梯度对剪枝的容忍度较高,神经元剪枝会比权重剪枝带来的精度损失更为严重。在上述基于模型剪枝的压缩方法的介绍基础上,对此进行了以下几点思考:
(1)模型剪枝的早期研究受限于增加元素的稀疏性,倾向于对整个维度进行结构化剪枝。相比之下,近期研究更注重对单个元素的非结构化稀疏性以实现加速,通常需要特殊的硬件支持。
(2)与早期的启发式方法相比,基于强化学习的自动化剪枝方法能够精准地动态裁剪无意义的结构,避免手动设置层敏感度和的参数微调的局限性,在不影响精度的前提下高效地减少计算量。
(3)全连接层通常比卷积层具有更多冗余信息,因此模型剪枝算法在拥有大尺寸全连接层的网络上(如AlexNet、VGG)的剪枝效果要明显优于在其他网络上(如ResNet)进行剪枝。
优势:模型剪枝能有效移除网络中的冗余参数,且灵活度高、泛化能力强,既可以应用在训练过程中也可以用于训练结束后,既可以应用在卷积层也可以用在全连接层,并且对任意一个结构,都可以对推理时间、模型大小与准确率三者进行平衡。
局限性:模型剪枝一方面阈值选取困难,人为设定的阈值很容易剪去某些重要的权重,而自动化搜索的范围过大,需要较高的算力支持。另一个缺点则是不同模型的参数冗余度不同,过度进行参数剪枝会使模型准确率有所下降,需要重新训练网络。
3.3 参数量化
参数量化的核心思想是采用低比特数来存储神经网络模型的参数,从而降低网络模型中权重参数的资源占用量。例如,将模型参数由标准32位转化为INT8整数时,浮点数被表示为低精度的定点数,使得参数被压缩了四倍。这个浮点数到定点数的量化本质上就是将实数域中的某一段映射到整数域上。
在模型训练阶段,主流目标检测模型大多采用高精度表示的数据来捕捉参数传递时微小的梯度变化,但是这些结构在推理阶段却是可有可无或无需精细表示的,因此可采用参数量化减少其表示所需的比特数,其量化过程如图6所示。如图,神经网络中可量化的数据对象包括权重(W)、激活函数(A)、误差(E)、梯度(G)和权重更新(U)。虽然这些数据对象均可进行量化,但其量化效果参差不齐,表8选取了部分典型量化研究来对比不同数据对象对量化的敏感性[96]。
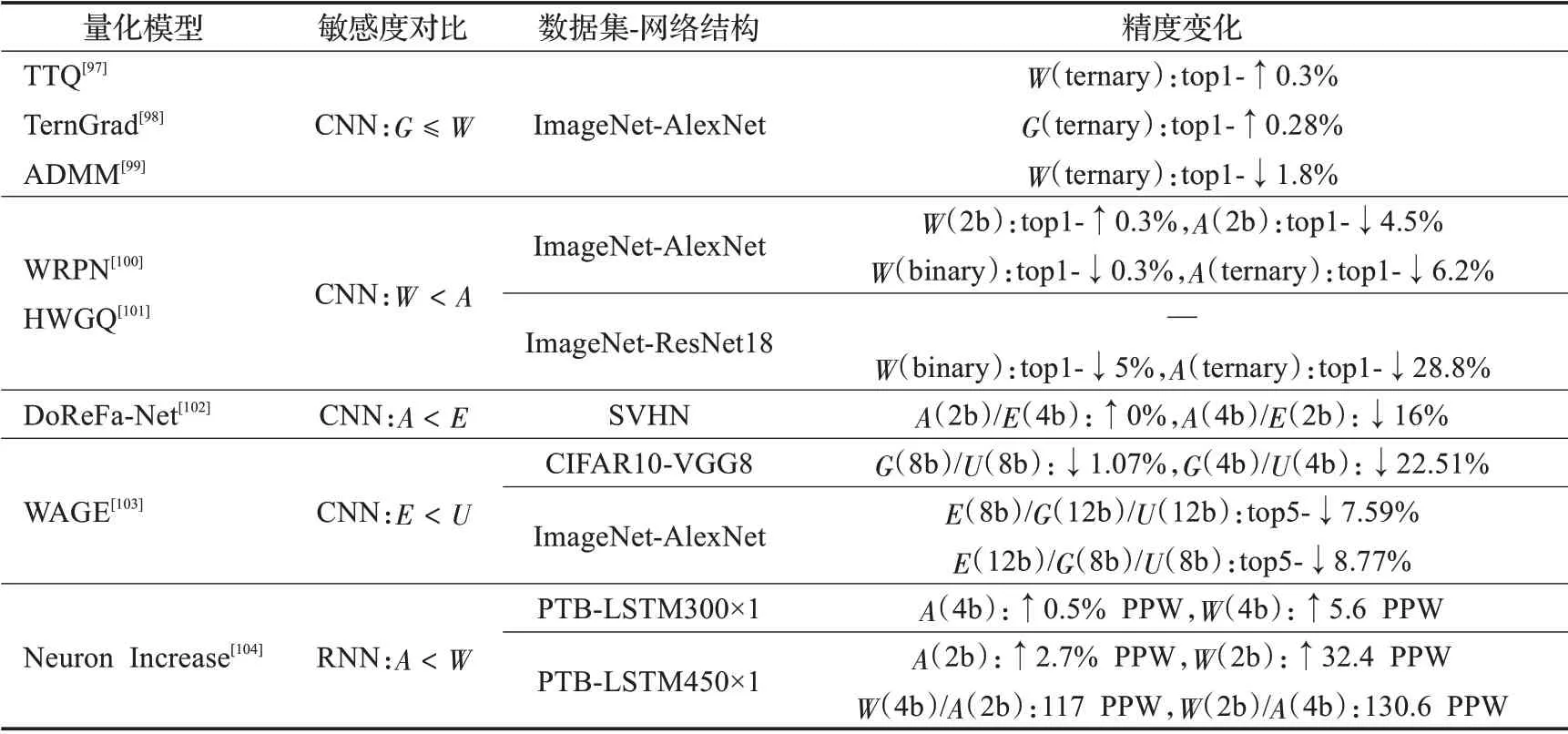
表8 量化对象的敏感性分析Table 8 Sensitivity analysis of quantization object
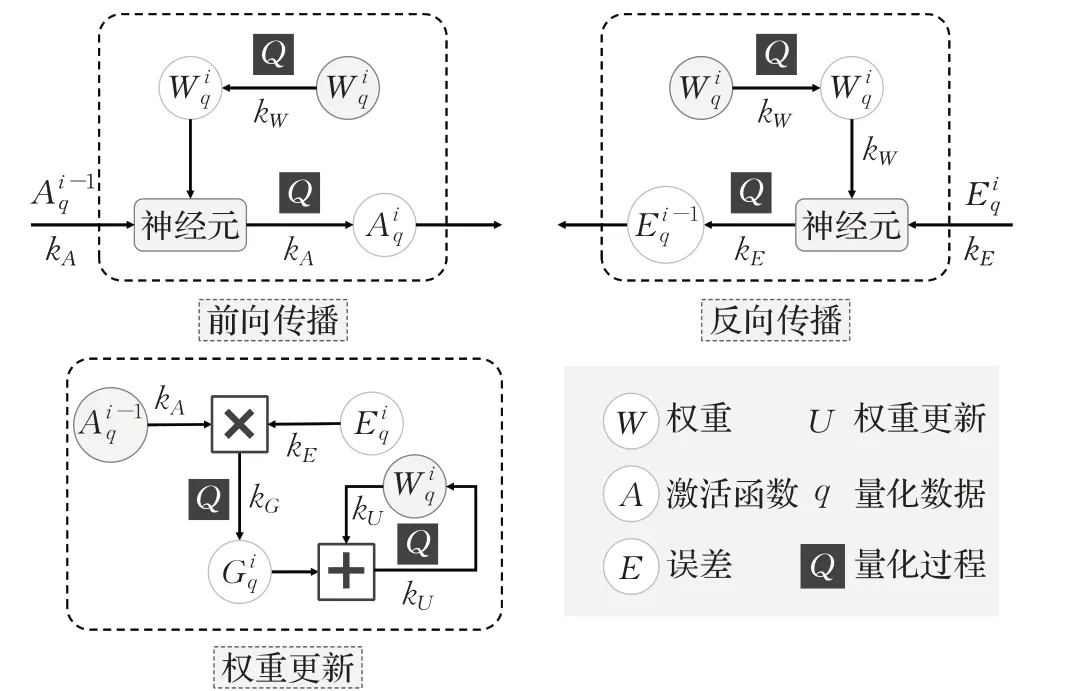
图6 量化过程Fig.6 Quantization process
参数量化的一个核心问题就是量化参数的选取,下文将就量化参数选取方法展开介绍。
(1)传统的量化参数选取方法
最早对神经网络的量化研究可追溯到1990年,Fiesler等人[105]最先意识到将神经网络运用于光学计算机中所面临的主要问题是连续实数表示的权重与离散表示的光学间的矛盾,由此提出基于反向传播(back propagation,BP)的权重离散化方法,将神经网络权重分布在有限的离散级数上。后来,Gupta等人[106]简单归结了低精度数据表示的两种基于“四舍五入”的量化方法,一种是就近取整法,另一种是向上或向下取整法,这也是最简单粗暴的量化方法。在此基础上,2020年Nagel等人[107]的最新研究中提出了利用泰勒级数展开任务的权重舍入机制,将舍入任务简化为逐层局部损失,大大优化了“四舍五入”方法。
(2)先进的量化参数选取方法
除了上述手工设定参数的量化方法外,目前已衍生出了丰富的用于模型参数压缩的量化方法。不可否认的是,这些量化方法或多或少带来了一定的精度损失。为了尽量减少量化误差,目前主要采用下述三种量化方法来选取最小化误差的量化参数。
①基于统计近似的选取方法
基于统计近似的量化参数选取方法是一个将信号连续值或大量离散值近似为有限多个或较少的离散值的过程。2016年,斯坦福大学的Miyashita等人[108]提出了一种用以2为底的对数来统计权重和激活信息的非均匀量化方法,较好地解决了可能存在的离群值带来的精度损失问题,具有比线性运算更好的鲁棒性。2018年,Gong等人[109]通过统计量化对象的最大值来选取量化参数,从而较好地支持8位低精度推理,并且其校准过程是自动生成的,因此无需微调或重新训练。2020年,Liu等人[110]提出了使用多个低位线性组合来近似高位矢量的多点量化方法,能够根据输出误差自适应确定每个权向量的低精度点数,仅对影响输出的重要权重保留较高的精度水平,从而产生了混合精度效果,解决了当前技术在进行端到端量化时对精度造成的损失。
②基于优化的量化参数选取方法
基于优化选取量化参数的方法即利用优化来求解量化误差最小值的方法。2017年,大疆的Lin等人[111]将激活值和权重看做一系列的线性组,提出了一种对误差进行优化的高精度二值化网络结构(ABC-Net),解决了量化中二值网络带来的精度损失问题。2019年,华为的Choukroun等人[112]将线性量化任务看做最小均方误差问题,对量化尺度进行精细搜索以求得最优解,类似的还有英特尔的Banner等人[113]的研究。2020年,Fang等人[114]提出了一种将整个量化范围分解为多个非重叠区域的分段线性量化方法,通过最小化误差来寻找最优断点。2021年,针对常用直通估计器忽略了输入和输出函数离散化误差的缺陷,Lee等人[115]提出了逐元素梯度放缩法(element-wise gradient scaling,EWGS),自适应地调整梯度元素的比例因子。2022年,张帆等人[116]针对敏感性数据场景下存在数据集在模型量化时不可用的问题,提出了一种不需要使用数据集的模型量化方法。上述量化方法将最小化量化误差作为优化目标,但最小化量化误差不等同于最小化精度损失,实际优化目标与最终优化目标仍存在偏差,如Nahshan等人[117]的研究内容。
③基于微分的量化参数选取方法
基于微分选取量化参数的方法以最小化精度损失为量化目标,借助随机梯度下降解决了上述基于优化选取量化参数时存在的优化目标不一致的问题。2018年,Choi等人[118]针对适宜部署到移动设备的低精度神经网络,提出以最小化精度损失为目标的优化方法,通过简单的逐位运算实现卷积操作。2019年,Gong等人[119]借助tanh函数构造了具有可微特性的量化函数(differen‐tiable soft quantization,DSQ),用可微量化弥补全精度神经网络和低位神经网络之间的差距。2022年,Guo等人[120]利用模型梯度的Hessian矩阵分层刻画量化模型的精度损失,提出了一种具有次秒级量化时间的无数据量化框架(SQuant),在隐私敏感和机密场景下前景广阔。除此之外,还有阿里的Yang等人[121]基于Sigmoid函数提出的可微分非线性方法。
基于微分选取量化参数的方法解决了最小化精度损失的问题,但其借助梯度下降法对多个参数进行联合量化也带来了双线性问题,使得训练的收敛更加困难。2020年,Zhuo等人[122]针对上述方法中对权重参数和激活参数进行联合量化导致的双线性问题,提出了利用投影函数协调变量的理论框架(cogradient descent,CoGD),利用两个变量间的耦合关系消除其中之一,诱导梯度同步下降以优化量化过程。
基于参数量化的压缩方法可以实现较好的模型优化与压缩效果,究其原因主要有以下几个方面:
(1)参数量化的本质是将多个参数映射到同一范围,从而减小模型尺寸、降低内存耗用、减少设备功耗,如进行8位整型量化可减少约75%的模型。
(2)对大多数处理器来说,浮点型运算的速度要显著低于整型运算,因此将模型参数由浮点数转化为低精度的整数能够加快模型的推理速度。
(3)从硬件角度来看,参数量化能够提高系统吞吐量,适用于性能有限的移动设备,例如对一个宽度为512位的指令来说,将32位数据量化为4位表示时,理论上可以让芯片的计算峰值扩大8倍。
表9进一步罗列了上述研究所涉及的量化方法的模型机制及优缺点。基于上述对基于参数量化的压缩方法的研究,本节进行了以下几点思考:
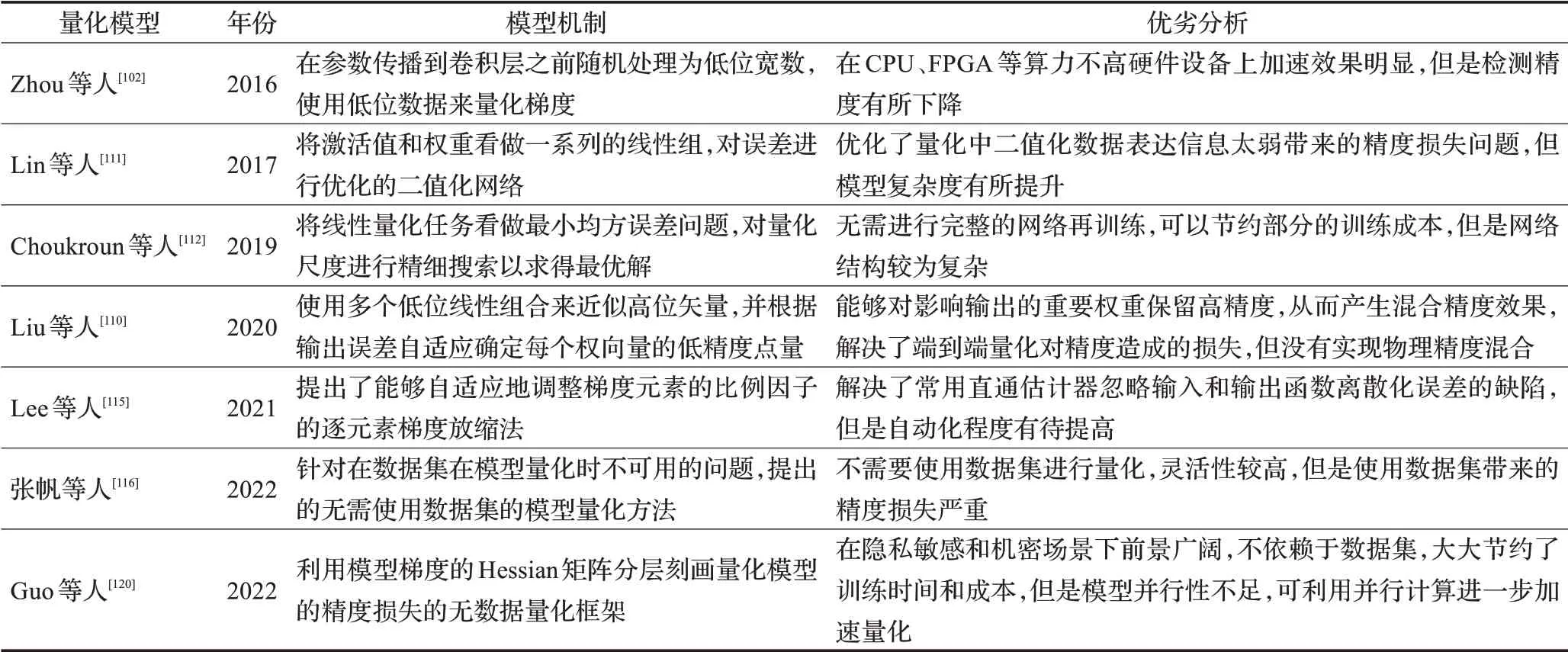
表9 参数量化方法对比Table 9 Comparison of model pruning methods
(1)参数量化使模型质量与特征表达能力受到影响,会导致一定程度的精度损失,尤其是对大型网络而言量化带来的影响更为明显,虽然通过微调可以减少部分精度的下降,但其损失仍是不可避免的。
(2)最小化量化误差并不等同于最小化精度损失,因此可以借助梯度下降法在训练网络的同时优化量化参数。但是,在这个过程中需要同时对多个参数进行量化,参数间的耦合关系可能会导致梯度消失现象,这使得训练的收敛难度有所增加。
(3)基于参数量化的压缩方法虽然涉及模型的算子层面较为局限,但兼容性较强,较好地与其他压缩算法相融合,如Ornhag等人[115]的研究,在未来长期发展中都会是一种主流的压缩方法。
优势:(1)减小模型尺寸,减少存储空间;(2)减少内存耗用,易于在线升级;(3)加快推理速度,减少设备功耗;(4)支持微处理器;(5)兼容性强。
局限性:参数量化不仅增加了操作复杂度,还给网络带来了不可避免的精度损失,尤其是二值化会使网络精度大幅下降,即使通过微调可以减少部分精度的下降,但其损失仍是不可避免的。此外,量化操作还涉及了框架的算子层面,具有一定的局限性。
4 面向移动端的产业化应用
我国人工智能领域的一线大厂和独角兽企业正在积极推进移动端目标检测理论研发与产业化应用的解决方案[124],其中的代表性企业如百度、商汤科技等,技术产品遍布金融安防、自动驾驶等领域,为移动端用户提供了无接触、无侵扰的良好体验。目前,我国面向移动端的目标检测产业化应用现状如下:
(1)人脸识别:人脸识别在身份认证与安全防护领域发挥着重要作用,被广泛应用于移动支付认证、身份核对、推荐消费等商业活动中。旷视科技旗下人脸识别开放平台(Face++)提供的实名验证服务已被广泛应用于支付宝、今日头条、小米、vivo等企业。
(2)移动医疗:人工智能影像检测已在呼吸系统疾病、神经系统疾病和恶性肿瘤上取得了一定成效。在移动医疗领域,依图科技借助智能影像检测技术研发的新冠肺炎辅助诊断系统为疫情防控做出了贡献,并且将医疗AI嵌入临床工作流,研发的智能机器人已在三甲医院落地应用。AI技术结合移动医疗在不远的将来或将真正实现“治于未病”的理念。
(3)自动驾驶:对具备自动驾驶能力的车载终端而言,目标检测可对车辆传感器和V2X设施搜集到的环境信息进行检测与识别,是自动驾驶系统的关键技术之一。常见的自动驾驶系统有特斯拉Tesla、小马智行Pony、百度Apollo等,其中国产自研品牌“百度Apollo”依托目标检测等技术已在无人驾驶车队和萝卜快跑两大业务上展现出了全球领跑的姿态。
(4)图像美化:基于目标检测等技术的图像美化可以轻松实现人像扣图、背景虚化、美瞳、瘦脸等美颜效果。如字节跳动的轻颜相机、脸萌团队的Faceu激萌、腾讯出品的天天P图等,借助AI技术实现各种图像美化操作,轻松拍出风格迥异的图像。
(5)媒体与娱乐:依托该技术用户可在虚拟世界内轻松尝试大量具有趣味性、挑战性和互动性的娱乐活动,如北京环球影城的哈利波特禁忌之旅等游戏项目。此外,诸如微信、QQ等即时通信工具及虚拟化的网络游戏也将成为广阔的移动端应用市场。
5 总结与展望
随着日常生产生活对智能移动设备的依赖逐渐加深,如何在资源有限的设备上在尽可能保持模型精度的前提下最大程度加快推理速度将成为将目标检测向移动端迁移的长期研究热点。为对本文所述的目标检测优化方法进行提炼分析,表10进一步总结了上述方法的适用层级、优劣性及适用场景。在上述介绍基础上,对本文研究提出了以下几点总结与展望:
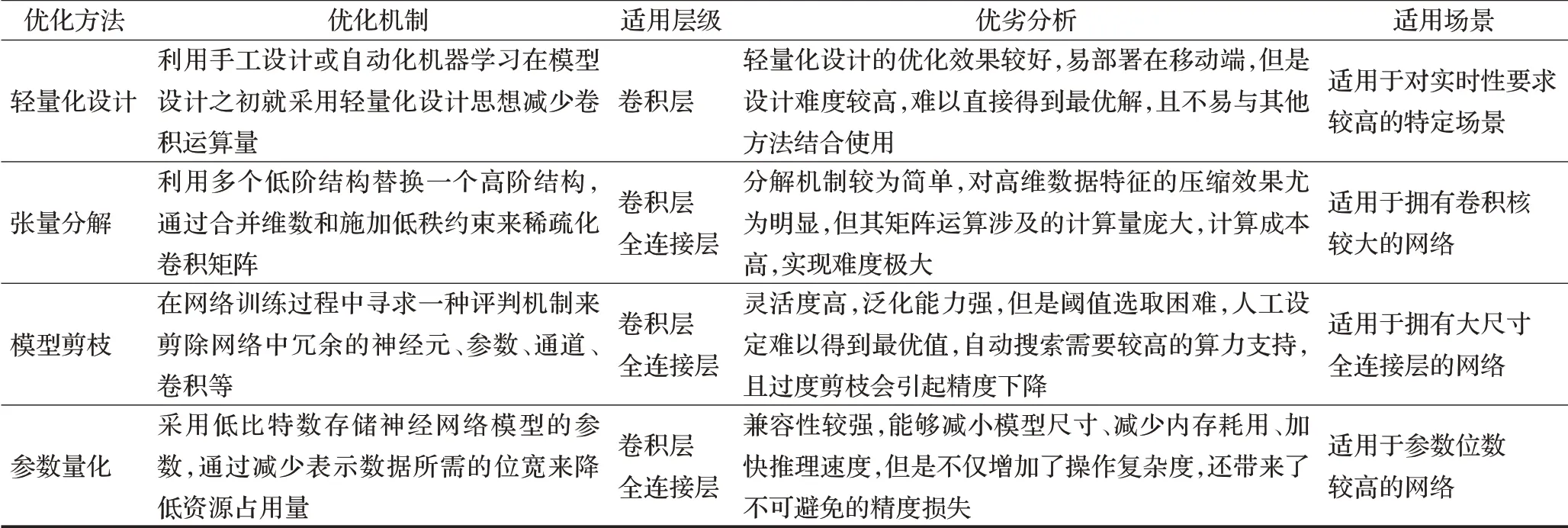
表10 目标检测优化方法对比Table 10 Comparison of optimization methods for object detection
(1)轻量化网络设计:基于轻量化设计的优化方法采用轻量化的卷积设计来优化网络,需要设计者具备较高的专业素养和娴熟的网络设计经验,进行针对性设计才能使模型各项性能达标,尤其适用于对特定的目标检测任务进行优化。轻量化设计方法虽然具有易部署、高性能等优势,但是其设计难度较高且不易与其他优化方法结合使用,因此未来仍需进行长期研究来挖掘更便捷、更通用的网络设计方法。
(2)模型压缩:基于压缩的优化方法依托于张量分解、模型剪枝和参数量化等手段对现有模型进行调整。张量分解可有效进行降维,但涉及的分解操作计算量大、计算成本高;参数量化能够显著减少存储空间,但随着网络表达能力的衰退会产生一定的精度损失;模型剪枝的鲁棒性较强,但自动化搜索的范围过大,需要较高的算力支持。同时,这些压缩手段虽各有特色,但压缩过程有所重叠、且不同手段相互兼容,因此在未来研究中会朝着联合压缩的方向发展。
(3)基准测试:基准测试通常选取AlexNet或VGG16网络进行优化并在ImageNet数据集上进行测试。显而易见,这两个网络的结构更加冗余,优化效果更为明显。但近期针对新代网络的优化研究表明,现有的优化方法还不足以支撑对自然紧凑型结构的优化,将当前优化方法扩展到更紧凑或更深的网络仍具有较大的挑战性。此外,这些方法明显在小型数据集(如MNIST)上取得了更优的优化效果,而在大型数据集(如ImageNet)上的效果仍有待加强。
目前常见的目标检测数据集有VOC 2007、VOC 2012、ImageNet、COCO、CIFAR-10、SUHN、MNIST和AITEX,相关数据集信息已在表11中列出。
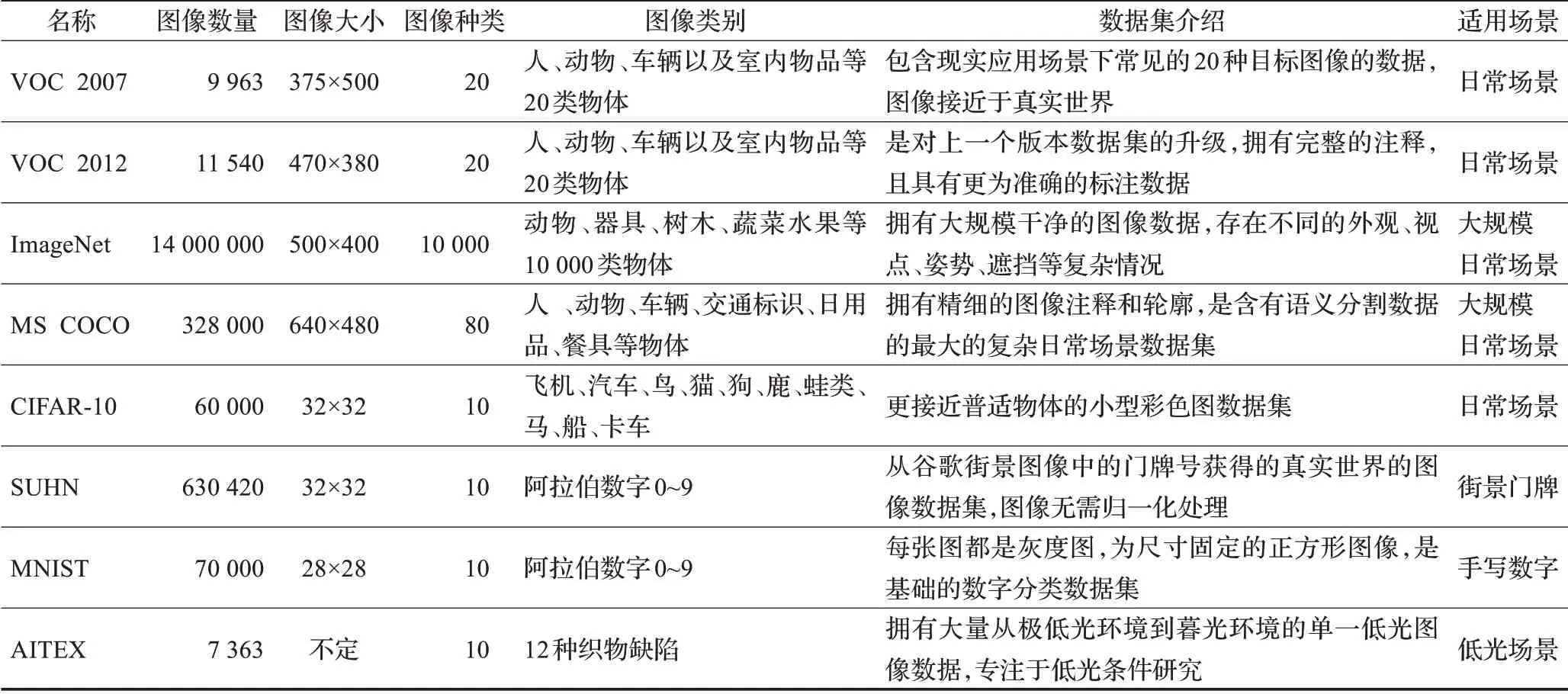
表11 常用目标检测数据集Table 11 Common object detection datasets
(4)衡量指标:在目标检测优化领域各种优化算法层出不穷,除了不同的求解路径(如量化等)外,每条路径也都蕴含着无数种方法。为公平比较这些方法,本文建议从以下几个角度进行衡量:
①训练速度与推理速度:模型在训练与推理阶段的实际优化效果不同,可按运算场景分别比较。
训练速度:s/iter即迭代每批样本所需的时间;
推理速度:FPS即检测器每秒处理的图片数量。
②压缩比与检测精度:压缩比与检测精度是一对相互制衡的数据,模型压缩一定会带来精度损失。
压缩比:即压缩后参数缩小的倍数。
检测精度:top-1即预测结果中第一个类别为正确类别的概率;top-5即前五个类别出现正确类别的概率;mAP即所有类别的平均AP值。
③实际收益:实际收益依赖于硬件支持,不能借助压缩比获取反馈,需要引入时延等实际收益指标。
④优化对象:不同数据对象在简化计算模式和减少内存成本方面提供的助力不同,对精度损失的敏感度也不尽相同,因此在进行横向对比时需基于相同的数据对象维度进行对比。
(5)自动化压缩:大多数目标检测压缩方法通常需要预先设定一些约束参数,如NAS中的搜索空间、分解中不同层的秩值、量化中的位宽等。这类基于手工参数的压缩方法高度依赖于手工试验和专业知识,繁琐的手动调参非常耗时,并且人工探索法通常得到的是次优解。因此,如何运用自动化机器自动进行目标检测优化是亟待解决的问题之一。
例如,基于AutoML的轻量化方法借助强化学习自动搜索,虽然相较于传统方法有所提升,仅是对手工设计的卷积块和网络结构的堆叠,并非完全自动设计。轻量化网络设计需要朝着更广泛的搜索空间和更高的设计自由度发展,进一步实现自动化。
(6)框架级支持:深度学习框架的出现显著降低了编程的入门门槛,提高了算法设计者的工作效率,这在目标检测的优化领域也同样适用。在1979年,英伟达最早发布了用FORTRAN语言编写的程序库(Basic Linear Algebra Subprograms,BLAS),此后又衍生出了经典的线性代数库,为张量分解中的稀疏化运算提供了框架级支持。除此之外,还有Tensorflow为量化感知训练提供的工具,这些框架的出现进一步推动了目标检测的理论研究和在移动设备中的快速部署。
(7)硬件级支持:现有的处理器可广泛支持从常规操作到大规模操作再到高精度操作范围内的数据运算。虽然轻量化网络引入了更紧凑的结构,但仍保持在通用处理器足以支持的数据精度范围内,而其他压缩方法(如高维张量计算、稀疏处理等)在一定程度上受到了通用处理器的限制而无法获得理想的速度增幅。因此通过设计专用硬件架构来提供硬件级支持是推动目标检测优化理应考虑的维度之一。
综上所述,目标检测的优化需要理论研究、算法设计、框架设计及硬件设计等多领域的紧密合作。尽管移动端目标检测优化领域已经拥有了大量的理论研究,但仍在以下几个方向提供了机会:(1)轻量化设计;(2)轻量级压缩;(3)压缩自动化;(4)框架级设计;(5)硬件级设计。这些研究方向终将催生出更多优秀的适用于移动端的优化方法。
6 结束语
近年来,尽管针对目标检测的优化问题已经涌现出了大量优秀的解决思路,但是大部分研究仍局限于实验室理论研究阶段,距离正式的产业化落地应用仍有很长的路要探索。技术的发展终究是为解决实际工业应用问题服务的,目标检测终将通过不断优化与发展普及到实际工业应用中,催生出一套智能的、完备的嵌入式人工智能应用体系。
猜你喜欢
保健医苑(2022年5期)2022-06-10
西南师范大学学报(自然科学版)(2022年1期)2022-03-02
精密成形工程(2022年2期)2022-02-22
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
成都信息工程大学学报(2021年6期)2021-02-12
五邑大学学报(自然科学版)(2020年4期)2020-12-09
计算机应用(2020年5期)2020-06-07
杭州电子科技大学学报(自然科学版)(2020年1期)2020-04-09
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
