
基于即时编译的GNU Octave性能优化*
2022-12-22 11:31莫舒恒卢圣有卢宇彤
计算机工程与科学 2022年12期
莫舒恒,卢圣有,黄 聃,卢宇彤
(1.中山大学系统科学与工程学院,广东 广州 510006;2.中山大学计算机学院,广东 广州 510006)
1 引言
随着科学技术的迅猛发展,数值计算成为科学研究、工程设计和金融建模等领域的重要手段。GNU Octave是一款免费、开源,且兼容MATLAB语言的数值计算软件,在教学、研究和商业应用中使用广泛。然而,运行效率低下一直是Octave发展面临的重要问题,同样的代码在Octave上的执行时间可达MATLAB的几十倍乃至几百倍。
对于Octave这类动态解释型语言,解释器的性能往往是其瓶颈所在。使用高效的即时JIT(Just-In-Time)编译器是提高程序运行效率的一种重要手段,当源代码被转换为中间语言后,由JIT编译器读取全部或部分中间语言,并将其即时编译成机器语言。机器语言可被缓存并在以后重用,这大大提升了JIT编译器的效率。许多解释型语言都具有成熟高效的JIT编译器,例如Java虚拟机JVM(Java Virtual Machine)[1]和JavaScript语言的V8引擎[2]及Microsoft.NET Framework中的JIT编译器[3]。一些成熟的编译器框架也提供了对JIT编译技术的支持。GCC(GNU Compiler Collection)提供了libgccjit库[4],用户可以调用该库的C/C++ API接口,以GCC作为后端动态生成机器指令;LLVM项目同样提供了JIT引擎[5],且该引擎已历经3次迭代更新,由最初的JIT引擎进化至MCJIT引擎,再到如今的ORC JIT引擎。使用LLVM JIT引擎不仅可以调用C/C++ API接口完成,还可以直接生成LLVM机器无关的中间表示IR(Intermediate Representation),由LLVM后端完成LLVM IR到机器语言的翻译。
MATLAB的JIT编译技术一直在不断发展。2002年,MATLAB®官方在MATLAB 6.5版本中引入被设计为对MATLAB解释器进行补充的JIT加速器(JIT-Accelerator),以支持MATLAB语言有限子集的JIT编译。相比于MATLAB 6.1版本,新版本在多种测试场景下均表现出了高达百倍的性能提升[6];MATLAB R2015b重新设计了MATLAB的执行引擎,重点在于重构JIT编译器部分。新的执行引擎不再是仅支持MATLAB语言的有限子集,而是能够编译整个语言;也不只在特定情况(如存在循环语句的情况)下使用JIT编译,而是对所有的MATLAB代码均进行JIT编译。对76个性能敏感程序的测试结果表明,相比于R2015a版本,新的执行引擎性能平均提高了40%[7]。
Octave内部存在一个基于LLVM的实验性JIT编译器[8],只能对少部分Octave语句进行JIT编译加速,且适用范围不明。因而,Octave 的官方二进制发行版并未包含这一功能。迄今为止,Octave JIT编译器的实现仍是基于Brister[9]在OctConf2012研讨会上提出的雏形。目前Octave JIT编译器的相关研究已停滞,若要从源码编译安装并正常运行包含JIT编译功能的Octave较为困难,甚至自6.1.0版本起已放弃对该JIT编译器的兼容。
本文对Octave JIT编译器的整体功能和性能进行了评估,结果表明Octave JIT编译器对提升Octave执行效率的效果明显,但是该JIT编译器适用的代码范围十分有限,几乎无法在实际应用场景中给Octave带来明显的效率提升。面对Octave JIT编译器缺乏后续更新和优化的现状,本文基于Octave JIT编译器对Octave的性能优化方案进行了探究。本文贡献主要有以下4点:
(1)分析了Octave JIT编译器的工作流程,评估了Octave JIT编译器的性能和适用范围,为基于JIT编译器的性能优化方案指明了方向。
(2)提出了融合渐进式调试输出与白名单机制的调试输出完善方案,改进了JIT编译失败时的异常发生机制,从而增强了Octave Debug系统对Octave JIT编译器编译过程的调试辅助功能。
(3)针对当前Octave JIT编译器的功能和性能缺陷,优化了JIT编译器中的函数调用、索引运算与算术逻辑运算,并在此基础上进行Octave优化效果验证与展示。
(4)分类总结了Octave JIT编译器的现有缺陷,为未来Octave JIT编译器的功能完善和性能优化奠定基础。
2 Octave JIT编译流程分析
本节从工作原理角度出发,对Octave JIT编译器及其类型推断系统的工作原理进行分析。
2.1 Octave JIT编译器整体设计
Octave JIT编译器以Octave解释器为前端,以LLVM编译框架为后端。在Octave解释器完成词法分析、语法分析和语义分析的工作后,由Octave JIT编译器完成Octave解释器与LLVM后端的交互,之后的工作由LLVM编译框架所提供的JIT执行引擎完成。
如图1所示,在JIT编译过程中,JIT编译器将解释器语义分析阶段得到的抽象语法树AST(Abstract Syntax Tree)通过逐一编写的中间代码生成规则转换为原始的Octave JIT IR,在此基础上构造静态单赋值SSA(Static Single Assignment)形式的Octave JIT IR,并通过类型推断得到含中间类型信息的Octave JIT IR。接着将该JIT IR通过逐一编写的对应规则利用LLVM的MCJIT引擎转换为LLVM IR,随后由LLVM完成代码优化和目标代码生成等编译器中、后端工作。JIT编译完毕的代码将以机器指令的形式存储于被标记为可读、可执行状态的内存中,以指针的形式返回函数入口地址供Octave调用。
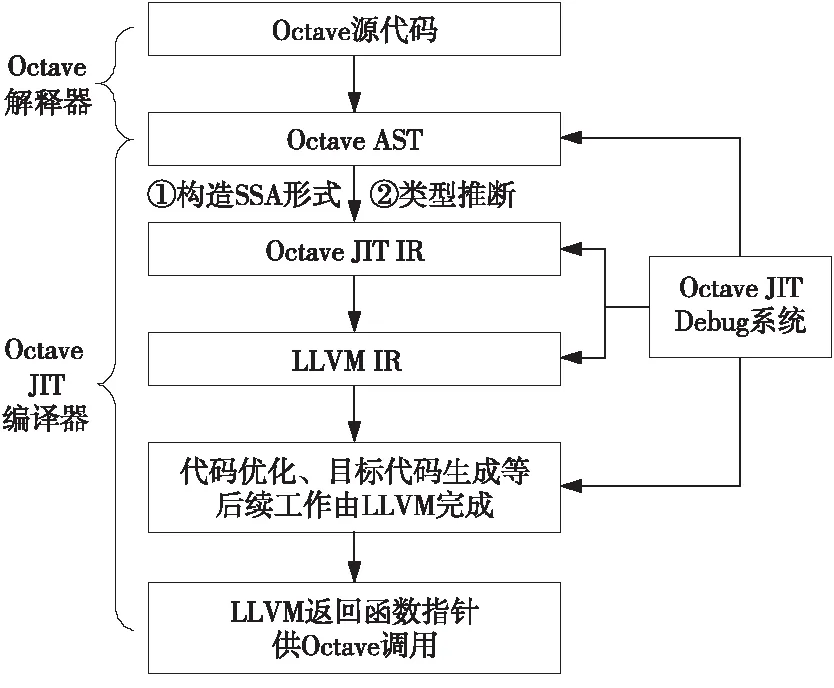
Figure 1 Overall workflow of Octave JIT compiler
Octave JIT编译器目前仅支持循环代码编译。Octave代码通过调用jit_enable函数控制JIT编译器的开关。Octave解释器在执行代码时,会将循环代码转交给JIT编译器。若JIT编译未开启,则JIT编译器把工作流交还给解释器,循环代码的运行时间为解释器用时,即解释器执行代码的时间。若JIT编译已开启,则JIT编译器对循环代码进行JIT编译,循环代码的运行时间为JIT编译用时及机器指令执行用时。若JIT编译后代码运行时间比解释器用时少,则JIT编译为循环代码执行带来了加速效果。
此外,JIT Debug系统与JIT编译的各个阶段均有交互,故Debug系统可获得JIT编译过程中包括AST、Octave JIT IR、LLVM IR和Optimized LLVM IR在内的各类中间信息。
2.2 类型推断系统
Octave语言是一种弱类型语言,而LLVM IR是强类型的中间表示。故在将Octave语言转化为LLVM IR的过程中需进行类型推断,以寻找各变量引用点的类型信息,从而将AST转化为强类型的Octave JIT IR。本节对Octave JIT编译器的类型推断系统进行介绍,首先介绍其中的类型系统,然后介绍类型推断过程。
2.2.1 数据类型
如表1所示,Octave JIT编译器的类型系统中定义了JIT编译器内部使用的数据类型。这些数据类型实质为中间数据类型,用于把Octave解释器中的数据类型转换为LLVM中对应的数据类型。

Table 1 Data types supported by the type system of Octave JIT compiler
除此之外,该类型系统会为每一个已支持JIT编译的Octave内置函数创建一个对应的数据类型,使得函数调用语句的实现可复用小括号索引运算的实现。
2.2.2 类型格
格是满足每对元素都存在最小上界和最大下界的偏序集。类型格(Type Lattice)是在类型系统中的格模型[9],其中元素表示数据类型,偏序关系对应数据类型之间由抽象到具体的继承关系。
Octave目前的类型格如图2所示,其中,any类型可指代任何数据类型,是类型格的最小上界;unknown指代类型推断前的未知数据类型,是类型格的最大下界。Octave的类型推断过程基于类型格实现类型转换,为此需要寻找每个变量引用点的数据类型在类型格中所组成的子集的最小上界。

Figure 2 Type lattices of current Octave JIT compiler
2.2.3 类型推断过程

由于LLVM的JIT引擎以函数为单位对代码进行JIT编译,Octave JIT编译器的类型推断系统也以函数为基础。因当前的Octave JIT编译器仅对循环代码进行JIT编译,故除循环体中调用的函数外,循环本身也被包装成一个函数。循环函数的输入参数为循环体中用到的上级作用域中的变量,而循环尾部的变量将作为循环函数的返回值返还Octave解释器。
Octave JIT编译器类型推断系统的核心思想可归纳为2点:(1)所有类型信息的根源来自常量,通过按照程序顺序模拟执行进行常量的类型传播,将其数据类型传播至每一个变量引用点,使得每个变量引用点均含有该变量的数据类型在类型格中所组成的子集信息。(2)因为迭代会改变同一个变量引用点在不同迭代轮次中的类型信息,故对同一个函数,可迭代进行类型推断,直到基本块中所有变量引用点的类型信息收敛至不再发生变化的稳定点为止。
通常情况下,编写得较好的Octave程序中很少发生固有类型的变化,类型推断过程几乎立即收敛。另外,Octave中还规定了类型推断迭代次数的阈值,若迭代次数超过阈值时函数中各点的变量类型仍未达到稳定点,则类型推断失败,JIT编译器将输出异常。
3 Octave JIT编译器功能和性能分析
本节从工作现状角度出发,对Octave JIT编译器的功能和性能进行测试及分析,为基于JIT 编译器的Octave性能优化方案指明方向。
3.1 Octave与JIT编译模块的编译兼容性研究
编译安装包含JIT编译器的Octave,需要在目标环境配置LLVM运行环境。
通过对目前较新版本的Octave和LLVM的编译兼容性研究发现,Octave 6.1.0及更高版本无法成功与LLVM组合编译。原因是自Octave 6.1.0起解释器的语法分析树(Parse Tree)被更改,但并未同步更新JIT编译器的中间代码生成部分。
而Octave 6.1.0的前一个版本Octave 5.2.0无法成功与非LLVM 4.0.1版本组合。由于LLVM C++ API变更频繁,该版本与高于LLVM 4.0.1的版本无法成功组合编译,且与低于LLVM 4.0.1的版本组合编译后运行闪退。
因此,本文以Octave 5.2.0为研究对象,同时修改其源代码,使其兼容LLVM 13.0.1这一新版本的C++ API。
3.2 JIT Debug系统的调试输出与异常定位优化
JIT Debug系统作用于JIT编译的代码。Octave通过启动参数——debug-jit来控制Debug系统的开关。JIT编译器开启后,将对所有while循环代码块和大于迭代次数阈值(默认阈值为1 000)的for循环代码块进行JIT编译。如图3所示,如果循环代码块中存在一处不支持JIT编译的语句,则JIT编译器放弃对所有语句的JIT编译,转而由Octave解释器执行这些代码。

Figure 3 Debug output process of current Octave JIT compiler
Debug系统会根据JIT编译结果的成功与否,输出不同的调试信息。当JIT编译成功时,Debug系统首先在Compiling tree字段中输出经过JIT编译的代码段,随后将会对JIT编译器生成的Octave JIT IR、LLVM IR和Optimized LLVM IR 3个中间表示字段进行调试输出。而当JIT编译失败时,Debug系统的调试输出仅有模糊的JIT fail字段,该字段中仅包含导致编译失败的错误类型,难以定位错误位置并对其进行修复。
为此,本文提出融合渐进式调试输出与白名单机制的方案,如图4所示,对JIT Debug系统的调试输出进行了优化,同时完善了编译失败时的异常产生机制,以实现明晰的错误原因阐释及精确的错误代码定位。

Figure 4 Debug output process of the improved Octave JIT compiler
对于中间表示字段的完全缺失问题,由于JIT编译失败时无法保证从AST到Optimized LLVM IR的转换过程中的3个阶段都成功完成,因而本文对Octave JIT 编译器的一次调试便输出4个字段的过程进行拆分,按过程的先后顺序分4步渐进输出当前阶段的调试信息,并采取白名单机制确定某一字段是否能正常输出调试信息。因JIT编译失败时会输出字符串形式的异常,本文通过实验确定异常信息和调试信息字段的匹配关系,并将这一关系加入白名单中,以实现渐进式调试输出。
对于编译失败时错误诊断输出功能羸弱的问题,本文针对JIT编译失败时的异常处理机制,对每一处可能产生异常的代码位置进行异常信息完善,使异常信息所描述的错误更为精确,同时携带导致该异常的Octave源代码位置及用户代码位置信息。
3.3 JIT编译器功能和性能评估
目前Octave JIT编译器仅可对循环语句进行JIT编译。本文从循环类型和循环体内容2个方面对JIT编译器进行测试。循环类型包括次数固定的循环与次数不定的循环,而循环体内容包括3个方面:
(1)顺序语句、条件语句和循环语句3种基本的流程控制语句;
(2)对实数标量和复数标量、实数矩阵和复数矩阵的操作,如算术逻辑运算操作、索引操作等;
(3)函数调用,包括内置函数和用户定义函数。
本文针对上述分类编写了测试样例,对Octave JIT编译器的功能和性能进行评估。测试结果显示,一部分样例可以进行JIT编译并正常运行,其他样例则在编译或运行中出现了错误。
成功编译的样例的测试结果如表2所示。其中,样例的JIT编译前用时指在未经过JIT编译时,样例代码由Octave解释器执行的运行时间。样例的JIT编译后用时指经过JIT编译后样例的运行时间,包括样例代码的JIT编译用时和JIT编译后的机器指令执行用时。样例获得的加速比由其JIT编译前、后用时的比值得出。表2中的数据均保留3位小数。
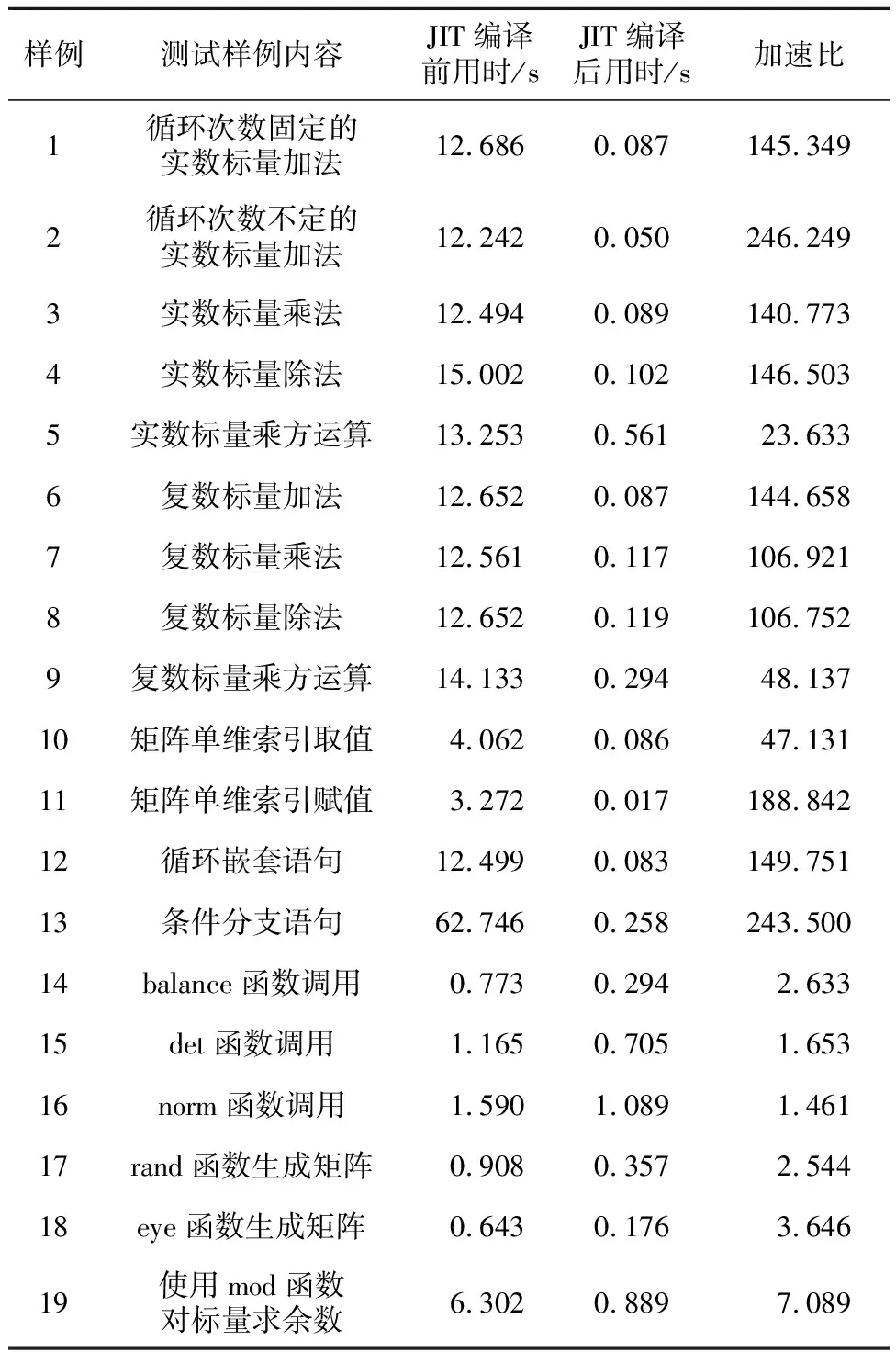
Table 2 Running time and speedups before and after JIT compilation
JIT编译成功并正常运行的样例根据测试内容分为4类:
(1)顺序语句、条件语句和循环语句3种基本的流程控制语句;
(2)对实、复数标量的算术逻辑运算操作;
(3)对矩阵的单维索引操作;
(4)对极少数内置函数的调用操作。
根据测试结果中的加速比将样例分为4类,如图5所示。
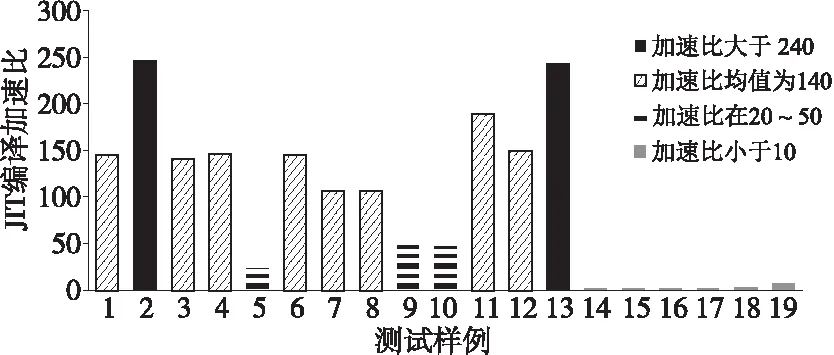
Figure 5 Classification of test case speedups
加速比在均值140倍左右的情况,可视为JIT编译消除了代码解释开销所获得的普遍性能提升。加速比达240倍以上的最佳情况对应于条件判断有关的测试。取得了比均值情况更佳的加速效果,原因是JIT编译不但去除了代码解释开销,而且代码被JIT编译成机器语言后可以充分利用现代处理器的分支预测技术。加速比仅有20~50倍的情况对应于乘方和索引有关的测试。这是由于乘方和索引计算本身开销更大,JIT编译所消除的代码解释开销带来的整体加速效果弱于均值。加速比小于10倍的样例则与内置函数调用操作有关。由于当前Octave JIT编译器对内置函数调用的低效实现方式,导致了JIT编译对内置函数调用操作的加速效果十分有限。
4 Octave JIT编译器性能优化
本节基于前述工作对Octave JIT编译器进行优化,然后以优化特性实验和LU分解实验来验证性能优化效果,最后分类总结优化后的Octave JIT编译器的缺陷,为未来工作指明方向。
4.1 内置函数调用优化
在第3节的测试中,因调用内置函数导致JIT编译失败的测试样例可以分为2类:(1)JIT编译成功,但执行时产生段错误的样例;(2)完全不支持JIT编译的样例。本节针对这2类样例中存在的问题对Octave JIT编译器进行优化。
本文通过进一步研究发现,样例执行产生段错误是因为函数特化过程中出现了函数重名问题。内置函数的JIT编译支持的实现方式分为2种:(1)将函数特化为LLVM的内置函数;(2)调用Octave解释器来执行其原有的内置函数。函数被特化为Octave内置函数时,由于函数名与LLVM内置函数重名,被LLVM错误链接到了LLVM内置函数的符号地址。在运行时,该函数的输入输出为Octave的数据类型且不被LLVM内置函数所支持,因此出现了段错误。在函数被特化为Octave内置函数时,可以通过在函数名上与LLVM内置函数进行区分的方式来修复这一漏洞。
由于JIT编译器直接调用解释器内置函数实现的加速效果有限,LLVM内置函数的支持也有限,故利用C/C++编写外部函数是为内置函数添加JIT编译支持的一种高效方式。
因此,本文新增了对内置函数特化为C语言函数的支持。LLVM的JIT执行引擎维护了一个全局映射表,可向全局映射表中添加指定的全局映射。故若要添加在JIT执行引擎中可调用的C语言外部函数,可显式地将外部函数指针作为全局符号地址添加至JIT执行引擎中。
基于上述工作,本文完成了对更多内置函数的JIT编译支持,如表3的第1~21行所示。
4.2 索引运算与算术逻辑运算的类型支持扩展
本节以range类型的索引赋值运算实现为例,说明对索引运算的类型支持扩展;以range类型和标量的加法运算操作实现为例,说明对算术逻辑运算的类型支持扩展。
4.2.1 range类型索引赋值运算实现
因range类型可简化向量化语句与固定步长的循环编写,故支持range类型的索引操作意义重大。range类型是Octave中表示范围的数据类型,以C++类的形式存储,其设计如表4所示。
实现任意类型的索引操作的整体思想和注册函数的思想一致。此处可分为2步:(1)编写C++/LLVM形式的JIT函数,在其内部完成对相应类型的索引操作;(2)将该函数添加至小括号索引取值运算符的重载函数列表中。
就range类型的索引赋值操作而言,其过程可分为索引值合法性检查、range类型到matrix类型的类型转换操作的支持和Octave JIT编译器的类型格的修改3个部分。
依据range类的成员变量的当前设计,该类型并不实际存储任何索引位置所对应的值,无法实现对任意位置的赋值操作。故在其索引赋值操作中,需在赋值前将range类型转化为matrix类型,从而利用matrix类型支持随机存取的特性完成这一操作。其中,索引值合法性检查操作在索引值为非整数或小于1时报告无效索引值错误。特别地,索引值越界不会被视为错误,因为新生成的matrix长度可由原range类型的长度和索引值中的较大者决定。若索引值更大,以零填充的方式对matrix扩容部分的内存空间进行初始化。
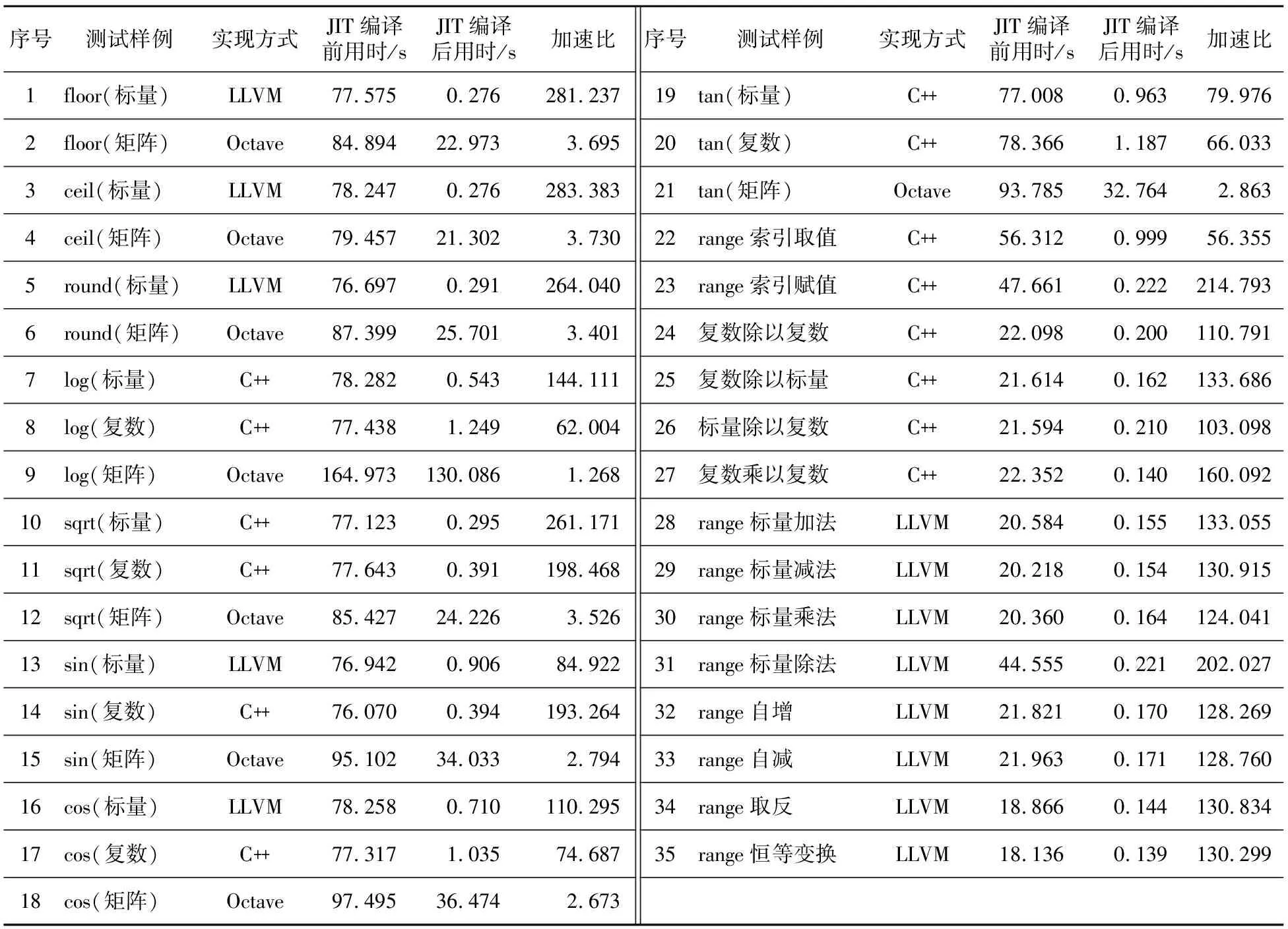
Table 3 Running time and speedups of optimization features before and after JIT compilation

Table 4 Member variables of range class
在将range类型变量转换为matrix类型变量后,SSA形式的Octave JIT IR在循环体首部插入的φ函数将会对该变量的2处来源进行合并,即将循环外部得到的range类型和循环尾部回传的matrix类型进行合并。然而,在当前Octave JIT类型系统的类型格中,matrix类型与range类型不存在偏序关系,这将导致类型合并后得到的最终类型为any类型,而非matrix类型。因此,需要对类型格进行相应修改,添加matrix类型与range类型的偏序关系,以支持range类型索引赋值操作。修改后的类型格如图6所示。

Figure 6 Modified type lattics of Octave JIT compiler
4.2.2 range类型与标量的加法运算操作实现
对双目运算符AST进行代码生成的过程可分为3个步骤:首先,将访问者模式与递归技术结合,为该AST节点的左子树和右子树进行代码生成,从而得到该双目运算符的左值和右值;然后,查找记录运算符与具体操作的映射信息,得到当前双目运算符对应操作函数;最后,将上述左值和右值作为对应操作函数的参数,生成对该函数调用的语句,即可生成该双目运算符对应的Octave JIT IR。
因此,新增的双目运算操作可分为以下2步:(1)实现该双目运算符对应的操作函数;(2)记录该双目运算符与上述函数的映射信息。
利用LLVM IR Builder编写LLVM函数,可以实现range与标量的加法运算。在该函数中,仅需实现成员变量base和limit与标量的加法,并保持inc不变即可。函数编写完毕后,记录该函数与双目加法操作符的映射信息。此外,应进行溢出检查。当成员变量base、limit和inc3者之一的值为inf时,应先将range转换成matrix,再计算其与标量的和。此时部分未溢出的元素正常计算得到结果,而溢出部分的元素标记为inf。
同理可实现range的其他运算操作,如表3的第28~35行所示。
4.3 优化特性实验结果与分析
实验环境的系统架构中,包含了2个关闭超线程的18核Intel(R)Xeon(R)Gold 6150 CPU,所有核心锁定2.70 GHz主频;共享192 GB内存;操作系统为CentOS Linux release 7.6.1810。
本文对优化特性分别进行迭代测试,迭代次数为213~224。测试重复执行10次,将其中得到的最小JIT编译前用时、最小JIT编译后用时分别保留,并由二者的比值得到加速比。测试参数中,矩阵均为10阶方阵,range值为1∶1000。表3展示了迭代次数为224的测试结果。图7~图9分别展示了JIT编译前用时、JIT编译后用时、加速比的测试结果。其中图7~图9的样例编号所对应的测试内容如表3所示,图中的横纵坐标轴是以2为底数的对数坐标轴。
如图7所示,每个样例的JIT编译前用时与迭代次数呈线性关系。此时样例代码由解释器执行,解释器执行每条语句的时间恒定,从而每轮迭代的时间恒定,样例的执行效率不会随着迭代次数增加而出现明显变化。

Figure 7 Running time of optimization features without JIT compilation
JIT编译后用时由JIT编译用时和机器指令执行用时组成。如图8所示,随着迭代次数的增加,机器指令执行用时增加,而JIT编译用时不变,使得JIT编译后用时增加。若迭代次数较少,此时JIT编译用时远大于机器指令执行用时,则迭代次数增多导致的机器指令执行用时增加,对样例总运行时间的影响十分微小。若迭代次数足够多,使得机器指令执行用时远大于JIT编译用时,则样例总运行时间与迭代次数在对数坐标系下几乎呈线性关系。

Figure 8 Running time of optimization features with JIT compilation
从图9可看出,JIT编译所带来的加速效果随迭代次数的增加逐渐提升且最终趋于稳定。当迭代次数增加至224时,可视为对每个样例的JIT编译均达到了最佳效率。此时JIT编译的加速效果如表3所示,表3所展示的数据均保留了3位小数。其中,“实现方式”和“加速比”2列预示使用LLVM和C++编写的JIT函数取得的加速效果相近。例如,样例1和样例3是特化为LLVM内置函数的实现,样例10是使用C++编写的函数作为外部函数的实现,二者均取得了260倍以上的加速效果。因而本文额外将样例1和样例3等使用LLVM实现的标量操作改为使用C++标准库函数实现,得到了与使用LLVM实现相近的JIT编译后用时与加速比。
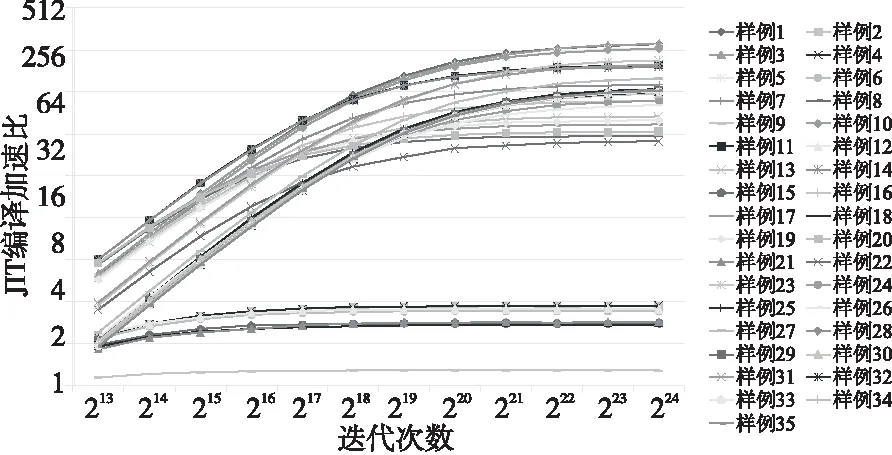
Figure 9 Speedups of optimization features with JIT compilation
从表3可以看出,直接调用Octave解释器原有函数实现的JIT函数取得的加速效果不佳。实际上,此类优化特性在JIT编译前后调用的是同一个内置函数实现,因而开销最大的函数体执行时间是相同的,只是因为JIT编译减小了解释开销,从而取得了一定的性能提升。此外,以上优化特性中部分函数的C++实现与Octave解释器原有实现相同,将此类函数的JIT实现方式改为直接调用Octave解释器函数,后者的JIT函数加速比最高仅为10倍,这表示当前Octave JIT编译器调用解释器函数的实现方式并不高效。
总之,测试结果说明了JIT编译器的加速规律:将Octave内置函数特化为LLVM函数的加速比,与特化为C++实现的外部函数的加速比相似,且远远大于调用原有的Octave内置函数得到的加速比。该规律也为未来的工作指明了方向:为取得更好的JIT加速效果,应把原本直接调用Octave内置函数实现的JIT函数改为使用LLVM或C++实现。
4.4 LU分解实验结果与分析
矩阵LU分解是常见的基准测试之一,MATLAB[10]和Linpack[11]均使用LU分解进行性能测试。本节以LU分解作为基准测试,对上述Octave JIT编译器性能优化进行验证。由于Octave内置的LU分解函数通过调用LAPACK库函数实现,使用Octave内置的LU分解函数无法有效验证Octave JIT编译器性能优化的效果。为此本文使用Octave代码实现了LU分解函数,并以此为基准测试,验证本文对Octave JIT编译器的性能优化效果。
上述LU分解函数采用杜尔里特算法(Doolittle algorithm)[12]实现,对于n阶方阵,该算法的时间复杂度为O(n3)。基准测试分为2部分:(1)固定矩阵阶数为10阶,改变实验的迭代次数,实验结果如图10所示;(2)固定迭代次数为2 048次,改变实验的矩阵阶数,实验结果如图11所示。与前述实验不同,由于LU分解计算量大,单次迭代用时长,故采用以固定步长递增的迭代次数,而非以指数形式递增的迭代次数。因此,本节实验结果的展示使用普通坐标。

Figure 10 Running time and speedups of LU decomposition with different number of iterations

Figure 11 Running time and speedups of LU decomposition with different matrix order
图10展示的不同迭代次数下的实验结果与4.3小节的优化特性实验结果相符。图10a表明,LU分解函数的JIT编译前、后用时与迭代次数均呈线性关系,且JIT编译后用时远小于编译前用时。图10b表明,随着迭代次数的增加,JIT编译的加速比从43倍上升到了62倍,并最终趋于稳定。
为便于实验结果分析,图11a中展示的JIT编译前、后用时采用了立方根用时。图11a表明,LU分解函数的JIT编译前、后的立方根用时与矩阵阶数呈线性关系。这是由于对该函数实现而言,增加矩阵规模实际上是增加迭代次数,且该函数的时间复杂度为O(n3)。图11b说明,随着矩阵阶数的增加,JIT编译加速比从3倍增加到了66倍,并最终趋于稳定,且稳定值高于图10b中的稳定值62倍。其原因为:当矩阵规模变大时,该算法内部的迭代次数增多,对最外层的单次迭代而言,解释器执行用时与JIT编译后的机器指令执行用时均增加,但解释器执行用时的增加速度大于机器指令执行用时的增加速度。
4.5 Octave JIT编译器现有缺陷
基于前文的分析和评估工作,本文对Octave JIT编译器完成了部分优化工作,未来工作中将进一步对Octave JIT编译器进行性能优化。为此,本文分类总结了Octave JIT编译器的现有缺陷,如表5所示。

Table 5 Defects summary of Octave JIT compiler
缺陷1:指Octave JIT编译器不支持对命令窗口(含控制台)中执行的语句进行JIT编译,而仅支持“.m”文件的JIT编译。
缺陷2:指原Octave内置的JIT编译器代码组织凌乱、杂糅,将本不耦合的代码置于同一个代码块中。加之缺陷3中描述的文档与注释的缺乏,源码分析过程存在很大阻碍。
缺陷4:指Octave JIT编译器仅支持对循环语句进行JIT编译,仅利用循环语句自身的信息会丧失大量编译优化空间。
缺陷5:指Octave JIT编译器不支持“parfor”循环并行语句。Octave解释器已在语义分析阶段生成“parfor”语句对应的Octave AST,但Octave JIT编译器并未对该AST进行代码生成。
缺陷6:指Octave JIT编译器在对循环进行JIT编译时,其边界检查条件冗余,在一定情况下可以消除或简化。
缺陷7:指Octave JIT编译器在循环的入口和出口处,均会对矩阵一类的大型对象进行拷贝构造,这是无意义的内存拷贝。
缺陷8:指Octave解释器与JIT编译器均存在内存泄漏问题。借助内存泄漏检测工具Valgrind,可发现解释器本身存在少量内存泄漏,而JIT编译器存在更多的内存泄漏。
缺陷9:指Octave JIT编译器仅支持对矩阵和range类型的单维索引,多维索引、切片索引和cell类型的索引操作均不支持。
缺陷10:指Octave JIT编译器无法充分利用上下文信息对索引时的索引值检查进行优化,其合法性检查在部分情况下可由LLVM本身实现,而目前的实现方式均是通过调用外部函数实现的。
缺陷11:指Octave JIT编译器的类型支持并不完善,许多Octave原生数据类型并未得到JIT编译器的支持。此外,当前类型系统的类型格并不符合类型的实际意义,例如在类型格中int类型与scalar、complex类型均不存在偏序关系。
缺陷12:指Octave JIT编译器对2类Octave内置函数的支持均十分有限。几乎所有使用Octave语言实现的、以“.m”文件形式存在的内置函数均无法进行JIT编译;而JIT编译器直接调用由C++实现的、硬编码在Octave解释器中的内置函数取得的加速效果最高不过10倍,无法在具体实践中应用。
缺陷13:指Octave JIT编译器对大部分数据类型的运算操作支持有限,除本文完善的range类型运算外,仅对scalar类型的支持比较完善。
缺陷14:指Octave JIT编译器未实现函数重载机制,无法基于类型格中的偏序关系完成隐式类型转换。
缺陷15:指Octave JIT编译器未完全实现AST到JIT IR的转换。如异常处理中的try catch表达式、函数的多返回值、多返回值对应的多赋值等多种语句的转换均不支持。
缺陷16:指Octave JIT编译器未对体系结构进行检测,而是完全假设目标环境为X86或X86_64。
5 结束语
本文探究了Octave内置JIT编译器的性能优化方案,通过提高该JIT编译器的性能,提升Octave整体的运行效率。本文首先对Octave的内置JIT编译器进行了整体编译流程分析,并着重分析了该JIT编译器的类型推断系统。其次,通过不同类别的样例对Octave JIT编译器进行了功能和性能分析,指明了本文的优化方向。然后,针对内置函数调用、索引运算和算术逻辑运算的类型支持2个重点,对该JIT编译器进行了优化。实验结果表明,本文的优化工作扩展了Octave JIT编译器对Octave代码的适用范围,从而有效提升了Octave数值计算的性能。最后,本文总结了Octave JIT编译器的现有缺陷,未来将针对这些缺陷开展更多优化工作。
猜你喜欢
心理学探新(2022年1期)2022-06-07
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
广东教学报·教育综合(2020年15期)2020-03-23
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
军事文摘·科学少年(2016年10期)2016-12-08
中国继续医学教育(2015年3期)2016-01-06
社会心理科学(2015年6期)2015-02-07
中学教学参考·文综版(2014年1期)2014-03-11
组合机床与自动化加工技术(2014年10期)2014-03-01
