
基于智能算法的高校智能快递柜选址问题研究
2022-12-26 15:11万波,卢洲
物流技术 2022年11期
万 波,卢 洲
(江汉大学 商学院,湖北 武汉 430056)
0 引言
近年来,云计算、物联网和移动通信等新技术的快速发展推动着电子商务高速发展,进而给传统物流行业带来了机遇与挑战。传统配送方式有着诸如快递服务人员有限、投递乱、快递丢失等问题。高校快递一般都是集中放在快递驿站,然后由快递驿站的服务人员将师生的快递扫码登记以后,通过短信的形式告知客户,这项工作不仅要耗费大量的劳动力,而且还容易出现错误。此外快递驿站的运营时间并不是全天的,导致部分师生无法及时领取快递。特别是“双十一”活动和开学季快递量激增,快递驿站的服务能力有限,取件时需要自己在大量的快递中寻找,不仅浪费了师生的时间,而且还降低了其对快递服务的满意度。
智能快递柜是一套智能化的设备,具有快递存储、通信等功能。它可以识别和读取包裹上客户的相关信息,并将客户包裹的位置和取件码自动发送到客户的手机上[1]。此外,智能快递柜具有存取操作简单、24小时无人看管运行、取件全程监控和柜体根据实际需求安装等优点。在新冠疫情的影响下,智能快递柜的使用可以减少人群接触,实现无接触式的快递配送方式,不仅可以减少快递配送过程中产生的成本,而且极大地满足了师生随时取件的需求,为在校师生提供便利的同时,也有利于学校减轻疫情防控的难度和保障师生的健康[2]。因此,对高校智能快递柜进行合理的选址和布局具有重要的现实意义。
1 文献综述
随着电子商务的快速发展和新冠疫情的持续蔓延,在智能快递柜的选址研究上,国内学者分别采用了不同的算法模型进行深入研究,如张梦露[3]运用层次分析法对山东理工大学进行智能快递柜选址,旨在提升快递配送效率。张西莎,等[4]在对社区楼栋分布和快递接收量进行调查的基础上,建立集合覆盖模型和运用层次分析法对社区内现有的智能快递柜进行重新选址。刘程程,等[2]在新冠疫情影响下提出了一种智能快递柜的选址模型,旨在解决无接触配送问题,并以哈尔滨香坊区为验证对象,结果表明该模型的使用能够减少人员接触。黄杜鹃,等[5]为了弥补乡镇智能快递柜布局的空缺,运用AHP-TOPSIS组合模型确定候选乡镇,然后利用Dijkstra算法来求解最优选址方案。冯瑛杰,等[6]为避免突发事件的影响,构建了紧急物流设施选址模型,设计了非支配遗传算法对选址模型进行求解。郭静文,等[7]将遗传算法运用在城市消防站选址问题求解中,结果表明遗传算法有助于平衡消防站布局中的安全性和经济性问题。刘善球,等[8]以物流配送中心为选址对象,结合建设成本等因素建立选址模型,并运用遗传算法对算例进行求解,结果验证了遗传算法在选址问题求解中的有效性。
对基于免疫算法的选址问题,国内学者进行了创新性的研究,如刘东运,等[9]在研究同时送取货选址路径问题时,建立了仓储成本和运输成本目标和最小的选址模型,运用混合免疫算法对其进行求解,结果表明混合免疫算法和免疫算法的求解结果均优于粒子群算法和模拟退火算法。淦艳,等[10]提出了由配送时间和需求量共同决定权值的选址模型,并运用免疫算法求解该选址问题,通过实例分析发现与不带配送时间相比,该模型得到的结果其配送距离和运行时间更少。HUANG,等[11]在研究逆向物流中心设施选址时,将免疫算法模型引入到该问题的求解中,系统地探讨了免疫算法的收敛性。该模型不仅为逆向物流网络的设施选址策略优化提供了一种新颖的解决方案,而且拓展了人工免疫系统的应用领域,丰富了现有的人工免疫系统模型。仿真研究表明,与遗传算法相比,免疫算法收敛速度更快,解更精确,更能保持抗体群的多样性。
文献[2-5]对智能快递柜的选址研究主要采用层次分析法,并没有采用其他方法进行对比。文献[6-8]中传统的遗传算法在求解复杂的选址问题时难以快速得出有效解,而改进的非支配遗传算法具有高计算复杂度,且随着种群数的增加呈指数增长。文献[9-11]在运用免疫算法的同时引入了其他算法进行比较,且求解结果均优于遗传算法。鉴于目前还没有学者将免疫算法运用到智能快递柜选址研究中,本文试图将免疫算法运用到高校智能快递柜选址方案的研究,以获得更好的求解质量。
2 模型建立
2.1 模型假设
为便于选址模型的建立,给出以下假设:(1)每个区域内的布局数量基于该区域内需求点的学生人数;(2)区域内的需求点用离散型需求点集合I表示,最终的选址点从设施点集合J中产生;(3)该模型考虑需求的全覆盖、需求点就近分配给设施点、需求点单一分配给设施点及开放与关闭设施数目限制等约束条件。
2.2 参数与决策变量定义
模型所用符号说明如下:
I:需求点集合,I={1,2,...,n};
J:设施点集合,J={1,2,...,m};
dij:需求点i到设施候选点j的距离;
P:开放设施点的数量;
Cj:设施点j所能服务的数量,即设施点j的服务容量;
ωi:需求点i的需求量;
Xj:0-1变量,当Xj=1时,表示在候选设施点j处安装智能快递柜;否则,Xj=0。
Yij:0-1变量,当Yij=1时,表示需求点i处的师生由设施点j进行服务,即在此处的智能快递柜拿取快递;否则,Yij=0。
2.3 模型构建
根据需求点到所选择的设施点之间的距离和需求量,可以得到师生的总出行距离,即基于P-中位模型的目标函数为:

s.t.

目标函数式(1)为最小化师生从需求点(教学楼、宿舍)到设施候选点(智能快递柜)的总出行距离;式(2)确保每个需求点都有相应的设施点服务,且仅被一个设施点服务;式(3)表示只有候选设施点处安装了智能快递柜,师生才可以去拿取快递;式(4)、式(5)为决策变量的取值范围。
3 算法介绍
选址模型的优化求解大致分为精确算法和非精确算法两类,精确算法能够找到精确解,在简单优化问题的求解上有优势。随着选址问题的规模越来越大,精确算法会出现难以求出最优解的情况,从而促进了以启发式算法为代表的非精确算法的应用[12]。经典P-中位选址问题属于NP-难问题[13],即是一类计算时间复杂度大的问题,无法在短时间内得到精确的解,基于此,人们退而求其次,运用启发式算法寻求决策问题的满意解。
遗传算法(Genetic Algorithm)是一种启发式搜索算法,由美国J.H.Holland教授与他的同事和学生于1975年提出[14]。GA把问题参数编码为染色体,再利用迭代的方式进行选择、交叉以及变异等运算,将最大的适应度个体作为最优解[15]。但大量的实践和研究表明,经典遗传算法存在局部搜索能力差和“早熟”等缺陷,不能保证算法收敛[16]。
Chun,等[17]提出了一种免疫算法(Immune Algorithm),实质上是改进的遗传算法。根据体细胞和免疫网理论改进了遗传算法的选择操作,从而保持了群体的多样性,提高了算法的全局寻优能力,克服了一般寻优过程尤其是多峰函数寻优过程中难处理的“早熟”问题[18]。通过在算法中加入免疫记忆功能,提高了算法的收敛速度。在现有的许多文献中,出现了针对经典遗传算法的各种改进算法,并取得了一定的成效[19-21]。因此,本文根据P-中位选址模型的具体特征,设计了免疫算法对其求解。
3.1 初始抗体群的产生
如果记忆库非空,则初始抗体群从记忆库中选择生成。否则,在可行解空间随机产生初始抗体群。本文采用简单编码方式。每个选址方案可形成一个长度为n的抗体(n表示设施点的数量),每个抗体代表被选为配送中心的需求点的序列。例如,考虑包含54个需求点的问题。1,2,…,54代表需求点的序号。从中选出8个作为智能快递柜的设施点。抗体[2 7 25 31 18 42 36 51]代表一个可行解,它表示2,7,25,31,18,42,36,51被选为智能快递柜的设施点。
3.2 解的多样性评价
解的多样性评价包括抗体与抗原之间亲和力、抗体与抗体间亲和力、抗体浓度和期望繁殖概率四个方面。
3.2.1 抗体与抗原之间的亲和力。抗体与抗原之间的亲和力用于表示抗体对抗原的识别程度,针对本文的选址模型设计亲和力函数Av:

其中Fv为目标函数;分母中第二项表示对违反距离约束条件的解给予惩罚,C是一个较大的正数,本文取C=3 000。
3.2.2 抗体与抗体间亲和力。抗体的亲和力反映了它们的相似程度。计算参考了Forrest,等提出的R位连续法,抗原的编码方法不考虑排序。我们使用可变形R位连续方法来计算亲和力,即:

其中L为抗体的长度,kv,s为抗体v和抗体s编码中相同的位数。
3.2.3 抗体浓度。抗体浓度Cv代表群体中相似抗体所占的比例,即:

其中,N为抗体总数;T为预先设定的一个阈值。
3.2.4 期望繁殖概率。在群体中,每个个体的期望繁殖概率由抗体与抗原间亲和力Av和抗体浓度Cv两部分共同决定,即:

其中α是常数。由式(9)可知,抗体与抗原之间的亲和力越高且抗体浓度越低,抗体的期望繁殖概率就越高。这样既鼓励了适应度高的个体,同时抑制了浓度高的个体,从而确保了个体的多样性。
3.3 免疫操作
(1)选择。按照轮盘赌法的选择机制进行选择操作,个体被选择的概率即为式(9)计算出的期望繁殖概率。
(2)交叉。本文采用单点交叉法进行交叉操作。
(3)变异。采用常用的变异方法,即随机选择变异位进行变异。
4 算例分析
以江汉大学校园为例,根据小型区域(宿舍楼栋、教学楼)的划分,共有54个需求点,准备设置8个设施点。
通过百度地图找出校园中每个需求点的经纬度坐标,对校园进行实地调查,计算出每栋宿舍楼的居住人数,然后根据人数确定每栋宿舍楼的具体需求量,大学的教学楼等地由于情况特殊,学生上课的教室不固定,流动性较大,因此各个教学楼的需求量根据各个学院的人数乘上一定的比例来确定。需求点和需求量的相关数据见表1。

表1 各需求点的需求量一览表
4.1 利用EWM确定设施候选点
在整个校园内初步选取了17个设施候选点,候选设施点包括在需求点中,利用EWM进行初步筛选。候选设施点的初始指标数据由以下几个因素构成:设施点附近的师生人数、一定距离内是否有快递驿站、是否位于主干道和女生所占比例[22]。在校园中,人数越多快递量就会越大,所以人数的多少是非常重要的因素,本文主要是通过实地调查各个宿舍楼栋的寝室间数再乘以每个宿舍的人数就得出了每栋楼的具体人数;快递驿站和快递柜之间有一定的竞争关系,所以需求点距离快递驿站越远,就越有利于智能快递柜的选址;高校网购群体中,女生占据绝对比例[22],所以女生比例越大的区域,对智能快递柜的需求量就越大。通过收集相关的数据得到原始数据矩阵,通过对原始矩阵归一化处理,得到归一化矩阵。
对归一化矩阵经过一系列的计算,可得到4个评价指标的信息熵值和权重值,结果见表2。将权重值与对应的原始值相乘,便可得到17个候选设施点的综合得分s=(5.02 6.44 5.55 7.86 6.12 8.69 7.10 6.67 6.17 4.96 6.04 5.45 5.74 6.99 5.57 5.26 5.25)。根据综合得分s值的大小,选取综合得分高的13个候选设施点:2、5、6、13、17、19、20、26、29、31、35、40、46号。
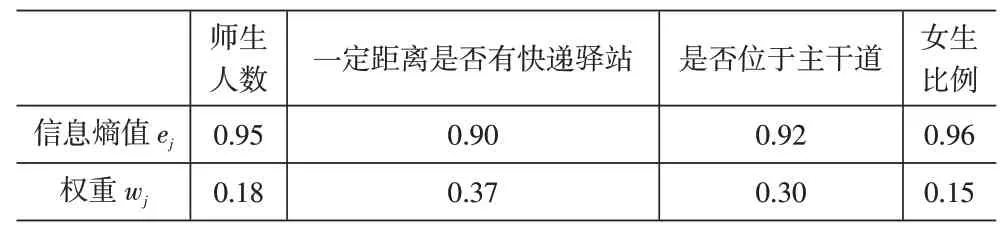
表2 信息熵值和权重值
4.2 算法求解与分析
本文采用免疫算法和遗传算法对选址模型进行求解。其参数设置是算法能够有效运行的关键,因此本文在算法参数的设置上参考了文献[18,23],具体的参数值见表3和表4。

表3 免疫算法参数一览表

表4 遗传算法参数一览表
对免疫算法和遗传算法的参数进行设置之后,就可以在实验环境为AMDRyzen7 5800H CPU@3.2GHz,16GB内存,操作系统为64位windows10,使用MatlabR2020a进行编程。
(1)选址与分配情况。免疫算法选址分配情况见表5 ,遗传算法选址分配情况见表6。
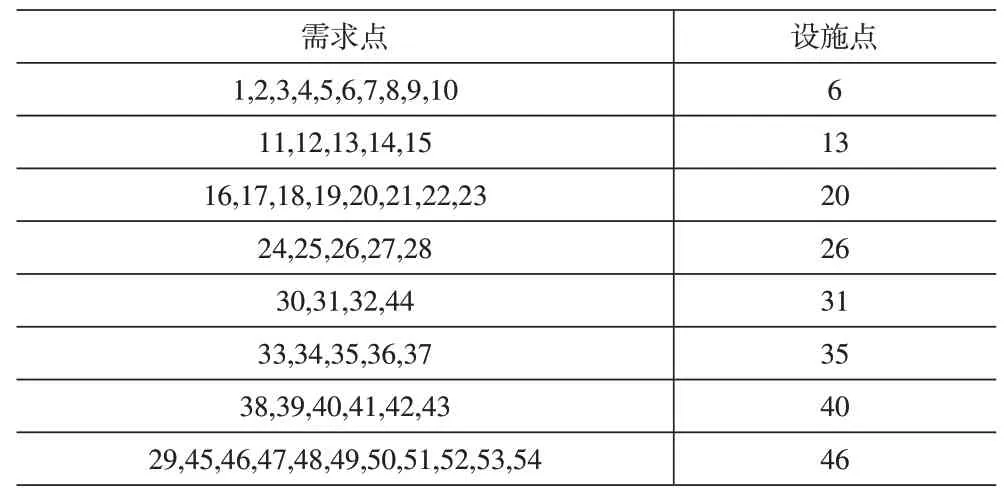
表5 免疫算法需求点对应的设施点

表6 遗传算法需求点对应的设施点
免疫算法选址示意图如图1所示,遗传算法选址示意图如图2所示。

图1 免疫算法选址与分配情况

图2 遗传算法选址与分配情况
(2)求解质量分析。通过两种算法选址结果可以发现,免疫算法求解的选址点主要集中在宿舍楼群、师生每天经过的主干道和图书馆附近,并且在选址点的分配上也是宿舍楼群下分配的多,符合实际情况。而遗传算法求解的选址点在教学楼群分配的较多,这种分配方式既不符合高校师生的生活习惯,也没有做到给师生提供便利的初衷。此外,北区是学校学生生活的主要区域,宿舍楼群庞大,而遗传算法在选址点的分配上只分配了三个点,这将会给师生的取件带来不便,尤其是在“双十一”促销活动和开学期间。由表7中的目标函数值和算法运行时间可知,免疫算法最终求解的目标值比遗传算法小,且速度更快。通过上述比较发现免疫算法相比遗传算法而言能够获得更为满意的解。

表7 免疫算法和遗传算法运行结果比较
算法求解结果的差异在于免疫算法时对遗传算法的改进,此外遗传算法在进行全局搜索是容易进入“早熟”状态,而免疫算法做到了在寻优过程中克服进入“早熟”的问题,进而得到全局最优解。从图2中的选址情况可以发现,遗传算法提前进入了“早熟”状态,陷入了局部最优解,导致选址点的分配出现不合理的情况。此外,免疫算法和遗传算法在对个体的评价和选择方式上也有所不同,遗传算法对个体的评价主要是通过计算个体的适应度得到的;而免疫算法则是通过计算亲和度得到的,个体的选择是以亲和度为基础进行,且亲和度包括抗体与抗原之间的匹配程度和抗体之间的相似程度,因此,免疫算法对个体的评价更加全面,求解出的结果也更加合理。
(3)算法收敛性分析。图3中免疫算法在迭代运行到30代就已经收敛,而图4中遗传算法在180代之前收敛曲线一直处于震荡状态,直到迭代到180代时才开始收敛。通过以上数据对比发现,免疫算法相比遗传算法而言具有较好的收敛性。

图3 免疫算法收敛曲线
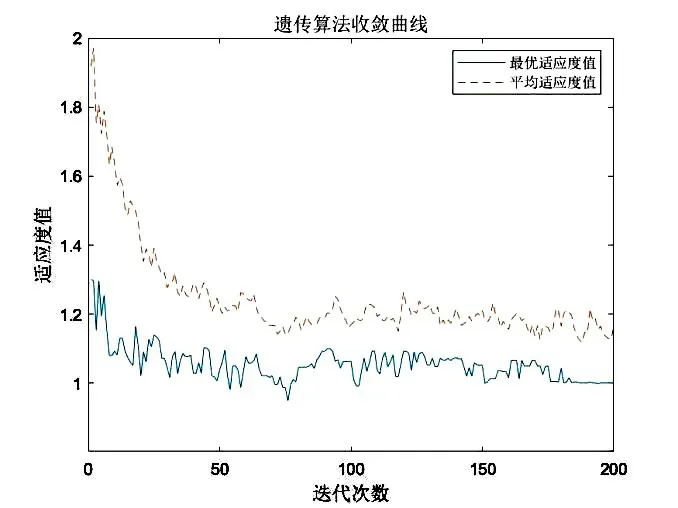
图4 遗传算法收敛曲线
算法收敛性的差异在于遗传算法通过交叉、变异等遗传操作产生新个体,而在免疫算法中,虽然交叉、变异等固有的遗传操作也被广泛应用,但是新抗体的产生还可以借助克隆选择、免疫记忆、疫苗接种等遗传算法中所欠缺的机理。其中,免疫记忆的主要作用是当免疫系统再次进行免疫应答时,可以加速优化搜索过程;克隆选择的主要作用是在抗原的刺激下,对抗体进行快速大量的复制操作,提高抗体的浓度和加速亲和度“成熟”的过程,从而可以快速的得到最优解。同时免疫算法还对抗体的产生进行促进或者抑制,体现了免疫反应的自我调节功能,保证了个体的多样性。
(4)算法稳健性分析。本文以江汉大学校园为对象,随机产生100个算例,分别运用免疫算法和遗传算法进行求解,发现免疫算法所求得的目标函数值平均值小于遗传算法,免疫算法运行时间的平均值也小于遗传算法,具体见表8。大量算例验证表明免疫算法具有较好的稳健性。

表8 免疫算法的稳健性分析
5 结语
本文构建以取件距离最短为目标的智能快递柜选址优化模型,并以江汉大学为研究区域,运用免疫算法与遗传算法进行智能快递柜选址研究。首先,对影响设施选址的因素运用熵权法来计算其权重,确定设施候选点;然后根据高校特点构建取件距离最短的选址优化模型进行选址,并分别采用免疫算法和遗传算法对选址模进行求解。结果表明相对于遗传算法而言,免疫算法对求解该模型有更好的收敛性和可行性,对高校校园智能快递柜选址有一定的参考作用。
今后,在算法方面,可以在经典免疫算法的基础上进一步改进或者使用混合算法进行求解,以增加算法求解的快速性和准确性;在模型建立上,可以在建立选址模型时考虑更多影响选址因素,如引入智能快递柜和快递公司成本最小和师生取件距离最小的多目标决策问题,使建立的模型运用范围更广和贴近实际需求。
猜你喜欢
今日农业(2021年20期)2022-01-12
中国现代医药杂志(2020年10期)2020-12-14
江苏安全生产(2020年4期)2020-05-30
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中国公路(2017年5期)2017-06-01
统计与决策(2017年2期)2017-03-20
现代检验医学杂志(2016年3期)2016-11-15
中国环境监察(2016年11期)2016-10-24
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
