
基于不同模型的赣南地区小型削方滑坡易发性评价对比分析
2022-12-30 11:43郭飞王秀娟陈玺王力谢明娟李玉谭建民
中国地质灾害与防治学报 2022年6期
郭飞,王秀娟,陈玺,王力,谢明娟,李玉,谭建民
(1. 湖北长江三峡滑坡国家野外科学观测研究站,湖北 宜昌 443002;2. 三峡大学土木与建筑学院,宜昌 443002;3. 中国地质环境监测院,北京 100081;4. 中国科学院新疆生态与地理研究所,新疆 乌鲁木齐 830011;5. 中国地质调查局武汉地质调查中心(中南地质科技创新中心),湖北 武汉 430205)
0 引言
易发性评价作为滑坡风险评估的基础工作,是近些年来国内外的研究热点,其评价结果也为防灾减灾工作提供了参考。目前我国滑坡易发性评价主要集中于发育规模较大的水库型滑坡[1−3]、黄土滑坡[4−5]、地震诱发滑坡[6−7]以及降雨型滑坡[8−9],在易发性评价指标、评价模型等方面积累了较多经验。但由于赣南地区滑坡灾害点多、面广、规模小,且90%以上的滑坡是因人工切坡导致的,这些滑坡与前述滑坡在规模、成因机制等方面存在显著差异,上述滑坡易发性评价所积累的经验并不能完全适用赣南地区滑坡易发性评价,仍需在指标体系、评价模型等方面进一步探索。
彭珂等[10]指出赣州市地质灾害的发生与该区地形地貌、地层岩性、岩土体类型及人类工程活动呈正相关关系。通过现场调查,人工切坡和降雨是赣南地区滑坡灾害最主要的诱发因素,赣南于都县银坑镇多以修路切坡为主[11]。目前开展的易发性评价对小型削方滑坡的指标多以距道路距离[12]表征,部分学者尝试采用道路空间密度[13]表征,对于小型削方滑坡的表征指标仍需进一步探索。
目前,滑坡易发性评价模型主要分为知识驱动、数据驱动和机制驱动模型三大类。在目前易发性评价中数据驱动模型应用最为广泛,常见的数据驱动模型包括随机森林[13]、信息量(I)[14]、支持向量机(SVM)[4]、逻辑回归(LR)[15]、人工神经网络(ANN)[16]、决策树(DT)[5]、确定性系数法(CF)[17]等。这些模型在水库型、地震型和降雨型滑坡易发性评价中应用较为成熟,而对于赣南地区小型削方滑坡易发性的适用性,仍需进一步探索。
文中以赣州于都县银坑镇为例,根据野外地质调查成果,利用地理探测器构建易发性评价指标体系,选取信息量、人工神经网络、决策树和逻辑回归模型开展易发性评价,并对模型精度进行验证以分析赣南地区小型削方滑坡易发性评价模型的适用性。
1 研究区概况
银坑镇位于江西省赣州市于都县北部,属典型的亚热带季风湿润气候,雨量充沛、四季分明。降雨量多集中于3—6 月,约占全年降水的55.4%。区内多为山地与丘陵,岗地与平原较少,强风化岩浆岩、变质岩广泛分布,复杂的地质环境条件极易产生地质灾害。常见地质灾害类型主要为崩塌、滑坡、泥石流等,主要发生在5—8 月,尤其是6 月,与当地雨季吻合,并存在滞后性。
根据现场调查,区内共有164 处滑坡灾害点(图1),滑坡点体积分布为38.5~3 045.0 m3,小于1 000 m3的滑坡占80%以上,多数为土质滑坡,极少数为岩质滑坡。滑坡主要集中于研究区南部,多发生在屋后和道路旁,这主要是由建房和修路切坡导致的,其中修路切坡诱发的滑坡占比较大,人工切坡一般会形成3~5 m 的陡坡,且鲜有护面或排水措施,在降雨作用下极易形成滑坡。
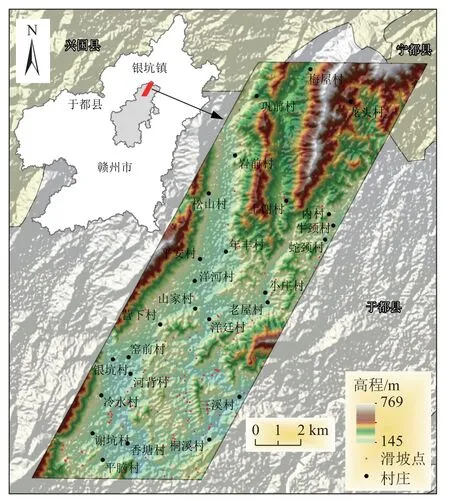
图1 银坑镇地理位置以及滑坡点分布图Fig.1 The distribution of landslides and location of Yinkeng Town,Yudu County
2 滑坡易发性评价方法
2.1 信息量模型(I)
信息量模型是基于信息论的一种统计方法,通过熵的变化来体现易发性程度[18]。信息量模型考虑了各评价因子之间的相关性,适用于不同比例尺的易发性评价中。该模型是以信息论为理论基础,其基本观点为将已有地质灾害影响指标分类并转化为影响大小的信息量值,进而利用信息量的值来评价各指标与研究对象的相关程度,信息量值越大,则代表越有可能引发滑坡等地质灾害,其计算公式为:

式中:I(Y1,x1,x2,···,xn)——各影响指标的信息量值;
P(Y,x1,x2,···,xn)——各影响指标组合条件下滑坡等地质灾害发生的概率;
P(Y)——滑坡灾害发生概率。
通常情况下,影响滑坡等地质灾害的指标种类较多,相对应各指标的组合状态也比较多,而通常样本统计的数量会受到限制,故一般情况下可先对每个单因素指标信息量模型进行分步计算,再进行综合叠加分析,其对应的信息量模型为:

式中:I——研究区域某指标x信息量值;
Ii——研究区域某指标xi信息量值;
Si——指标xi所占单元总面积;
——因素xi单元中发生滑坡灾害的单元面积之和;
A——区域内单元总面积;
A0——已经发生滑坡灾害的单元面积之和。
2.2 人工神经网络模型(ANN)
人工神经网络模型是进行分布并行信息处理的一种算法数学模型。通过其自学习和训练,建立输入因子与输出结果的关系,该模型通常用于非线性回归和分类问题[19]。而其中的BP 神经网络最具有普遍性和代表性,其结构分为输入层、隐藏层和输出层,其中输入层为影响因子,隐藏层为问题复杂性程度,输出层为结果[20]。
2.3 决策树模型(DT)
决策树是在已知情况发生概率的基础下,通过求取净现值的期望值大于等于零的概率,来评价项目可行性的一种分析方法。文中采用ID3 算法,该算法通过熵来度量信息的不确定度[21]。在信息论中,熵叫做信息量,是来衡量变量的不确定性的,其表达式为:
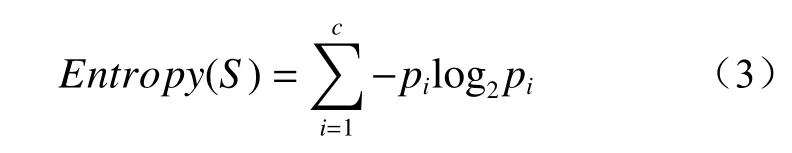
式中:c——划分的类别总数;
pi——各个分类的概率。
2.4 逻辑回归模型(LR)
逻辑回归是一种概率与统计模型,在易发性研究中,将影响灾害发生的因子作为自变量,灾害是否发生(0 为不发生,1 为发生)作为二值因变量[15,22]。逻辑回归的表达式为:
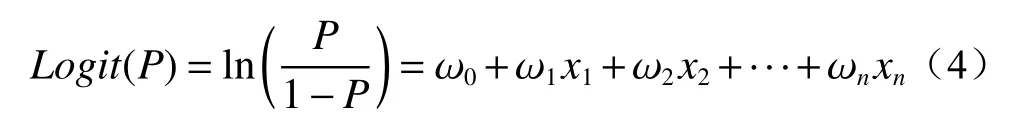
式中:Logit(P)——指为P做的Logit变化;
P——滑坡发生的概率;
1−P——滑坡不发生的概率;
x1,x2,···,xn——各影响因子的值;
ω0,ω1,···,ωn——回归系数。
3 数据分析
3.1 评价单元
评价单元是易发性评价的最小单元,其选取的依据很大程度上受滑坡的空间尺度、评价范围和资料详细程度的影响,文中采用栅格单元来进行易发性评价,与其他评价单元相比在处理大量空间数据叠加上显得更加便捷。另外,考虑到研究区内滑坡规模较小,栅格分辨率选用5 m×5 m,研究区共分为5 518 864 个栅格单元。
3.2 评价指标的选取
指标体系的构建对滑坡易发性评价结果的合理性起着决定作用[23]。通过野外地质调查及滑坡灾害与各评价指标的相关性统计分析,从地形地貌、地层岩性、地质构造、植被条件等方面初步筛选评价指标,再利用地理探测器对上述指标进行贡献排序,从而构建滑坡易发性指标体系。
地理探测器是探测空间分异性以及揭示其背后驱动力的一组统计学方法[24]。其核心思想是若某个自变量对某个因变量有重要影响,那么自变量和因变量的空间分布应该具有相似性。地理探测器具有两大独特优势,一是可以探测数值型数据和定性数据,二是探测两因子交互作用于因变量。地理探测器通过分别计算和比较各单因子q值及两因子叠加后的q值,可以判断两因子是否存在交互作用,以及交互作用的强弱、方向、线性还是非线性等。文中利用地理探测器的因子探测器探测定量(如坡度)和定性(如岩组)数据,并根据分异探测器判断两因子的交互作用,从而构建易发性评价指标体系。
指标X对于其属性Y的空间分异表达式q如下:
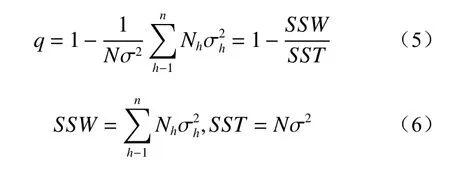
式中:q——反映空间分异程度,q∈[0,1];
h——变量Y或指标X的分层,h=1,2,···,n;
Nh、N——层h和全区Y的单元数;
SSW、SST——层内方差之和和全区总方差。
q值是指X对Y发生的贡献值,也可将其视为权重值。q值越大,表示指标空间分异性越明显,自变量指标X对于属性Y的解释能力越强,反之则越弱。
根据《赣州市地质灾害防治规划(2012—2020)研究报告》及野外地质调查分析,地形地貌选择了坡度、坡向、高程变异系数、地表切割深度、曲率等因子;地质条件考虑了岩组、坡体结构、距断层距离等因子;植被条件选择了植被覆盖率这一因子;人类工程活动,主要考虑研究区修路切坡是滑坡灾害最主要的诱发因素,因此根据常规表征方法,选择了距道路距离这一指标进行表征。
采用地理探测器的因子探测器计算出上述11 个评价指标的q值(表1),从表中可知,坡度、坡体结构、岩组、距道路距离、距断层距离、植被覆盖率等6 个指标对滑坡的贡献占95%以上,所以选其作为易发性评价指标。

表1 地理探测器得到11 个指标的q值Table 1 The normalized weight values of 11 indicators
3.3 评价指标的分析
(1)坡度:文中以1∶1 万等高线为基础生成高程TIN 模型,然后利用TIN 转栅格工具以5 m×5 m 为单位生成最终的DEM 模型,最后通过自然间断点分级法将坡度分为5 类:①0°~7°;②7°~17°;③17°~26°;④26°~36°;⑤>36°。通过坡度与灾害点叠加图见图2(a),可以看出滑坡大多发生在7°~17°和17°~26°区间内,这与人们在此切坡建房和修路密切相关。
(2)坡体结构:文中以等高线图和地层产状图绘制坡体结构,将其划分为4 类:①岩质-斜向坡;②岩质-逆向坡;③岩质-顺向坡;④碎石土质边坡。通过坡体结构与灾害点的叠加图见图2(b),可以看出滑坡大多处于岩质-顺向坡和岩质-斜向坡这两个分类当中,这与滑坡的发育分布规律较吻合。
(3)岩组:通过研究区域的地质图和结合灾害分布规律,将岩性划分为8 类:①坚硬花岗岩组;②软硬相间岩组(砾岩、粉砂岩);③坚硬岩组(石英砾岩、砂砾岩等);④较软-较硬岩组(石英砾岩、泥岩等);⑤较硬-较软岩组(粉砂岩、页岩等);⑥较坚硬岩组(砾岩、安山岩);⑦较硬-坚硬岩组(变质砂岩、变质粉砂岩等);⑧多层含砾黏土、粉质黏土。通过岩组和灾害点的叠加图见图2(c),分析可知较坚硬-坚硬的变质砂岩、变质粉砂岩等岩组中滑坡点较多。
(4)距道路距离:在研究区内以50,100,200,500,大于500 m 划分缓冲区,得出切坡修路对于研究区域的影响区域。通过道路与滑坡点的叠加图见图2(d),分析可知灾害点与道路重合度很高。
(5)距断层距离:在研究区域内以100,200,300,400,500,大于500 m 划分缓冲区,得出断层的影响区域。通过断层与滑坡点的叠加图见图2(e),分析可知灾害点与断层重合度较高。
(6)植被覆盖率:通过遥感数据,并运用ENVI 软件获取归一化植被指数(NDVI),最终在GIS 软件中通过自然断点法将形成的栅格文件划分为6 类。通过植被与灾害点的叠加图见图2(f),分析可知灾害点大多集中在植被覆盖率较低、低和极低区域。
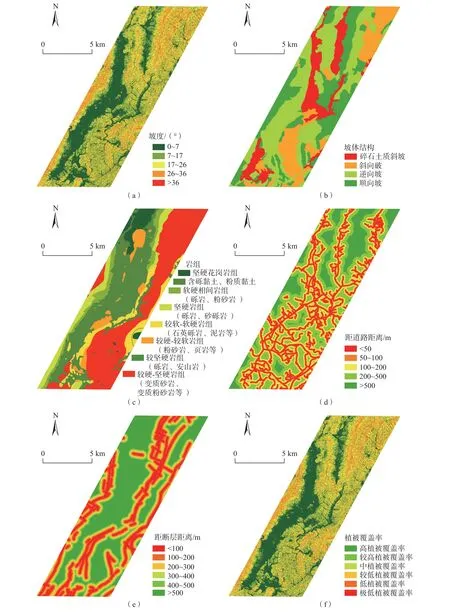
图2 易发性评价指标图Fig.2 The susceptibility evaluation index chart
3.4 结果计算
信息量模型利用信息量法计算式(2),以银坑镇地质灾害野外调查数据为基础,对6 个评价指标的信息量值进行计算,计算结果如表2 所示。
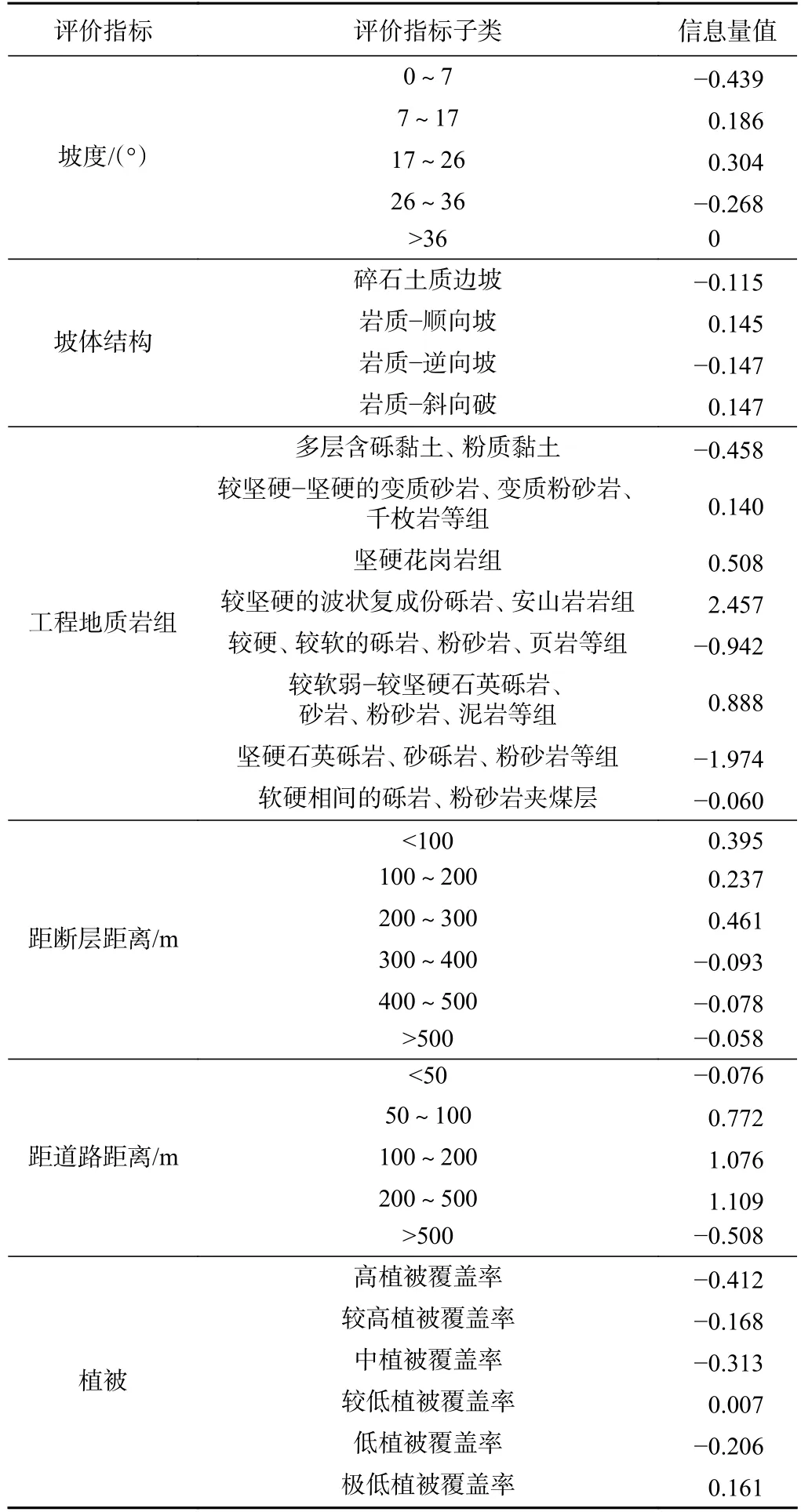
表2 评价指标各自信息量值Table 2 Each information value of evaluation index
通过对各评价指标各自的信息量值和权重值进行分析可以得知距道路距离和工程地质岩组两个指标对滑坡发生的影响较大,坡度和坡体结构次之,植被和断层影响相对较小。
4 滑坡易发性评价
4.1 易发性分区对比
基于ArcGIS 平台,利用栅格计算功能,对于各评价指标按各指标归一化的权重值进行叠加,得到易发性分布图,参考自然资源部中国地质调查局编制的《地质灾害风险调查评价编图技术要求(1∶50 000)(试行)》,根据自然断点法将易发性分布图划分为高、中、低和非易发区四级(图3)。
4.2 评价结果对比
根据图3 可以看出:高易发区主要分布于河背村、谢坑村、三溪村、小庄村、老屋村和龙头村等地区;中易发区主要分布于梅屋村、上谢村和年丰村等地区;低易发区主要分布岩前村、松山村、杨河村和窑前村等地区。人工神经网络模型和逻辑回归模型的高易发区主要集中在道路两侧。滑坡点在各个分区所占比例见表3。
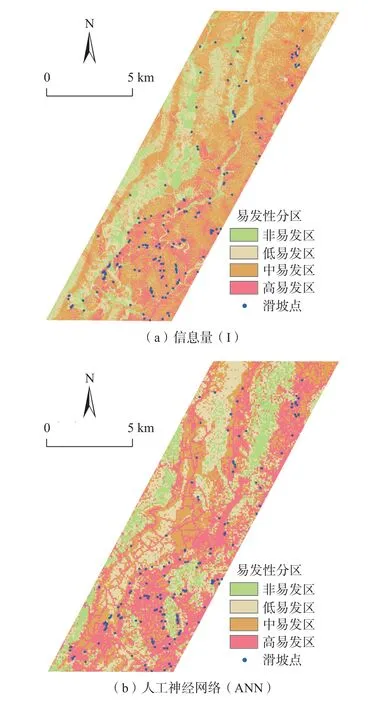
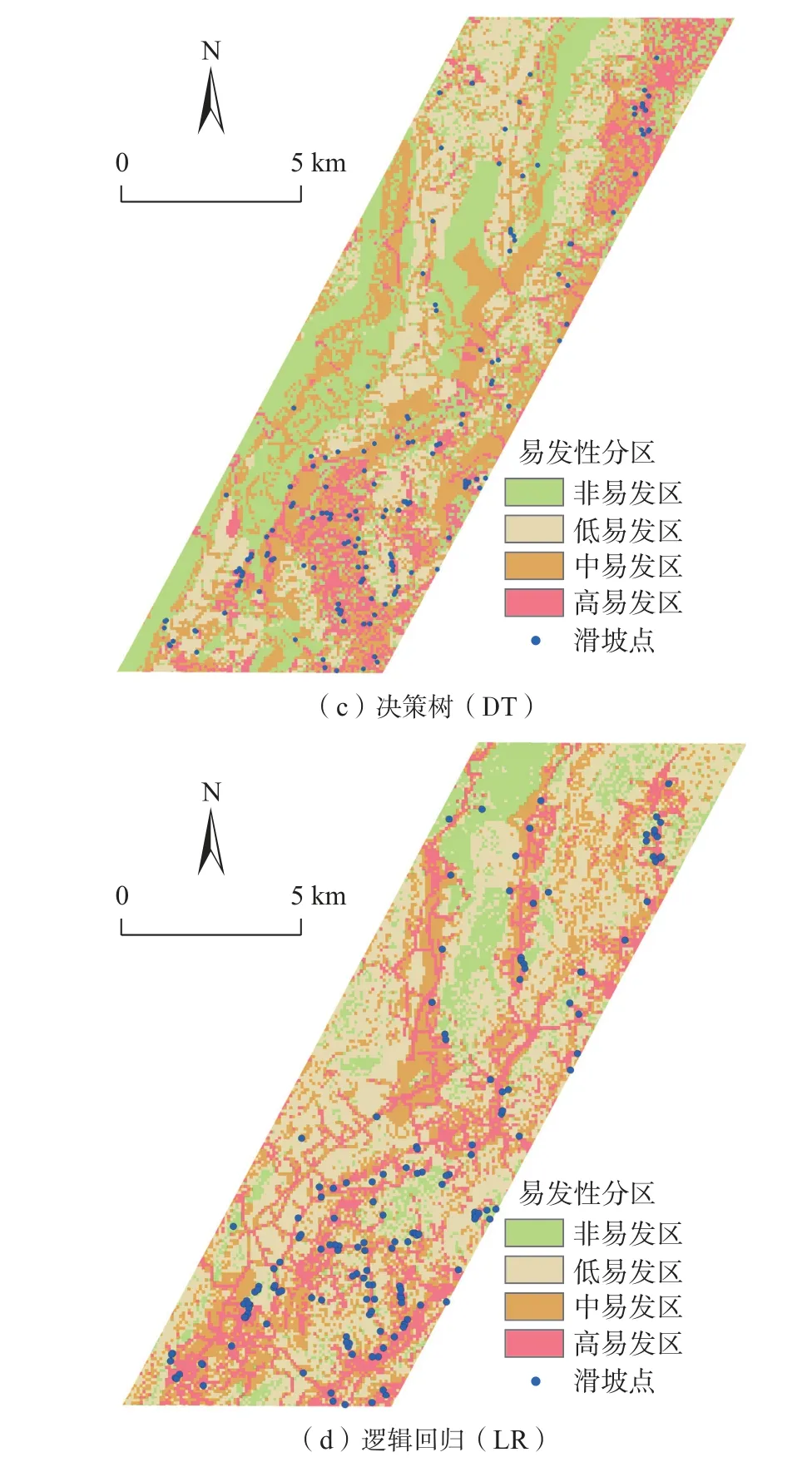
图3 不同模型下易发性分区图Fig.3 Susceptibility partition chart under different models
从表3 可以看出,各模型得到高、中易发性面积占比分别为77.6%、76.9%、60.1%和60.6%。其中信息量模型高、中易发性面积占比最高,且从图3 可以看出,滑坡点基本分布在高、中易发性区。

表3 滑坡点在各个分区所占比例Table 3 The proportion of disaster points in each partition
4.3 精度对比
ROC 曲线在易发性评价精度检测中被广泛应用,横坐标为假阳性率(1-特异性),纵坐标为真阳性率(即敏感性)。ROC 曲线下的面积即AUC值,AUC评价指标值越大,则代表模型分类结果的准确性越高。银坑镇滑坡易发性评价结果ROC 曲线见图4,图中信息量模型的AUC值为0.800,而其他三个模型的AUC值分别为0.708、0.672 和0.586,说明信息量模型具有较高的精度和可靠性。
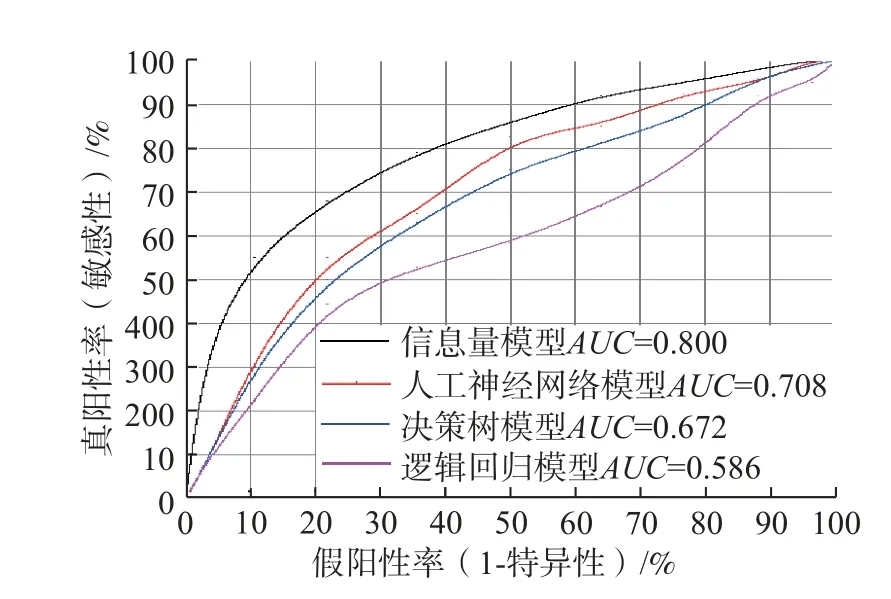
图4 各个模型准确率曲线图Fig.4 The accuracy curve of each model
5 结论
(1)开展赣南地区小型削方滑坡易发性评价时,信息量模型较人工神经网络模型、决策树模型和逻辑回归模型准确率更高,适用性较强。
(2)于都县银坑镇高易发区主要分布于河背村、谢坑村、三溪村、小庄村、老屋村和龙头村等地区;中易发区主要分布于梅屋村、上谢村和年丰村等地区;低易发区和较低易发区主要分布岩前村、松山村、杨河村和窑前村等地区。
猜你喜欢
中国药学药品知识仓库(2022年9期)2022-05-23
大众科学(2022年5期)2022-05-18
房地产导刊(2022年1期)2022-02-28
今日农业(2021年10期)2021-11-27
今日农业(2021年1期)2021-03-19
世界有色金属(2020年5期)2020-12-08
环球人文地理·评论版(2017年3期)2017-06-14
西部资源(2016年1期)2016-07-30
成才之路(2016年18期)2016-07-08
企业导报(2016年8期)2016-05-31
