
基于BERT模型的领域知识图谱构建研究
2023-01-06 09:56郭伟鹏沈松雨
科技创新与应用 2022年36期
郭伟鹏,沈松雨
(1.广州城市信息研究所有限公司,广州 510665;2.公安部第三研究所,上海 200031)
2012年5月17日,谷歌公司(Google Inc.)首次提出知识图谱(Knowledge Graph,KG)的概念,旨在描述客观世界的概念(Concept)、实体(Entity)、事件(Event)及其之间的关系(Relation),作为构建下一代智能化搜索引擎的核心能力。知识图谱的本质是一种大规模的语义网络。知识图谱作为新兴的人工智能技术,可以有效地挖掘和分析知识实体间的相互联系,从而促进知识的交叉融合[1]。在一个成熟的面向特定领域的知识图谱中,通常存储数十亿条实体,数百亿条实体与实体之间的关系。基于领域知识图谱,无论用户输入该领域相关何种关键字,知识图谱均能呈现与该关键字密切相关的实体及关系。例如,腾讯公司(Tencent)基于社交数据构建了社交网络空间,将社交网络转换为知识图谱[2]。该图谱在人与人之间、人与群体之间及群体与群体之间构建出复杂的关系网络,通过某个人的属性信息,便能够快速找出所在学校和社区相关人员的关键信息,并研发出关系推荐系统,如通过相同好友、地理位置(Geographical Location)或者同群组等关系,推荐出可能认识的人。
随着信息技术的快速发展,当今世界步入信息爆发性增长的时代[3],社会治理工作更依赖于大规模信息检索与分析技术。目前诸多单位已经积累了大量的具有位置属性的网格事件数据资源。研究表明,80%的人类活动信息与地理位置有关。这些重要的网格事件数据资源普遍具有海量、多源及异构的特点。为整合这些异构环境下的海量数据资源,提高数据价值密度,迫切需要构建基于位置数据的网格事件领域知识图谱,以满足大数据环境下的地址搜索、事件关联及网格员调度推荐等各类的业务需求。基于位置的网格事件数据,如何构建价值密度较高、知识较为丰富的网格事件领域知识图谱成为一个难点。
自然语言处理(Natural Language Processing,NLP)是人工智能的核心技术[4],实体关系提取和语义分析均属于典型的自然语言处理工作。作为人工智能领域重要的研究方向之一,已经出现诸多自然语言处理方法和模型。同时,随着机器学习模型算法在各领域的广泛应用,自然语言处理算法显然已从以规则为核心逐步发展为以统计为核心,并且以统计为核心的自然语言处理算法已深入应用在命名实体识别、实体关系提取等典型的自然语言处理工作中。然而,目前常用的自然语言处理算法如CRF条件随机场、BILSTM双端长短记忆门等,通常需要大量的人工标注样本作基础支撑,而这项标注样本工作耗时比较多,这显然增加了语料生产的人工成本,影响了自然语言处理算法实现的经济可行性。
为解决网格事件领域知识图谱构建过程中标注成本高昂的问题,本文将采用BERT(Bidirectional Encoder Representation from Transformers)双向转换的编码器迁移学习算法模型。BERT模型基于Transoform深度学习架构,采用注意力机制实现,BERT模型作为预训练模型的典型被广泛关注[5]。BERT模型的核心思想是使用大体量廉价的非标注语料进行预训练(Pre training),实现具有特定领域特征的文本分布式表示的预训练模型;基于该预训练模型,仅用少量人工标注作辅助语料,便可对预训练模型进行微调,进而可解决领域业务问题解答的算法模型。本文的研究表明,在网格事件领域,基于BERT预训练模型在模型训练的准确率方面表现良好。
1 研究方法
1.1 总体思路
基于多层双向转换编码的BERT模型是一种新型的语言处理技术,该模型通过对每一层的双向转化器调节进行预训练。BERT模型的出现是自然语言处理领域的一次重大进步,其显著改变了预训练过程中词向量和下游具体自然语言处理任务之间的关系。该模型分2个阶段,第一阶段进行模型预训练,即采用大体量非标注语料作预训练,获得文本分布式表示,其结果和上下文紧密关联;第二阶段进行模型微调(Fine Tuning),即使用训练好的模型迁移学习到下游的训练任务,并采用有标注的训练样本对其进行模型微调,进而获得特定领域的知识,减少训练时资源、时间等方面消耗。BERT模型典型体系结构如图1所示。
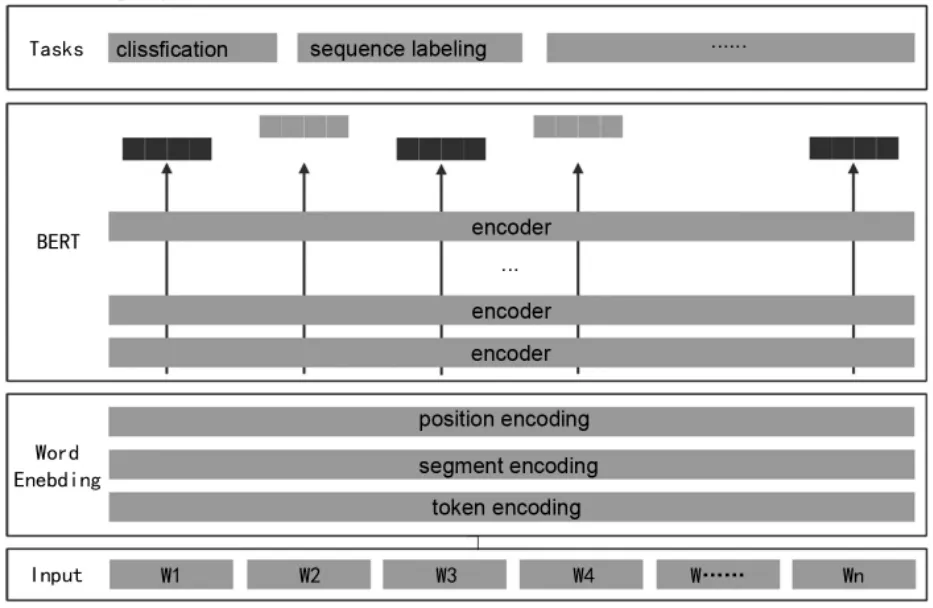
图1 BERT模型典型体系结构
1.2 预训练
本文采用广东省信息点数据、广东省地址数据、广东省某辖区网格事件数据构建BERT预训练模型,一方面可以有效降低网格事件领域知识图谱构建过程中,自然语言处理模型人工语料标注成本较高问题,另一方面有助于该模型有效推广到社会治理领域的自然语言处理各种任务中。
训练过程中采用屏蔽语言模型(Masked Language Model)训练方法,即随机屏蔽(masked)输入部分表征(token),在文本段中随机选择12%的词汇用于预测。被屏蔽的词汇中70%使用特殊符号[MASKED]替换,15%采用随机词替换,剩余15%保持词汇不变。训练模型依托上下文信息对被屏蔽的词汇进行预测,进而使模型可以理解词语的表征,并进行纠错工作。具体操作过程见表1。

表1 训练过程说明
1.3 命名实体识别
在社会治理网格事件领域,实体关系信息蕴含于多源异构数据中。依据网格事件管理和决策业务需要,在大体量文本数据中进行实体与关系提取,形成用于构建网格事件领域知识图谱的三元组(实体,关系,实体),为社区治理中关系查询业务提供数据支撑。
构建实体识别模型,需要在训练好的BERT模型末端补充前向网神经网络层,采用Adam算法优化器,并结合交叉熵损失函数对模型参数进行局部微调。基于BERT的命名实体识别模型结构如图2所示。
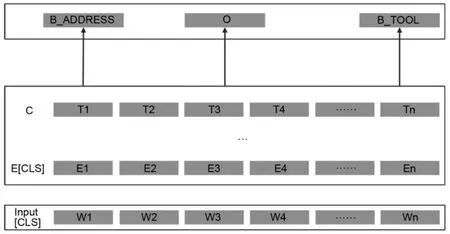
图2 命名实体识别
1.4 实体关系识别
在文本关系提取的业务中,重点关注网格事件和位置信息密切相关的实体,如人(PERSON)实体、地址(ADDRESS)实体、事件(EVENT)实体、物品(GOODS)实体和车(CAR)实体等。实体之间的关系包含:居住(LIVE)、发生(HAPPEN)、拥有(OWN)、丢失(LOST)、落脚(STAY)、归属(BELONG)和提交(APPLY)等。在精调BERT模型过程中,每回合随机抽取小批量人工标注的语料进行模型训练,对模型参数进行微调。实体关系识别如图3所示。
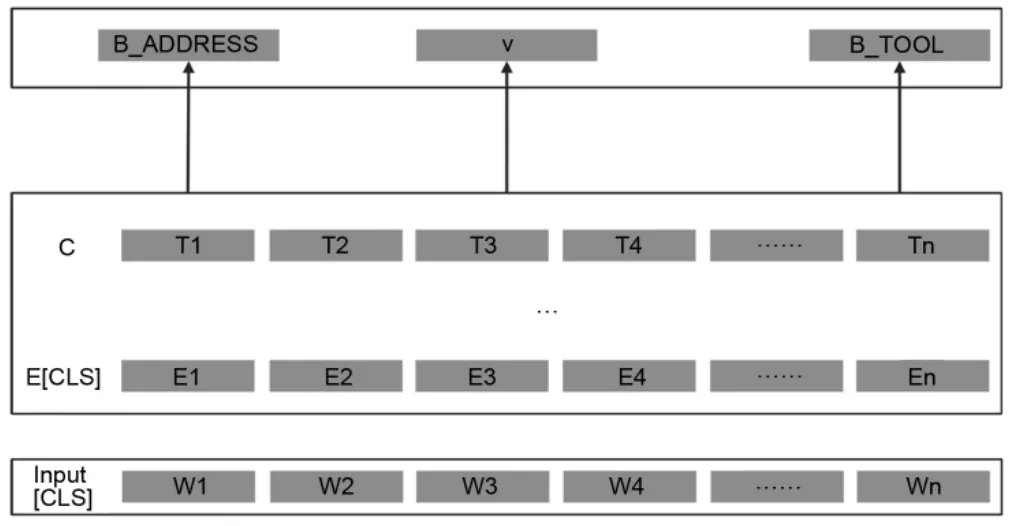
图3 实体关系识别
1.5 知识图谱构建过程
对本文数据进行基于BERT模型算法的预训练,预训练过程使用人工标注语料精调后,提取一个实体、关系并进行语义解析,形成实体—关系—实体三元组,定期三元组数据持久化到图数据库(Neo4j)中,开发面向实体、关系的图谱检索服务,便可对网格事件管理起到决策支持作用。本文采用的领域知识图谱构建过程如图4所示。
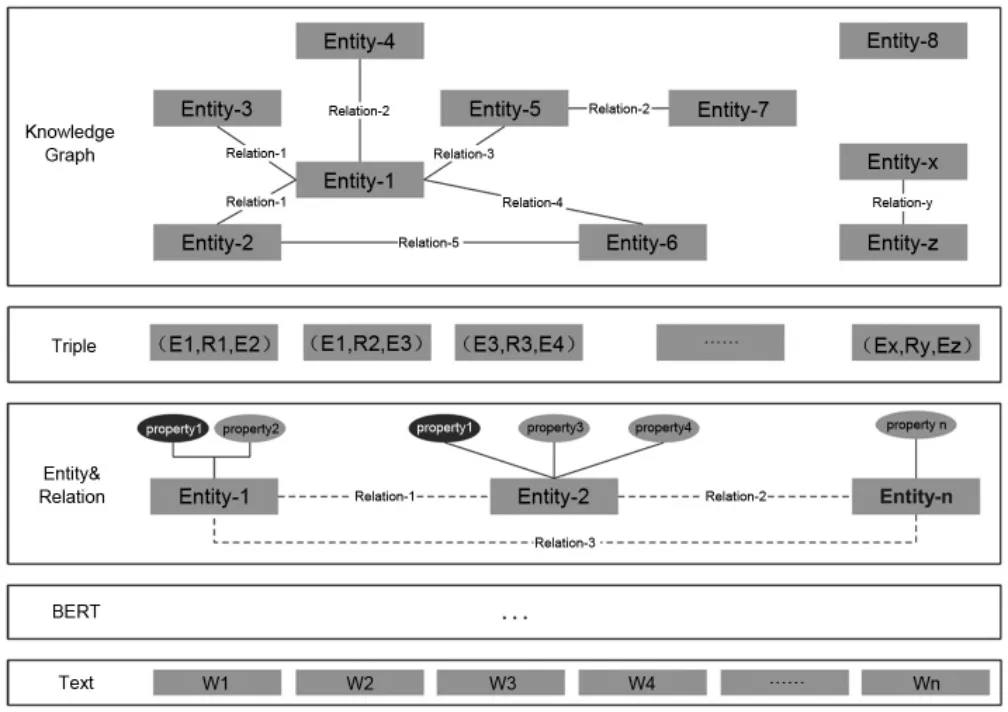
图4 领域知识图谱构建
1.6 实验
1.6.1 实验环境
本研究的实验环境见表2。

表2 实验环境
1.6.2 实验结果
本研究实验结果见表3。

表3 实验结果
1.6.3 网格事件知识图谱示例
本研究构建的面向用于社会治理的网格事件领域知识图谱示例中共包含6种实体,12种关系。实体包括人员(PERSON)实体、地址(ADDRESS)实体、事件(EVENT)实体、物品(GOODS)、车辆(CAR)及电话(phone);关系包括居住(LIVE)、发生(HAPPEN)、拥有(OWN)、丢失(LOST)、落脚(STAY)、归属(BELONG)、提交(APPLY)、关联(LINK)、同住(COHABIT)、同行(PEER)、亲属(RELATIVES)及密接(TIGHT JOINT)。本文实验结果部分成果示例如图5所示。
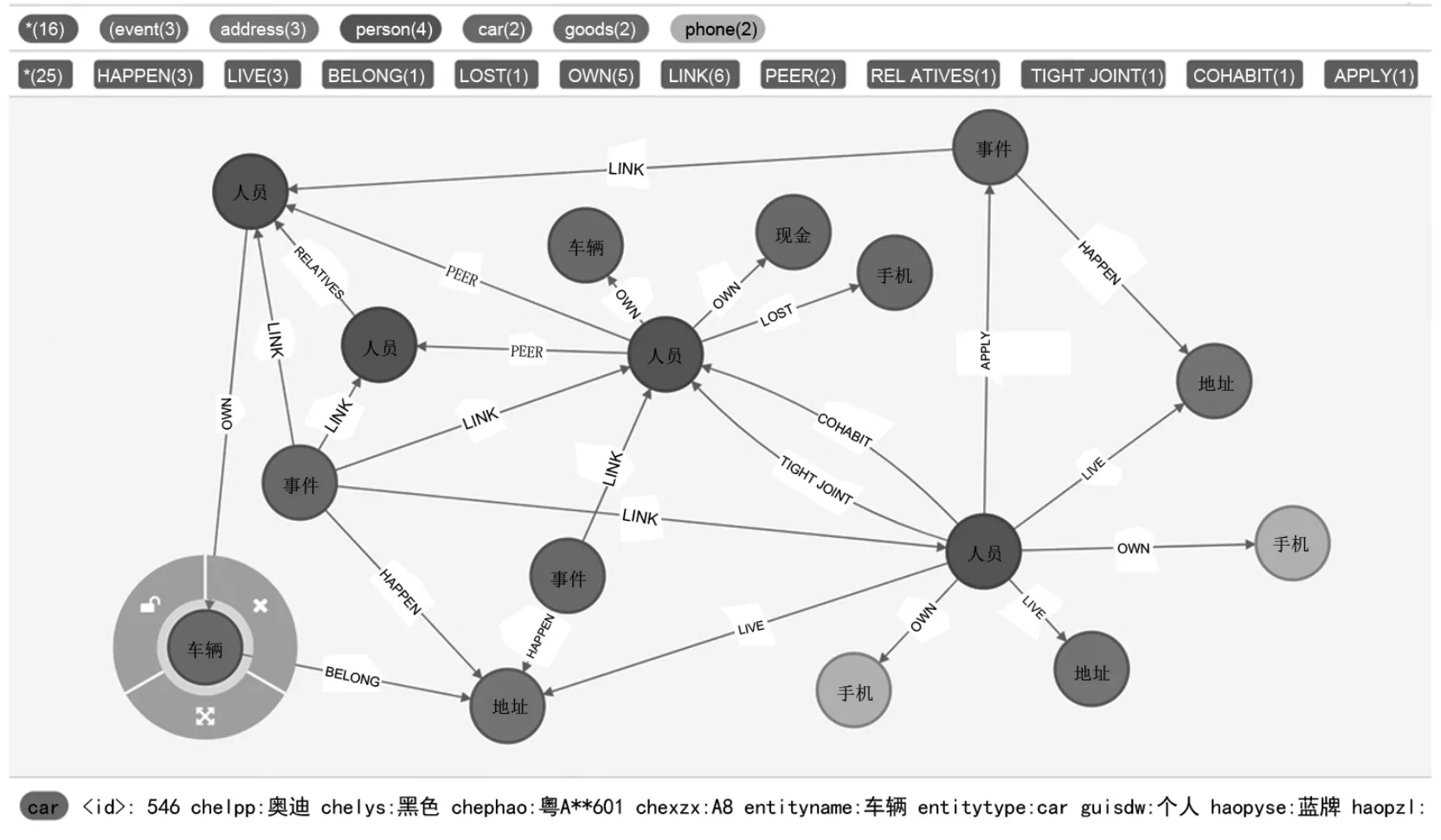
图5 领域知识图谱成果示例(查询车,深度3)
2 结论
实验结果表明,本文面向社会治理层面的网格事件管理,本文提出基于预训练模型(Bidirectional Encoder Representations from Transformers,BERT)的命名实体识别方法[6]和领域知识图谱构建技术,在实体提取、关系提取等自然语言处理(NLP)任务中可获得良好的效果,基于图数据库存储在关系存储和表达方面也更为直观。该模型在区别于训练样本格式的文本数据处理中同样获得较好的识别支持率,具备较强的社会治理赋能领域进一步泛化赋能。
猜你喜欢
通信技术(2021年12期)2022-01-25
世界科学技术-中医药现代化(2021年7期)2021-11-04
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
计算机应用与软件(2018年9期)2018-09-26
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
