
基于最邻近帧质量增强的视频编码参考帧列表优化算法
2023-01-08 14:31霍俊彦邱瑞鹏马彦卓杨付正
通信学报 2022年11期
霍俊彦,邱瑞鹏,马彦卓,杨付正
(西安电子科技大学ISN 国家重点实验室,陕西 西安 710071)
0 引言
近年来,短视频的广泛普及使视频数据量进入持续爆发式增长阶段。同时,直播电商作为一种新的购物消费方式开始上线。受新冠疫情影响,视频会议的应用需求也呈现爆炸式增长。为保证用户间的实时交互,这些视频业务对时延有严格的要求。针对低时延、大数据量的特点,在低时延视频应用场景下,提高视频编码效率对高效开展视频会话具有积极的意义。与此同时,基于深度学习的卷积神经网络(CNN,convolutional neural network)在视频处理等方面取得了令人瞩目的成果,利用深度学习提升视频编码效率是未来的研究趋势。
高效视频编码H.265/HEVC[1]标准采用传统的视频混合编码框架,使用灵活的块划分结构,并在预测、变换和熵编码等各个环节增加多种新算法。相比于先进视频编码H.264/AVC[2]标准,在相同的视频质量条件下,H.265/HEVC 可降低约50%的编码码率。针对日益增长的低时延视频业务,视频通用测试条件设计了低时延P 帧(LDP,low-delay only P)配置,其仅利用单向参考帧进行帧间预测。在此配置下,视频序列的编码顺序与播放顺序一致,每帧编码时仅参考播放顺序在当前帧之前的已编码帧。在以往的研究中,基于深度学习的方法已经应用到了视频编码框架的主要模块中,如帧内预测、帧间预测和环路滤波等。本文算法的设计目标是借助深度学习的方法辅助帧间预测,提高LDP配置下H.265/HEVC 的编码效率。
帧间预测是视频编码框架的关键模块,其利用视频的时间相关性提高编码效率。针对每个待编码块,帧间预测利用多个参考帧的重建样本,运用多种运动补偿技术构造预测样本,预测样本与原始样本之间的差值经过变换、量化、熵编码等模块处理后被送入码流进行传输。
目前,基于深度学习的帧间预测包含亚像素插值、预测值生成和参考帧列表(RFL,reference frame list)优化等方案,其中,参考帧列表优化使用神经网络生成额外的虚拟参考帧,用于待编码帧的预测参考。虚拟参考帧的生成涉及内插(两帧之间插入)和外插(多帧之外插入)2 种方式。在LDP 配置下,为了保证低时延,参考帧列表的图像皆为先于待编码帧的图像。此时,虚拟参考帧的生成仅能由当前时刻之前的参考帧外插得到。相比于内插算法,外插算法需要生成参考帧之外的新内容,预测精度较低,对帧间编码性能的提高非常有限。
本文针对LDP 配置提出基于最邻近帧质量增强的参考帧列表优化算法,优化框架如图1 所示。将待编码帧前向参考帧列表中的第一个参考帧,即最邻近参考帧,送入提出的参考帧质量增强网络进行质量增强,并将其作为额外的参考帧整合到待编码帧的参考帧列表中。与现有虚拟参考帧算法相比,本文提出的参考帧增强算法的输出帧不包含虚构内容,其构造算法较简单,且性能优于已有虚拟参考帧算法。
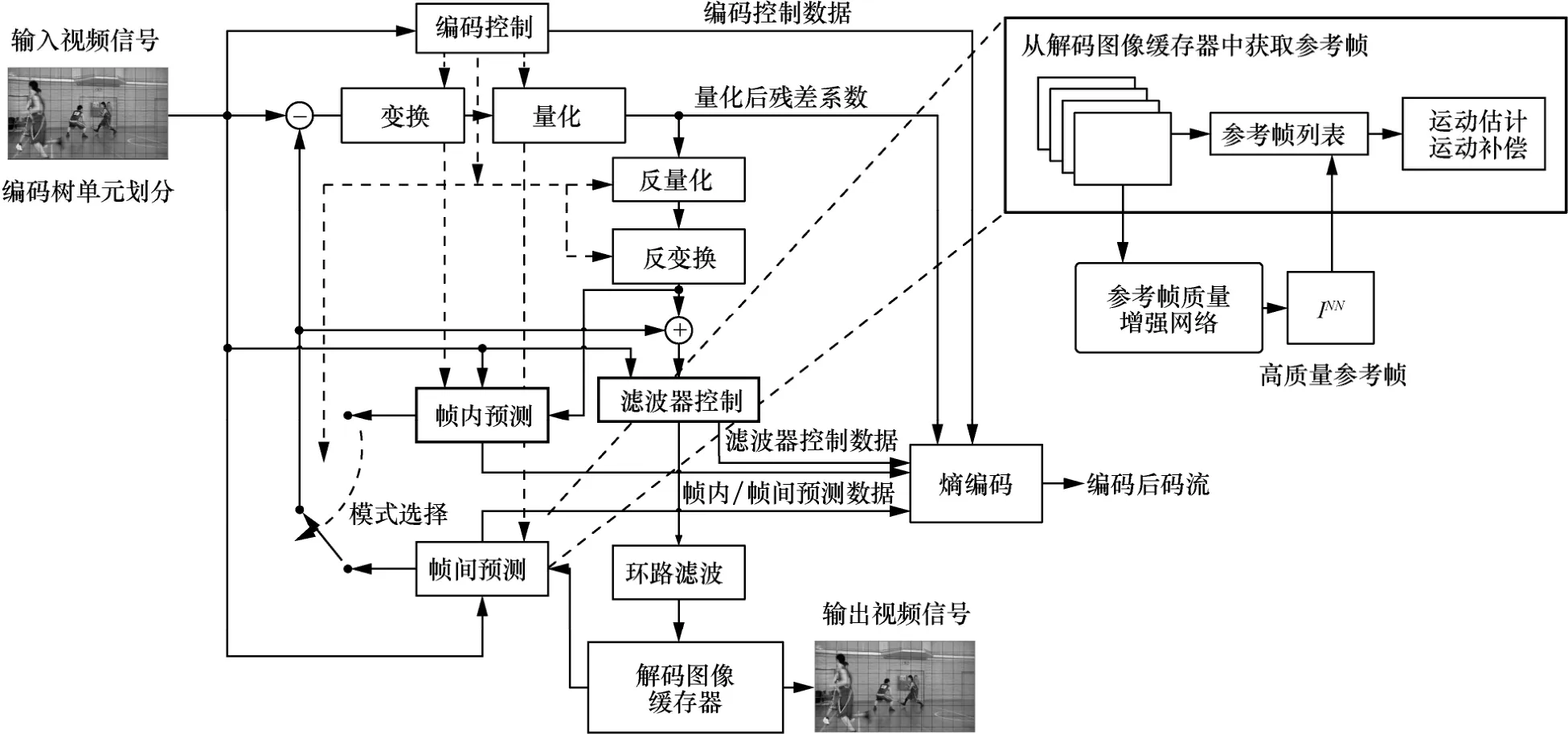
图1 基于最邻近帧质量增强的参考帧列表优化框架
综上,本文提出一种新型的参考帧列表优化算法,设计一种改进的视频帧质量增强网络对最邻近帧进行质量增强。首先将可变形卷积网络(DCN,deformable convolutional network)和光流相结合,应用光流引导可变形卷积的偏移预测,然后将网络生成的高质量参考帧插入参考帧列表参与帧间预测,提高预测准确度,进而提高编码效率。
1 相关研究
1.1 基于神经网络的视频帧质量增强
视频帧质量增强旨在减弱视频经过有损压缩引入的失真,基于深度学习的方法在视频帧质量增强方面取得了显著的成效。该类方法大致可分为单帧质量增强和多帧辅助质量增强。单帧质量增强方法基于深度学习的卷积神经网络来提取图像的空域信息和特征,通过强化这些信息对图像进行增强。多帧辅助质量增强方法则利用一个或多个相邻帧的时域和空域信息进行质量增强,是目前视频帧质量增强的主要手段。
1.1.1 单帧质量增强方法
受基于神经网络的图像超分辨率算法的启发,面向减弱失真的卷积神经网络(ARCNN,artifact reduction CNN)[3]率先针对JPEG 重建图像引入CNN 滤波方法,实现对单帧图像的质量增强。基于卷积神经网络的环内滤波(IFCNN,in-loop filtering using CNN)技术[4]使用三层卷积网络代替H.265/HEVC 中的样点自适应补偿滤波模块。残差高速卷积神经网络(RHCNN,residual highway CNN)[5]引入由残差高速单元和卷积层组成的神经网络,作为H.265/HEVC 中额外的环内滤波器。非对称卷积残差网络(ACRN,asymmetric convolutional residual network)[6]利用密集结构来提取重建帧的层次性特征,利用非对称卷积块提取纹理的方向性特征来恢复纹理。递归残差卷积神经网络(RRCNN,recursive residual CNN)[7]作为H.265/HEVC 中额外的环内滤波器,在编码树单元(CTU,coding tree unit)级自适应选择使用此滤波器,同时采用递归残差模块实现残差模块的参数共享。基于变滤波器尺寸的残差学习卷积神经网络(VRCNN,variable-filter-size residue-learning CNN)[8]应用Inception 模块的方式,利用多个小尺度卷积层并行组合来代替大尺度卷积层。多级注意力卷积神经网络(MACNN,multi-stage attention CNN)[9]采用改进的Inception 模块和自注意力机制,使用较浅的卷积网络获得全局信息能力。基于压缩激发模块的滤波卷积神经网络(SEFCNN,squeeze-and-excitation filtering CNN)[10]利用特征提取和特征增强2 个子网组合来更获取通道间的非线性关系,并结合压缩激发(SE,squeeze-and-excitation)模块[11]来建立通道间注意力机制。
有些工作将编码信息应用到网络中,帮助网络快速收敛并进一步提高重建帧的质量。多模型/多尺度卷积神经网络(MMSCNN,multi-modal/multi-scale CNN)[12]将H.265/HEVC 的编码单元和变换单元的分区映射作为网络的输入。分区掩盖卷积神经网络[13]深入分析编码单元分区信息的生成方法和帧融合方法。引入残差的卷积神经网络滤波器(CNNF-R,CNN filter using residual)[14]将编码后的残差信息作为辅助信息输入网络。深度残差卷积神经网络(DRCNN,deep residual CNN)[15]采用归一化量化参数(QP,quantization parameter)作为网络输入,帮助网络学习QP 与输入重建帧压缩失真的关系。
1.1.2 多帧辅助质量增强方法
空-时残差网络(STResNet,spatial-temporal residue network)[16]通过同时输入当前块和同位块提高重建帧的质量。深度卡尔曼滤波网络(DKFN,deep Kalman filtering network)[17]融合卡尔曼滤波模型和神经网络的高度非线性映射的优势,提供更准确的时间信息,同时还利用预测残差作为先验信息,从而产生更高质量的恢复结果。质量门控卷积长短期记忆(QG-ConvLSTM,quality-gated convolutional long short-term memory)网络[18]根据不同质量帧的重要性不同,通过网络学习使每帧的信息得到合理和充分的使用。上述方法直接使用相邻同位块或参考帧作为网络的输入,未考虑运动信息,难以利用神经网络学习跨多帧的依赖关系。
考虑运动信息的多帧辅助质量增强一般分为帧对齐、帧融合和质量增强3 个步骤。基于光流对齐和基于可变形卷积对齐是目前最常用的帧对齐方法。帧融合是将对齐的帧与待增强的帧进行融合,学习时域和空域相关性来生成融合特征以增强图像质量。质量增强是充分挖掘融合特征中的互补信息,生成增强目标帧。
基于光流的帧对齐通过估计帧之间的运动信息,将邻近帧变形映射(warp),使之与待增强帧对齐。质量增强网络(QENet,quantity enhancement network)[19]、基于学习的多帧视频质量增强(LMVE,learning-based multi-frame video quality enhancement)[20]和多帧引导的注意力网络(MGANet,multi-frame guided attention network)[21]利用光流网络[22]及使用金字塔、映射和代价量的卷积神经网络(PWC-Net)[23]估计的光流得到对齐帧,并与当前帧一起作为网络的输入。多帧质量增强(MFQE,multi-frame quality enhancement)[24]和MFQE 2.0[25]由基于光流的运动补偿子网络和质量增强子网络组成,将与待增强帧最接近的2 个高质量关键帧作为输入。
现有的光流估计算法对有遮挡场景内容的稳健性不强,在运动幅度大的情况下不能保证运动信息的准确性。基于光流的帧对齐在每个特征位置只学习一个偏移量,而DCN[26]和DCNv2[27]引入多个偏移量进行帧对齐。空-时可变形融合(STDF,spatio-temporal deformable fusion)[28]和递归融合及可变形空-时注意力(RFDA,recursive fusion and deformable spatial-temporal attention)[29]学习一种新的时空可变形卷积来聚合时间信息的同时进行帧融合,并利用由密集连接的卷积层来实现质量增强。基于可变形卷积的帧对齐仍然存在一些问题,如快速运动不准确、训练不稳定。由于可变形偏移与基于光流的偏移关系密切,光流引导的可变形对齐网络(FDAN,flow-guided deformable alignment network)[30]和基本视频超分(BasicVSR++,basic video super-resolution)算法[31]提出了新型的对齐算法,将可变形卷积和光流相结合。
帧融合是将对齐后的相邻帧与当前帧进行融合,生成融合特征以增强图像质量。RFDA[29]提出一种递归融合模块,在一段长时间范围内构建时间依赖性。LMVE[20]和基于预测的多帧视频增强(PMVE,prediction-based multi-frame video enhancement)[32]展示了直接融合、早期融合和慢速融合3 种不同的融合方法,并通过实验验证了慢速融合在效率上的优势。但是这些方法忽略了不同位置对增强帧的影响不同。为此,基于增强可变形卷积网络的视频恢复(EDVR,video restoration with enhanced deformable convolutional network)算法[33]引入了时间和空间注意力来帮助跨多个对齐特征聚合信息,但是没有区分多个相邻帧的重要性,忽略了它们的不同特征。
1.2 基于神经网络的虚拟参考帧生成
上述单帧或多帧辅助质量增强方法可作为后处理技术应用在视频编码系统中,也可用于环内滤波处理。但这些方式多以提高主观质量为目标,对提高编码效率帮助有限。同时,基于神经网络的环内滤波处理不可避免的一个问题是多次增强,即多帧之间存在参考依赖,质量提升效果会随着帧之间的传递逐渐减小。质量增强之后的帧较平滑,多次滤波后平滑效果更加明显,这时直接作为输出会影响主观质量。
出于以上原因,本文聚焦于基于神经网络的帧间预测技术,此类技术不仅致力于提高重建图像的质量,而且利用增强技术可提高帧间预测的精确度,从而明显提高视频编码效率,同时也避免了多次增强的问题。
目前,基于神经网络的帧间预测方法主要应用在亚像素插值、预测值生成和参考帧列表优化等环节。亚像素插值方法[34-37]通过神经网络利用整像素来推导亚像素位置。预测值生成方法[38-39]通过神经网络来代替线性加权预测,可更好地处理复杂运动。使用网络生成额外的虚拟参考帧是目前基于深度学习的参考帧列表优化的主要方法。虚拟参考帧生成一般采用内插、外插2 种方式。Lin 等[40]采用拉普拉斯金字塔状的生成式对抗网络,利用待编码帧的前4 个已编码的重建帧生成额外的具有高质量的参考帧。Zhao 等[41]从2 个重建参考帧中生成高质量虚拟帧放入参考帧列表,并设计CTU 级编码模式。之后Zhao 等[42]进一步利用神经网络将合成帧整合到参考帧列表中进行运动估计。Lee 等[43]提出使用之前已编码的重建帧来合成虚拟参考帧,具有更高的时间相关性,可以同时进行视频帧内插和外插,并自适应地修改了高级运动向量预测(AMVP,advanced motion vector prediction)模式和Merge 模式的预测机制。Choi 等[44]利用非线性变换和自适应空间变化滤波器,使用扩张的卷积和减少滤波器长度以减少网络模型参数,为单向预测和双向预测2 种方式设计模型。此类方法在实时性的LDP 配置下编码时,仅能采用外插虚拟帧方法。而外插虚拟帧方法准确度低,很难生成之后时刻尚不存在的信息,导致性能损失。针对该问题,本文提出利用深度学习实现参考帧质量增强,并将增强后的参考帧作为额外的参考帧插入参考帧列表,以提高帧间预测准确度,从而提高视频编码效率。
2 基于神经网络的参考帧列表优化算法
2.1 网络结构
在常见的基于深度学习的视频帧质量增强网络中,一般仅对一个分量,即Y 分量进行质量增强。H.265/HEVC 的通用测试序列格式为YCbCr 4:2:0格式,Y、Cb、Cr 这3 个分量在尺寸、分布范围、纹理特征等方面各不相同。本文提出的网络结构设计对3 个分量分支路单独处理。由于色度分量纹理相对平坦,因此色度分量支路网络结构为亮度分量支路的简化版本,并且Cb 和Cr 分量支路共享网络参数,以避免色度分量的过拟合。
在LDP 配置下,待编码帧的参考帧列表一般存在4 个可用参考帧,故网络输入设置为4 个参考帧,其中参考帧列表中第一帧(即最邻近帧)为待增强的参考帧。帧质量增强网络旨在估计出一个高质量的参考帧放入参考帧列表中。假设参考帧列表中的参考帧对应的时刻依次为t,t1,t2,t3,网络生成的高质量参考帧表示为
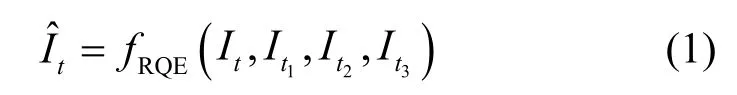
其中,fRQE为本文所提出的参考帧质量增强网络,为输入的参考帧。
如图2 所示,首先,参考帧被送入偏移和掩码预测(OMP,offset and mask prediction)模块。偏移信息为参考帧对齐提供参考帧之间的运动偏移量,掩码信息为帧融合提供融合权重。
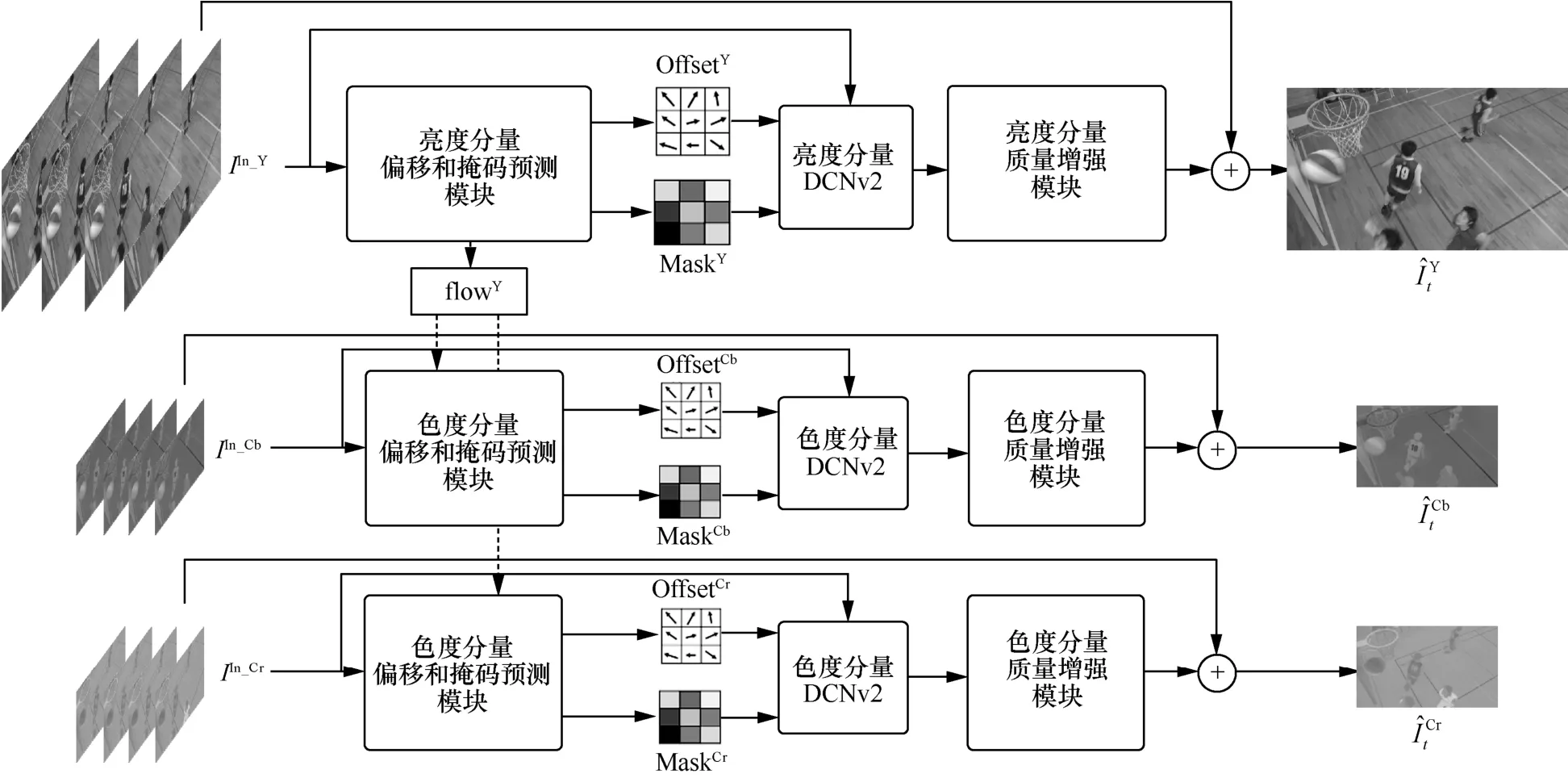
图2 基于深度学习的参考帧质量增强网络模型框架
然后,利用OMP 模块提供的偏移信息和掩码信息,本文提出的网络模型使用DCNv2[26]来对齐并同时融合待增强参考帧和其他参考帧。
最后,将融合得到的特征送入质量增强(QE,quality enhancement)模块进一步处理,计算出增强的结果。为了利用残差学习的优势[45],QE 模块的输出与待增强参考帧相加得到增强后的参考帧。生成的高质量参考帧为
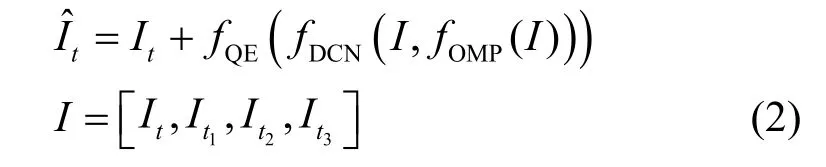
其中,fOMP、fDCN和fQE分别为OMP 模块、可变形卷积DCNv2 模块和QE 模块;I为参考帧集合,包含4 个参考帧。OMP 模块生成t1,t2,t3时刻参考帧与t时刻参考帧之间的偏移信息和掩码信息,如式(3)所示。

2.1.1 偏移和掩码预测
不同参考帧之间存在不同程度的运动偏移,准确的帧对齐可以更有效地挖掘多个视频帧的信息。考虑到光流引导的可变形对齐的优异性能[31],如图3 所示,本文使用光流引导偏移量预测(FGOP,flow guided offset prediction)子模块来获得基本偏移量。进一步地,使用特征学习子模块(FLSN,feature learning sub-net)获得残差偏移信息和掩码信息,进而为输入帧的每个位置提供最终偏移信息和融合权重。
如图3 所示,以It和Iti为例,首先将这2 个重建帧的亮度分量经过光流预测得到两帧亮度分量之间的光流信息,再将其和经过warp 操作得到对应的warp 图像。在色度分量支路中,使用亮度分量光流信息的下采样作为两帧色度分量之间的光流信息,具体如式(4)所示。
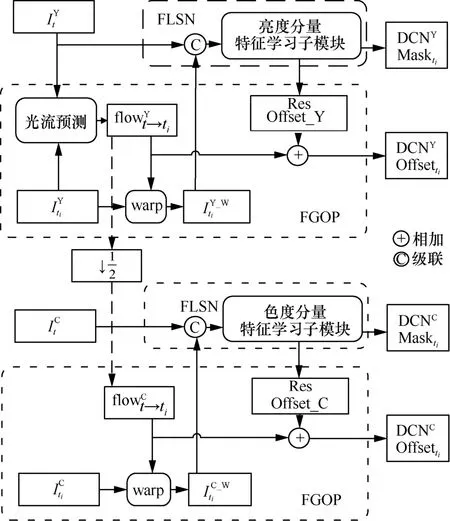
图3 带有光流引导的偏移和掩码预测模块
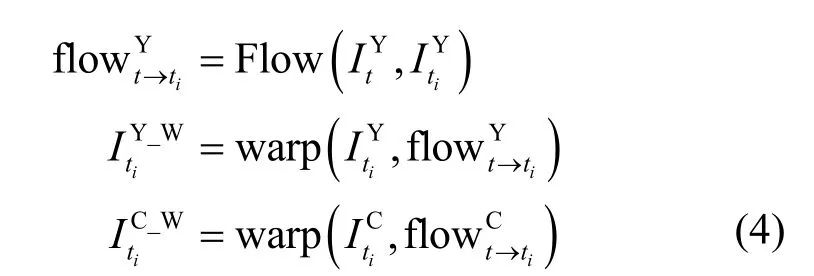
基于编码-解码网络结构,本节中的亮度分量特征学习子模块的网络结构如图4 所示。在该结构中,跨度为2 的卷积层和反卷积层分别用于下采样和上采样,亮度分量分别进行三次卷积下采样和反卷积上采样。对于跨度为1 的卷积层,使用零填充来保留特征大小。为了简单起见,所有(反)卷积层的通道数为32。这样,每一层的内部特征的通道数是相同的。在FLSN 中,将输入帧经过图4 所示的一系列处理得到残差偏移信息和掩码信息。
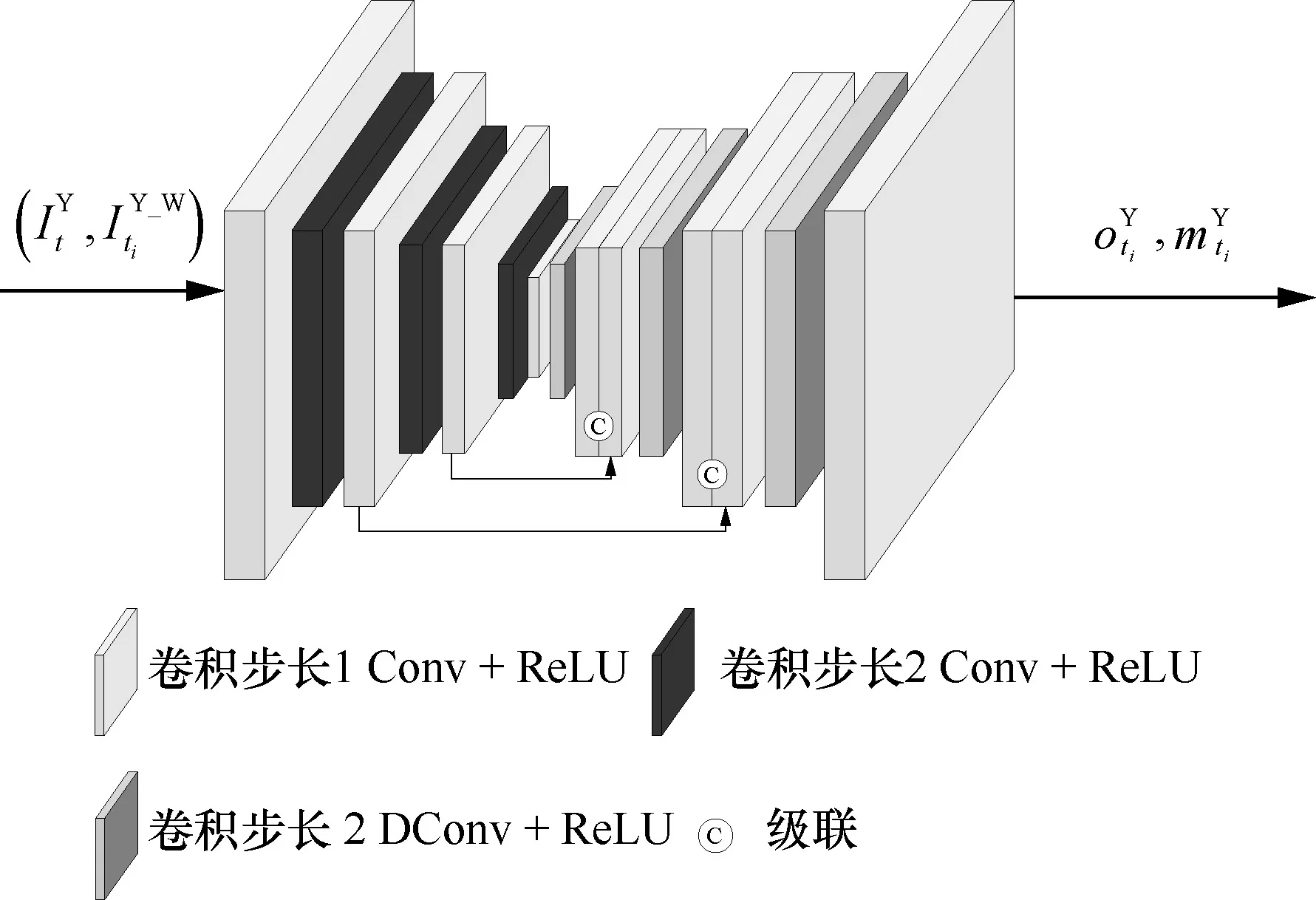
图4 亮度分量特征学习子模块的网络结构
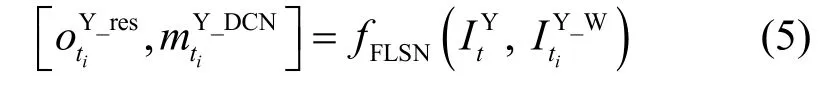
其中,fFLSN表示特征学习子模块。最终的偏移信息为
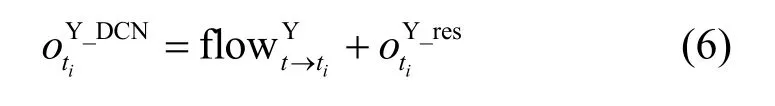
色度分量支路的特征学习子模块为亮度分量的简化版本,其网络结构如图5 所示。

图5 色度分量特征学习子模块的网络结构
2.1.2 质量增强模块
QE 模块将帧对齐并融合后得到的特征作为输入,充分挖掘特征图中包含的信息,进一步提高生成帧的质量。
通过DCNv2 得到的融合特征(FF,fusion feature)如式(7)所示。
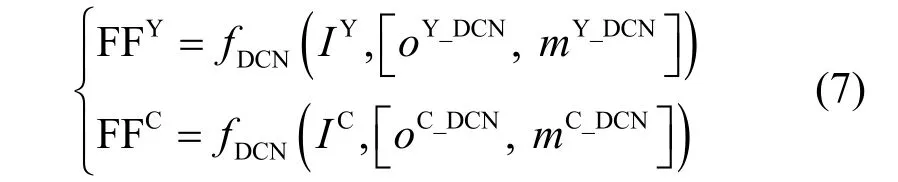
其中,FFY表示亮度分量的融合特征,FFC表示色度分量Cb 或Cr 的融合特征。经过QE 模块之后将得到最终的高质量参考帧,各分量的处理如式(8)所示。
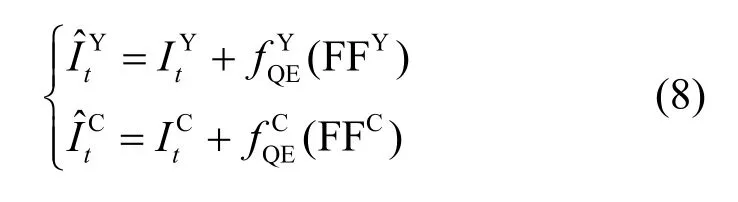
本文采用8 层卷积网络作为亮度的质量增强模块,使用4 层卷积网络作为色度的质量增强模块,分别如图6 和图7 所示。
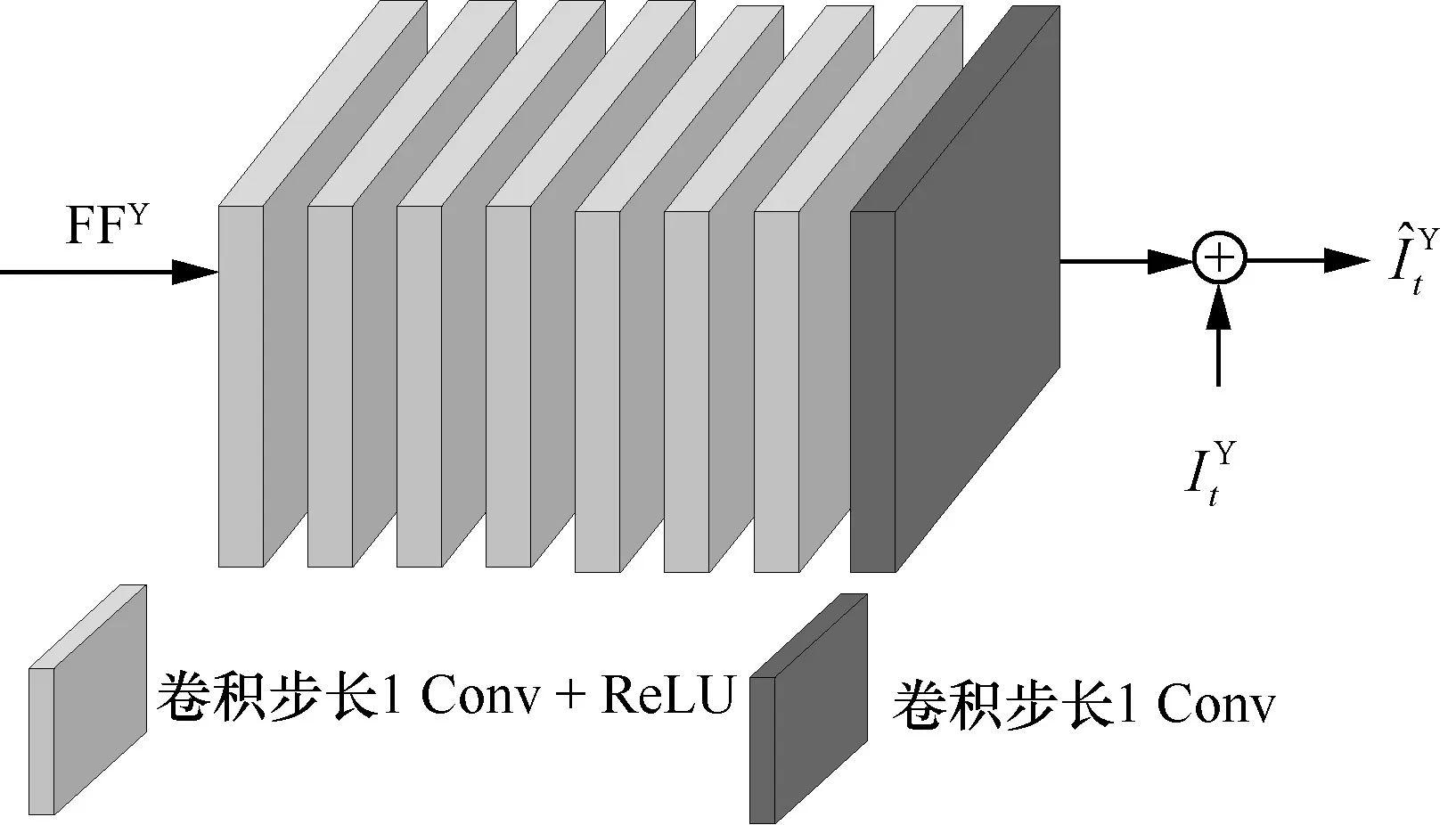
图6 亮度分量质量增强
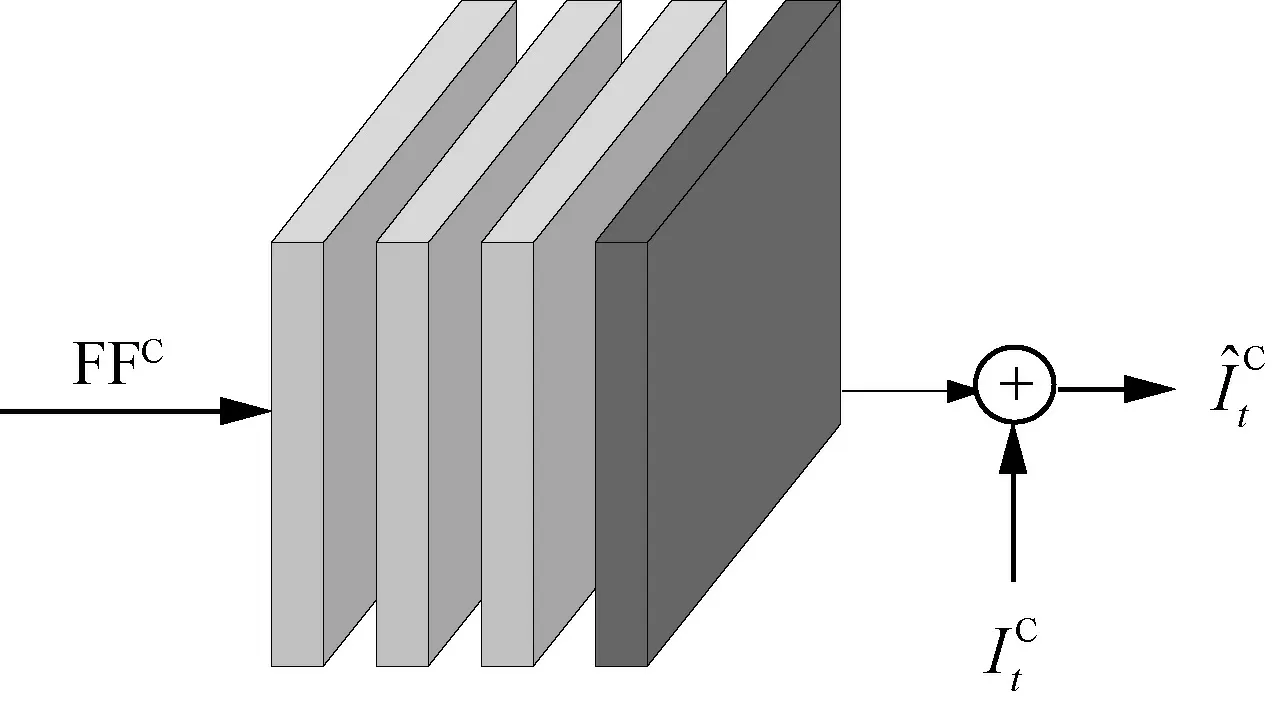
图7 色度分量质量增强
2.2 高质量参考帧的整合
如图1 所示,解码图像缓存器(DPB,decoded picture buffer)用于存放解码重建完成的图像。每个片(slice)的帧间预测参考帧都由RFL 来管理,RFL 的图像实际存储于DPB 中。在编解码过程中,不同时刻会为DPB 中存在的每帧重建图像赋予一个不同的标记,标记有两层含义,首先区分其是否作为参考帧,如果作为参考帧,再区分其是长期参考帧还是短期参考帧。当图像不再作为其他图像的参考帧时,将其从DPB 中移除。
图8给出了LDP配置下图像之间参考关系以及各位置图像与其质量对应关系。通常,图像组(GoP,group of picture)大小设置为8,图像间的编码顺序、解码顺序与显示顺序均相同。图8 中的箭头方向表示参考关系,每帧图像仅参考显示顺序排在其之前的图像,包括其最邻近图像和3 个前序GoP 中质量最高的图像。图8 中的图像使用不同的QP 进行编码,因此具有不同的重建质量。一般来说,QP 越小质量越高,图8 中白色框表示对应图像使用的QP 最小,其质量最高;图像标识颜色越深,表示其对应的QP 越大,质量越差。
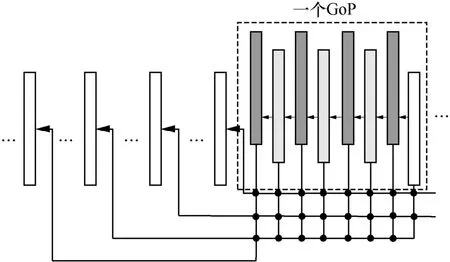
图8 LDP 配置下图像之间参考关系以及各位置图像与其质量对应关系
观察图8 可知,由于采用了不同QP,与待编码图像时间上最接近、内容最相似的参考帧质量往往不是最好的。基于此,本文提出对最邻近参考帧进行质量增强从而得到高质量参考帧。
本节将本文算法集成到H.265/HEVC 参考软件平台HM(HEVC model)16.22 版本上,可分为以下几个步骤。
步骤1在待编码帧编码之前创建一个增强参考帧缓存INN,并将其放入DPB 中。本文所提出的算法对参考帧列表中第一个参考帧进行质量增强,即图像顺序计数(POC,picture order count)值最大的参考帧作为待增强帧。将INN的POC 值设置为DPB 中最大的POC 值,同时设置一个标志信息与原参考帧进行区分。
步骤2LDP 配置下待编码帧仅含有前向参考帧列表,如图9 所示,将前向参考帧列表的4 个参考帧输入本文提出的网络,进行参考帧质量增强。将增强后的参考帧赋给INN,并将INN整合到参考帧列表中。

图9 LDP 配置编码下参考帧列表优化方案
步骤3对待编码帧进行编码。在当前帧编码完成之后,将INN从DPB 中移除,以免影响后续的输出及编码。
需要注意的是,本文提出的参考帧质量增强网络的输入均为存储在DPB 中的重建帧,编码端和解码端的操作保持一致,所以编码端不需要向比特流中传输任何额外的信息来标记创建的参考帧。
3 实验结果
3.1 训练细节
本文使用的数据集选自Xiph 和VQEG 中的106 个序列,包含280p~1 080p 不同分辨率。使用H.265/HEVC参考软件HM16.22对每个序列分别使用4 个典型的QP {22,27,32,37}进行LDP 配置下的编码。
常用的损失函数包括均方差(MSE,mean squared error)、平均绝对误差(MAE,mean absolute error)等。本文使用式(9)所示的MAE 作为损失函数,为方便整数运算,最终选取式(10)作为最终的损失函数。

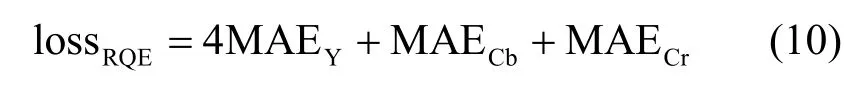
在训练过程中,本文使用Adam 优化算法对网络进行更新,其相应参数设置为α= 0.0001,β1= 0.9,β2= 0.999,ε= 10-8。
3.2 与标准参考软件的对比
本文在H.265/HEVC 的LDP 配置[47]下进行了相关的测试,具体测试了A~E 类共计18 个视频序列,测试仍采用4 个典型的QP,即{22,27,32,37}。
本节实验使用BD-rate[48]对测试方法进行客观评价,以HM16.22 作为基准方案,BD-rate 值代表在相同重建视频质量下的码率节省量,若BD-rate为负值,则表示测试方法优于基准方案;若BD-rate为正值,则表示测试方法相比于基准方案需要传输更多的编码码率,引入了编码损失。
表1 给出了相应的测试结果,其中包含三类内容,即不同测试序列对应的类别、名称、3 种颜色分量的性能。为充分分析增强参考帧放在参考帧列表不同位置造成的影响,本文方案将增强参考帧分别放到参考帧列表的第一位、第二位和最后位进行测试。同时,为了验证不改变参考帧列表长度下引入增强参考帧的性能,本文也测试了将增强参考帧替换最邻近参考帧的性能。

表1 LDP 配置编码下引入增强参考帧在HM16.22 下的测试结果
从表1 中可以看出,基于最邻近帧质量增强的参考帧列表优化算法将增强参考帧放到参考帧列表第二位时,获得的性能最高。在Y、Cb、Cr 这3 个分量上平均得到-9.06%、-14.92%、-13.19%的BD-rate 增益。同时,在所有测试序列上都得到了增益,从Y 分量来看,可得到-15.21%~5.02%的BD-rate 增益。在不改变参考帧列表长度的情况下,将增强参考帧替换最邻近参考帧也可带来一定的BD-rate 增益,在Y、Cb、Cr 这3 个分量分别得到-4.92%、-10.11%、-7.84%的BD-rate 增益。在相同视频质量前提下,所提算法均可降低编码码率。
在测试时,本文深度学习网络部分使用GPU进行运算,编解码器的其他部分均使用CPU。表2给出了增强参考帧放到参考帧列表中不同位置时的编解码时间比。

表2 增强参考帧放到参考帧列表中不同位置时的编解码时间比
由表2 可知,将增强参考帧放到参考帧列表中不同位置时的编解码时间接近,其中,编码时间约为HM16.22 的1.2 倍,解码时间约为HM16.22 的55 倍。
基于以上结果,本文选择将质量增强后的视频帧插入待编码帧的参考帧列表中的第二个位置。
3.3 与现有方法的对比
本节将所提算法与文献[39,44]方法在相同的条件下进行测试和比较。由于HM16.20 的LDP 配置编码使用的GoP 为4,与HM16.22(GoP 为8)有较大差异,本文将参考帧质量增强网络在HM16.20上重新训练并测试,如表3 所示。

表3 与现有方法的编码性能比较
由表3 可知,所提算法在Y、Cb、Cr 这3 个分量分别获得了-8.9%、-12.5%、-10.4%的BD-rate增益。将所提算法与文献[39,44]方法的最优性能进行对比,可见其在不同分辨率的序列上都取得了最优的性能。
正如前文所述,在LDP 配置下,文献[39,44]方法都利用当前时刻之前的重建帧进行外插来得到虚拟参考帧,旨在生成与待编码帧内容一致的参考帧。然而,因为无法避免运动遮挡问题,虚拟参考帧中往往存在部分虚构内容,从而影响帧间预测的准确性。而本文算法仅对已有的最邻近参考帧进行质量增强,避免了因虚构内容带来的预测误差,同时经过增强的参考帧内容往往具有较高的预测精度,有助于提高帧间编码效率。
文献[39,44]方法经过神经网络处理得到的帧可直接作为编码块的预测值,从而减少了大量运动信息的传输,这是本文算法无法达到的效果。后续研究可以考虑综合这2 种方法的优势进行组合设计,达到更高的压缩性能。
4 结束语
本文提出了一种基于最邻近参考帧质量增强的参考帧列表优化算法,以提高在LDP 配置下的视频编码效率。具体做法是先应用光流引导可变形卷积的偏移预测,再结合多参考帧通过QE 网络对最邻近参考帧进行质量增强,将增强后的参考帧作为额外的高质量参考帧插入参考帧列表。本文实验结果表明,所提算法可以提高低时延场景下视频帧间编码的效率。
本文将基于神经网络的视频帧质量增强应用于参考帧列表优化算法中,为视频编码标准的研究提供了可行的研究方向。然而将基于深度学习的网络模型与传统编码框架相结合大大增加了编解码复杂度,下一步可考虑对神经网络进行压缩和简化以降低复杂度。同时,随着软硬件计算能力的提升,设计更高效的质量增强网络应用到参考帧列表优化中,也可进一步提升视频编码性能。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(中年级)(2021年4期)2021-04-27
汉字汉语研究(2020年2期)2020-08-13
课堂内外(初中版)(2020年5期)2020-06-19
电子制作(2019年22期)2020-01-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
疯狂英语·新读写(2018年3期)2018-11-29
北京航空航天大学学报(2018年1期)2018-04-20
