
一种用于因果式语音增强的门控循环神经网络
2023-01-09 14:28李江和
计算机工程 2022年11期
李江和,王 玫
(桂林理工大学 信息科学与工程学院,广西 桂林 541006)
0 概述
近年来,语音增强技术在军事、商业等领域发挥着重要作用,在工业界与学术界受到越来越多的关注。在语音识别、通信等应用领域,由于背景噪声的影响,语音质量、语音可懂度等指标大幅下降,从而导致语音识别率下降,同时给试听者带来较差的听觉体验。为解决该问题,语音增强技术在语音预处理中成为不可或缺的一部分[1]。
当前,语音增强技术发展迅速,传统经典的语音增强算法包括谱减法[2-3]、统计模型法[4-6]、维纳滤波[7-8]等。传统谱减法的关键在于对噪声频谱进行估计,通过在带噪频谱中减去噪声谱,从而得到增强后的语音频谱。在传统基于谱减法的语音增强方法中,需要对先验信噪比进行估计,但这会影响到算法性能。除此之外,基于子空间的语音增强算法[9-10]也得到一定发展。
传统的语音增强方法均建立在数字信号处理的基础上。近年来,基于深度学习的语音增强方法逐渐引起研究人员的关注并展现出优越性能。相较传统的基于数字信号处理的语音增强方法,基于深度学习的语音增强方法在语音客观可懂度、语音感知质量(PESQ)等指标上得到大幅提升。XU 等[11]提出基于深度神经网络(DNN)的语音增强方法,通过多目标、多通道的网络学习,在语音可懂度、语音感知质量等指标上得到较大提升。由于语音信号在频域表现出时频相关性,为了更好地学习这种相关性,文献[12-14]提出基于卷积循环神经网络的语音增强方法,通过卷积神经网络学习频谱的空间相关性,同时利用循环神经网络学习频谱的时间相关性,研究结果表明,这种方法能更好地建模语音信号。一些学者通过研究发现,听觉特征可以提高深度学习的语音增强性能,文献[15-16]通过融合使用MFCC、Log_Mel 频谱等听觉特征,提高了神经网络对语音信号的建模能力。
然而,现有基于深度学习的语音增强方法[17-19]为了使网络更好地学习语音信号相邻帧的相关性,网络采用了非因果式的对称窗作为输入,即输入不仅为当前帧(第n帧),而且需要先前的N帧以及后续的N帧共同作为网络的输入特征(2N+1 帧),这导致在语音增强过程中产生了固定时延,不能满足语音增强系统对实时性的要求。因果式语音增强方法仅利用当前帧(第n帧)与先前的N帧作为网络输入,从而避免了固定时延问题。文献[20]从实验中寻找适合因果式语音增强的网络结构,增强后的语音质量得到较大提升,但其并未针对网络本身结构进行改进。
本文从网络结构出发,为充分利用先前N帧语音信号的信息,提出一种用于因果式语音增强的门控循环神经网络CGRU。该网络结构单元的输出结合当前时刻的输入xt以及上一时刻的输入xt-1和输出ht-1,充分利用先前帧的信息来提高网络的建模能力。在实验过程中,将本文CGRU 网络与简单循环神经网络(SRNN)、门控循环神经网络(GRU)、简化循环神经网络(SRU)[21]等传统网络结构进行性能对比,验证算法增强后的语音在短时客观可懂度(STOI)、语音感知质量、分段信噪比(SSNR)等指标上的性能表现。
1 深度学习因果式的语音增强方法
假设加性噪声为n(t),纯净语音信号为s(t),带噪语音为y(t),则带噪语音信号的时域表示为:

为了更好地分析语音信号,一般需要对时域信号进行短时傅里叶变换(Short Time Fourier Transform,STFT)。对带噪语音信号y(t)进行的短时傅里叶变换为:

其中:n、k分别表示第n帧的第k个频带。本文采用基于非负幅度的特征实现语音增强实验,以验证所提方法的有效性。通过短时傅里叶变换式(2),得到音频的频率分量。非负幅度谱[22]可通过式(3)计算:

其中:Y(n,k)为语音通过短时傅里叶变换后的幅度谱;Z(n,k)为非负幅度谱特征。在深度学习因果式的语音增强中,语音增强可视为通过非线性函数fx实现带噪语音到纯净语音的复杂映射:
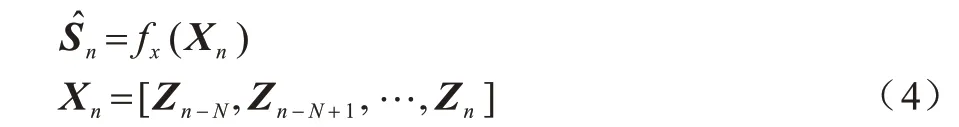
其中:x为神经网络训练后的参数;Xn代表网络的输入特征,其为当前帧(第n帧)与先前N帧拼接而成的因果式输入特征(N+1 帧);为神经网络对纯净语音特征的估计结果。
通过网络的不断训练迭代,得到一个从带噪语音到纯净语音的复杂映射函数,记为fx。在网络的训练过程中,本文通过多次实验发现绝对误差的语音增强效果较好,最后选择的损失函数为平均绝对误差,如下:

其中:fx(Xi)是通过网络后得到的输出特征值,即对纯净语音非负幅度谱的估计;Ti为网络的训练标签,即目标语音的非负幅度谱;M为网络在训练时采用的批量大小,本文通过实验得出M的合适取值为256。
通过神经网络对带噪语音非负幅度谱Zn(n,k)进行估计得到纯净语音非负幅度谱,记为Zs(n,k),然后利用人耳对相位不敏感的特点,通过带噪语音的相位谱φ(n,k)结合估计的纯净语音非负幅度谱逆变换,得到增强后的时域语音分帧后的信号,利用重叠相加法得到估计的语音信号xt:
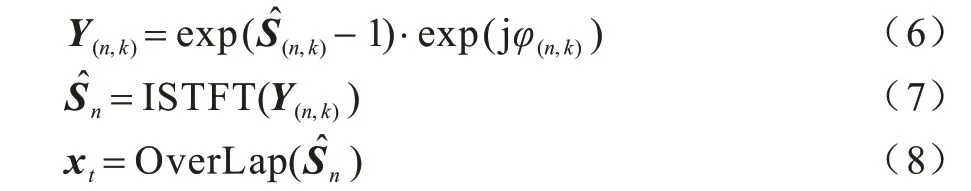
对于语音信号,通过对分帧加窗(hamming 窗)处理后的数据进行STFT(式(2)),得到语音信号的时频二维分量,求取频率幅度值并保存相位φ(n,k),利用幅度谱,通过式(3)可计算得到非负幅度谱特征以用于网络训练和测试。通过语音增强算法得到增强后的非负幅度谱,并经由式(6)、式(7),联合保存的相位φ(n,k)经过傅里叶逆变换得到增强后的时域语音信号,最后利用重叠相加法(式(8))恢复增强后的信号时域序列xt。
2 门控循环神经单元
2.1 GRU 门控循环神经单元
图1 所示为门控循环神经单元结构,其中,xt、ht、ht-1分别为当前时刻输入、当前时刻输出以及上一时刻输出,rt、zt、分别为重置门、更新门和候选隐藏状态。门控循环神经单元(GRU)采用了门控机制,在一定程度上能够缓解网络过拟合问题,且网络能够学习更长的时序关系[23]。GRU 对长短时记忆(LSTM)网络进行优化,在网络结构复杂度、网络参数量等指标上均有改进,LSTM 具有3 个门结构,而GRU 只有重置门rt和更新门zt这2 个门。GRU 相对于LSTM网络结构复杂度更低,语音增强实时性更高,此外,GRU 网络结构对语音增强系统的硬件要求更低。
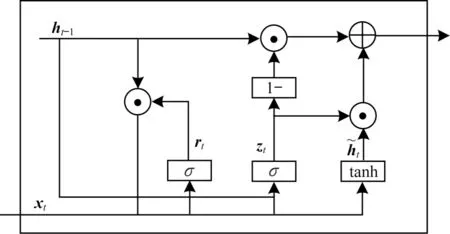
图1 GRU 结构Fig.1 Structure of GRU
GRU 的单元更新关系可由式(9)表示:

其中:W、U为权重矩阵,b为偏置项,它们均为可训练的参数;⊙为Hadmard 乘积;σ为Sigmoid 激活函数。
2.2 CGRU 因果式门控循环神经单元
图2 所示为本文所设计的CGRU 因果式门控循环神经单元结构。为了解决传统神经网络语音增强中因采用非因果式(输入为2N+1 帧)的对称窗而产生的固定时延问题,本文采用因果式(输入为N+1 帧)的网络输入。由于采用了因果式的网络输入,因此神经网络获得的语音信号特征信息衰减为非因果式输入的0.5 倍,为减小其对神经网络学习的影响,本文充分利用前N帧的语音信号特征信息,在CGRU网络单元中融入上一时刻的输入特征xt-1。

图2 CGRU 结构Fig.2 Structure of CGRU
在图2 中,xt、ht、xt-1、ht-1分别为当前时刻的输入和输出以及上一时刻的输入和输出。CGRU 神经网络单元当前时刻的输出ht由上一时刻的输入xt-1、上一时刻的输出ht-1以及当前时刻的输入xt共同决定,从而充分利用先前帧的语音信号特征。受空间注意力机制以及门控线性单元(GLU)[24]的启发,本文在CGRU 因果式门控循环神经网络的单元输入中首先计算xt、xt-1、ht-1的带权特征向量:

与GRU 不同,CGRU 的候选隐藏状态仅由当前时刻的输入xt决定:

当前时刻网络单元的输出ht由候选隐藏状态、遗忘门ft以及上一时刻输出的带权特征共同决定,如式(13)所示:
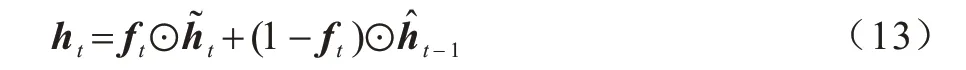
为了降低网络的结构复杂度,本文仅在CGRU网络中采用一个遗忘门ft,同时,针对在因果式语音增强中因输入语音信号特征信息减少所导致的语音增强性能下降问题,本文充分利用先前帧的语音信号特征,在当前时刻的输入xt中融合上一时刻的输入xt-1,同时采用GLU 控制特征信息的传递,从而大幅提高网络性能。
3 实验结果与分析
3.1 实验设置
为了验证CGRU 网络的有效性,本文进行对比实验。针对纯净语音,本文在TIMIT 语音数据集[25]的训练集中随机选取2 000 条音频作为训练集,从测试集中随机选取500 条音频作为测试集。对于训练集的噪声,本文使用文献[26]中的100 种环境噪声,对于测试集的噪声,使用文献[27]中的15 种噪声。在信噪比分别为-5 dB、0 dB、5 dB、10 dB 这4 种情况下,将从TIMIT 训练集中随机选取的2 000 条音频与文献[26]中的100种环境噪声随机混合生成8 000条训练数据集。在信噪比分别为-5 dB、0 dB、5 dB、10 dB 这4 种情况下,将从TIMIT 测试集中随机选取的500 条纯净语音数据与文献[27]中的15 种噪声随机混合生成2 000 条带噪语音测试数据集。在特征提取时,纯净语音、噪声的采样频率均设置为8 000 Hz,帧长为256(约31 ms),帧移为128。
在keras/tensorflow2.0 的环境下完成网络构建与训练。网络的初始学习率设为1e-4,为了使网络更好地收敛,设置学习率的衰减系数为1e-6,最大学习迭代次数为50 次。网络训练采用批量梯度下降算法,利用Adam 算法做迭代优化,批量大小设置为256。网络训练的损失函数使用平均绝对误差(MAE)。在实验过程中,分别设计4 层的GRU、SRNN、SRU 以及CGRU 网络结构,每一层均为512 个神经网络单元。
3.2 结果分析
分别对4 层的GRU、SRNN、SRU 以及CGRU 网络结构模型进行实验。在-5 dB、0 dB、5 dB 这3 种信噪比条件下,测试集上的factory2、destroyerengine、buccaneer1、hfchannal 4 种噪声[27]分别与测试集中的500 条纯净语音进行混合,利用4 种网络模型进行语音增强对比实验,从而验证所提网络的有效性。
在本次实验中,语音增强性能评估指标选择STOI、PESQ 以及SSNR。STOI 的取值范围为0~1,PESQ 的取值范围为-0.5~4.5,数值越大,表明增强后的语音质量越高,语音可懂度越高。表1、表2 所示分别为不同网络模型得到的平均语音感知质量与平均语音短时可懂度。

表1 平均语音感知质量对比Table 1 Comparison of average speech perceptual quality

表2 平均语音短时可懂度对比Table 2 Comparison of average speech objective intelligibility
通过对表1、表2 中的平均语音感知质量与平均语音短时可懂度进行分析可以发现,SRNN 的语音增强效果最差,SRU 与GRU 具有较好的语音增强效果,这是由于简单循环神经网络并不能学习到长期依赖关系,而GRU 与SRU 采用的门控机制在很大程度上提升了网络的学习能力。与其他3 种网络相比,本文因果式语音增强网络CGRU 在语音质量与语音短时可懂度上均取得了良好表现。
在CGRU 网络的单元结构中,采用门控循环神经网络的门控机制,同时,为了充分利用输入特征先前的特征信息,在当前网络的输出特征计算中,不仅整合当前时刻的输入xt与上一时刻的输出ht-1,而且还融合了上一时刻的输入xt-1,从而充分利用语音信号先前的N帧特征信息。表1 和表2 的实验结果证明了因果式循环神经网络CGRU 的有效性。为了进一步直观地展现CGRU 的优越性,统计4 种噪声的平均语音感知质量与平均语音短时可懂度,结果如图3 所示。从图3 可以看出,CGRU 在语音短时可懂度上取得了最好的可懂度评分,在平均语音感知质量方面,虽然在-5 dB 信噪比条件下CGRU 性能略低于SRU,但是随着信噪比的增加,CGRU 表现出更好的性能。
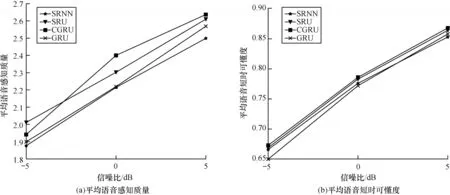
图3 平均语音感知质量与平均语音短时可懂度Fig.3 Average speech perceptual quality and average speech objective intelligibility
为了进一步验证CGRU 的优越性,统计不同信噪比条件下4 种噪声通过4 种不同网络增强后得到的平均语音分段信噪比SSNR,结果如图4 所示。从图4 可以看出,在图4(c)的destroyerengine 噪声下,SRNN 在-5 dB 和0 dB 信噪比条件下获得了较高的SSNR 得分,除此之外,CGRU 在增强后的语音分段信噪比评价指标上得分普遍优于其他3 种网络结构,这进一步验证了CGRU 的优越性。
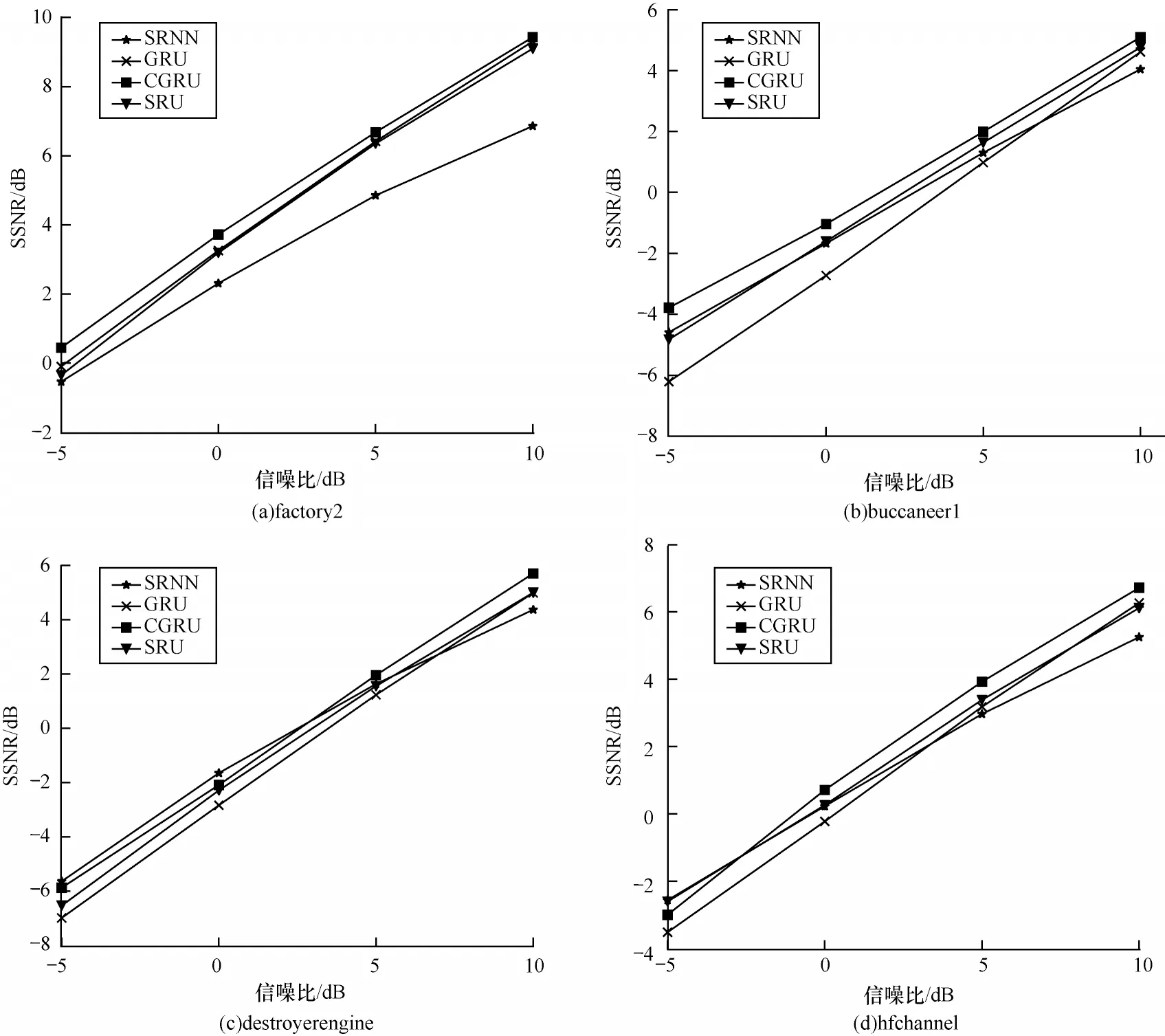
图4 不同噪声条件下的分段信噪比结果对比Fig.4 Comparison of SSNR results under different noise conditions
在图3 中,相较传统的循环神经网络(GRU、SRNN),CGRU 网络在增强后的语音可懂度(STOI)、语音感知质量(PESQ)评价指标上均有较大提升。在图4 中,CGRU 网络相较GRU、SRNN、SRU 等传统网络在增强后的语音平均分段信噪比评价指标上也得到了提升。GRU、SRNN 网络仅融合上一时刻的输出,很多情况下语音增强性能反而低于未融合上一时刻输出的SRU 网络。本文CGRU 网络在当前时刻的输入中融合上一时刻的输入与输出,同时采用线性门控机制控制信息传输,缓解了网络过拟合问题,提升了网络对带噪语音的建模能力,使得增强后的语音评价指标结果均取得了较大提升。
表3 所示为不同网络结构的参数量对比,从表3可以看出,相对于GRU 的双门控机制,CGRU 由于采用了单门控机制,因此其参数量较少。

表3 不同网络模型的参数量对比Table 3 Comparison of parameter quantity of different network models
4 结束语
传统基于深度学习的语音增强方法采用非因果式的输入,导致产生固定时延问题,难以满足语音增强系统对实时性的需求。本文提出一种基于因果式门控循环神经网络CGRU 的语音增强方法。实验结果表明,在平均语音短时客观可懂度、平均语音感知质量、分段信噪比等指标上,CGRU 网络的表现均优于SRNN、GRU、SRU 等传统网络。下一步将以提高语音增强系统的实时性、降低网络复杂度作为研究目标,此外,考虑到卷积神经网络能够提取频谱结构特征,后续将融合卷积神经网络同时建模音频的时间相关性与空间相关性,从而提高网络性能。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
西安邮电大学学报(2020年1期)2020-12-17
北京航空航天大学学报(2019年9期)2019-10-26
计算机系统应用(2019年9期)2019-09-24
雷达学报(2017年3期)2018-01-19
军事运筹与系统工程(2016年4期)2016-07-10
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
雷达与对抗(2015年3期)2015-12-09
