
基于QMix 的车辆云计算资源动态分配方法
2023-01-09 14:29刘金石ManzoorAhmed
计算机工程 2022年11期
刘金石,Manzoor Ahmed,林 青
(青岛大学计算机科学技术学院,山东青岛 266071)
0 概述
随着车联网(Internet of Vehicles,IoV)和智能车辆的发展,车辆正在从出行工具向智能终端转变[1-2]。然而,对用户体验质量[3](Quality of Experience,QoE)不断提高的要求以及车联网中各种智能应用的爆发式增长[4],对远程信息处理应用的实现提出了挑战,尤其是复杂决策和实时资源管理等计算密集型应用。
车辆自组织网络[5-6](Vehicular Ad-hoc Network,VANET)是为车辆之间提供网络连接和实时信息共享而提出的。此外,VANET 还集成了传感器和路边单元(Roadside Unit,RSU)用于与道路上的车辆通信,以提高交通安全[7]。近年来,为了将VANET 与云计算技术相结合,研究人员提出了车辆云[8](Vehicular Cloudlet,VC)系统。VC 系统的计算和通信能力为道路上的用户提供了实用性和便利性,因此相关研究近年来备受关注。VC 由一个未充分利用的车辆资源共享池组成,其中包括计算、存储、传感和通信设备[9]。一组车辆可以通过分享自己的计算资源,并根据车联网形成云计算网络来实现资源共享,这与传统的云计算非常相似,不同之处在于计算资源是由车辆提供的。车辆通过创建自组网络,避免传输数据到远程的计算中心,节省网络带宽,同时可以显著降低应用延迟[10-11],另外为智能驾驶、道路规划的决策等基于智能交通的应用程序提供支持,使车辆更加智能化。
由于车辆的地理分布特性,VC 系统具有高度的动态性与资源波动性,传统的资源优化方法[12]已经不能满足其资源动态管理与分配的要求。近年来,由于人工智能技术的快速发展,研究人员开始尝试使用强化学习理论来实现车辆计算资源的动态管理。文献[13]提出使用任务复制的方法来解决车辆任务请求未完成而车辆离开VC 覆盖范围的情况,并给出一种平衡任务分配(Balanced Task Assignment,BETA)策略,证明了该策略是最优策略,但是该方案只考虑了相同的任务大小。文献[14]考虑VC系统中的任务迁移问题,即对于具有拓扑顺序的任务可以在未完成之前迁移到其他车辆上,以最小化整体响应时间。文献[15]使用公共交通车辆来提供计算服务,并且使用了M/M/C 优先队列模型,最后基于半马尔可夫决策过程提出一个感知应用程序卸载策略来获取最优的资源分配方案,并最大化长期奖励。文献[16]考虑了异构车辆与RSU 计算资源分配的场景,并且对于不同类型的任务请求遵循不同的泊松分布,但由于使用的是传统的强化学习算法,因此不能很好地处理复杂环境状态情形。
将深度学习的感知能力与强化学习的决策能力相结合的深度强化学习(Deep Reinforcement Learning,DRL)技术[17],不需要明确状态转移概率,只基于当前的情况,根据系统状态的样本和客观奖励的经验策略来做出决策。DRL 模型有效地改善了传统强化学习算法在高维输入状态空间或大动作集的环境下性能差的问题。文献[18]提出一种三层卸载框架使得总体能耗最小,并且考虑了运动车辆和停靠在停车场的静态车辆,由于具有较高的计算复杂度,因此将资源分配问题分解为流量重定向和卸载决策两部分,对于流量重定向问题使用Edmonds-Karp 算法,而卸载决策部分使用双Q 网络[19](Double Deep Q-Network,DDQN)。文献[20]提出一个知识驱动车联网服务卸载框架,基于A3C(Asynchronous Advantage Actor-Critic)算法可以同时在多个不同的边缘节点训练,然后将学到的知识传递到VC 控制器,使得决策能更好地适应环境变化。文献[21]提出一种通过启发式算法将有限的计算资源分配给车辆应用的模型,由于环境中的高维信息和连续行为空间,通过递归神经网络(Recurrent Neural Network,RNN)来提取基于时间和位置的资源可用性模式,使用近端策略优化(Proximal Policy Optimization,PPO)算法对计算资源进行分配,模拟实验结果表明,相比于传统的方案可以取得更高的服务满意度。
本文在二次资源分配(Secondary Resource Allocation,SRA)机制[22]的基础上,提出一种基于双时间尺度的二次资源分配机制。该机制考虑了异质化车辆与不同类型的任务请求,其不同于单智能体算法,而是运用多智能体强化学习(Multi-Agent Reinforcement Learning,MARL)算 法QMix[23]对 计算资源进行分配从而获得更好的服务满意度。
1 系统模型
本文的VC 系统模型如图1 所示,系统主要由车辆和路边的RSU 设备组成。VC 系统的控制中心部署在RSU 上,通过车辆-基础设施[24](Vehicle-to-Infrastructure,V2I)通信方式实现无线连接。本文的VC 系统考虑了异质车辆,定义K种车辆类型,不同类型的车辆可以提供不同大小的计算资源。为了更好地量化VC 中的资源大小,本文使用资源单元(Resource Units,RUs)来表示整个VC 中最小的资源单位,所有资源池中的资源被中心的VC 控制系统进行分配。
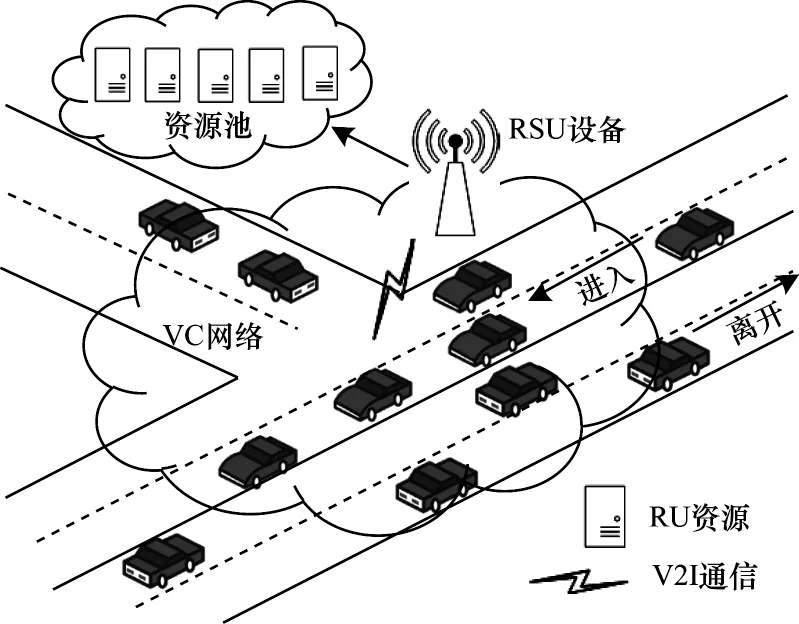
图1 VC 系统模型Fig.1 VC system model
对于进入与离开VC 的车辆遵循泊松分布,当车辆进入VC 覆盖范围后,由于车辆自身的计算资源有限,当车辆有计算任务时就会向VC 发送任务请求。VC 接收到任务请求后,根据任务信息与当前资源池中的资源数量来决定是否接收请求,并分配相应数量的RU。如果VC 根据当前系统的请求服务状态拒绝接收请求,此时会把该服务发送到附近的边缘服务器执行,在这种情况下系统会受到惩罚。
为了更加贴合实际情况,对于不同的任务请求具有不同的描述特征。比如对于自动导航任务需要严格的时间限制,而对AR、VR 车载娱乐等计算密集型任务则不需要严格的时间限制。本文将任务信息定义如下:

1.1 通信模型
车辆v的j类型任务请求的传输时间和信道传输速率相关。其中信道传输速率可以表示为:
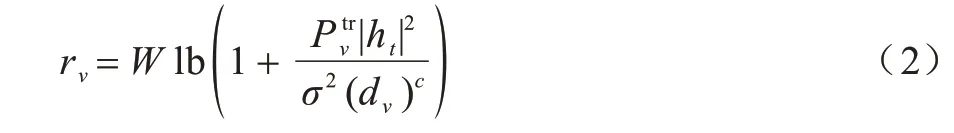
其中:d和c分别为车辆距离RSU 的距离和路径损耗指数;为车辆与RSU 之间的传输功率;ht为t时刻车辆与RSU 之间的信道衰减系数;σ2为传输的高斯噪声功率;W为可用的频谱带宽。此时,对于属于车辆v任务类型为j的请求i的传输时间为:

1.2 队列模型
当VC 系统内的车辆产生任务请求时,VC 为其分配RU 资源进行服务,虽然同时要服务多个任务请求,但是可以把整个VC 看作是一个基于M/M/1 的队列模型。队列中的任务等待流为λ,即队列的到达率。本文假设对于每一个RU 资源的服务率为μu,那么此时整个系统的服务率为:

其中:αk表示k类型车辆可以提供的RU 数量,α为系数;Nk表示在VC 覆盖范围内车辆类型为k的车辆数量,且满足λ<μ关系。根据队列理论,对于队列中一个任务i的等待时间为:

对于任务i的执行时间可以表示为:

其中:表示对于任务i分配的RU 数量。
1.3 二次资源分配机制
由于VC 环境的动态性,车辆进入或者离开都会对VC 中可用的资源产生影响,进而影响到分配决策,因此以往简单的卸载方式很难动态地满足任务的计算需求。本文中使用基于双时间尺度模型的SRA 机制。
在本文的模型中,存在大时间尺度和小时间尺度两种资源分配动作。当VC 接收到范围内车辆的任务请求时,需要决定接收请求或者把请求发送到附近边缘服务器上执行,这个过程本文定义为大时间尺度动作。大时间尺度动作的间隔比较长,期间可以根据环境的变化对已经分配RU 的任务请求进行资源二次调整,这个调整动作过程定义为小时间尺度动作。比如,若某一任务请求分配的资源很充足,则可以适当缩减其RU 数量,另一方面,对于某一请求分配的RU 资源不能在时间限制之前完成,且此时资源池中还有剩余的资源,那么就可以通过增加其RU 数量来减小任务完成时间。总地来说,在大时间尺度上决定任务请求是否接收,在小时间尺度上不断地调整已分配的RU 数量以跟踪环境细微的变化,这样通过SRA 机制,模型可以很好地适应高速动态的VC 环境。
1.4 问题归纳
在给定的时隙h内,对于在VC 覆盖范围内的车辆v生成的j类型请求i,使用=1 来表示VC 接收该请求,使用=1 表示VC 将该请求发送到附近的边缘服务器,在其他情况下和都为0。本文系统的优化目标是在H的时间段内,调整对VC 范围内车辆的任务请求的资源分配数量,在任务延迟要求的限制下最大化提高系统效用,从而提高用户的服务质量。
因此,可以归纳出如下优化问题:

其中:β为VC 选择将任务发送到附近边缘服务器时受到的惩罚;H为每一幕的时隙数;Nj表示当前时隙j类型的请求数;为完成任务i需要的时间,可以表示为,对于前两条限制表示对于一个请求VC 只能选择一种处理方式;L表示一次可以分配的最大RU 数量。
2 车辆云计算资源分配系统
2.1 决策模型
与单智能体强化学习不同,MARL 中由于状态空间变大,联合动作空间随着智能体数量呈指数增长,因而很难拟合出一个合适的函数来表示真实的联合动作值函数。在这样一个随机博弈[25]环境中,智能体需要在有限的计算资源下协作,实现整体的收益最大化。本文使用元组G=(S,U,P,R,O,γ)来描述部分可观测马尔可夫决策模型(POMDP),在时隙t有st∈S表示全局的环境信息,智能体的数量为A,则对于每一个智能体a∈A都需要选择一个动作ua∈U去组成一个联合动作u,通过把联合动作u作用于环境,根据状态转移概率P(st+1|st,ut)进入下一个状态。同时,所有的智能体都会收到一个奖励r(st,ut)。在实际观测过程中,智能体只能获取自身的状态信息,不同的智能体具有不同的观测信息用O(s,a)来表示。使用RNN 对于不完全观测可以取得较好的效果,因此使用τa表示智能体a的动作观测历史,基于这个动作观测历史来构建策略函数πa(ua|τa),由此可以得到联合动作值函数:

其中:γ表示折扣因子。
2.1.1 状态与观测空间
对于VC 环境中全局状态st需要考虑车辆、队列等所有信息,可以表示为:
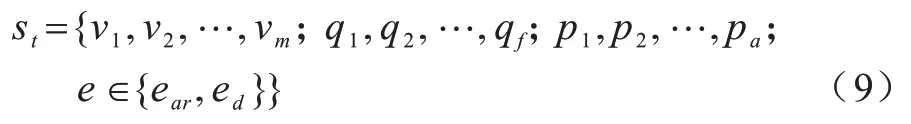
其中:vm表示VC 范围内车辆的信息,包括车辆类型、位置、速度以及生成的任务请求;qf表示队列中等待的请求信息;pa表示正在执行中的任务请求信息,每一个智能体a处理一个任务请求;e表示当前时隙的事件,包括请求到来ear与请求离开ed。对与当前时隙的任务请求,需要获取的部分观测信息Oa,有:
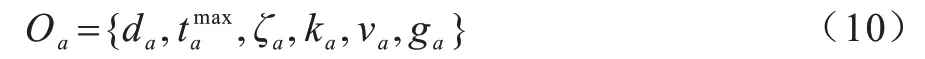
其中:ka表示请求a所属车辆的类型,不同类型的车辆可以提供不同数量的计算资源;va和ga分别表示当前时隙车辆的速度与位置坐标。
2.1.2 动作空间
由于系统模型使用基于双时间尺度的SRA 机制,因此存在两种动作。对于大时间尺度,在时隙t的联合动作为ul={a1,a2,…,an|a∈{0,1,…,l}},其中,an表示对第n个请求分配的RU资源数量,最大值为l,当an=0 时表示VC 拒绝接收请求并把请求发送到附近的边缘服务器上执行。对于小时间尺度,在时隙t的联合动作为:
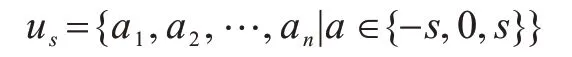
其中:-s与s表示对某一请求减少或增加s数量的RU;当an=0 时表示对该请求不做任何操作。
2.1.3 奖励函数
本文系统的优化目标是最大化系统整体效用,强化学习的目标就是最大化获得的累计奖励,所以定义奖励函数值为在每一个时隙获得的效用值。若要获得更大的效应值,那么就要最小化每一个接收的任务执行时间ttot。对于每一个任务请求的效用,本文定义Δt=(tmax-ttot)为请求完成总时间与其最大时间限制的差值,则奖励函数如下:
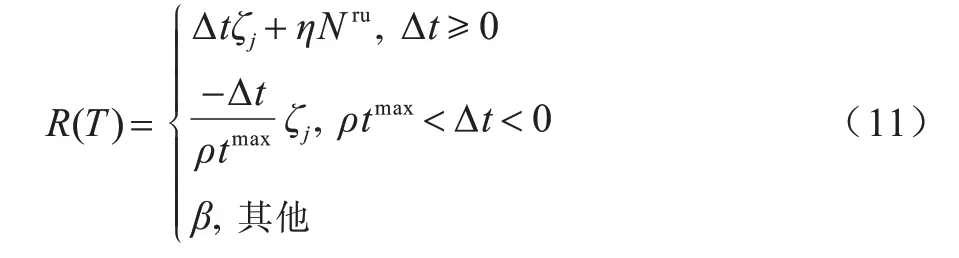
其中:β表示对VC 拒绝请求的惩罚;η表示一个RU可以获得的效用值;ρ是一个参数,满足0 <ρ<1。最优的资源分配策略π*就是使得整体奖励最大的策略,可以表示为:

2.2 DQN 与SRA-QMix
DQN 是在Q-Learning 算法的基础上引入神经网络来代替Q 表格,使得可以处理连续状态的环境,其损失函数为:

本文将QMix 算法与SRA 机制相结合,提出一种新的计算资源分配算法SRA-QMix,使用集中式训练分布式执行(Centralised Training with Decentralised,CTDE)机制。每个智能体表示要处理的请求,所有智能体的部分观测之和就是全局状态,即通过全局状态st信息训练Q网络得到全局的值函数Qtot(τ,u)。在分散执行阶段,根据每个任务请求信息以及其所属车辆的局部观测状态oi来估计动作价值,每个智能体都采取贪婪策略来选择动作。全局Q值计算过程如图2所示。

图2 SRA-QMix 算法全局Q 值计算过程Fig.2 The process of the global Q value calculation in SRA-QMix algorithm
全局值函数Qtot(τ,u) 与单个智能体值函数Qa(τn,un)单调性相同,那么对全局值函数取argmax操作与对单个智能体的值函数取argmax 操作能够得到相同的结果:

为了保证值函数的单调性使得式(14)等式成立,算法存在以下约束:

不同于值分解网络(Value-Decomposition Networks,VDN)算法中对所有智能体的值函数简单相加,如图2所示,QMix 使用混合网络通过非线性方式对单智能体局部值函数进行整合:
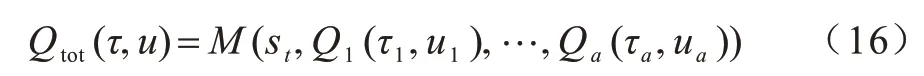
其中:M表示Mixing 网络,是一种前馈神经网络。为了满足式(15)的要求,混合网络的参数由单独的超参数网络生成,其采用一种超网络结构,输入不仅有各个智能体的局部值函数,还包括全局状态信息st,输出为混合网络的权值与偏移量。这样,通过对Qtot(τ,u)进行分解,对其进行argmax 操作的计算量就不再是随着联合动作空间呈指数增长,而是随着智能体数量呈线性增长,极大地提高了算法的效率。每一个智能体的结构都为DRQN 网络,输入为单个任务观测的轨迹信息,经过GRU 循环网络,即具有学习长时间序列的能力。在程序中对于所有的智能体可以使用one-hot 编码方式共用同一套网络。
SRA-QMix 是基于DQN 算法得到,两者基本流程相似,都用到了经验池用来存放经验信息,同时存在相应的目标网络,其最终的损失函数可以表示为:
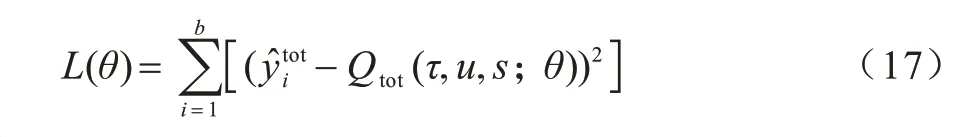
其中:b表示从经验池中采样的样本数量。

SRA-QMix 算法描述如下:
算法1SRA-QMix 算法
输入DRQN 和Mix 神经网络参数,全局状态st以及所有任务的部分观测
输出可以获得最优效用值的动作向量
1.初始化环境参数,车辆到达流λ,车辆类型以及环境参数β、η 和ρ;
2.初始化DRQN 网络、Mix 网络和相应的目标网络参数,以及算法的超参数;
3.初始化两种时间尺度对应的经验池Buffer;
4.对于每个epoch 做以下操作:
5.重置环境信息得到初始st,根据当前step 为每一个agent 根据DRQN 网络的输出选择动作;
6.获取下一时刻状态st+1与奖励;
7.重复步骤5 和步骤6,直到当前环境结束,将搜集到的大时间尺度和小时间尺度经验序列存入经验池;
8.从相应经验池中选取batch_size 大小的数据分别对大时间和小时间策略进行训练;
10.利用Mix 网络与式(18)计算Qtot与
11.利用式(17)计算损失;
12.更新网络参数;
13.一定次数后更新目标网络参数;
14.结束当前训练,进入下一个epoch;
15.结束算法。
3 仿真结果与分析
3.1 仿真环境与参数
仿真软件使用SUMO,硬件使用Intel Xeon W-2133,32 GB 内存,基于Ubuntu18.04,仿真程序使用Python3.6+Pytorch1.8 编写。仿真场景考虑了一个十字路口的区域,部署一台RSU 与作为VC 的控制中心,车辆进入VC 环境后,假设都会分享计算资源,同时每辆车辆都有一定的概率产生任务请求。算法采用退化∊-greedy 策略,部分仿真参数如表1 所示。
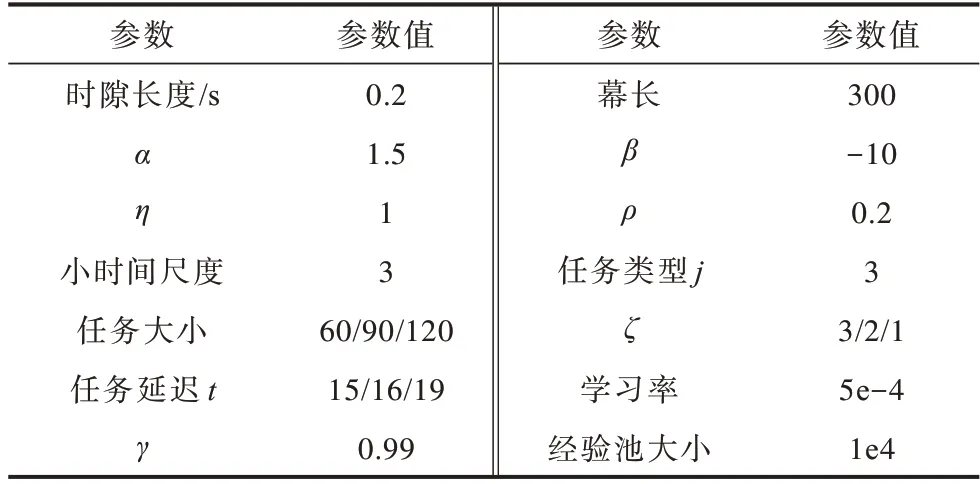
表1 部分仿真参数设置Table 1 Setting of part the simulation parameter
3.2 结果分析
为验证本文计算资源分配算法SRA-QMix 的性能及其双时间尺度的有效性,本文将以下3 种算法作为基准进行对照:
1)QMix。没有使用二次资源分配策略的方案。
2)MADDPG。确定性策略梯度算法DDPG 的多智能体改进版。
3)SRA-MADDPG。在MADDPG 算法的基础上增加二次资源分配机制。
图3 所示为不同算法下的总效用值随车辆到达率λ变化情况,λ越大表示同一时刻进入VC 覆盖范围的车辆就越多,相应地,同一时隙需要处理的请求数也会增加。当λ为0.3 时,4 种算法效用值都比较低,这是由于此时任务数量比较少。随着车辆到达率的增加,4 种算法的总效用值也随之增加。可以看出,SRA-QMix算法可以获得更高的效用值,相比SRA-MADDPG 算法,系统效用平均提高了70%。这是因为该算法可以更好地处理多个任务之间的合作竞争关系,得到整体最大奖励。另外,相比于不使用SRA 机制的算法,SRA 机制可以获得更高的系统效用值。

图3 系统总效用随车辆到达率的变化情况Fig.3 The total utility of the system varies with the vehicle arrival rate
图4 所示为不同算法下任务的完成率与车辆到达率λ之间的关系。可以看出随着车辆到达率的增加,对于任务请求的完成率在下降。在λ=0.3 时刻,SRA-QMix 算法的任务完成率可以接近90%,但是随着到达率的增加,4 种算法对任务的完成率都随之下降。这是因为随着到达率的增加,每一时刻系统需要处理的请求数量也会增加,对于在有限的RU 计算资源情况下,算法的分配策略就不再精准,任务在最大时间限制之前完成的概率就减小。在不同到达率下提出算法相比于SRA-MADDPG 算法的任务完成率平均高6%。另外,相比于未使用SRA 机制的算法相比,上述两种算法任务完成率分别提高了13%和15%。可以看出应用了SRA 机制可以显著提高算法性能,这是由于通过小时间动作的不断微调,提高了资源利用率。

图4 任务完成率与车辆到达率的关系Fig.4 Relationship between task finish rate and vehicle arrival rate
从图3 和图4 可以看出:MADDPG 算法的表现是弱于QMix 算法的,这是因为MADDPG 算法是在深度确定性策略梯度DDPG 算法基础上改进得来的,对于Critic 部分能够获取到全局状态用来指导单个Actor 的训练,在测试时Actor 根据局部观测来采取行动,遵循集中式训练分布式执行过程。但是由于缺乏QMix 对于各个智能体的Q值融合机制,没有整体的奖励函数,对于在资源受限情况下的智能体协同表现要弱于QMix 算法。
图5 所示为任务完成率与参数α之间的关系。其中α表示车辆类型与可提供的RU 数量之间的关系,α越大,同样的车辆就可以提供更多的计算资源,那么整体的RU 数量就会增加。本文设置当前每个时刻可以处理的请求数量为10。在开始时,由于RU数量很少,此时4 种算法的完成率都比较低,主要是因为资源池中没有足够多的RU 资源。随着α的增加,同样的车辆可以贡献更多数量的RU,4 种算法的任务完成率也随之增加,因为更多的资源可以使得请求更快地被完成。可以看出SRA-QMix 算法具有最好的表现。
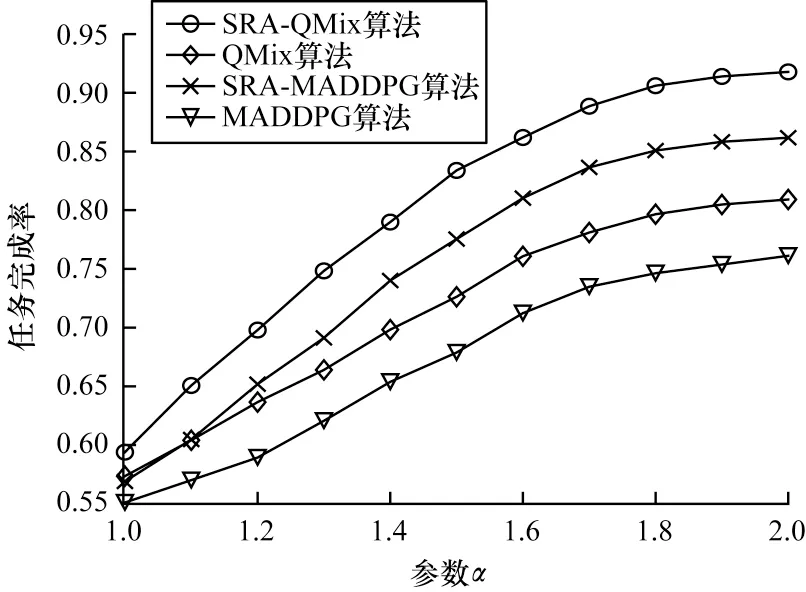
图5 任务完成率与参数α 的关系Fig.5 Relationship between task finish rate and parameter of α
图6 所示为小时间尺度在不同更新间隔下总效用与任务完成率的情况。此处展示的是车辆到达率在λ=1、α=1.5 情况下的表现,小时间尺度更新间隔越小,更新越频繁。当更新间隔为1 时隙时,表示在环境的每一步都会通过小时间尺度更新对分配的RU数量进行调整。可以看出,在间隔为1 时隙时,两种算法都有最高的效用值和任务完成率。随着更新间隔时间的增加,系统总效用和任务的完成率都随之下降,说明通过高频率的小时间尺度更新可以适应高度动态的VC 环境,帮助算法学习到更好的资源分配策略。
图6 系统总效用和任务完成率随小时间尺度更新间隔的变化Fig.6 The total utility and task finish rate of the system varies with the small time scale update interval
4 结束语
对于VC 环境的任务卸载与计算资源分配问题,本文提出一种考虑异质性任务和车辆的多智能体卸载算法SRA-QMix,并根据VC 环境中计算资源波动对任务卸载的影响,提出二次资源分配机制,即在大时间尺度上决定是否接收任务请求,在小时间尺度上对已经分配的计算资源进行动态调整。对于多智能体环境下状态与动作空间的维度诅咒问题,结合QMix 算法对各个局部Q值进行非线性融合,降低算法复杂度。针对VC环境中计算资源的分配问题,通过预测VC 范围外的车流量,在大时间尺度上提前做出应对策略,从而辅助大时间尺度上的资源分配决策过程,提高算法的动态资源分配能力。实验结果表明,与深度确定性策略优化算法对比,本文提出的决策算法具有更高的效用值与任务完成率,并证明了二次资源分配机制对解决车辆云环境中任务卸载与资源分配问题的有效性,且高频次的小时间动作对车辆云卸载环境有更好的适应性。近年来深度强化学习技术受到人们越来越多的关注,如何使用深度强化学习技术对车辆状态和奖励函数设定等车联网任务卸载策略进行通用建模,并使其更加简单易用,将是下一步的研究方向。
猜你喜欢
中国西部(2022年2期)2022-05-23
当代县域经济(2022年4期)2022-04-08
力学学报(2021年7期)2021-11-09
科学技术创新(2021年18期)2021-06-23
能源工程(2021年1期)2021-04-13
苏州科技大学学报(自然科学版)(2021年1期)2021-03-24
军民两用技术与产品(2021年12期)2021-03-09
苏州科技大学学报(自然科学版)(2020年1期)2020-04-13
微型电脑应用(2019年10期)2019-10-23
计算机测量与控制(2017年12期)2018-01-05
