
影响最大化问题中基于K-truss 的投票改进算法
2023-01-09 14:29孙飞翔陈卫东林天森
计算机工程 2022年11期
孙飞翔,陈卫东,林天森
(华南师范大学 计算机学院,广州 510631)
0 概述
随着微信、Facebook 和Twitter 等在线社交网络的兴起,越来越多的人们使用不同的社交网络进行交流和分享,使得网络中信息扩散研究成为社交网络分析的热点。影响最大化(Influence Maximization,IM)作为信息扩散研究中的关键问题,具有较广泛的应用场景。文献[1-3]分别把IM 问题应用于病毒式营销、谣言控制和社会计算领域,将社交网络建模为一个图G,并给图G的每条边分配一个传播概率。IM 问题是给定一个传播模型及正整数k,从节点集V中选择一个不多于k个节点的种子集合S,使得S的影响范围σ(S)达到最大。
文献[4]证明IM 问题也是NP-hard 问题,表明IM问题在多项式时间内不可能得到最优解的精确算法,其求解方法主要是近似算法和启发式算法。文献[5-6]针对IM 问题,提出基于次模函数的贪心近似算法,具有较大的时间复杂度,因此,该算法在规模较大的图上难以得到实际有效的应用。以上贪心近似算法均具有较大的时间复杂度,其原因为在节点选择过程中,每个种子节点的选择均使用大量的Monte-Carlo 模拟来计算节点集的影响范围。为了更快地求解IM 问题,启发式算法利用不同的策略来代替模拟过程。此类算法分为基于中心性的算法、基于社区的算法和基于排序的算法。启发式算法与近似算法相比具有较低的时间复杂度,但是在具有不同拓扑结构的图上,启发式算法和近似算法都缺乏稳定性。文献[7]提出基于VoteRank的投票算法,在求解IM 问题时具有较强的稳定性。在该类算法中,节点v具有投票能力vav和得票分数vsv两种属性,其中vav表示节点v能够给邻居节点投票的票数,vsv表示节点v的邻居给其投票的票数总和。此外,在每轮投票中得票分数最高的节点将不参与后续的投票,即投票能力为0,其邻居节点的投票能力也会随之得到一定程度的弱化。投票算法通常定义一个衰减因子f来表示投票能力的弱化程度。然而该算法并未有效地区分节点对其不同邻居的投票能力,种子节点所有的邻居均使用相同的衰减因子,不能有效地表示出它们投票能力的弱化程度。
本文基于K-truss 提出一种改进的投票算法TrussVote,用于求解IM 问题。基于边的truss 值设计节点有效投票能力的计算方法,该方法不仅考虑网络拓扑结构对投票能力的影响,同时也有效地区分节点对其不同邻居的投票能力。基于节点的相似性提出动态的衰减因子,表示节点邻居的投票能力具有不同程度的弱化。此外,本文结合IC 模型下的原始传播结果提出影响范围的等价分析指标——传播差异(Diffusion Difference,DD),以直观地区分各个算法的实验效果。
1 相关工作
为了表述方便,表1 所示为本文所需主要变量的说明。
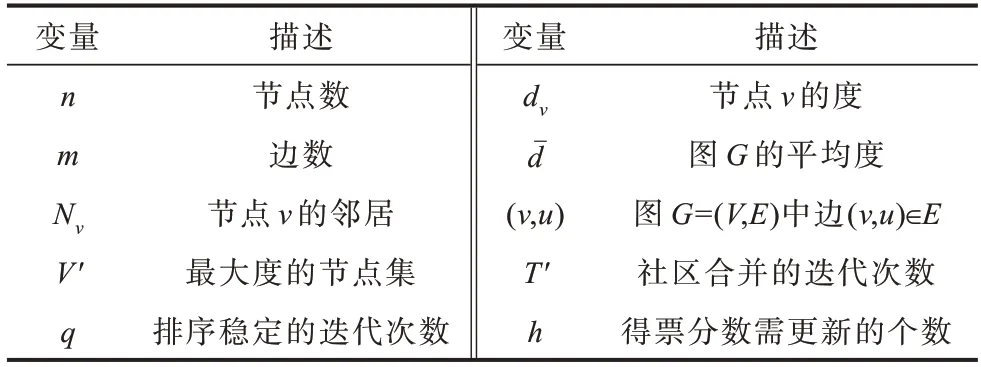
表1 重要变量的说明Table 1 The description of important variables
网络中节点的中心性是衡量节点重要性的关键指标,中心性较高的节点在网络中通常占据着信息传播的关键位置。节点的中心性分为局部中心性和全局中心性。文献[8-10]和文献[11-12]分别基于局部中心性和全局中心性提出不同的启发式算法,以求解IM 问题。此类算法的主要原理是在计算每个节点的中心性之后,选择中心性最高的前k个节点作为种子节点集。相比基于局部中心性的启发式算法,基于全局中心性的启发式算法在获得较优实验效果的同时提高了算法的时间复杂度。
影响力的扩散与社区结构有着密切关联,并且在社区内节点之间联系紧密,更容易传播影响力。文献[13-14]基于图的社区提出用于求解IM 问题的方法,其原理是将网络中的节点划分为不同的社区,并在每个社区中选取影响力较大的节点作为种子节点。文献[15-16]提出基于排序的算法,采用不同方式定义节点的影响力,通过迭代方式使节点按照影响力的排序达到一个稳定状态。该类算法与基于中心性的算法相比能够获得更广泛的影响力覆盖范围,但迭代次数的增加也提升了算法的时间复杂度。
文献[7]提出一种新的解决方案用来求解IM 问题,它最早基于投票机制提出VoteRank 算法。在初始化阶段,每个节点的投票能力均被设置为1,在投票过程中,每轮选出一个得票分数最高的节点作为种子节点,在此基础上,使用固定的衰减因子弱化该种子节点一跳邻居的投票能力。当权重表示节点间联系紧密性的加权网络时,文献[17]基于VoteRank提出WVoteRank 算法,在计算节点的得票分数时,权重的差异使得节点对其不同邻居的投票能力产生差异。文献[18]设计的NCVoteRank 算法认为节点的投票能力取决于其在网络中的拓扑结构,并提出邻居核心值(Neighborhood Coreness,NC)的概念,当计算节点的得票分数时,综合考虑了邻居节点的NC 值及投票能力。文献[19]提出EnRenew 算法,采用信息熵的方式来表示节点的重要性及投票能力。文献[20]不仅引入投票比例的概念以区分节点对其不同邻居的投票能力,而且在更新种子节点邻居的投票能力时,采用不同程度的衰减因子分别弱化其一跳和二跳邻居的投票能力。
2 本文算法
本文基于第1节中的投票机制提出TrussVote算法,该算法在投票阶段使用K-truss的相关理论及算法区分节点对其不同邻居的投票能力,在更新阶段通过节点相似性指标定义一个动态的衰减因子,用于表示种子节点邻居的投票能力具有不同程度的衰减。
2.1 K-truss 分解
K-core[21]揭示了网络的结构性质和层次性质,而K-truss 则是K-core 基于三角形的一种扩展,它所推导的子图在结构上更接近一个团[22]。
定义1(边的支持度sup(e,G))边的支持度等于图G=(V,E)中边e∈E所在三角形的个数。
定义2(K-truss 子图TK)若满足K≥2,∀e∈且sup(e,G)≥K-2,则称TK为G的K-truss子图。
定义3(边e=(v,u)的truss 值tvu)tvu=max{K:e∈,TK为图G的K-truss 子图}。
定义4(边集K-class,记为ΦK)图G=(V,E)的ΦK={e=(v,u)|e∈E,tvu=K}。
本文的投票算法通过引入K-truss 相关理论,不仅考虑网络的拓扑结构对投票能力产生的影响,同时有效地区分节点对其不同邻居拥有不同的投票倾向。对于边e=(v,u),tvu的计算与v和u的公共邻居相关,因此边的truss 值在一定程度上反映了节点间联系的紧密程度。对于同一节点的不同邻居,邻边的truss 值越大,其两端节点的联系越紧密。无向图示例如图1 所示。
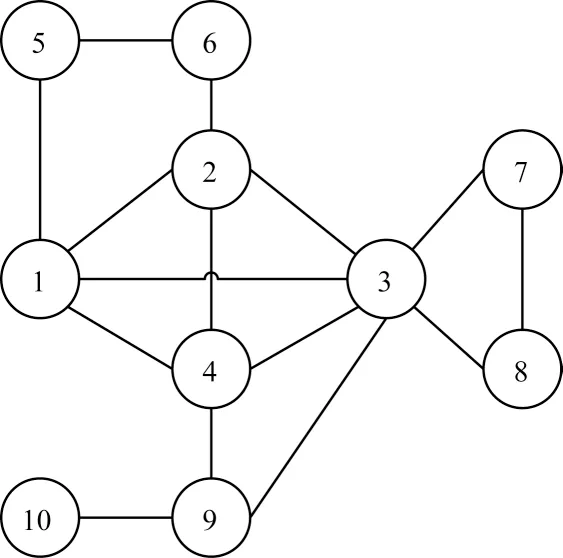
图1 无向图示例Fig.1 The example of undirected graph
在节点3 的邻边中,边(3,4)具有最大的truss 值,它们的联系也更加紧密。基于网络的核分解理论[23],K-truss 分解与K-core 分解相似,K值越大的子图在网络中的相对位置越趋于核心。对于网络中不同位置的节点,truss 值可以对节点的投票能力进行有针对性和不同程度的放大。从图1 可以看出,Φ3和Φ1中的边对它们两端节点投票能力的放大程度不同,在同一轮投票中趋于中心位置的节点将会获得更高的得票分数。
2.2 有效投票能力
节点间相似性差异会导致节点对其邻居的投票能力不同。为了更准确地表示这种差异,本文基于边的truss 值提出有效投票能力,用于计算节点v对其邻居节点u∈Nv的投票能力。当不考虑节点间的相似性时,节点v给其每个邻居投票的概率均为1/dv;当考虑节点间的相似性时,本文基于边的truss值定义了节点v对其邻居节点u∈Nv的有效投票能力,其计算过程如式(1)所示:

2.3 得票分数
本文在计算节点的得票分数时,利用有效投票能力来表示节点对其邻居拥有不同的投票票数,而这种有效的投票能力也会受到边的传播概率的影响。在实际传播过程中,节点v通过边(v,u)将u激活,其激活概率大于该边的传播概率。因此,基于传播模型的随机性特点,本文将投票算法中能够得到的有效投票能力乘以传播概率,用来表示u能够获得v投票的票数期望值。对于节点表示能够得到其邻居节点u∈Nv的实际票数,其中puv为边(u,v)的传播概率。与其他投票算法相似,本文节点v的得票分数来源于邻居节点的投票,其计算过程如式(2)所示:

2.4 衰减因子
本文基于ra 指标[24]提出一种动态的衰减因子,以区分种子节点不同邻居的衰减情况。ra 指标是一种基于资源分配策略的节点相似性指标,ra(v,u)表示节点v、u之间的相似度,也表示v接收到u资源的能力。其计算过程如式(3)所示:

当节点v被选为种子节点后,其邻居节点u∈Nv需去除来自v的资源,本文将减去的这部分视为节点u投票能力的衰减程度fu,其计算过程如式(4)所示:

当节点v被选为种子节点后,其邻居节点u∈Nv的投票能力可根据式(5)计算:

2.5 复杂度分析
TrussVote 的算法过程:首先,在初始化阶段,计算所有边的truss 值,并且给每个节点都赋予相同的初始投票能力;然后,重复k轮投票,每次均将投票分数最高的节点选为种子节点,并使用动态的衰减因子更新其邻居节点的投票能力。TrussVote 如算法1所示。
算法1TrussVote 算法


3 实验设计
本文所有的算法均使用Python 语言来实现。运行环境为Windows10 操作系统,内存8 GB,处理器Intel®CoreTMi7-7700 CPU @3.60 GHz。
3.1 数据集
本文实验选用4 个不同规模的真实网络数据集,数据集的统计特征如表2 所示,其中pc表示网络的传播阈值[25]。

表2 数据集的统计特征Table 2 Statistics characteristic of datasets
3.2 对比算法
为验证本文算法的性能,本文将其与当前具有代表性的启发式算法进行对比。不同算法的时间复杂度对比如表3 所示。
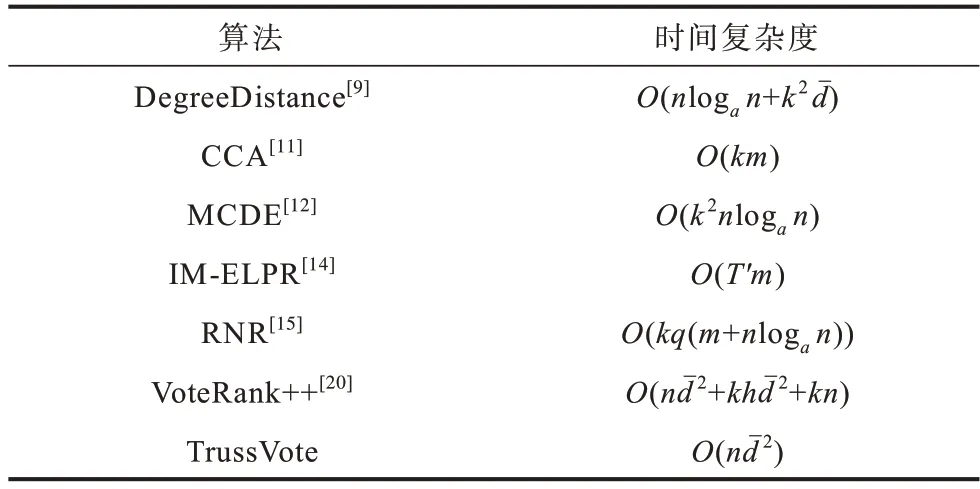
表3 不同算法的时间复杂度对比Table 3 Time complexity comparison among different algorithms
3.3 实验设置与评价指标
本文在4 个不同规模的真实网络数据集上,使用IC 模型[4]和SIR 模型[26]对不同算法进行对比实验。
3.3.1 IC 模型
在IM 问题中,IC 模型是一种应用最为广泛的影响力传播模型。在IC 模拟传播过程中,每个数据集使用pc作为传播概率,并且每次选择50 个节点作为初始传播源的种子集合。在IC 模型下的影响范围即种子节点影响扩散的个数,并将其作为算法的主要评价指标。由于IC模型的传播具有随机性,因此本文使用10 000次的Monte-Carlo 模拟来保证实验能够得到较为精确的影响范围。但是多数算法在IC 模型下的影响范围比较接近,并且当k值不同时,不同算法的表现也会上下浮动。为了便于分析,本文给出一个等价的分析指标——传播差异。算法a1和a2在k=x时的传播差异如式(6)所示:
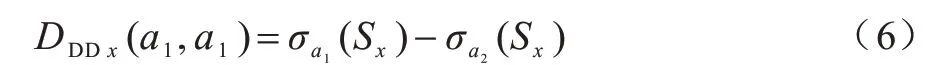
其中:σa(Sk)表示算法a选取大小为k的种子集Sk所达到的影响范围。
3.3.2 SIR 模型
SIR模型是一种经典的病毒传播模型,近年来在IM问题中得到了广泛的应用。在SIR 模型中,每个节点具有易感S、感染I和治愈R 这3种状态。节点由易感S到感染I 的状态转换称为感染,感染率为μ;节点由感染I 到治愈R 的状态转换称为治愈,治愈率为β。该模型下算法的评价指标有2 个,第1 个是当给定初始感染比例时对比算法在t时的感染规模F(t),计算过程如式(7)所示:

其中:nI(t)表示t时感染状态的节点个数;nR(t)表示t时恢复状态的节点个数。第2 个评价指标是当初始感染比例不同时,对比算法的最终感染规模F(tc),计算过程如式(8)所示:

在SIR 模型中,感染比例λ=μ/β对模型的传播速度具有至关重要的作用,本文将其设置为1.5。感染率的选择没有固定标准[19],一些算法根据边的传播概率来选取种子节点,而本文为了保证算法的有效性及统一性,将每个数据集的传播阈值pc设置为感染率。
4 实验结果分析
在解决IM 问题的投票算法中,节点向其邻居的投票可以被看作是一个局部信息的扩散过程,当每轮投票结束后均选择信息量最高的节点作为种子节点。投票算法通过信息扩散最大化的方法来识别网络中最有影响力的节点。因此,IM 问题作为信息扩散的核心及关键问题,使用投票机制获得较优的实验效果。
4.1 IC 模型下的结果分析
本文将CCA 算法作为基准算法来计算不同算法在各个数据集上的传播差异。当种子节点数k分别为10、20、30、40、50 时,CCA 算法在不同数据集上的传播差异如表4 所示。
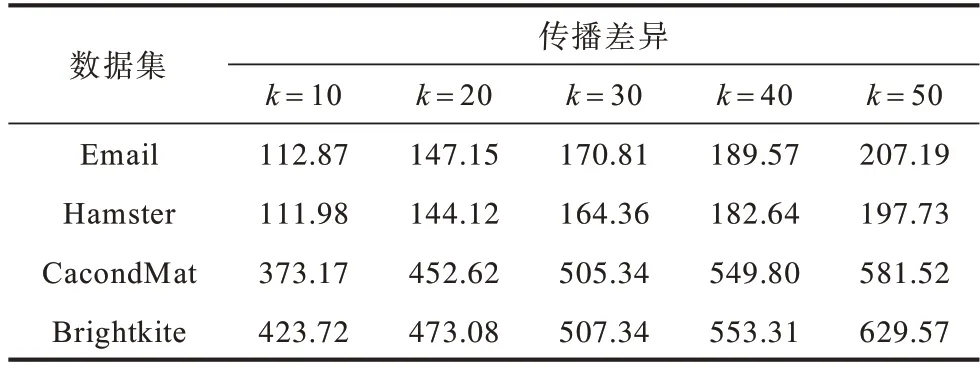
表4 CCA 算法的传播差异Table 4 Diffusion difference of CCA algorithm
在不同数据集上各个算法使用IC 模型产生的传播差异如图2 所示。从图2 可以看出,大多数算法在开始时选择的节点拥有类似的影响范围,但随着种子节点数的增大,算法的表现呈现出不同的特点。
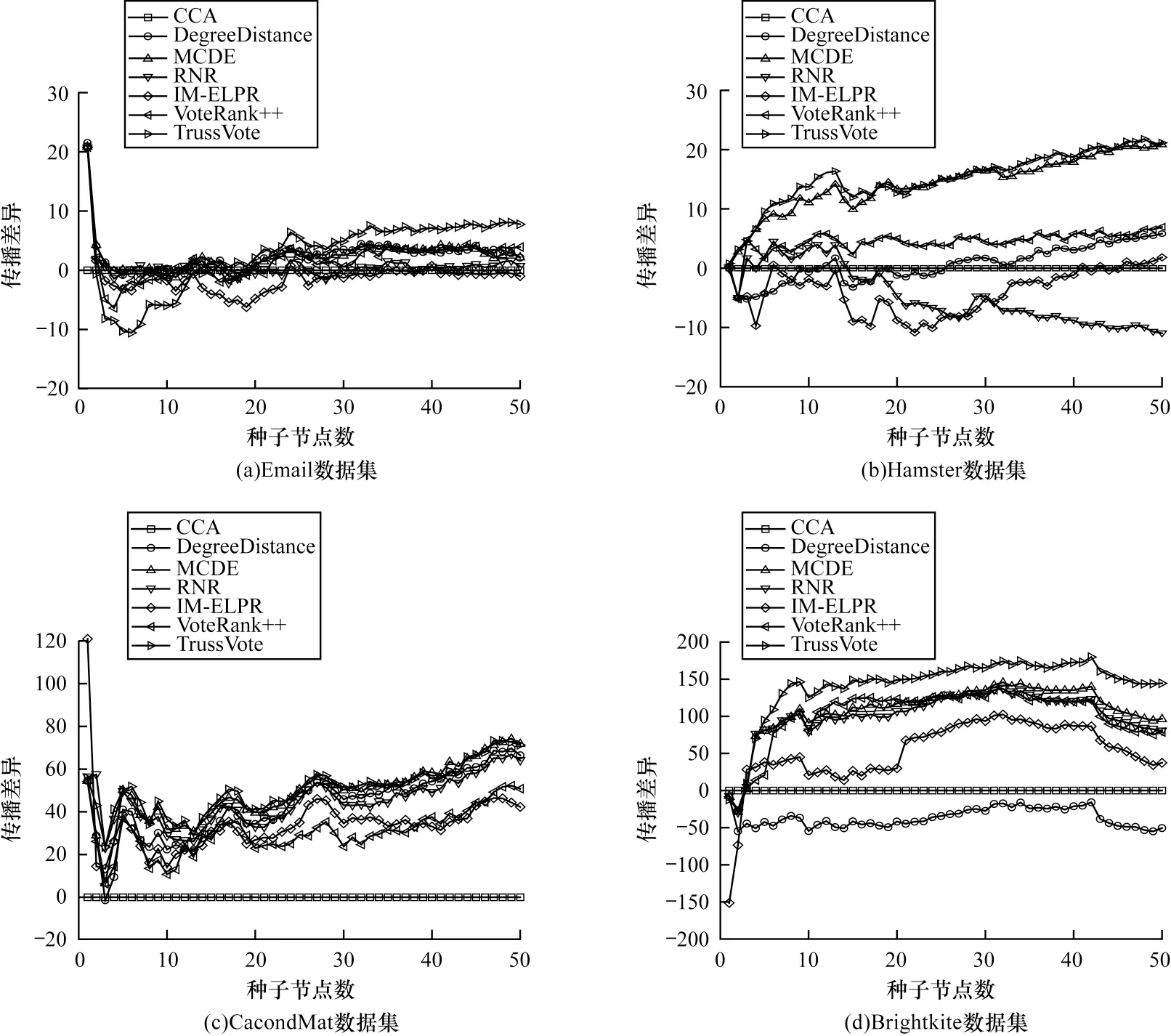
图2 IC 模型下不同算法的运行结果Fig.2 The running results of different algorithms under IC model
在Email 数据集上,TrussVote 和VoteRank++具有类似的传播特点,当种子节点数较小时影响的范围相较于其他算法小,但随着种子节点数增大,影响范围逐步增大并趋于稳定。相比VoteRank++,TrussVote 在种子节点数较大时影响范围最大。这种变化趋势也说明了TrussVote 在消除影响力重合时的作用更加显著。在Hamster和CacondMat数据集上,TrussVote 与MCDE总体的变化趋势接近,但TrussVote的表现更好,在Email和Brightkite数据集上,TrussVote具有较优的实验结果。在CacondMat 数据集上,除CCA 算法以外,其他算法具有相似的传播特点,影响范围的变化情况都基本类似,而TrussVote 算法在k∈[1,50]的多数情况下能获得最广泛的影响范围。
在Brightkite 数据集上,CCA 与DegreeDistance算法的表现较差,在其他数据集中的表现也有波动。这说明基于中心性的算法,在网络特点不同的数据集中难以产生持续有效的实验效果。在Hamster 数据集上RNR 算法的表现说明它在度数较大的数据集中,也不能有效解决富人俱乐部效应。与投票类算法相似,随着种子节点数增大,IM-ELPR 算法的影响范围逐渐优于其他算法,但TrussVote 与其相比,不仅时间复杂度更低,而且传播效果也更好。在IC模型下不同算法的实验结果表明,TrussVote 算法具有更广泛的影响范围。
4.2 SIR 模型下的结果与分析
当给定初始感染比例时,SIR 模型下不同算法的感染规模F(t)随迭代轮次变化的结果如图3 所示。当初始感染节点数相同时,TrussVote 只在Hamster数据集上的峰值略低于MCDE,而在其他数据集上均达到峰值。TrussVote 选取的种子集能够在最短的时间内感染更多的节点,说明TrussVote 具有更快的感染速度与更大的感染规模。
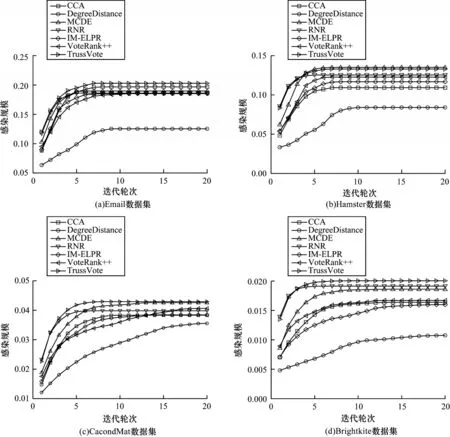
图3 不同算法的感染规模随迭代轮次的变化曲线Fig.3 Change curves of infection scale of different algorithms with iterations
各个算法的最终感染规模F(tc)随初始感染比例增大的变化曲线如图4所示。在Email和CacondMat数据集上,TrussVote 在初始感染比例较小的情况下最终感染规模略低于VoteRank++及IM-ELPR 算法,但随着初始感染比例的增大,TrussVote拥有更大的感染规模。TrussVote 在Hamster 数据集上初始感染比例为2.65%时表现相对较差,但在Hamster 和Brightkite 数据集上,TrussVote 的最终感染规模总体最优。这说明TrussVote选取节点的策略及算法更新的过程都较为合理,具有较优的稳定性。在SIR 模型下不同算法的实验结果表明,TrussVote 不仅具有更快的感染速度及更大的感染规模,在不同初始感染比例下也拥有最好的表现。
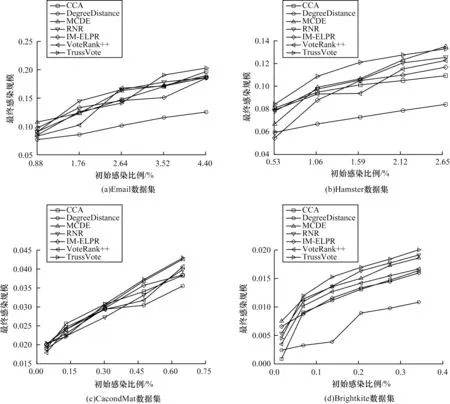
图4 不同算法的最终感染规模随初始感染比例的变化曲线Fig.4 Change curves of final infection scale of different algorithms with initial infection ratio
因此,相比基于中心的算法,TrussVote 在不增大时间复杂度的同时取得了更稳定且有效的实验效果。当迭代轮次较多时,RNR 和IM-ELPR 在较大网络规模中的时间和影响范围相比TrussVote 较差。另外,与VoteRank++更新节点两跳之内的邻居投票能力不同,TrussVote 在更新阶段对节点一跳之内的邻居投票能力赋予了不同程度的更新,不仅具有更低的时间复杂度,同时也能够获得拥有更大影响范围的种子集合。以上实验结果也验证了TrussVote算法的正确性及有效性。
5 结束语
针对社交网络中的影响最大化问题,本文提出基于K-truss 的投票改进算法。在投票阶段和更新阶段分别引入边的truss 值及节点相似性指标对投票类算法进行改进,以区分更新节点邻居的投票能力。在不同规模的真实网络数据集上的实验结果表明,本文算法在具有较低时间复杂度的同时,给IM 问题提供了较有效的解决方案。下一步考虑将本文TrussVote 投票算法应用到IM 的拓展问题中,如利润最大化问题,使其具有更优的鲁棒性。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
四川大学学报(自然科学版)(2021年6期)2021-12-27
计算机应用(2020年12期)2020-12-31
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
