
国内知识产权信息服务研究主题演化分析
2023-01-14 02:24张琳娜朱佳轩
科技和产业 2022年12期
张琳娜, 魏 娟, 朱佳轩
(南京信息工程大学 管理工程学院, 南京 210044)
知识产权是自然人或法人对其智力活动创造的成果依法享有的权利,包括专利权、商标权、著作权等。知识产权信息服务是指信息资源服务、专利信息检索服务、专利信息分析服务、知识产权数据库或信息系统建设服务等多种面向知识产权的信息服务集合[1]。伴随着互联网的普及,知识经济、创新型经济和经济全球化快速发展,知识产权的国际化也日益加深。即使自改革开放以来,中国先后制定并颁布了《商标法》《专利法》《著作权法》等相关法律制度和规范,逐步建立起相对完善的知识产权法律体系[2],但距离知识产权强国还有些距离。
因此选择使用主题分析法对知识产权信息服务领域的研究成果进行分析,利用隐含狄利克雷分布(LDA)模型提取研究主题,提炼总结该领域的研究现状,为知识产权信息服务增加服务主体、拓宽服务范围和深化服务内容等方面提供参考。
1 相关研究
知识产权服务工作在创新驱动战略实施中发挥重要的支持作用。与此同时,知识产权信息服务研究逐渐受关注,成果数量增多、主题呈现多样性。研究内容可以分为服务模式、服务内容、服务对象、服务主体、服务能力和服务效果等方面。王丽萍等对不同层次的专利信息服务模式展开研究,重点探索嵌入科研过程的高端专利信息服务模式[3]。吴红等以山东理工大学知识产权信息服务中心专利服务实践为例,从3个维度探讨高校图书馆的专利服务内容以及服务模式[4]。徐晨琛对服务内容进行调查统计和分析,发现现存的问题,并提出相应建议和对策[5]。马慧萍从服务方式、服务内容等方面对42家“双一流”高校图书馆专利信息服务现状进行调查与分析[6]。刘艳丽等通过调研信息需求,从服务内容、服务形式等对信息服务进行设计,形成嵌入科研管理过程的信息服务模式[7]。冉从敬等从服务效果和内容角度分析存在的问题,以知识产权生态链为逻辑支撑,为建设高校国家知识产权信息服务中心提供参考路径[8]。慎金花等从服务对象、服务内容、服务方式等角度分析高校图书馆信息服务的趋势[9]。张善杰等从服务内容、服务主体和服务能力等方面揭示产业技术创新对高校图书馆专利信息服务的需求[10]。周静等对中国81所拥有教育部科技查新站且开展知识产权信息服务的高校图书馆的知识产权信息服务内容、服务方式、服务效果等进行分析,并提出相应的建议[11]。
以往研究大多数是基于知识产权信息服务的部分维度或特定的服务主体(如高校图书馆),缺少对该领域研究内容的概括和梳理。本文基于LDA的主题建模是一种无监督的文本挖掘方法,被广泛应用于多个领域。通过使用LDA主题模型对知识产权信息服务相关研究成果进行主题识别和挖掘,以期为该领域后续的研究提供借鉴。
2 研究过程
研究分为4个阶段:①确定数据来源,收集数据。从CNKI数据库中检索与知识产权信息服务相关的论文,导出论文题目、摘要和关键词等信息。②对保存的文本数据进行预处理,包括去除标点符号、剔除数字和过滤停用词等。③进行主题识别与抽取。选择按时间先离散的方式,将预处理后的数据分为3个时间窗,即时间窗1(2006—2010年)、时间窗2(2011—2015年)和时间窗3(2016—2020年),采用LDA模型对不同时间窗口下的数据进行主题建模,计算困惑度,并据此确定最优主题数。根据最优主题数,利用 LDA模型抽取出不同时间窗口下知识产权信息服务研究成果的主题,并对主题进行过滤。④根据文档-主题概率分布和主题-词项概率分布结果,进行主题演化分析。
2.1 数据来源与预处理
以CNKI数据库收录的文献为数据来源,以关键词=“(知识产权+著作权+商标权+专利权) * 信息服务”为检索表达式,匹配方式为“精确”,并将文献发表时间限定为2006—2020年,共检索到18 607条学术论文,手工去除字段不完整和非学术研究成果,共保留11 986条。将文献的“题名”“关键词”“摘要”等信息保存为.txt文件,并借助Python的pandas模块将文本文件导入Excel表格中。
使用Python对数据进行预处理,包括将获取的摘要进行格式转换、过滤停用词、词干提取、构建词袋等处理,能够有效提高主题识别的效率和准确度。采用jieba分词模块对预处理后的文本进行分词处理。
2.2 主题聚类
LDA主题聚类模型可以将每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出主题,根据主题进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。LDA主题模型就是根据给定的一篇文档,推测其主题分布。
在进行LDA主题聚类之前,引入TF-IDF分析来提取文本特征关键词。TF-IDF模型是一种词频模式,TF表示一个词在一个特定文档中的出现频率,IDF表示出现了某个词的文档数量的倒数。假设一个大规模的文本数据中,共有M个文档,其中,有m(t)个文档包含了词语t,在文档d中一共有N(d)个词,而词语t出现了n(t,d)次,那么,词语t在文档d中的“关键词得分”为
tf-idf(t,d)=tf(t,d)×idf(t)=
(1)
式中,m(t)+1是为了避免有部分新的词没有出现过而导致分母为0的情况出现。
在一个文档中,得分最高的词就是该文档的关键词,表示这些词语在目标文档中出现次数多,在其他文档中出现次数少。为提高主题识别的准确性,对预处理完后的文本数据进行困惑度计算,计算方法为
(2)
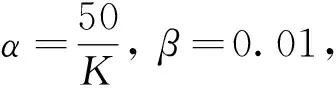
2.3 相似度计算
采用余弦相似度方法计算各时间窗内数据之间的相似度,主题A与主题B的余弦相似度计算公式为
(3)
式中:Ai、Bi分别代表两个主题向量A和B的分量;相似度S的取值范围为[0,1],据此可以得到不同时间窗内数据之间主题的关联性。
3 结果分析
3.1 主题聚类挖掘
通过编写Python代码计算困惑度,完成语料训练后,可以得到3个时间窗的困惑度,如图1所示。
以图1(a)为例,当主题数=7时,困惑度较低,文本聚类效果较好,故以主题数=7对这一时间窗内文本做LDA主题聚类。另外,根据肘部判别法确定图1(b)、图1(c)的最佳主题数,分别为8和6。
确定最佳主题数后,据此对3组文本数据划分主题分布,每篇文档按概率由大到小的顺序输出主题及各主题出现概率最高的10个主题词,并进行人工标识,见表1。
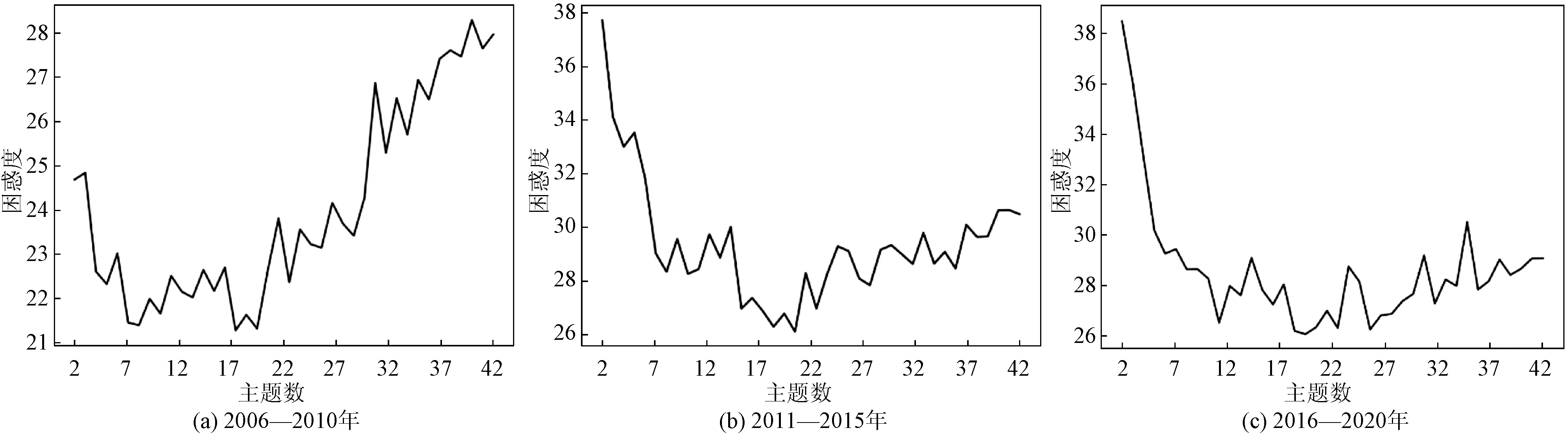
图1 3个时间窗的困惑度
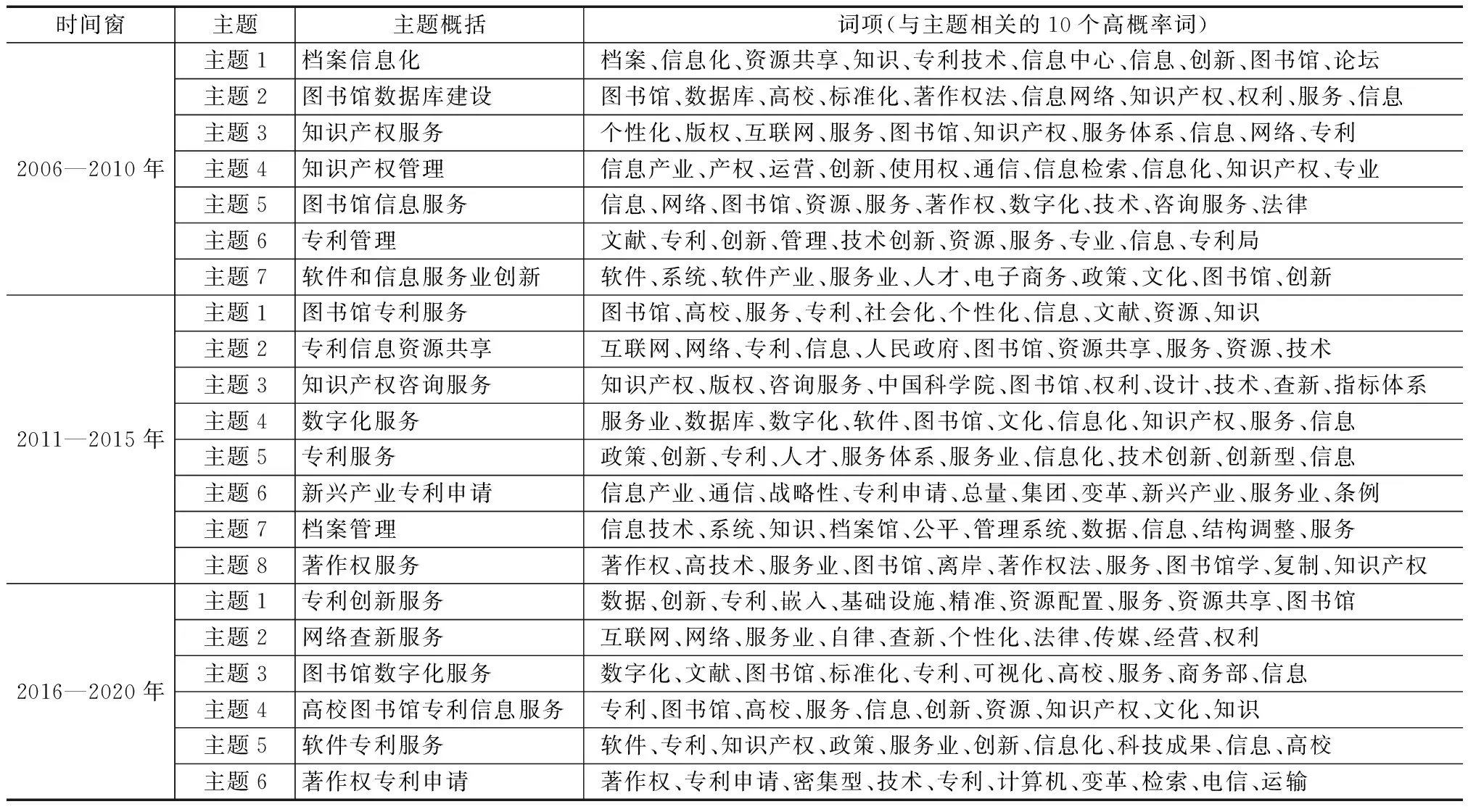
表1 3个时间窗“主题-词项”分布
3.1.1 时间窗1的主题分布
2006—2010年,主题1是关于档案和信息化,涉及专利技术和图书馆;主题2的主要内容为高校图书馆数据库建设,主要涉及标准化和著作权法;主题3则是关于知识产权服务,涉及个性化和版权,图书馆知识产权服务和专利信息服务;主题4的主要内容为知识产权管理,涉及信息产业运营、创新和知识产权信息化服务体系;主题5是关于图书馆信息服务,涉及著作权、数字化和咨询服务;主题6的主要内容为专利管理,包括技术创新、专利服务等;主题7的主要内容为软件产业和信息服务业创新,涉及软件产业人才、政策和文化等。
由此可见,2006—2010年,知识产权信息服务的服务范围以专利和著作权为主,其次是档案、软件和咨询服务;服务主体以图书馆为主,出现专利局;服务模式主要为信息化和数字化,其次是个性化和标准化。
3.1.2 时间窗2的主题分布
2011—2015年,主题1的主要内容为图书馆专利服务,尤其高校图书馆提供个性化、专业化的专利服务;主题2是关于专利信息资源共享,互联网为政府或图书馆提供专利信息资源共享提供平台和途径;主题3的主要内容是知识产权咨询服务,咨询服务机构,如中国科学院、图书馆提供信息咨询、科技查询等服务;主题4的主要内容是数字化服务,涉及图书馆的信息资源数字化、数据库建设、数字图书馆的知识产权等;主题5的主要内容为专利服务,制定政策、推进创新,完善专利人才服务体系;主题6是关于新兴产业专利申请;主题7的主要内容为档案管理,档案馆运用信息技术、管理系统等手段高效地管理档案资料;主题8的主要内容为著作权服务,涉及图书馆信息服务中的著作权和著作权法。
由此可见,2011—2015年,知识产权信息服务的服务范围以专利为主,其次为著作权,再次为软件;服务内容有咨询服务和查新;服务主体以图书馆为主,档案馆也可以提供知识产权服务;服务模式主要为信息化、数字化和个性化。
3.1.3 时间窗3的主题分布
2016—2020年,主题1的主要内容为专利创新服务,以专利信息资源共享为基础,把专利嵌入到基础设施建设、技术创新等,促进资源配置;主题2主要涉及网络查新服务,规范查新工作,个性化查新模式,有助于提高查新质量;主题3的主要内容为图书馆数字化服务,围绕服务的数字化、标准化和专利可视化;主题4的主要内容为高校图书馆专利服务;主题5是关于软件专利服务;主题6的主要内容为著作权专利申请。
由此可见,2016—2020年,知识产权信息服务的服务范围依然以专利为主,其次为著作权和软件;服务内容有查新服务;服务主体以图书馆为主;服务模式除了信息化、个性化,还出现了可视化。
总体来看,2006—2020年内关于知识产权信息服务的研究中,服务范围以专利、著作权、软件为主;服务内容主要有咨询服务和查新服务,2011—2015年出现查新服务,2016—2020年咨询服务已不在高频词中;服务主体以图书馆为主,2006—2010年出现专利局,2011—2015年出现档案馆;服务模式以信息化、数字化、个性化为主,2016—2020年出现可视化。
3.2 主题演化分析
主题演化体现在同一主题的关键词随时间的变化,而相邻时间窗中具有演化关系的主题在内容上会表现出一定的相似性。因此,可以通过计算相邻时间窗中主题内容的相似性来确定主题之间的联系,以便进行主题演化分析。
计算相邻时间窗内的主间相似度后,结合阈值(根据相似度位于前25%的值确定)识别关联主题,绘制主题演化路径,如图2所示。

图2 主题演化路径
从时间窗1至时间窗2的演化路径可以发现,存在主题分裂、主题合并、主题继承、主题新生和主题消亡。部分主题的演化路径如下:
1)主题分裂。时间窗1的专利管理分裂成时间窗2的图书馆专利服务和专利服务,时间窗2的图书馆专利服务又分裂成时间窗3的网络查新服务、图书馆数字化服务和高校图书馆专利信息服务,结合主题挖掘结果中的主题词,时间窗1内关于专利管理的研究偏向技术和政策研究。企业和公众提出了专利信息服务需求,但知识产权服务类系统功能相对匮乏,急需拓展系统的服务功能和内容,集成各类资源,建立知识产权信息快速处理机制,强化专利信息服务体系建设,提升专利管理能力。时间窗2内则偏向服务内容和体系建设。政府部门、社会机构、高校、知识产权服务机构共同参与、协调联动,提供多层次、规范的专利信息服务,形成知识产权信息服务业发展的政策体系。图书馆推进信息资源数字化建设,提高专利信息服务能力。时间窗3则偏向服务模式创新。创新、重组、开拓知识产权信息业务,尤其构建大数据环境下新型服务体系,重新定义参与者的职责,构建服务模式框架和平台。
2)主题合并。时间窗2的图书馆专利服务和数字化服务合并成时间窗3的图书馆数字化服务。从信息时代到数智时代,以大数据、人工智能技术为基础,图书馆充分挖掘用户需求,推进数据驱动的专利信息精准服务,利用可视化技术,丰富专利精准服务内容,提升专利精准服务效果。
3)主题继承。时间窗2的专利服务由时间窗3的软件专利服务继承,关于专利服务的研究具体到软件行业。时间窗2的新兴产业专利申请由时间窗3的著作权专利申请继承,关于专利申请的研究具体到著作权专利。研究内容随时间推移逐渐具体、细化。另外,从时间窗1的图书馆信息服务到时间窗2的知识产权咨询服务到时间窗3的网络查新服务的演化路径可以看出咨询服务和查新服务的继承演化。咨询和查新服务作为知识产权信息服务中较为基础的服务内容,在研究期间内一直保持较高热度。地方各局举办的知识产权咨询或查新服务活动,如2017年苏州张家港市举办知识产权日广场咨询服务活动,也表明了相关研究受到的关注较多。从时间窗1的软件和信息服务业创新到时间窗2的数字化服务到时间窗3的软件专利服务的演化路径可以看出关于软件研究的继承演化。软件专利和盗版问题一直受到较高的关注。近年来,中国知识产权保护工作向全面从严转变,让盗版软件的生存空间越来越小,加之政策手段激励正版软件的创造,有效优化了软件市场的供给侧。从时间窗1的图书馆信息服务到时间窗2的数字化服务到时间窗3的图书馆数字化服务的演化路径可以看出关于数字化研究的继承演化,并发展出可视化研究。数据建设是知识产权信息化建设“十一五”规划中的重点建设任务。截至2012年底,全国所有省级数字图书馆和部分市级数字图书馆的硬件平台搭建工作完成,2013—2015年进入全面推广阶段,知识产权信息化、智能化基础设施建设扎实推进。
4)主题新生和主题消亡。时间窗1的档案信息化与时间窗2的档案管理都是消亡主题,说明有关档案管理中的知识产权信息服务并没有得到持续的关注与研究。随着档案工作的有序开展,档案管理存在的诸多问题逐渐显露。例如高校科技档案管理工作中,知识产权保护相对滞后和薄弱影响了科技人员积极性,制度设计本身存在的不完善和操作性较弱导致部门间职责不清和落实不力[12]。此外,社会认知度较低、服务创新力较弱、内容质量较差、用户活跃度较低等问题也都在一定程度上限制了档案工作的进行[13],导致相关研究热度较低,主题出现消亡现象。
4 结论与展望
通过使用LDA主题模型对近15年来知识产权信息服务相关研究论文进行主题演化分析,明确不同时期的研究方向和相关领域的研究变化,结论如下:
1)主题聚类挖掘。2006—2010年的高频主题有档案信息化、图书馆数据库建设、知识产权服务、知识产权管理、图书馆信息服务、专利管理、软件和信息服务业创新;2011—2015年的高频主题有图书馆专利服务、专利信息资源共享、知识产权咨询服务、数字化服务、专利服务、新兴产业专利申请、档案管理和著作权服务;2016—2020年的高频主题有专利创新服务、网络查新服务、图书馆数字化服务、高校图书馆专利信息服务、软件专利服务和著作权专利申请。
2)主题内容演化。知识产权信息服务的服务内容、服务范围和服务模式都依赖相关政策支持出现一定程度的继承演化,比如咨询和查新服务、软件知识产权、数字化服务。而档案管理方面的知识产权信息服务却由于存在知识产权、制度、社会认知度等多方面的问题限制了档案工作的进行,导致出现了消亡现象,没有得到持续的关注与研究。
研究中采用的LDA模型能够对现有研究成果进行主题提炼和挖掘,以便于研究者了解某一领域的研究现状和主要热点。但是,研究中也存在一些局限:主题含义的赋予还有待完善;设定LDA模型的超参数时存在一些随机性误差;选择文献摘要作为主题挖掘的文本数据,并不能完全展现有知识产权信息服务的所有研究。
猜你喜欢
水运工程(2022年7期)2022-07-29
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
World Journal of Stem Cells(2020年8期)2020-09-18
中国洗涤用品工业(2019年4期)2019-05-11
人大建设(2018年11期)2019-01-31
电脑爱好者(2017年7期)2017-05-06
领导决策信息(2017年9期)2017-05-04
江淮论坛(2011年2期)2011-03-20
