
基于手机信令数据的游客识别方法
2023-01-16 03:54韩艳,龚浩
公路工程 2022年6期
韩 艳,龚 浩
(北京工业大学 交通工程北京市重点实验室,北京 100124)
0 引言
在节假日等旅游高峰期,部分热门景区(点)大量游客聚集而形成区域拥堵,对游客体验、安全和景区管理产生较大影响,急需精准识别景区内不同区域或景点的游客,实时预测预警游客流量,实施分流和限流[1-3]等客流调控方案。
游客客流采集数据有视频数据、闸机刷卡数据、RIDF数据、人工统计数据等,多为景区整体客流数据,无法准确获取景区某些局部区域或者某热门景点的客流量,数据实时性较差,无法满足实时客流预测预警的要求[4]。手机信令数据具有覆盖面全、实时性高等优势[5-6],被广泛用于游客的识别与出行特性分析。手机信令数据是由手机终端和手机基站间联系时生成的数据,景区的边界与基站服务边界通常不完全重合,服务于景区与其周边的基站用户包含游客和非游客,不少学者开展了基于手机信令数据的游客识别方法研究,提出用停留时间等指标差异进行用户分类。杨东、LI等[7-8]将景区基站服务用户分为游客与非游客两类,前者以8 h为长白山景区内游客平均停留时间阈值,后者以8—18点内的停留时间在0.5~5 h为阈值,区分游客与非游客。龙奋杰等[9]将用户分为园区工作者、路人和游客3类,假设在景区基站停留时间不超过0.5 h的用户为路人;一周内出现5 d以上且每天停留时间超过5 h的用户为园区工作者,其余为游客,校验结果显示精度达到80%左右。ZHAI等[10]先将至少2次经过出入口基站的用户筛选为潜在游客,再根据用户停留时间(1~6 h)和连接景区基站的时间占比(超过90%)两个指标识别游客。方家、陈圣威等[11-12]将用户分为路人、居民、工作人员和游客4类,方家假定0—5点手机为关机状态的用户为居民。陈圣威根据用户多日凌晨、工作时间内在研究区域的停留时长,识别用户的工作地与居住地,筛选并剔除在景区周边居住或工作的用户,根据景区面积设置停留时间的阈值为1~3 h,识别游客,精度达到75%左右。
已有研究多用单一指标景点停留时间进行用户分类,问题在于不同类型用户在不同景点的停留时间的阈值不同,且当将用户分为路人、居民、工作人员和游客4类时,短时游览的游客与路人特性、长时间游览的游客与工作人员的停留时间接近,导致游客的识别精度为60%~80%[9,12]。为解决上述问题,论文提出基于手机信令数据提取出行者的出行链,分析游客与非游客(工作人员、路人)一日、多日或者更长时间内(工作日、假日)的出行链时空特性差异,修正现有游客识别方法,以提高识别精度,为不同景区游客停留时间阈值和后续景区局部客流预测预警提供数据支持。
1 手机信令数据特点和应用
手机信令数据是由手机终端和手机基站间联系时生成的数据。当用户在某个基站内进行通话、短信、开关机等事件时,事件会被该基站记录,并生成一条数据。当用户进行基站间移动时,会自动切换连接的基站,同时生成一条数据。因此用户接打电话、开关机或进行较大范围移动时,均会生成信令数据[13]。手机信令数据主要包含国际移动用户识别码(IMSI,International Mobile Subscriber Identity)、时间(TIME)、基站编号(CELLID)、基站经度(LONGITUDE)和基站纬度(LATITUDE)5类信息,部分信息如表1所示。

表1 手机信令数据表(部分)Table1 Mobile data sheet (part)国际移动用户识别码时间基站编号基站经度基站纬度114:00:182 057116.586 8640.078114:17:2053 167116.478 3339.979 69115:04:5339 667116.339 9139.944 63116:58:593 827116.331 6639.956 67
现有数据获取技术包括射频识别技术、视频识别技术、人工统计和手机信令数据等方式,各类数据的特点和适用场景如表2所示。

表2 数据类别和特点Table 2 Data types and characteristics数据类别适用场景优点缺点射频识别数据设有门禁的区域精度高开放区域数据和分布获取困难视频采集数据室内区域精度较高可获取客流分布数据室外数据精度低人工统计数据多用于局部区域精度高处理方便成本高实时性低手机信令数据较大范围区域较小范围识别精度不足实时性高可获取时空分布数据
对于不同应用场景,不同的数据适用程度不同。以景区为例,对于景区的整体客流量数据获取来说,通过门禁的统计数据可以准确的得到景区内不同时段的入园人数、在园人数等整体数据,但对于景区内不同区域、不同景点的客流分布情况却无法准确及时地获取;对景区内较小的室内景点来说,视频识别数据可以简单地获取到室内的客流量、密度和分布情况,对于室内区域的客流情况可以快速做出识别与分析,但该技术在室外的效果会受到天气、建筑遮挡等多种因素的影响,造成精度不足的问题;传统的人工计数方式能解决前面两类技术存在的问题,可以通过增加调查人员获取景区不同区域、不同景点的客流量、密度、分布等数据,但数据采集成本高、实时性低,对于景区短时预测预警和景区管控等参考价值有限。
手机信令数据具有覆盖范围广、定位速度快、实时性强、连续性强等特点。结合数据的连续性,对客流进行连续的追踪与分析,因此多用于城市内多个景区间的客流特征分析和挖掘[14-18]。并且根据景区类型的不同,可以通过手机信令数据,实时获取景区内不同区域的客流分布数据,针对景区内不同区域的客流量、分布情况、客流特征和出行特点进行提取与分析。
2 基于出行链的游客识别方法
2.1 景区游客识别考虑的因素
景区游客识别中需要考虑游客的停留时间、出行轨迹等出行的因素,以及景区的类型、景区大小、景区位置、景区周边用地性质和道路情况等景区的因素,这两部分。
出行因素中,主要考虑游客在景区研究范围内的停留时间,以及出行轨迹是否经过景区范围。
景区因素中,首先旅游景区分为开放型与封闭型两种,开放型是没有面积和空间限制、免费、游客流动性更大不易管控的一类景区[19],封闭型是指有空间限制,通过一定的物理设施隔离景区与外围的空间的一类景区。研究中提出的识别方法适用于设有出入口的封闭式景区。
不同景区的覆盖面积大小不同、所处位置有所差异、且不同的地理地貌均会对游客识别造成影响,因此选择手机基站为最小单位,进行游客数据的识别。大型景区内包含的基站数会较多,单个基站面积较大;小型景区基站数较少,单个基站面积较小。基站较多的景区中,基站在游客识别中的作用也会有所差异,需要根据功能和位置进行分类以保证识别精度。
同时,景区周边的用地性质、路网特征也会对景区游客识别产生干扰。当景区周边存在居住用地、商业用地和工作用地等,用户类型就会出现居民、路人和周边工作人员等;当景区周边路网较为密集时,周边路人的比例也会提升。
因此景区的游客识别中,需要将基站进行分类,根据特定的基站选定研究区域,以保证识别方法适用于不同面积和位置的景区;需要将用户进行分类,保证识别方法可以将游客与居民、路人和周边工作人员进行区分,保证识别精度。
2.2 基站分类与研究区域选取
景区内部和周边设置了一定数量的基站为景区用户服务,手机基站受到周边环境干扰、基站空间分布与基站信号强度等影响,服务范围不规则,通常采用泰森多边形的方法表示基站的实际服务范围[20],如图1所示。

图1 泰森多边形
可以发现基站服务范围通常略大于景区的物理边界,如图2所示。根据景区边界与基站服务范围的空间重叠关系,考虑到游客均通过景区出入口进出,景区出入口基站具有特殊性,将景区基站分为3类:第一类为覆盖景区出入口的基站;第二类为完全处于景区边界内的基站;第三类为与景区有部分重叠的基站。为获取全部游客数据,选取第一、二和三类基站覆盖的范围作为景区研究区域。

图2 景区边界和基站分类示意图
2.3 用户分类和特征
景区研究区域内的手机用户有游客和非游客,非游客包括景区周边的居民、工作人员和经过景区周边道路的路人。研究将景区研究范围内的用户分为4类:路人、居民、工作人员和游客。4类用户与3类基站的对应关系如表3所示。
a.居民:具有固定的居住地,即凌晨至早上、或晚间时段内,具有固定停留点,停留时间超过一定的时间阈值。居民数据一定出现在第三类基站,可能出现在第二类基站。现有研究多将凌晨0:00—5:00停留时间大于4 h的景区研究区域内用户认定为居民[11]。
b.周边工作人员:具有固定的工作地点,即连续几天出现在同一地点,在工作地累计停留时间超过一定的时间阈值。工作人员一定不会出现在第二类基站,可能出现在第一类和第三类基站。我国工作时间多为:8:00—17:00,根据《2016-2017年中国休闲发展报告》(休闲绿皮书)中数据,2016年北京市居民工作时长约为362 min/d,现有研究将9:00—16:00时段内累计停留时间超过5 h的用户识别为工作人员。
c.游客:在研究区域停留时间超过一定的时间阈值,不会连续几天出现在研究区域,出行目的地较多。游客经景区出入口进出景区,因此一定出现在第一类基站,可能出现在第二类和第三类基站。
d.路人:在景区覆盖范围内没有固定的驻留地点,在研究区域内的总停留时间短于其他类型用户。路人一定不会出现在第二类基站,可能出现在第一类和第三类基站。
2.4 基于出行链的游客识别方法
从表2分析可以看出,路人、居民、工作人员和游客在空间分布特性上存在一定重叠。如何应用手机信令数据进行游客的识别,成为景区客流预测的重要环节。
2.4.1不同用户的出行特征
手机信令数据中包含了表示手机用户所在位置的经纬度坐标,以及用户出现在该坐标下的时刻。基于这两类数据,将用户出行的时间与空间数据进行整合,得到按时间顺序排列的用户全天的出行轨迹,即出行链。游客出行链是游客以旅游为目的,从出发至到达景区目的地,以及从当前景区目的地至下一目的地的出行全过程。基于游客出行链的时空分布特性,研究基于4类用户的出行链特性分析,提出基于出行链的游客识别和特征分析方法。
基于手机信令数据,进行数据预处理后,提取用户的出行链[21-24],绘制用户的出行链,4类用户的出行链形式如图3所示。
a.居民用户出行链特征:居民的多日出行链起讫点具有较强的规律性,出行起讫点均在研究区域内,凌晨至早上在区域内没有移动。当出行链包含多个活动点时,通常离开研究区域,并在中午或晚上返回研究区域内的居住地,凌晨停留时间较长。
b.工作人员出行链特征:出行起点在研究区域外,进入研究区域后,在工作时间内、景区外围基站有固定的停留地点,最后离开研究区域,工作时间段内停留时间较长。
c.路人出行特征:出行起点在研究区域外,进入研究区域后,沿研究区域外围边界移动,没有长时间停留点,最后离开研究区域,总停留时间较短。
d.游客出行特征:出行起点在研究区域外,在开园时间段内,由景区出入口基站进入研究区域,且在研究区域内有多处停留时间较长的地点,最后经过景区出入口基站离开研究区域,总停留时间较长。
2.4.2游客识别步骤
基于手机信令数据提取用户的出行链,结合出行链中的活动点和每个活动点的停留时间,构建基于出行链的景区游客身份识别方法。游客识别步骤流程如图3所示。具体步骤为:

图3 游客识别流程
a.将服务景区的基站分为3类:①覆盖景区出入口的基站,用Ω1表示;②位于景区边界内的基站,用Ω2表示;③与景区有重叠部分的基站,用Ω3表示。将这3类基站选定为研究区域,在区域中的用户用Ω表示。
Ω=Ω1+Ω2+Ω3
(1)
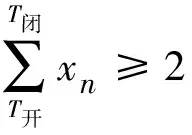
c.将用户分为4类:①居民;②工作人员;③路人;④游客。

(2)
式中:Oi,Di为用户i的出行起讫点所在基站,Ω为研究区域;Pi为用户i经过的中途点;t1为用户在凌晨期间在区域内的停留时长。
(3)
式中:Oi,Di为用户i的出行起讫点所在基站,Ω为研究区域;Pi为用户i经过的中途点;t2为用户在工作时间内在区域内的停留时长。
f.在景区开园时间内,存在用户经过景区周边的基站,在景区基站的停留时间t3<1.5 h,出行链起讫点均在研究区域外,在研究区域内没有固定停留点,仅在景区外围活动,将这类用户识别为经过的路人。剔除路人数据。
(4)
式中:Oi,Di为用户i的出行起讫点所在基站,Ω为研究区域;Pi为用户i经过的中途点;t3为用户全天在区域内的停留时长。
g.将d至f中识别的非游客数据剔除后,数据中仍可能存在无法通过前面步骤识别筛除的非游客,因此需要根据以下两步进行游客的识别:
① 若景区边界内包含一个或多个完整基站,则将出现在这些基站内的用户识别为游客。
∃Pi∈Ω2
(5)
② 若用户第一次进入出入口基站的时间为开园时间以内,停留时间t4≥1.5 h,经过景区多个基站且出行链起讫点均在景区相关基站外的用户,判断为景区游客。
(6)
式中:tin为用户进入出入口基站的时刻;T开,T闭为景区开园和闭园时间;Pi为用户i经过的中途点;t4为用户在景区开园时间内在区域内的停留时长。
3 案例分析
3.1 研究区域
3.1.1景区和手机信令数据简介
颐和园位于北京市西郊,是国家5A级旅游景区,中国清朝时期皇家园林,自然风光优美秀丽,节假日期间会吸引国内外众多游客前往游览,是我国最热门的景区之一。颐和园占地面积大,不同区域的热门程度不同,在节假日期间会形成明显的客流分布不均的现象。同时,颐和园周边基站布置较为密集,因此,选取颐和园为研究对象,开展基于手机信令数据的游客识别案例分析具有典型意义。
手机信令数据来自北京移动公司某年5月1日0时至5月3日24时的全部数据,划分研究区域,基于手机信令数据提取出行链,开展基于出行链的游客识别和出行特性研究。
3.1.2研究区域选取
使用ARCGIS软件,绘制每个基站的泰森多边形,使用泰森多边形表示该基站的服务范围,并将多边形范围与颐和园景区范围进行比较,选取相交和包含关系的基站,即选择可以覆盖颐和园景区的多边形所在的基站作为颐和园景区的研究区域。颐和园景区研究区域共设有13个基站。为方便后续研究,将基站重新编号,编号如图4所示。

图4 颐和园研究区域
3.2 游客识别结果
识别结果显示:5月1日至3日颐和园景区研究区域内游客总数量为103 966人次。其中5月1日颐和园景区游客数为45 136人,居民769人,工作人员1 255人,路人97 039人。
在5月1日的所有出现在颐和园景区附近的用户中,路人占比最大,为67%,游客占比31%,居民最少,仅占1%,如图5所示。
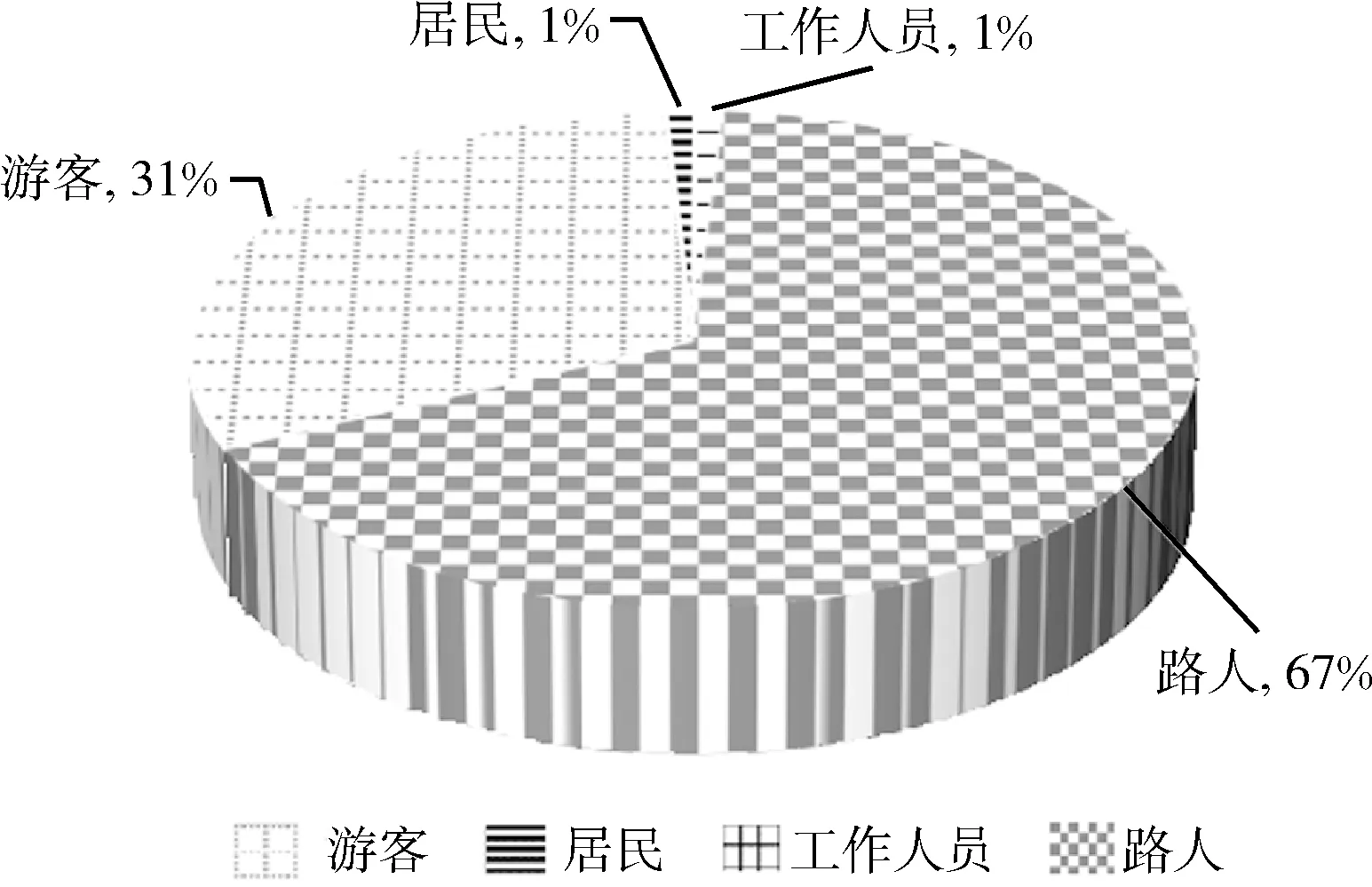
图5 各类用户人数比例图
3.3 精度验证
根据数据当年通信运营业统计公报数据显示,北京手机普及率为90.8%,中国移动市场份额为62.1%,根据普及率与市场份额,将识别的游客数量进行扩样,得到景区接待客流量的数据,得到扩样后的景区3 d接待游客184 380人。
根据颐和园“智慧旅游”系统数据显示,当年五一长假颐和园景区接待有客流量为32.7万人次,其中4月30日接待人数最多,达到13.8万人次,由此计算得到5月1日至3日颐和园共接待游客18.9万人次。扩样后识别数量占实际数据的97.56%,认为提出的基于出行链的游客识别模型精度较高,识别较为准确。
3.4 颐和园游客停留时间分布分析
游客停留时间指游客在研究区域内停留的时间长度,研究以游客出现在研究区域的累计时长,即游客第一次出现在景区出入口基站时的数据时间,与最后一次出现在景区出入口基站的时间内,连接研究区域基站的时间长度。
游客停留时间的分布,会影响到游客识别流程中停留阈值选择。因此根据识别后得到的游客数据,进行统计分析,得到如图6所示的游客停留时间分布情况。
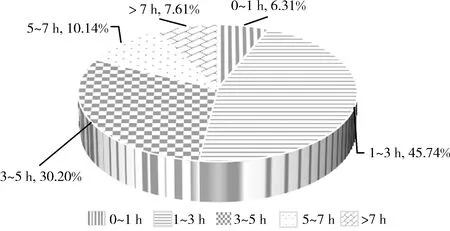
图6 颐和园游客停留时间分布图
从图6可以看出,5月1日的颐和园游客停留时间分布主要集中在1~3 h,占45.74%;其次是游览3~5 h的游客占30.2%;占比最少的是停留时间小于1 h的游客,仅为6.31%。由此可以看出,颐和园景区范围较大,所需停留时间稍长,游客也更倾向于中长时间的游览。
得到的游客停留时间分布,与游客识别模型中选定的大于1.5 h的游客停留时间判断阈值相比,分布大致相同,说明选取的阈值适用于颐和园景区的客流识别。
通过景区停留时间分布也可以反映出,在颐和园景区中,超过93%的游客在景区的停留时间超过1 h,在进行游客识别时,选取的游客停留时间判断阈值应大于1 h,可以提升识别精度。
4 结论
研究基于手机信令数据,对景区的客流识别方法进行研究,根据景区边界与基站服务范围的空间重叠关系,考虑游客通过景区出入口进出景区而产生的出入口基站的特殊性,将景区基站分为3类,第一类为覆盖景区出入口的基站;第二类为完全处于景区边界内的基站;第三类为与景区有部分重叠的基站,选定了景区的研究区域。将用户分为居民、工作人员、路人和游客4类,分析不同用户的出行特征,提取用户出行链,提出基于出行链的游客识别方法,最后以北京市颐和园景区为例进行案例分析,得到五一期间共识别游客103 966人次,游客识别准确率达到97.56%,识别精度较高。结果显示,识别方法对于如颐和园占地面积较大的自然类景区有较好的识别精度。研究提出的游客识别方法可以用于大型自然类景区的客流统计,为景区的客流分布和移动等研究提供数据支持,给景区管理员进行大客流预警调控提供参考。
猜你喜欢
作文小学高年级(2022年6期)2022-07-01
艺术品鉴(2020年9期)2020-10-28
通信技术(2020年2期)2020-03-26
恋爱婚姻家庭·青春(2019年9期)2019-12-10
铁路通信信号工程技术(2019年10期)2019-11-06
中国交通信息化(2019年2期)2019-03-25
金桥(2018年6期)2018-09-22
消费导刊(2017年24期)2018-01-31
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
