
融合对象和多尺度视觉特征的遥感图像描述模型*
2023-01-16 12:25贾亚敏彭玉青
网络安全与数据管理 2022年12期
贾亚敏,陈 姣,彭玉青
(河北工业大学 人工智能与数据科学学院,天津 300401)
0 引言
图像描述是旨在从语义层面上对图像进行总结。遥感图像是利用遥感技术从高空获取的图像,遥感图像描述(Remote Sensing Image Caption,RSIC)是上述两个领域的结合,旨在为指定的遥感图像生成综合性的文本描述,在交通指挥、地理研究等领域[1]具有广泛的应用前景,已成为新兴的研究热点。遥感图像描述的实现最初沿用了图像描述的编码器-解码器模型[2],随后提出了许多模型来解决不同的问题,多数研究使用卷积神经网络(Convolutional Neural Networks,CNN)作为编码器提取图像特征,但CNN卷积层的输出特征所对应的感受野都是大小和形状相同的均匀网格,因此仅利用CNN提取的图像特征容量有限,难以识别图像中的微小物体,且由于拍摄角度问题,遥感图像中存在一些多义和易混淆物体,不易区分。
为解决上述问题且适应遥感图像场景多尺度的特点,本文提出了融合对象和多尺度视觉特征的遥感图像描述模型(Fusion of Object and Multiscale Visual Feature,FO-MSV)。该模型构建对象提取器(Object Extractor,OE)利用指针生成网络[3]得到的整合描述提取对象信息以避免遗漏微小物体。同时提出了一种新的多尺度交互模块(Multiscale Interaction Module,MSCM)来获取图像的多尺度视觉特征适应多尺度的特点。此外,设计一种新的对象-视觉融合机制(Object-Visual Fusion Mechanism,ovFM)来利用对象信息并融合多尺度视觉信息避免出现识别对象错误的问题,且改善了长短时记忆网络(Long Short Term Networks,LSTM)的结构,称为多输入LSTM(Multi-Input LSTM,I_LSTM)。
1 相关工作
由于遥感图像自身的多尺度、多方向、分辨率低等特点,且在采集遥感图像过程中容易受到光照、遮挡、距离等周围环境的影响,会造成目标遥感图像特征模糊易混淆,使得遥感图像的语义层次的理解变得更加困难,研究者针对上述问题也提出了大量RSIC方法。
从模型设计的角度,Wang等人[4]提出了一种检索主题循环记忆网络,利用循环神经网络处理图像特征以及从主题库中检索出的主题信息生成描述。考虑到注意机制的有效性,Cui等人[5]提出了一种基于注意力的遥感图像语义分割和空间关系识别方法,但是其描述模块独立于其他模块,并未有效提升描述性能。Cheng等人[6]采用多级注意模块自适应聚合特定区域的图像特征以解决多方向的问题,并提出一个新的NWPU数据集。Li等人[7]提出了一种多层次的注意模型,有效地结合视觉信息和语义信息增强注意指导描述生成。Zhao等人[8]提出了一种结构化注意机制,来解决粗粒度注意单元问题,减少因图像模糊而带来的特征误差。
从遥感数据本身出发,Zhang等人[9]探索如何解决由于训练样本少造成的过拟合的问题,并受到图片分类任务的启发,提出了多尺度的裁剪机制;Zhang等人[10]提出利用图片类别标签的LAM模型,该模型能够更好地挖掘与类别相关的目标和关系信息;Huang等人[11]提出了一种基于降噪的方法来增强图像特征表示的清晰度。Zhang等人[12]引入了全局视觉特征,并通过去除冗余特征分量,得到了与图像场景密切相关的描述性语句。
上述工作虽然在一定程度上提升了描述性能,但大多仅致力于改进或增强图像特征表示,未充分考虑上述提到的CNN感受野的局限性,因此会遗漏微小物体。并且遥感图像从高空拍摄且分辨率低,仅利用编码器提取的视觉特征极易识别错误,不能有效区分易混淆物体,如森林和草地等。在多尺度问题的处理上,大多工作只是简单地连接多层特征代表全局特征,未考虑层间交互的重要性。基于此,本模型总结如下:(1)提出一种新的对象提取器从描述图像的整合描述中提取准确全面的对象信息;(2)设计了多尺度交互模块获取图像多尺度视觉特征;(3)探索了一种新的对象视觉融合方式并改进了LSTM结构。
2 FO-MSV模型
本文提出的基于FO-MSV的方法分为三部分:整合描述及对象提取器、多尺度交互模块、属性视觉融合模块。图1为模型结构图。
2.1 对象提取器
为了弥补CNN的不足,本文考虑可直接向解码器提供对象的语义概念来避免遗漏微小物体,从真实描述中提取对象信息。利用指针生成网络处理五个真实描述得到整合描述I,既消除了真实描述中的冗余信息,又保证了句子的完整性。OE旨在提取其中的对象信息,对象的关系、动作等信息可依靠视觉特征更好地获取。由于篇幅有限,指针生成网络的具体实现过程不再赘述,可参考文献[3]。
整合描述是对真实描述的总结,获取的对象信息具有全面和准确性。如图2所示,本文首次提出将自然语言处理的词性标注(Part Of Speech,POS)任务应用于RSIC,作用于本文的OE获取图像对象特征,之前没有此类的研究。利用POS任务可得到文本中单词的对应类型。此阶段,OE对I进行分词、实体词性标注和物体词的提取。属性信息用词嵌入列表 的形式表示,O={O1,O2,…,Om},Oi∈RE,其中E是属性词嵌入的维度。

图2 对象提取器结构图
首先通过Tokenizer注释器对I进行分割处理得到令牌级别的单词Tk。通过词性标记,Tk得到对应的词性标签Pk,以(Pk,Tk)形式表示。 例如,′NN′、′CC′等分别表示名词、连接词等。本文认为对象词在I中均以名词形式描述,因此提取Pk=′NN′的Tk表示对象信息,最后进行词嵌入操作,实现对象生成。
2.2 多尺度交互模块
相比在正常角度拍摄的自然图像,遥感图像具有多尺度的特点。为此,本文设计了MSCM结构,分别抽取CNN第5、7层的特征,首先在每一层设计一个层内注意只关注一个尺度并且使所有特征之间建立内部连接。其次设计交互注意部分实现不同尺度特征之间的信息流交互,基于上述连接两层输出特征Ci后可实现本文的多尺度特征Vm。
层内注意是在多头自注意的基础上添加了一个残差连接,并分别在自注意前和残差连接后添加了归一化处理。这里设置多头自注意里的多头为4。
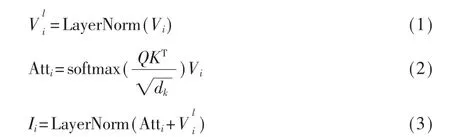
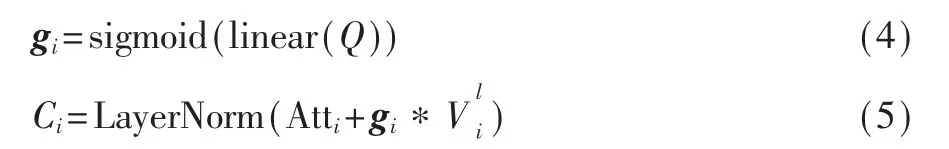
2.3 对象-视觉特征融合模块
注意力机制可以使解码器在根据最感兴趣的信息得到结果,为了充分融合视觉信息和对象信息,该部分在上层I_LSTM、视觉注意、属性注意的基础上设计了一种新的融合机制(Fusion Mechanism,FM)引导视觉信息和对象信息之间的信息流,FM包含本文设计的函数S和下层I_LSTM结构。
2.3.1 I_LSTM
LSTM会在每一时刻根据两个输入(上一时刻单词yt-1和上下文向量vt)进行单词的预测,在以往工作中经常将两个输入向量串联进而进行预测。然而,这种连接的向量中的一些信息往往在预测当前单词时会带来噪声,若前一个单词预测不准确,会造成累积错误。因此本文设计了I_LSTM以更合理的方式处理这两个输入,将yt-1和vt分别作为记忆单元的输入,可以丢弃用于生成前一个单词的视觉特征(可能是视觉噪声)和先前单词的累积偏差。
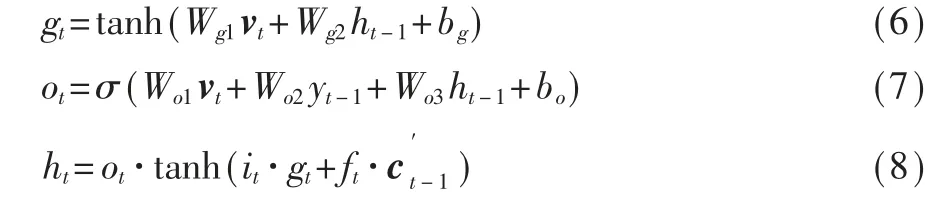
其中,W、b都是可学习参数,输入门it和遗忘门ft计算方式同gt和ot,注意vt在上层I_LSTM中是多尺度特征Vm,在下层I_LSTM中是上下文向量ct。
2.3.2 注意机制
(1)视觉注意
本文认为,上一时刻的单词输出yt-1比下层I_LSTM的隐藏状态更具明确的指示性,而当前时刻上层I_LSTM的隐藏状态ht∈RJ同时包含yt-1和视觉信息,因此本文利用ht来计算视觉注意向量。

其 中,WP,V∈RD×N,WP,H∈RJ×N,ωP,β∈RN是 可 学 习 参数。值得注意的是,为了方便后续计算,用vt=tanh·(Wv,oOt),Wv,o∈RE×D表 示 视 觉 注 意 向 量。
(2)对象注意
基于OE获得的属性具有无序性,若只依靠O和yt-1获取属性注意向量,因为缺乏关注的视觉信息,生成描述时很可能将描述词或关系词与物体任意组合。为避免上述问题,本文利用包含视觉信息和先前单词信息的ht作为注意计算额外的输入,来计算属性注意上下文向量at,计算过程同视觉注意。
2.3.3 融合机制
基于以上,本文得到了当前最感兴趣的视觉区域和对象,但在每一时刻同等对待两种信息是不合理的。因此本文设计了程度函数S,基于ht计算当前时刻对象注意和视觉注意的重要程度,分别用S(at)和S(vt)表示。
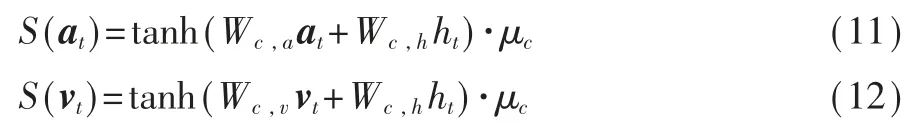
其 中,Wc,a∈RM×E,Wc,v∈RM×E,μc和Wc,h是 可 学 习参数。通过与其对应程度分数的加权和实现对象和视觉的融合,得到用于计算输出词的上下文向量ct。最后,通过下层I_LSTM得到输出词yt。
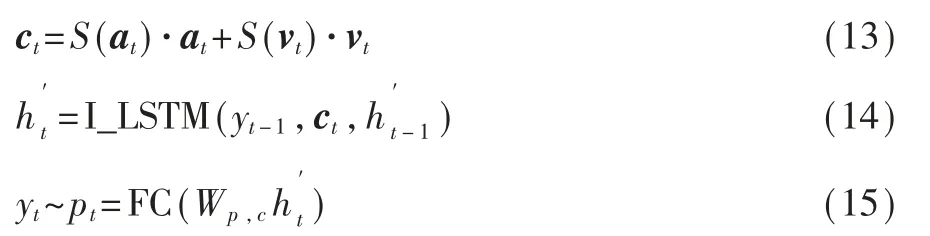
其中pt∈R|T|表示词汇表T中对应的单词是当前输出单词的可能性。总之,ovFM可以精准加权对象和视觉并使模型充分利用对象。
3 实验
在本节中,会依次介绍实验的数据集、评价指标和参数设置以及实验结果的定量和定性分析来证明本文提出方法的有效性。
3.1 数据集和评价指标
本文使用了RSIC领域的三个数据集:RSICD[13]、UCM-captions[2]和新提出的NWPU-captions[6]数据集。对每个数据集进行了划分,其中80%作为训练集,验证集和测试集分别占10%,每张图像都有五个描述。
RSICD数据集有10 921张图像。图像的大小为224像 素×224像 素,包 含30种 场 景。UCM-captions数据集包含21种类别,每个类别有100张256像素×256像素的图片。NWPU-captions数据集包含45种类别,图像大小为256像素×256像素。
本文采用了在图像描述领域应用比较广泛的评价指标来衡量生成描述,分别是BLEU[14]、Meteor[15]、Rouge[16]和CIDEr[17],其中BLEU利用了B-1和B-4指标。上述指标都是分值越高代表描述性能越好。
3.2 实验设置
本文采用ResNet152[18]网络作为CNN,损失函数采用交叉熵损失。作为编码器的输入之前,本文对图像进行了预处理,将其大小调整为512×512。单词嵌入维度和LSTM的隐藏层的大小为512,词汇表中保留了在训练集中至少出现2次的单词,设置了属性词的个数m为5。本文在一个GPU上使用Adam优化器进行了两个阶段的训练。首先设置学习率为5×10-4,批量大小设置为60,训练迭代25次,然后使用自临界序列训练(Self-Critical Sequence Training,SCST)方法[19]进行强化训练迭代15次,学习速率设置为5×10-5,批量大小设置为50。测试时,采用beam search算法,beam size大小设置为3。
3.3 实验结果
在本节中,本文在RSICD数据集上对比了属性词的个数对实验结果的影响,分别验证了FO-MSV各部分的有效性。并在多个数据集上与其他方法进行了对比。
3.3.1 属性个数
本文分别在属性词个数为3、5、7和9的情况下在FO-MSV模型上进行了实验,图3展示了B-1、B-4和CIDEr的结果,当属性词数量为5个时,分数最高,当个数从5到9的过程中,结果明显降低。这是由于当提取属性词过多时,会产生重复或相似的属性,从而降低生成描述的性能。因此限制属性词的个数很重要。综合考虑,本文设置属性词个数为5。
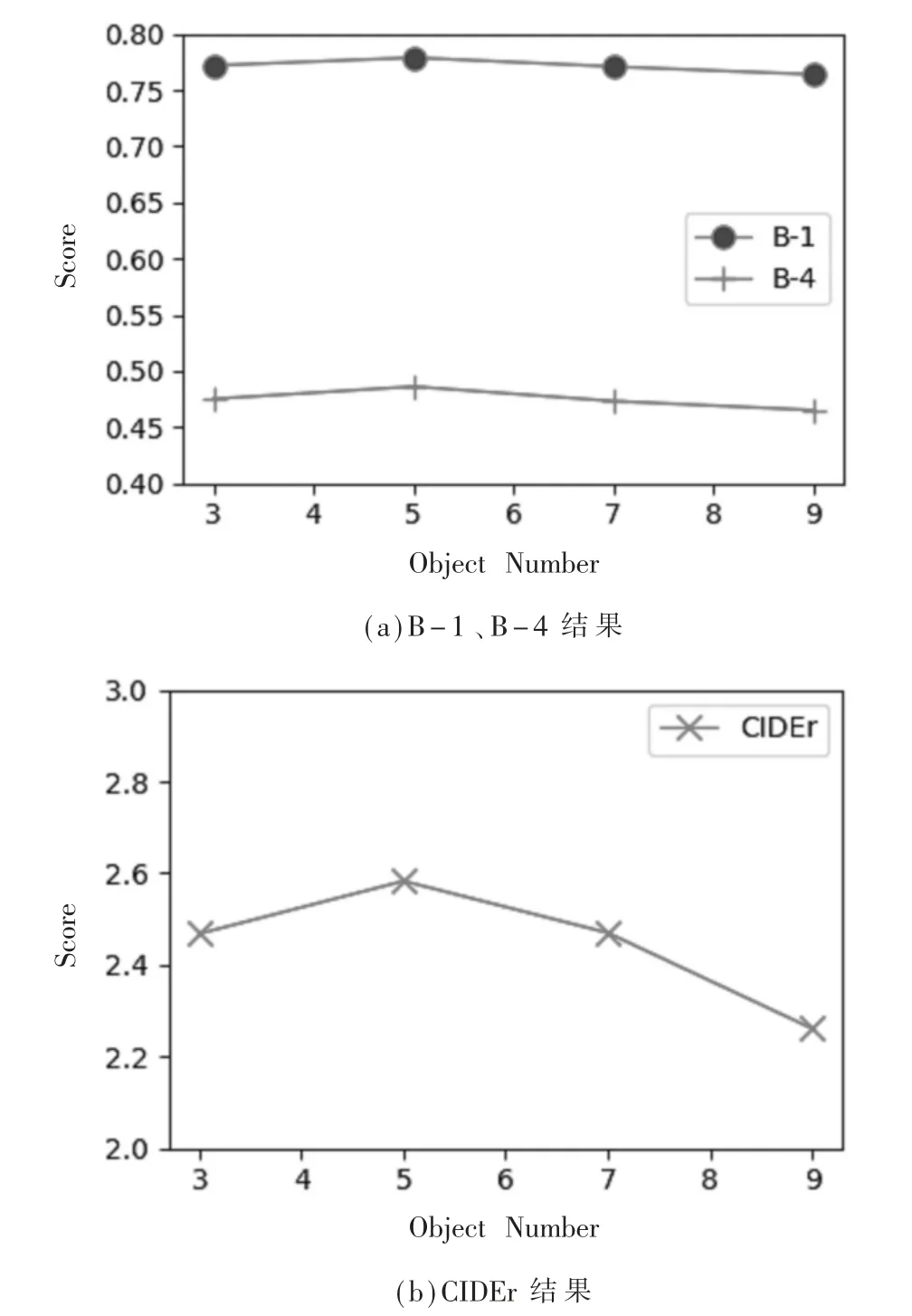
图3 属性个数实验
3.3.2 消融结果
消融实验的结果见表1。其中“Base-line”是传统的CNN-LSTM结构,使用CNN最后一层特征;“+MSCM”表示使用本文提出的多尺度交互特征;“+I_LSTM”表示改进LSTM结构之后的结果;“+V_Att”表示引入视觉注意;“+O_Att(+)”表示以直接相加的形式结合对象注意;“FO-MSV”表示本文的模型;最后的“+SCST”是强化训练后的结果。
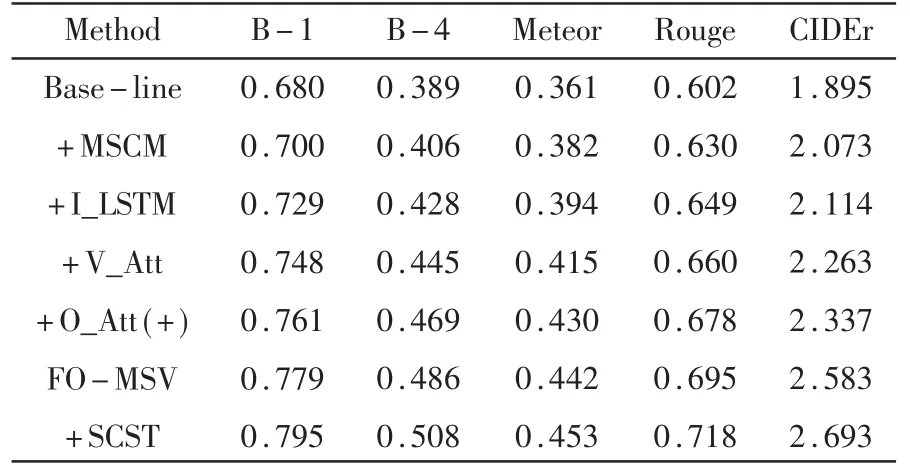
表1 本模型消融实验结果
从表1可以看出,提出多尺度特征和改进LSTM机制都会使结果有明显提升;使用传统的方法使视觉注意与对象注意直接相加也会使结果有所提升,但是利用FM对两者进行融合,明显有更为显著的提升,且强化训练效果也较为明显。
3.3.3 对比实验
在三个数据集上对本文的方法进行了评估,并与典型的遥感图像描述方法进行了比较,包括Soft[14]、Hard[14]、Stru[8]、Lsga[2]、Mlca[6]。 比 较 结 果 如 表2~表4所示,并标粗了最好的结果。
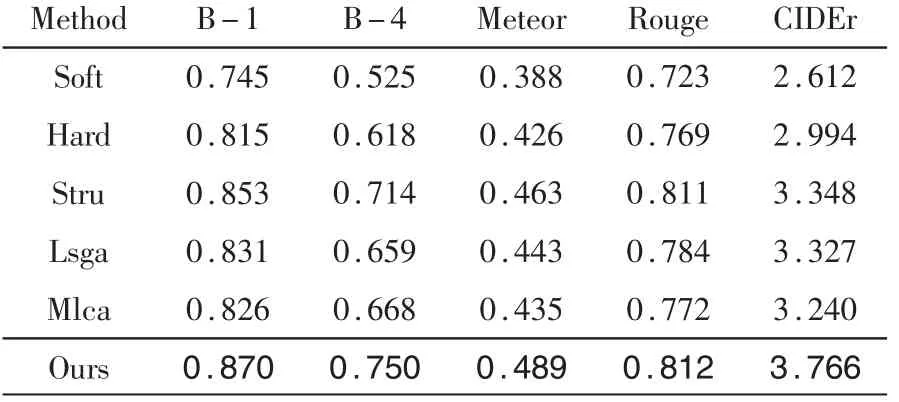
表2 UCM数据集上不同模型对比实验

表3 NWPU数据集上不同模型对比实验
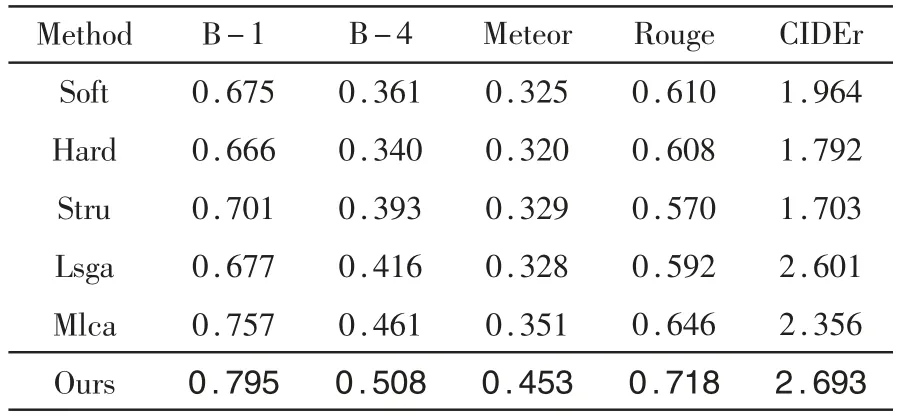
表4 RSICD数据集上不同模型对比实验
由于缺乏数据,本文在NWPU数据集上进行了其他模型的实验。在UCM、RSICD和NWPU数据集上,本文的方法均优于其他模型,并且在未进行强化训练的情况下,本文的结果也明显高于其他方法。总体而言,本模型在RSIC领域内表现出较好的性能。
3.4 定性分析
在图4中展示了本文模型结果示例。文字部分依次为:五个ground-truth中的一个,整合描述,OE得到的对象词,软注意描述,本模型描述。可以看出,本文的整合描述全面概括了每个图像的内容,对象词可以准确获取每个物体信息。虽然“soft”描述可以很好地表示颜色等描述性词语,但在对象上不够全面,且易出现错误,例如“pond”“school”;而FO-MSV通过对象注意充分利用了对象词,可以得到正确的对象类别,几乎没有错误的描述。总之,本模型可以描述更多且正确的对象,并包含丰富的描述性词语,且对于单一场景的描述更具有纹理性,在各方面都具有较好的性能。

图4 RSICD数据集部分描述结果
4 结论
本文提出了融合对象和多尺度视觉特征的遥感图像描述方法,通过引入词性标注任务设计了对象提取器来提取图像对象信息,以避免遗漏小物体并保证物体类别准确。同时,提出了MSCM机制对不同层的特征进行交互连接来获取多尺度视觉特征。最后,基于注意机制和改进的I_LSTM结构,经过设计了程度函数的FM模块以平衡有效的方式融合了两种信息并生成描述。在三个公共遥感图像数据集上的实验结果表明,FO-MSV方法与其他主流RSIC方法相比,准确率有较大的提升且生成的描述更为全面、灵活和健壮。
猜你喜欢
大学数学(2022年6期)2023-01-14
四川大学学报(自然科学版)(2021年6期)2021-12-27
湖南税务高等专科学校学报(2021年4期)2021-08-30
中学生数理化·中考版(2020年10期)2020-11-27
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
意林(2018年3期)2018-03-02
太空探索(2016年5期)2016-07-12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
文苑(2015年9期)2015-09-10
时代英语·高三(2014年5期)2014-08-26
