
基于语义相似度改进的少样本终身主题模型
2023-01-16 03:46买日旦吾守尔古兰拜尔吐尔洪雷恒林
东北师大学报(自然科学版) 2022年4期
曾 琪,买日旦·吾守尔,古兰拜尔·吐尔洪,雷恒林,王 松
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
社会经济及互联网技术的快速发展使得购物网站、社交平台、短视频及各大论坛上的用户评论、分享等数据量迅速增长,信息量多且分布不均.传统的机器学习主题模型可以从广泛的文本信息中获取到有效信息,但通常情况下信息量获取有限,因此通过积累知识帮助样本数量少的领域进行学习(Few-shot Learning)有重要研究价值.[1-4]
受到人类学习过程的启发,终身机器学习LML(Lifelong MachineLearning,LML)是一种能够在顺序学习一系列任务时,将过去学到的知识积累下来指导下一个新任务的机器学习范式[5].LML之所以适用于少样本主题建模,原因有以下3点:(1)在自然语言处理任务中,不同的任务之间会存在不少重叠的主题或知识;(2)过去学到的知识或主题可以在下个新任务到来时指导新任务的模型推理;(3)通过不断学习积累,可在样本量不足时结合过去学习到的知识提升少样本主题模型的建模性能.
过去学习到的先验知识的正确性及适用性能够对终身主题模型的建模效果产生较大的影响.Chen等[6]认为文档中两个单词的共现次数越高,其权重越大,但并未考虑共现词语之间的语义关系,因此主题一致性和可解释性欠佳[7].Dat等[8]提出的LF-LDA(Latent Feature-LDA)在大规模语料库上训练获得的词向量与LDA[9](Latent Dirichlet Allocation)模型结合改进主题-词映射,在主题一致性评估标准中取得了显著的性能提升.Liu等[10]提出的评分预测联合模型,引入终身主题模型的思想提升了模型性能.Chen等[11]首先提出终身主题模型LTM(Lifelong Topic Model),可以自动挖掘领域知识形成must-links(必须链接),must-links指经常同时出现在同一个主题下的两个单词,一般情况下这两个词语语义相关,将其作为先验知识.模型中must-links的正确性问题的解决方法是评估一个任务的must-links中的单词是否存在语义相关性,如果存在较强的相关性,则认为其对当前领域来说是正确的,可以用来提升模型,但根据词频确定的词义相关性在一定程度上不够准确.因此,针对少样本终身主题模型AMC[1](topic modeling with Automatically generated Must-links and Cannot-links)中以词频确定语义相关性存在词语出现次数影响实验结果的问题,本文提出了基于语义相似度改进的终身主题模型SS-AMC(Semantic Similarity-topic modeling with Automatically generated Must-links and Cannot-links,SS-AMC),在原来AMC模型的基础上,引入BERT词向量,获取must-links词对在空间上的语义特征向量,通过词对的余弦相似度来表示其语义相似度,进而设置相似度阈值来优化同一领域下的must-links,达到优化知识库以最终提升生成主题质量的目的.实验表明,基于语义相似度优化的终身主题模型在中英文数据集上都能够获得更加连贯的主题.
1 终身主题模型
1.1 终身主题模型AMC
终身主题模型LTM是一种终身无监督学习,最早由Chen等[11]提出,AMC是对LTM的一个优化模型,更适用于少量数据的主题挖掘[1].
AMC模型包含基于知识的挖掘器、知识库以及采样器3个主要模块.其中基于知识的挖掘器主要挖掘模型中的必须链接must-links和不能链接cannot-links(指通常不同时出现在同一个主题下的两个词语)知识,用来指导未来任务的建模;知识库用来存储模型过去学到的知识;采样器用来挖掘和优化最终主题.当一个由文档集合表示的新任务(当前任务)到达时,终身主题模型将从知识库中挖掘先验知识,以帮助当前任务进行模型推理.必须链接和不能链接作为其一种先验知识用来优化最终的主题结果,完成当前任务上的主题建模后,将得到的主题添加到知识库,为未来的任务使用.
1.2 先验知识挖掘
终身主题模型的先验知识包括must-links、cannot-links及先前任务挖掘到的过去主题p-topic.mustLink挖掘器和cannotLink挖掘器分别用来挖掘must-linkwml和cannot-linkwcl.p-topic则在采样环节通过采样器产生,将产生的p-topic存储在知识库S中.wml通过Liu等[12]提出的MS-FIM(Multiple minimum Supports Frequent ItemsetMinging)频繁项集挖掘算法得到.频繁项集指的是多次在知识库S的p-topic中出现的一组单词,将长度为2(两个单词)的频繁项集作为must-links先验知识.其基本思想是从全局项集Q中挖掘出满足条件的一组词项.全局项集Q是知识库S中所有p-topic的集合.MS-FIM满足两个条件:一是每个单词都被赋予一个不固定的最小支持度(MIS);二是项集中的词项的MIS差值不能过大.另外,must-link知识有两个必须考虑的问题:(1)一词多义导致的传递性问题;(2)must-links知识的正确性及适用性问题.针对第一个问题,在AMC模型中通过构建must-link图来解决,以每个must-links为顶点,在包含两个相同单词的must-links之间形成一条边,对于每条边都有p-topic,其主题的重叠程度决定其是否具有相同的词义.当满足
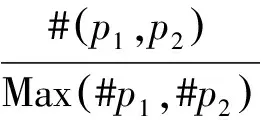
(1)
时,两个must-links具有相同的语义.其中πp指的是不同语义的阈值.由于p-topic也可能存在错误,因此小于阈值的边并不考虑.针对第二个问题,本文提出比AMC模型能得到更正确的must-link知识的SS-AMC模型.在AMC模型中,为了计算must-link之间的语义相关性,利用单词相关性度量方法PMI[13](Pointwise Mutual Information,PMI),定义为
(2)
式中:P(wx,wy)表示一个文档中两个词同时出现的概率.上述概率计算也可以用在本文模型的评论文档数据中,P(w)表示一个文档中单词w出现的概率,P(w)和P(wx,wy)的公式为:
(3)
(4)
式中:DN+1为当前任务的评论文档,#DN+1(w)为DN+1中包含单词w的文档数量,#DN+1(wx,wy)为同时包含单词wx和wy的文档数量,#DN+1为DN+1中所有的文档数量.
通常情况下,一个单词w的cannot-linkwcl比must-linkwml要少,对于这两种先验知识的挖掘方式也不同.两个词之间形成cannot-links,如果这两个单词wx和wy很少同时出现在S中的过去主题中,那么在很大程度上其语义不同,它们满足以下2个条件:
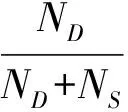
(5)
ND>πD.
(6)
其中:知识库S中的单词wx和wy出现在不同p-topic的次数表示为ND,出现在同一个p-topic的次数表示为NS,且ND应该大于NS.对cannot-links中存在的语义相关及适用性问题在采样过程中做了检测和平衡.
1.3 主题采样分布
AMC模型中的Gibbs采样器在主题生成环节主要有两个任务:一是计算每个单词w所属主题k的概率;二是形成cannot-links.
将先验知识挖掘出来的must-links提取一个与主题k语义最相近的单词w的must-linkmm,创建一组must-links集,这组must-links集和单词w具有相同的语义.单词w在主题k下出现的次数记为nk(n-k表示除了当前分配k之外的次数),将主题k分配给单词wm的概率为
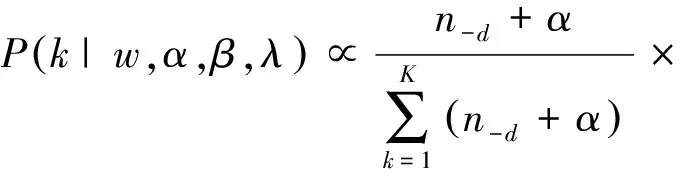

(7)
其中:主题k分配给文档d的次数记为nd;K和V分别代表主题数和词汇数;α和β是Dirichlet超参数.对于单词w的每一个cannot-linkwcl,对其根据以下条件分布进行采样,形成cannot-link集
(8)
2 基于语义相似度改进的终身主题模型SS-AMC
2.1 优化must-links集合
词嵌入(word embedding)作为一种语言模型和特征学习技术[14],利用神经网络把文本映射到向量空间,能够提取词向量并获取文本潜在的特征信息,进而用到主题模型等自然语言处理任务来提升建模性能.BERT是基于双向Transformer结构的语言预训练模型[15],可以在外部海量语料库的基础上为单词学习一个好的特征表示,在后续特定的自然语言处理任务中直接用来作为某个任务的词嵌入特征.鉴于BERT优秀的模型性能且已被广泛应用,本文选择其进行提取特征输出向量,通过词向量计算语义相似度来准确评估must-links之间的语义关系,实验证明优选语义相似度更高的must-links集合能够有效提升AMC模型.
对于终身主题模型来说,假设must-links两个词语共现频率较高表示两个词语具有一定的相关性,则认为其对当前任务来说是正确的,但只是计算must-links一起出现的频率,并没有考虑其本身存在的语义关系.针对上述问题,本文提出的SS-AMC引入BERT预训练模型输出的词向量计算must-links的语义相似度,从而选择语义关系更为相似的must-links来作为先验知识,增强主题词之间的内部关联,更好地对主题进行采样.词向量之间的语义相似度采用余弦相似度方法计算,一对must-links的两个词的词向量分别用cx和cy表示,则cx和cy之间的语义距离为
(9)
设置相似度阈值ω,取γ大于ω的must-links集合作为最终保留的先验知识.
2.2 SS-AMC模型框架
SS-AMC主要框架如图1所示,主要包括先验知识挖掘、相似度计算及主题采样3个部分.对每个产品评论数据进行数据预处理之后进入任务管理器,每个评论文档被视为一个任务,依次输入基于知识的挖掘器挖掘must-links和cannot-links知识.对must-links词对的语义关系用词向量表示的语义相似度来度量,获得具有较大语义关系的词对输入采样过程和cannot-links辅助主题生成.

图1 SS-AMC模型框架
SS-AMC整体算法如算法1描述.首先,从知识库S的过去主题中挖掘出一组must-linksM;其次,优化M,用BERT预训练语言模型产生每对must-links词语的向量c,计算每对向量cx和cy的语义相似度,设置相似度阈值ω对must-links进行筛选;然后,运行Gibbs采样器,只用must-links产生一组当前任务主题AN+1,nl是采样器的迭代次数;再根据S中的过去主题P和当前主题AN+1挖掘cannot-links集合C,第8行用M和C优化主题集合;最后更新主题库.
SS-AMC整体算法:
算法1:SS-AMC;
输入:新任务文档DN+1,知识库S;
输出:新任务的主题AN+1,(1)M←MustLinkMiner(S),
(2)c←BERT(wml),
(3)M←Simlarity(cx,cy,ω),
(4)C=φ,
(5)AN+1←GibbsSample(DN+1,M,C,nl),
(6)Forr=1 toR,
(7)C←C∪CannotLinkMiner(S,AN+1),
(8)AN+1←GibbsSample(DN+1,R,C,n),
(9)End for
(10)S←UpdateKB(AN+1,S).
3 实验结果
3.1 数据集
本文在公开英文数据集和自建中文数据集上分别评估SS-AMC模型.英文数据集来自亚马逊评论数据,共有50种产品的评论各1 000条.在中文方面由于没有可参考的实验设置,本文在中文数据集上与英文设置保持一致,自建一个京东产品评论数据集.通过在中文和英文两个数据集上分别进行实验验证,证明了SS-AMC模型具有较好的建模效果.
对以上数据集按照文献[16]中的步骤进行数据预处理操作.对中文数据集中的每个文档用jieba工具进行分词,去除停用词、标点符号,删除出现小于5次的单词,以及只保留名词和形容词.由于商品名称在数据集中出现非常频繁,会对模型结果造成干扰,因此也会被剔除.从每个产品的1 000条评论数据中随机抽取100条用作少量数据的评估数据集,以验证模型在少量样本数据上的优异表现.
3.2 评价指标
本文采用主题一致性(Topic Coherence)评分作为评估指标[17],其不依赖于外部语义信息,能减少外部信息对主题质量评价的干扰,是一种方便有效的主题模型评估方法.主题一致性评分结果为负数,值越大代表生成的主题质量更好.其基本原理是词语在同一个文档下出现次数越多,则理论上二者语义相似度越大.设Dw为单词w出现的文档数,D是单词w和单词w′共现的文档数,则主题k的一致性评分公式定义为
(10)
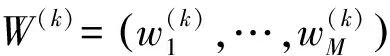
3.3 参数设置
LDA[9]模型中的狄利克雷分布超参数α设置为1,β分别设置为0.1.LTM及AMC模型均按照原模型的参数进行设置.对于SS-AMC模型最主要的参数是相似度阈值ω,由于ω过大会使生成的must-links太少,主题词之间有较大的重复,过小会对must-links约束不够,两种设置均会对实验造成一定的影响.因此,实验中分别采用ω为0.5,0.6,0.7的不同阈值进行对比.
3.4 实验结果与分析
由于本文主要是对少样本数据集上的终身主题模型进行改进,每个测试集由从1 000条产品评论中随机抽取的100条评论组成,从其余的49个产品的完整数据(1 000条评论)中生成的主题中提取知识.对比实验主要选取有AMC、LDA.由于AMC模型已经优于许多相关模型,如MC-LDA[7]、GK-LDA[16]、DF-LDA[18]、LTM[11],因此在实验中主要比较了SS-AMC与AMC,不同模型的主题一致性评分对比见图2.AMC模型主要在少样本上具有一定的优势,因此不与其他需要依赖大量数据的主题模型比较.
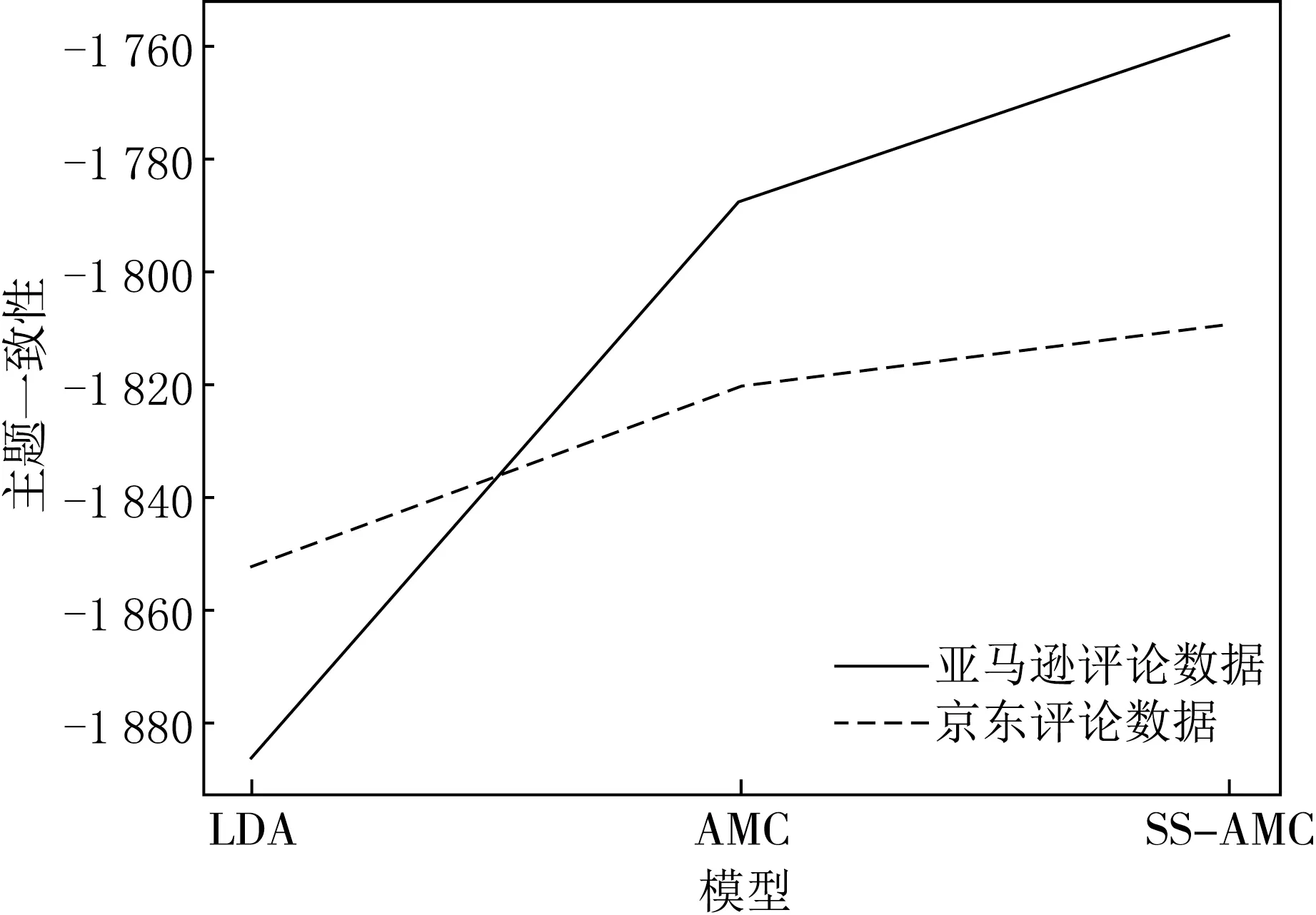
图2 主题一致性评分
由图2可以看出,在两个数据集上,SS-AMC的平均主题一致性评分均较AMC有不同程度的提升.同时,京东评论数据集上主题一致性评分的提高也说明了终身主题模型同样适用于中文数据.由此可见,SS-AMC模型在中英文数据集上都具有适用性,说明利用词向量计算语义相似度,优化先验知识能够对终身主题模型产生积极影响,能够生成更连贯的主题.
SS-AMC模型的关键参数相似度阈值ω不同会对实验结果造成一定的影响,本文评估模型的主题一致性评分见表1.
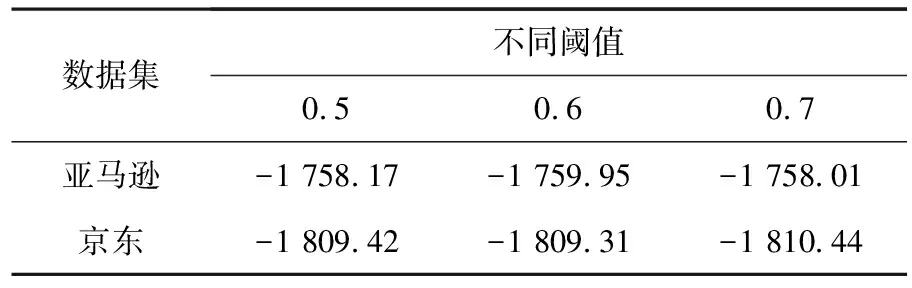
表1 不同阈值的主题一致性对比
SS-AMC模型通过设置must-links的相似度阈值来优化初始的must-links,在阈值等于0.5,0.6,0.7时的结果最好.由于must-links集合本身存在较大的语义相关性,如果阈值设置过小,会对must-links包容性过强,无法起到约束作用,阈值设置过大,会使得must-links过少,主题词重复性过高.
4 结论
本文模型利用在外部的大规模语料库上已训练好的词向量特征对must-links先验知识的生成过程加以改进.在真实的数据集上进行实验验证,与AMC、LDA模型的对比实验结果表明,该模型能利用BERT词向量信息进一步提高先验知识的正确性,挖掘出的主题语义相关性更大、主题质量更高,并且在中文和英文数据集上都有提升,在英文数据集上提升较大.对于把词向量引入到终身主题建模过程中,本文的工作仍较为初步,未来的研究工作将词向量融入整个建模过程中,探索如何从初始的数据集上挖掘更深层次的语义信息,提升建模效果.
猜你喜欢
客联(2022年3期)2022-05-31
中国卫生统计(2022年2期)2022-05-28
四川大学学报(自然科学版)(2021年6期)2021-12-27
中国新闻周刊(2021年26期)2021-07-27
陕西理工大学学报(自然科学版)(2021年3期)2021-06-23
唐山师范学院学报(2018年6期)2018-12-25
自动化学报(2017年5期)2017-05-14
电脑爱好者(2017年7期)2017-05-06
探测与控制学报(2015年4期)2015-12-15
