
嵌入卷积块注意力模块的人像自动抠图算法
2023-01-16 07:27侯玉寒宋建辉刘砚菊刘晓阳
沈阳理工大学学报 2023年1期
侯玉寒,宋建辉,刘砚菊,刘晓阳
(沈阳理工大学 自动化与电气工程学院,沈阳 110159)
图像抠图技术作为计算机视觉领域的研究内容,在影视特效、视频创作和平面设计等方面有着广泛的应用[1]。目前,大多数抠图任务需要人工选择区域完成,因为输入的三分图需要手动创建,导致工作量大且效率低下。因此,研究无需人工输入三分图且能确保精确度的人像自动抠图算法具有重要意义。
图像抠图方法分为传统方法和深度学习方法。传统抠图方法包括基于采样、基于传播及采样传播相结合三种[2]。Huang等[3]提出了像素级多目标采样算法,该算法虽然提高了采样性能,但最优像素对易丢失,无法保证其鲁棒性。Chen等[4]提出了K近邻(KNN)抠图算法,在非局部区域使用K个最近邻像素进行匹配,但对存在间断(如孔洞等)的物体前景提取效果较差。随着深度学习的快速发展,基于深度学习的抠图算法占据了重要地位。Xu等[5]提出了深度图像抠图(DIM)算法,该算法由编解码网络与细化网络组成,无需传统方法辅助,但需要三分图作为输入,时效性较差。Chen等[6]提出了语义人像抠图(SHM)算法,在自动抠图领域中取得了突破性进展,该算法无需三分图作为输入,但其参数量较多,模型较大。
针对以上问题,本文提出嵌入卷积块注意力模块的人像自动抠图算法。通过预分割分支网络、Alpha抠图分支网络和细节融合分支网络进行学习,恢复人像复杂结构,得到最终Alpha图,在无需三分图输入的情况下完成自动抠图。
1 网络结构与原理
1.1 预分割分支网络
1.1.1 MobileNetV2主干网络
预分割分支网络采用轻量级MobileNetV2[7]作为主干网络,以减少网络参数,使网络更轻量化。
MobileNetV2网络保留了MobileNet网络[8]的深度可分离卷积,同时加入具有线性瓶颈的倒残差结构[9]。倒残差结构如图1所示。

图1 倒残差结构图
由图1可见,倒残差结构通过1×1卷积进行升维及降维,中间使用3×3深度可分离卷积对各通道的空间特征进行提取,最后使用线性变换(Linear)代替ReLU进行激活。对于步长为1的卷积,其输入、输出特征大小相同,故对获取的特征图进行跨越连接操作;步长为2时,其输入、输出特征大小不同,为加强算法精度,不进行跨越连接。标准卷积的参数数量为M×N×Dk×Dk,其中M为输入图像通道数、N为输出图像通道数、Dk为卷积核大小;深度可分离卷积将卷积参数数量减少至M×Dk×Dk+N×M。MobileNetV2通过深度可分离卷积减少卷积参数,同时通过倒残差结构确保深层分割网络的鲁棒性。
1.1.2 轻量级MobileNetV2-Unet网络构架
本文预分割分支网络搭建了一个轻量级神经网络,其结构如图2所示。通过对输入的人像进行语义分割,获取包括背景、前景和不确定区域的三分图。本文采用的基础网络框架Unet是以用于语义分割的全卷积网络(FCN)[10]为基础的U形对称网络。通过编码器完成降维和特征提取,初始卷积层使用3×3卷积核并逐级进行4次2×2最大池化,得到尺寸缩小1/8、通道深度扩大16倍的特征图。本文算法在上采样前将Unet特征连接与MobileNetV2特征提取相结合,经过一个2×2的卷积提取特征,防止参数过多导致过拟合问题;在获得较浅层特征时使用更少的卷积,从而保留更多的浅层特征信息,加快人像的分割速度。

图2 预分割分支网络结构图
对于5层的Unet网络,其规模较大,模型参数较多,为降低模型体量,本文在保留其U形编解码结构的同时,使用MobileNetV2作为编码器进行特征提取,减少卷积参数。在MobileNetV2中使用的ReLU6激活函数无负值,表达式如式(1)所示,其必要的稀疏处理操作会过滤很多有效特征,从而影响模型对有效信息的学习;线性激活函数计算复杂,对量化过程不友好。故本文引入hswish激活函数[11],将MobileNetV2倒残差结构中的ReLU6、线性激活函数替换为h-swish进行优化,如式(2)所示。

式中x为输入。
因h-swish激活函数在更深层网络上的效果更好,故在预分割网络结构中浅层网络的激活函数仍使用ReLU6和线性激活函数,在第5层倒残差模块中使用替换的h-swish激活函数,以保留更多的有效特征,提高神经网络的精度。
网络的解码器部分包括解码模块和一个输出预测层,解码模块由跳跃连接结构及最大值去池化层、卷积层、批处理标准化(BN)层[12]组成。本文通过解码模块使经过特征提取后得到的低分辨率图片在保留高级抽象特征的同时变为高分辨率图片;再通过特征拼接后使用反卷积-卷积至下一次上采样,逐级进行4次上采样操作,恢复原图分辨率;最后通过输出预测层采用2个卷积核大小为1×1的卷积得到三通道的特征图。
1.1.3 预分割分支网络损失函数
通过预分割分支网络得到三分图,使用如式(3)所示的Softmax函数[13]输出概率分布,采用交叉熵损失函数Lt,其计算式如式(4)所示。

式中:qim表示像素i属于类别m时通过Softmax函数获得的网络预测图像类别概率;yi表示预分割网络输出;ym表示像素属于类别m时的输出;N表示类别数量;Pim表示像素i的标签,当预测的三分图像素i所属真实类别为m时,Pim为1,否则为0。
1.2 Alpha抠图分支网络
1.2.1 卷积块注意力模块
卷积块注意力模块(Convolutional Block Attention Module,CBAM)[14]结构如图3所示。该模块首先通过通道注意力模型对输入的特征图使用最大池化及平均池化进行压缩;再将获得的两个权重向量送入多层感知机(MLP)神经网络[15];最后将其输出的两个特征相加并使用Sigmoid函数激活得到通道注意力特征图MC(F),其表达式为

图3 CBAM模块结构
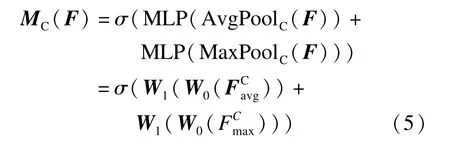
式中:F为输入特征图;σ表示Sigmoid函数;AvgPoolC、MaxPoolC分别表示在通道上的平均池化和最大池化;W0和W1为感知机的学习权重,W0∈Rc/r×c、W1∈Rc×c/r,其中r为控制感知机的衰减系数,c为特征图的通道数;FCavg、FCmax分别表示平均池化和最大池化的通道特征图。
通过空间注意力模型在通道方向上对特征图MC(F)与输入F进行张量乘法操作得到特征图F',对F'进行平均池化和最大池化,并将得到的两个特征图在通道方向上进行连接,经过卷积、Sigmoid激活后生成空间注意力特征图MS(F'),其表达式为

式中:f7×7为7×7的卷积;AvgPoolS、MaxPoolS分别为在空间上的平均池化和最大池化;、分别表示平均池化和最大池化的空间特征图。
将二维空间特征图MS(F')与输入特征图F'进行张量乘法操作,得到最终的输出特征图。
1.2.2 嵌入CBAM的Alpha抠图分支网络
Alpha抠图分支网络将预分割分支网络的输出与原始图像合为一个图像后作为语义输入,其架构为编解码(Encoder-Decoder)结构[5],但对其结构进行剪枝操作,在确保精度的前提下尽量缩小模型;在网络中加入CBAM模块,捕捉人像目标细节信息,加强边界细节的恢复,最后得到Alpha图。Alpha抠图分支网络结构如图4所示。

图4 Alpha抠图分支网络结构
Encoder网络采用5个卷积核大小为3×3的卷积层和4个最大池化层。在每个卷积层后加入BN层和ReLU激活函数以加速收敛。为将网络层中复杂丰富的细节信息最大化恢复,在编码器最终的卷积层后加入CBAM模块:首先采用通道注意力模块进行通道权重向量计算得到MC(F),融合高级人像特征,获取丰富的上下文信息;然后通过空间注意力模块进行权重矩阵计算得到MS(F'),提升关键区域的特征表达,减少毛发等输出的纹理细节信息的丢失。CBAM模块输出特征图通过Decoder网络用5个卷积核大小为5×5的卷积层和4个最大去池化层进行上采样操作,每个卷积层结构均由3×3卷积、BN层和ReLU激活函数组成[12],在上采样时依照下采样得到的最大池化映射进行反池化,从而逐步恢复特征图分辨率,进而更好地恢复边缘信息,最后通过输出预测层得到初步的Alpha图。
1.2.3 Alpha抠图分支网络损失
Alpha抠图分支网络损失主要包括Alpha预测损失和合成损失,其损失函数Lp计算式为

式中:λ为约束,设置为0.5;αr表示Alpha图的初步预测值;αg表示Alpha图的真实值;hp、hg分别表示图像前景的预测值及真实值,计算式分别为

式中I表示输入的图片。
1.3 细节融合分支网络
细节融合分支网络将预分割分支网络输出的语义信息与抠图分支网络输出的结构和纹理细节信息相融合,聚焦于不确定区域,以得到精细的Alpha图。使用P、B和U分别代表预分割分支网络在Softmax层之前预测的前景、背景和不确定区域的通道,则预测前景、背景及不确定区域的概率计算式分别为

式中Pg、Bg和Ug分别为预测前景、背景及不确定区域的概率。
当像素位于不确定区域内时,该像素更可能属于人的轮廓并构成类似发丝等的复杂结构,使用Alpha抠图分支网络得到的αr更精确。像素位于不确定区域之外时,该像素属于前景的概率为Pg/(Pg+Bg),则Alpha图的最终预测值αp的计算式为

本文网络总损失L包括预分割分支网络损失和Alpha抠图分支网络损失,其表达式为

式中λ为分解约束,用于保证三分图有实际意义,本文设为0.01。
2 实验与分析
2.1 数据集及评价指标
本文实验数据集采用Human Matting[6]和Real World Portrait[16]人像数据集,各包含34 427张人像及对应Alpha图、636张人像及对应Alpha图。去掉含遮挡的不规范图片及Alpha图效果较差的图片,挑选出包含人体各个部位、各种姿势的16 000张高质量图片作为训练集,并将其大小统一裁剪为600×800进行训练。
为定量评估抠图算法的性能,使用绝对误差和(SAD)、均方误差(MSE)[17]作为评价指标。SAD用来衡量图像像素之间的相似度,MSE表示图像像素间误差平方的期望值,SAD和MSE值越小,模型预测结果越准确,两者计算式分别为

式中:αip为像素i处Alpha图的预测值;αig为数据库中像素i处Alpha图的真实值;n为像素的个数。
2.2 实验环境与参数设定
本文实验硬件环境为Ubuntu20.04 64位系统、GPU为NVIDIA Quadro P5000、CPU为Intel Xeon×12,通过PyTorch框架及编程语言Python3完成训练和测试。训练过程中样本设为160个/批。
使用自适应矩估计(Adam)优化器对网络进行优化。表1为本文算法预分割分支网络与端到端网络训练的超参数设置。

表1 超参数设置
2.3 实验结果分析
采用网络参数统计工具torchstat对原始Unet网络、SHM算法采用的PSPNet网络及本文采用的MobileNetV2-Unet网络进行参数量计算,结果如表2所示。

表2 网络参数量对比
由表2可知,与图像分割网络Unet及PSPNet网络相比,本文采用的MobileNetV2-Unet网络应用深度可分离卷积,在参数规模上具有一定优势。
为评估本文嵌入CBAM模块抠图算法的有效性,分别与具有代表性的传统KNN抠图算法、深度学习的半自动DIM算法及无CBAM模块的SHM自动抠图算法进行对比。由于SHM算法未公开其相关程序,故本文对比实验使用相同数据集的复现版。为保证实验结果可靠,对比算法均使用与本文相同的数据集进行训练,并且将经过良好训练的网络得到的三分图作为约束,采用SAD、MSE作为通用衡量标准,对比分析结果如表3所示。

表3 不同抠图算法对比
由表3可见,本文提出的嵌入CBAM人像抠图算法评价指标SAD、MSE值最小,与Trimap+DIM算法相比,SAD值降低了7.5%、MSE值降低了19.4%,运算时间为每张图片0.162 s,从精度与时间两方面衡量,均具有一定优势。本文算法加入CBAM模块,充分利用人像的语义特征及细节信息,无需三分图输入,只需要一张彩色图像即可完成抠图任务。
本文对各算法进行测试的直观对比结果如图5~7所示。图5、图6、图7分别代表在自然场景下、室外及室内环境下各复杂背景的细节识别,每组效果图包括人像Alpha图及对应细节放大图。

图5 自然场景下算法对比效果图

图6 室外环境下算法对比效果图

图7 室内环境下算法对比效果图
对比图5~7可以看出:传统的KNN算法在三种环境下人像抠图效果最差,易过度分割,在图5(b)、图7(b)中存在严重的背景误判问题,在图6(b)中存在很多伪影;SHM算法对人物边缘轮廓的处理较柔和,其Alpha图较为平滑,但对于有过多发丝的人像仍然存在背景误判现象,如在图5(c)中对于人像的发尾没有完全分割出来,也存在漏分情况,如图7(c)的细节放大图中未完全分离出其发丝之间的孔洞;DIM算法抠图效果较好,对于人像的发丝部分能较好分离出来,但其算法需要以三分图作为输入,其三分图的准确程度对于人像的抠图效果有直接影响。对比上述方法,本文采用的人像抠图算法可以较为精细地完成人物细节信息处理,将图像中人物与背景分离,对于复杂结构也可以得到较好的抠图效果,如图5(e)和图6(e)中人像发丝识别较好,图7(e)中分离出发丝之间的孔洞,且无需三分图作为输入,边界清晰。本文提出的算法达到了良好的抠图效果,具有一定的可靠性。
3 结论
本文针对大多数人像抠图算法需要人工交互及抠图精度不高的问题,提出了一种嵌入CBAM的人像自动抠图算法。通过预分割分支网络学习人像的语义信息,采用轻量级网络MobileNetv2与Unet结合并加以改进,减少模型参数;使用Alpha抠图分支网络学习人像细节信息,在网络中加入CBAM模块,提高抠图质量;通过细节融合分支网络将前两者学习的特征进行汇总,使用总损失函数进行约束,完成具有一定通用性的人像自动抠图算法。实验结果表明,本文提出的算法无需三分图作为辅助输入,模型参数量有所减少,其SAD、MSE指标较其他算法均有所降低,网络模型预测结果更准确,抠图效果更好。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
计算机应用(2022年9期)2022-09-25
黑龙江大学自然科学学报(2022年1期)2022-03-29
软件导刊(2022年3期)2022-03-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
