
基于船厂分段时空数据的分段状态识别及转运监测
2023-01-18 02:17陈俊宇
上海交通大学学报 2023年1期
陈俊宇, 田 凌
(清华大学 a. 机械工程系; b. 精密超精密制造装备及控制北京市重点实验室,北京 100084)
大型船舶一般以三级中间产品分级建造,规模由小到大分为零件级、组立级和分段级.其中,分段在船厂的生产设计和生产管理中居于核心地位.分段在建造中需要经历5种工艺(即组装、预舾装、冲砂打磨、涂漆和预总组)以及在工艺之间的堆场周转,场地之间的分段转运通过专用平板车完成.分段转运保障了分段在各个工艺之间的有序流动,但消耗了大量成本.以国内某水平领先的船厂(以下称为S船厂)为例,年均分段转运3.7万次,相关一线员工(平板车司机、起重工和叉车工)42~45人,每次转运平均需要3.3人次、耗时40 min,物流部门每日两班倒以满足船厂转运需求,年均消耗成本 2 200 万元,约占船厂年净利润的1/10.
大量分段转运不是分段建造所必需的,即为非生产性转运,包括两类.第一类非生产性转运是由于分段堆场拥挤,分段之间互相阻挡所造成的额外转运,特征为转运的起止分段状态均为堆场周转.堆场相关转运中第一类非生产性转运的比率,即第一类非生产性转运率[1-7]是常用的评价指标,已有研究显示其集中在10%~30%,可以通过评估这一指标来监测船厂的第一类非生产性转运.第二类非生产性转运是由于派工调度不合理、场地沉降、工装设备故障等原因,工艺出现返工所造成的额外转运,特征在于转运终点的分段状态为已经历过的工艺,可以通过评估单位时间内各项工艺的返工数和开工数之比,即返工开工比来监测船厂的第二类非生产性转运.除这两类转运之外,其余转运均为生产性转运.
合理的生产计划和堆场调度是减少两类非生产性转运的关键.然而,由于生产和转运现场的干扰因素多,一线班组在执行中具有一定决策权,所以分段转运的计划和执行之间存在较大区别.船厂管理者需要监测实际转运过程,特别是监测两类非生产性转运,进而实现衡量转运计划执行情况,为后续的优化提供数据支持.在分段转运过程监测领域,韩国团队[8-11]利用全球定位系统(Global Positioning System,GPS)、射频识别设备(Radio Frequency IDentification,RFID)、惯性测量单元(Inertial Measurement Unit,IMU)、无线局域网(Wi-Fi)等技术实时显示分段位置,为船厂提供了分段位置数据的实时监测手段.我国船厂也跟进了这一领域,张恒等[12]研究了船体分段外场物流实时综合监测系统方案,包括船厂的场地编码体系和基于GPS/RFID组合的分段、平板运输车的定位方案等技术,可以自动化获取分段的时空数据.在空间充裕的船厂中,场地一般用途专一,可以直接通过时空数据反映分段的实时状态.然而S船厂生产任务多、场地紧张,存在一场多用的现象,即部分场地对应了多种分段状态,在应用分段转运过程监测技术时,分段的时空数据可以给出分段在建造过程中经历的场地序列,但是无法直接转换为分段状态序列,因此难以实现两类非生产性转运的监测.
本文针对S船厂在分段转运监测中存在难以获取分段状态的问题,通过研究分段转运过程中分段状态的特征,提出了基于隐马尔可夫模型(Hidden Markov Model,HMM)的分段状态识别方法,并应用于船厂分段时空数据,实现了船厂的两类非生产性转运的监测,验证了本文方法的有效性.
1 分段转运过程分析
分析船厂分段转运中分段状态的规律,是选取合适的推理方法,实现分段状态识别的基础.首先经由领域专家构造标注数据集,在此基础上分析了分段状态间时序关系和分段状态的耗时特征,为分段状态识别奠定了基础.
1.1 领域专家标注单船建造中的分段状态
分段状态会因为分段转运而发生变化,针对船厂的分段转运过程已有一定研究.Lee等[13]为了描述典型的分段转运过程,与韩国大宇船厂合作,基于某一条船190个分段的转运日志数据,采用事件日志驱动的过程挖掘方法[14-16],通过挖掘频繁起止分段状态对,描述了“标准型”“简单型”“翻转型”和“外协型”4种典型的分段转运过程,并指出由于标准型分段转运过程中只在预舾装和冲砂打磨两个工艺前有堆场周转,是韩国大宇船厂的生产瓶颈.这一研究说明现代船厂中分段状态的变化具有稳定的时序特征,然而该研究使用的分段转运数据样本量较小,且不同船厂的典型分段转运过程不同,其给出的典型分段转运过程不能直接用于本文.陈好楠等[17]研究了国内某船厂的分段转运数据,这一数据给出了转运的日期和起止场地,不包含分段状态.研究人员通过现场调研获得了两条船480个分段相关转运的起止状态,利用层次聚类算法,给出了典型的11种分段转运过程.这一研究面临的困境与本文相似,即分段转运数据中缺乏分段状态.虽然其通过现场调研方式人工标注了分段状态,但是这种方式能处理的数据量少,难以对全船厂所有分段的状态进行监测,分析结果也仅能用于描述单船的分段转运情况,无法反应船厂各个工艺的整体情况,无法对分段转运过程的影响因素进行监测和分析.
S船厂虽然存在一场多用的现象,但是分段转运并不是随意的,转运的起止场地和分段状态受到多种因素的影响,包括船厂内部的物流惯例、分段规格、场地的设备能源条件、调度人员掌握的信息和权限范围等.例如,有的冲砂场地多用于曲面分段,而有的冲砂场地多用于平面分段;双层底分段由于规模较大,往往在喷漆后安排在特定的周转堆场;有的工艺场地可以支持完工后的检验工作,之后分段直接进入下一工艺,不需要转运到堆场进行检验.这样的规则数量极多且难以穷尽,将其枚举并显式表达的成本很高.然而,熟悉这些规则的领域专家可以在参考船厂的历史生产计划的基础上,通过分析单个分段所经历的场地序列,就较为准确地推理出对应的分段状态序列.
为了研究S船厂分段转运中分段状态的变化规律,获得可以像专家一样从场地序列推理分段状态序列的推理模型,邀请船厂物流部门的班组长,为某船234个分段的时空数据标注了分段状态,构造了标注数据集,其形式如表1所示.表中前4列为分段时空数据原有数据,后2列为人工标注数据,从中可以看出分段101的转运轨迹,经历了“G场—I场—D场—……—K场—C场”的场地序列,以及“组装—堆场周转—预舾装—……—堆场周转—预总组”的分段状态序列.标注数据集覆盖了 2 990 次转运,有3 224 个分段状态,其中234个分段状态为分段开始第一次转运前的组装,234个分段状态为分段完成最后一次转运后的预总组,因此,这468个分段状态的耗时无法计算;而其余分段状态可以通过各自的起止时间计算耗时.

表1 标注数据集Tab.1 Labeled dataset
抽取出标注数据集中75%的分段(176个)相关的数据作为训练集,用于后续分段转运过程的分析和分段状态识别方法的研究;剩余25%的分段(58个)相关的数据作为测试集,用于验证相关结论.
1.2 分段状态间时序关系分析
分段状态之间通过分段转运发生时序上的转化,本文采用有向图描述不同分段状态之间的时序关系,如图1所示.节点为分段状态,其中矩形节点为堆场周转,椭圆节点为5种工艺;有向边为分段状态之间的转化(即分段转运),有向边的宽度和数字表示对应转运在训练集中的频次,图中只绘制了频次超过10次的转运.由于S船厂中5种工艺都与堆场周转有关,如果将堆场周转视为一个节点,则有向图中会出现以堆场周转为中心的布局,难以直观表达不同工艺之间的时序关系,所以在构建有向图时,按紧随的工艺区分了堆场周转.

图1 分段状态间时序关系Fig.1 Time sequential relationships between state of blocks
由图可见,S船厂中分段经历的工艺顺序一般为组装、预舾装、冲砂打磨、喷漆和预总组,有部分分段跳过了预舾装,工艺之间大多数情况下有堆场周转,也存在直接转运的情况,这种不确定的时序关系表明前序的分段状态会影响但不能直接决定未来的分段状态;由于分段组装之后才会进行第一次转运,完成预总组之后分段建造就结束,不再进行转运,所以以组装为起点的转运远多于以组装为终点的转运,以预总组为起点的转运远少于以预总组为终点的转运;堆场周转节点上存在自环有向边,例如有406次转运的起止分段状态均为冲砂打磨前周转,说明存在大量第一类非生产性转运;工艺节点上存在环形子图,例如“组装-组装”,“预舾装-预舾装前周转-预舾装”,说明存在某一分段不止一次经历同一工艺,即第二类非生产性转运.
1.3 分段状态耗时特征分析
根据S船厂的生产特点,可知分段在加工中,可能会多次经历某一工艺,然而其中一般只有一次为实质性加工,其余为修补返工.实质性加工和非实质性加工本质上是不同的,在研究其耗时特征时应予以区分.因此,规定每个分段经历的预舾装、冲砂打磨和喷漆中停留时间最长的一次视为实质加工,其余为非实质加工;分段第一次转运前的组装为实质组装,后续出现的组装为非实质组装;分段最后一次转运后的预总组为实质预总组,之前出现的预总组为非实质预总组.统计不同分段状态的耗时情况(不包括实质组装和实质预总组,这二者的耗时无法计算)如图2所示.将耗时(t′)分为短期(t′≤3 d)、中期(3 d
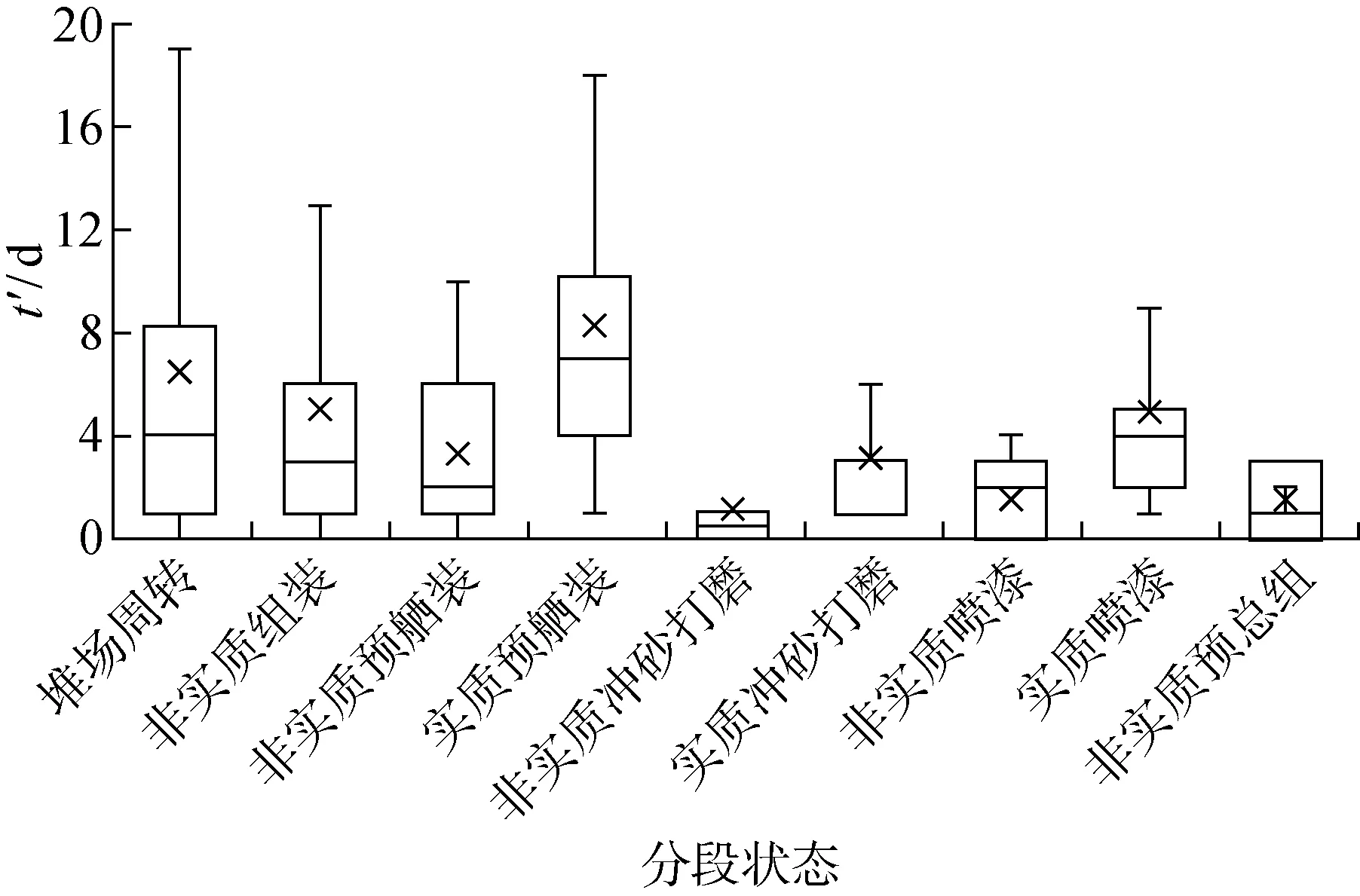
图2 各种分段状态的耗时Fig.2 Durations of state of blocks
2 分段状态识别
对分段转运过程中分段状态间时序关系和耗时特征进行分析,可知一方面分段状态受到前序分段状态影响,可以采用时间概率推理模型实现未知分段状态的推理;另一方面分段状态的耗时可能有助于识别分段状态的具体类型,不仅应该考虑直观上最明显的位置变量(即场地),也可以尝试考虑耗时特征.在此基础上,简述所使用的时序概率推理工具HMM,提出分段状态识别方法并应用于测试集,验证了本文方法的准确性.
2.1 时序概率推理工具HMM
常用的时间概率推理方法包括动态贝叶斯网络、卡尔曼滤波器以及HMM,后二者是动态贝叶斯网络的特例.三者都是通过将问题模型化,求解可观测部分在特定取值下不可观测部分为各个取值的条件概率,主要区别在于解决的问题类型不同.如果变量是小规模离散的,可用HMM解决;如果变量是连续的,可用卡尔曼滤波器解决;如果变量的数量较多,则动态贝叶斯网络更为高效[18].HMM作为离散随机变量时间序列的推理工具,提供了一种自然且高度稳健的概率推理方法,可以给出给定观察变量序列下状态变量的后验分布,适用于本文要解决的问题类型;其所遵循的假设具有直观的合理性,因此本文尝试使用HMM作为时间序列概率推理工具.Baum等[19]提出了用于推理和学习的HMM;Viterbi[20]提出了Viterbi算法,用于在HMM的基础上计算最可能状态变量序列.Rabiner[21]提供了关于HMM的详细教程.HMM可以形式化定义为一个5元组,表示为
λ=〈Xt,Ot,P(Xt|Xt-1),P(Ot|Xt),P(X0)〉
(1)
5元组各个元素的含义如下.
(1)Xt和Ot.将问题域离散化,并看作是一系列时间片,每个时间片都包含了一组离散随机变量,其中一部分是不可观察的,将所有不可观察变量合成为一个随机变量,称为状态变量,用Xt表示t时刻的状态变量,Xt取值范围为{1, 2, …,n}.另一部分是可观察的,将所有可观察变量合成为一个随机变量,称为观察变量,用Ot表示t时刻的观察变量,Ot取值范围为{1, 2, …,m}.
当某待定数量xt或ot以独立的形式出现在概率P后的括号中时,是一种缩写形式,代表了对应的随机变量等于相关值这一事件的概率,例如P(xt) =P(Xt=xt),P(ot) =P(Ot=ot).
(2)P(Xt|Xt-1)和P(Ot|Xt).Xt满足两个假设:一是马尔可夫假设,即当前状态只受前一个状态影响,不受更前的状态影响,即有
P(Xt|X0,X1,X2, …,Xt-1) =
P(Xt|Xt-1)
(2)
式中:P(Xt|Xt-1)用于描述状态演变的规律,称为转移模型,为一个n×n的矩阵T,其元素为
Tij=P(Xt=j|Xt-1=i)
(3)
二是稳态过程假设,即P(Xt|Xt-1)不随t变化.
Ot满足传感器马尔可夫假设,即观察变量值由当前状态变量值直接决定,即有
P(Ot|X0,X1, …,Xt,O0,O1, …,Ot-1) =
P(Ot|Xt)
(4)
式中:P(Ot|Xt)用于描述观察过程,称为观察模型,为一个m×n的矩阵O,其元素为
O[k,i] =P(Ot=k|Xt=i)
(5)
(3)P(X0).P(X0)为Xt的先验概率分布.
HMM是动态贝叶斯网络的特例,使用动态贝叶斯网络表示HMM,如图3所示.
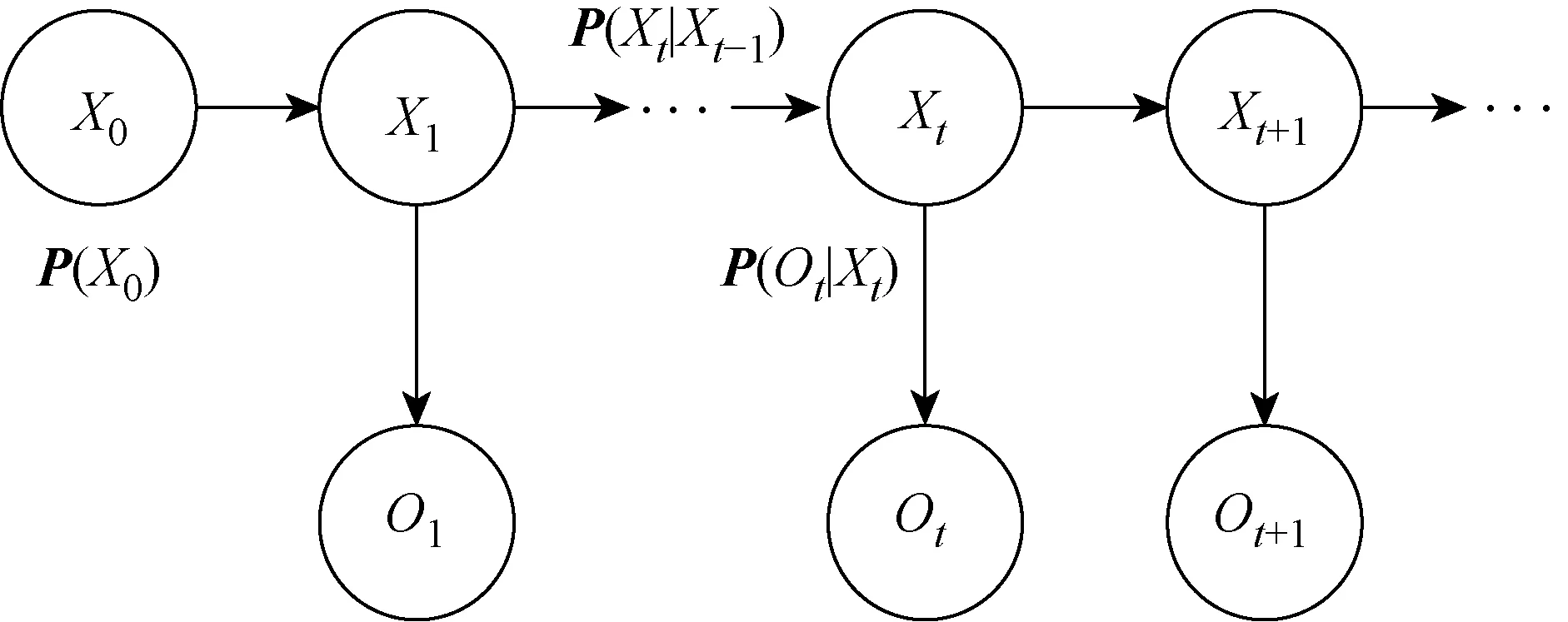
图3 使用动态贝叶斯网络表示隐马尔可夫模型Fig.3 Hidden Markov models in form of dynamic Bayesian networks
2.2 分段状态识别方法
为了实现分段状态识别,需要定义HMM中的Xt和Ot,再利用训练集学习HMM的转移模型、观察模型和先验概率分布,获得完整的HMM;在此基础上,利用Viterbi算法,实现分段状态序列的推理.
(1) 设置状态变量Xt和观察变量Ot.Xt和Ot的设置可以影响推理的准确度,其实质是对分段状态和观察到的情况进行离散化.根据图1,分段状态中堆场周转可以根据紧随的工艺分为组装前周转、预舾装前周转、冲砂打磨前周转、喷漆前周转和预总组前周转;根据1.3节的讨论,可以在设置观察变量时,既包含场地信息,也包含耗时信息.在训练集规模有限的前提下,为了准确获取HMM参数,状态变量和观察变量的取值多样性是有限的.因此,本文给出了4种Xt和Ot的设置方案.
方案1不区分堆场周转和耗时.不区分堆场周转,状态变量Xt有6个取值,代表5种工艺和堆场周转,n=6;不考虑观察变量Ot耗时,有42个取值,代表S船厂的42个场地,m=42.
方案2区分堆场周转,不区分耗时.按紧随的工艺区分堆场周转,状态变量Xt有10个取值,代表5种工艺和5种堆场周转,n=10;观察变量Ot设置方法同方案1,m=42.
方案3不区分堆场周转,区分耗时.状态变量Xt设置方法同方案1,n=6;观察变量Ot中融合42个场地和3种耗时(短期、中期或长期).为了形式的一致性,规定某分段的第一个和最后一个分段状态的耗时为中期,共有42×3=126个取值,即m=126.
方案4区分堆场周转和耗时.状态变量Xt设置方法同方案2,n=10;观察变量Ot设置方法同方案3,m=126.
使用上标s标识方案1~4获得的HMMs及其相关变量,如下式所示.
λs=
s=1, 2, 3, 4
(6)
(2) 学习HMM参数.无监督的方法(例如Baum-Welch法[22])学习复杂HMM参数需要超大规模的数据集,不适合S船厂的具体数据条件,因此本文采用有监督的方法学习HMM的参数,步骤如下.
步骤1计算转移模型P(Xt|Xt-1).通过频率估计概率,统计训练集中,状态变量由时刻t-1时的Xt-1=i,变为在时刻t下Xt=j的频数aij,则转移模型的元素表示为
(7)
步骤2计算观察模型P(Ot|Xt).通过频率估计概率,统计训练集中,时刻t时状态变量为Xt=i,同时观察变量Ot=k的频数bik,则观察模型的元素表示为
(8)
步骤3按均匀分布设置P(X0).由于HMM的鲁棒性,先验概率分布P(X0)对于推理结果的影响不大,所以可以直接规定这一分布为均匀分布.
步骤4修正转移模型.分段建造的一般过程是组装-预舾装-冲砂打磨-喷漆-预总组,但是一些加工需要返工,因此各个工艺之间都存在互相之间转移的可能,应该为转移模型中相对应的元素设置一个不为0的小正数作为其最小值;又因为在正常的加工中工艺环节隔得越远,二者之间越不可能返工,所以这个小正数可以随着工艺隔得越远而越小.
步骤5修正观察模型.一个场地能完成的工艺是有限的,观察模型描述了场地与分段状态之间的对应关系,如果统计表明某个场地未曾存在过某项工艺,就说明对应的元素值确实为0;如果统计表明某个场地未曾存在过某项周转,并不能说明该场地不可能承担该项周转任务,相应的元素最小值应设置一个不为零的小正数;多个场地属于室内车间,空间狭窄,限制较多,并不会承担分段的周转任务,这种事件在目前的训练集中没有发生过,可以认定这些场地内并不会发生周转,因此将观察模型中相应的元素设置为0.
(3) 分段状态序列推理.单独计算每个时刻各个状态的滤波或平滑的后验概率,并不能得出最优的状态序列推理,因此必须考虑所有时间片的联合概率.Viterbi算法[20]解决了这一问题,通过记录到达当前状态的有最大后验概率的前端状态序列,利用到达Xt+1的各个取值最可能的状态序列与到达Xt的各个取值最可能的状态序列之间的递归关系,求得有最大联合概率的状态及其所对应的前端状态序列为

P(Xt+1|xt)P(ot+1|Xt+1)=
(9)
式中:o1:t为o1,o2, …,ot的简写;P(x1, …,xt,Xt+1,o1: t+1)为一个n元向量,其第i个元素的值为P(x1, …,xt,Xt+1=i,o1: t+1).
表2和表3分别展示了HMM1的转移模型和部分观察模型,用以举例说明基于Viterbi算法的分段状态识别方法.依据HMM1进行某一分段的最可能分段状态序列推理,其观察变量序列的值(o1,o2,o3)是已知的,具体为(1, 13, 9),即(A场,G场,I场).

表2 HMM1的转移模型Tab.2 Transition model of HMM1

表3 HMM1的部分观察模型Tab.3 Part of observation model of HMM1
因为o1=1,根据联合概率分布的链式规则,以及贝叶斯网络中所有节点条件都独立于父节点以外的其他节点, 所以有
P(X1,o1)=P(o1|X1)P(X1)=


(10)
若观察到的场地序列到此为止,则由式(9)可知,最可能的分段状态序列为X1=3,即预舾装,其与观察序列同时发生的联合概率为0.040;此外,还有可能是X1=1,即堆场周转,联合概率为0.021,或者X1=2,即组装,联合概率为0.028.其他分段状态的概率较低.
因为o2=13,所以有
(11)
其中第3行的的因子〈0.021 0.028 0.040 0.0 0.0 0.0〉对应了x1=1, 2, 3, 4, 5, 6时P(o1|x1)P(x1)的值,已经在式(10)中求出;第4行第1个元素代表X2=1时对应的最可能的分段状态序列的联合概率,为了求得最可能的前序分段状态,需要以x1为自变量求这一元素的最大值,通过遍历可知x1=2时这一元素取得最大值,0.028为P(o1|x1)P(x1)在x1=2时的取值,0.54为P(X2|x1)在x1=2,X2=1时的取值;类似地,第4行其余5个元素分别代表代表X2=2, 3, 4, 5, 6时对应的最可能的分段状态序列的概率.
若观察到的场地序列到此为止,则由式(11)可知,最有可能的分段状态序列为X1=2,X2=1,其与观察序列同时发生的联合概率为0.001 361.另一个可能的分段状态序列是X1=2,X2=2,对应的联合概率为 0.000 481 6;其他序列的联合概率均较低.
因为o3=9,所以有


(12)
式中:第3行的因子0.000 1×〈13.61 4.816 0.0 0.0 0.0 0.0〉对应了x2=1, 2, 3, 4, 5, 6时P(o1|x1)P(x1)P(o2|x2)P(x2|x1)的值,这一值已经在式(11)中求出.
因为观察到的场地序列到此为止,所以由式(12)可知,最可能的分段状态序列为X1=2,X2=1,X3=1,即(组装,堆场周转,堆场周转),其与观察序列同时发生的联合概率为 0.000 022 05.另一个可能的分段状态序列为X1=2,X2=2,X3=2,即[组装,组装,组装],联合概率为 0.000 018 64;其他序列的联合概率较低.
以上这一计算实例如图4所示,其中,箭线表示分段状态在相邻时刻间转化的所有类型,这是一个全连接;实箭线表示当前观察变量条件下最可能的分段状态转化类型,其起点分段状态是终点分段状态的最佳前序分段状态;在完成最后一个时间的分段状态推理后,由于X3=1对应了最大的联合概率,因此可以认为堆场周转为t=3时的分段状态,通过实箭线反推出整个分段状态序列,在图中将这一序列对应的箭线和分段状态标红.这样就基于Viterbi算法实现了分段状态识别.
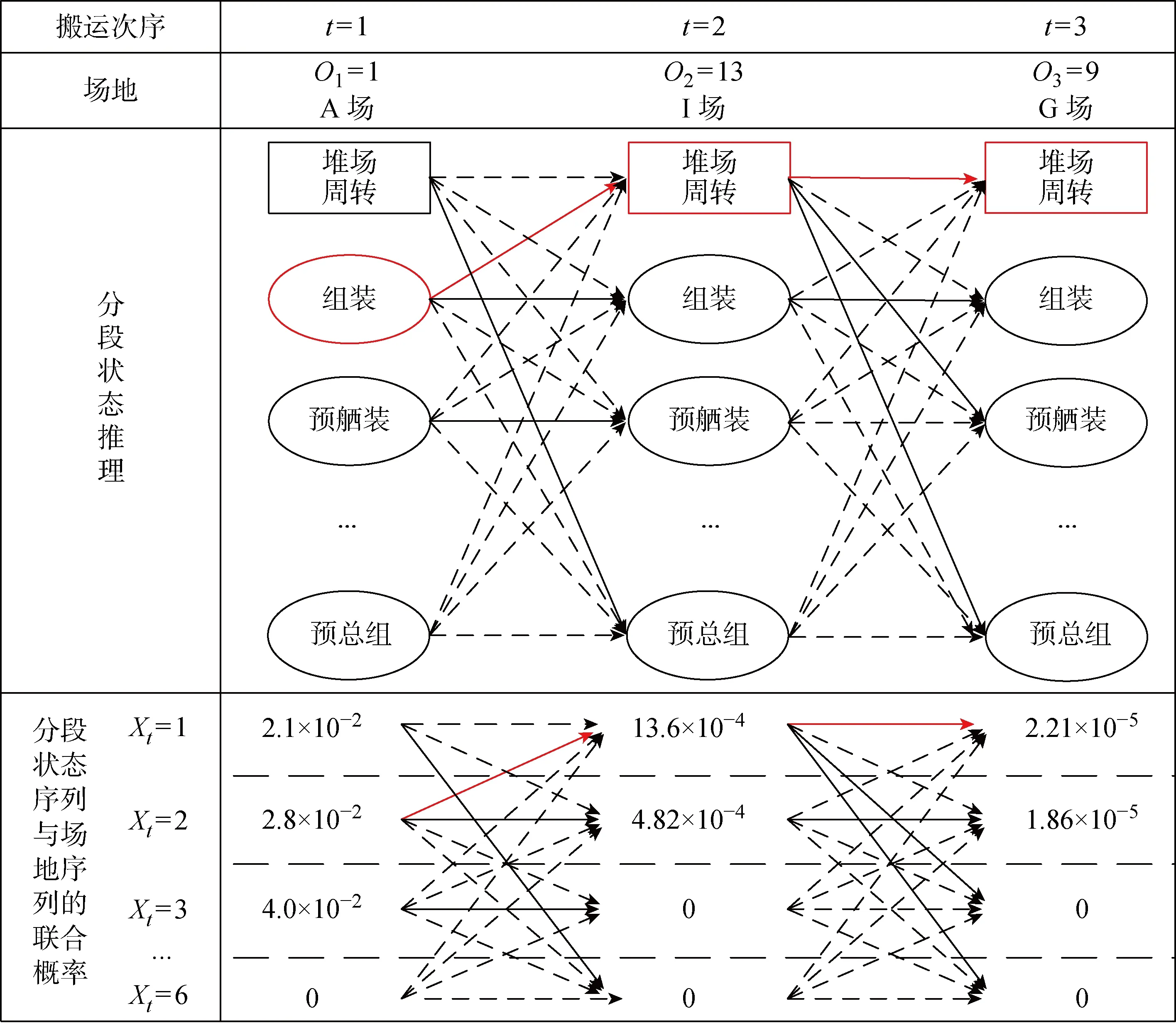
图4 利用HMM1和Viterbi算法推理某个分段的分段状态Fig.4 Reasoning of states of a block using HMM1 and Viterbi algorithm
2.3 分段状态识别结果
将2.2节中获得的4个HMM应用于测试集,推理分段状态序列,并验证其准确率和两类非生产性转运数量,结果如表4和表5所示.由于堆场周转的具体类型不影响转运性质的判断,所以基于HMM2和HMM4获得的分段状态推理结果还需要一步后处理, 即将目前按紧随的工艺分类的堆场周转退化为堆场周转大类,再计算状态识别准确率.

表4 4个HMM推理的分段状态结果Tab.4 Results of states of blocks predicted by 4 HMMs
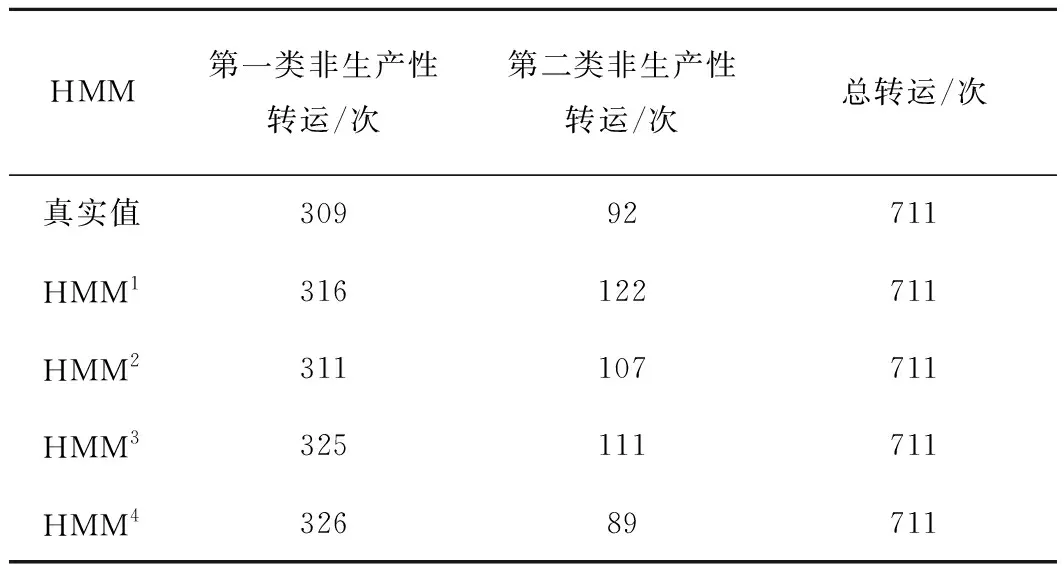
表5 4个HMM推理的两类非生产性转运数Tab.5 Results of 2 types of unproductive transfers predicted by 4 HMMs
可以看出:首先,在测试集上,4个HMM均有较高的分段状态识别准确率,这说明了将HMM应用在分段状态识别问题上是有效的,分段转运过程很大程度上满足HMM的3个先验假设,即马尔可夫假设,稳态过程假设和传感器马尔可夫假设.然后,HMM4在分段状态序列推理时具有最高的准确率,HMM2略微次之,HMM3再次,HMM1的效果最差.因此按紧随的工艺区分堆场周转、区分分段状态的耗时均有助于提高识别的准确率,HMM4效果更明显.最后,HMM2获得的第一类非生产性转运数量最准确,HMM1次之;HMM4推理的第二类非生产性转运数量较准确,HMM2次之.因此,HMM2在分段状态推理、第一类非生产性转运推理和第二类非生产性转运的推理上都有较好的应用效果.
为了验证本文方法的准确率,选用典型的机器学习算法——支持向量机(Support Vector Machine, SVM)作为对照.应用方案1~4提供的状态变量Xt和观察变量Ot,并规定t<1时,有Xt= 0,Ot= 0.以某个分段状态Xt的前2个分段状态Xt-2,Xt-1以及最近的3个观察变量Ot-2,Ot-1,Ot为输入特征,以Xt为输出值,以训练集学习每个方案对应的SVM分类器,记为SVMs,s=1, 2, 3, 4.使用测试集对4个支持向量机分类器进行准确率测试,与基于HMM的方法的分段状态识别准确率比较,结果如图5所示.由图可见,与基于SVM的分段状态识别方法相比,本文提出的基于HMM的识别方法在分段状态识别的准确率和鲁棒性上有明显优势.

图5 HMM与SVM方法的分段状态识别准确率对比Fig.5 Comparison of recognition accuracy of HMMs and SVMs
训练集和测试集来源于船厂实际的分段时空数据,现有的4个HMM在测试集上的准确率均较高,船厂的分段生产规律是长期较为稳定的.实验表明HMM2在识别两类非生产性转运上的表现良好,又因为HMM方法本身具有的鲁棒性,综合考虑,本文可采用HMM2作为分段转运监测使用的推理模型.
3 分段转运监测应用
上文提出了基于分段时空数据的分段状态识别方法,并在测试集上验证了其准确率.接下来,通过将这一方法应用到船厂实际的分段时空数据上,实现两类非生产性转运的监测,根据监测结果为优化船厂分段转运过程提出初步建议,验证本文方法的有效性.
以S船厂23个月的分段时空数据为样本,这一数据集的形式如表6所示,包括船号、分段号、转运日期、起点场地和终点场地;从表中可以大致看出303号船的134号分段、317号船的810号分段以及446号船的685号分段所经历的分段位置变化过程.这一数据集涵盖 9 984 个分段的 70 420 次转运对应的起点和终点场地.逐月转运次数如图6所示.

图6 S船厂逐月分段转运次数Fig.6 Monthly block transfers in S shipyard

表6 S船厂部分分段时空数据样本Tab.6 Samples of time-site data of blocks in S shipyard
将HMM2应用在船厂分段时空数据上进行分段状态识别,并逐月监测两类非生产性转运.对第一类非生产性转运情况进行逐月监测,计算第一类非生产性转运率,结果如图7所示.在23个月的观察期内,船厂中与堆场周转相关的转运中,第一类非生产性转运率平均值为62.5%,最高达到72%,这一比率在次年有所下降,但始终保持在52%以上,远高于现有研究给出的10%~30%的理论值,亟待通过优化船厂堆场调度策略、降低堆场负载率、降低分段在堆场的平均周转期、放松分段进出场时间约束等手段,减少第一类非生产性转运.

图7 第一类非生产性转运逐月情况监测Fig.7 Monthly monitoring results of Type I unproductive transfers
对第二类非生产性转运情况进行逐月监测,并计算各个工艺的开工数(ns)、返工数(nr)和返工开工比(r),结果如图8所示.在观察期内,组装的返工数和返工开工比一直处于高位,且返工开工比在次年的1月和2月间突然升高,这种异常情况被监测到后,可以提示管理者及时加强组装后的验收环节,提高组装场地的调度水平,避免在组装上产生过多的返工,减少第二类非生产性转运.
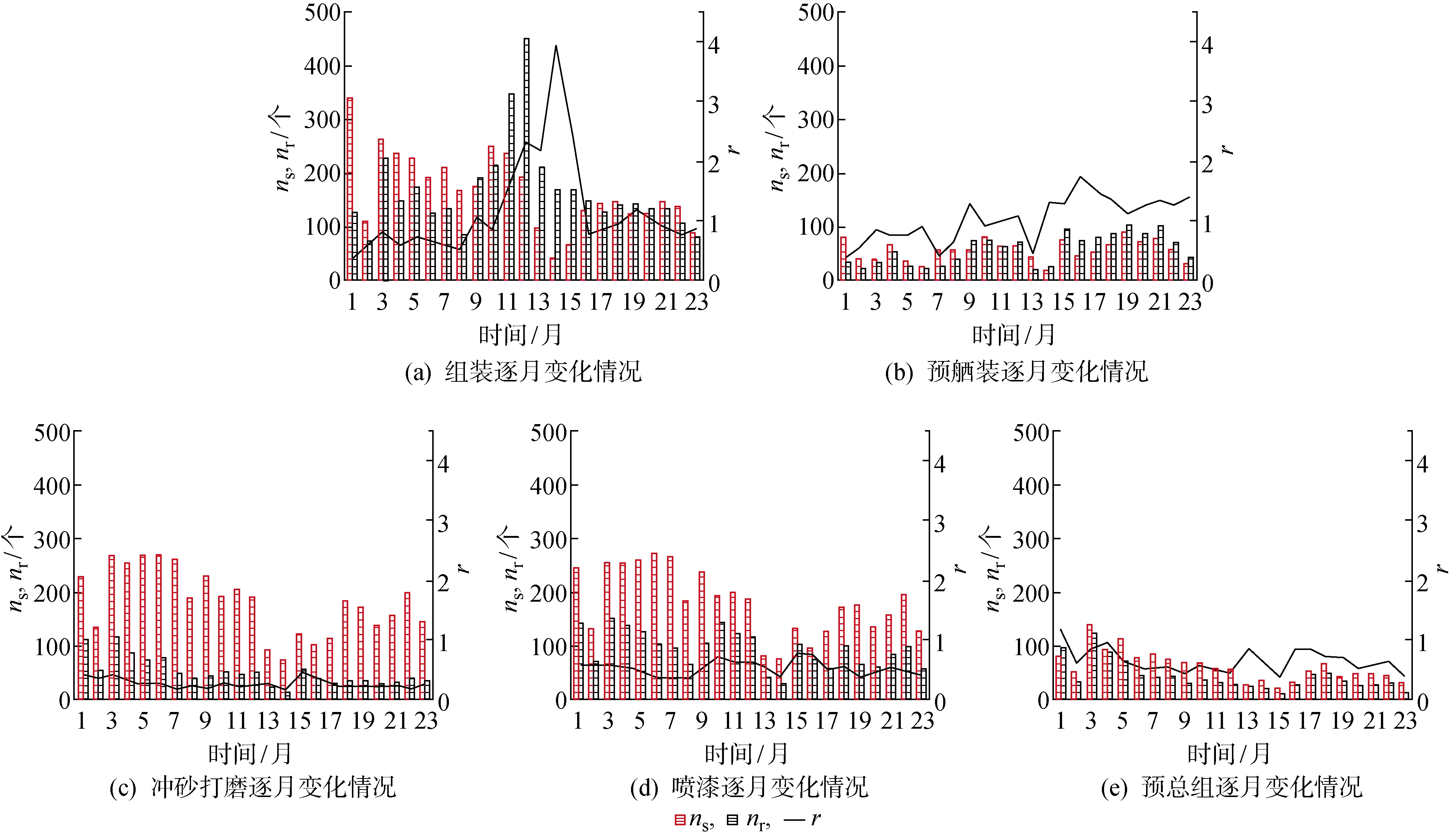
图8 第二类非生产性转运逐月情况监测Fig.8 Monthly monitoring results of Type II unproductive transfers
4 结语
针对S船厂中现有监测技术难以从分段时空数据中获取分段状态且难以监测两类非生产性转运的问题,本文在领域专家对船厂的部分分段时空数据进行分段状态标注的基础上,研究了转运过程中分段状态的时序关系和耗时特征.进而选用HMM作为时序概率推理工具,建立了4个HMM并使用有监督的方法学习其参数,通过Viterbi算法实现了分段状态识别,以区分堆场周转和耗时为特点的HMM4在测试集上准确率最高,达到了93.5%;以区分堆场周转、不区分耗时为特点的HMM2在分段状态识别和两类非生产性转运监测上都有较好的表现.将HMM2应用于船厂分段时空数据,识别了分段状态,实现了船厂两类非生产性转运的监测,监测结果显示目前船厂分段堆场中第一类非生产性转运率过高,组装的返工开工比较高并在个别月份突增,需要针对性优化.
猜你喜欢
建筑与预算(2022年2期)2022-03-08
智能建筑电气技术(2022年2期)2022-02-06
鸭绿江(2021年17期)2021-10-13
船舶标准化工程师(2020年1期)2020-06-12
人大建设(2019年7期)2019-11-18
运筹与管理(2019年1期)2019-02-15
制造技术与机床(2017年7期)2018-01-19
中国农业文摘-农业工程(2016年5期)2016-04-12
中国修船(2015年3期)2015-11-25
集装箱化(2014年12期)2015-01-06
