
基于SQL语义的流式数据总线行列级数据访问控制研究
2023-01-20 21:01禹熹方亚超洪丁节
计算机应用文摘·触控 2022年22期
禹熹 方亚超 洪丁节

关键词:流式数据总线;数据安全;访问控制;数据视图;SQL
中图法分类号:TP311 文献标识码:A
1技术背景
随着企业内数据的急剧膨胀和快速增长,如何在企业内不同应用间高效、安全的共享数据,避免数据孤岛效应,成为现代企业数字化转型的巨大挑战。一方面,数据的整合和共享是“让企业内数据用起来”的前提,只有实现“数据的平民化”,使企业内数据取数.用数便捷高效,才能打通企业内各业务线的七经八脉,让数据信息得以快速触达企业各处,为企业创造有效价值、预警不利风险;另一方面,数据是企业的核心资产,数据安全是每个企业都需要重视的课题,实现便捷的数据访问的同时,企业数据的安全应同样得到保障。数据的访问须满足“最小权限访问”原则,通过赋予数据访问者满足其业务需求的必要、最小的数据集,可极大地降低数据泄露和滥用的风险,从而保护企业的权益。
在企业内,通过构建基于OLAP关系型数据库的传统数据仓库或基于Hadoop生态的大数据平台,归集源自企业内外的数据,可以实现数据的集中,提供统一的数据访问服务。为保障数据的访问安全,在基于RDMBS的数据仓库中,可按数据访问需求创建数据访问视图(view)并授权用户访问。基于大数据Hadoop生态构建数据平台,可通过Ranger或Sentr等大数据体系安全访问控制组件,并结合数据私有视图的方式实现对大数据表的行列级访问控制,从而保障数据的访问安全。
传统的数据仓库和大数据平台可提供原始明细数据和汇总数据的访问,然而其提供的数据主要基于T-1日的历史数据,无法提供时效性更高的数据访问。基于高吞吐消息队列打造企业级实时的流水数据总线,将实时数据流水统一归集至数据总线,可以为企业内各系统提供各种实时数据流的数据订阅服务,然而目前却缺少有效的数据访问控制机制来满足数据安全性需求:(1)消息队列提供访问控制机制粒度较粗,通常基于单份数据整体,无法提供细粒度的行列级访问控制,如Apache Kafka通过ACL控制对数据topic的访问,但不支持对topic内数据内容的访问控制,阿里云Datahub服务基于阿里云通用访问控制RAM机制控制对Datahub资源的访问,但目前只实现了针对项目级(Project)、主题级(Topic)以及订阅级(Subscription)三级的控制,并没有更细粒度的数据范围控制能力;(2)为支持细粒度的访问控制,可采用新建应用二次转移的方式为下游系统按需筛选、过滤,提供对应的数据和字段,但这会导致数据冗余存储、应用开发成本高、部署结构以及上线流程复杂等问题。
本文提出了一种基于SQL语义在流式数据总线(Apache Kafka)上的行列级数据访问控制方式,解决企业实时数据总线的细粒度数据访问控制问题,如图1所示。
2设计思路
按照批量数据平台上的访问控制方式,通过在流式数据总线上建立类关系型数据库( RDBMS)的数据表(Table)、数据视图(View)能力,并对数据视图进行赋权,实现对流式实时数据总线上的数据的行列级访问控制。
2.1通过建立数据表(Table),赋予流式数据总线上元数据管理能力
流式数据总线中的消息中间件通常以主题(Topic)形式存储二进制数据,不具备数据内容、数据字段等元信息管理能力,这也导致其数据访问控制的粒度仅能到Topic级别。通过为流式总线上Topic中存储数据建立数据表,将数据字段名称、数据字段类型、数据字段的解析器(Deserializer)等涉及数据内容的信息保存下来,赋予流式数据总线对数据内容的元数据管理能力,从而支持对Topic中保存的二进制数据进一步解析、处理的能力。
2.2通过建立数据视图(View),实现数据行列级数据访问控制
不同业务系统对同一份数据的访问需求不尽相同,因此,需要根据实际需求制定不同的安全控制规则。在数据表上支持建立私有的数据视图,为下游数据应用系统按需创建不同的视图并赋予其访问权限。控制业务系统仅能访问业务所需的数据和字段,支持行级过滤、列级过滤,并通过UDF函数支持数据字段的处理,以支持脱敏、加密等数据字段的处理,满足了最小化数据访问原则,无须再进行定制化开发数据处理应用。
2.3扩展实现流式数据总线的SQL能力
在数据表和数据视图的基础上,支持对流式数据总线的进一步扩展,使其建立较完备的SQL访问能力,支持RDBMS常用SQL语义:(1)支持创建、修改或删除表/视图/用户(CREATE TABLE/VIEW/USER);(2)支持从数据表和视图上查询数据(SELECT…FROM TABLE/VIEW WHERE);(3)支持对用户赋权( GRANT/REVOKE SELECT/INSERT
.. TO/FROM USER);支持(4)查看表/视图/用户信息DESCRIBE TABLE/VIEW/USER等。
通过建立基于流式数据总线的SQL访问能力,不仅能满足日常运维查询需求,同时使流式数据总线像数据库一样简单易用。
2.4访问接口兼容
为不侵入流式数据总线的内部,和原系统耦合,对流式数据总线的访问接口外层进行封装并提供兼容于原数据的访问API接口,使外部应用仍可通过简单的形式订阅实时流水数据。业务系统透明化,实现即插即用,使业务系统开发和改造的影响性最小化,并在安全控制的限制下实现轻松接人。
2.5不顯著降低数据访问性能
对于流式数据总线而言,其重要的一项指标是实时数据访问的吞吐量和时效性。引入行列级的访问控制不可避免地带来性能开销,但应尽量减小对流式数据总线性能的影响。
3原型系统实现
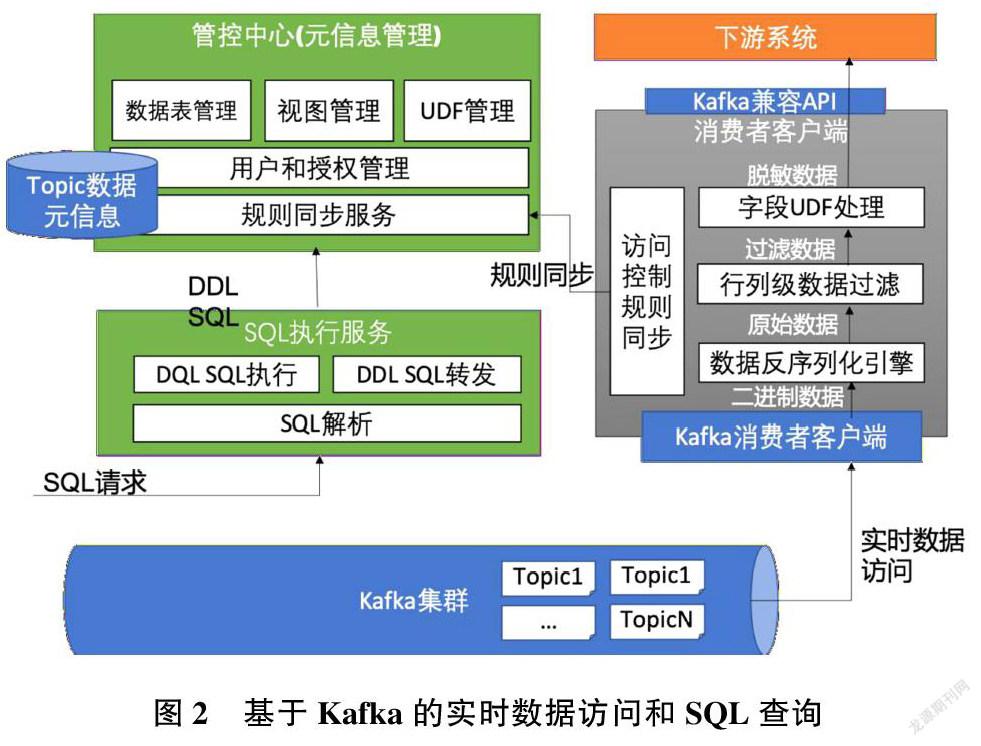
基于业界流行的高吞吐开源消息中间件Kafka,实现了本文提出的流式实时总线的行列级访问控制原型以及基于“一套公共的流式实时数据,多套私有视图”数据安全访问模式(图2)。本原型系统在Kafka上实现类RDBMS的数据表/视图模式的访问管理能力,建立基于SQL的行列级数据访问控制,并支持基础的SQL查询,配套的客户端包联通了业务系统和Kafka,显著提升了实时服务的安全性和运维便捷性。
原型系统主体包括SQL执行服务、管控中心、消费者客户端三大模块,每个模块涉及的关键功能点如下。
3.1 SQL执行服务
SQL执行服务对外提供SQL语义接口,支持以SQL语句作为输入进行数据表与视图的管理或数据查询。对于数据表、数据视图定义等DDL类型的SQL(如CREATE TABLE/VIEW),SQL执行服务将其转发给管控中心进行进一步处理,这是本文目标实现的安全控制规则的定义;对于Kafka数据的DQL查询请求(如SELECT FROM TABLE/VIEW),SQL执行服务将其请求解析后转化为对Kafka数据的读取并在SQL执行服务中处理SELECT语句,这是附带实现的类数据库查询Kafka中数据的功能。
3.2管控中心
管控中心负责数据表、数据视图、UDF函数等Topic元信息的管理,并保存在自有数据库中。通过管控中心创建应用私有视图并赋权给下游应用用户访问实现数据的权限控制。数据视图定义支持行级过滤/列级过滤/字段处理和UDF函数等功能。
3.3消费者客户端
消费者客户端封装原生的Kafka消费者客户端(Kafka-consumer),对外部应用提供兼容原Kafka-consumer API的接口,实现应用的快速接人和平顺迁移。Kafka中的数据仍然通过原生的Kafka-consumer客户端读取,避免和Kafak系统的深度耦合,简化系统的实现流程。同时,通过定期访问管控中心服务,实现数据视图所定义的访问控制规则的同步后,对从Kafka中读取的数据进行反序列化、行列级数据过滤以及脱敏、加密等操作后送给下游系统,实现业务对数据的最小访问。
4结束语
本文提出了一种基于SQL语义的流式数据总线行列级数据访问控制方式,主要解决企业中实时数据总线细粒度的数据访问控制问题,并基于业界流行的开源消息中间件Apahce Kafka,验证了系统实现的可行性。本文方式一方面实现了对企业中流式数据总线的行列级数据访问控制,无须冗余存储和数据处理应用,同时統一了流式数据总线上实时数据、数据仓库/大数据平台中批量数据的访问控制形式,均可通过广泛应用的SQL语言定义数据视图并赋权实现业务数据的最小访问。
作者简介:
禹熹(1986—),硕士,研究方向:大数据应用和开发。
猜你喜欢
电子制作(2019年14期)2019-08-20
当代贵州(2018年21期)2018-08-29
电子制作(2017年20期)2017-04-26
中国公共安全(2017年11期)2017-02-06
通信学报(2016年11期)2016-08-16
现代工业经济和信息化(2016年19期)2016-05-17
信息安全研究(2016年10期)2016-02-28
信息安全研究(2015年3期)2015-02-28
