
基于前视三维声呐的轨条砦识别方法
2023-01-27 05:45李宝奇任露露黄海宁
水下无人系统学报 2022年6期
李宝奇 ,任露露 ,陈 发 ,钱 斌 ,黄海宁
(1.中国科学院 声学研究所,北京,100086;2.苏州桑泰海洋仪器研发有限责任公司,江苏 苏州,215000;3.中国科学院大学,北京,100086;4.中国科学院 先进水下信息技术重点实验室,北京,100190)
0 引言
在现役破障装备中[1-2],微波、电磁感应、机器人和激光等技术得到了广泛的应用,但是对于水下轨条砦的探测和识别却一直缺乏有效手段[3-4]。
与二维成像声呐相比,三维声呐兼具水平和垂直窄波束,具有很强的抗混响能力,更适合浑浊水和浅水等高混响环境下的探测。三维声呐可获取三维立体数据信息,能够根据图像判断水下物体的形态和位置,而且通过三维立体空间旋转,可从多个视角对水下目标物进行观测,提高对水下复杂环境的判断能力[5]。三维成像声呐主要有机械扫描、多波束电子扫描和基于二维面阵扫描3 种形式。机械扫描的成像方式要想获得三维图像,需要利用单波束对探测场景进行全方位的扫描,成像速率过低;多波束电子扫描的方式通过相控阵技术,能够提高扫描速度,但声脉冲的单次收发不能获得三维图像;而基于二维面阵的三维成像声呐单次发射声脉冲,即可一次性获得场景中水平、垂直和距离3 个维度的信息,图像刷新率高,同时增加垂直维度的信息能在较大程度上提高无人系统的自主识别能力[6]。
经典的三维点云物体识别方法多是通过提取物体的特征点几何属性、形状属性、结构属性或者多种属性的组合等特征进行比对和匹配,从而完成物体的识别与分类。主要包括基于局部特征和基于全局特征的物体识别方法。基于局部特征的方法无需对处理数据进行分割,通过提取物体的关键点、边缘或者面片等局部特征并进行比对来完成物体的识别;基于全局特征的方法需要从背景中将目标物体分割出来,通过描述和比对三维物体形状中的全部或者最显著的几何特征来完成物体的识别。近年来,随着深度学习在图像分类、目标检测和图像分割中成功应用[6-7],基于深度学习技术的点云数据分析也成为了研究的热点。从数据输入角度考虑,当前基于深度学习的点云目标识别方法大体可以分为以下3 类: 多视图、体素结构和直接点云数据[8-11],其中多视图类方法可以直接利用二维目标检测方法,并且具有明显的速度优势。
在二维图像目标识别研究方面,为了提高模型的检测速度。Redmon 等[12]提出了一种无区域建议的目标检测模型,称为YOLO(you only look once)。YOLO 通过采用空间限制,大大提高了效率,能够达到实时的效果。但是YOLO 的检测精度不如Faster R-CNN(faster region-convolutional neural networks)[13]。针对YOLO 存在的不足,Liu 等[14]提出了单步检测 (single shot detector,SSD)模型,该模型通过融合6 个尺度的特征来提高目标检测的精度,但检测时间依然偏高。
为了兼顾SSD 对小目标的检测精度和速度,Howard 等[15]提出了轻量化的卷积神经网络(convolutional neural net works,CNN)MobileNet V1。MobileNet V1 用深度可分离卷积 (depthwise separable convolution,DSC)替换标准卷积来减少模型的参数和计算量,其在不影响目标检测精度的条件下能极大地提高SSD 的检测速度。Sandler 等[16]提出了MobileNet V1 的改进版本MobileNet V2。MobileNet V2 在深度可分离卷积的基础上引入了跨连接(shortcut connections)结构,并设计了新的特征提取模块IRB(inverted residual block)。新模块将原来的先“压缩”后“扩张”调整为先“扩张”后“压缩”,同时为了降低激活函数在高维信息向低维信息转换时的丢失和破坏,将最后卷积层的激活层由非线性更改为线性。Howard 等[17]在Mobile-Net V1 和MobileNet V2 的基础上提出了改进版本MobileNet V3 和特征提取模块IRB+,IRB+引入了SE(squeeze and excitation)注意力机制[18]。SE 首先对卷积得到的特征进行squeeze 操作,得到全局特征,然后对全局特征进行excitation 操作,得到不同特征的权重,最后乘以对应通道的特征得到最终特征。本质上,SE 组件是在特征维度上做选择,这可以更加关注信息量最大的特征,而抑制那些不重要的特征。IRB+在保持较低计算量的同时,具有更好的特征提取能力,但其捕获所有通道的依赖关系是低效且不必要的。Wang 等[19]提出了跨通道交互的极轻量注意力组件ECA(efficient channel attention)。ECA 去除了原来SE 组件中的全连接层,直接在全局平均池化(global average pooling,GAP)之后的特征上通过一个可以权重共享的一维卷积进行学习,其中一维卷积的卷积核尺寸表示局部跨通道交互的覆盖率。
借助前视三维声呐对水下轨条砦目标进行成像,并针对上述多视图类点云识别方法存在的问题,设计了一种基于SSD 的轨条砦目标识别方法PCSSD(point cloud SSD)。另外,提出了基于多尺度注意力机制的特征模块,进一步改善了PCSSD对轨条砦目标的检测性能。
1 基于前视三维声呐的目标检测方法
1.1 PCSSD
PCSSD 将三维点云数据进行前向投影,利用二维目标检测方法对投影图像中的轨条砦目标进行检测,并与目标深度信息结合实现三维点云中轨条砦目标的检测、识别和测量,识别方法原理如图1 所示。

图1 PCSSD 原理图Fig.1 Schematic diagram of PCSSD
PCSSD 的实现过程: 1)对原始波束域数据进行阈值和直通滤波处理,消除噪声和干扰,得到稀疏的点云数据;2)对稀疏的点云数据进行前向投影,同时依据点云的距离信息得到深度图;3)将深度灰度图伪彩化,并制作基于深度伪彩图的轨条砦目标识别数据集;4)利用轨条砦目标训练集对检测模型进行训练,得到训练充分的目标识别模型;5)利用训练充分的模型对深度伪彩图进行识别,得到目标的类型、概率和位置信息(平面xy);6)结合目标位置(平面xy)计算深度灰度图中目标的深度范围(z轴),联合目标类型、概率、xyz信息对稀疏点云轨条砦目标进行标注,从而实现三维点云目标的识别。
1.2 三维点云数据预处理
前视三维声呐接收到的原始回波信号是阵元数目和距离向采样的乘积。对每一帧接收到的声学回波数据进行波束形成处理,得到大小为B·B·Q的波束域数据,数据结构如图2 所示,其中B·B是2 个方向形成的波束数量,Q为距离切片数量,由成像距离和距离分辨率决定。

图2 波束域数据结构Fig.2 Data structure of beam domain
波束形成之后的数据代表的是空间中每一点的强度信息,这里的采样网格遍布空间中的每个点。根据三维声呐的成像场景,无论是对目标或者地形地貌等特征进行成像,成像目标都是三维空间中的有限个点,是绝对稀疏的,所以波束形成之后的数据有着非常大的冗余,需要将无用的噪声数据加以去除。
1.2.1 阈值滤波
原始阵元域数据进行波束形成之后得到波束域数据,鉴于目标在波束域数据的强度较大,随机噪声在波束域的强度较小,使用阈值滤波对波束域数据进行第1 步处理:

式中:Pixel为波束域数据;PixelT为阈值滤波后数据。进行阈值滤波之后,将强度小于一定阈值的点进行删除,数据量会大大减小,一定程度上可以展示成像场景,如图3 所示。
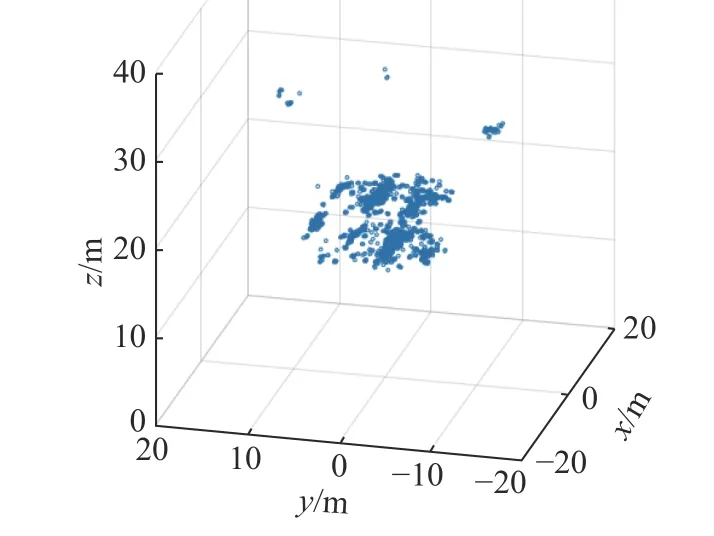
图3 阈值滤波数据Fig.3 Threshold filtered data
1.2.2 直通滤波
波束形成之后进行阈值滤波,仍然有一些不完善的地方,尤其是在空间中存在非常强的散射点的情况下,由于声呐设备有一定的动态范围,这些强的散射点会导致声呐对相对较弱的目标成像能力大大减弱。考虑到三维成像声呐的工作频率为上百千赫兹,穿透性很弱,进行直通滤波操作,在每个波束方向上保留强度最大的点:
式中:Pixelpt是每个波束方向强度最大点的强度,也就是强度信息矩阵;Indpt是直通滤波每个波束方向强度最大点的距离切片索引,也就是位置信息矩阵。直通滤波后的点云数据如图4 所示。

图4 直通滤波数据Fig.4 Pass-through filtered data
1.2.3 深度灰度图和伪彩图
在阈值滤波和直通滤波的作用上,得到稀疏点云Pixelpt和位置信息矩阵Indpt,文中利用Indpt生成深度灰度图
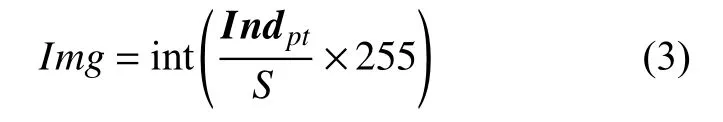
式中,Img为深度灰度图。进一步,可将深度灰度图转换为深度伪彩图,便于训练和目标检测,深度灰度图和深度伪彩图如图5 和图6 所示。

图5 深度灰度图Fig.5 Depth grayscale image

图6 深度伪彩图Fig.6 Pseudo color depth image
1.3 改进的特征提取模块和目标检测模型
鉴于ECA 的单尺度卷积核提取轨条砦目标的能力有限,提出了一个多尺度轻量化注意力组件MECA(multiscale efficient channel attention)。MECA通过多个尺度的特征融合来提高组件对输入特征通道的选择能力,利用该组件设计新的特征提取模块MEIRB(multiscale efficient inverted residual block),如图7 所示。MEIRB 模块采用了反残差网络结构,即对通道采取先“扩张”后“压缩”的策略,由扩张层、通道可选择组件和压缩层组成,其中扩张层负责输入特征通道扩张;通道可选择组件通过学习权重选择包含重要信息的通道;压缩层负责将特征通道压缩成与输入特征一致的数量。
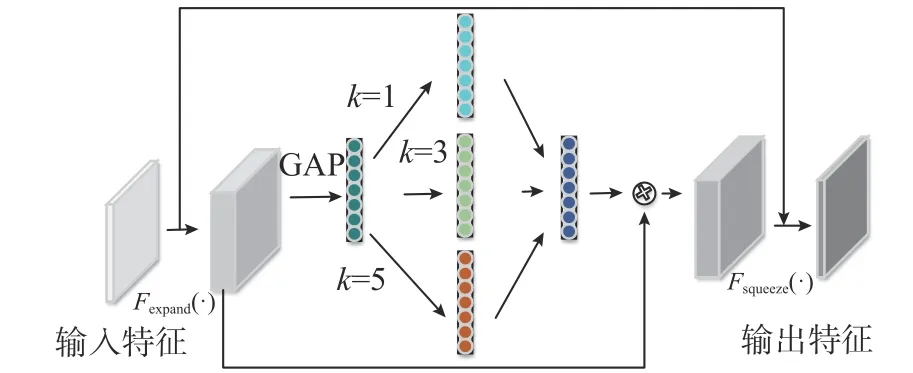
图7 MEIRB 模块Fig.7 MEIRB module
对于一个任意的输入特征D∈ΦH×H×M,其中H×H为输入特征的尺寸,M为输入特征的通道数。输入特征D进入MEIRB 模块的2 个支路网络: 下侧支路负责水下感兴趣小目标特征提取和选择;上侧支路保持D不变,并最后与上侧支路网络的输出特征相加。对于下侧支路网络,输入特征D首先经过扩张层,其数学表达式为

式中:D为原始输入特征;Dex为经过扩张层后的特征,扩张层的卷积核尺寸为1×1,卷积核的数量为输入特征通道的k倍,即k×M。
将输出特征Dex送入MECA 通道选择组件,其输出特征的数学表达式为


接着,对Dse进行通道压缩,数学表达式为

式中,D′为通道压缩后的特征。
通过上面的计算,最后可以得到MEIRB 模块的输出特征数学表达式为

利用MEIRB 模块在SSD-MV3 框架内替换IRB+模块,得到改进的目标检测模型SSD-MV3ME,结构如图8 所示,包括基础网络、附加特征提取网络、候选框生成和卷积预测4 个部分。SSDMV3ME 附加特征提取网络一共提取6 个尺度的特征,基础网络中的第14 层(conv14)和第19 层(conv19)作为附加特征提取网络的第1 特征层和第2 特征层,输入特征图尺寸为19×19 和10×10;Conv19_1、Conv19_2、Conv19_3 和Conv19_4 作为附加特征提取网络的第3~6 尺度特征层,输入特征图尺寸分别为5×5,3×3,2×2 和1×1。候选框生成部分从上述6 个尺度的特征层中提取数量和大小不同的候选框;卷积预测部分则是对候选框内目标的类型和位置进行判断。SSD-MV3ME 与目标检测模型SSD-MV3 的训练过程[18]相同。

图8 SSD-MV3ME 模型Fig.8 SSD-MV3ME model
2 实验分析
为了验证PCSSD 的有效性以及相关参数对其性能的影响,设计实验1,以轻量化目标检测模型SSD-MV3 为研究对象,比较分析不同注意力机制的性能差异;设计实验2,以注意力机制MECA 为研究对象,比较分析MECA 中多尺度卷积核的数量对PCSSD 性能的影响。
2.1 轨条砦目标检测数据集
为验证文中点云识别方法的有效性,在中国南海某浅水海域布放多个轨条砦目标,如图9 所示,并通过无人艇搭载前视三维声呐按不同距离和不同方位对轨条砦目标进行数据采集,每帧点云数据中最少存在1 个轨条砦目标。

图9 轨条砦布放Fig.9 Deployment of erect rail barricades
数据采集完毕后,利用1.2 节方法对采集到的轨条砦点云数据进行预处理,得到深度伪彩图,并建立一个轨条砦目标检测数据集GTZ,其中训练数据集包含444 幅图像,验证数据集包含140 幅图像,测试数据集包含88 幅图像,3 个数据集的比例约为7∶2∶1,组成如表1 所示。

表1 轨条砦目标检测数据集Table 1 Dataset of erect rail barricades for target detection
2.2 实验1
在PCSSD 框架内,实验1 比较分析了SSDMV3、SSD-MV3E 与文中SSD-MV3ME 在数据集GTZ 上的性能差异。SSD-MV3 的特征提取模块为IRB+,采用SE 注意力组件;SSD-MV3E 的特征提取模块为EIRB,采用ECA 注意力组件;SSDMV3ME 的特征提取模块为MEIRB,采用MECA注意力组件。分别记录检测模型在迭代1 000 次时对GTZ 测试数据集的平均精度(mean average precision,mAP)数值、参数大小和平均检测时间。
从表2 可以发现,SSD-MV3ME 的检测精度比SSD-MV3 和SSD-MV3E 分别高1.05%和0.55%;参数大小比SSD-MV3 减少2 482 kB,比SSD-MV3E增加8 kB;检测时间比SSD-MV3 和SSD-MV3E分别增加0.32 ms 和1.32 ms。综合考虑mAP、参数大小和检测时间,SSD-MV3ME 更适合三维点云轨条砦目标检测识别。

表2 目标检测模型性能比较Table 2 Performance comparsion of target detection models
为了进一步验证PCSSD 对轨条砦目标的检测识别效果,利用PCSSD 对轨条砦三维点云数据进行识别,识别结果如图10 所示。从图10 可以发现,PCSSD 能有效检测识别出三维点云数据中的轨条砦目标。

图10 轨条砦目标识别结果Fig.10 Detection results of erect rail barricades
2.3 实验2
实验2 比较了具有不同数量多尺度卷积核的MECA 对SSD-MV3ME 性能的影响。MECA 多尺度卷积核数量分别为1,2,3 和4,其中多尺度卷积核数量为1 时,SSD-MV3ME 为SSD-MV3E;多尺度卷积核数量为2 时,SSD-MV3ME 中MECA 卷积核尺寸为1×1 和3×3;多尺度卷积核数量为3 时,SSDMV3ME 中MECA 卷积核尺寸为1×1、3×3 和5×5;多尺度卷积核数量为4 时,SSD-MV3ME 中MECA卷积核尺寸为1×1,3×3,5×5 和7×7。分别记录检测模型在迭代1 000 次时对GTZ 测试数据集的mAP 数值、参数大小和平均检测时间,如表3 所示。

表3 MECA 不同数量多尺度卷积核对SSD-MV3ME 性能的影响Table 3 Effect of different accounts of MECA multiscale convolutions kernel on the performance of SSDMV3ME
从表3 可以发现,随MECA 多尺度卷积核数量的增加,SSD-MV3ME 检测精度逐渐增加,当多尺度卷积核数量等于4 时,SSD-MV3ME 的检测精度为88.26%,比卷积核数量等于3、2 和1 时的检测精度分别高0.13%、0.66%和0.68%。SSD-MV3ME的模型参数并没有随多尺度系数的增加有明显的变化,但检测时间随多尺度系数增加也不断增大,当多尺度卷积核数量等于4 时,SSD-MV3ME 的检测时间已经达到13.94 ms,比多尺度卷积核数量等于1 时的SSD-MV3ME 增加16.55%。显然,MECA多尺度卷积核数量的选取应兼顾检测精度和检测时间,文中MECA 多尺度卷积核个数为3,检测时间与SSD-MV3 基本相同,但检测精度有显著提升。
2.4 小结
实验从mAP、参数大小和运算时间3 个方面比较了目标检测算法SSD-MV3ME 与经典算法(SSD-MV3)和最新算法(SSD-MV3E)性能上的差异,进一步分析了MECA 多尺度卷积核数量的选取如何影响SSD-MV3ME 的性能。与SSD-MV3 相比,SSD-MV3ME 能更好地兼顾检测精度和检测时间,并能准确识别三维点云数据中的轨条砦目标。
3 结束语
基于前视三维声呐的轨条砦目标检测识别具有重要的理论研究和实际应用价值。文中提出了一种基于改进SSD 的前视三维声呐轨条砦目标检测方法PCSSD,并提出了轻量化小目标检测模块MEIRB 和目标检测网络SSD-MV3ME,理论分析和仿真实验证明了基于SSD-MV3ME 的PCSSD对轨条砦目标的有效性。
对于前视三维声呐的轨条砦目标检测任务,下一步的研究重点包括: 1)研究更加轻量化的目标检测模型;2)研究适合更复杂环境下的轨条砦目标识别算法。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
成都信息工程大学学报(2021年6期)2021-02-12
海洋信息技术与应用(2020年3期)2020-08-24
舰船科学技术(2020年3期)2020-04-22
小学科学(学生版)(2019年10期)2019-11-16
电子制作(2019年15期)2019-08-27
通信技术(2019年3期)2019-05-31
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
