
基于聚类的地铁通勤行为时空规律挖掘方法
2023-02-04 08:15李明珠赵习枝张福浩仇阿根
集成技术 2023年1期
李明珠 赵习枝 陈 才 张福浩 朱 军 仇阿根
1(西南交通大学地球科学与环境工程学院 成都 611756)
2(中国测绘科学研究院 北京 100830)
3(江苏海洋大学 连云港 222005)
1 引 言
自改革开放以来,我国大城市的城市范围迅速扩展,人口快速增长,使得职住空间组织模式不断演化。适度的职住分离布局,有助于提高城市效率、降低土地利用强度。但随着城市规模的不断扩张,职住分离导致通勤距离显著增加,不仅降低了居民幸福感,还引发了环境污染问题[1]。通过开展职住关系的研究,深化对中国城市发展规律的认识,对于解决职住空间结构不平衡及其衍生的交通环境住房等问题,具有重要理论和现实指导意义。
在宏观层面上,职住关系研究通常基于一定的范围尺度,如区(县)、街道、交通分析小区、千米尺度的格网等[2-3],利用出行调查获得的统计数据,通过研究区域内职住比[4]、通勤效率、通勤效率使用率[5]等评价因子,对职住平衡进行测算,或对职住空间关系的影响因素和产生机理进行探究。探究内容包括:(1)探究制度转型和城市空间结构变化对都市区就业空间分异、职住空间错位、就业可达性的影响[6];(2)基于建成环境因素,讨论土地利用的混合程度[7]、不同土地利用类型等对居民通勤的影响,探究交通设施和职住情况之间的关系[4]。在微观层面上,现有研究探究了职住关系的影响因素,主要以个人的社会经济属性为解释变量[8],讨论就业者收入水平、受教育情况、住房类型、工作性质等因素,对居民居住就业区位选择的影响[9-10]。此外,还通过分析居民通勤移动行为,反映职住空间结构特征和交互规律[11-12]。随着信息技术手段的快速发展,轨迹大数据为城市职住关系的研究提供了新的数据思路。相比于出行调查统计存在获取成本高和抽样不均匀等问题[13-14],移动轨迹大数据则具有样本量大、实时全面、成本较小的优点[4]。
近年来,基于移动轨迹数据或社会经济数据等多源数据,有研究分析了不同性质居民的通勤活动规律[15-16],探究了职住关系演变及其影响因素。通过对不同通勤群体之间通勤活动差异进行分析,有助于更深入地了解通勤群体对于职住空间变化的反应和受影响程度[17],从而为规划方案提供建议,使规划方案尽可能满足通勤群体多样性的通勤需求。目前,已有学者进行了通勤人群划分的研究,如付晓等[18]通过构建居民出行群体画像,分析不同出行人群的行为特征;万明等[19]采用潜在类别分析法对出行数据进行分析,将出行者划分为 3 类异质群体。基于交通卡数据的研究,则主要通过指定阈值和利用上下车时刻、出行次数等非连续性通勤特征,实现通勤个体分类[20-21],由于较少考虑通勤行为时间连续性,难以挖掘更多潜在的时间规律。此外,基于经验的阈值具有不稳定性,如会将阈值两端接近的个体划分为两类,而未考虑到阈值左右的个体具有较强的相似性。因此,利用合适的指标快速选择准确的阈值较为困难。
在大数据背景下,聚类算法可根据属性相似性,快速地将个体划分为不同的组,近年来,出现了利用聚类算法挖掘乘客出行特征的趋势[22-23]。与阈值法相比,聚类算法更好地考虑到参与聚类个体之间的相似性,从个体出发,将特性相似的个体聚为一类。如孙世超等[24]利用分层聚类方法,确定了墨西哥城工作丰富和住房丰富的区域。龙瀛等[25]将共享自行车和码头的相似站点逐层聚类为应用模式,提取出各站点的时间行为聚类特征。
针对现有研究在划分通勤人群时未充分利用时间特征,划分方法多采用经验阈值导致准确性不足的问题,本文进行了一系列研究。首先,基于上海地铁刷卡数据,通过构建职住识别模型,识别通勤群体及其就业居住地;然后,采用一种时间相似度计算方法,即在单向的一维时间空间中,将两个体通勤行程的时间重叠度作为衡量时间相似度的指标,提取通勤个体的时间相似度特征进行层次聚类,以研究不同通勤群体的时间规律性;最后,利用热点分析模型,对通勤群体空间规律进行分析,利用 ArcGIS 平台进行可视化表达,实现对上海通勤人群的通勤时空规律及职住空间组织特征的探究。
2 研究区域数据
本文选择上海市的整个区域范围作为研究区域,包括中心城区(黄浦、徐汇、长宁、静安、普陀、虹口、杨浦)、近郊区(闵行、宝山、嘉定)、远郊区(金山、松江、青浦、奉贤、崇明)和浦东新区 16 个行政区,截至 2020 年 11 月,总面积约1 237.85 km2,常住人口为 2 487.09 万人。
研究源数据为 2016 年 07 月 11 日—2016 年07 月 17 日上海市交通卡连续一周的地铁刷卡数据(交通卡刷卡数据包括地铁、公交、出租刷卡记录,地铁记录约占 66%,公交约占 32%,出租车约占 2%,由于公交无下车刷卡记录,本文选择地铁刷卡数据作为研究数据)。选取日期避开了法定节假日和重大活动日,避免异常情况对研究造成影响。地铁刷卡数据原始字段包括:交通卡号、刷卡日期、进站刷卡时间、出站刷卡时间、刷卡线路站点、刷卡交易金额、是否优惠。在研究时间段内,地铁总刷卡次数为 62 968 491次,工作日地铁日均刷卡约 994 万次。此外,研究数据还包括地铁站点和线路空间数据,共计 323 个地铁站点,站点数据字段包括站名、经度、纬度和线路号。
3 研究方法
3.1 职住识别模型
从单日通勤特征来看,工作日通勤活动有两个刷卡高峰:早高峰与晚高峰,对应上班与下班行为;从多日通勤特征来看,通勤属于满足日常生存需求的出行,工作日期间存在居住地和就业地之间的往返,一周之内满足一定的通勤天数。因此,综合考虑通勤人群稳定性的特点,即工作日高频出行时间段的稳定性、出发地和目的地的稳定性、工作日通勤行为的稳定性,结合已有研究,建立职住识别模型[26],从交通卡持卡人中识别出通勤人群和其职住地。
3.1.1 一日通勤出行行为识别步骤
一日通勤出行行为识别步骤为:(1)若持卡人当日首次地铁出行进站刷卡时间在 6:00—10:00 之间,那么将进站点设为居住站点R(调查统计表示:99.5% 居民每日首次出发点是居住地[27]);(2)若持卡人当日在 16:00 以后有地铁出行,那么将 16:00 以后的首次进站点设为W;(3)若站点W与(1)中地铁出行的出站点相同,且居住站点R与(2)中地铁出行的出站点相同,则称持卡人在该日具有通勤出行行为,居住站点为R,就业站点为W。如图 1 所示,如果持卡人在 6:00—10:00 内首次出行站点为居住站点R到就业站点W,16:00 后的首次出行站点为就业站点W到居住站点R,则认为持卡人当日实现由居住站点到就业站点的一次往返,具有通勤出行行为。
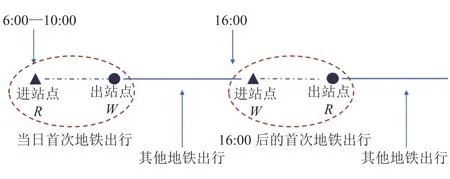
图1 一日地铁出行记录示意图Fig. 1 One-day subway trip record schematic diagram
可将通勤出行行为识别模型概括如公式(1)~(3)所示。

3.1.2 一周通勤个体与职住地识别步骤
一周通勤个体与职住地识别步骤为:(1)持卡人一周具有 3 次及以上的通勤出行行为,则认为该持卡人为通勤个体。(2)若通勤者有且仅有一个居住站点,就将该站点视为其居住地;若有 2 个及以上居住站点,则计算每个居住站点的概率;(3)选择概率最大且次数大于 1 的居住站点作为居住地,若存在两个这样的居住站点,且两居住站点距离≤1.4 km(步行合理接驳阈值范围为 600~800 m,是较适中且能容忍的最大程度[28-29]),则将两站点的中间点作为居住地;若两居住站点距离>1 km,则剔除该持卡人数据。
就业地识别方法同居住地识别方法。
3.2 时间规律挖掘
3.2.1 时间相似度计算方法
通勤是在时间和空间上的移动行为,为探究通勤群体[30]在早晚通勤期出行的时间规律,挖掘不同通勤需求并制定更合理的交通规划方案,常对通勤人群进行分类,将具有相似出行时间规律的人划分为一类。常见的分类方法为阈值法,例如,将第一次刷卡记录早于 6:00 或 6:30 的持卡人定义为早出型通勤人群[21],但该划分方法可能会将在阈值两端但接近的乘客划分为两类(如6:29 和 6:31 出行的通勤人群会被分为两类)。因此,参考 Murtagh 等[31]计算公交乘客时间相似度的度量方法,本文提出一种通勤行程时间相似性的度量方法:若两个行程在时间上有重叠部分(图 2(a)),则认为它们相似;若两个行程没有重叠部分(图 2(b)),且行程间隔大于较小行程,说明呈明显分离趋势,则认为它们相似度为 0;若行程间隔小于较小行程,那么仍然认为通勤行程时间具有相似性。

图2 行程时间关系Fig. 2 Time relationship of the trips
具体计算方法为:若行程时间存在重叠,则两行程的时间相似度为重叠时间长度与较长行程时间长度的比值;若不存在重叠但时间间隔小于较短行程时间长度,则两行程的时间相似度为时间间隔与较长行程时间长度的比值。为避免相似度出现负值,将以上两种情况的计算结果加 1 作为最终相似度值。

地铁刷卡数据会提供乘客的上车、下车刷卡信息,在通勤人群一天的刷卡记录中,分别提取早晚通勤高峰期的通勤出行记录,代入上式计算时间相似度。两类通勤人群的时间相似度即为早晚行程时间相似度之和。
3.2.2 时间聚类方法
层次聚类通常被用于时序数据的趋势分析[32-33],本文通过层次聚类对时间相似度进行聚类分析,以揭示通勤群体的层次结构。层次聚类的表现形式有“自上而下”的分裂和“自下而上”的凝聚层次聚类两种。凝聚层次聚类通过距离函数将数据集划分为多类,以降低簇数量,不断重复直至形成一个单独的类。
层次聚类主要的步骤在于确定不同层次最接近的簇类数,集群可通过距离判断数据点之间的相似性,对于簇间的距离度量有多种方式:最小值法(Single)、最大值法(Complete)、平均值法(Average)及最小方差法(Ward)。根据已有研究对上述方法的比较[34],当无离群值时,Ward 性能较好,故本文最终选择 Ward (即在并类时,选择使误差平方和增加最少的两类进行合并)。
对抽取的所有通勤人群进行聚类后,本文结合轮廓系数[35-36](Silhouette)进行最佳簇数的选择。其中,Silhouette 值越大,聚类效果越好。
3.3 空间规律挖掘
3.3.1 热点分析
热点分析(Getis-Ord Gi*)是一种利用 Getis-Ord Gi* 指数衡量观测数据之间空间依赖性的技术,可用于识别局部的空间自相关现象[37-38]。基于量测邻近观测值,可确定热点或冷点区域,具有统计显著性意义的热点不仅要求该位置自身要素具有较高值,而且周围要素也要具有较高值。本文以居住站点和就业站点的刷卡数作为属性值,利用 ArcGIS 热点分析工具,分析每类通勤人群职住热点和冷点区域,并进行可视化表达,用于识别每类通勤者就业和居住密度与整体情况有明显差异的位置。Getis-Ord Gi* 局部统计表达式如公式(5)所示。


4 职住空间关系与通勤时空特征分析
4.1 上海市总体职住特征分析
核密度估计是一种典型的分析点模式空间分布及集聚变化情况的分析方法。由于本文的分析对象为轨道交通乘客的职住区域,故本文基于识别的通勤人群的通勤数据,提取居住站点和就业站点,利用核密度估计方法,以分析上海通勤人群居住与就业总体的空间聚集特征并进行可视化分析。
如图 3 所示,居住高聚集区域主要沿内环线分布,并在内环以外沿轨道线呈放射状向外扩散分布,沿交通线呈点状离散分布或呈带状分布,且总体上浦西的居住密度高于浦东。

图3 居住核密度图Fig. 3 Kernel density of the residence
由图 4 可知,就业活动主要在内环以内,就业聚集点在内环内呈现东-西方向多核心分布,少量就业聚集地散落在内环以外,但范围不会延伸到外环以外,散落的高密度就业地是上海一些典型的产业园区,如东南方的张江高科技园区以及西边的漕河经济技术开发区。

图4 就业核密度图Fig. 4 Kernel density of the workplace
4.2 通勤活动的时空特征分析
通勤活动直接体现为轨道交通站点客流,站点客流是站点周边用地形态产生的出行需求体现,亦是站点设施使用情况的直接反映[39]。由于通勤人员依据站点进行通勤活动,故根据构建的职住识别模型识别出 562 268 位通勤人员。随机选取 5% 的通勤人员,将上述的时间聚类方法应用于抽取的通勤样本。通过计算时间相似度,可得到一个相似度矩阵实现层次聚类,表 1 为随机抽取 5 名通勤人计算出的时间相似度示例。由于应用背景是通勤人群的分类,本实验将聚类数范围初定为 3~7,计算每个簇数对应的 Silhouette指数,并与其他层次聚类进行比较,结果如表 2 所示。由表 2 可知,Ward 的结果整体较优。此外,当簇数为 5 时,Silhouette 指数较高,因此,为揭示通勤人群的层次结构,本实验将通勤人群分为 5 簇进行分析。

表1 时间相似度Table 1 Temporal similarity

表2 簇数与对应的 Silhouette 指数Table 2 Number of clusters and Silhouette values
4.2.1 时间特征分析
根据 5 个簇早晚通勤期(6:00—10:00、16:00—22:00)的刷卡量统计可知,各簇的上下班刷卡时间的分布存在一定的差异(图 5)。
cluster1 的上班刷卡时间集中在 7:00—8:30,下班刷卡时间集中在 17:00—19:00;cluster2 的上班刷卡时间分布在 8:00—9:00,下班刷卡时间集中在 17:30—19:00;cluster3 的上班刷卡时间明显较晚,出行时间最晚,主要集中在 8:30—10:00,下班刷卡时间集中在 16:00—17:30 和 18:30—22:00,存在加班晚归现象;cluster4 的上班刷卡时间比cluster1 推迟 0.5 h,分布在 7:30—8:30,下班刷卡时间与 cluster1 和 cluster2 相似,主要集中在17:30—19:00;cluster5 明显有较多的早出通勤者,上班刷卡时间集中在 6:00—7:30,下班时间也偏早,集中在 16:30—18:30。
利用时间相似的聚类划分,要求通勤人员不仅在刷卡时刻相似,还要在出行时段具有一定的相似性,综合上述的上下班刷卡时间分布,可将通勤人员汇总成 3 类(表 3):(1)上海大多数通勤人员属于常规型通勤者,占比为 68%,在常规型中的 3 类群体也具有一定规律,cluster1 和 cluster4上班出行时间更偏早(7:00—8:30),cluster2 上班出行时段偏晚(8:00—9:00);(2)晚出型通勤者占比为21%,下班有早归和加班晚归两种情况,由图 5(c)可知,19:30 以后下班的通勤人群占比约为 10%;(3)早出型通勤者占比最小,早出型通勤人员同时也是早归型通勤人员,占通勤人群的 11%。

表3 通勤出行时间规律Table 3 Time patterns of commuting

图5 早晚通勤高峰刷卡情况Fig. 5 Travel rate of morning-evening commuter rush hours
4.2.2 空间特征分析
在空间分布上,基于 ArcGIS 软件,得到 5个簇的就业点与居住点冷热空间分布图(图 6)。由图 6 可知:(1)就业热点聚集在城市中心区分布,5 类就业热点基本分布在中环内,集中在内环,结合就业核密度图可知,就业呈现向心聚集的单中心格局,但在中心显现就业的多核心结构。(2)各类的居住热点分布存在一定差异,但与居住核密度图具有一致性。具体地,cluster5和 cluster4 的居住热点离中心就业区较远,分布在远郊区的 9 号线末端;cluster3 的居住次热点分布在城南中心区,离中心就业区最近,使得其有条件能够晚出行上班,但需要支付更多的住房成本,结合时间特征分析,cluster3 可能是工作时间灵活的高收入群体和加班活动多的软件信息就业者;cluster1 和 cluster2 的居住热点主要集中在就业中心区的近郊与远郊区,cluster1 热点分布在 7 号、1 号和 3 号线末端及中心区北边的 11号线,cluster2 热点分布在 10 号、9 号和 5 号线并向西延伸至远郊区。综上所述,早出型离就业中心区更远,晚出型离就业中心区更近。(3)居住的冷点区基本聚集在黄浦江东边及中心区北边,该情况与浦东与浦西发展时期不同、浦南与浦北发展差异有关。
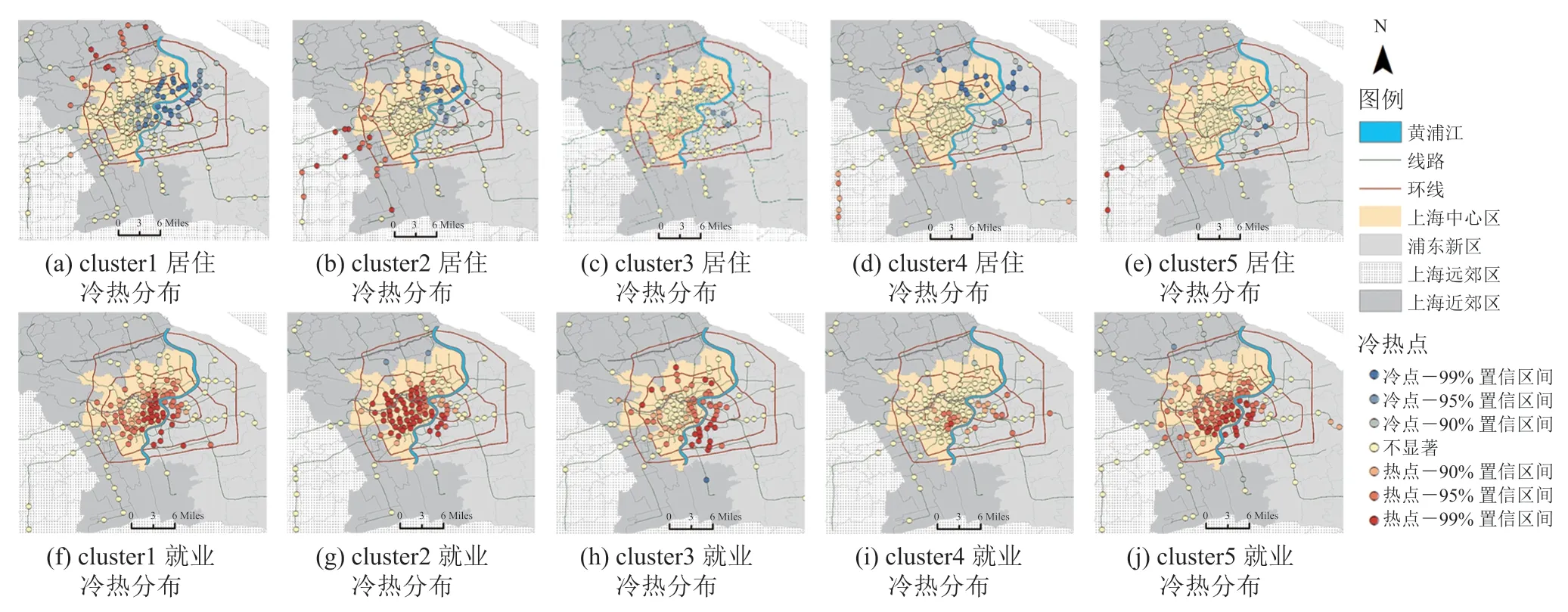
图6 居住与就业冷热空间分布Fig. 6 Spatial hot-cold distribution map of residence and workplace
5 结 语
目前,通勤群体的划分方法较少考虑通勤行程的时间连续性特征,针对该问题,本文进行了进一步的研究。本文基于上海市 288 个轨道交通站点和连续一周的交通卡地铁刷卡数据,构建了职住识别模型,用于识别通勤人群和职住地,定义了一种通勤行程时间相似度的度量方法,基于层次聚类的结果,对通勤人群进行细化分析,并结合热点分析模型,探究各类型通勤人群居住与就业的热点区域,挖掘上海市通勤人群潜在的时空规律及职住空间组织特征。
研究发现:(1)上海市的职住空间呈环状分布,就业热点区分布在城市中心区域,具有强就业吸引力;居住郊区化明显,居住热点区大多分布在市中心以外,与总体居住和就业的核密度图一致,即高密度居住点在内环外沿轨道线分布、高密度就业地在中心区聚集。(2)按照通勤出行时间规律,可将上海市通勤人员划分为常规型、晚出型和早出早归型,与居住热点分布相对应。总体上,越早出行的类型,其居住热点离就业中心区越远,在常规型中偏早出行的两个簇,其居住热点离就业中心区比偏晚的簇更远,从侧面验证了上海的单中心结构。此外,上海大多数的通勤方式属于常规型通勤,即在 7:00—9:00 进行上班通勤活动,17:00—19:00 进行下班通勤活动,占比达 68%。在常规型通勤中,上班通勤出行时间主要聚集在 7:00—8:30。(3)各类型的就业热点区差异不明显,大多集中在内环;但上海市中心黄浦江东西侧的居住热点分布不一致,居住热点分布在北部和西部的近郊和远郊区,居住冷点区主要分布在中心区的东部,并向浦东新区延伸。
尽管 Song 等[37]和 Goulet[38]试图利用 POI 赋予通勤人员属性,但因 POI 存在多尺度疏密不一的问题,难以构建有效的属性连接。由于缺少通勤人群的社会经济数据,故本文未能在不同群体差异和职住空间分布的成因方面进行深入探讨。此外,职住空间的形成是一个多因素作用和长期动态演化的过程,尹芹等[39]学者目前也仅对单一时间段内的居民职住变化进行研究。可根据居民的通勤模式对职住空间规划提供科学建议,在后续研究中,将多年的通勤数据和社会经济数据纳入研究,从更广的时间度揭示通勤人群层次结构和职住空间分布的变化规律及影响因素,有助于更好地了解不同通勤群体的需求。
猜你喜欢
加油站服务指南(2022年6期)2022-07-28
电子制作(2019年14期)2019-08-20
车迷(2019年10期)2019-06-24
国际呼吸杂志(2019年1期)2019-01-28
快乐语文(2018年7期)2018-05-25
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
小学生·新读写(2016年5期)2016-05-14
奥秘(2014年8期)2014-08-30
中国记者(2014年6期)2014-03-01
