
面向点云配准和地点识别的多头旋转注意力网络
2023-02-09 02:04施成浩陈谢沅澧郭瑞斌肖军浩卢惠民
控制理论与应用 2023年12期
施成浩,陈谢沅澧,郭瑞斌,肖军浩,戴 斌,卢惠民
(1.国防科技大学智能科学学院,湖南长沙 410073;2.国防科技创新研究院无人系统技术研究中心,北京 100091)
1 引言
点云配准和地点识别是计算机视觉、机器人和自动驾驶领域中的关键和热难点问题.地点识别旨在判断当前机器人或车辆是否位于已有地图表示的环境中,并大致估计其在地图中的位置.点云配准则旨在利用点云信息进一步估计部分重叠点云之间的精确位姿变换关系.由于点云配准和地点识别在研究上的相关性,研究者很自然地会去思考如何在一个统一的框架下实现点云配准和地点识别.虽然已有大量基于词袋的方法[1-3],通过提取局部特征并将其组合为词袋模型进行地点识别,并随后通过局部特征匹配进行位姿估计.但受限于当前点云特征提取方法的困难,该类方法难以平衡地点识别所需的全局描述能力和点云配准所需的局部描述能力.也有研究尝试用深度学习的方法在生成全局特征的同时估计1-DOF(degree of freedon)[4]或3-DOF[5]的位姿,但这对于实际应用显然是不够的,要实现定位通常还需要其他传感器的辅助.目前仍鲜有方法能够在实现高效地点识别的同时输出准确的6-DOF位姿.
针对上述问题,本文提出一种新颖的多头网络在统一框架下实现高效的地点识别和精确的点云6-DOF配准.该网络首先在点云中提取特征显著的稀疏特征点,随后,分别在两个头中实现地点识别和点云配准.稠密点匹配头采用由粗至精的方式[6-7],首先建立特征点之间的匹配,随后根据邻域一致性,将特征点之间的匹配拓展为其邻域的匹配关系,从而寻找更稠密和可靠的点匹配.全局描述头则将主干网络提取的特征点压缩为一个全局描述子用于地点识别.与地点识别只需要大致描述整体环境特征不同,点云配准对特征点的落点和显著性的要求更高.因此,本文的创新点之一是采用提出的特征投票层学习每个特征点到其附近几何显著区域的偏移量.如图1所示,与基准方法相比,本文方法提取的特征点更容易落在几何显著区域且更紧凑,据此找到的稠密点匹配也更可靠.此外,可以注意到稠密点匹配头以及全局描述头的最终表现都依赖于主干网络提取的特征点的特征表达能力.因此,本文的另一个创新是采用了新颖的注意力机制3D-RoFormer[8]来提高特征点对邻域和几何结构信息的特征表达能力.3D-RoFormer 基于注意力机制(Transformer)设计,通过将三维位置信息编码为旋转矩阵,显式地将相对位置关系编码在点特征中.其他尝试编码相对位置信息的方法存储复杂度高[9]或计算复杂度高[7],与之不同,3D-RoFormer在维持轻量和快速的同时,还具备良好的平移不变性.

图1 本文方法与基准方法在点云匹配上的对比示例Fig.1 Comparison example of point matching between our and baseline method

图2 网络结构示意图Fig.2 The overview of our network
为了充分评估本文方法的点云配准和地点识别性能,本文在多个室外数据集上进行了实验.实验结果表明,本文方法在位姿估计和地点识别方面的表现较当前先进方法都更优或相当,且具有很强的泛化能力.综上,本文的主要贡献是:
1)提出一种新颖的多头网络,在统一的框架下实现快速的地点识别和精确的6-DOF位姿估计;
2)提出一种新颖的注意力机制3D-RoFormer,能够以轻量、快速的方式编码相对位置信息,具备强大的上下文和几何特征描述能力;
3)在多个室外数据集上对本文方法进行了测试,结果表明本文方法较现有的方法在点云配准和地点识别均表现出了卓越的性能以及泛化能力.
2 相关工作
本节将介绍点云配准和地点识别相关的先进工作.
2.1 点云配准
现有的点云配准方法可以大致分为两类: 无匹配的方法和基于匹配的方法.
无匹配的方法将配准问题转化为一个回归问题.早期的工作如Aoki等[10]提出的PointNetLK,首先,使用PointNet[10]提取点云的特征,然后,利用回归方法从特征中估计位姿.Huang等[11]通过最小化特征-度量投影误差来解决配准问题.这类方法的挑战在于构建可靠的回归模型,而且配准的准确性也得不到保证.
基于匹配的方法首先提取两个点云之间的匹配关系,然后使用求解器计算相对位姿.提取正确的匹配关系是这类方法最具挑战性的部分.基于匹配关系的经典方法是迭代最邻近点法(iterative closest point,ICP)[12]及其众多变体[13-14].他们使用近邻搜索或其他启发式方法迭代地寻找匹配关系,因此高度依赖良好的初始估计,否则极易陷入局部最优.与上述类ICP的方法不同,基于特征点的方法通过均匀采样[15-16]或特征点检测[17-19]来寻找稀疏点上的匹配关系.与上述在均匀采样点上建立匹配的方法不同,基于特征点的方法根据人工设计的显著性[20]或学习到的显著性[17-19]提取特征点,以保证更高的特征点重复检测率.除了显著性,特征点是否位于重叠区域也是影响其重复检测率的关键因素.为了处理低重叠度下的配准问题,Huang等[21]提出的PREDATOR以及Zhu等[9]提出的NgeNet提取了不仅显著且趋向于落在重叠区域的特征点.
近来一种由粗至精的匹配方法[6-7,22]受到广泛关注.该方法首先找到可靠的稀疏点块匹配,然后将点块匹配拓展为稠密邻域点的匹配.受益于高效的主干网络,这些方法能够获得大型点云的稠密描述子,然后在由粗到细的机制下,限制了匹配的搜索空间,提高了匹配的可靠性.稀疏点块匹配关系的质量对于这种由粗至精的方法很重要.为了提高匹配精度,CoFi-Net[6]采用了注意力机制[23]作为上下文信息编码器来生成更鲁棒的点描述子.GeoTransformer[9]通过在注意力机制中注入点对的距离和三元组的角度信息来对增强对位置信息敏感,NgeNet[7]也在其工作中尝试用点对特征[24]引入几何信息.虽然得到了不错的结果,但GeoTransformer对点对距离和三元组角度的计算和存储,也使其存储复杂度达到了O(n2).而NgeNet则由于需要估计法向量,计算量巨大.此外,现有的工作忽略了初始稀疏特征点的分布.它们仅使用简单的均匀采样方式采样.这种方式可能会将一个物体分成几个点块进行匹配.这是不符合直觉的,且点块间的重叠率也通常较低以至于影响点块匹配和稠密点匹配拓展的结果.
与现有方法不同,本文方法采用了最新的3D-Ro-Former[8]以轻量和快速的方式利用了点云的上下文和几何信息取得更可靠的匹配关系.同时,本文方法利用特征投票层使得特征点向其附近的特征显著区域产生偏移,得到更显著也更紧凑的特征点.
2.2 地点识别
地点识别算法通过当前传感器信息与已有地图之间对比,判断当前机器人或车辆所在位置是否位于地图中,以及大致所处的位置.基于激光雷达的地点识别方法有局部特征法和全局特征法.局部特征法通常提取点云的局部特征[20,25-26],然后通过词袋模型将局部特征组织起来用于地点识别[1-3,27].全局描述法,如Kim等[28]提出的Scan Context通过将点云表示为鸟瞰图并对不同分割空间进行编码构建全局描述子;Wang等[29]通过LoG-Gabor阈值滤波的方式提取描述子并用汉明距离描述相似度.上述方法需要额外的函数以评估地点的相似度.这在地图逐渐增大后,会显著降低计算效率.
最近Chen等[4]提出基于深度学习的方法Overlap-Net,通过估计一组点云的重叠度和相对偏航角用于地点识别和位姿的初值估计.Ma等[30]结合OverlapNet和Transformer[23]提出一种旋转不变的全局描述子.Uy和Lee等[31]提出PointNetVLAD结合PointNet[32]和NetVLAD[33],首先,提取局部特征随后将其聚合为全局描述子.与直接工作在原始点云上的方法不同,Zhou等[34]将点云转换成正态分布变换(normal distribution transform,NDT)并结合Transformer生成描述子.Komorowski[35]通过将点云体素化后,采用稀疏卷积生成描述子.Cattaneo等[36]提出LCDNet,基于PVRCNN[37]将高维体素特征与鸟瞰图特征结合用于地点识别.最近还有方法基于语义拓扑图[38-39],首先,提取语义信息并构建语义实例作为语义图的节点,随后,通过图匹配实现地点识别.然而,此类方法在精确的图匹配上仍然存在问题.
与本文最相关的工作是LCDNet[36].和本文方法一样,LCDNet也能够在统一框架下实现地点识别和6-DOF点云配准.与LCDNet基于稀疏卷积的框架不同,本文方法采用了新设计的基于原始点云的卷积框架,能够更灵活地选择特征点并聚合特征.本文方法还采用了新颖的由粗至精的匹配方式,直接在原始点云上构建稠密点匹配关系,避免了在下采样的稀疏点上构建匹配而导致的配准精度下降问题.
3 基于旋转注意力机制的多头网络
3.1 3D-RoFormer网络
利用旋转矩阵的性质,可以推导式(4)得
其中
基于上述优势,本文在特征点检测模块和稠密点匹配头中均使用了3D-RoFormer以更好地学习特征,并在3D-RoFormer中交错使用l层的旋转自注意力和交叉注意力来增强最终输出特征
3.2 特征点检测模块
特征点检测模块旨在提取服务于后续稠密点匹配头和全局描述头的可靠的稀疏特征点.网络使用KPEncoder[40]作为主干网络,将点云逐级地降采样为均匀分布的稀疏特征点并编码相关特征该特征点均匀分布在点云中,具备足够的信息来描述整体点云的特征,因此,网络直接使用该特征点作为全局描述头的输入.然而,该特征点用于点云配准还是不够的,原因在于: 第一,由于KPEncoder只在单个点云上进行卷积,特征点缺乏两个点云之间的关联信息,如重叠区域等,无法更好地为点云配准任务服务;第二,特征点仅通过均匀采样的方式获得,无法满足点云配准任务对特征点重复检测率和显著性的要求.
3.3 稠密点匹配头
本文选择Nc个最大通道对应的特征点对作为匹配,即
上述特征点匹配,随后将用于稠密点的精匹配.
在精匹配中,本文使用一种点到节点的策略[18]对每个特征点构造局部点块Gi.具体而言,通过下式将点云中的每个点分配给最近的特征点:
基于邻域一致性,一对匹配的特征点对应的点块也应是匹配的,因此可以进一步从中寻找出更多的点匹配.
其中m和n表示Zi中最大值通道的索引.每个点要么与目标点块中的点相匹配,要么没有匹配点(即附加行或列通道值最大).由于点云的稀疏性质,实际上不存在严格的一对一点匹配关系,因此,本文保留双向的匹配结果,即同时保留行最大值与列最大值的通道.这有利于找到更多的匹配关系而不过大地影响匹配的准确率以实现更精确的位姿估计.最终的点匹配关系是所有匹配点块中找到的点匹配的组合,即
3.4 全局描述头
在全局描述头中,本文首先采用NetVLAD[33]将特征点特征压缩为单个描述子X ∈RG.参照文献[36],本文使用上下文门控模块(context gating module),基于自注意力机制重新评估特征X各通道的权重,进一步将其增强得到最终的全局描述子V ∈RG,即
其中:σ为sigmoid激活函数,⊗为元素级乘法,W和b分别是可学习的权重和偏移量.
本文的全局描述头设计轻便,但依然取得了较现有先进方法更优的性能.这得益于网络整体的色痕迹合理,以及采用的双阶段训练方法,这将在第3.5节具体介绍.
3.5 损失函数及训练
本文的损失函数由稠密点匹配头的损失和全局描述头的损失两部分组成.其中: 稠密点匹配头的损失由3部分组成L=Ls+Lc+Lf,其中:Ls是特征点检测损失,Lc是粗匹配损失,Lf是精匹配损失.全局描述头的损失Lt采用三元损失(triplet loss).
特征点检测损失:特征点检测损失Ls=Ls1+Ls2由两个部分组成.第1部分Ls1旨在指导特征点落在显著区域,而第2部分Ls2旨在使特征点尽可能接近实际测量点,而不会落在无意义的虚空中.具体而言,对于Ls1,本文没有明确定义区域的显著性,而是使用chamfer损失来最小化真实匹配的特征点之间的距离
在Ls1的监督下,特征点会倾向于移动到最近的“显著”区域以最小化特征点对之间的距离.对于Ls2,本文使用另一个chamfer损失来最小化特征点与其最近真实测量点之间的距离,即
精匹配损失:为学习一个具有区分性的软分配矩阵以支持本文的稠密点匹配方法,本文采用gap损失函数[41]对软分配矩阵Zi进行监督.
全局描述损失:本文参照文献[30]采用三元损失作为全局描述损失.本文定义对任意一个查询帧,与其重叠率达到30%以上的为正样本,否则为负样本.对每个三元组,本文使用一个查询帧Vq,Np个正样本{Vp}和Nn个负样本{Vn}来计算三元损失,即
双阶段训练: 本文没有简单地将上述4个损失函数直接相加进行训练,而采用双阶段的训练方式,即首先仅对稠密点匹配头进行训练,随后将主干网络的参数固定而只训练全局描述头.这样做的考虑是: 第一,好的特征点提取方法会自然地覆盖点云中具备信息量大的区域,因此直接从中学习全局特征是可行的;第二,通过将全局描述头分开训练,可以选择更大的训练样本数量加速网络收敛速度并避免网络在学习过程中灾难性遗忘特征点提取的“知识”.
本文用4个NVIDIA RTX 3090 GPU训练网络,实际测试时则只使用1个GPU.网络的训练使用Adam优化器[42],学习率为10-4,每4个训练周期按0.05的速率指数衰减.稠密点匹配头使用的训练样本批大小为1,全局描述头使用的训练样本批大小为24,每批数据包含1帧参考点云,Np=6帧正样本和Nn=6帧负样本.本文还采用了与文献[21]相同的数据加强技术增强网络的鲁棒性.
4 实验验证
本文共开展了3组实验来测试本文方法的性能,包括: 连续点云配准性能、闭环处点云配准性能和地点识别性能.本文在实验中采用Patchwork[43]对输入网络的点云进行了地面滤除以达到最佳性能.下面将对各实验的设置和结果进行介绍.在此之前首先介绍本文使用的数据集,包括KITTI-Odometry[44],KITTI-360[45],Apollo-SouthBay[46]和Mulran[47].这些数据集提供了在不同环境用不同激光雷达采集的点云数据和相应的真值位姿.KITTI-Odometry和KITTI-360都使用Velodyne HDL64 LiDAR在德国采集数据,两个数据集使用相似的传感器设置,但采集时间和环境不同.Apollo-SouthBay数据集也使用了Velodyne HDL-64 LiDAR,但传感器设置与KITTI数据集不同,采集位置在美国城市.Mulran数据集则使用OS1-64 LiDAR在韩国采集.4 个数据集的传感器、环境和平台设置有所不同,从而使得本文能够更全面地测试各种方法的泛化能力.
4.1 连续点云配准
数据集: 本文参照文献[7,21]将KITTI-Odometry数据集分为3个子集: 序列00-05 用于训练,序列06-07用于验证,序列08-10用于测试.为了评估模型的泛化能力,本文直接使用KITTI数据集上训练的模型在其他数据集上测试.与文献[7,9,21]一致,本文将距离最远为10 m的点云对视为一个样本、采样得到1358个训练样本,180个验证样本和14577个测试样本.
评价指标:本文参照文献[7]使用3个指标来评估连续点云配准性能:1)相对平移误差(relative translation error,RTE),即估计平移向量与真实平移向量之间的欧几里得距离;2)相对旋转误差(relative rotation error,RRE),即估计旋转矩阵和真实旋转矩阵之间的测地距离;3)配准召回率(registration recall,RR),即相对旋转误差和相对平移误差都低于阈值(即5°和2 m)的点云对的比例.
配准结果:连续点云配准实验的基准方法为当前先进的基于随机采样一致(random sample consensus,RANSAC)的方法: Predator[21],CofiNet[6],NgeNet[9]和GeoTransformer[7],以及当前先进的无RANSAC方法: HRegNet[22].Qin等[7]提出一种专门为由粗至精方法设计的求解器LGR(local-to-global registration).它计算每个点块内的匹配进行加权奇异值分解(singular value decomposition,SVD)的位姿,并选择其中使得内点最多的位姿作为最终估计,从而将迭代次数限制在|M|内,大幅减少了计算时间.因此本文还展示了GeoTransformer(fast)和本文方法(fast)使用LGR的结果.如表1所示,本文在配准精度上显著优于其他基准方法.从实验结果还可以发现,本文方法使用LGR在平移估计上达到最佳,使用RANSAC在旋转估计上达到最佳.

表1 连续点云配准性能对比Table 1 The comparison of continuous point cloud registration performance
4.2 闭环处点云配准
数据集: 为进一步验证本文方法的配准性能,本文在闭环处开展点云配准性能的测试.区别于连续点云,闭环指平台经过长时间运行后回到之前来过的位置.闭环处的点云配准,观测角度差更大、观测位置区别更多样、环境动态变化更大,因此挑战也更大.本文参照文献[36]将KITTI-Odometry 数据集分为3个子集:序列03-07,09用于训练,序列02用于验证,序列00和08用于测试.这样设置是因为00和08序列分别是数据集中包含闭环最多以及逆向闭环最多的序列,因此能够更充分地测试方法在闭环处的配准性能和对观测角度的鲁棒性.本文将真值位姿距离小于4 m,时间间隔在50 s 以上的点云作为闭环样本.
评价指标:同文献[36]一致,本文使用3个指标来评估闭环处的配准性能:1)相对偏航角误差(relative yaw error,RYE),即估计偏航角与真实偏航角的平均误差;2)相对平移误差(RTE);3)配准召回率(RR)与第4.1节保持一致.
配准结果:该实验的基准方法为先进的传统配准方法: ICP[12],基于快速点特征直方图(fast point feature histogram,FPFH)特征[48]的RANSAC[49]以及当前先进的深度学习方法:RPMNet[50],FCGF[51],DGR[52],LCDNet[36].本文还展示了先进的能够输出偏航角的地点识别方法的结果:Scan Context[28],LiDAR-Iris[29],OverlapNet[4].由于这些方法无法输出平移估计,因此,它们的平移误差并没有展示.如表2所示,本文方法在00和08序列都实现了最优的性能.在实现100%召回率的情况下,大幅地将先进方法的平移估计精度在00序列上提升约64%,在08序列上提升约47%.值得注意的是,本文方法的最优结果是使用LGR求解器得到的.这意味着本文方法可以在实现最优性能的同时保证极高的运行效率.

表2 闭环处的配准性能对比Table 2 The comparison of registration performance at loop
4.3 地点识别
数据集: 本文参照文献[30]将KITTI-Odometry数据集分为3个子集: 序列03-10用于训练,序列02用于验证,序列00用于测试.在该实验中,本文将重叠率大于30%的点云对作为正样本,小于30%的为负样本.测试时,本文滤除了查询点云前后50帧点云,以确保测试样本不包含相近的点云对,增加测试集难度.
评价指标:与文献[30]一致,本文采用4个指标评估地点识别的性能:1)曲线下面积(AUC,area under curve),即受试者工作特征曲线(ROC,receiver operating characteristic curve)与坐标轴所围成的面积;2)最大F1值(F1max),即在不同阈值取值下F1值的最大值,其中3)Recall@1,即只取相似度最高的待选帧时的召回率;4)Recall@1%,即当选择相似度最高的前1%个待选帧时的召回率.
地点识别结果:该实验的基准方法为当前先进的地点识别方法: Histogram[53],Scan Context[28],LiDAR-Iris[29],OverlapNet[4],PointNetVLAD[31],NDTTransformer-P[34],MinkLoc3D[35],OverlapTranformer[30].所有方法都采用其默认设置.如表3所示,本文方法在AUC和F1max指标上较当前先进方法有明显的优势,并在Recall@1和Recall@1%与先进方法相当.值得注意的是,全局描述头并没有采用复杂的结构,其结果依然达到了前沿水平.这得益于本文在特征点提取和描述上的优异性能.

表3 地点识别性能对比Table 3 The comparison of loop closure detection performance
4.4 消融实验与运行时间分析
本文在KITTI和Apollo数据集上对本文方法在点云配准上的性能进行了消融实验,以更好地了解本文方法每个模块的有效性.表4总结了各模板对点云配准的影响的实验结果,其中: Vote表示投票层为特征点检测模块的核心结构;RoFormer表示旋转注意力机制,消融3D-RoFormer表示网络采用原始注意力机制;gap loss为本文针对精匹配使用的损失函数,消融gap loss表示网络使用负对数似然损失函数训练.将使用以上全部3个模块的方法为基准,“+”表示数值上较基准方法变大,“-”表示数值上较基准方法变小.可以看出,本文方法的所有模块都可以单独提高点云配准的效果.将所有模块组合使得本文方法表现达到最佳.

表4 网络各模块对点云配准的影响实验Table 4 Influence of individual module on point cloud registration
表5总结了各模板对地点识别的影响的实验结果.为了保证地点识别模块的实时性,本文没有在全局描述头中采用复杂的结构设计,因此本文研究了主干网络对地点识别的间接影响.如表5所示,3D-RoFormer虽然没有直接参与全局描述子的计算,但对性能的提升有一定帮助.可能的原因是3D-RoFormer能够更好地帮助网络学习特征的表达.消融投票层可以进一步提高地点识别的表现,然而,考虑到投票层对配准表现的巨大提升,本文保留了这一设计.
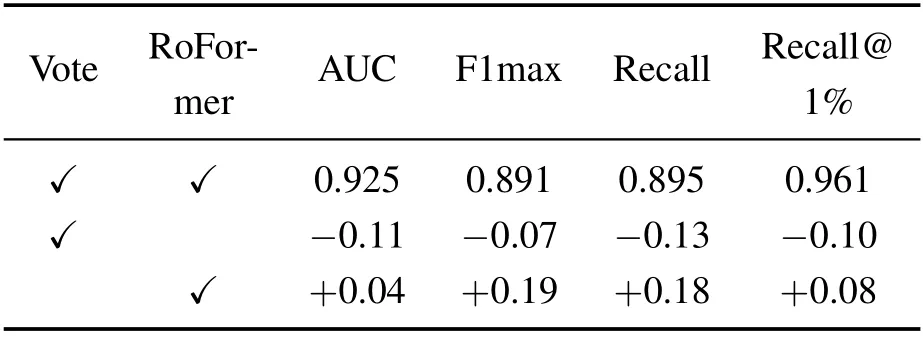
表5 网络各模块对地点识别的影响实验Table 5 Influence of individual module on loop closure detection
本文在表6中对3D-RoFormer在不同输入节点情况下的运行时间和内存占用进行评估,并与几种典型的transformer 进行对比,包括vanilla transformer[23],绝对位置编码(absolute position embedding,APE)transformer[41]以及GeoTransformer[7].实验表明本文方法在运行时间和内存占用上能够与vanilla transformer一样随着输入节点变化而线性变化,并显著低于Geo-Transformer.
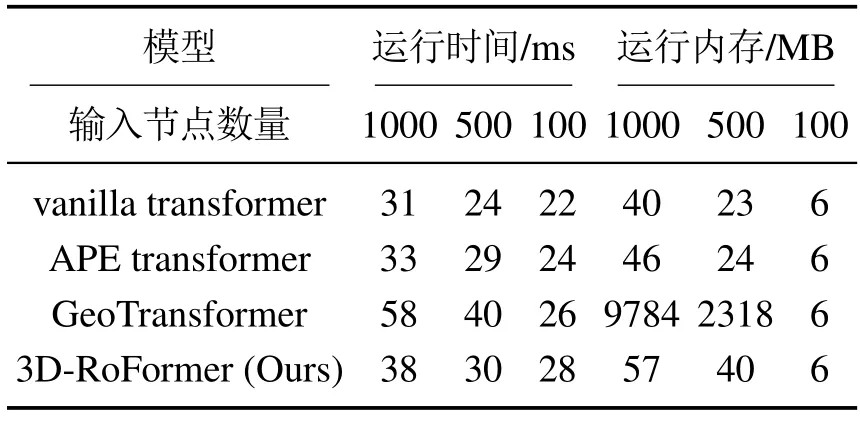
表6 运行时间和存储对比Table 6 The comparison of runtime and storage
5 总结
本文提出了一种基于旋转注意力机制的多头网络用于在统一框架下同时解决点云配准和地点识别问题.本文应用了一种新颖的注意力机制3D-RoFormer设计主干网络,以快速轻量的方式学习聚合点云的上下文和几何结构信息,并提取显著而紧凑的特征点服务后续的点云配准和地点识别.网络在全局描述头中将特征点压缩为全局描述子用于高效的地点识别,并在稠密点匹配头中利用由粗至精的策略提取稠密点匹配进行高精度的点云配准.本文在多个数据集上评估了方法在连续帧的点云配准、闭环处的点云配准以及地点识别多方面的能力.实验充分地表明本文方法在解决点云配准和地点识别问题上的表现较当前先进方法均更优或相当,并具有强大的泛化能力.未来,我们将继续探索本文方法在解决全局定位问题上的潜力.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
金桥(2018年4期)2018-09-26
黑龙江电力(2017年1期)2017-05-17
环境科技(2016年5期)2016-11-10
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
湖北工业大学学报(2016年5期)2016-02-27
系统工程学报(2015年2期)2015-02-28
电网与清洁能源(2015年2期)2015-02-28
