
采用密度比估计的多窗口变点检测方法
2023-02-14 10:31崔文泉
计算机工程与应用 2023年3期
张 曼,崔文泉
中国科学技术大学 管理学院 统计与金融系,合肥 230026
自新型冠状病毒COVID-19爆发以来,全球疫情呈蔓延之势,病毒具有较长潜伏期和高度传染性,在没有政策干预的情况下传播速度较快,会极大程度地干扰公共卫生系统,给经济和社会带来巨大的破坏。全球各国采取了多项紧急措施,如区域封锁和大规模检测等,一个自然的问题是,这些干预措施是否以及在多大程度上有效地减缓疫情的传播[1],为此需要分析各个国家疫情的阶段性特征。
COVID-19的传播可能经历几个阶段,最初由于人群缺乏防范意识导致传播速度较快,接着由于政府干预和公共卫生措施传播速度将逐渐放慢,这种阶段性分析可以表述为疫情数据的变点检测问题。本文基于疫情背景,研究时间序列的变点检测问题。
时间序列是随着时间变化对系统行为的描述,系统的行为会由于外部或内部因素随着时间而改变[2-3]。变点分析是统计学中的一个经典分支,其基本定义是在一个序列或过程中,当某个统计特性(分布类型、分布参数)在某时间点受系统性因素而非偶然性因素影响发生变化,称该时间点为变点[4]。时间序列变点检测问题作为时间序列分析的一个重要研究方向,在经济、金融、医学和气象学等方面都有较广的应用[5]。
时间序列的变点检测研究可追溯至Fox[6]在1972年提出的时间序列异常点检测,此后时间序列变点检测问题逐渐受到更为广泛的关注。当前对于时间序列的变点检测方法,可分为监督式(Supervised)方法和无监督(Unsupervised)方法[7]。
监督式变点检测方法是指收集足够数量的不同状态分布下的时间序列数据,结合这些样本时间序列的类别标签,对该序列集进行监督式训练,学习得到适合的模型,通过该模型对给定的时间序列进行分类识别,以确定其数据分布状态[7]。监督式方法包括基于支持向量机[8]、随机森林[9-10]、神经网络[11]的检测方法等。监督学习需要事先大量地训练,在应用中是一个挑战[7]。
无监督方法是指对无标签的时间序列直接进行变点检测,定量计算当前时刻发生结构变化的可能性,从而进行变点分析[7],与监督变点检测方法相比,无监督的方法应用更为广泛。因此,本文对时间序列的无监督变点检测方法展开研究。根据检测延迟的不同,无监督检测方法可分为两类:实时检测和回溯性检测,其中回溯性检测更稳定,检测效果一般会更准确。
回溯性变点检测方法需要待测时刻前后的数据,主要包括基于贝叶斯检验[12]、似然比检验[13]、累积和检验[14]、密度估计的变点检测等方法。
时间序列变点检测问题可描述如下[13]:
设y(t)∈ℝd是时间t时的d维时间序列,令:

是长度为k的时间t处的时间序列的子序列。变点检测问题即检测两个相邻时间段(称为参考区间reference和测试区间test)之间是否存在变点。设tref和ttest(tref<ttest)分别是参考区间和测试区间起始时间点,ptest(Y)和pref(Y)分别是参考区间和测试区间样本的概率密度函数。假设参考区间和测试区间的样本量分别为nref和ntest,则ttest=tref+nref,为简洁,记Yref(i)=Y(tref+i-1),Ytest(i)=Y(ttest+i-1),则第i个参考样本记为Yref(i),第i个测试样本记为Ytest(i),于是变点检测问题可表述为如下假设检验问题:
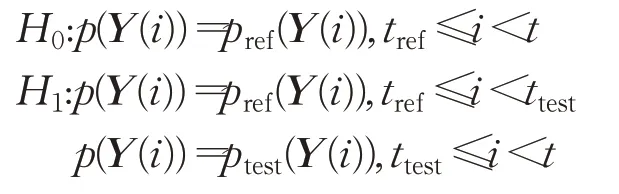
Brodsky[15]提出了基于密度估计的变点检测方法,在高维的情形下因“维度灾难”导致检测精度大大降低。
为了克服这一困难,直接估计概率密度比值的密度比估计方法被广泛应用起来,密度比框架在不进行密度估计的情况下,直接估计密度比,可以高效、统一地解决很多机器学习问题。因此研究如何更好地利用密度比来对时间序列进行变点检测具有重要研究意义和实际应用价值。已有的密度比估计包含如下方法[16]:核均值匹配[17]、Logistic回归方法[18]、Kullback-Leibler重要性估计程序[19(]KLIEP)、无约束最小二乘重要性估计[20](unconstrained least squares importance fitting,uLSIF),相对无约束最小二乘重要性估计[21(]relative uLSIF,RuLSIF)。
Kawahara等[13]和Liu等[22]提出了基于密度比的时间序列变点检测方法,主要是通过比较相邻时间窗数据的分布差异来识别变点。本文的目标是继续推进基于密度比的变点检测这一研究路线,同时考虑结合COVID-19全球蔓延的应用背景。然而该类方法存在局限性,Liu等[22]提出,基于密度比的变点检测方法的检测效果受到超参数窗宽的影响。Kawahara等[13]指出,窗宽越大,密度比的估计就越准确,但在变点个数较多的情形下,可能漏检相邻较近的一些变点。
鉴于本文的研究背景是基于疫情数据,政府干预、公共卫生措施等诸多宏观、微观影响因素会导致疫情数据发生结构性变化,由于影响因素的多元性和复杂性,致使疫情数据变点出现的时间尺度不一致。然而基于密度比的变点检测方法[22]中不同时间窗检测效果不尽相同,考虑对时间窗窗宽进行超参数选优,超参数选优往往需要足够数量的验证集更新超参数,当COVID-19病例数据较少时,需要进一步探究基于密度比的时间序列变点检测方法中时间窗窗宽的选择问题。
Messer等[23]提出多重过滤算法(multiple filter algorithm,MFA),该方法按照一定的算法汇集不同时间窗检测所得的备选变点集。
为了更好地对疫情数据等时间序列数据进行变点分析,本文在基于密度比的变点检测方法的基础上,利用和发展动态多重过滤MFA算法,提出一种新方法:基于密度比的时间序列多窗口变点检测方法(mDRCPD),可同时应用多个窗口进行检测。引入多窗口使得该方法更加适用于类似于疫情数据等多变点时间序列数据,这是已有的时间序列变点检测中所没有出现过的方法。
接着采用绝对误差、精确度、召回率和F1得分等指标来验证mDRCPD方法的有效性,模拟结果表明该方法在各项性能指标下表现优于单窗口方法。
最后将mDRCPD变点检测方法拓展到COVID-19传播进程的分析中,与Wang等[24]提出的疫情预测的生存卷积模型组合,通过对传播率的分段建模来刻画疫情的阶段性特点,评估国家政策在控制疫情传播上的效果。现有文献中关于疫情数据变点分析的研究数量相对不多,该分析能够为政府决策及疫情分析提供有效依据,在疫情大背景下具有重要的现实意义。
1 方法及算法
mDRCPD方法包括固定窗口下寻找变点集和变点集的汇集,下面将分别介绍这两个步骤及其中涉及的方法原理。
1.1 基于密度比的时间序列变点检测方法
设y(t)∈ℝd是时间t时的d维时间序列样本,令
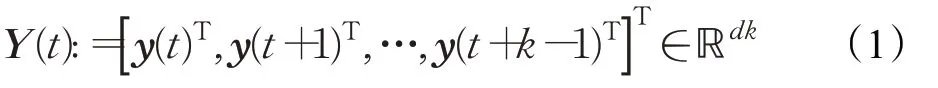
是长度为k的时间t处的时间序列的子序列。本文以Y(t)为样本点,为了能够利用密度比建模方法处理具有相依性结构的时间序列数据,类似于文献[13,22]中的处理方式,需要进行“工作独立假定”,视窗宽为n的样本是独立同分布的[25],对原始时间序列的相依性是由作为样本点的子序列Y(t)进行刻画的。不妨设新样本容量为T。
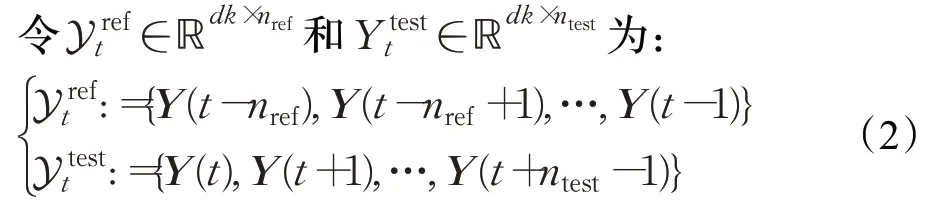
称Ytref和Yttest分别为t时刻窗口为nref和ntest的相邻时间窗,在工作独立假定下,Ytref和Yttest分别为样本容量为nref和ntest的简单随机样本。
基于密度比的时间序列变点检测方法步骤如下:
(1)考虑两个相邻时间窗Ytref和Yttest,然后计算Ytref和Yttest间的某种差异性度量作为点t的检测得分[26],记为score(t),检测得分越高,差异性越大,点t越可能是变点。
(2)计算每个时间t的检测分数:
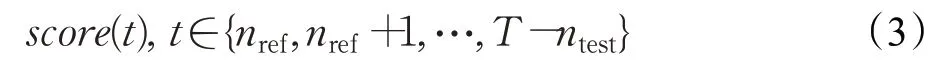
检测得分随t变化的曲线的超过预先设定的某个阈值的峰值点[22]处即为估计的变点。
这里给出t点处阈值的选取方法:仿照Sugiyama等[27]提出的最小二乘两样本置换检验,针对样本集Ytref和Yttest,对Ytref∪Yttest进行随机置换,置换后的前nref个样本记为,剩余ntest个样本称为,再对和计算检测分数,如此重复M0次,得到置换后样本的M0组检测分数的上α1分位数即为t处阈值。
由于nref和ntest表示时间窗的长度,故称之为窗宽,不妨称nref为左窗宽,ntest为右窗宽,由于这里的左右窗宽是固定不变的值,为与本文提出的方法区分,称这里的方法为基于密度比的单窗口变点检测方法(single window density-ratio change point detection,sDRCPD)。
方法使用对称散度来度量分布的差异性:

其中,Ptref和Pttest分别表示Ytref和Yttest所对应总体的分布,PEα(P||P′)表示α相对Pearson(PE)散度[21]:
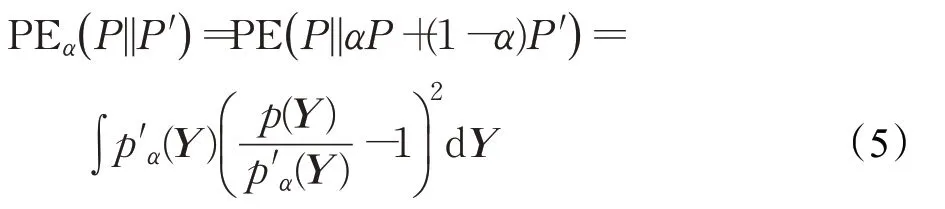
其中,p(Y)和p′(Y)分别是P和P′的概率密度函数,0≤α<1,p′α(Y)=αp(Y)+(1-α)p′(Y)称为α混合密度,rα(Y)=p(Y)/(αp(Y)+(1-α)p′(Y))称为α相对密度比。
本文根据基于RuLSIF的密度比估计方法对PE散度进行估计[21],Sugiyama等[16]给出以下核模型对密度比p(Y)/p′α(Y)进行建模:
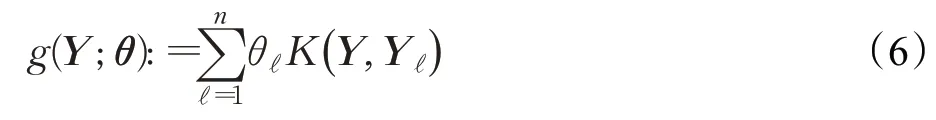
其中,θ:=(θ1,θ2,…,θn)T是从样本中学习的参数,K(Y,Y′)是基函数,本文使用高斯核:
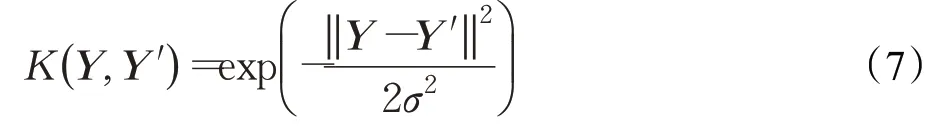
其中,σ(>0)表示核宽,在平方损失J(Y)最优的准则下对密度比进行估计:
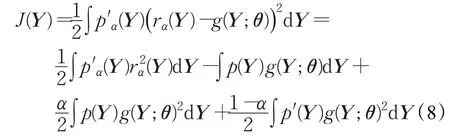
第一项与θ无关,故只需考虑最后三项。利用式(6),并对目标函数(8)进行经验化处理,给出了RuLSIF优化问题:
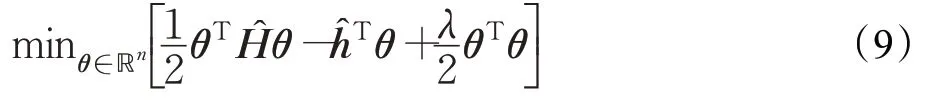
其中,λθTθ/2为惩罚项,λ(≥0)表示正则化参数,是n×n矩阵,第(ℓ,ℓ′)元素为:

式(9)的解为:

其中,In表示n维单位矩阵,密度比估计为:

由于缺乏非负限制,估计的密度比可能是负的,为了解决这个问题,负的输出可以这样处理:

利用α相对密度比的估计量,α相对PE散度的可估计为[21]:
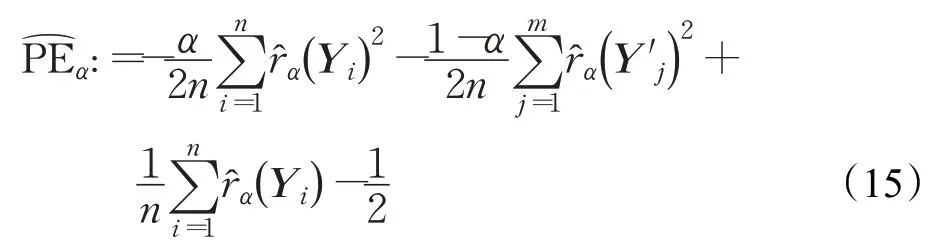
1.2 mDRCPD方法
在基于密度比的单窗口变点检测方法中,不同的窗宽检测效果不尽相同,大窗宽时密度比估计更准确,小窗宽则更适用于检测变化较快的点[13],但同一段时间序列数据包含的变点时间尺度多样,仅仅用单窗口滑动来检测变点有一定的局限性。为了进一步验证引入多窗口方法的必要性,本节实验分析了改进后的多窗口方法和未改进的单窗口方法在检测不同时间尺度变点上的区别。
实验仿照Takeuchi and Yamanish(i2006)[28]中一维自回归模型下生成1 000个样本(即t=1,2,…,1 000):
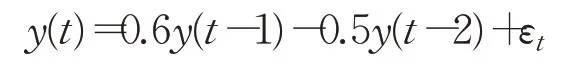
其中,εt是均值为μ和标准差σ=1.5的高斯噪声,初始值y(1)=y(2)=0,通过设置μ插入变点。变点分别为C1=400,C2=420,C3=440,C4=460,C5=480,C6=500,C7=600,C8=700,C9=800,C10=900,其中Ci表示第i个变点,人为设置前5个变点变化频率快,变化程度大,后5个变点变化频率慢,变化程度小。
实验结果如表1,表1显示不同窗宽下基于密度比的变点检测方法分别检测到了不同类型变点,小窗宽检测方法对前5个变点较为敏感,大窗宽则对后5个变点检测效果好。实验结果说明了“小窗宽不易漏检变化较快的点,大窗宽则对点识别更准确”,主要原因在于大窗宽时间窗包含的数据信息多,密度比估计更为准确,故变点识别更为准确,但在变点距离较近时,容易受到同一个时间窗内存在不止一个变点的影响从而降低检测效果。

表1 不同时间尺度变点检测结果Table 1 Detection results of change points on different time scales
在本次实验中,各窗宽检测效果差异较大,因此有必要引入多窗口方法,从而改善单窗口方法受窗宽影响,检测效果不足的问题。为了进一步提高检测效果,本文引入Messer等提出的多重过滤算法MFA[23],即同时应用多个窗口进行检测,并将结果汇集。将引入MFA算法后的基于密度比的时间序列变点检测方法称为多窗口方法,即mDRCPD,mDRCPD算法步骤如下:
(1)首先在每个固定的窗宽nref和ntest下寻找各自变点集,从观测时间点t∈{nref,nref+1,…,T-ntest}开始,得到时间点t的相对PE散度,即检测分数。
(2)若检测分数的最大值(设为M)大于阈值,则认为最大值所在的t是估计的变点。
(3)通过去除上一个估计变点的(t-nref,t+ntest)邻域来更新候选点并继续寻找下一个最大值点。
(4)这种算法重复直到M低于阈值停止。
(6)对于任意点v∈P2,仅当该点不属于集合任何现有变点的左邻域,右邻域时,点v才被添加到集合P中。
(7)该过程一直向前推进,直到左右窗宽为和停止。
算法1和算法2具体描述mDRCPD方法的代码实现过程:
算法1基于密度比的单窗口变点检测(sDRCPD)

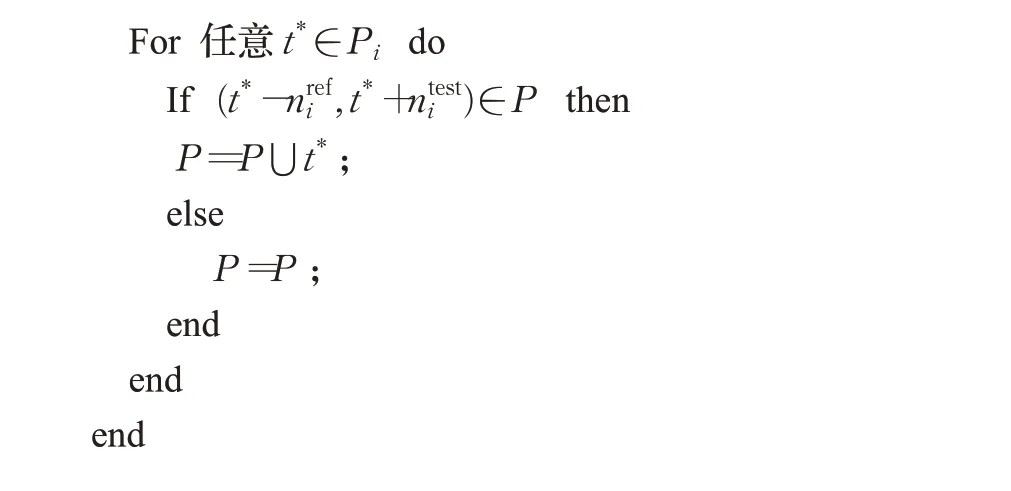
2 模拟分析
为了验证提出的mDRCPD方法相较于单窗口变点检测方法的优越性,本文模拟分析了两种方法在四类多变点时间序列数据集上的表现。对于所有实验,RuLSIF方法中的α=0.1,k=10[22],阈值选取中M0=100,α1=0.01,窗宽取nref=ntest=n,niref=ntiest=ni,i=1,2,…,|H|,σ和λ的参数调优采用5折交叉验证,两组候选参数如下:
(1)σ=0.6dmed,0.8dmed,dmed,1.2dmed,1.4dmed
(2)λ=10-3,10-2,10-1,100,101
其中,dmed表示样本之间的距离中位数。
2.1 模拟数据集
模拟使用的时间序列数据集具体介绍如下,其中包含人工插入的变点:
数据集1(均值变化):采用Takeuchi and Yamanishi(2006)[28]中一维自回归模型下生成1 000个样本(即t=1,2,…,1 000):
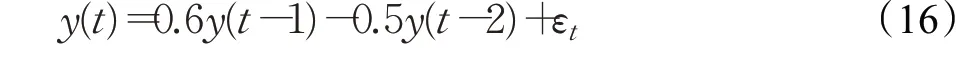
其中,εt是均值为μ和标准差σ=1.5的高斯噪声,初始值y(1)=y(2)=0,通过设置μ在每100个时间点插入一个变点:
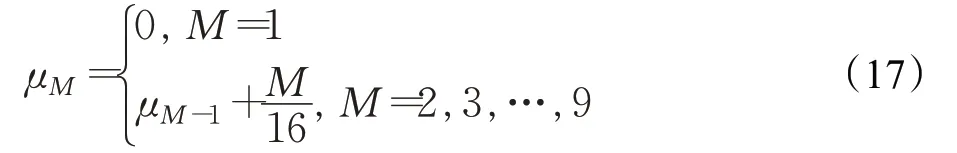
其中,M是使得100(M-1)+1≤t≤100M的自然数。
数据集2(方差变化)使用与数据集1相同的自回归模型生成1 000个样本,但通过设置σ在每100个时间点中插入一个变点:

数据集3(协方差变化)从原点为中心的正态分布中生成1 000个二维样本,通过设置时间t处的协方差矩阵Σ在每100个时间点处插入一个变点:
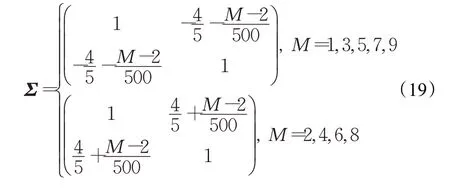
数据集4(频率变化)通过以下模型生成1 000个样本:

其中,εt是以原点为中心的高斯噪声,标准差为0.8,通过改变时间t的频率ω在每100个时间点插入一个变点:

上述数据集中后一个变点均比前一个变点更重要。
模拟实验中统计了100次蒙特卡洛模拟中的平均指标数据,采用的评价指标为:绝对误差、精确度、召回率、TP(True Positive)和F1得分。其中绝对误差、精确度、召回率、TP和F1得分都取为100次模拟的均值,2.2节将介绍所使用的评价指标。
2.2 评价指标
真实的变点集用T*={t1*,t2*,…,tK**}表示,估计的变点集用表示[30]。绝对误差记为ΔAE,表示预测的变点数和真实的变点数|T*|(=K*)之间的差异:

精确度表示估计的变点中是真实变点的比例。召回率表示真正的变点中被估计出的比例。类似Messer等[23]的做法,对于单窗口检测方法来说,一个估计的变点若它的n2邻域包含了真实的变点,就认为它是正确检测的;而对于多窗口检测方法,一个估计的变点若它的ni2邻域包含了真实的变点,方认为它是正确检测的,这里的ni指的是该点被添加到最终变点集前所属的窗宽ni。TP(true positive)表示被正确检测的变点数,即:
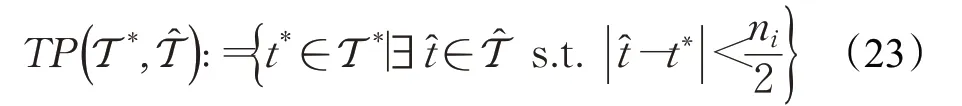
精确度(Precision)和召回率(Recall)定义为:
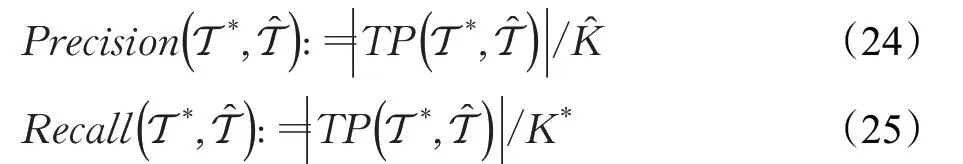
F1得分是精度和召回率的调和平均值,记为ΔF1:
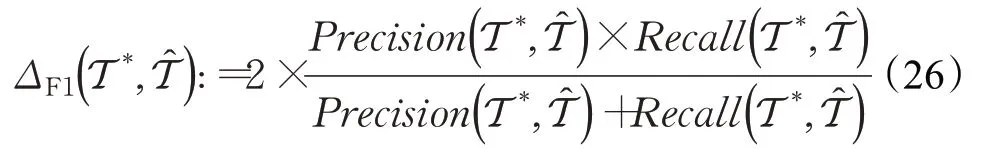
F1得分最优为1,最差为0。
2.3 模拟结果
表2~5分别展示了四种数据集在单窗口检测方法和本文提出的多窗口检测方法下的评价结果,其中n1=100,n2=90,n3=80,n4=70,n5=60,n6=50。
在表2~表5中,绝对误差指标越小表现越优,而TP、Presicion、Recall和F1得分四列指标均是越大表现越优。
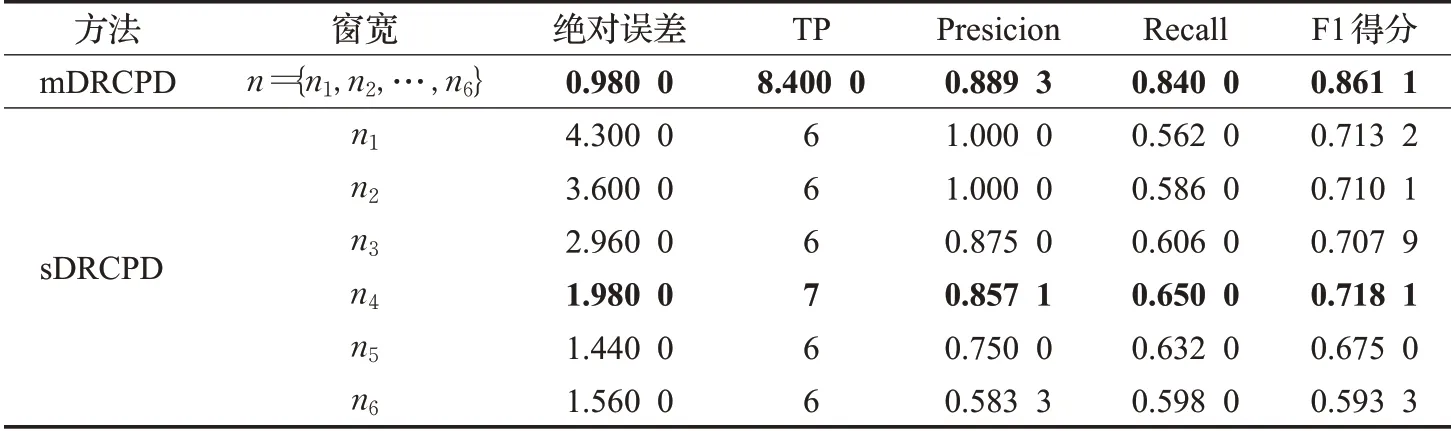
表2 数据集1评价指标对比结果Table 2 Comparison of evaluation index on dataset 1
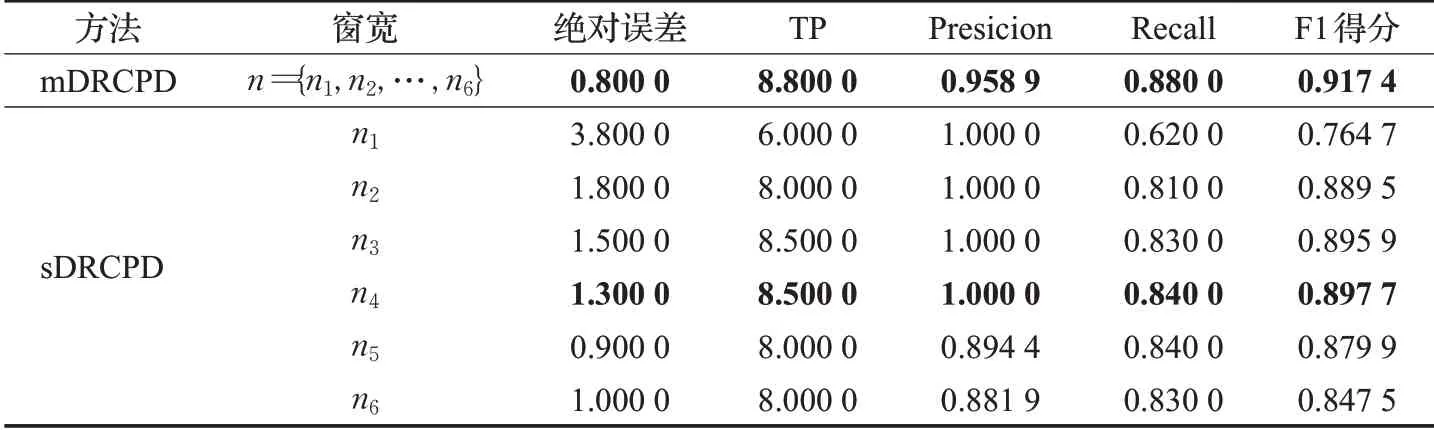
表5 数据集4评价指标对比结果Table 5 Comparison of evaluation index on dataset 4
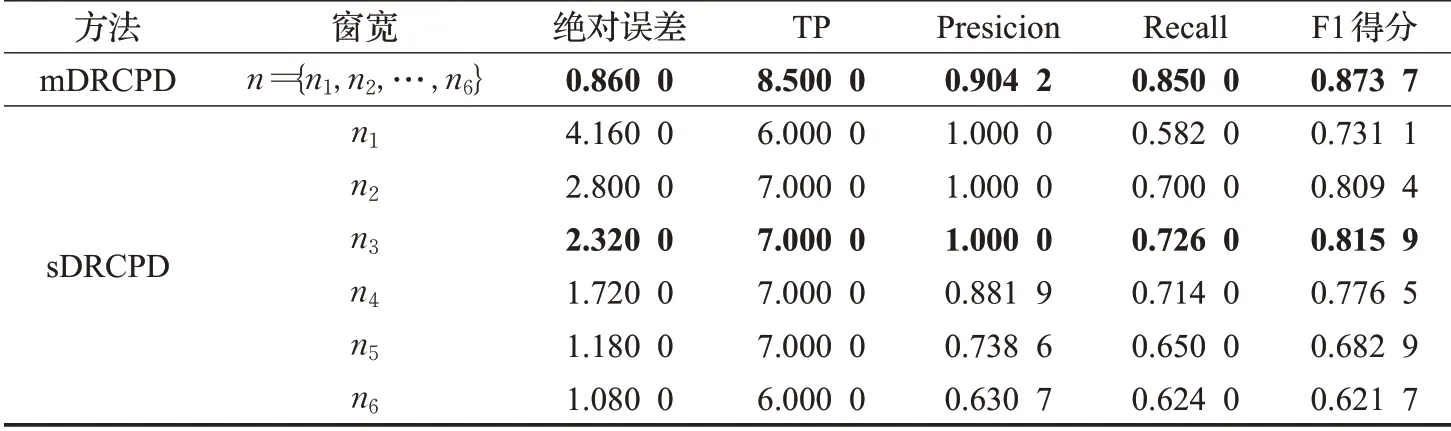
表3 数据集2评价指标对比结果Table 3 Comparison of evaluation index on dataset 2

表4 数据集3评价指标对比结果Table 4 Comparison of evaluation index on dataset 3
针对数据集1,mDRCPD方法相对于表现较好的单窗口方法(加粗显示,下同),绝对误差降低了1个单位,TP提高了1.4个单位,精确度提高了3.76%,召回率提高了29.23%,F1得分提高了19.91%。
针对数据集2,mDRCPD方法相对于表现较好的单窗口方法,绝对误差降低了1.46个单位,TP提高了1.5个单位,召回率提高了17.08%,F1得分提高了7.08%。
针对数据集3,mDRCPD方法相对于表现较好的单窗口方法,绝对误差降低了4.12个单位,TP提高了2.94个单位,召回率提高了66.03%,F1得分提高了29.68%。
针对数据集4,mDRCPD方法相对于表现较好的单窗口方法,绝对误差降低了0.5个单位,TP提高了0.3个单位,召回率提高了4.76%,F1得分提高了2.19%。模拟结果表明了提出的mDRCPD方法在检测多变点时间序列时的优越性。
3 实证分析
3.1 基于婴儿心率数据集
为进一步论证mDRCPD多窗口变点检测方法在真实数据集上仍然取得较好效果,利用R包wavethresh中提供的医学时间序列数据集BabyECG和BabySS进行实证分析。BabyECG是某婴儿心率的记录(以每分钟心跳次数为单位),每16秒采样一次,记录时间为21:17:59到06:27:18,包含2 048个观测值。BabySS是婴儿睡眠状态的记录,由经过培训的专家监测EEG(大脑)和EOG(眼动)确定,等级为1到4。睡眠状态代码是1=安静睡眠,2=安静和活跃睡眠之间,3=活跃睡眠,4=清醒。
本文应用变点检测模型来检测该婴儿睡眠状态的变化时刻,而BabySS数据中睡眠状态切换的时刻记为真实变点。表6展示了婴儿心率记录数据集在单窗口检测方法和提出的多窗口检测方法下的评价结果,其中n1=100,n2=90,n3=80,n4=70,n5=60,n6=50。
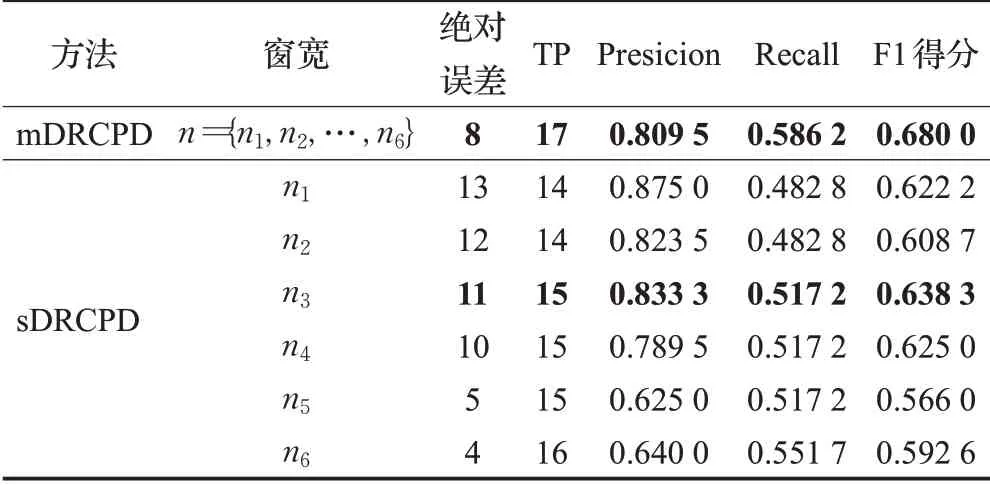
表6 婴儿心率记录数据集评价结果Table 6 Comparison of evaluation index in infant’s heart rate record data
从表6中可以看出,mDRCPD方法相对于表现较好的单窗口方法(加粗显示),绝对误差降低了3个单位,TP提高了2个单位,召回率提高了13.34%,F1得分提高了6.53%,该实证分析结果也表明mDRCPD方法相较于单窗口方法在实际时间序列数据变点检测中的优越性。
3.2 基于COVID-19数据集
3.2.1 COVID-19数据变点检测及政策效果评估
全球各国已经采取了前所未有的措施来缓解COVID-19的蔓延,一个自然的问题是各国的干预措施是否有效遏制了疫情传播的速度。
Wang等[24]提出了生存-卷积模型来评估国家政策对降低疫情传播速度的效果和预测COVID-19病例数据。该方法对传播率函数分段线性建模,当大规模公共卫生干预在特定日期实施时,引入额外的线性函数和新的斜率参数,则干预前后斜率的变化反映了政策对降低疾病传播速度的影响。接着假设未来一段时期传播率斜率保持不变,将历史数据代入生存卷积模型中,预测未来数据。本节将提出的mDPCPD变点检测方法与生存卷积模型组合,应用到COVID-19传播进程的分析中。
本小节实证分析的数据为COVID-19传播过程中每日新增病例(含境外输入)时间序列数据,来源是https://ourworldindata.org/coronavirus-source-data,分析的国家包括:美国、巴西、俄罗斯、英国、德国、墨西哥、印度、韩国,数据对应时间从每日新增确诊病例数超过3的日期开始,截止日期为2021年4月6日,各国实证分析中使用的时间序列数据样本量在表7中给出。在分析过程中,选取时间序列中2021年3月18日至2021年4月6日的20个样本作为测试集,其余数据作为训练集。
利用mDRCPD变点检测模型估计变点,以变点为节点,对传播率函数分段线性建模,变点前后传播率函数斜率的变化反映了变点处政策对降低疫情传播速度的影响。
表7总结了8个代表性国家的基于mDRCPD方法的检测结果,其中包括检测时间序列数据的开始日期,时间序列数据长度(m),估计的变点个数(NO.CP),前3个变点对应的日期(1stCP,2ndCP,3rdCP),ai表示第i个变点到第i+1个变点之间传播率函数a(t)的斜率。

表7 基于mDRCPD的疫情数据变点细节展示Table 7 Detail of change point detection on epidemic data based on mDRCPD
将部分变点与国家政策和估计得到的传播率联系,对政策效果进行评估。对于美国,变点出现在2020年3月24日,距离2020年3月13日“国家宣布全国进入紧急状态”有11天,差不多是一个正常的病毒潜伏期,且从3月20日起,“美国开始禁止在过去14天内曾去往28个欧洲国家旅行的外国公民入境”,变点的发生与此也对应。
对于巴西,变点是3月27日与3月30日,“感染者逼近一万例时,巴西政府陆续关闭边境,并呼吁民众戴口罩出行”事件对应。
对于俄罗斯,变点出现在2020年4月2日与“3月18日至5月1日期间,限制外国人和无国籍人员进入俄罗斯;3月27日起,完全停止与所有国家的包机和常规航班”的政策对应。
对于德国,变点是2020年3月16日,当时“3月16日德国封锁了边境,17日,德国措施开始加码,联邦政府提议关闭大量商店”,变点日期与之呼应。
对于墨西哥,变点日期为2020年4月14日与“4月4日,墨西哥政府宣布即日起至4月30日全国进入公共卫生紧急状态,在此期间公共和私营部门的所有非必要活动全部暂停”事件相对应。
对于印度,变点发生时间为2020年4月3日与“3月25日,印度开始进行为期21天的全国封锁;印度铁路停驶全国客运列车至4月14日”事件对应。
对于韩国,变点出现在2020年2月29日与“3月3日,韩国总统文在寅在国务会议发言中强调,所有政府机构要启动24小时应急体制”事件对应。
上面所分析的变点对应的内在表现均为变点后一个阶段传播率的较快下降,说明了政策的效果和公共卫生干预对降低疫情传播速度的重要性。
3.2.2 基于mDRCPD的COVID-19两阶段预测
对COVID-19的每日新增确诊病例数的预测对于公共卫生决策至关重要,可以帮助政府以数据作为决策依据。提出一种两阶段方法来进行每日新增病例数短期预测,第一阶段利用mDRCPD变点检测模型估计变点,第二阶段将变点作为传播率的分段节点,假设传播率短期的线性趋势保持不变(即斜率保持不变)进行预测,预测结果部分展示如图1,其中虚线表示训练数据的估计变点。
对于预测结果的评价,仿照Wang等[24]的方式构造预测结果的置信区间。设θ表示模型中的参数,将每日新增病例数划分为训练集和测试集,训练集表示为:
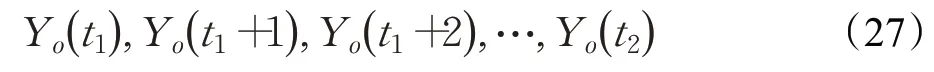
其中,t1和t2分别表示训练集的开始时间和结束时间。模型为,其中ε(t)表示残差项,Y(t;θ)表示生存卷积模型预测的每日新增病例数。估计置信区间时,假设残差值是可交换的,因此可以使用置换方法。首先拟合模型,得到残差,再置换残差,并利用置换的残差重构观察到的每日新增病例数,重新拟合模型得到新的预测结果,如此重复这个过程100次,以产生一组新的预测值Y(t;θ),最后估计100组预测值的经验分位数获得了95%的置信区间。
图1显示,真实值大部分都包含在预测值的95%置信区间内,说明预测是有效的。
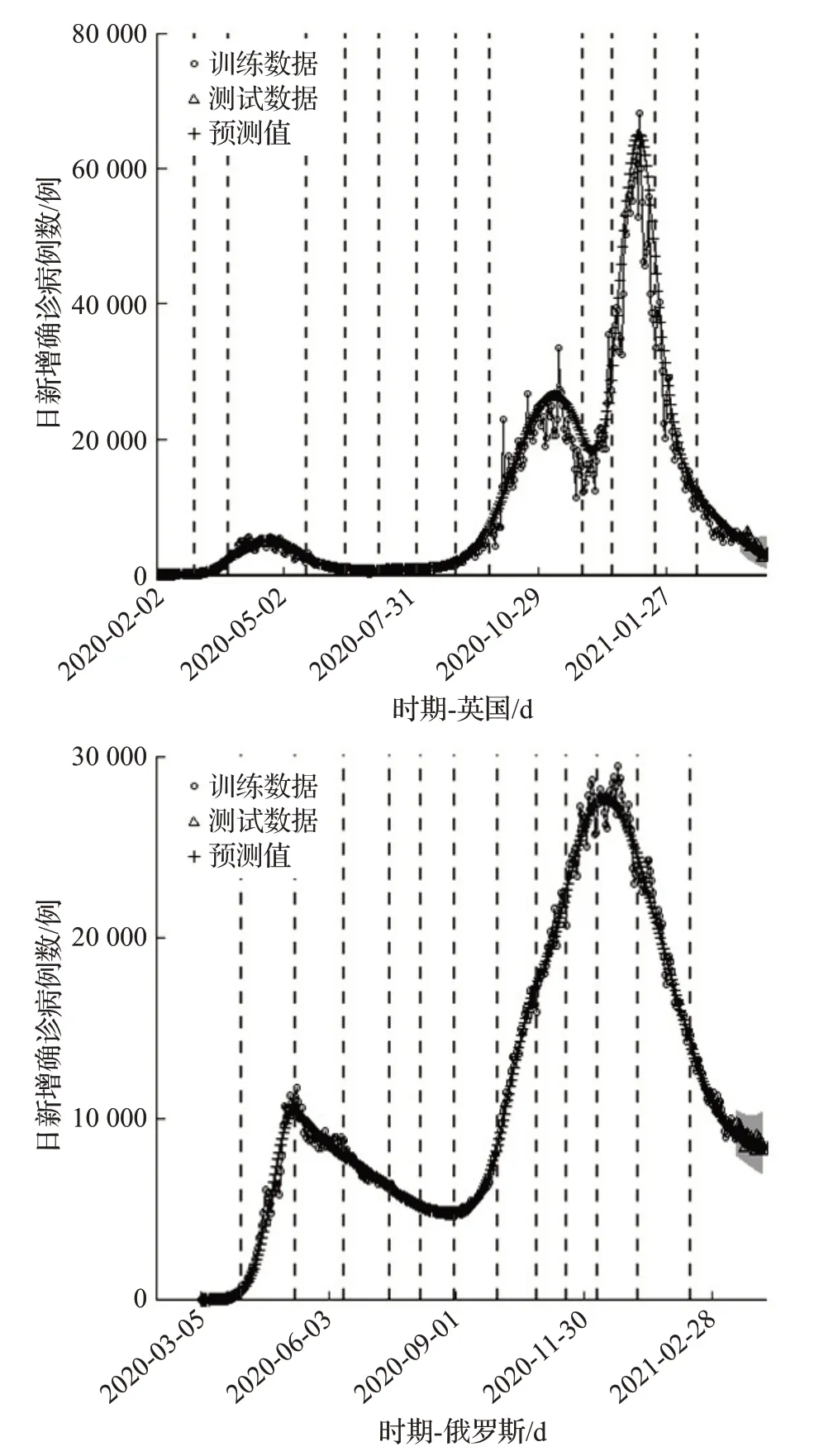
图1 新增确诊病例观测值和预测值Fig.1 Observed and predicted values of newly confirmed cases
4 算法分析
针对本文提出的mDRCPD检测方法,本文给出了算法的性能分析和与其他变点检测方法的比较分析,据此,来验证本文算法的有效性和可行性。
4.1 性能分析
本节对改进后方法的性能分析分为两个阶段,一是算法完成前的理论分析,即复杂度分析,可以从时间和空间两个维度去衡量,二是算法完成后的实验分析,即灵敏度分析。
4.1.1 算法复杂度分析
任何模型都不是两全其美的,在基于密度比的变点检测中引入多窗口算法MFA的同时,可能带来了算法复杂度的增加,这里进行复杂度分析。假设所有其他因素,如处理器的速度等是恒定的,对算法的实现没有影响。本文的算法复杂度从以下两个方面来说明。
时间复杂度是指执行这个算法所需要的计算工作量,其复杂度反映了程序执行时间随输入规模增长而增长的量级,在很大程度上能很好地反映出算法的优劣与否。在已有的单窗口方法中,见1.2节中算法1,只需要在固定窗口下遍历集合C={nref,nref+1,…,T-ntest}中所有的点,计算每个时间点的基于密度比的检测得分,时间复杂度记为O(T),其中T为样本容量。
在提出的多窗口mDRCPD方法中,见1.2节算法2,需要在窗宽序列集n={n1,n2,…n|H|}中每个窗宽下遍历集合C,时间复杂度变成O(|H|×T),然而在本文的模拟和实际应用中,|H|往往取为3~6的较小常数。故相较于单窗口方法,多窗口方法并未给时间复杂度带来较大增长,仍可记为O(T)。
空间复杂度是指一个算法在运行过程中临时占用存储空间大小的量度,已有的单窗口方法和改进后的多窗口方法空间复杂度均为O(d×k×T),由于d和k为常数,故记为O(T)。
在模拟分析和实际数据分析中已论证多窗口方法在检测效果上的显著提升,故权衡的来说,在实际应用中,往往愿意牺牲计算时间上的稍微代价,换取更好的检测效果。
4.1.2 灵敏度分析
针对本文提出的mDRCPD检测方法,这里给出了基于窗宽序列集n={n1,n2,…,nl}和调整参数k的灵敏度分析。采取不同的窗宽序列集n={n1,n2,…,nl}和调整参数k进行模拟实验,表8给出了mDRCPD方法和单窗口方法在不同窗宽序列集和不同k下的F1得分,其中黑体加粗部分表示基于mDRCPD方法的F1得分,未加粗部分表示各单窗口下的最优F1得分。
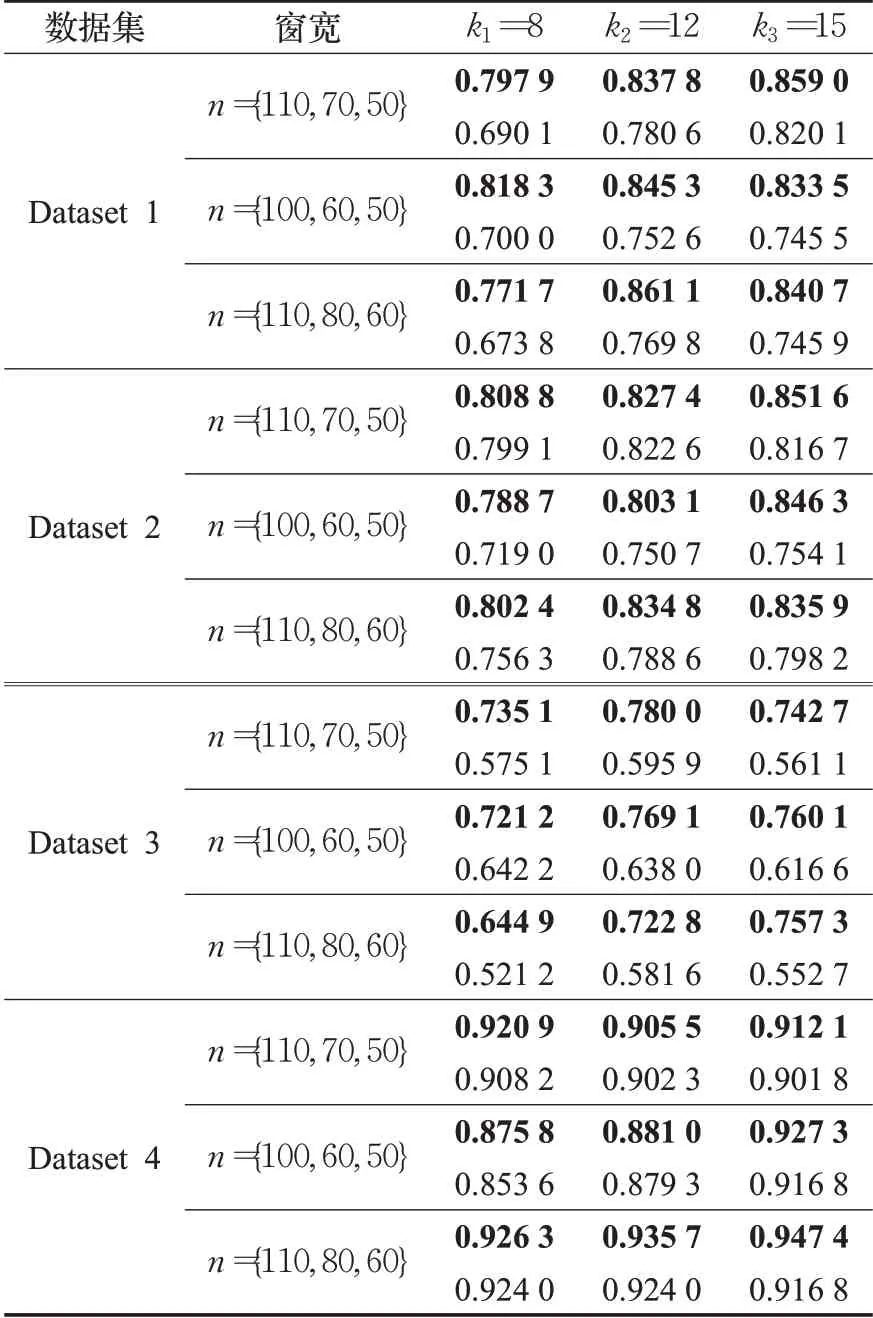
表8 灵敏度分析结果Table 8 Sensitivity analysis results
表8显示,随着窗宽序列集和调整参数k的变化,本文提出的多窗口方法性能始终优于单窗口方法,该结果并没有因为各参数的选取不同而产生较大差异,可见提出的模型是稳定有效的。
4.2 与现有方法的对比分析
本文提出的方法是引入多重过滤算法MFA,同时对时间序列多窗口分割,在文献[30]中总结了变点检测的主要分割算法,典型的有二进制分割(binary segmentatio,Binseg)和自下而上分割(bottom-up segmentation,BottomUp)。Binseg是一种顺序方法,首先在完整的输入序列中检测到一个变点,然后据此变点将序列拆分,并对拆分后的子序列重复上述操作。BottomUp方法是先将序列沿着规则网格分割成许多子序列,后根据相似程度不断合并连续的段,即先从许多变点开始,然后不断删除不太重要的变点。
为了进一步验证引入多重过滤算法对时间序列同时多窗口分割的必要性,本节进行了与其他两种主要分割方法的对比分析实验,实验中mDRCPD方法各参数取值同第2章模拟分析,实验结果如表9。

表9 与现有方法比较结果Table 9 Comparison of results with existing methods
从表9可知,在数据集1~4中,本文提出的多窗口方法的表现均优于另外两种分割过滤算法。
5 结束语
本文在基于密度比的变点检测方法基础上进行了改进,引入了MFA算法,提出了多窗口mDRCPD方法,并进行了模拟实验和实证分析,结果均表明该方法在各项性能指标下表现优于单窗口方法,因此,本文的研究具有应用和实用价值。
其次将变点检测mDRCPD算法和疫情预测的生存卷积模型组合,对疫情数据进行统计学变点检测并与国家政策联系,从而进行政策效果的评估以及短期预测,最后利用置换法构造预测值的95%置信区间,说明了预测结果的有效性。
本文提出的多窗口mDRCPD方法适用于生物医学、经济学、金融学等领域时间序列数据的变点分析问题,有效改善了单窗口方法受时间窗窗宽影响,检测变点时间尺度单一,检测效果不足的问题。
猜你喜欢
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
数学物理学报(2021年4期)2021-08-30
湖北第二师范学院学报(2020年8期)2020-10-13
河南科学(2020年4期)2020-06-03
安徽师范大学学报(自然科学版)(2020年1期)2020-03-28
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
