
融合CNN-BiLSTM和自注意力模型的音乐情感识别
2023-02-14 10:31钟智鹏王海龙苏贵斌裴冬梅
计算机工程与应用 2023年3期
钟智鹏,王海龙,苏贵斌,柳 林,裴冬梅
内蒙古师范大学 计算机科学技术学院,呼和浩特 010022
音乐是抒发情感的语言,曲作者和演奏者通过音乐抒发内心情感,聆听者通过音乐表现的情感与内心情感产生碰撞引起共鸣,以此激发听者对音乐情感本质的内在理解。音乐情感是人们在欣赏音乐时内在的心理情感状态对音乐主观的描述,受到内部主观因素和外部客观因素的影响[1]。音乐情感随着时间循序渐进发生着变化,在抑扬顿挫的旋律中,内涵着情感的主观性与复杂性,以及音乐的时序性与连续性。音乐情感特性的复杂多样化,为聆听者带来丰富的情感,人具备感受丰富情感的能力,但是计算机通过智能计算感受音乐情感的能力与人相差甚远,无法像人一样感受音乐表现的丰富情感,因此为计算机识别音乐情感带来了巨大挑战。
计算机通过智能计算感受音乐情感的过程也称为自动化音乐情感识别(music emotion recognition,MER),企图使计算机具备像人一样识别音乐情感的能力,通过音乐情感识别网络模型,对输入至模型中的音乐情感特征进行分析,从而识别音乐情感。目前,音乐情感识别网络模型主要以循环神经网络(recurrent neural network,RNN)为基础进行构建。歌曲中不同时间片段表示情感的形式亦不同,为了寻找片段中表示音乐情感的关键信息,在循环神经网络中引入卷积神经网络(convolutional neural networks,CNN),可以有效地捕获局部时间片段内关键的音乐情感信息[2]。歌曲中不同时间片段包含的音乐情感特征信息与音乐情感之间存在不同的相关性,为了获取与音乐情感最相关的特征信息,在神经网络中引入注意力模型,可有效捕获全局数据信息中与音乐情感最相关的特征信息,进而提升情感识别精确度[3]。从研究方法上看,近期的相关研究主要围绕着以循环神经网络为基础进行网络模型设计,注重局部关键信息及全局关键信息对音乐情感的影响,大部分研究针对事先已标注的歌曲识别音乐情感,进而验证模型的性能。
在实际应用中,人类通过听觉感知系统自听到的歌曲中获取音乐主旋律片段,考虑音乐主旋律片段中上下文的相关性,将获得的情感信息与人脑中存储的音乐情感记忆相结合,分析得到全局关键音乐情感信息,进而实现人类感受音乐表现情感的过程。文中构建CBSA(CNN BiLSTM self attention)网络模型模拟人类感受音乐情感的过程,基于CNN提取音乐情感的局部关键特征,利用双向长短时记忆神经网络(bidirectional long short term memory,BiLSTM)从局部关键特征中学习音乐情感过去与未来的上下文序列化信息,通过引入自注意力模型(self attention,SA)获取与音乐情感相关性较高的全局关键音乐情感特征信息,实验结果验证了文中方法的有效性。
1 相关研究
在研究音乐情感识别任务中,将构建音乐情感识别模型的方法划分为基于传统机器学习方法与基于深度学习方法两类。
基于传统机器学习的音乐情感识别方法大多数为统计概率模型。传统机器学习方法中手工特征的选择与组合对模型学习效果有重要影响,适合处理小样本数据问题。最初研究者较常使用支持向量机(support vector machines,SVM)或SVM与其他统计概率模型结合的方式对音乐情感进行分类训练。虽然取得了不错的识别效果,但是情感分类标准存在不确定性。Yang等[4]针对该问题,首次提出以回归训练的方式解决音乐情感识别问题,他们将不同特征工具提取的特征拼接为114维音乐特征,使用基于支持向量回归(support vector regression,SVR)模型识别每个音乐样本的效价值和唤醒值。Han等[5]使用7种音乐特征,基于SVR模型识别连续维度情感值,并与SVM模型进行对比,实验结果表明在识别维度情感时SVR比SVM具有更佳的性能效果。
近年来,随着深度学习的发展,使用深度学习方法识别音乐情感的准确率有了大幅提升[6]。深度学习的音乐情感识别方法大多数基于神经网络模型,其网络模型的设计方式影响着识别精确度,适合处理大样本数据问题。其中较常使用的神经网络模型可分三类,分别为:(1)循环神经网络;(2)组合使用卷积神经网络与循环神经网络;(3)融合注意力模型的神经网络。
(1)循环神经网络。Coutinho等[7]在ComPareE特征集基础上融合心理声学特征,使用基于长短时记忆循环神经网络(LSTM-RNN)实现对更长距离的上下文信息建模,捕捉音乐的时变情感特征,进而识别音乐情感。Li等[8]提出了一种融合超极限学习机的深度双向长短时记忆算法(deep bidirectional long short term memory extreme learning machine,DBLSTM-ELM),该算法使用超限学习机对DBLSTM训练不同时间距离长度的音乐情感识别结果进行融合,进而得到最终结果。循环神经网络在解决时序问题时有着不错表现,但是未考虑局部关键信息对音乐情感的影响,同时LSTM在训练时容易产生过拟合的风险,且存在训练效率低和长距离依赖问题。
(2)组合使用卷积神经网络与循环神经网络。考虑局部关键信息对音乐情感的影响,Koh等[9]使用L3-Net卷积神经网络和VGGish卷积神经网络通过深度音频嵌入方法聚合高维语谱图特征,用于识别音乐情感。然而卷积神经网络未考虑音乐情感的时序性,因此单一的使用卷积神经网络或循环神经网络并不能很好地解决音乐情感识别问题。唐霞等[10]针对此提出了一种深度学习模型,使用二维CNN和RNN相结合的方法分析语谱图特征识别音乐情感。缪裕青等[11]为了充分提取语谱图时频两域的情感特征,提出了结合参数迁移和卷积循环神经网络的方法,用于识别语音情感。Hizlisoy等[12]提出了卷积长短时记忆深度神经网络(CLDNN),在标准声学统计特征基础上,结合梅尔倒谱系数(MFCC)语谱图和梅尔滤波组能量语谱图特征识别音乐情感。针对LSTM训练效率低的问题,林颖[13]在图片识别任务中提出CNN能够直接从输入数据中进行学习,因此可减少空间结构信息的参数量,进而提高训练效率。
(3)融合注意力模型的神经网络。针对LSTM长距离依赖问题,Chaki等[14]提出了融合注意力的LSTM混合模型,缓解LSTM随着音乐时间输入距离长度增加,学习上下文信息能力降低的问题。传统注意力模型对外部信息依赖程度高,而音乐情感特性的复杂多样化,使整体情感表现并非时间与情感特征的简单汇总,很大程度上取决于与音乐情感特征信息的相关性。冯鹏宇[3]针对此问题,提出了融合自注意力的双向门控循环单元(bidirectional gate recurrent unit,BiGRU)网络模型对音乐情感及主题进行识别,与融合传统注意力的LSTM混合模型做比较,实验结果表明自注意力模型比传统注意力模型的拟合能力强、训练效率高。
综上,为了充分考虑音乐情感的时序性与连续性,选择BiLSTM网络为基础模型,为解决LSTM未考虑局部关键信息对音乐情感的影响与训练效率低的问题,选择融合二维CNN构成CNN-BiLSTM模型;针对LSTM长距离依赖问题,选择融合自注意力模型构成CNN-BiLSTM-SA模型,进而得到CBSA网络模型。该模型通过捕获音乐情感的局部关键信息、序列化信息和全局关键信息,解决LSTM识别长距离音乐情感能力差和训练效率低的问题,是提高长距离音乐情感识别精确度与训练效率的一种可行方法。文中距离定义为基于同一首歌曲不同分帧间隔得到不同时间序列总长度。分帧间隔大生成短距离样本数据,分帧间隔小生成长距离样本数据。
2 CBSA网络模型构建方法
文中将每首歌曲表示为IM×N音乐情感特征矩阵的形式,其中M表示时间维度,N表示音乐情感特征维度。CBSA网络模型包括二维卷积层、双向长短时记忆层和自注意力层,该模型的整体结构如图1所示。

图1 CBSA网络模型整体结构Fig.1 Overall structure of CBSA network model
2.1 方法描述
CBSA网络模型模拟人类感受音乐表现情感的具体模拟过程为,首先使用二维CNN获取歌曲中音乐主旋律片段,其次采用BiLSTM网络从音乐主旋律片段中获取音乐情感上下文信息,最后利用SA模型将获得的音乐情感信息与人脑中存储的音乐情感记忆相结合,进而得到全局关键音乐情感信息。表1为基于一首歌曲CBSA网络模型各层输出的形式化定义。

表1 基于一首歌曲文中各输出层的形式化定义Table 1 Formal definitions of output layers based on a song
2.1.1 二维卷积层
为了从音乐情感特征矩阵的时间与音乐情感特征两个维度获取音乐情感局部关键特征,因此使用二维CNN进行处理,其结构如图2所示。以识别一首歌曲的连续维度情感值为例,首先将IM×N音乐情感特征矩阵输入到二维卷积层,经过K(3×3)滤波器提取音乐情感特征并保留边缘信息;其次使用BatchNorm2d进行数据归一化处理,保证卷积后的输出数据分布一致;然后通过ReLU激活函数加入非线性因素,提高二维卷积层表达音乐情感的能力;最后选择最大池化(MaxPooling)方式降低矩阵维度保留音乐情感特征中某些关键信息,进而得到局部关键音乐情感特征矩阵NA×B。
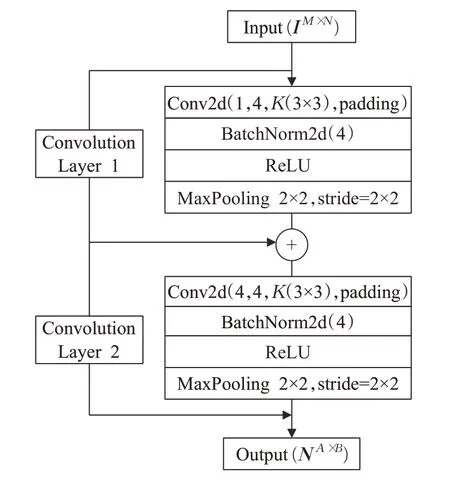
图2 二维卷积层Fig.2 Two-dimensional convolutional layer
2.1.2 双向长短时记忆层
LSTM传输方向为自前向后单向传输,然而音乐情感内部相关性较强,当前时刻状态不仅与前一时刻状态有关也与后一时刻状态有关。因此采用两个方向的LSTM层搭建BiLSTM网络[15],识别过去与未来的音乐情感信息,实现音乐情感上下文信息建模。
LSTM循环单元结构包括三个“门”和两个状态,分别为输入门it、遗忘门ft、输出门ot、内部状态ct和候选状态,其结构如图3。假设t时刻外部状态为ht,上一时刻的外部状态为ht-1,LSTM的计算过程为0,结合上一时刻的外部状态ht-1和当前时刻输入音乐情感特征向量nt,通过公式(1)~(4)计算LSTM循环单元内三个门值及候选状态值,利用遗忘门ft和输入门it通过公式(5)更新记忆单元ct,使用输出门ot通过公式(6)将内部状态的音乐情感信息传递给外部状态ht。

图3 LSTM循环单元结构图Fig.3 Structure diagram of LSTM cycle unit
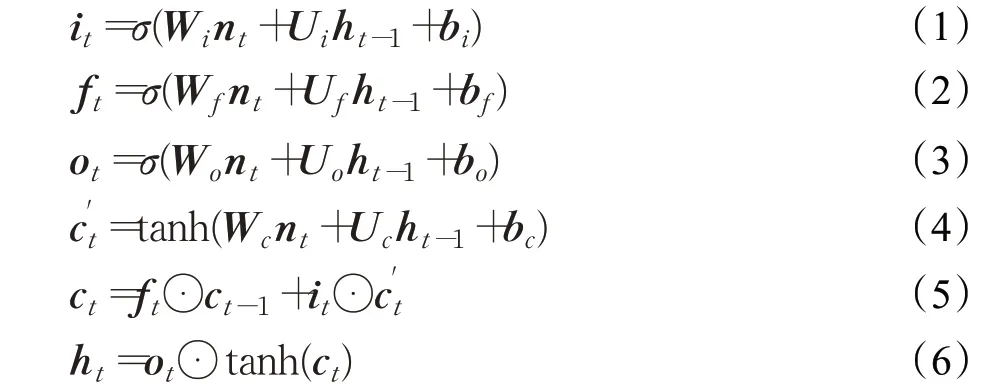
其中,Wx,Ux和bx中的x∈{i,f,o,c},Wx为当前时刻权重矩阵,Ux为上一时刻权重矩阵,bx为偏置向量,σ为Sigmoid函数,tanh为tanh函数。
BiLSTM通过Forward层与Backward层的LSTM,使用公式(7)与公式(8)分别对过去和未来的音乐情感信息进行提取与保存,单层BiLSTM网络结构如图4。假设Forward层按时间顺序,Backward层按时间逆序,t时刻的隐层状态定义为h1t和h2t,根据两个方向的隐层状态计算t时刻双向长短时记忆层输出向量lt,如公式(9)所示:

图4 BiLSTM神经网络Fig.4 BiLSTM neural network
其中,Wx(x∈{1,2})为当前时刻权重矩阵,U1和U2分别为上一时刻与下一时刻权重矩阵,f代表隐藏层激活函数,Wtx(x∈{1,2})为当前时刻隐层状态权重矩阵,bx(x∈{0,1,2})为偏置向量。经过两层BiLSTM得到序列化音乐情感特征矩阵LD×H。
2.1.3 自注意力层
双向长短时记忆层输出的音乐情感特征矩阵LD×H输入至自注意力层。将L中每一时刻的音乐情感特征向量作为查询向量,与歌曲中不同时刻的音乐情感特征向量进行相似度评分,通过加权平均后得到音乐情感全局关键特征信息。自注意力模型结构如图5所示。

图5 自注意力模型Fig.5 SelfAttention model
图5中每个方框外标有矩阵的行数和列数,其计算过程如下:
(1)对于输入矩阵L,首先进行线性映射,从而得到Q、K和V矩阵,如公式(10)~(12)所示:

其中,Wq、Wk和Wv分别为线性映射参数矩阵。Q、K和V分别是查询向量、键向量和值向量构成的矩阵。
(2)K的转置矩阵和Q点乘得到音乐情感特征相似度评分矩阵ScoreH×H。当点乘结果很大时,存在SoftMax分布不均衡从而带来梯度过小的问题,针对该问题使用矩阵Q的行标度平方根K缩放点乘结果平滑梯度,如公式(13)所示:

(3)使用SoftMax将音乐情感相似度评分矩阵Score归一化为概率分布矩阵,通过公式(14)将概率分布矩阵与V点乘得到音乐情感全局关键特征矩阵AV×H。

2.2 模型训练损失函数
损失函数作为深度学习模型训练中不可或缺的部分,在回归模型训练中常使用均方误差(mean squared error,MSE)和平均绝对误差(mean absolute error,MAE)作为损失函数。MAE对离群点不敏感,在梯度更新过程中梯度不随损失值减小而减小,不利于模型收敛;MSE对离群点比较敏感,在梯度更新过程中随着损失值的减小梯度也在减小,有利于模型收敛。离群点是分布规律明显异于主流数据的极少部分数据,其中常常蕴含着事物的变化趋势,因而不能简单地等同于噪声[16]。因音乐情感特性的复杂多样化,所以音乐情感信息中的离群点可能是音乐情感突然发生转折变化的点,但也不排除是噪声数据的可能。从对离群点敏感程度与收敛性两方面考虑,文中选择MSE作为模型训练损失函数,其计算式如公式(15)所示:

其中,N是音乐情感数据点总数量,yi是第i个音乐情感数据点的标签真值,ŷi是第i个音乐情感数据点的回归值。
3 实验与结果分析
3.1 实验相关介绍及参数设置
实验对EmoMusic数据集和DEAM数据集的音频数据进行数据预处理。为保证CBSA网络模型分析的音乐情感特征信息具有标准规范性,选择经过研究者验证并取得显著成果的音频情感特征集eGeMAPS,以该特征集为标准,自预处理后的音频数据中提取音乐情感特征。
3.1.1 数据集
实验使用EmoMusic[17]数据集和DEAM[18]数据集来训练评估CBSA网络模型在情感回归中识别的性能。EmoMusic数据集由744首歌曲组成,自歌曲15 s后截取45 s长的音乐片段。由Amazon Mechanical Turk众包工作人员标注,每个片段至少有10人标注,每段标有一个静态VA(valence-arousal)值和间隔为0.5 s的动态VA值。DEAM数据集在EmoMusic数据集基础上扩充至1 744首歌曲,除了歌曲数量增加,在标注方式及音乐片段长度方面均一样。为了获取长距离音乐情感信息,实验基于连续时间识别静态音乐情感,对真值标签进行归一化处理使其分布在[0,1]区间内。数据集划分方式按照8∶2的比例随机分成2份,分别为训练集和测试集。
3.1.2 数据预处理
实验采用数据增强的方式对音频数据文件进行预处理。数据增强是指将一系列变形数据应用于实验数据集[19],其基本原则是新数据的标签不会因为变形而发生变化[20]。音频数据增强方法可以明显增强模型的泛化能力[21],减少训练数据和测试数据之间误差差距,提高模型性能。在预处理阶段使用AudioSegment工具将压缩有损的.mp3音频文件转换成无损不压缩的.wav音频文件,既保证了音频的无损性,又方便在Python中处理;利用Audiomentations工具在无损不压缩的音频数据内添加高斯噪声、改变播放速度、音调及时间滚轴以此进行音频数据增强。
3.1.3 特征集及特征提取
实验将eGeMAPS特征集作为提取音乐情感特征的标准。该特征集是一个音频情感特征集,由7个谱特征、11个频率相关特征和7个能量/振幅相关特征通过统计计算得到88个统计声学特征[22]。特征集中的特征及特征之间的相关性经过理论与实践验证是一个具有标准规范性的音频情感特征集[23]。在语音情感识别[24]和音乐情感识别[25]等音频情感相关的研究中被广泛使用。基于eGeMAPS特征集使用OpenSimle工具从音频数据集中提取连续时间的音乐情感特征。采取简便变异方式,仅考虑使用不同距离长度的样本特征识别音乐情感,不考虑分帧间隔时间是否合理,并忽略最后一帧信息。将每首歌曲表示为时间×特征的形式,保存到.csv文件。
3.1.4 模型参数及评价指标
实验设置模型优化算法为Adam、权重衰减系数weight_decay=0.000 1、学习率lr=0.000 1和每个批次4个样本,构建模型过程中使用ReLU作为激活函数,训练轮数Epoch为80。基于eGeMAPS特征集,自源音乐中提取88维特征,以99时间距离长度为例,模型具体参数如表2所示,其中CNN和BiLSTM每个部分都由两层神经网络构成,因为上一层输出为下一层输入,所以使用Connection作为连接层避免输入输出层的重复表示。自注意力模型中的Q=K=V,使用求和方式聚合输出层时间维度信息。因为batch_size为每层tensor的第0维度且数值相同,所以不予呈现在模型训练参数内。采用均方根误差(root mean square error,RMSE)作为识别精确度指标,R2决定系数(R-squared,R2)作为模型拟合优度指标。

表2 模型参数表Table 2 Model parameter
3.2 CBSA网络模型消融实验结果与分析
由于不确定CBSA网络模型是否可以提高训练效率和音乐情感识别精确度。为了验证CBSA网络模型及各部分作用的有效性,自EmoMusic数据集中提取不同时间距离长度的音乐情感特征,以此对CBSA网络模型及其消融模型进行实验。首先将BiLSTM作为基准模型,其次向BiLSTM中分别添加二维CNN和SA,最后得到消融模型分别为BiLSTM、CNN-BiLSTM及BiLSTM-SA。通过消融实验在时间距离长度为99、199和299的数据上评估识别精确度RMSE、拟合优度R2及训练效率。使用每个模型在训练过程中最小Loss的RMSE和R2做比较,训练效率(training efficiency,TE)为训练总时长与训练总轮数之比,即模型训练一轮的时长,单位为s。
基于不同距离长度使用各消融模型,在效价维度(Valence)和唤醒维度(Arousal)的回归评估指标结果如表3和表4所示,CBSA网络模型在三种不同距离长度的数据集识别性能均优于或接近于其他三种消融模型,并且随着距离长度增加识别精确度也在提高。
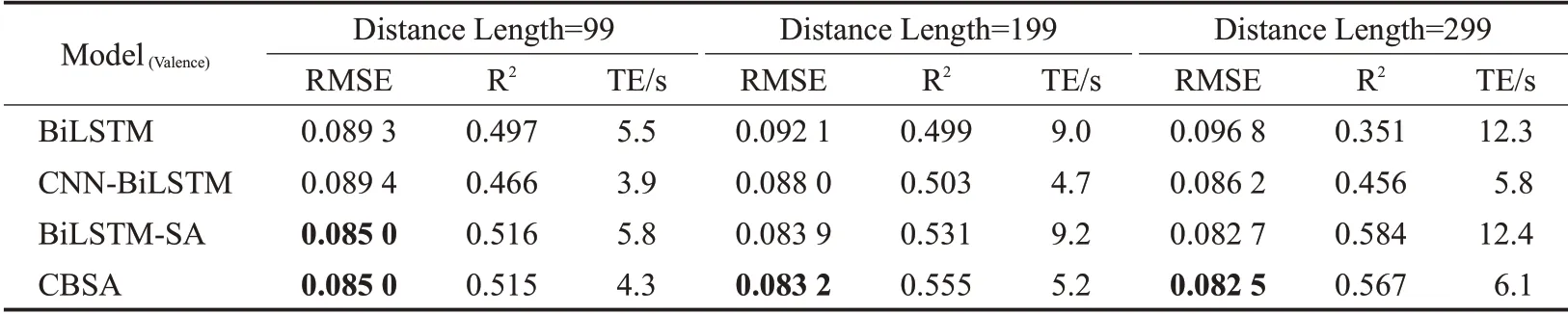
表3 在效价维度中各消融模型回归评估指标结果Table 3 Regression evaluation index results of each ablation model in valence dimension
3.2.1 验证二维CNN与Self Attention有效性
结合表4以Arousal在99距离长度为例,相对于使用BiLSTM的RMSE,CNN-BiLSTM和BiLSTM-SA的RMSE分别降低了0.004 2和0.009 8。这项结果表明了二维CNN和SA对识别精确度有提升效果。融合SA模型在三种距离长度的表现来看,相对于BiLSTM,BiLSTM-SA在三种距离长度的RMSE分别降低了0.009 8、0.009 3和0.012 3;融合CNN模型在三种距离长度的表现来看,相对于BiLSTM,CNN-BiLSTM在三种距离长度的RMSE分别降低了0.004 2、0.005 6和0.008 9,训练效率降低了1.7、4和6.4,这两项结果再次证明了融合SA和二维CNN有益于提升CBSA模型的整体性能。
3.2.2 分析各模型RMSE曲线和R2曲线
结合表4以Arousal在99距离长度为例,CBSA模型的RMSE相对于BiLSTM、CNN-BiLSTM和BiLSTMSA分别降低了0.009 8、0.005 6和0,如图6所示,虽然CBSA模型与BiLSTM-SA最小Loss的RMSE相同,但是CBSA模型的RMSE整体趋势低于BiLSTM-SA,这项结果证明了CBSA模型的整体识别精确度接近或高于BiLSTM-SA;CBSA模型的R2相对于BiLSTM、CNNBiLSTM和BiLSTM-SA分别升高了0.03、0.014和-0.049,如图7所示,虽然CBSA模型与BiLSTM-SA相比低了0.049,但是R2受多种因素影响,该结果仅说明CBSA模型拟合优度低于BiLSTM-SA,不影响两者识别精确度的比较。

表4 在唤醒维度中各消融模型回归评估指标结果Table 4 Regression evaluation index results of each ablation model in arousal dimension
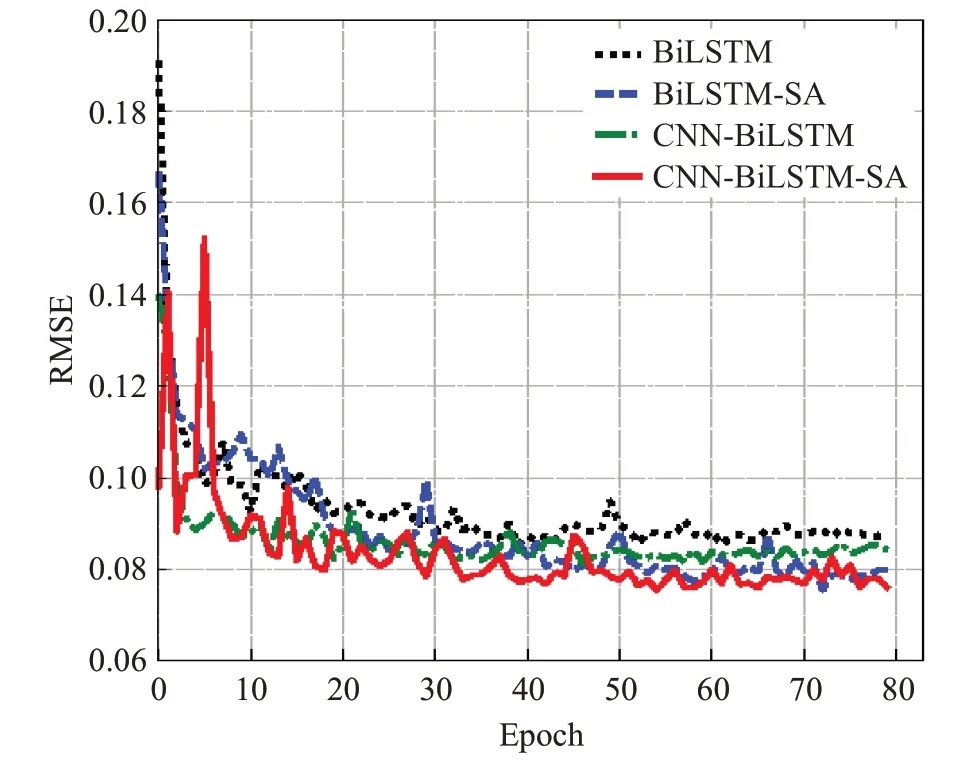
图6 Arousal中各模型99距离长度的RMSEFig.6 RMSE of 99 distance lengths of each model in Arousal
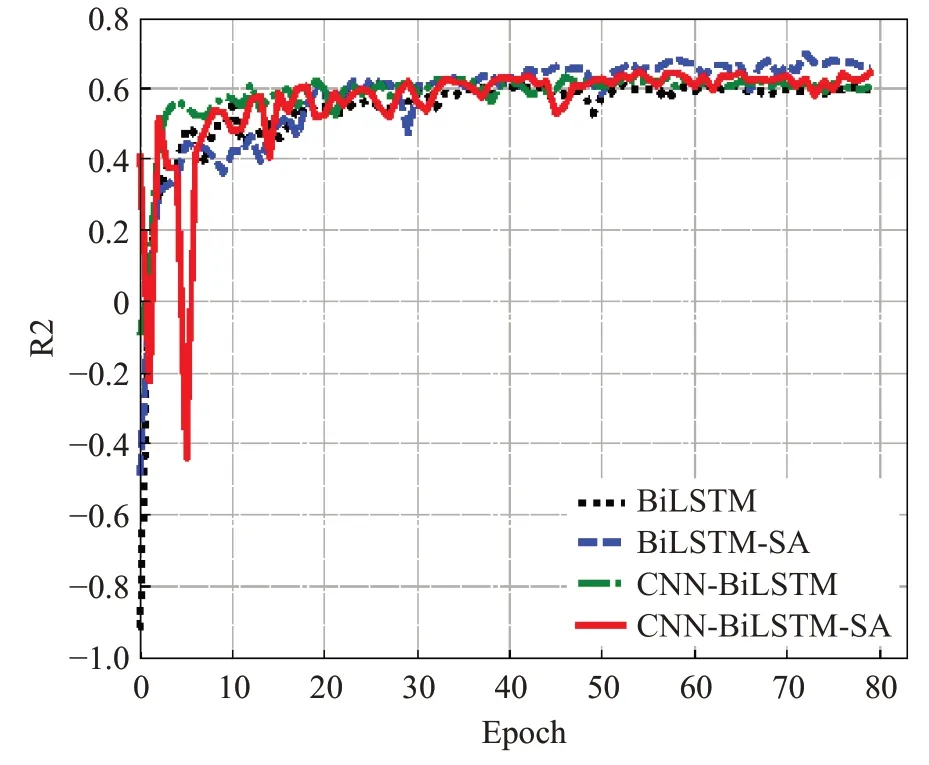
图7 Arousal中各模型99距离长度的R2Fig.7 R2 of 99-distance length of each model in Arousal
3.2.3 各模型不同距离长度的RMSE与训练效率
结合表4以Arousal为例,Arousal中随着距离长度增加各模型最小Loss的RMSE变化如图8,BiLSTM在299距离长度的RMSE相对于199距离长度升高了0.001 5,这项结果证明了超过一定距离长度后,LSTM存在学习能力下降问题。使用BiLSTM-SA、CNN-BiLSTM和CBSA网络模型,相对于99距离长度,在199和299距离长度的RMSE值分别降低了0.001 1、0.002 6,0.003、0.004 8和0.001、0.003,这项结果证明了相对于短距离,使用长距离数据可以提高识别精确度。随着距离长度增加CBSA模型识别精确度逐渐高于其他消融模型,进一步证明了CBSA模型可提高长距离音乐情感识别精确度。在训练效率方面,图9可以清晰看到每个模型随着距离长度增加训练效率逐渐升高。相对BiLSTM-SA,CBSA模型在不同距离长度的训练效率降低了1.8、4和6.4,这项结果证明了融合CNN可以降低模型复杂度并提高训练效率。

图8 Arousal中各模型不同距离长度的RMSEFig.8 RMSE of each model in Arousal with different distance

图9 Arousal中各模型不同距离长度的训练效率Fig.9 Training efficiency of each model with different distance lengths in Arousal
综上,虽然CNN-BiLSTM比CBSA模型训练效率低,但 是RMSE较高;BiLSTM-SA与CBSA模 型 的RMSE基本接近,但是训练效率较低;因此模拟人类感受音乐表现情感的过程构建CBSA网络模型在识别连续时间的长距离静态音乐情感中存在一定优势,可提高长距离音乐情感识别精确度与训练效率。
3.3 对比实验结果与分析
3.3.1 BiLSTM与CNN不同层数的识别精确度对比
调整确定BiLSTM和CNN网络层数的取值,使CBSA模型达到更高的音乐情感识别精确度,为此首先进行BiLSTM网络层数实验,在确定该网络层数基础上,确定CBSA模型中CNN的网络层数。为保证时间距离长度适中,选择199距离长度的RMSE作为模型层数评估指标,其中BiLSTM网络的RMSE为单独使用该网络的识别精确度;2D-CNN网络的RMSE是在BiLSTM层数确定的基础上,调整CBSA模型中使用不同层数CNN网络的识别精确度。
实验分别对比了1~3层的BiLSTM识别精确度以及使用1~3层CNN时CBSA模型的识别精确度,试图找出BiLSTM与CNN的层数对识别精确度的影响,实验结果如表5所示。以Arousal为例,两层的BiLSTM网络相对于一层和三层BiLSTM网络的RMSE降低了0.015 7和0.001 9;两层的CNN网络相对于一层和三层CNN网络的RMSE降低了0.001 8和0.001,这项结果证明了两层的BiLSTM和两层的CNN识别精确度均高于其他两个网络层数,并且增加层数并没有使识别结果更加优秀。因此实验基于两层BiLSTM网络,使用两层CNN网络,构建CNN-BiLSTM模型,使其与自注意力模型相结合得到CBSA模型,进行音乐情感回归训练。
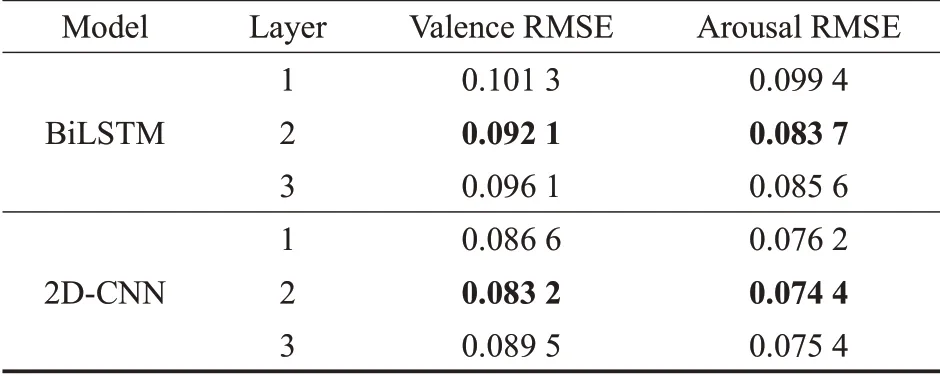
表5 不同BiLSTM和CNN层数的识别精确度比较Table 5 Comparison of recognition accuracy of different BiLSTM and CNN layers
3.3.2 数据增强对MER的影响
音频数据增强方法包括音频加噪、音频变速、改变音调和音频时间翻转。文献[21]提出同一种数据增强方式使用过多将产生大量的相似数据,易导致模型识别性能降低。为此同一种数据增强方法仅选择一种增强方式对原音频进行操作。实验在EmoMusic数据集的原音频基础上,使用Audiomentations工具的AddGaussian-Noise、TimeStretch、PitchShift和Shift以上四个函数对原音频进行添加高斯噪声、改变播放速度、调节音调和时间翻转的操作,每种数据增强方法生成一组数据,填充至原音频数据集。实验以原音频数据识别精确度为基准,使用CBSA模型在训练299距离长度数据时,最小Loss的RMSE为评估指标,对使用各音频数据增强方法的识别结果进行对比。根据对比结果选择超过基准精确度的数据增强方法,一同对原音频进行数据增强操作,生成一组增强数据,作为训练评估CBSA网络模型在情感回归中识别的性能。
实验使用CBSA模型,训练原音频与增强音频的组合数据,对比使用不同音频数据增强方法的识别精确度,结果如表6所示。以Arousal为例,未增强数据的RMSE相对于加噪、变速、改变音调和时间翻转的增强数据分别升高了0.003、0.004 2、0.001 6和0.003 5,这项结果证明了使用加噪、变速、调节音调和时间翻转的数据增强方法可提升音乐情感识别精确度。根据该结论,使用上述四种数据增强方法一同对原音频进行操作,生成一组增强数据填充至原音频数据集,使用这种数据增强方法的RMSE相对于仅使用加噪、变速、改变音调和时间翻转的数据增强方法分别降低了0.002、0.000 8、0.003 4和0.001 5,这项结果证明了使用上述四种数据增强方法同时对原音频数据进行增强操作,比单独使用其中一种数据增强方法的识别精确度高。
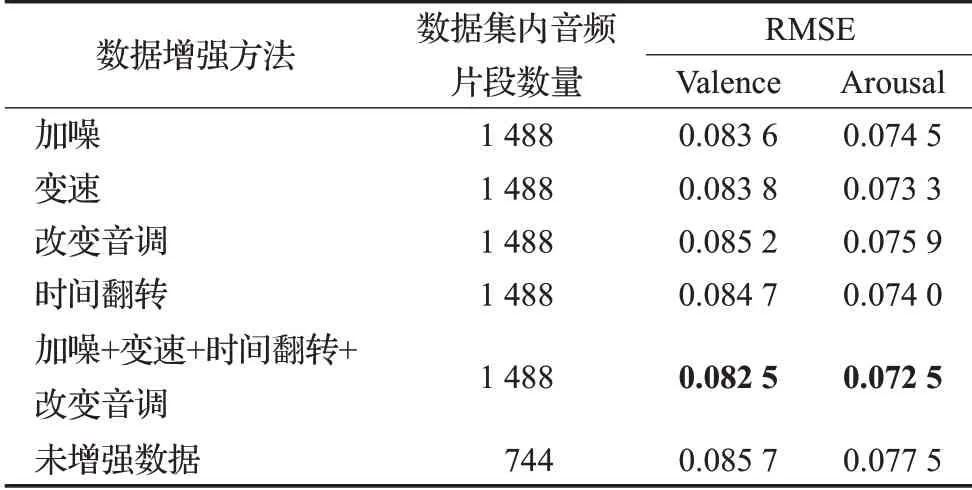
表6 音频数据增强方法的识别精确度对比Table 6 Comparison of recognition accuracy of audio data enhancement methods
3.3.3 损失函数对MER的影响
从音乐情感特性的复杂多样化以及接受离群点的敏感程度与收敛性考虑,为验证基于eGeMAPS特征集得到的音乐情感特征中的离群点是否为影响音乐情感变化趋势的转折点。在CBSA模型中分别使用MAE与MSE作为模型训练损失函数,以RMSE为识别精确度评估指标,实验结果如图10所示,可清晰看出,Valence和Arousal使用MSELoss相较于MAELoss取得了不错的识别精确度。因此基于eGeMAPS特征集提取的音乐情感特征信息具有标准规范性,信息中包含的离群点蕴含着音乐情感变化趋势,可以提高模型识别精确度。
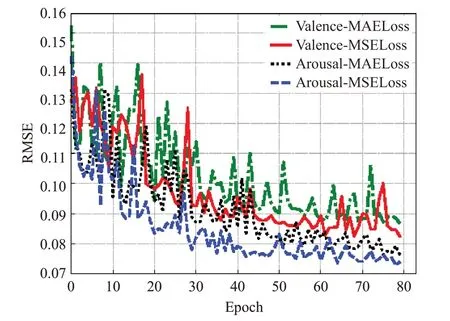
图10 Valence和Arousal对比MSE与MAEFig.10 Valence and Arousal compare MSE and MAE
3.3.4 文中方法与其他方法对比
为进一步验证模型性能的有效性,基于同一评估指标,使用EmoMusic数据集和DEAM数据集,将文中方法与数据集基线及当前性能较好的音乐情感识别方法进行比较,下文给出了各对比方法及其简介。
(1)MLR、BLSMT-RNN、SVR和GPR[26]。上述四个模型分别为数据集基线以及慕尼黑工业大学、会津大学和乌得勒支大学训练评估EmoMusic数据集使用的识别方法。
(2)ConvNet_D-SVM[27]。基于空洞卷积(dilated convolution,ConvNet_D)增加网络层感受野的方式探索情感计算的上下文信息,将其输入到SVM回归模型。
(3)AC2DConv[28]。采用音频和计算二维卷积(audio and computed 2D convolution,AC2DConv)网络模型分析由原始音频、音频信号及频谱图组合而成的音频特征表示形式。
(4)ResNets-audioLIME[29]。采用源分离解释器audioLIME与残差网络(residual networks,ResNets)相结合分析中级感知特征和频谱图特征。
上述方法的评估指标结果如表7所示,与其他方法相比,文中方法在音乐情感识别任务中具有最小的RMSE和最大R2,可以提高音乐情感识别精确度,模型拟合度相对较好。
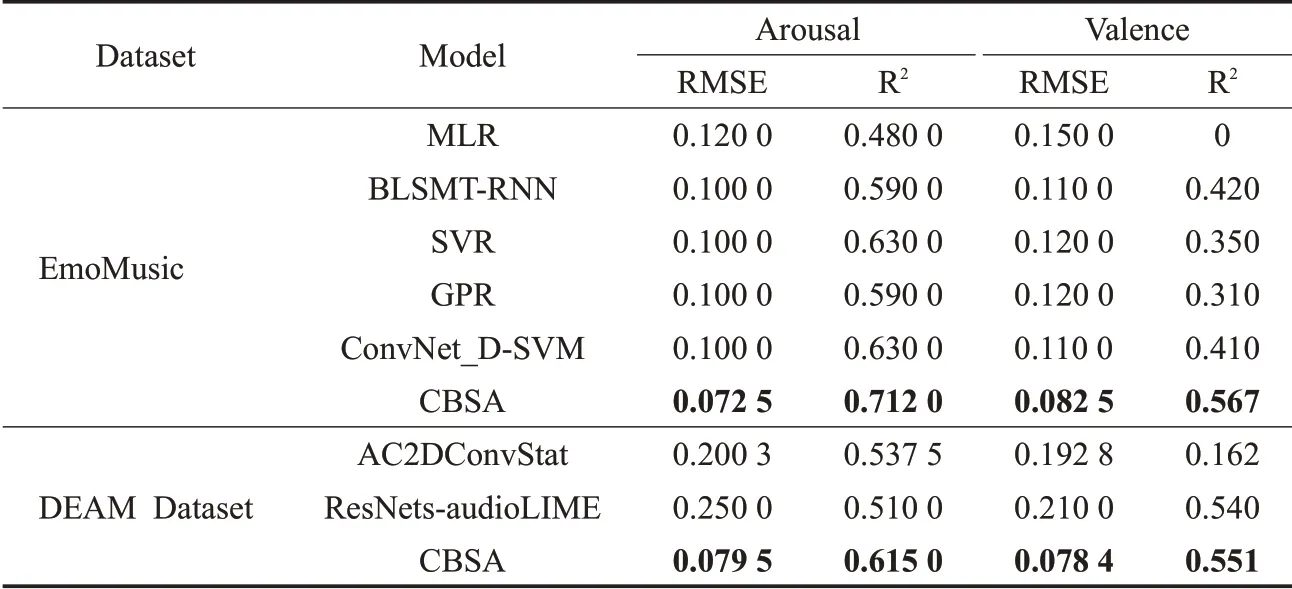
表7 模型精确度汇总Table 7 Model accuracy summary
4 结语
文章模拟人感受音乐表现情感的过程,针对音乐情感识别中长短时记忆网络的长距离依赖和训练效率低问题,提出了CBSA网络模型识别长距离音乐情感。在音频预处理阶段,使用数据增强方式减少训练数据和测试数据之间误差差距;在音乐情感特征提取阶段,使用eGeMAPS特征集,保证提取的音乐情感特征具有标准规范性;在音乐情感识别阶段,文中提出了CBSA网络模型用于识别音乐情感,首先通过二维CNN提取音乐情感中局部关键特征,然后采用BiLSTM神经网络从局部关键特征中学习音乐情感过去与未来的上下文序列化信息;再利用自注意力模型从音乐情感序列化特征信息中获取与音乐情感相关性较高的全局关键特征信息,提高识别精确度及训练效率。
在不同的时间距离长度中,通过消融实验验证了二维CNN和自注意力模型的作用,以及CBSA模型相对于其他消融模型在训练效率和识别精确度方面的优势;同时发现基于同一首歌曲,使用长距离特征信息表示方式可以提高音乐情感识别精确度。通过对比实验结果可知,文中识别音乐情感的方法比其他方法识别精确度高;同时,验证了基于eGeMAPS特征集提取的音乐情感特征信息包含的离群点有助于发现音乐情感变化趋势。综上,基于CBSA音乐情感识别网络模型可以从较长距离的连续时间中获取音乐情感信息规律进而提高识别精确度和训练效率,有效地实现了音乐的情感回归,为音乐情感识别方向提供了一个新的可行性思路。未来研究可考虑结合音频、歌词文本和视频画面的多模态方法,从多角度对音乐情感进行全面描述,以此提高音乐情感识别精确度。
猜你喜欢
云南教育·中学教师(2020年11期)2021-01-07
山东煤炭科技(2020年1期)2020-03-06
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子制作(2017年9期)2017-04-17
重型机械(2016年1期)2016-03-01
人间(2015年8期)2016-01-09
海军航空大学学报(2015年4期)2015-02-27
