
联合对话行为识别与情感分类的多任务网络
2023-02-14 10:31林鸿辉刘建华郑智雄胡任远罗逸轩
计算机工程与应用 2023年3期
林鸿辉,刘建华,郑智雄,胡任远,罗逸轩
1.福建工程学院 计算机科学与数学学院(原信息科学与工程学院),福州 350118
2.福建省大数据挖掘与应用技术重点实验室,福州 350118
情感分类(sentiment classification)与对话行为识别(dialog act recognition)是两个相联的任务。情感分类任务是将每条语句添加上标签,表示出说话者的隐藏意图;对话行为识别任务同样是对语句添加标签,来表示出说话者的显示意图。具体地来说,情感分类任务是将一系列的语句(u1,u2,…,uN)添加上与之对应的情感标签(y1s,y2s,…,yNs),其中N代表对话中的语句数量。同样地,对话行为分析任务也是对一系列语句预测的分类任务,有对话行为标签(y1d,y2d,…,yNd)。
在对话系统中,有两个关键的因素影响着情感分类与对话行为识别两个任务,一是跨任务的交互信息,二是语句的上下文信息[1]。例如,图1展示的对话取自于Mastodon公开数据集中的一段对话,其中虚线表示的箭头为跨任务交互信息,实线箭头表示为上下文信息。说话者A的对话行为是陈述,而情感为积极。现在,假若要对说话者B所说的语句情感预测,由于说话者A与B正在进行对话,而说话者B的对话行为是赞同,那么说话者B的情感有更大的概率也同为积极情感。这意味着上下文信息与跨任务交互信息对预测标签来说都是至关重要的。所以,将情感分类任务与对话行为识别任务联合训练是非常必要的。

图1 Mastodon数据集中的对话示例Fig.1 Sample conversations in Mastodon dataset
近年来,研究者们利用跨任务交互信息与上下文信息协同,提出了不同模型方法,其主要有三种模型,如图2所示的。第一种模型只利用了跨任务交互信息的模型,如图2(a)所示。例如,Cerisara等人[2]为了利用跨任务交互信息,提出了JointDAS模型联合训练情感分类任务以及对话行为识别任务,该模型的输入为词嵌入序列,该模型共有两层,第一层使用BiLSTM生成包含上下文信息向量;第二层为标准RNN,并将RNN的输出分别传递到两个多层感知机中,一个用于对话行为识别另一个用于情感分类,但该模型只利用了跨任务交互信息而没有利用对话上下文信息,只利用跨任务交互信息而没有利用文本上下文信息的方法无法让模型学习到对话语句之间的关联,导致模型无法充分学习文本信息。第二种模型只利用上下文信息的模型,如图2(b)图所示。例如,Kim等人[3]提出的模型利用先前的行为信息去预测接下来的行为标签,也就是只利用了上下文的信息而没有利用跨任务交互信息去构建模型,这样的做法等于将两个相关联的任务分别建模,同样也无法充分利用对话文本信息。Qin等人在2020年提出DCRNet[4]模型,该模型利用了Co-Attention机制建立了关系池对两种任务的交互信息采集并且该模型取得了当时最先进的性能,但是该模型忽略了文本上下文信息。近期,Qin等人提出了Co-GAT[1]模型,该模型利用图注意力网络[5]很好地利用了跨任务信息以及对话上下文信息对语句标签完成预测,并且取得了很好的效果,但是该模型在对对话文本编码时只是简单地将同一说话者所说出的语句连接,从而产生N个对话者数量的连通分量输入到图注意力网络中,然后再将图注意力网络的输出复制成两个相同的信息向量向前传递,这样简单的复制生成两种任务的信息向量并不能使后续的模型充分利用编码信息,本文后续的实验中也证明这点。
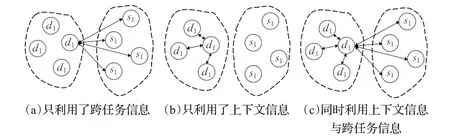
图2 联合对话行为识别与情感分类任务的方法Fig.2 Strategies of joint dialogue behavior recognition task and emotion classification task
本文提出一种新的模型跨任务协同图注意力网络(MGAT)去编码跨任务信息以及上下文信息,使模型框架在编码时就能从不同任务中学习到交互信息,并且使两种任务的信息向量相互影响,使后续模型更好地利用所产生的信息向量。
1 协同交互式图注意力网络
为了能够在一个模型里同时对输入文本上下文信息和不同任务交互信息建模,2020年Qin等人提出了协同交互式图注意力网络模型[1(]co-interactive graph attention network,Co-GAT),该模型分为三个模块,其结构如图3。第一模块为编码层,如图3左边模块,其利用图注意力网络对文本编码,产生向量,为中间提供初始信息。第二模块为模型的核心模块,是基于图注意力网络的协同交互层,如图3的中间模块,其提出了两种边连接方式,用于构建输入的图结构。一种连接为跨语句连接,具体为目标语句会与其他相同任务的语句信息连接;另外一种为跨任务连接,也就是目标语句会与不同任务的语句信息连接;两种连接实现将两种任务联合建模并且同步更新。第三模块为解码层,如图3右边模块,包含两个独立的解码器,其分别对应情感分类任务与对话行为识别任务。协同交互式图注意力网络模型在实验中取得了很好的效果,证明了图注意力网在对多任务联合建模上十分有效。
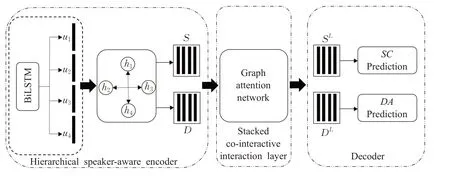
图3 协同交互式图注意力网络Fig.3 Co-interactive graph attention network
但是该模型左边模块的编码器存在弊端,即无法采集输入文本序列的跨任务交互信息。针对该问题,本文提出了对话行为识别以及情感分类联合训练模型,改进图3模型的第一个模块,并且取得了很好的效果。
2 多任务协同图注意力网络
本章提出一种多任务图注意力网络(MGAT),该网络抽取两个相关任务之间的关联信息与文本上下文信息,并利用该网络构建分层对话注意力编码层,该编码层替换了图3模块的第一个模块,即对话交互注意力编码层,如图4所示。相较于Co-GAT[1]中提出的分层对话注意编码器,本文提出的方法解决了对文本编码时忽略了跨任务交互信息的弊端,使模型更好地学习初始文本中的跨任务信息。并且对图3中的第二与第三个模块进行改进。新模型命名为多任务协同图注意力网络(multitask synergic graph attention network,MSGAT)。
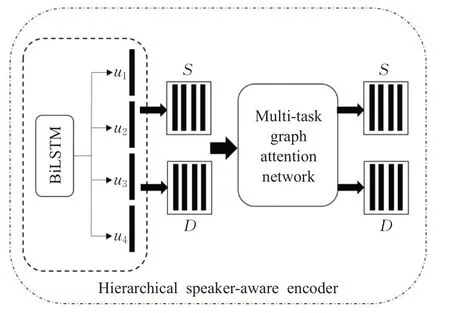
图4 分层对话交互注意力编码层Fig.4 Hierarchical interactive encoder
2.1 多任务图注意力网络
在开始对本文提出的分层对话交互注意力编码器描述之前先介绍多任务图注意力网络。本文提出多任务图注意力网络(MGAT),该网络被应用在分层对话交互注意力编码器中,如图4所示,MGAT具体结构形式如图5,其中虚线与实线代表两个不同任务。该网络能够更好地实现跨任务之间的关联信息以及文本的上下文信息学习。该网络借鉴了图注意力网络的思想,并且整合了多任务之间跨任务交互信息以及节点之间的关联信息,计算出不同任务各自的特征信息,继而再计算不同任务之间的交互信息,该信息体现出两种任务之间的隐含关联,使多种任务相互影响从而提高性能。
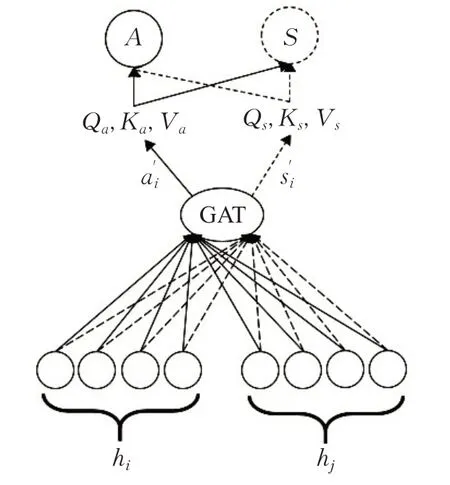
图5 多任务图注意力网络Fig.5 Multi-task graph attention network
多任务图注意力网络的输入为初始节点特征H={h1,h2,…,hN},输出交互节点信息为A′={a1,a2,…,aN},S′={s1,s2,…,sN}。其具体计算过程及其公式如下:
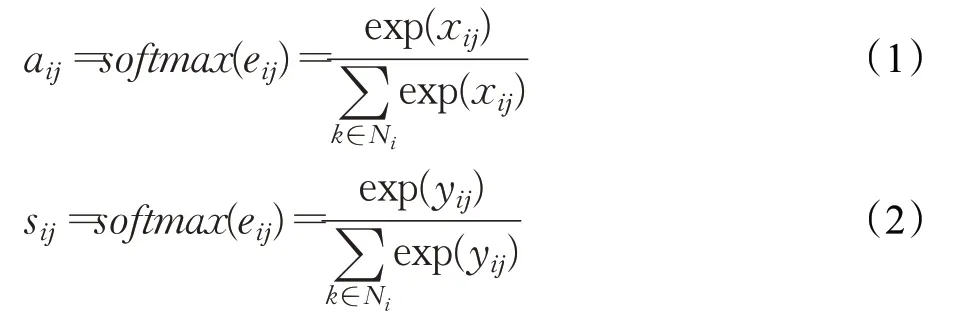
其中,j代表与i相邻的节点,k∈Ni,Ni表示所有与目标节点相邻节点的集合,注意力值xij与yij代表两个不同任务中邻接节点对目标节点信息的重要程度,使用softmax函数对两个不同的注意力值分别归一化,得到图注意力分数节点i与节点j之间的注意力分数aij与sij,使用该分数描述邻接节点与中心节点的关联程度,公式如下:
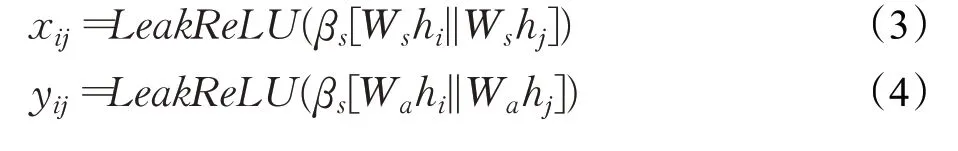
其中,hi代表目标节点的特征信息,||代表拼接操作,hj代表目标节点邻接节点特征信息,β与W为可训练参数。继而使用两个注意力分数分别对两个不同任务的目标节点初始特征向量更新,公式如下:

为稳定化模型的学习过程,采用各自独立的多头注意力机制对目标节点向量更新,如下:

其中,K代表多头注意力机制的堆叠次数,σ(·)表示非线性激活函数,Wk代表第k个注意力机制下的可训练参数。为了使模型学习到跨任务的交互信息,使用交互注意力机制[6],分别将a′i与s′i分别映射为与Transformer类似的queries(Qa,Qs),key(Ka,Ks),values(Va,Va),继而获得跨任务交互信息,公式如下:
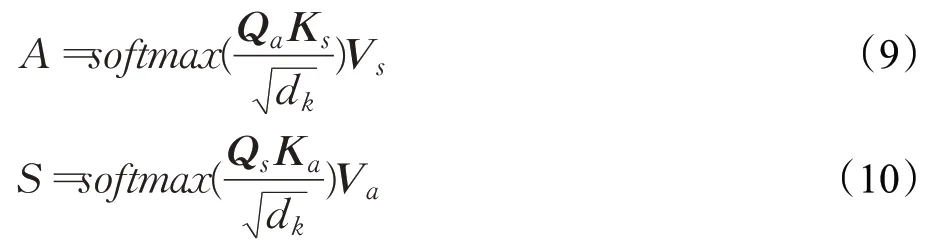
其中,dk为矩阵Q、K的维度,Ca、Cs为MGAT最终输出,该向量包含了节点与节点之间的信息以及跨任务交互信息以方便交给下游模型处理。
2.2 分层对话交互注意力编码器
分层对话交互注意力编码器是模型的第一个模块,该模块结构如图4所示,其作用是挖掘对话中情感分类和对话行为识别两种任务的隐性共享信息,利用这些信息使两种任务信息相互影响。对话文本信息的采集使用双向长短期记忆人工神经网络[7(]BiLSTM),可以捕捉单词之间的关系信息。本文采用语句级的BiLSTM对文本信息采集:对于给定的输入对话文本信息C=(u1,u2,…,uN),其包含N条语句,第t条语句ut=(w1,w2,…,wn)包含n个单词,BiLSTM读取从前向后以及从后向前的单词信息,获取单词上下文语义信息,产生向量信息H={h1t,ht2,…,htn},然后编码器通过最大池化操作,将语句向量压缩成et,最后语句级向量信息E=(e1,e2,…,eN)作为输出向后传递,具体公式如下:
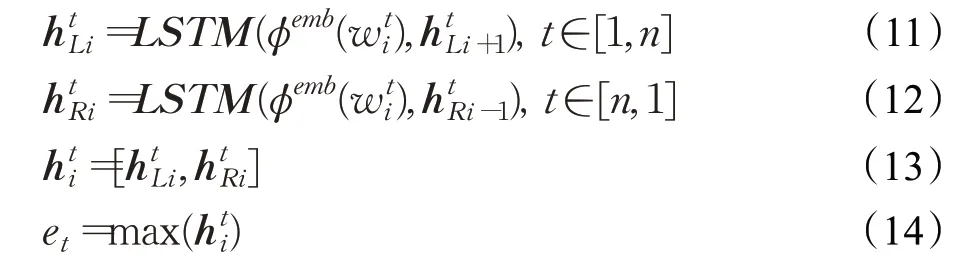
其中,表示从左往右获得的语义信息,表示从右往左获得的语义信息。
在接收到语句级信息向量后,将向量E作为输入传递到多任同图注意力网络(MGAT)中,该网络的作用是挖掘对话信息,它可以使模型更好地理解对话者的情感以及行为意图,并且使两种信息相互影响,继而更充分挖掘情感分类与对话行为识别两种任务之间的联系。对于多任务图注意力网络的输入的图结构有如下定义:
顶点定义:在对话中的每一条语句都分别看作为图的一个顶点。每个顶点都代表着一句话的初始特征向量ei,i∈[1,2,…,N],N对话中语句数量,因此节点特征向量表示为E=(e1,e2,…,eN)。
边定义:为了使多任务图注意力网络更好地学习到对话上下文信息,本文将同一对话者所说的语句信息用边连接,即任意一个从同一对话者说出的语句,该语句所代表的信息节点ei都存在边连接另一句该说话者说出的语句信息节点ej,并且每个节点都存在自连接的边。定义一个邻接矩阵A,若第i条语句与第j条语句是同一说话者发出,那么Aii=1,并且每个节点有着一条与自己相连的边Aii=1,否则Aij=0,紧接着模型将对话图信息输入进多任务图注意力网络中,最终输出有如下公式:
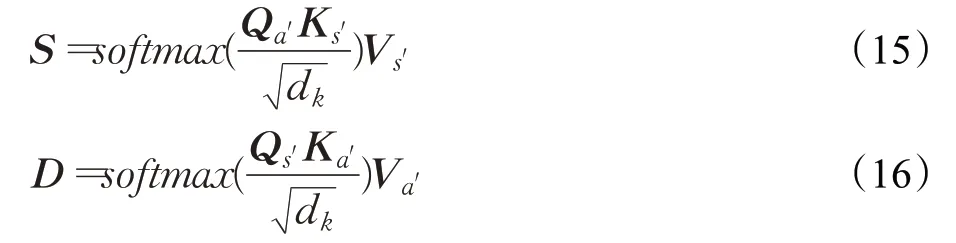
其中,S代表学习了跨任务信息以及对话上下文信息的情感分类信息向量。类似地,D代表经过交互跨任务学习的行为识别信息向量,分别记作S=(s1,s2,…,sN),D=(d1,d2,…,dN)。
然后将两个向量S与D往第二模块协同交互层传递,即图3的中间模块。最后使用两个独立解码器分别对情感分类以及对话行为识别任务联合训练,即图3的右边模块。最后,MSGAT模型利用反向传播训练权重。
2.3 强化协同信息层
图3中的第二个模块利用图注意力网络获取包含跨任务信息与跨语句信息的向量,对话行为识别更新公式如下:

其中Ni表示节点i的所有邻接节点的集合,包含了上下文信息节点与不同任务信息节点。与前者类似,情感分类向量更新公式如下:
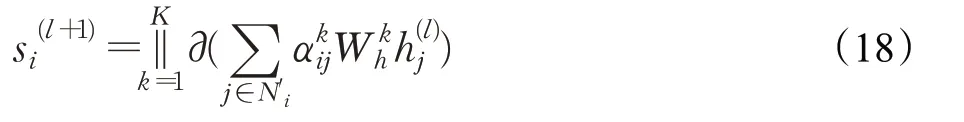
该方法将跨语句连接与跨任务连接直接合并,缺失对两种连接方式的权重。针对该问题本文做出改进,将该层命名为强化协同信息层。
由于训练数据不存在长距离依赖问题,应用两个独立的BiRNN[8]到分层对话交互注意力编码器产出的向量,增强对话语句序列的上下文关联性,同时放大不同任务信息的区别增加任务的特异性,得到D0=[d10,d20,…,dN0],S0=[s10,s02,…,s0N],公式如下:

为了加强模型产出向量的表达能力,本文对图3第二个模块进行了改进,对输入的图结构有如下定义:
顶点定义:图中有2N个节点,其中N个节点为对话行为识别任务信息,另外N个节点为情感分类任务节信息。公式(19)、(20)的结果D0与S0对应对话行为识别任务与情感分类任务的初始节点。
边定义:图结构中的顶点之间存在两种连接方式。
跨语句连接:将上下文信息节点连接。如果节点j与节点i是相同任务的信息节点,则在两个节点之间构建跨语句连接,定义一个邻接矩阵A,则有Aij=1。
跨任务连接:将不同任务的信息节点连接。如果节点j与节点i是来自不同任务的信息节点,则建立跨任务连接,邻接矩阵A有Aij=1。
对于两种不同的连接方式,本文提出区分两种不同连接的权重,使模型在训练中适应这两种连接各自的重要程度。对话行为识别向量更新公式如下:
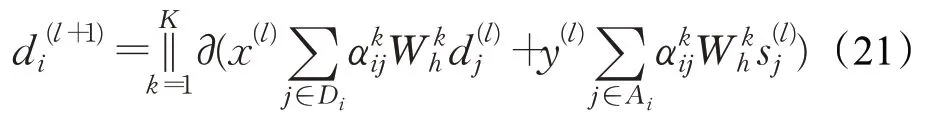
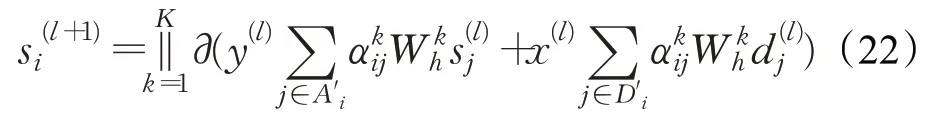
并且使用残差连接抑制训练时网络退化与梯度消失问题,公式如下:

2.4 联合训练解码器
在模型最后将对话行为识别任务与情感分类任务联合训练,并且对两个不同任务设置超参数,公式如下:

其中,L1与L2表示两个不同任务的交叉熵损失函数,α、β为超参数,使模型在训练时可以精调两种任务的损失函数的占比。
3 实验
3.1 实验数据
为了对模型验证,本实验分别对两个公开对话数据集Mastodon和Dailydialog做预测实验。Dailydialog数据集有11 118段对话用于训练,1 000段对话为验证集,1 000段对话为测试集。Mastodon数据集的训练集为243段对话,测试集为267段对话。
3.2 实验设置
实验使用Adam[9]优化参数,选择在训练时的验证集中最好模型对测试集的评估。所有实验都在GeForce 3070上运行。为抑制过拟合,本文采用Hinton等人[10]提出的Dropout策略,在模型每次迭代过程中随机地丢弃隐藏层中的部分神经元。表1为具体实验参数。
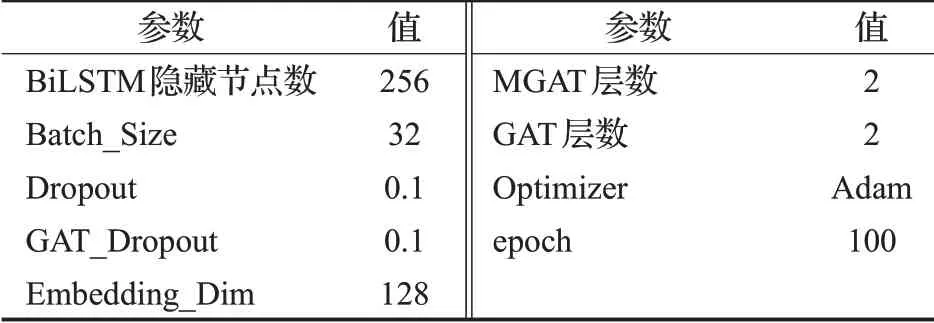
表1 实验参数Table 1 Experiment parameter
3.3 评价指标
本实验包括两个分类任务,两个任务都是多标签分类任务,本文的实验采用正确率P(%)、召回率R(%)以及F1分数(%)评价模型的预测效果。计算公式如下:

其中,TP代表真阳性,预测为正,标签实际也为正;FP代表假阳性,预测为正,标签实际为负;FN代表假阴性,预测为负,标签实际为正。F1值越大表明模型在分类任务中预测的精确度越高,模型的性能越好。
3.4 实验结果与分析
本模型在Mastodon和Dailydialog公开数据集上测试,并且分别与对话行为识别模型HEC、CRF-ASN、CASA与对话情感分类模型DialogueRNN、DialogueGCN以及联合模型JointDAS、IIIM、Co-GAT模型对比,此外,本文在实验中设置了其他任务的联合模型进行对比。结果如表2所示。
表2的第一部分为对话行为识别单任务模型的实验结果,第二部分为情感分类单任务模型的实验结果,第三部分为联合模型的实验结果,第四部分为联合槽位填充与意图检测任务的联合模型。其中,HEC[11]模型使用了一个分层Bi-LSTM-CRF去解决对话行为识别问题,该模型捕捉了词语之间与语句之间的依赖关系。CRF-ASN[12]使用了用于对话行为识别的crf-attentive,该模型动态地将语句切分,从而获取对话上下文信息。CASA[13]这项工作中利用了上下文自注意力机制为对话行为识别任务建模。DialogueRNN[14]模型提出了一种基于RNN的神经网络结构,用于挖掘对话中的情感信息,并利用该信息解决对话情感分类问题。DialogueGCN[15]模型提出了一种对话图卷积网络去捕捉所有对话语句之间的依赖关系,用这种方式为对话情感分类问题建模。JointDAS[2]模型使用了一种多任务模型联合情感分类以及对话行为识别任务。IIIM是一种集成的神经网络模型,同时训练情感分类以及对话行为识别两种任务。DCR-Net使用了一种关系层为跨任务交互信息以及语句上下文信息单独地建模。Co-GAT[1]模型使用了图注意力网络为跨任务交互信息以及上下文信息联合的建模,并且在当时达到了最先进的性能。从表中的结果可以看出:(1)本文提出的模型性能优于单独建模情感分类模型与对话行为识别模型。这表明,利用跨任务交互信息联合建模是有效的,它可以更好地挖掘出在对话中的隐性信息从而让模型更充分地学习,并达到比单独建模的模型更好的效果。(2)与其他联合模型相比,本文提出的模型有很大的改进,并且取得最先进的性能。在Mastodon数据集上,本文的模型在情感分类与对话行为识别的F1分数上分别比Co-GAT高出了2.0%和1.3%,在Dailydialog数据集上也呈现出了同样的趋势。这说明了多任务协同图注意力网络对隐藏交互信息挖掘的有效性。最后,本文在实验中引入了Co-Interactive Transformer[16]、AGIF[17]以及GL-GIN[18]模型进行对比,为了契合数据集对模型进行微调,其中Co-Interactive Transformer模型通过建立相关任务之间的双向连接考虑交叉影响,而不是采用普通的Transformer中的自注意力机制,并且提出一种协同交互模块实现任务间的特性传递。AGIF模型提出了一种交互层,该层可以提取其中一个任务的信息集成到另一个任务中,从而建立强相关性。GL-GIN模型是一种快速非自回归模型,该模型建立一种关系槽缓解两种任务信息不协调问题,并且训练速度十分可观。但是由于这些联合模型对于初始执行任务的不同,模型设计并没有充分利用好对话上下文信息与跨任务交互信息等原因,所以在对话行为识别与情感分类任务联合训练上并不能达到很好的水平。从图6到图9对比中可以看出,本文提出的模型收敛速度达到良好水平,验证了本文提出方法的有效性。
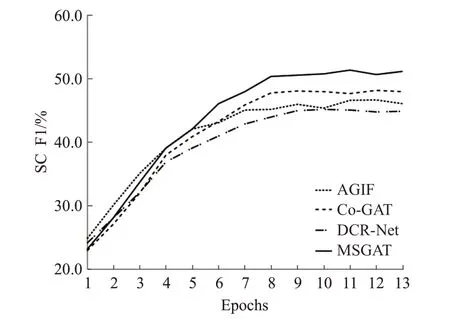
图6 Mastodon数据集上四种模型情感分类F1分数变化Fig.6 Four models score change of sentiment classification on Mastodon dataset
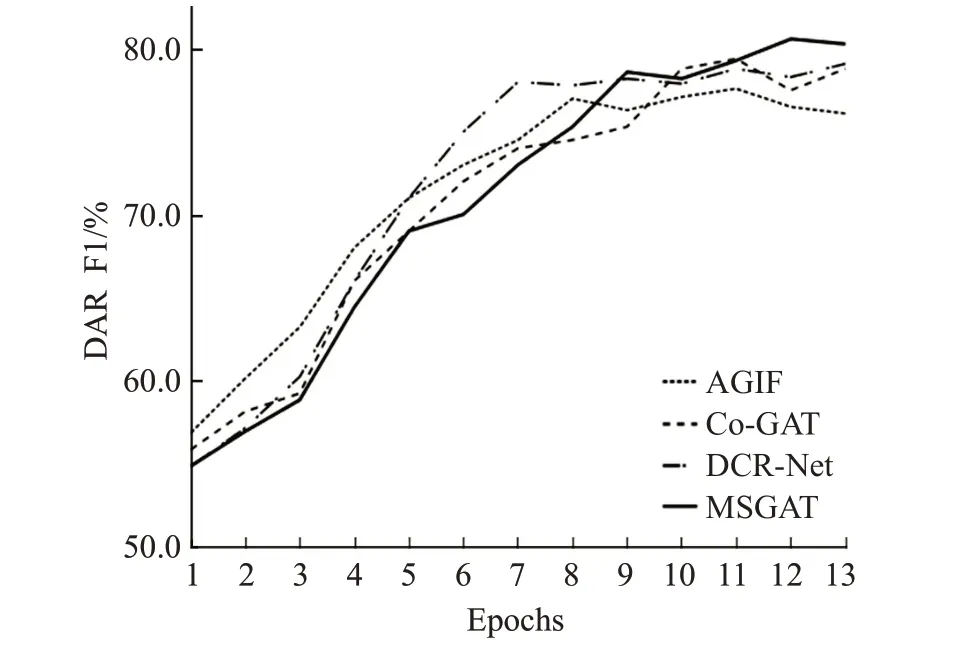
图9 Dailydialog数据集上四种模型对话行为分析F1分数变化Fig.9 Four models score change of dialog act recognition on Dailydialog dataset
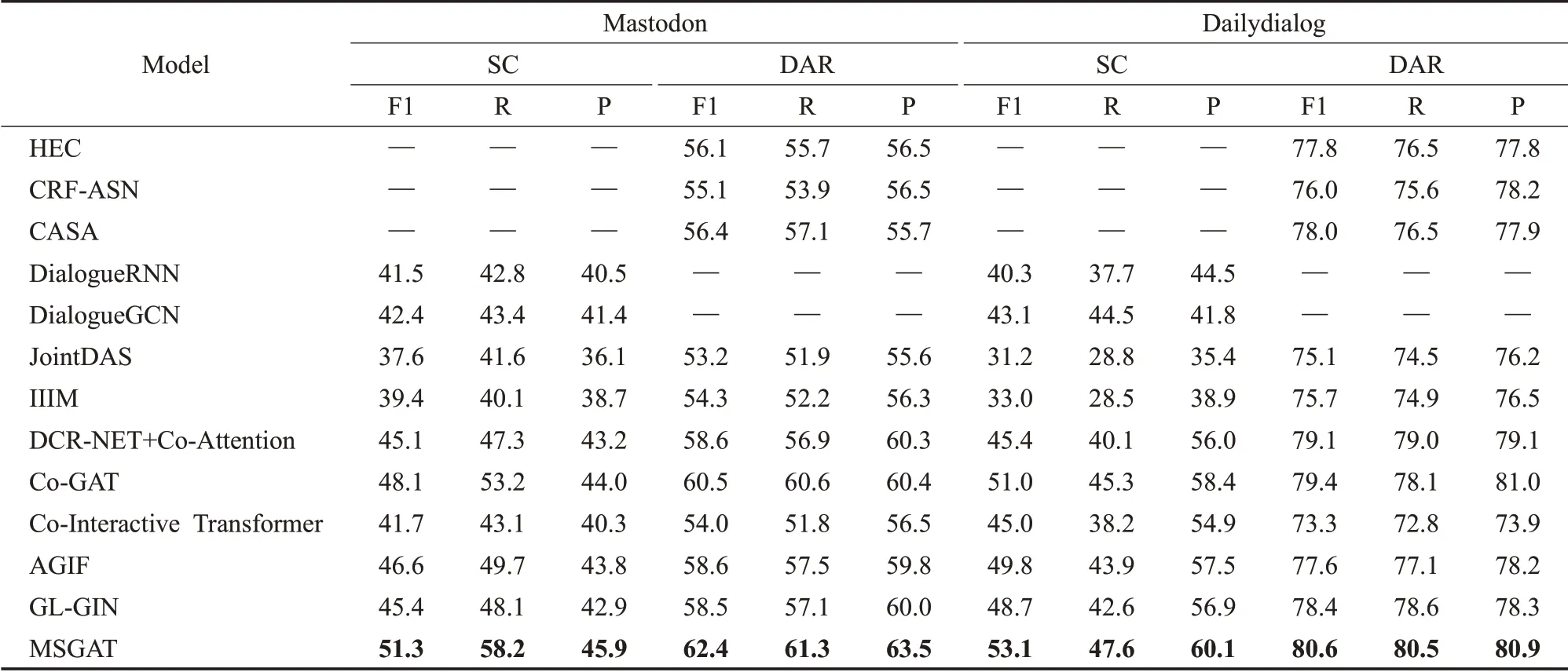
表2 在Mastodon与Dailydialog数据集上的对比实验结果Table 2 Results of comparative experiment on Mastodon and Dailydialog data sets 单位:%
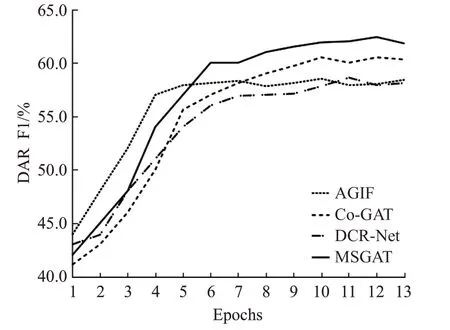
图7 Mastodon数据集上四种模型对话行为分析F1分数变化Fig.7 Four models score change of dialog act recognition on Mastodon dataset
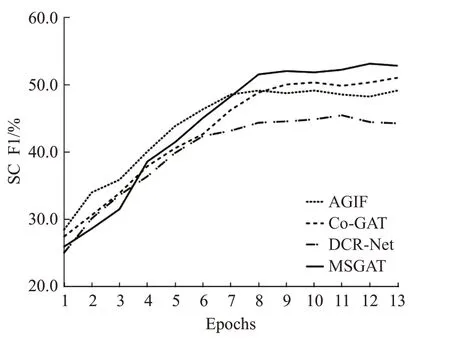
图8 Dailydialog数据集上四种模型情感分类F1分数变化Fig.8 Four models score change of sentiment classification on Dailydialog dataset
3.5 消融实验
尽管本文提出的模型取得了很好的效果,但依然需要了解在协同图注意力网络中的各个部件对最终性能有多大程度的影响,因此本文对模型中的各个部件消融。实验的效果如表3所示。
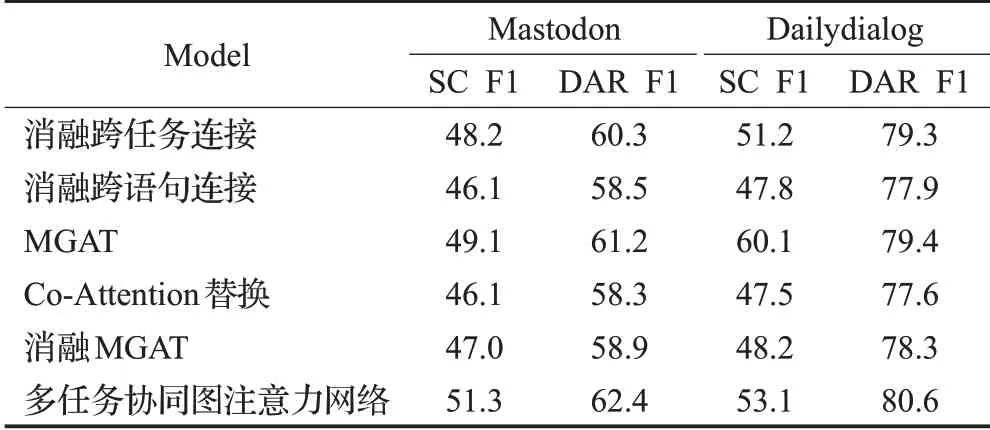
表3 在Mastodon与Dailydialog数据集上行进消融实验结果Table 3 Results of ablation experiments on Mastodon and Dailydialog data sets 单位:%
在消融跨任务连接实验中,将跨任务连接从模型中删除。因此,在这时的模型只考虑了上下文信息而忽略了跨任务交互信息,从表中可知,在Mastodon和Dailydialog数据集中情感分类的F1分数下降了3.1%与1.9%;而对话行为识别的F1分数分别下降了2.1%与1.3%。本文将出现这一现象的原因归咎于跨任务信息的缺失,导致模型性能降低。
在消融跨语句连接实验中,与消融跨任务连接实验类似,删除了跨语句连接,从表中可以看出,这时模型的性能出现了明显的下降。结果验证了上下文信息的有效性,该信息可以减少文本歧义从而提高模型性能。
接着,在只使用MGAT模型的实验中,情感分类与对话行为识别的F1分数也出现了不同程度的降低,这是因为跨任务信息与上下文信息相互的影响力被削弱。同时采用Co-Attention机制替换强化协同信息层,性能同样也出现了不同程度的削弱,这两个实验也证明了Qin等人提出的利用图神经网络为两种信息建模是有效的。值得注意的是,在实验中只使用MGAT的性能已经超过Co-GAT,证实了本文提出的MGAT模型在多任务中的有效性。
最后,消融MSGAT的核心模块,模型的性能出现了大幅的降低,出现这种现象的原因是模型被削弱了跨任务信息与上下文信息的交互,也证明了多任务图注意力网络的有效性。
3.6 BERT组合实验
为了探索联合BERT[19]预训练模型产生的效果,本文设置了BERT与MSGAT的组合实验。本文将分层对话交互注意力编码器中的BiLSTM替换为BERT,模型的其他组件保持不变。本文在Mastodon数据集上实验,实验中分别与DCR-Net和Co-GAT与BERT组合以及不组合BERT的MSGAT对比,结果如图10。从结果中可以看出BERT预训练模型与MSGAT组合可以得到非常好的效果,模型的性能得到了卓越的提升,并且提出的MSGAT与BERT组合相较于其他对比模型的性能,领先进一步拉开,再次证明了本文提出模型的有效性。
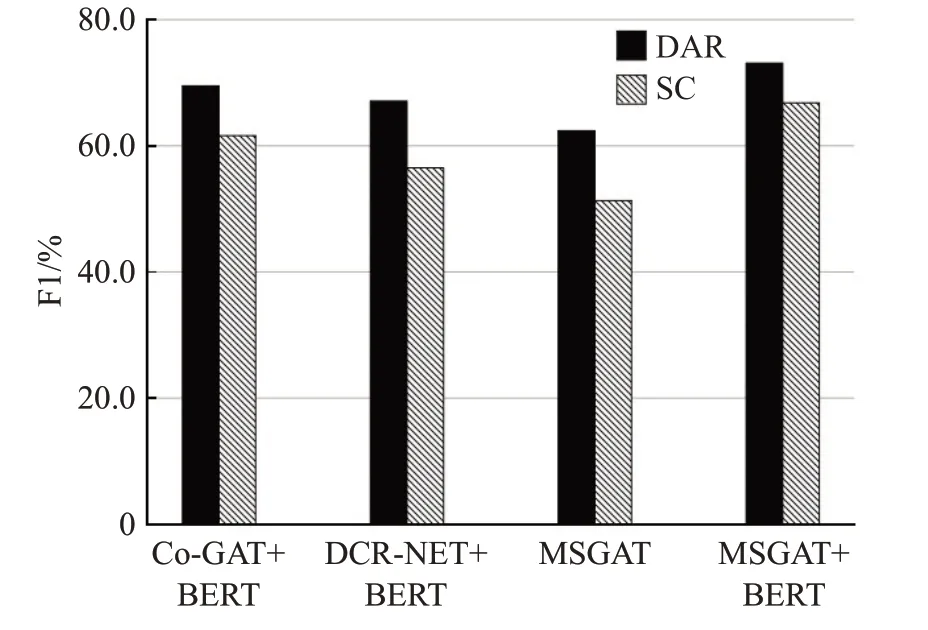
图10 模型与BERT组合实验Fig.10 Combination experiment with BERT
3.7 模块堆叠实验
设置了模块堆叠实验,分别在Mastodon数据集上对多任务图注意力网络与强化协同信息层中的图注意力网络进行叠加,结果如图11、图12所示。从图中可以看出,当模型叠加两层时性能最好,这是因为堆叠模型可以更好地模拟两个任务的交互,当堆叠层数超过2时,模型性能开始下降,本文将原因归咎于随着网络深度的增加出现过拟合以及梯度消失等问题[20]。
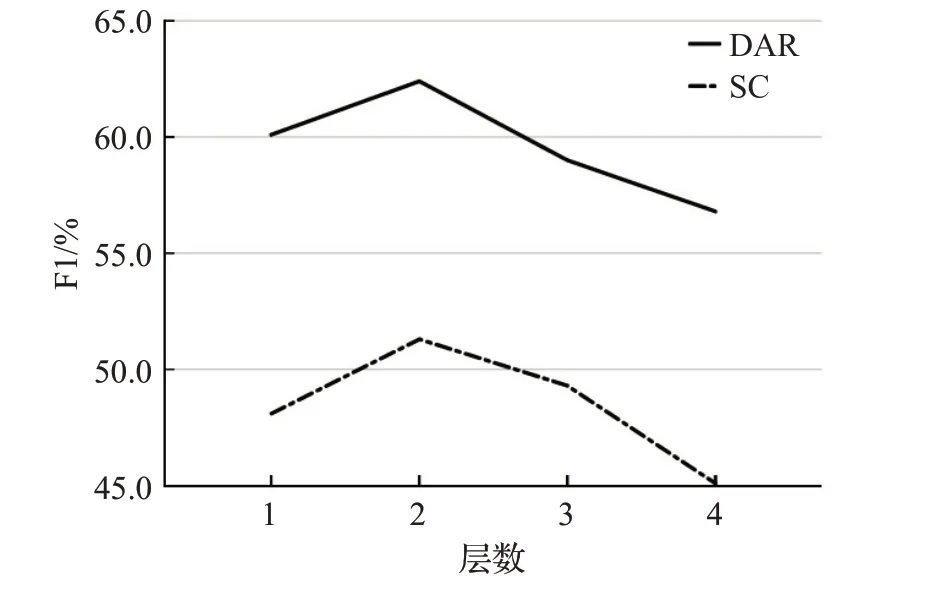
图11 堆叠不同层数MGAT时模型性能Fig.11 Model performance at different layers of MGAT
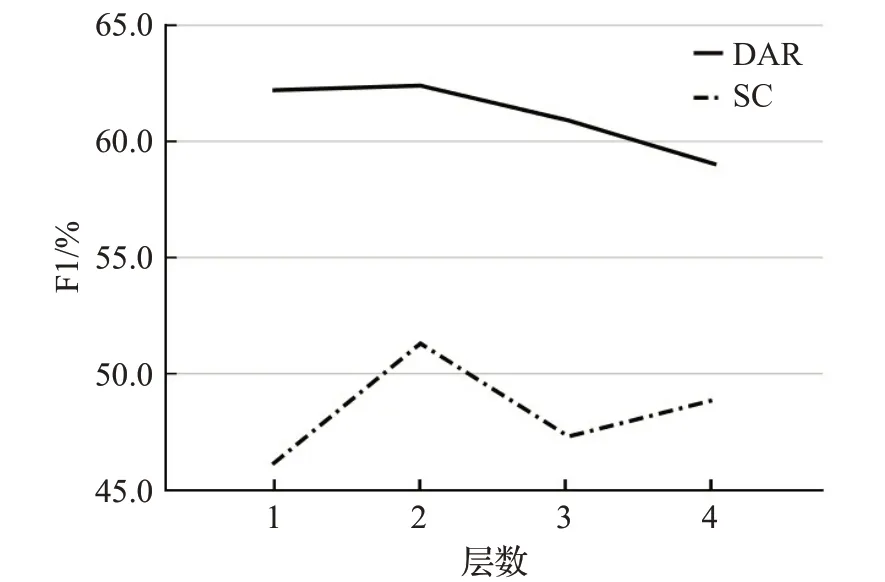
图12 堆叠不同层数GAT时模型性能Fig.12 Model performance at different layers of GAT
4 结论
本文针对多个相关联的任务提出了多任务图注意力网络(MGAT),并以该网络为核心搭建了多任务协同图注意力网络(MSGAT)。为解决情感分类与对话行为识别任务,该模型构建了跨语句连接以及多任务连接网络,使模型充分学习语句上下文信息以及跨任务交互信息。实验中证明了,该模型具有比以往的模型更好的效果,并且在与BERT预训练模型组合实验中,本文提出的模型与BERT组合得到的提升比其他模型与BERT组合的提升更显著,这说明了BERT预训练模型与MSGAT是互相补充的。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年4期)2021-06-09
新世纪智能(语文备考)(2020年4期)2020-07-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
