
融合关键点属性与注意力表征的人脸表情识别
2023-02-14 10:31高红霞
计算机工程与应用 2023年3期
高红霞,郜 伟
1.河南工程学院 软件学院,郑州 451191
2.信息工程大学 理学院,郑州 450001
人脸表情作为展现情绪变化的媒介,时刻反映人类的内心活动以及心理状态。不同的情绪状态会产生差异化的行为和认知改变,因此,在智慧医疗、学生行为分析、驾驶员情绪监测等领域,人脸表情识别成为研究的热点[1]。Ekman[2]描述六种基本表情类型:愤怒、快乐、悲伤、惊讶、厌恶和恐惧,这些表情通常由面部肌肉的细微运动所引起,造成图像中不同类型之间差异不明显。此外,在表情图像采集中,由于光照、角度、表情强度等变化,使得人脸表情识别充满挑战[3]。
传统的人脸表情识别方法采用手动设计特征结合分类器实现整个识别过程,其性能主要依赖特征表达的有效性。局部二值模式(local binary pattern,LBP)、Gabor小波、SIFT、SURF等特征及其变体[4-5]由于其良好的表征性能,在早期得到了广泛的应用。张哲源等[6]提出一种结合分块LBP特征与投影字典对学习的表情识别方法。Revina等[7]在LBP的基础上提出显性梯度局部三元模式(DGLTP)特征。Shi等[8]提出了一种特征点约束算法来确定点的最优位置,以有效地表示变化区域,并利用SIFT描述子提取区域梯度信息作为特征参数进行识别。Meng等[9]通过融合局部Gabor特征、LBP特征和关节几何特征,提出一种基于变换多级特征融合和改进加权支持向量机的表情识别方法。虽然这些方法在实验室数据集上性能良好,但在实际复杂场景下,性能往往急剧恶化。
近年来,卷积神经网络(convolutional neural network,CNN)在自然图像处理领域展现出强大的活力,研究者开始热衷于利用CNN强大的非线性映射能力抽取更深层次、更抽象的语义表征来实现鲁棒的人脸表情识别[10-11]。Lu等[12]采用18层残差网络提取深层特征,同时利用CLBP提取纹理特征,并将两者融合后输入网络进行识别。Shi等[13]在ResNet基础上引入树形结构构建网络,提出一种多分支交叉连接卷积神经网络(MBCCCNN)的人脸表情识别方法。崔子越等[14]通过对预训练的VGG模型进行微调,并在损失函数中加入FocalLoss进一步提升模型的识别性能。梁华刚等[15]将Inception-V3作为骨干网,通过加入双向LSTM模块捕获表情的时序特征。上述方法通过将整张人脸图像输入到不同的网络,获得最终的表情类别。然而,人脸表情变化非常细微,人脸图像中包含大量非表情的背景信息,导致网络很难关注到人脸图像中的细微表情变化,降低识别的精准度。
为了减小人脸中非表情区域对神经网络识别造成的干扰,研究人员根据图像处理中抑制背景噪声影响的原则,提出了一些新的消除背景干扰的人脸表情识别方法。Li等[16]对人脸图片检测后进行感兴趣区域裁剪,并利用CNN网络对裁剪后的区域实现表情分类。钱勇生等[17]提出在网络中输入多视角人脸表情图像,并在残差网络基础上嵌入压缩和奖惩模块提高网络表达能力。姜月武等[11]通过人脸关键点获取最大表情范围以消除非表情区的干扰,将裁剪后的图像输入到带权重分配机制的残差网络中,引导网络学习具有强鉴别力的特征。上述方法通过裁剪人脸的感兴趣区域,从而减小人脸图像中非表情区域的干扰,但裁剪后的图像只包含人脸的局部信息,缺失全局特征。此外,类间差异微小的表情,如:生气、伤心、郁闷等,表情变化多表现为“眉头紧锁、嘴角下拉、脸颊微抬”,其信息差异主要集中在局部关键点区域。这种细微的改变在整张人脸图像网络上难以学习,但是关键点位置包含的信息会发生较大改变(如生气时嘴角关键点下移)。因此,引导网络关注这些关键点的属性信息将对模型识别率的提升至关重要。
为了减小人脸非表情干扰,从而捕获局部表情的细微变化,本文提出一种融合关键点属性与注意力表征的人脸表情识别方法,主要贡献为两个方面:
(1)关键点属性表征机制。通过神经网络提取人脸图像中的关键点信息,利用关键点属性而不是图像全局信息表征人脸表情变化,不仅能够有效避免非表情区域的干扰,而且还可以关注图像中局部位置的细微变化。
(2)基于注意力的特征融合机制。在获得人脸关键点属性的基础上,为了进一步探索关键点之间的关系,引入Transformer的注意力机制,引导网络学习对人脸表情类型更具分辨力的特征表示。最后,在CK+、JAFFE、FER2013三种公开数据集上进行实验验证,最高达到99.22%的识别准确率。
1 融合关键点属性与注意力表征的识别模型
本文提出的表情识别模型主要包括两个模块,其中基于注意力的人脸关键点属性表征模块主要抽取具有表情的区分性的特征,而基于Transformer的特征融合机制则是探索不同特征点属性之间的相关关系,网络结构图如图1所示。
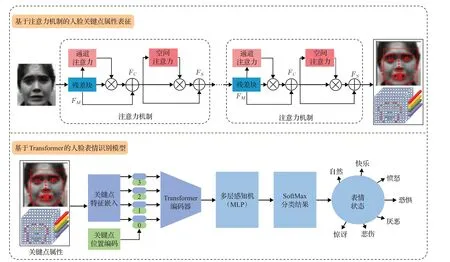
图1 本文算法框架图Fig.1 Overview of proposed framework
1.1 混合注意力模块
传统人脸识别方法直接将整张人脸图像输入网络中推理,进行表情状态的预测。这些方法容易受人脸图像中非表情区域的干扰,很难获得最佳的识别结果[14-15]。因此,本文提出一种基于注意力的人脸关键点属性表征的特征描述符,通过利用卷积神经网络回归获得人脸中的关键点以及对应的关键点特征向量,然后将其通过Transformer模块编码,进而进行表情状态的识别。
注意力机制作为一种模拟人的认知行为所提出的理论,在图像处理方面展现出优异的性能,因而在人脸表情识别领域也受到众多研究者的应用。亢洁等[18]在网络中引入注意力模块,结合迁移学习策略进行表情识别,但是其注意力模块只包含通道注意力,忽略了空间位置关系。程换新等[19]将通过LBP算子与VGG网络提取的特征在通道上通过注意力模块进行融合,同样缺失图像像素的空间关系。
综上所述,可以看出注意力机制已经取得了优异的性能,对本文工作有极大的借鉴参考价值。因此,本文在计算人脸关键点过程中,应用通道和空间的混合注意力模块进一步丰富骨干网的结构,提升其性能。
主要原因有两点:其一,在CNN逐层运算中往往会产生较高的通道数,导致通道间的信息冗余,以至于出现过拟合问题。其二,在关键点检测中,图像的不同位置应该具有不同的重要性,网络在关键点区域应该加强关注,但是卷积核对它们的处理却是相同的。为了解决上述问题,本文引入自适应学习通道和空间关系的注意力网络结构。
通道注意力:在CNN网络的逐层运算过程中,通道数会有所增加,而每个通道对于关键信息的贡献是不同的,因此当通道数过多时,会产生信息冗余。为了解决这一问题,本文采用通道注意力模块,通过利用不同的池化策略压缩输入特征的空间维度,进行通道计算。
此前研究多偏向于采用平均池化作为压缩和激励的模块,而仅使用全局平均池化操作不足以区分人脸属性。而最大值池化则只取覆盖区域中的最大值来保持特征图的最大响应值。基于此,本文采用将全局平均池化和最大池化相结合的策略,通过交叉矩阵乘法获得注意力掩模的通道注意力矩阵,如图2所示。
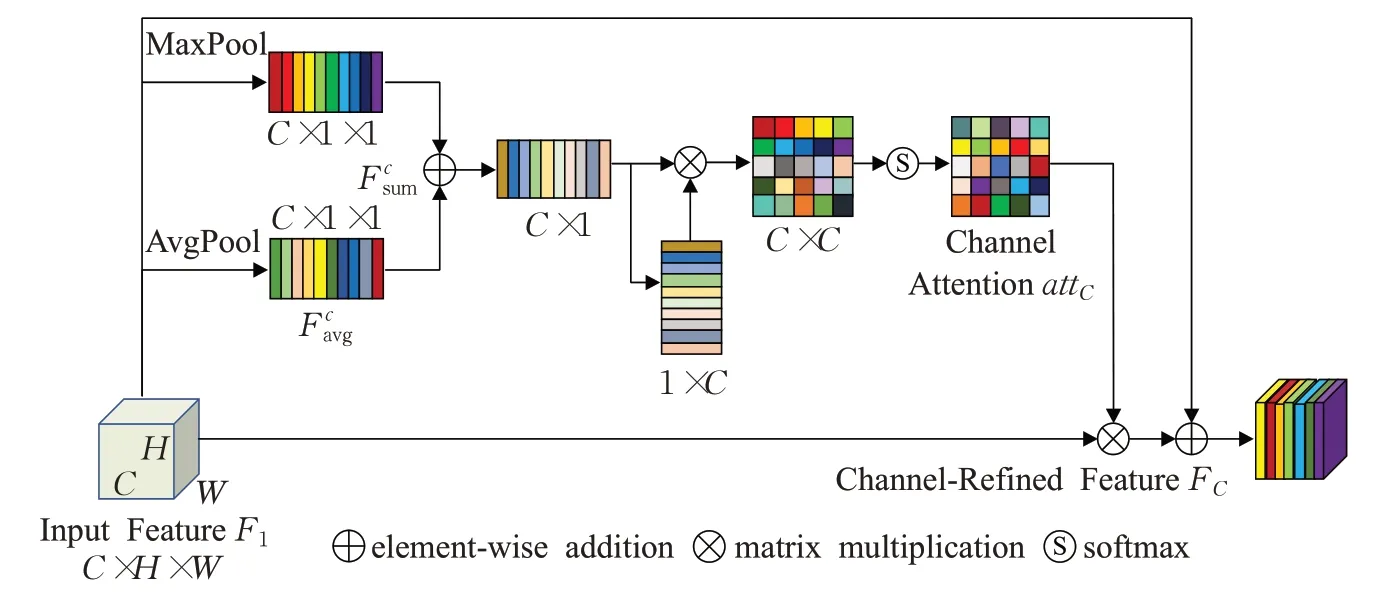
图2 通道注意力模块Fig.2 Channel attention module
首先将输入特征FI∈RC×H×W馈送至通道注意力块,对FI沿空间轴进行并行的全局平均池和最大值池化操作,得到C×1×1维的特征向量和,然后通过对和逐元素求和得到具有特征聚合特性的,使用1×1的卷积处理,再执行PReLU和BatchNorm操作,得到中间的特征图,故有:

其中,∈RC×1×1;⊕表示逐元素求和;∅表示卷积运算。去掉的冗余维度,并对其进行转置,得到尺寸分别为C×1和1×C的特征图,将这两个特征图相乘再通过softmax运算得到最终的通道注意力矩阵attc。

其中,⊗表示矩阵乘法,可得到下式:
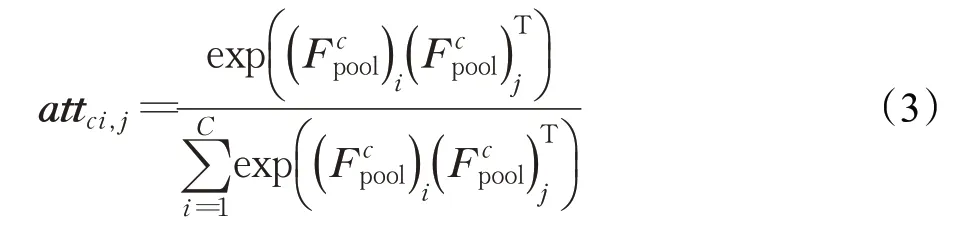
其中,attc∈RC×C是二维矩阵;attci,j为在输入特征映射中第i个通道对第j个通道的影响。最后,将输入特征FI与通道注意力矩阵attc相乘,经过残差学习得到通道精细后的特征FC∈RC×H×W。
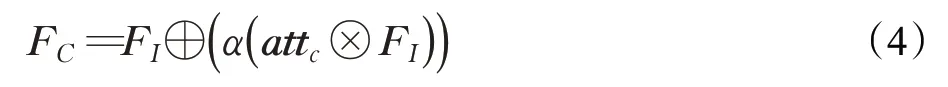
其中,⊕表示元素求和;⊗表示矩阵相乘;α是可学习的参数,一般初始值设为0,以降低前几个训练周期收敛过程的难度。通道注意力矩阵attc可被看作是一个选择器,可筛选出能够捕获人脸特征的最佳滤波器。
空间注意力:在人脸中,五官的位置是具有一定空间关系的,即图像的不同位置具有不同的重要性,而卷积核对它们的处理却是相同的。为了解决该问题,学习特征图中存在的空间结构之间的关系,本文在通道注意力模块的基础上,提出了一个空间注意力模块。将空间注意力模块与通道注意力模块相结合,可以同时获得重要的通道特征及特征之间的空间关系,从而使得最终得到的特征图更精细化,如图3所示。
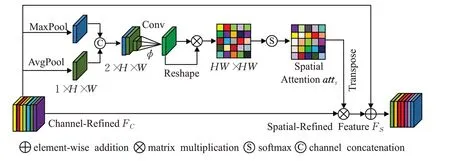
图3 空间注意力模块Fig.3 Spatial attention module
首先将输入的通道细化特征FC∈RC×H×W馈送至空间注意力模块,对FC沿通道轴并行采取全局平均池化和最大池化操作,分别得到尺寸均为1×H×W的特征向量和,采用通道级联的方式合并和构成聚合特征∈R2×H×W。然后使用3×3卷积作用于,卷积步长和填充值均设为1,之后再进行PReLU和BatchNorm运算得到中间特征图。在卷积过程中对步长和填充值的设置可以保证特征图的大小不变,于是有:

其中,∈R1×H×W;∅表示卷积运算。对Fpsool进行维度变换,将其维度转换为HW×1,再进行转置得到1×HW的特征图,对二者执行矩阵乘法和softmax运算,得到空间注意矩阵atts。

其中,⊗表示矩阵乘法,可得到下式:
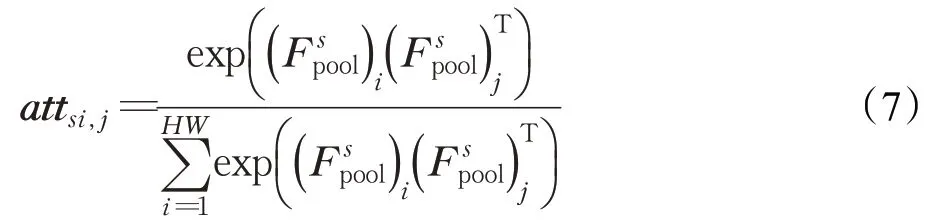
其中,atts∈RHW×HW是二维矩阵;attsi,j表示第i个空间位置对第j个空间位置的影响。最后,将通道细化特征FC与空间注意力矩阵atts相乘,再经过残差学习得到空间精细后的特征FS∈RC×H×W。
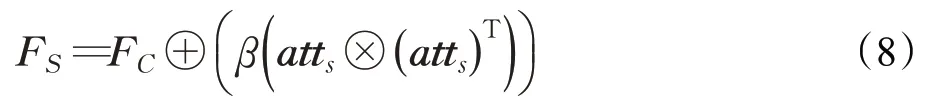
其中,⊕表示元素求和;⊗表示矩阵相乘;β是可学习的参数,一般初始值设为0,以降低前几个训练周期收敛过程的难度。这样空间注意力矩阵atts就可被看作是一个位置掩膜,可以细化通道特征的空间信息,使得特征图能够获取到人脸中具有空间关系的重要特征。
1.2 基于注意力的人脸关键点属性表征
在残差网络的基础上,将通道注意力和空间注意力模块附加到每个残差块之后,为了直观地理解绘制了基于注意力机制的神经网络(CS-ResNet)的残差结构如图4所示。
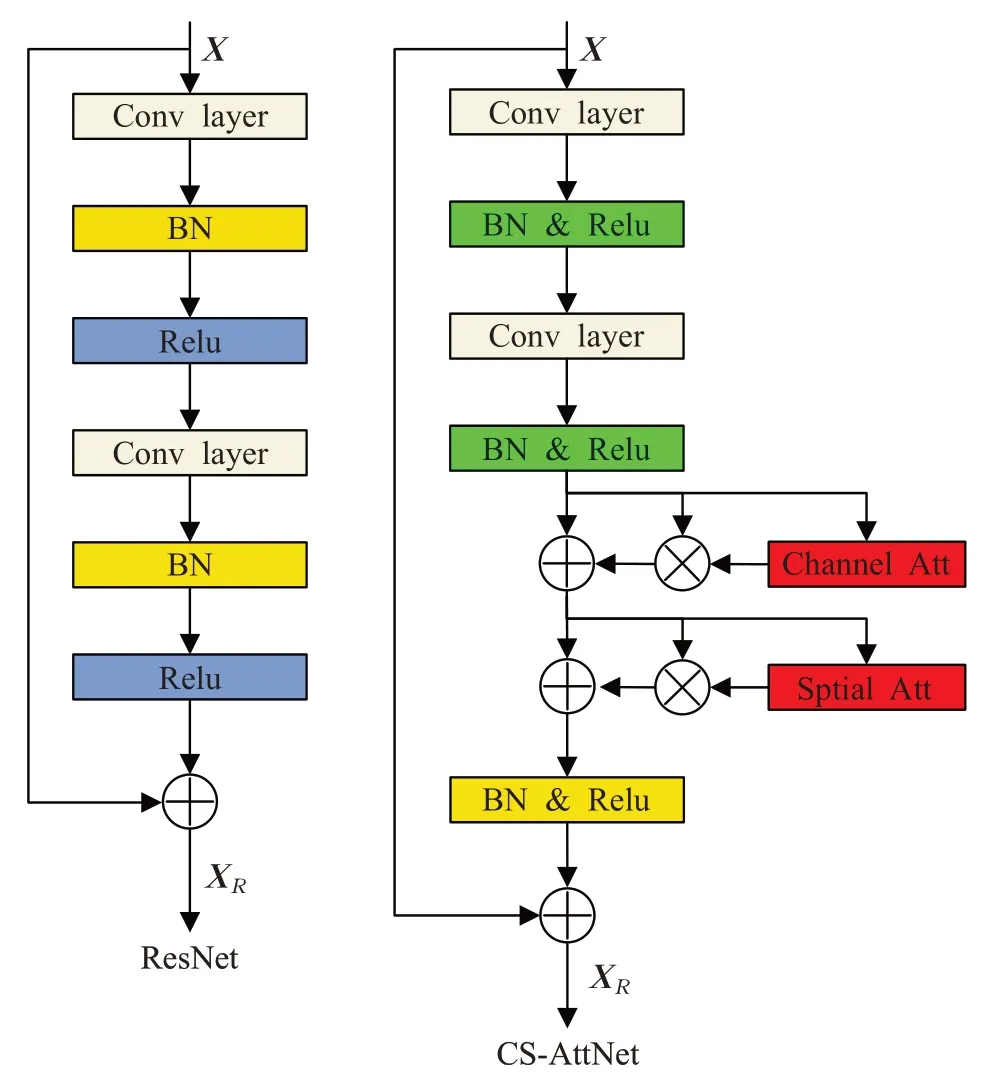
图4 ResNet与CS-AttNet的对比Fig.4 Comparison between ResNet and CS-AttNet
给定中间特征图X,网络首先生成一个通道注意力矩阵,并通过矩阵乘法得到加权特征,然后经过逐元素求和得到通道细化特征。按顺序,使用类似的方式得到空间细化特征。此外,批量归一化是一种被广泛应用的稳定训练的技术,同样采用它加快收敛过程。最后通过残差连接快速学习细化后的特征XR。
通过构建的CS-AttNet网络,在获得人脸关键点位置的同时为每个点抽取对应的特征表示,文中关键点数量设为kp=68,特征维度dim=512,如图5所示。

图5 关键点属性表征示图Fig.5 Keypoints-attributes diagram
经过网络训练,输出端不仅可以获取每个点的位置坐标,也可得到对应点的特征属性,这样为使用Transformer模块去融合关键点之间的相关特征联系奠定基础。
1.3 基于Transformer的人脸表情识别模型
Transformer作为一种自注意力机制,在NLP任务中被首次提出即获得巨大的关注,因其能在所有实体对之间执行信息交换,这种特有的机制及其出色的性能,最近被广泛应用到各种计算机视觉任务中,并且在各自研究领域取得了最好的性能结果[20-21]。
1.3.1 Transformer网络框架
标准Transformer的输入是一维的词嵌入向量,通过获取网络全连接层512维的向量,参照ViT中的参数设置[19],利用可训练的线性投影变换将原始特征映射为768维的向量,文中将此投影的输出称为Embedded-Keypoints。Transformer层由Multi-Head Attention和Multi-Layer Perception(MLP)块的层组成。在每个块之前应用层归一化(Norm),在每个块之后使用残差连接。图6显示了Transformer网络框架的主要结构,通过使用CS-AttNet模型从原始图像中提取关键点特征表示。
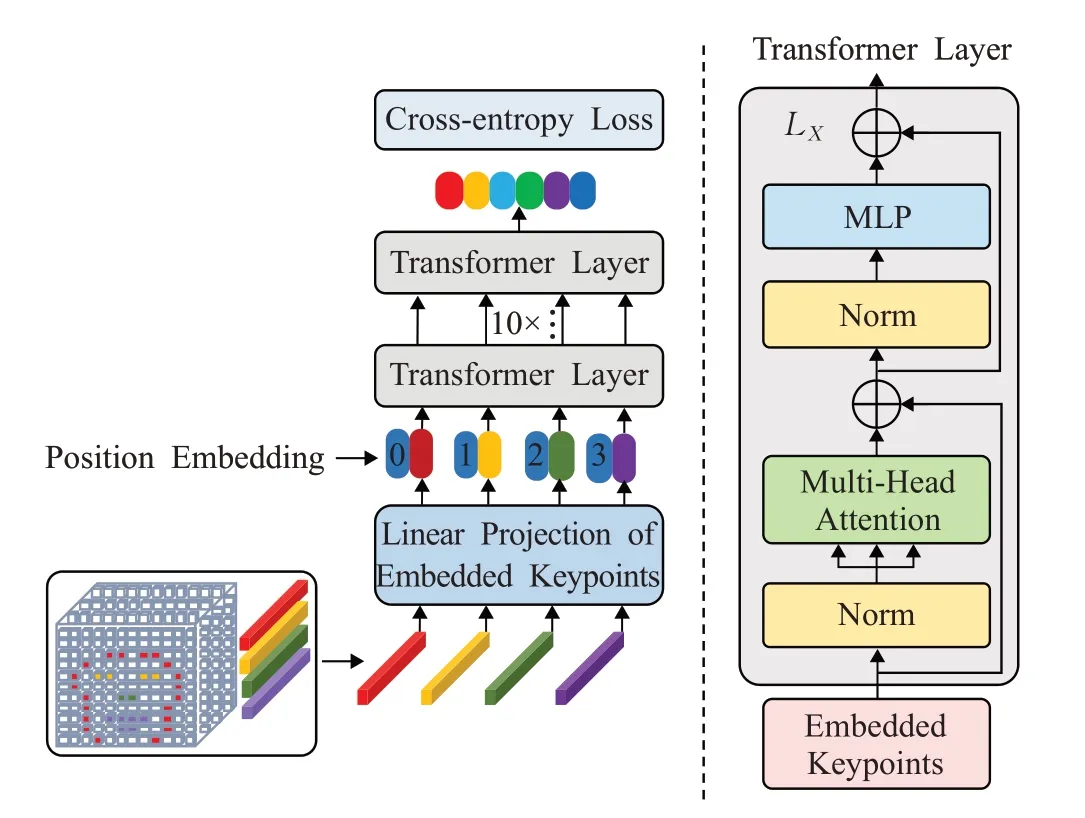
图6 基于Transformer的表情识别框架Fig.6 Expression recognition framework via Transformer module
位置编码模块采用不同频率的正余弦函数对空间信息进行编码。网络将特征向量映射后,利用位置编码补充它们,并将其输入到12层的Transformer Layer中,文中所述的各层结构相同,包括Multi-Head为8的自注意模块和MLP模块。最后,将网络的输出与金标准进行对比,计算交叉熵损失。
1.3.2 位置编码
Transformer和传统CNN不同,需要位置编码结构来编码每个词向量的位置信息,因为self-attention的结果具有排列不变性,即打乱关键点序列中点的排列顺序并不会改变输出结果。如果缺少关键点的位置信息,模型就额外需要通过点与点之间的语义信息来学习相关联系,就会进一步增加学习成本。
为了更好区分不同位置的关键点之间的差异性,以便网络更好的训练。本文把“位置编码”添加到Transformer Layer底部的输入词嵌入中。由于位置编码与关键点嵌入向量具有相同的维度,将两者相加。本文使用不同频率的正弦和余弦函数构造Position Embedding:
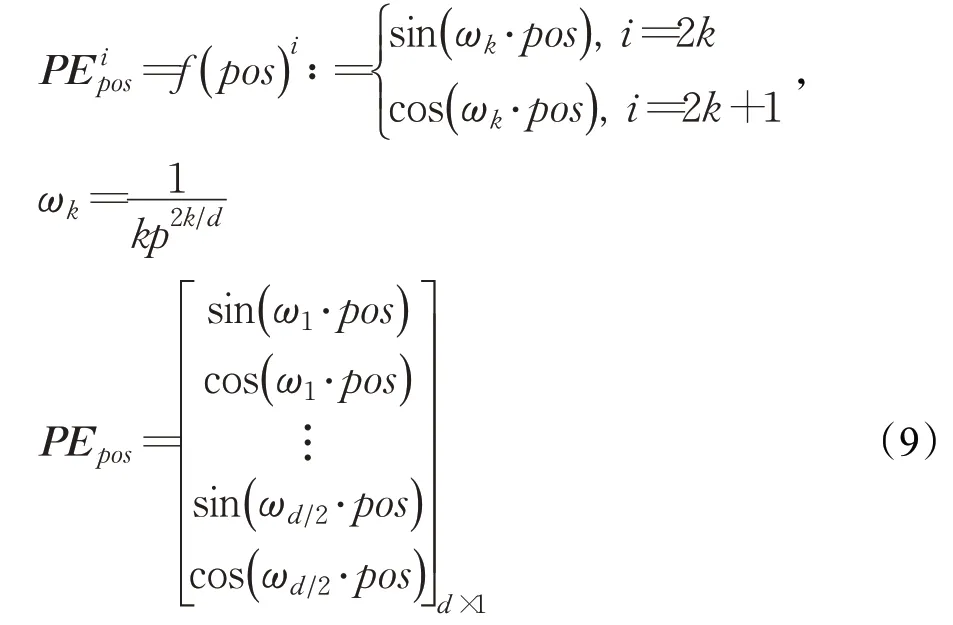
其中,pos表示特征点在序列中的位置;kp=68为关键点序列长度;d=768为线性变换后嵌入向量的维度;i表示嵌入向量的位置,i∈[1d]。由于位置编码的每个维度对应于1个正弦信号,在每个特征点向量的偶数和奇数位置分别添加sin和cos变量,从而填满整个PE矩阵,再加到经过线性映射后的输入向量中,从而实现位置编码的引入。
2 实验与结果分析
2.1 数据集及评价准则
本文在三种人脸表情公开数据集进行实验,包括:CK+、JAFFE、FER2013。其中,CK+数据集含有326例标注的图像序列,共7种类别;JAFFE数据集含有213张人脸表情图像,共7种类别标签;FER2013数据量大,包含35 887张人脸表情数据,但人脸角度更多变且有一定的遮挡,表情类别仍是7种标签,具体信息如表1所示。
此外,由于三种数据集中每类表情样本的数量不尽相同,表1中详细描述。数据中不同情感类别的数量分布不均,差异较大,因此本文采用一种加权精度(weighted accuracy,WA)的评价方法,如公式(10)所示:

表1 CK+、JAFFE、FER2013数据集样本分布Table 1 Sample distribution of CK+,JAFFE,FER2013
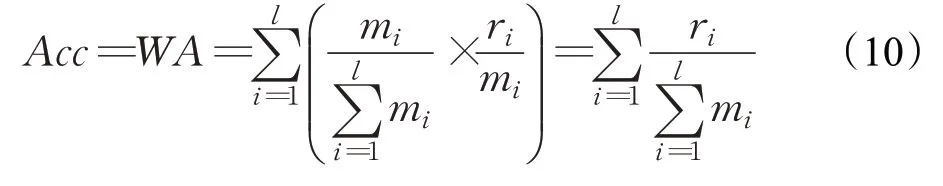
其中,l表示类别标签的数量,mi为第i个情感类别的数量,ri是第i个类别识别正确的个数。由于本文所使用的数据库不均衡,实验阶段的精度计算均基于“WA”方法,下文以“Acc”表示。
2.2 参数设置
实验中,将输入图像大小调整为256×256,并采用平移、旋转、缩放等方法进行数据增强,提高模型鲁棒性。关键点检测阶段,初始学习率为10-4,批数据大小为8,迭代次数为300,关键点数量kp=68,其特征维度dim=512,其他参数与文献[20]一致。表情识别阶段,输入特征为CS-AttNet网络提取的512维向量,Transformer Layer数量为12层,Multi-Head数为8,反向传播中采用交叉熵损失函数,详细设置可参考文献[19]。本文实验过程中共使用三个数据集,由于CK+与JAFFE数据量较小,因此网络首先都是在FER2013数据集上进行训练,获得模型参数。然后在CK+、JAFFE两个数据集上,将保存好的参数作为预训练参数加载,通过微调后再测试获得最终的结果,这样可以有效避免数据量小所带来的模型过拟合问题。
2.3 结果分析
2.3.1 网络模型有效性验证
为了验证本文所提算法的有效性,在CK+、JAFFE、FER2013数据集上分别进行五折交叉验证(5-fold crossvalidation)实验,即数据集随机分成5等份,选择第1份作为测试集,剩余4份作为训练集,类似地,选择第2份作为测试集,剩余作为训练集,累计循环重复5次获得输出结果,最后统计其平均准确率。实验结果的混淆矩阵如图7所示。
从图7的混淆矩阵中可看出:本文算法在CK+和JAFFE数据集上都能取得较好的结果,达到0.94以上的识别准确率,其中“高兴、惊喜”表情结果最高,因为这两类中人脸的面部变化最大,能够产生更多差异性的特征点,因此也最容易识别。但是在FER2013数据集中,整体的识别精度与CK+和JAFFE有较大的差距。
由于FER2013数据集中包含大量人脸遮挡和低对比度图像,加之数据集中各表情类别数据不均衡,差异较大,给模型的识别造成较大的困扰。此外,从图7(c)可以看出“悲伤、生气、害怕”表情识别结果较差,分别达到0.65、0.64、0.60的准确率。分析这三类表情同属于消极类情绪,它们之间本身具有很强的相似性,三者中互相错分的比例很高,并且在出现这些表情时,面部关键点通常只有细微的改变,因此识别难度更高,后续可能需要引进一些细粒度分类的方法做进一步的改进提升。
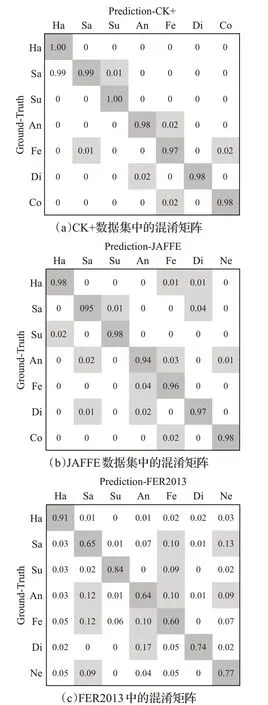
图7 三种不同数据集中表情识别混淆矩阵Fig.7 Confusion matrix of three different datasets
2.3.2 现有方法对比验证
为进一步验证本文所提模型的识别性能,对三种公开数据集采用与2.3.1小节一致的数据划分方式,将本文算法与现有的公开方法进行对比,结果如表2所示。从表2可看出:四种现有方法和本文算法在三种数据集上都取得了较好的识别结果。其中在CK+数据集上,本文算法达到99.22%的准确率,与最好的方法Resnet-MER-WAM[11]结果相当;在JAFFE数据集上,本文算法获得96.57%的准确率,比SACNN-ALSTM[23]提升0.92个百分点;特别地,在包含人脸遮挡和图像对比度低的FER2013数据集中,本文方法获得73.37%的最好结果,提升2.06个百分点。
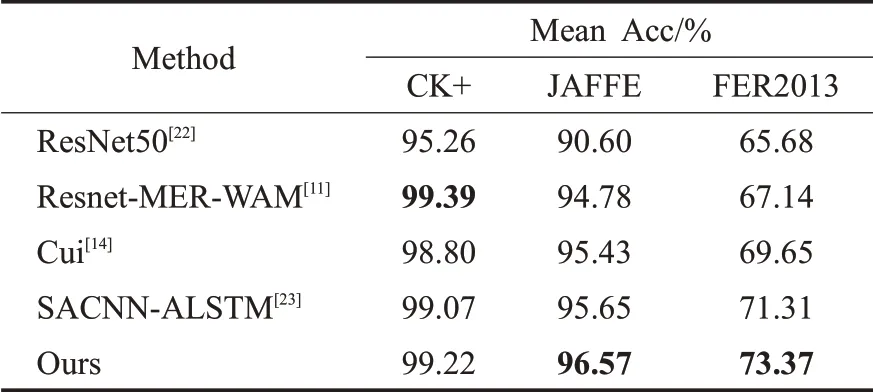
表2 不同算法在三种数据集上的实验结果Table 2 Experimental results of different algorithms on three datasets
因此,在数据清晰、差异化较小的情况下,目前大部分方法都能取得较好的结果,但是在真实的复杂场景下,很多方法难以适用。然而本文所提的关键点属性表征模块和基于注意力的Transformer识别模块能有效解决上述问题,实验结果也展现了本文所提模型的识别精度,获得目前最优的结果。
此外,利用小提琴图展示不同方法识别结果的准确率波动情况,如图8所示。小提琴图中心线越高代表平均精度值越大,图越扁平,说明结果方差越小,波动也越小,模型也就越稳定。
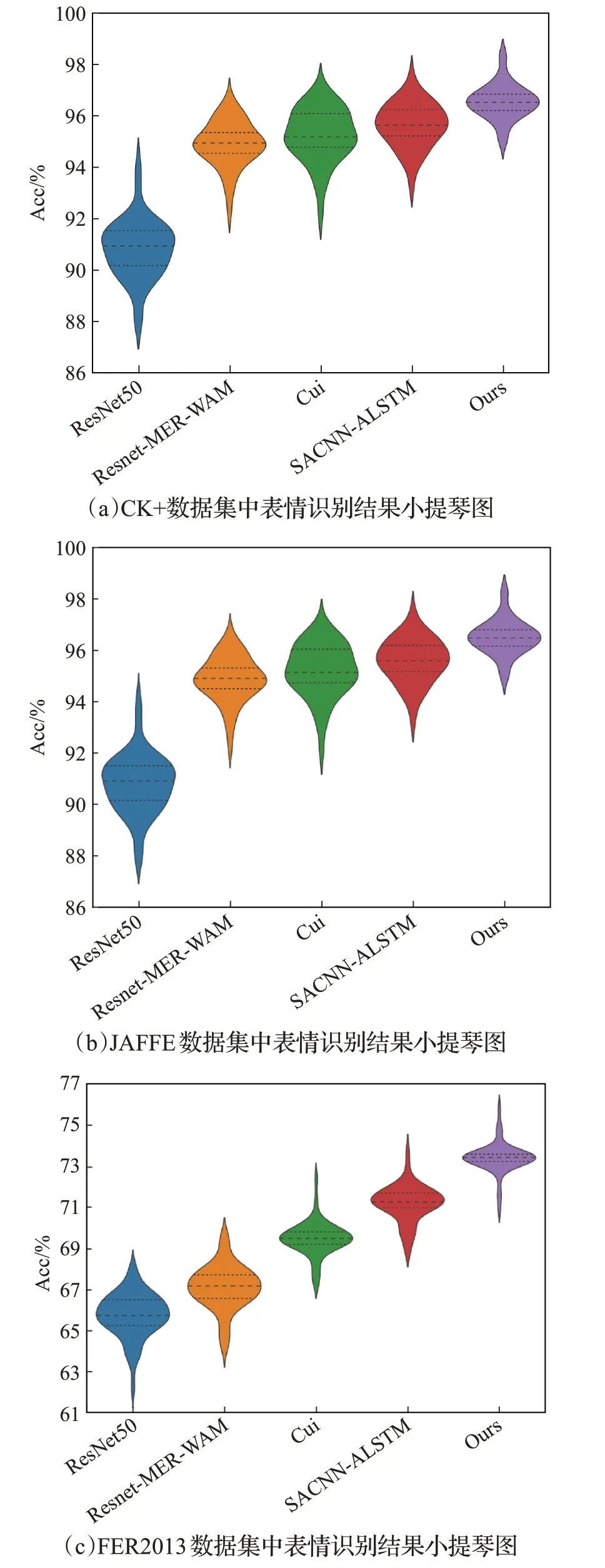
图8 三种不同数据集中识别结果小提琴图展示Fig.8 Violin plots of expression recognition in three datasets
如图8(a)所示,尽管在CK+公开数据集中Resnet-MER-WAM方法准确率略高于本文算法,但其结果有较大方差,并不能产生鲁棒的结果。
在JAFFE和FER2013数据集中,本文方法不仅取得最高的识别精度,而且结果的波动变化也更小,更稳定,显著优于其他方法。所以进一步证明了所提模型不仅在数据良好的状态下取得较优性能,在复杂的场景下依然具有较强的识别能力和较强的鲁棒性。
2.3.3 消融实验
为了测试本文所提注意力机制和Transformer模块的有效性,以ResNet50作为骨干网,将其网络中的残差结构置换为图4中所示的注意力模块,记为CS-AttNet。此外,在CS-AttNet基础上,本文进一步加入Transformer模块,记为CS-AttNet-Trans模型,能够捕获关键之间的相关联系,对人脸表情识别产生积极作用。实验数据的划分和设置与2.3.1小节保持一致,结果如表3所示。

表3 网络不同模块的实验结果Table 3 Experimental results of different modules
从表3可以看出,在三种不同的数据集上,本文所提的CS-AttNet模块和Transformer模块对表情识别的准确率都有一定的提升,充分表明本文所提模块对人脸表情识别任务具有极大的提升作用。其中,CS-AttNet模块相对于骨干网ResNet50识别准确率平均增加4.13个百分点。在CS-AttNet基础上加入Transformer模块,构成CS-AttNet-Trans模块,可以看出在CK+和JAFFE数据集上准确率分别只有0.37和1.37个百分点的提升。主要原因在于CK+和JAFFE数据集图像清晰、差异化较小,因而基础网络都能取得较好的结果,表2所示的4种方法在其中也都能取得令人满意的识别结果。
然而,FER2013数据集中包含大量人脸遮挡和低对比度图像,其他算法很难得到较好的结果,而本文所提模块在ResNet50基础上准确率分别提升4.21和7.69个百分点,充分说明其在高质量数据中能够保持较高的识别准确率,在低质量数据中同样能够取得较大的指标提升,进一步证明了本文算法的鲁棒性和有效性。
3 结束语
本文提出一种融合关键点属性与注意力表征的人脸表情识别方法,不仅能够有效避免非表情区域的干扰,而且可以关注图像中局部位置的细微变化。通过添加通道注意力和空间注意力机制,实现不同维度和位置的权重分配,引导网络学习更具有表征性的特征。本文提出基于Transformer模块构建表情识别模型,通过Transformer模块在所有实体对之间执行信息交换,捕获关键点之间丰富的位置信息和互信息,从而有效提升表情识别精度。最后将本文所提出的算法分别在CK+、JAFFE、FER2013三种公开数据集上进行实验验证,分别达到99.22%、96.57%、73.37%的识别准确率,其中FER2013数据集场景复杂、识别难度较高,本文提出的算法达到了目前为止最高的准确度,充分展现了算法的有效性和鲁棒性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
动漫星空(2018年9期)2018-10-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
新高考·高一物理(2015年5期)2015-08-18
中国卫生(2014年2期)2014-11-12
