
基于pu-learning的同行评议文本情感分析
2023-02-14 10:31王凯巧林鸿飞
计算机工程与应用 2023年3期
林 原,王凯巧,杨 亮,林鸿飞,任 璐,丁 堃
1.大连理工大学 科学学与科技管理研究所,辽宁 大连 116024
2.中国科学院 声学研究所 南海研究站,海口 570105
3.大连理工大学 信息检索实验室,辽宁 大连 116023
同行评议(peer review)是定性评价的一种主要方法,亦称同行专家评审,虽然同行评议的质量、随机性、偏差和不一致性在学术界存在着广泛的争论[1-2],但目前同行评议仍然是最受普遍的论文评审过程[3]。同行评议是指作者将完成的论文提交给某一期刊或会议,该期刊或会议的编辑/主席将其分发给多个领域专家进行评审,以达到相应期刊或会议的标准。通常情况下,专业审稿人收到审稿请求后会仔细审稿,并为论文写一篇审稿意见和推荐分数。之后,编辑/会议主席将根据几个审稿人的评议文本和分数为论文撰写一篇总评并决定论文的最终状态。
近年来,开放数字运动使得有些期刊会议开始尝试着开放学术评价过程,例如Nature Communication,PLOS,Open review等。其中,Open review网站(https://openreview.net/)是其中较为成熟的开放同行评议平台,数据集的获取较为方便且完整,因此本文选取了Open review中的开放同行评议文本作为研究对象。Open review主要用于计算机人工智能领域会议的同行评议过程的交流,该网站目前支持ICLR、UAI、NIPS、ICML等60多个会议公开同行评议过程,这些会议在接收稿件时会询问作者是否公开同行评议过程,经作者同意的同行评议过程会公开在该网站中,作者以及公众可以看到审稿人写的同行评议文本,作者还可以在一定时间内根据审稿人的意见进行回复。以ICLR会议为例,表1为通过python爬虫程序从该网站中爬取到的在该网站中公开同行评审过程的论文统计数据,检索日期为2020年3月20日。此外,加入Open review网站的国际会议每年都在增加,数据集的公布也越来越规范化与结构化,这为论文的刊前定性评价研究提供了大量的、良好的数据集。

表1 2017—2020 ICLR公开同行评议过程的论文统计Table 1 Paper statistics of 2017—2020 ICLR public peer review process
表2为本文从Open review网站收集到的一篇同行评议文本样例,一般来说,在评审文本中,审稿人首先会对论文的贡献进行总结(见表2中的前两句),然后审稿人会对论文发表自己的观点,包括正反两方面(见表2中的3~8句)。推荐分数是审稿人综合论文的各方面表现给出的总分,根据推荐分数,审稿人还会给出推荐论文的决策状态,即接收或拒绝,有时还会有临界状态。

表2 同行评议文本样例Table 2 Sample of peer review text
本文将同行评议文本分类的任务分成了两个子任务:
任务1挖掘同行评议文本中审稿人的正向、负向情感,预测审稿人的两种推荐状态,即接收/拒绝(二分类)。
任务2挖掘同行评议文本中审稿人的正向、中性、负向情感,预测审稿人的三种推荐状态,即接收/临界/拒绝(三分类)。
第一个任务是同行评议文本的二分类任务,根据审稿人的实际推荐分数将论文划分成两类,拒绝(1≤分数≤5)和接收(6≤分数≤10),通过情感分析模型挖掘同行评议文本的情感极性并据此为同行评议文本分类,当同行评议文本情感极性为正向时,模型将预测论文的审稿人推荐状态为接收,当同行评议文本的情感极性为负向时,模型将预测论文的审稿人推荐状态为拒绝,通过对比论文的实际推荐状态和预测推荐状态来评估模型的准确率。第二个任务是同行评议文本的三分类任务,它根据审稿人的实际推荐分数将论文划分成三类,拒绝(1≤分数≤4)、临界状态(5≤分数≤6)和接收(7≤分数≤10),其他的设置与第一个任务一样。
1 相关研究概述
文本情感分析又称意见挖掘,是指通过计算技术对文本的主客观性、观点、情绪、极性的挖掘和分析,从而分析文本情感极性。情感极性分为两极,即正面(positive)的赞赏和肯定、负面(negative)的批评与否定,也有一些学者在正面和负面之间加入了中性(neutral)。情感分类的方法大致可分为基于词典的方法[4-5]、基于机器学习的方法[6-7],其中,基于机器学习的方法,尤其是深度学习神经网络模型[7-10]具有优越的性能。深度学习情感分析目前已广泛应用于各种文本分类任务,并取得了显著的效果,包括产品评论[11-12]、电影评论[9,12]、推特[7-8]、新闻文章[13]等。
正例和无标记样本学习(positive-unlabeled learning)简称pu-leanrning,是一种半监督的二元分类模型,与普通分类问题不同,pu-learning问题中P的规模通常相当小,扩大正样本集合也比较困难;而U的规模通常很大。其可以在检索、异常检测、序列数据监测中应用。pu-learning可以训练一个基于正样本P和未标记样本U(包括正样本和负样本)的二元分类器,计算每个样本属于正样本的概率。
此前,有学者对同行评议文本进行了研究,研究表明,审稿人通常在评论的开头一段描述对于论文的总体意见,如这篇论文有什么贡献,解决了一个什么样的问题,是否具有一定的创新性[14],而论文存在的主要问题,特别是可能使论文无法录取的问题一般会在同行评议文本的后面部分列出,同样的,审稿人对于文章的赞赏一般也是在审稿文本后半部分列出[15]。因此,为了让情感分析模型将注意力放在更有可能包含审稿人情感的后半部分审稿文本,本文在情感分析模型中引入了pu-learning方法,基于同行评议文本中的开头部分更有可能是审稿人的非观点句的假设,通过pu-learning中的“两步法”[16]训练一个可以区别化同行评议文本中观点句和非观句的分类器,使得情感分析模型加大对观点句的分析权重,从而使得情感分析模型达到更好的效果。为了验证引入pu-learning的有效性,本文分别采用了三个传统的神经网络来进行同行评议文本的情感挖掘。
2 研究思路
如果能自动区分同行评议文本中审稿人对于论文的观点句(如论文的优缺点)和非观点句,一方面,在情感分析过程中,可以通过改变不同句子的重要性,使得模型能将注意力放在包含了审稿人情感极性的观点句中,从而可以使得模型达到更好的分类效果,另一方面,通过可视化的方法可以给予同行评议文本观点句和非观点句不同的强调颜色,这将不仅有助于编辑/会议主席撰写一篇全面的总评,也将便于作者进一步改进论文。此外,完成训练的情感分析模型可以用于大量没有分数的同行评议文本,为其分类,从而为学术论文质量评价体系提供新指标。
目前存在一些关于同行评议文本的情感分析研究,由于同行评议文本篇幅太长,观点句和非观点句混杂、优缺点交织,现有的模型均引入了论文或摘要作为外部资源嵌入其中,这使得模型算法变得很复杂,但效果并没有实质性的提高。不同于传统方法,本文创新性地提出了针对这一任务的基于观点句注意力机制的同行评议文本研究模型,简称OSA(opinionated sentence attention)机制。本文巧妙地将同行评议文本中的前N个句子标记为正例,将其他句子标记为未标记的样本,通过两步法使每个句子得到一个观点句权重,并用倒数第二层的编码器对这些权重进行点乘,得到最终的预测结果。模型在ICLR 2017—2018的数据集上进行了评估,实验结果验证了OSA的高效性,并在两个数据集上取得了优异的性能。
3 同行评议观点句注意力机制模型
图1为本文提出的OSA机制的总体架构。该机制有两个部分,第一部分是pu-learning的两步法,在这一部分,将每一篇同行评议文本的前N个句子标记为正例,其他句子标记为未标记样本。训练一个观点句和非观点句的句子分类器,为每一个句子分配一个非观点句的权重。第二部分是情感分析编码器与两步法相结合,在情感分析编码器的倒数第二层,将每句话的观点句权重乘以这一层的值并求和来得到最终的分类概率。
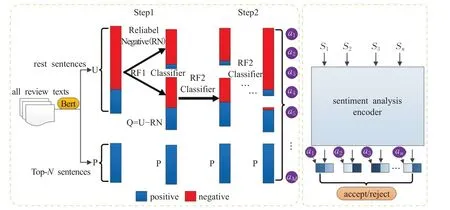
图1 同行评议观点句注意力机制模型研究Fig.1 Study on attention mechanism model of peerreview opinion sentences
3.1 两步法
本文首先采用谷歌预训练的句向量语言模型BERT[17]来对同行评议中的每一句话进行编译,从而得到每一句的表示向量,如图2所示,这里的BERT是谷歌将多个transformer encoder叠加起来训练好的可直接外部使用的句向量语言模型,其中,句向量长度为768维。

图2 BERT句向量语言模型Fig.2 Sentence vector language model BERT
图2展示了两步法的具体过程,这里模型的输入是通过句向量语言模型编译好的所有同行评议文本的M个句子,两步法包含了两个步骤:
步骤1为了从未标记的样本中提出到相对可靠的负例样本RN(reliable nagative),以每篇同行评议文本的前N个句子P(positive samples)为正例,以其余未标记样本U(unlabeled samples)为负例,采用随机森林分类器训练一个分类器RF1,接着用训练完成的RF1应用于未标记样本集U,设定一个阈值,将概率小于该阈值的样本标记为相对可靠的负例样本集RN[18],那些在U中未被标记为RN的样本被记为样本集Q。
步骤2在这个步骤,另一个随机森林分类器RF2不断地以P、RN和Q进行迭代训练,在每一次的迭代中,RF2以P为正例、RN为负例进行训练,将训练完的RF2分类器应用于Q样本集,在Q中被确定为新的负例的样本会被添加到RN中,构成新的RN,如此迭代直到Q中不再产生没有新的负例被添加到RN。
通过两步法,所有的同行评议的句子都会得到一个权值q:

这个权值代表了这句话为非观点句的概率,通过a=1-q的计算可以得到代表了这句话属于观点句的概率a。
3.2 基于两步法的情感分析
在这个部分,通过预训练的词向量语言模型查找将每一个单词表示为一个固定长度的词向量wi∈Rd,这里d为词向量的维度,一个长度为L的句子S则可以表示为:
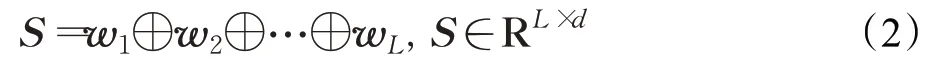
其中,⊕是拼接操作,因此,一篇具有n个句子的同行评议文本可以表示为:
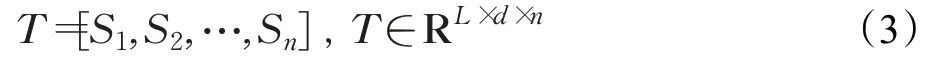
接着,采用一个情感分析编码器来对每一篇同行评议文本进行编码来得到模型的倒数第二层的值:
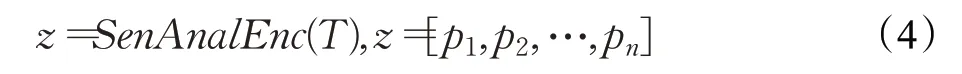
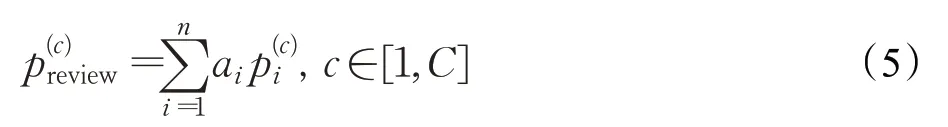
此外,模型训练过程中采用交叉熵损失函数来最小化预测值与实际值之间的误差:

这里Treview代表了同行评议文本中的训练数据集。
4 实证研究
4.1 实验数据集
本文从Open review平台中爬取了2017—2018年ICLR(国际学习代表大会)的所有同行评议文本作为研究数据集,包括论文的同行评议文本和每篇同行评议文本对应的1~10分推荐分数作为实验数据。表3展示了ICLR各年数据的基本统计信息。

表3 ICLR 2017—2018数据集基本统计信息Table 3 ICLR 2017—2018 dataset basic statistics
为了研究将同行评议文本的开头句子作为pulearning分类器正例的可行性,本文抽取了ICLR 2018的200篇同行评议文本作为样本进行了分析,人工标注这200篇同行评议文本的第一个句子,结果发现有13篇同行评议文本的第一句为审稿人情感句,其他的187篇为非情感句,这一结果与之前的研究是一致的[14-15],这也验证了将同行评议文本的开头句作为pu-learning正例的可行性。
4.2 实验设置
本节采用了不同的情感分析编码器和正样本句子进行了实验。对于两步法的参数设置,本节使用了预训练的词向量模型Googles BERT-Base Uncased模型来将同行评议文本中的每一个句子表示成768维的表示向量,在步骤1使用的是n-estimators为1 000且n-jobs为-1的随机森林分类器来获取相对可靠的负样本RN;在步骤2中同样使用的是n-estimators为1 000且n-jobs为-1的随机森林分类器来不断的迭代从Q中获取新的相对可靠的负样本。步骤2进行了100次迭代且使用了早停机制。对于情感分析部分,本节分别使用了CNN[7]、LSTM[19]、CNN-BiLSTM、CNN-BiLSTM-Att[8]模型来进行实验。
为了评估OSA机制的有效性,本节还使用了不加两步法的三个情感分析原始模型作为基线参考模型。使用预先训练好的wiki百科200维词向量作为初始词嵌入,在训练过程中对词向量进行固定,每篇同行评审文本分别设置了最大句子数M1=130和句子最大序列长度M2=100,通过随机梯度下降和Adam优化器的超参数进行训练。采用十折交叉验证法来训练模型并计算模型的准确率,每个数据集被随机分成10个部分,每次使用一个部分进行测试,另外9个部分进行训练。也就是说,对于ICLR-2017数据集,使用1 366条评论作为训练集,151条评论作为测试集;对于ICLR-2018数据集,使用2 588条评论作为训练集,286条评论作为测试集,最终模型的准确率为模型10次训练结果的平均值。
4.3 不同的前N句子作为正例对比
为了找到更准确的同行评议文本的前N句作为两步法中的正例样本,首先用CNN情感分析模型来分别对前1、前2、前3、前4和前5个句子进行了实验。表4的实验结果表明,将前两个句子作为正例样本可以使得两步法得到最佳的实验结果。从表4可以看出,前1句的结果比前2句的结果稍差,超过2句会使结果越来越差,其中,括号中的数字是十折交叉验证结果准确率的标准差。因此,在以后的实验中,采用了Top-2机制。
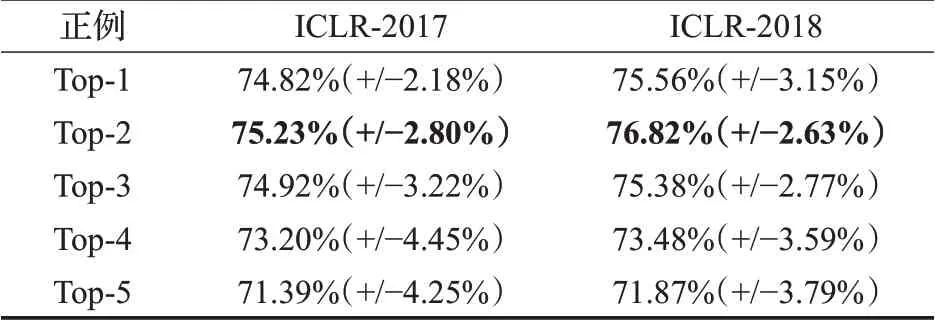
表4 不同的前N句作为正例结果Table 4 Result of taking different first N sentences as positive examples
4.4 同行评议观点句注意力机制可视化
图3是从ICLR-2018数据集中提取的同行文本的一个例子,由于篇幅有限,本节展示了一些句子。本文通过两步法得到了每个句子是观点句的权重,图中不同的红色代表句子的不同权重,颜色越深表示权重越大。从图中可以看出,OSA机制可以直观地从同行评议文本中识别出非观点句和观点句。例如,在这里,同行评议文本中的前四句话显然是评论人对论文贡献的总结,它们是非观点句,因此它们在图中的颜色较浅。此外,即使非观点句混合在观点句的句子中,如数字8,两步法仍然可以捕捉到它并给出较小的权重,在图中表现为较浅的颜色,而那些给出了审稿人意见的观点句,如图中的9、10、11、12得到较深的颜色。通过这样的可视化可以直观地感受到OSA机制带来的贡献,它可以很好地区分同行评议文本的观点句和非观点句,并定量化给予它们不同的权重,使得情感分析模型能更加注意审稿人的观点句,从而使得情感分析模型达到更好的分类效果。

图3 同行评议观点句注意力机制的可视化Fig.3 Visualization of attention mechanism in peerreview opinion sentences
4.5 二分类任务的表现
表5列出了本文的OSA机制和基线参考模型的实验结果。本文分别在ICLR-2017和ICLR-2018两个数据集上进行了实验,评价结果证明了本文提出的OSA机制的有效性。本文采用了平均准确率和标准偏差作为评估指标。总的来说,CNN、CNN-BiLSTM、CNNBiLSTM-Att这三个模型在添加了OSA机制以后准确率都有了不同程度的提升。显然,基本的CNN模型表现得最不佳,添加了BiLSTM和Att后可以使稍微改善模型结果。但OSA机制的应用可以使得三个基线参考模型有很大的改进。
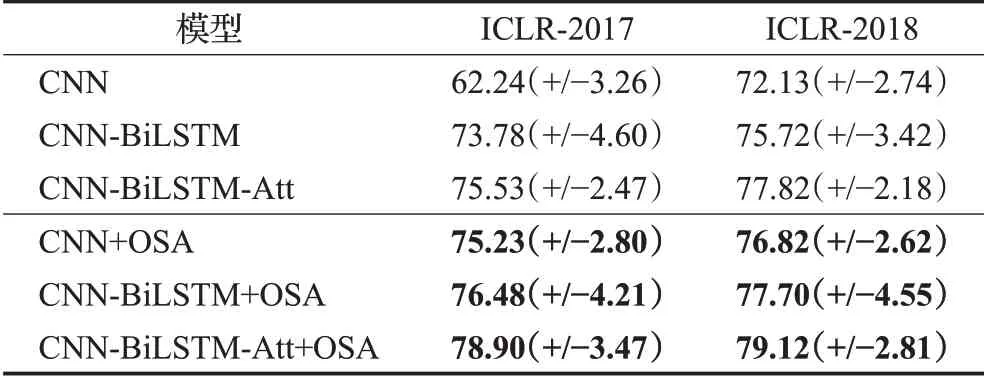
表5 二分类实验结果Table 5 Experimental results of two classification 单位:%
从表5也可以看到,对于不同的基线参考模型,OSA的效果也不尽相同。在这里,OSA对CNN的促进作用最大,在ICLR-2017和ICLR-2018的数据集上分别提升了12.99和4.69个百分点,将其归因于OSA的使用:即使不使用论文和摘要信息,这种机制也能成功捕捉到同行评议文本中的观点句。另外,CNN-BiLSTMAtt+OSA模型在两个数据集上取得了最好的结果,分别比CNN-BiLSTM-Att模型的结果高出3.37和1.30个百分点的准确率,低于CNN的提升率,这也表明了为两步法寻找一个更加合适的情感分析模型仍然是一个需要继续研究的问题。
4.6 三分类任务的表现
在本节中,将展示三分类任务的结果,该任务比任务1多了一个边界状态类别。表6是任务2的实验结果,总的来说,与二分类任务相比,三分类任务难度更大。在这里,CNN-BiLSTM-Att在所有基线参考模型中表现最好,而添加了OSA机制的CNN-BiLSTM-Att机制可以得到更好的结果,说明OSA机制是一种强大的注意到观点句的工具。更重要的是,三个变体模型仍然可以极大地提升它们的基础模型,这证实了OSA机制在不同的任务上仍然具有有效性。在任务2中,CNN+OSA仍然得到了最大的准确率提升,而CNN-BiLSTMAtt+OSA在所有模型中都获得了最好的性能。
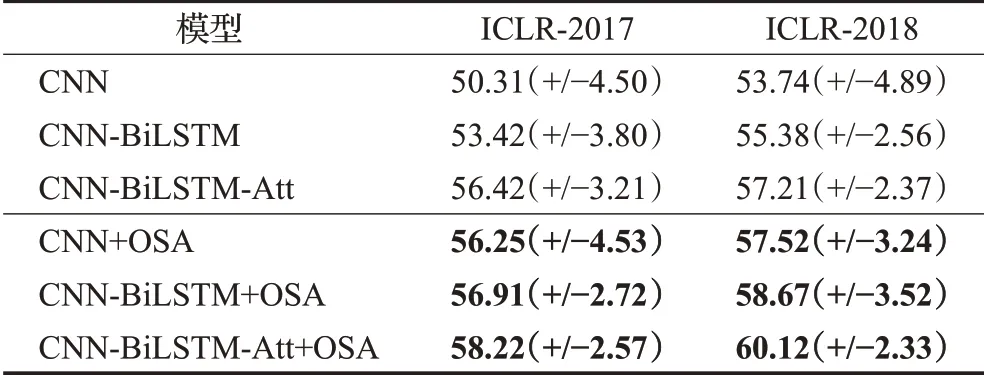
表6 三分类实验结果Table 6 Experimental results of three classification单位:%
4.7 决策状态预测任务表现
以完成预测审稿人推荐状态准确率最好的CNNBiLSTM-Att+OSA二分类模型为例,通常情况下每篇论文会有三篇同行评议文本,因此采用该模型进行同行评议文本定量化可以得到论文的三个预测推荐状态,如接收、接收、拒绝,可以认为这三个预测推荐状态代表了该论文在三位审稿人之间的接受度,显然得到接收个数越多的论文,代表该论文在审稿人中的普遍接受度越高,认可度越高,论文被录取的可能性就越大,本文将这种审稿人的三种推荐状态称为论文接受度指标。
因此本节尝试着采用论文接受度指标对最终决策状态进行预测,规定高接受度的论文决策状态将被预测为接收,低接受度的论文决策状态将被预测为拒绝。如图4所示,通过定量化论文的三篇同行评议文本可以得到论文的接受度指标,这里本文规定了“少数服从多数”的投票法,如果一篇论文通过训练好的模型预测得到两个接收、一个拒绝的结果,则规定论文的最终预测决策状态为接收,如果一篇论文得到一个接收、两个拒绝的预测结果,则规定论文的最终预测决策状态为拒绝,规定当一篇论文得到的接收个数和拒绝个数相等时,论文的最终预测决策状态随机获取。对比论文的预测决策状态和实际决策状态,当预测决策状态与实际决策状态一致时,判定模型成功地通过同行评议文本预测了论文的最终决策状态,否则判定模型预测失败。
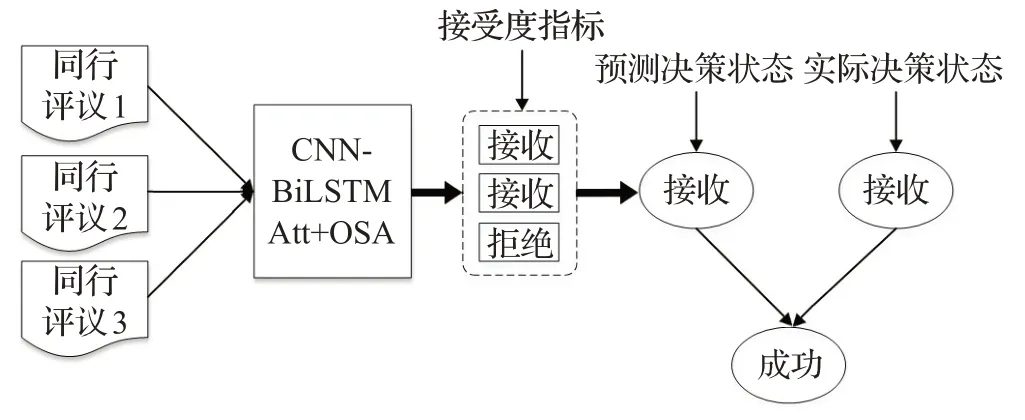
图4 接受度指标预测论文决策状态Fig.4 Acceptance index predicts paper decision-making status
将收集到的约10%的ICLR 2017—2018年论文数据作为测试集,其中2017年和2018年各有49篇和95篇论文,对比论文的预测决策状态和实际最终决策状态来判定模型是否成功完成预测。这样便可以得到ICLR 2017和ICLR 2018的论文决策状态预测准确率分别为81.63%和83.16%,可以看出,通过论文接受度指标,可以使得模型得到很好的决策状态预测准确率,是用于划分未发表论文质量的有效指标。
5 结论
同行评议是一种定性评价,是当前国内外学术期刊与会议最普遍的学术评价方式,是把控学术论文质量的最重要的方式。本文收集了开放获取的同行评议文本作为研究数据集,采用情感分析模型挖掘文本情感极性,为同行评议文本分类,从而达到了定性评价定量化的目标,完成训练的情感分析模型可以用于大量没有分数的同行评议文本,为其分类,从而为学术论文质量评价体系提供新指标。
为了进一步提升情感分析模型对于同行评议文本的分类准确率,本文将机器学习方法pu-leaning引入到同行评议文本情感挖掘任务中。通过pu-learning中的两步法可以使得同行评议文本中的每一个句子得到一个观点句权值,这个权值可以使得情感分析模型更加注意到同行评议文本的观点句,从而使得情感分析模型能更好地挖掘到审稿人的情感极性,OSA的可视化直观地表明,该方法能够成功地捕获评论文本中的观点句。本文将这种机制称为OSA机制,本文使用了三个情感分析编码器来验证OSA机制的有效性。本文提出的方法在不融合论文和摘要信息的情况下,可以在两个子任务中使得使用了OSA机制的模型优于所有的基线参考模型。最后,通过论文接受度指标探讨了本文提出的模型的实际应用场景,该指标可以有效地用于论文决策状态预测任务。
猜你喜欢
军事护理(2023年1期)2023-01-19
成都信息工程大学学报(2022年4期)2022-11-18
江苏安全生产(2022年9期)2022-11-02
电源技术(2022年5期)2022-05-26
实用骨科杂志(2020年3期)2020-04-10
人大建设(2017年2期)2017-07-21
海南开放大学学报(2017年2期)2017-06-22
中华诗词(2017年10期)2017-04-18
中国医学装备(2016年6期)2016-12-01
中国科技期刊研究(2016年11期)2016-04-17
