
深度学习屈光检测方法研究
2023-02-14 10:31丁上上郑田莉张贺童裴融浩付威威
计算机工程与应用 2023年3期
丁上上,郑田莉,姚 康,张贺童,裴融浩,付威威
1.中国科学技术大学 生物医学工程学院(苏州)生命科学与医学部,江苏 苏州 215000
2.中国科学院 苏州生物医学工程技术研究所,江苏 苏州 215000
屈光不正的早期检测在近视防控中起到了至关重要的作用,若能及时发现屈光异常并采取措施进行干预与控制,就可以阻止近视的发展并减轻视力的受损[1]。因此,美国儿科学会(AAP)、美国小儿眼科与斜视协会(AAPOS)和欧洲斜视协会(ESA)推荐早期的屈光筛查[2]。
目前摄影验光方法被广泛应用于屈光筛查。摄影验光是一种通过摄影手段来测量眼睛屈光度的客观方法,其基本原理是采用摄影技术拍摄视网膜反射出的光线,因屈光状态不同,瞳孔区会出现不同的光影,从而可测出被检者的屈光度。1974年美国学者Howland根据视网膜检影法的基本原理提出了正交摄影验光法[3],这标志着摄影验光的开始。1979年芬兰科学家Kaakinen根据正交摄影验光法的原理提出了对角膜和眼底反光同时摄影的偏心摄影验光法[4]。在此之后,中国学者瞿佳[5]、加拿大学者Roorda[6]、德国学者Kusel[7]、中国学者叶宏伟等人[8]先后对摄影验光技术进行了研究与改进,使得此屈光检测方法的精度与准确度得到了提高。
摄影验光采用非接触的方法进行屈光检测,不需固定被测者头部,降低了对被测者的配合要求,比其他验光方法更适用于婴幼儿、青少年儿童等难以长时间配合执行规范检测流程的特殊群体,效率较高,适合大规模的屈光筛查。但是,使用摄影验光的方法进行屈光筛查,目前还主要面临着两个问题:屈光检测的准确度相对于其他检测方法较低;对被测者的测量位置有较高的要求,影响检测效率。
目前市面上使用摄影验光原理的屈光检测设备的柱镜精确度和球镜精确度一般为±0.50D或±1.00D,此精度与其他验光方法相比,相对偏低。这是因为使用摄影验光原理进行屈光检测的方法,主要有两种,一种是根据瞳孔图像中新月形亮暗区域高度关系计算屈光度,另一种则是根据瞳孔图像内光影的亮暗变化规律进行屈光度的计算。第一种方法,使用图像处理技术寻找瞳孔图像中的亮暗区域边界,并将亮暗区域进行分割,再计算亮暗区域的高度,从而得到被测眼的屈光度。然而,瞳孔图像中的亮暗变化是渐变的,使用图像处理的方法很难准确获取亮暗区域的边界,在此过程中,会引入较大误差,很难得到准确的屈光度结果。另一种方法则不需要获取亮暗区域边界,而是使用由光源在视网膜上反射图像的照度斜率来判断屈光状态,即以瞳孔图像中心为中点,沿光源布置方向取若干个像素点的灰度值,将此组灰度值拟合成一条直线,根据此直线的斜率确定被测眼的屈光状态。使用此方法对图像分辨率有较高要求,若图像分辨率较低,则无法获取合适数量的像素点灰度值,导致计算精度较低。另外,此方法需要将计算得到的斜率与真实屈光度进行拟合,此过程需要较多数据,且计算相对复杂,会造成较大误差,使屈光检测准确度很难进一步提高。
摄影验光采用非接触的方式进行屈光检测,与其他验光方式相比,降低了被测者的配合度要求。但是,此种方法对被测者的位置要求依旧较高,当被测者瞳孔偏离图像中央区域较多时,屈光检测结果将会受到较大影响。这是因为当被测者位置改变时,图像特征会随之而产生变化,影响图像处理的结果。目前的解决办法主要是通过对不同位置状态下的检测结果与真实屈光度进行标定,但整个过程较复杂,在标定的过程中会引入较多因素,使得检测结果的准确度受限。因此,在实际验光过程中,设备操作人员要花费较长时间调整与被测者的相对位置,使被测者眼部区域位于图像中央区域附近,这将降低屈光筛查效率,使摄影验光的优势得不到充分发挥。
为了解决现有摄影验光方法存在的几个问题,本文提出一种基于深度学习的屈光检测方法,此方法利用偏心摄影验光的光学原理,获取被测者人脸面部近红外图像,使用图像处理技术对面部近红外图像进行处理,得到左右瞳孔图像和瞳孔位置信息,使用混合数据多输入神经网络模型进行训练与屈光度的预测。深度学习是一种对大量数据进行表征学习的方法,其自动提取特征,具有非常强的学习能力和适应能力,且由数据驱动,上限高。与传统偏心摄影验光原理的屈光检测方法相比,此方法可以随着数据集的扩增而达到更高的准确度,并且此方法将瞳孔位置信息作为模型的输入,有希望解决传统算法对被测者配合度要求较高的问题。
此方法作为对新式屈光检测方法的一种有益探索,有利于屈光筛查更便利地进行,提高大规模屈光筛查的效率。未来,尝试将此方法应用于终端设备上,探索自助式屈光检测的可行性,从而使屈光检测高频率、常态化地进行,便于青少年儿童近视的防控。
1 偏心摄影图像获取
1.1 偏心摄影验光原理
偏心摄影验光法是一种利用摄影获得的瞳孔图像来判断患者眼瞳屈光状态的方法[9],拍摄经过视网膜反射出的光线在瞳孔区域因屈光状态不同而表现出的不同光影,从而检测患者的屈光状态,其光学原理如图1所示(以近视眼为例)。
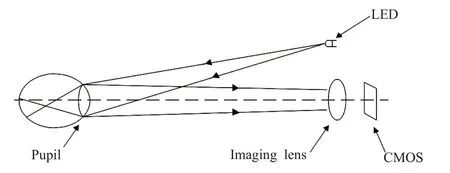
图1 偏心摄影验光原理图Fig.1 Schematic diagram of eccentric photography optometry
1.2 图像采集系统设计
偏心摄影图像采集系统硬件组成如图2所示。

图2 图像采集系统硬件组成示意图Fig.2 Image acquisition system hardware schematic
光源模块发射的850 nm波段近红外光线,经过半透半反镜后进入人眼,人眼屈光系统反射回来的光线再通过半透半反镜到达图像采集模块前,经过图像采集模块镜头前的850 nm窄带滤光片后,最终在图像采集模块传感器上成像。光源模块中心与图像采集模块的光轴在同一中轴线上,通过光源模块上的偏心光源实现对眼瞳的偏心摄影。
光源模块由光源电路板和LED阵列组成,LED阵列排布方式如图3所示。
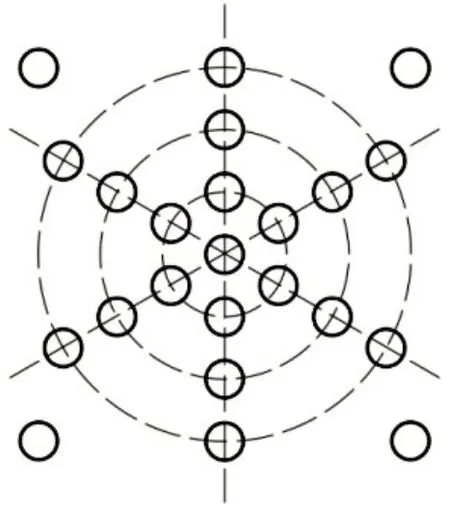
图3 光源模块LED阵列Fig.3 LED light source array module
LED阵列由23个850 nm近红外LED组成,包含1个同心近红外光源和22个偏心近红外光源。同心近红外光源的作用是照亮瞳孔整体区域,为使用图像处理技术进行瞳孔定位以及提取提供了有利条件。偏心近红外光源为摄影验光提供偏心光源,根据偏心摄影验光原理,光源位置与图像采集模块光轴之间存在一定偏心距,不同偏心距下获取到的瞳孔图像对屈光状态程度反应不同,从而可以控制LED阵列中不同LED组合而成的亮灯模式,获取到可以反应被测眼不同方位和屈光程度的偏心摄影图像。
2 基于深度学习的屈光检测方法
为了解决现有摄影验光技术屈光检测准确度较低,且对被测者位置配合度要求较高的问题,本文提出一种基于深度学习的屈光检测方法,方案如图4所示。首先通过偏心摄影图像采集系统采集被测者近红外面部图像,使用图像处理技术,从被测者面部图像中分别提取左右瞳孔图像以及左右瞳孔在图像中的相对位置信息。其次将提取到的瞳孔图像和瞳孔相对位置,两种数据作为深度学习的输入,一起送入混合数据多输入神经网络模型中。最后经过模型的计算预测,同时得到球镜度与柱镜度结果。
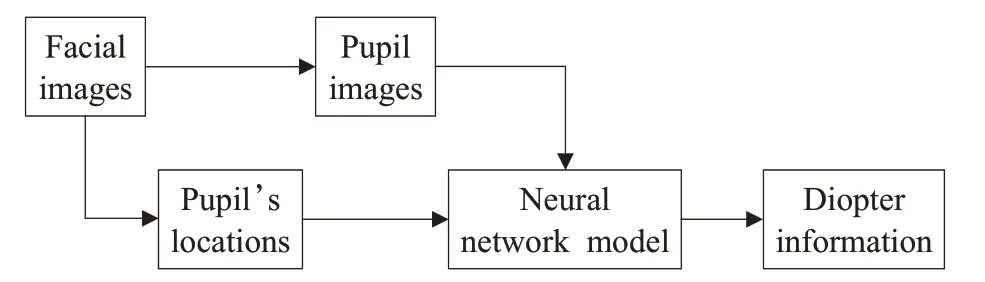
图4 基于深度学习的屈光检测方法Fig.4 Refractive detection method based on deep learning
2.1 自制数据集
使用深度学习的方法进行屈光检测,其中一个关键前提是要对神经网络模型进行训练,这需要大量的数据,此数据包括被测者瞳孔图像以及瞳孔位置信息。然而,目前还没有公开的包含以上两种数据的用于屈光检测的数据集,因此,需要自制数据集。
本研究所采集的数据包括:近红外偏心摄影面部图像、球镜和柱镜。其中,近红外偏心摄影面部图像是通过第1章中所述的图像采集系统,在环境相对稳定的室内所采集获取的,共采集了1 517组面部图像(3 034组瞳孔图像),每组图像由22幅在不同光源下所拍摄的图像组成,并且为避免拍摄过程中位置移动影响,控制相机以每秒30帧的速度拍摄;球镜度和柱镜度由专业持证验光师对被测者进行多次验光,并取平均值而得。
2.1.1 图像预处理
基于第1章中的偏心摄影验光原理和图像采集系统,获取近红外面部图像,图像如图5所示。本文所提出的屈光检测方法,需要使用瞳孔图像以及瞳孔位置信息作为输入,因此,在整幅近红外面部图像中,仅对瞳孔区域感兴趣。

图5 近红外面部图像Fig.5 Near infrared facial image
为了从面部图像中获取瞳孔区域图像以及瞳孔位置信息,需要使用图像处理技术对面部图像进行处理,步骤如图6所示。

图6 预处理流程图Fig.6 Preprocessing flow chart
首先,使用模板匹配[10]的方法分别对左右眼区域进行定位,并根据匹配结果的坐标判断左眼与右眼。模板匹配方法采用归一化平方差匹配法(TM_SQDIFF_NORMED),当模板与目标区域完全匹配时,计算数值为0,两者匹配度越低,计算数值越大。其形式如下所示:

为了降低计算量,避免对面部非眼部区域进行无意义的处理,所以根据模板匹配结果提取眼部区域图像,对非感兴趣区域进行舍弃,如图7(a)所示。在得到眼部区域图像后,需对图像进行二值化处理,为了准确提取目标,找到合适的阈值尤为重要。此处采用局部自适应阈值法进行二值化[11],利用图像的局部阈值代替全局阈值进行分割,根据图像不同区域像素点的灰度值分布计算局部阈值,实现不同区域采用不同阈值分割的效果。多次实验结果表明,采用75×75大小的模板进行高斯加权平均值运算,可以实现较理想的效果,对眼部区域图像采用局部自适应阈值二值化,结果如图7(b)所示,中间的白色圆形区域即为瞳孔区域。

图7 瞳孔区域提取过程Fig.7 Pupil region extraction process
由经过二值化后的眼部图像可以看出,图像中不仅包含了瞳孔区域,还包含其他眼部干扰信息,瞳孔区域与干扰信息间具有较明显的分界,遂使用区域生长法对瞳孔区域进行提取[12]。区域生长法是一种可以精确地将具有某种特征的像素点区域提取出来的算法,其基本原理是判断相邻的像素元素是否具有相同特征,并将具有相同特征且能够连通的像素点合并为生长区域。提取结果如图7(c)所示。
提取瞳孔区域后,其边缘并不平滑,这将有可能导致部分有效信息缺失,因此对瞳孔区域进行形态学滤波,填补瞳孔边缘较小空洞,并去除边缘毛刺。对一组图像进行上述预处理步骤,得到22幅不同偏心光照状态下的瞳孔图像,每幅图像尺寸均为128×128,如图8所示,这将作为本文屈光检测方法的输入图像。

图8 一组预处理后的瞳孔图像Fig.8 A set of preprocessed pupil images
2.1.2 数据集制作
本文采用监督学习的方法进行屈光检测,数据集包含特征与标签,其中特征又由混合数据组成,包括图像数据与数值数据。数据集的组成如图9所示。本研究一共获取了3 034组数据样本,其中80%用于训练屈光检测神经网络,20%用于测试。采用深度学习框架Keras,一 个NVIDIA GeForce GTX 1060 GPU与16 GB内存用于训练和测试。
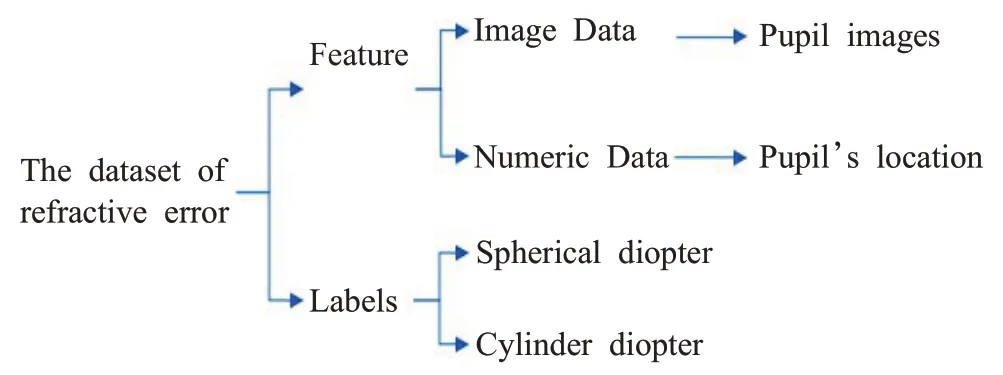
图9 数据集组成Fig.9 Composition of data set
2.2 提出SE-mini-Xception网络
数据集中每一组数据样本中都包含了22幅单通道瞳孔图像,这22幅图像是通过偏心摄影原理获取的,每幅图像在采集使所使用的光源不同,即每幅图像所呈现出的特征及信息都因光源的方位以及偏心距的不同而不同,各图像中所包含的屈光信息将由22幅独立的图像综合而决定。
为了更方便地将多幅图像输入到神经网络中,在训练前将每组数据样本中的22幅单通道瞳孔图像进行通道的合成,即以一个22通道数据的形式输入到网络中,其尺寸为128×128×22。考虑到上述偏心摄影图像的特点,一组数据中的每幅图像在相同区域下所呈现的特征和代表的信息都是不一样的,可以这样理解,虽然同一组图像中的某个相同区域所代表的都是瞳孔的某个特定区域,但此特定区域中瞳孔图像的明暗分布是不同的,即其包含的屈光信息是不同的。这将导致,合成后的22维数据,其在相同区域内的各通道信息具有一定的独立性,意味着若想更好地获取屈光特征,需要将通道与区域进行解耦。因此,本研究在网络中使用了深度可分离卷积[13],用于将通道与区域分开考虑,从而更好地提取屈光信息特征。
标准的卷积过程,对应图像区域中的所有通道均被同时考虑,深度可分离卷积提出了一种新思路:对于不同的输入通道采取不同的卷积核进行卷积。它将普通的卷积操作分解为了两个过程:深度卷积和逐点卷积。采用深度卷积对不同的输入通道分别进行卷积,然后将得到的特征图进行第二次卷积,将上面的输出进行结合,这里的卷积都是1×1的逐点卷积。使用深度可分离卷积可将通道与空间区域分开考虑,并可大幅降低计算量和模型参数量。以三通道输入为例,其卷积过程如图10所示,多通道与之类似。
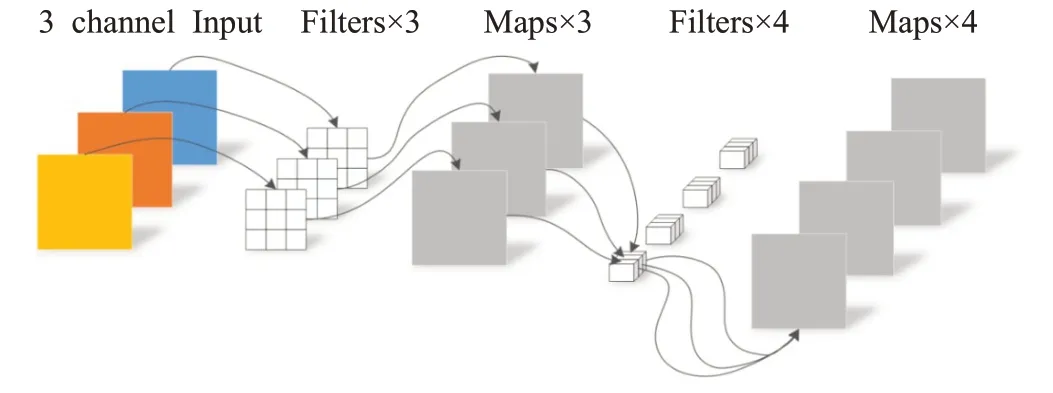
图10 深度可分离卷积过程Fig.10 Process of depthwise separable convolution
由于22幅图像是在多个不同偏心距的光源下进行采集的,数据中的每个通道都包含了屈光信息,但根据偏心摄影验光原理,不同偏心距对图像中亮暗阴影呈现是不同的,即各通道所包含的屈光信息的重要程度是不一样的。因此,本研究中引入特征重标定卷积(SE模块)[14-15],通过学习的方式自动获取到每个特征通道的重要程度,然后依照此重要程度去提升有益特征并抑制对当前任务用处不大的特征。SE模块如图11所示。

图11 SE模块Fig.11 Squeeze-and-Excitation module
SE模块主要包括三个步骤:压缩(Squeeze)、激励(Excitation)、重标定(Reweight)。首先进行压缩(Squeeze)操作,顺着空间维度来进行特征压缩,将每个二维的特征通道压缩为一个实数,此实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道相匹配,如公式(2)所示。式中下标c表示第c个通道。

其次是激励(Excitation)操作,为每个特征通道生成权重。如公式(3)所示,其过程可以分为三步,首先经过一个全连接层,将特征维度进行降维,然后经过ReLu函数激活后再通过一个全连接层将维度恢复,最后经过Sigmoid函数获得0~1之间归一化的权重。此处的s即为通过前面的全连接层和非线性层学习而得到的权重。

最后是重标定(Reweight)操作,将激励操作后输出的权重作为经过特征选择后的每个特征通道的重要性,逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定,如公式(4)所示:
我国廉政总署可以考虑就以下若干方面的权力作出法律规定:一、接受举报权;二、调查权;三、逮捕权;四、搜查权;五、限制转让(处置)财产权;六、预审、审问、登记权;七、要求交出(收缴)旅游证件权;八、建议解除公职权;九、采取预防措施权;十、起诉权;十一、审判权,等等。

综合考虑基于偏心摄影验光原理所获得的图像以上两个特征,提出了结合深度可分离卷积与SE模块的新型神经网络SE-mini-Xception,网络结构如图12所示。

图12 SE-mini-Xception网络结构Fig.12 Structure of SE-mini-Xception
Xception[13]是谷歌公司继Inception后,提出的InceptionV3[16]的一种改进模型,Xception的一个很重要的工作是提出用深度可分离卷积代替过去的标准卷积。本文所提出的卷积神经网络结构参考了Xception网络结构特点,经过对原有结构进行层数修剪以及修改,并且加入了SE模块为模型增加了注意力,因此将其命名为SE-mini-Xception。
SE-mini-Xception由输入流、中间流和输出流组成。其中输入流由两个深度可分离卷积层组成,实现对22通道图像信息的输入提取;中间流由4个结合了SE模块与残差模块的基础模块组成,基础模块结构组成如图13所示,每个基础模块中都使用了深度可分离卷积,并结合SE模块对各特征通道进行特征重标定,使用残差模块在降低计算量的同时起到防止神经元退化问题的发生,有利于网络更好地训练学习;输出流经过一个卷积层和池化层,并通过全连接层将SE-mini-Xception网络计算结果输出为一个一维张量。

图13 基础模块结构Fig.13 Structure of basic block
上述所提出的SE-mini-Xception卷积神经网络将用于处理图像信息,即本文中的22通道图像数据。此网络对每个多通道图像数据进行计算,返回一个一维张量,用于后续的屈光度预测。因此,在本文中,SE-mini-Xception卷积神经网络将作为混合数据多输入神经网络的一条核心分支使用。
2.3 混合数据多输入神经网络
本文所提方法基于偏心摄影验光原理进行屈光检测,并且在图像采集过程中不严格要求被测者与图像采集系统光轴对齐,而是允许被测者在一定范围内可产生位移,本文将瞳孔位置信息以及瞳孔图像信息相结合,从而解决屈光检测过程中的位置适应性问题。基于以上目的,提出混合数据多输入神经网络结构,神经网络结构如图14所示。
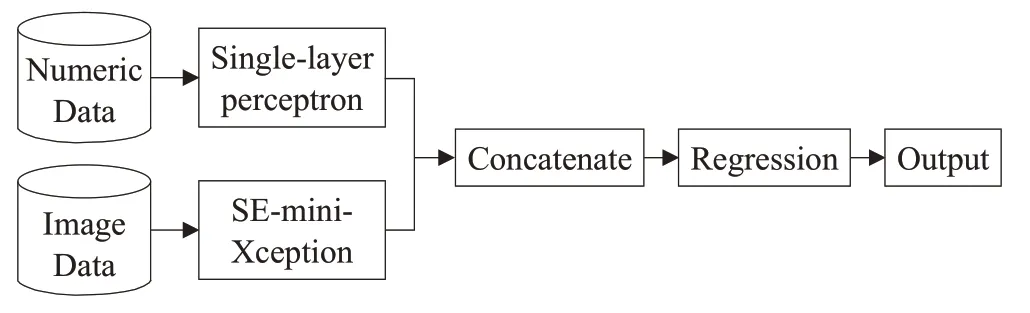
图14 混合数据多输入网络Fig.14 Mixed data and multiple input network
此混合数据多输入神经网络模型由两个分支组成,分别为数值分支和图像分支。其中,数值分支较简单,数值数据经过不使用激活函数的单层感知机计算,输出一个一维张量,记为T1。由于此处的数值数据仅用到了瞳孔位置信息,且不使用激活函数,因此此处的单层感知机相当于仅对位置数值做简单的线性变换。图像分支如2.2节所述,输入一组22通道图像数据,经过SE-mini-Xception卷积神经网络的处理,输出一个一维张量,记为T2。
上述两分支仅用于提取特征信息,并不进行屈光度结果的回归计算,回归计算放于两分支连接后进行。将数值分支和图像分支所输出的两个一维张量T1、T2进行连接组合,形成一个新的一维张量T3,并使用以“tanh函数”为激活函数的全连接层进行回归计算,从而得到屈光度预测结果,此处屈光度结果包含柱镜度和球镜度。
2.4 网络训练
本文使用均方误差(MSE)作为损失函数,如式(5)所示,其指参数估计值与参数真实值之差平方的期望值。

使用决定系数(R²_score)作为评价指标,如式(6)所示,决定系数反应因变量的波动,可以用来判断模型对数据的拟合能力,决定系数越高,则模型对数据的拟合能力越好。
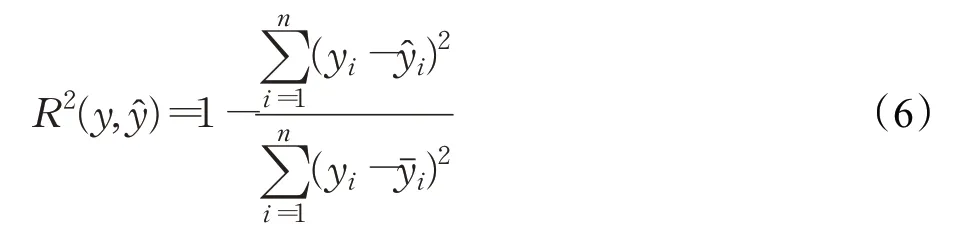
并使用随机梯度下降法训练模型,设置batch size为16,epochs为70,初始学习率为0.000 1;设置自适应学习率下降,val_loss五次不下降便将学习率修改为原来的二分之一;训练过程中保留验证集中决定系数最大的模型。训练结果如图15所示。图中,本文的混合数据多输入神经网络的R²_score为99.17%。
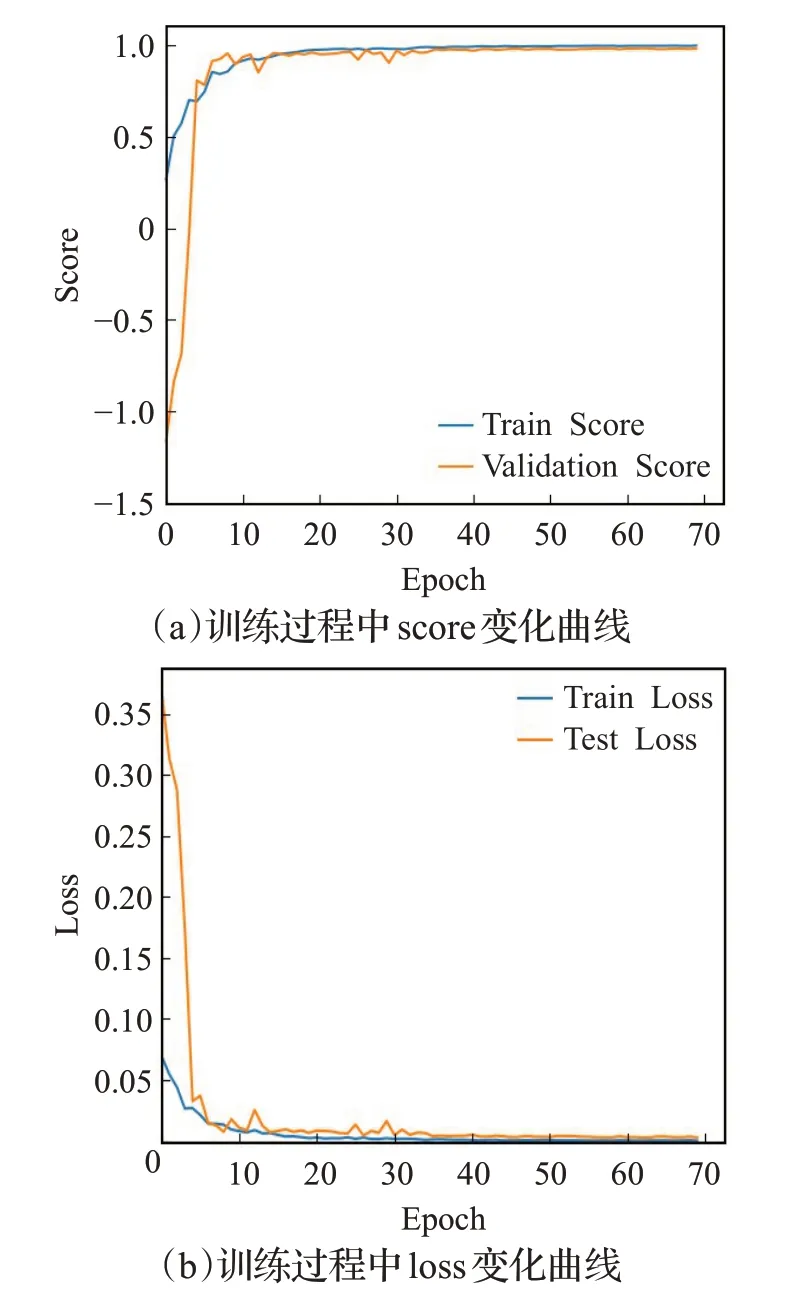
图15 网络训练过程评价Fig.15 Network training process evaluation
3 实验与分析
3.1 屈光度准确性实验
本文用于测试的样本共有613个,球镜度分布范围为-8.0D~2.75D,柱镜度分布范围为-2.5D~0D。使用上述所提出的神经网络模型对所有测试样本进行屈光度预测。
为了更直观地看出屈光度预测结果,从测试样本中随机选取100个样本,将此100个样本的球镜度和柱镜度的标签值与预测值进行对比,得出如图16和图17所示结果。

图16 球镜度预测Fig.16 Spherical diopter prediction
由图16、图17结果显示,球镜度与柱镜度预测结果均与标签值接近,随着标签值单调递增的过程而单调递增。因此,可以得出结论,使用本文中所提出的深度学习屈光检测模型,能够实现屈光度的计算,且与标签值变化趋势基本一致。

图17 柱镜度预测Fig.17 Cylinder diopter prediction
为了更清楚地分析屈光度预测结果,验证本方法在不同球镜度和柱镜度范围内的适用性,在此处将屈光度范围进行分级,并分别对每级的预测结果进行准确度分析。由于目前市面上的多数视力筛查仪的球镜度与柱镜度的精度为±0.50D,因此将此处的预测准确定义为预测值与标签值的差的绝对值在0.50D以内。
如表1所示,将球镜度范围分为9类,将-8D到0D范围内的球镜度按1D的间隔进行分类,将大于0D的球镜度单独作为一类。结果显示,613例测试样本中预测准确的样本数共计536例,准确率达87.44%,高于韩国学者Chun于2019年做的相关研究[17],其以2.0D和2.5D为间隔对-5.0D到5.0D的球镜度对进行分级,并进行分类预测,准确率为81.6%。
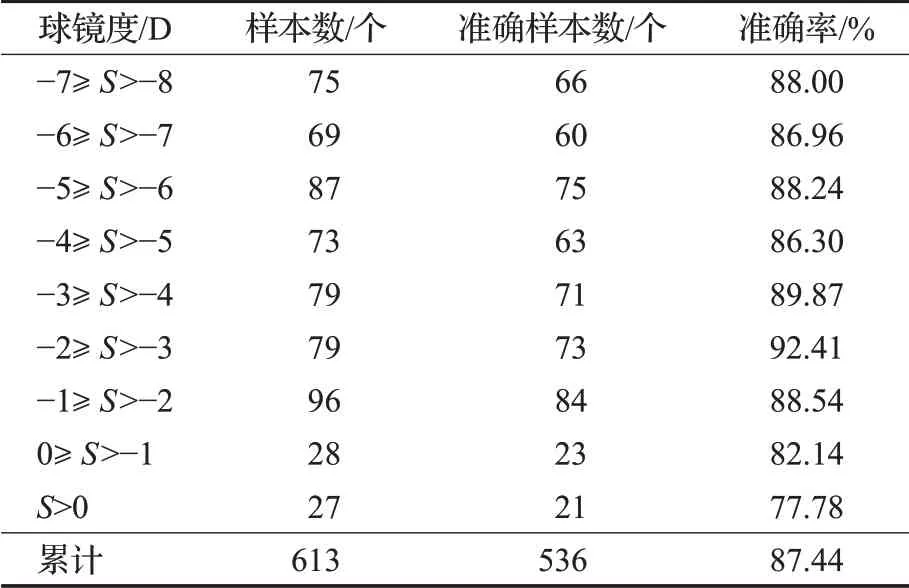
表1 球镜度预测结果Table 1 Result of spherical diopter prediction
表1中结果显示,各类球镜度范围的预测准确率均在总体准确率87.44%上下波动,且波动范围较稳定。其中S>0D的预测准确率稍低,这是由于远视样本较少,且样本分布不均,因此预测准确率较低。可以得出结论,本文所提出的屈光检测方法对于-8.0D到0D范围内的球镜度均适用。
如表2所示,将柱镜度范围共分为了5类,将-2.0D到0D范围内的柱镜度以0.5D的间隔进行分类,将小于-2.0D的柱镜度单独作为一类。结果显示,613个测试样本,其中预测准确样本数为566个,准确率达92.33%。表中结果显示,在柱镜度小于-2.0D以及在-2.0D到-1.5D范围内,柱镜度预测准确率较低,这是由于散光程度较严重的样本较少,且分布不均,模型对这部分样本特征未能较好地学习,因此预测准确率偏低。不过,表2所示结果,可以得出结论,该模型在-1.5D到0D范围内的柱镜度预测较准确,均在95%左右。
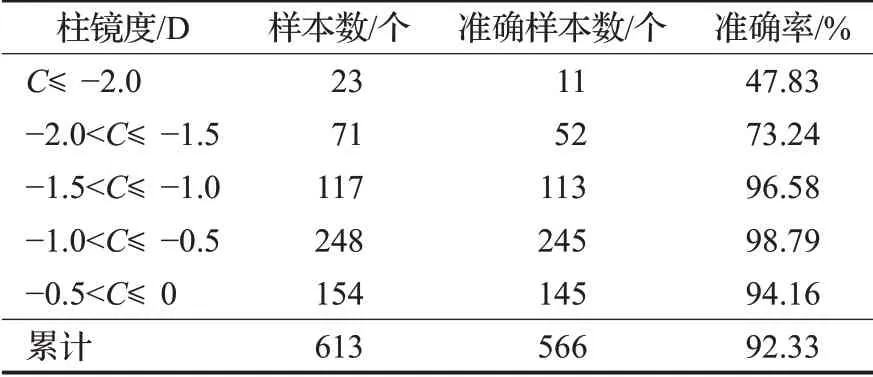
表2 柱镜度预测结果Table 2 Result of cylinder diopter prediction
综上所述,本文所提出的基于深度学习的屈光度预测算法,适用于绝大多数范围的屈光度预测,并且可以同时实现球镜度和柱镜度的预测,准确率分别达到87.44%与92.33%,超过了现有的基于深度学习的屈光度预测方法。
3.2 位置适应性实验
本文所提方法不需要严格要求被测者对准图像采集系统光轴,给被测者提供了一定的位移范围,具有位置适应性的功能。因此,在本节中,对该方法的位置适应性进行实验分析。
以图像中心点为原点,计算每个瞳孔图像质心与图像中点的距离,即瞳孔偏心距,此处偏心距的单位为像素。正常人的瞳距约为58 mm到75 mm,根据图像传感器分辨率(1 280×1 024)、像元尺寸(4.8 μm×4.8 μm)、拍摄距离为1 000 mm、镜头焦距为50 mm,计算而得,在要求被测者对准图像采集系统光轴时,正常人的瞳孔偏心距在此图像中的对应范围约为302到390之间。
为验证本方法对瞳孔不同位置状态的适应性,对瞳孔偏心距进行分级。如表3所示,将测试样本的瞳孔偏心距进行划分,共分为七类,250到500范围内以50为间隔划分为五类,大于500和小于250的偏心距各单独为一类。表中结果显示,随着偏心距的改变,球镜度和柱镜度的预测准确度并没有剧烈波动,球镜度预测准确度保持在80%以上,柱镜度预测准确度也在90%左右。其中,在偏心距小于250时,球镜度与柱镜度的预测准确率均较低,此处由于样本量较少,深度学习模型对特征学习不充分,导致预测准确率较低。
由表3结果,可以得出结论,本文所提出的屈光度预测算法,具有位置适应性的特点。
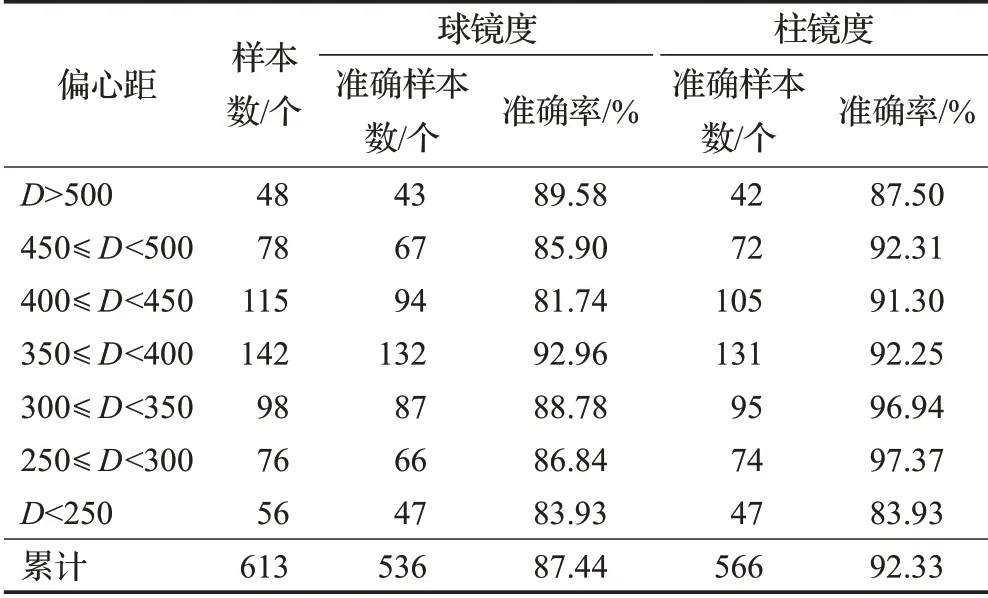
表3 位置适应性结果Table 3 Result of location adaptability experiment
4 结束语
本文提出了一种基于深度学习的屈光检测算法,作为对未来自助式屈光检测算法的一种探索尝试。在该方法中,首先进行了图像采集系统的搭建,使用搭建好的图像采集系统进行基于偏心摄影验光原理的近红外人脸图像的采集;然后使用图像处理技术对人脸图像进行预处理,得到瞳孔图像和瞳孔位置信息;最后使用预先训练好的具有数值分支和图像分支的混合数据多输入神经网络进行屈光度的预测,其中图像分支使用了针对图像数据集特点特地设计的卷积神经网络。
本文提出的端到端的神经网络模型,可以同时预测出球镜度和柱镜度结果,在测试样本中,球镜度准确率为87.44%,柱镜度准确率为92.33%,较大地超过了目前的基于深度学习的屈光检测方法,且随着数据集的积累,准确率将进一步提高。同时该方法将瞳孔位置信息作为神经网络模型的输入,有效地解决了传统屈光检测方法对被测者位置要求较高的问题,有望实现自助式的屈光筛查。
该方法目前还存在一些不足,有待进一步研究。目前数据集较小,模型准确率和位置适应性还存在很大的优化进步空间;模型不够精简,运行速度还有待提高;该方法目前仅考虑了瞳孔图像和位置信息,随着数据的积累,未来将结合被测者相关个人信息,如BMI、性别、父母近似情况等与近似相关的因素,进一步提高准确率;模型目前可以同时预测出球镜度和柱镜度,未来将进行球镜、柱镜、轴位三个信息的同时预测研究。
猜你喜欢
中国眼镜科技杂志(2022年9期)2022-09-07
广东医科大学学报(2020年6期)2020-02-06
中医眼耳鼻喉杂志(2019年3期)2019-04-13
青年歌声(2018年2期)2018-10-20
中国眼镜科技杂志(2017年13期)2017-08-16
中国眼镜科技杂志(2017年13期)2017-08-16
中国眼镜科技杂志(2017年13期)2017-08-16
阅读与作文(初中版)(2017年6期)2017-07-05
中国实用医药(2016年19期)2016-08-05
学苑教育(2015年16期)2015-08-15
