
使用CIDOC CRM构建建筑领域非遗知识本体
2023-02-14 10:32王艺茹史东辉
计算机工程与应用 2023年3期
王艺茹,史东辉
安徽建筑大学 电子与信息工程学院,合肥 230601
非物质文化遗产作为优秀的传统文化需要人们共同保护和传承,而中国是拥有非物质文化遗产数量最多的国家,利用现代计算机技术实现非遗的保护、管理和利用,是广大学者学习和研究的方向。知识本体技术的出现为实现非遗的数字化管理提供了条件。
本体(ontology)是对某一领域内概念类及其类之间关系的形式化表示[1]。“本体”一词最早起源于哲学。现在,本体已经在人工智能、软件工程、语义网等领域广泛应用。将本体技术应用于非遗知识的构建,使非遗数据由单一线性组织转变为多元特征的知识组织形式[2],可以解决非遗领域知识半结构化、碎片化的问题,促进对非遗文化的研究和传承,也促进非遗知识的传播。
本项目的目标是构建一个非遗知识领域本体,实现对我国非物质文化遗产的基本信息以及知识关联的描述。考虑到非遗知识的特殊性,本文采用CIDOC概念参考模型(CIDOC conceptual reference model,CIDOC CRM)对该领域本体的核心概念类和关系进行定义,并以中国传统木结构建筑营造技艺这一非遗领域为例进行本体构建。最后,对所建立的本体数据进行存储,以知识图谱的形式做出可视化展示。
CIDOC CRM模型是国际博物馆理事会(ICOM)国际文献委员会(CIDOC)开发的一套应用于文化遗产的信息集成概念参考模型[3]。CRM模型的开发工作始于1996年[4]。经过20多年的开发和维护,模型的最新版本Version 7.2于2021年9月发布。该模型共声明了81个类和160个属性。CRM模型的主要作用是实现不同来源文化遗产信息之间的信息交换和整合,其目的是提供必要的语义定义,将不同的、本地化的信息源转换为一致的知识资源。在CIDOC CRM模型与文化遗产领域本体结合的应用中,可以根据所研究的特定文化遗产领域,在该模型中选取部分结构,而非照搬所有结构,并且可以在模型原有结构上进行扩展和简化。扩展可以获取更丰富的文化遗产信息,简化可以去除部分不需要的结构。截至目前,国内外已有很多专家和学者成功应用CIDOC CRM模型构建文化遗产领域本体。在国内,刘宏哲等利用CIDOC CRM概念模型及Web Services技术构建了虚拟博物馆的语义网络架构,在不改变原有文物数据的基础上,最大程度地实现了数据共享与交换[5]。戴畋在博物馆影像数字化管理方面,提出了一个以CIDOC CRM模型为框架的文物影像集成方案,在智慧博物馆标准化体系研究中做出了有益尝试[6]。吴琼等考虑到不可移动文物描述的局限性,提出CIDOC CRM模型与地理本体融合的方法,针对不可移动文物提供了保护管理的思路[7]。何琳等以CIDOC CRM模型为框架,结合自然语言处理技术构建了先秦典籍《左传》的知识本体,对古文文本进行研究并挖掘隐性知识[8]。在国外,Kouis等针对文化遗产文物保护记录存在的碎片化、不完整等缺陷,使用CIDOC CRM构建本体数据文件,用于保存文物无损检测产生的大量数据[9]。Davide等在EPIA项目中开发了一种可视化工具,旨在利用CIDOC CRM表示葡萄牙国家档案记录信息,最终实现用户浏览归档文件[10]。
以上是国内外的专家学者将CIDOC CRM与文物、博物馆等有形文化遗产结合的研究,而对于无形的文化遗产,即非物质文化遗产也有相应的研究。Carboni等使用CIDOC CRM模型开发了一个用于保存塞浦路斯教堂中的材料、空间和符号等信息的本体,用于记录遗产的有形和无形要素[11]。Hu等以广东瑶族庞旺节为例,运用CIDOC概念参考模型构建了庞旺节知识本体。该知识本体有利于非物质文化遗产的数字化存储和管理[12]。何春雨等以赫哲族非遗资源为例,利用CIDOC概念参考模型构建本体概念类、属性及其关系,为非遗资源的有序组织提供参考[13]。肖希明等提出以CIDOC CRM为框架,将本体应用于元数据系统,构建公共数字文化资源模型,为其语义互操作提供解决思路[14]。从现有研究成果来看,专家学者将CIDOC CRM与某地区或民族领域的非遗资源相结合的研究较多,而对于建筑领域的非遗资源还未曾发掘,再加上该领域非遗数据分布广泛,存在数据庞大且零碎的问题,本项目以中国传统木结构建筑营造技艺资源为例,提出了构建建筑领域非物质文化遗产知识本体来辅助知识管理,并为公众提供可视化服务。
表1列出了各种非遗知识表述方法的优、缺点和案例。从中可以看出,使用CIDOC CRM构建某特定领域的非遗本体能将各种碎片知识相联接,有较为明显的优势。非物质文化遗产有着悠久的文化底蕴和鲜明的地域特色,而建筑领域的非遗资源更有其独特的制作技艺和时代传承,包含了大量有形和无形的元素。目前,我国对建筑非遗资源的记录大多以网站和数据库的形式收集,存在知识关联性不强,多源异构以及知识记录不完整等问题。本项目通过引入本体和知识图谱技术,并充分利用CIDOC CRM模型的可扩展性,将建筑领域特性与模型结合,使非遗资源形成结构化的语义知识单元,最终实现非遗资源的检索、可视化与知识共享。

表1 各种非遗知识表现形式的优、缺点和案例Table 1 Advantages,disadvantages and cases of various forms of intangible cultural heritage knowledge representation
1 非遗知识本体构建
1.1 非遗知识要素分析与构建方法的确定
非物质文化遗产是国家的宝贵资源,它的保护与传承对弘扬民族文化和精神具有重要意义。非遗知识涉及人、物、时、地和非遗项目本身等方面[15]。非遗项目是指包含在国家非遗保护名录的每个具体项目。项目所涉及的人指非遗的传承人、相关活动的主办方、参与者等,项目所涉及的物指非遗文化的相关资讯、研究成果及代表作品等,项目所涉及的时间指其公布时间,文化发展中重要活动时间等,项目所涉及的地点指其申报地区/单位、分布地区等。非遗知识要素如图1所示。

图1 非遗知识要素Fig.1 Intangible cultural heritage knowledge elements
非物质文化遗产拥有庞大而复杂的信息量,随着时间推移也会产生相应变化[16]。基于非物质文化遗产本体的特殊性,本文采用人工方式来构建非物质文化遗产本体。七步法是经典的本体构建方法,其主要思想是将本体主要术语抽象为类别,然后定义类别的属性并构造实例,通过七个步骤对领域本体进行构建。本文将运用七步法结合CIDOC CRM元数据参考模型进行非遗本体构建,在实例化构建中使用TextRank算法进行本体扩充,使得本体内容更加丰富。
1.2 本体创建相关模型及TextRank算法
基于1.1节对非遗本体构建方法的确定,本文选择成熟本体方案CIDOC CRM作为基本框架。在CIDOC CRM中,每个实体都有自己的属性,实体之间的关系通过属性显示。其中实体以“E”开头,属性以“P”开头作为表示。模型规定每一个实体和属性都有其固定的编号,例如:“E52 Time-Span”表示“时间”实体,“E55 Type”表示“类型”实体,“P2 has type”表示“属于……类型”属性“,P4 has time-span”表示“发生时段”属性等。
基于非遗知识要素的分析,图2展示了以“E2 Temporal Entity”即“非遗项目”实体为中心,使用CIDOC CRM构建的实体-属性关系,例如:“非遗项目”与“地点”实体通过“P59 is located on(位于)”和“P105 right held by(申报关系)”连接,“非遗项目”与“参与者”通过“P128 carries(传承)”和“P147 curated(保护关系)”连接。这样的模型结构不仅可以表示本体概念类,还可以表示概念类之间的关系。
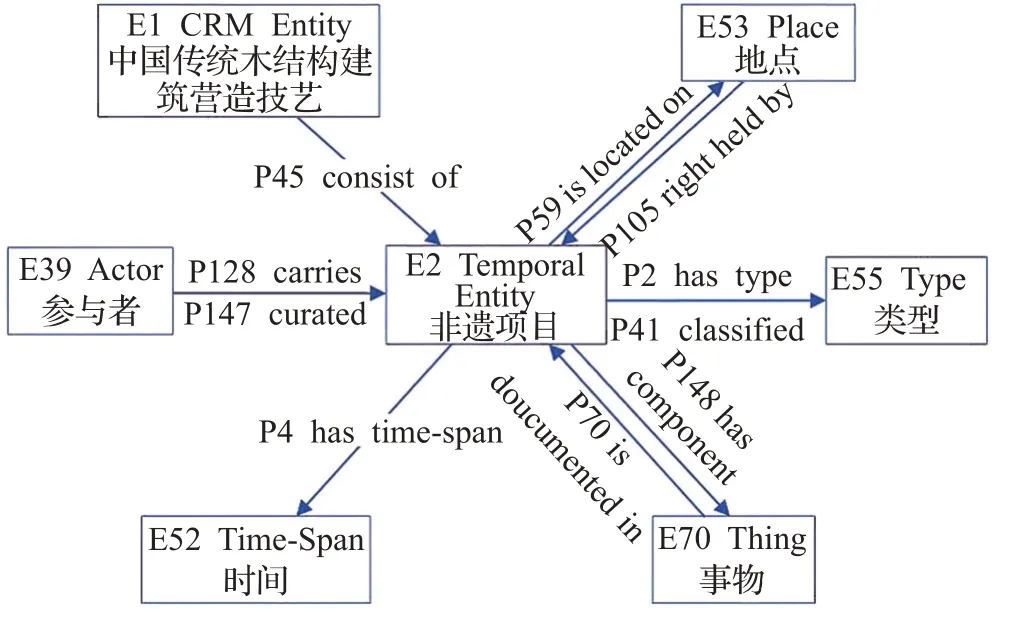
图2 CIDOC CRM“非遗项目”实体-属性关系Fig.2 Entity-attribute relationship of“intangible cultural heritage project”based on CIDOC CRM
在本体实例化创建过程中,本文选用TextRank算法,对收集到的非遗项目文本语料进行关键信息的抽取,并从中选取相关实例进行本体扩充。TextRank算法是一种基于图的关键词抽取和文档摘要的排序算法,它的实质是将文本数据转换为以词为节点,语义关系为边的网络图结构,通过投票机制,选取文本数据的关键词/词组及摘要。算法公式为:
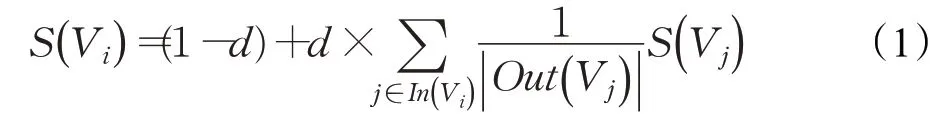
式(1)为算法对文本关键词的提取公式,其中,S(Vi)表示词语i的重要性,In(Vi)表示节点Vj的前驱节点集合,Out(Vj)表示节点Vj的后继节点集合,|Out(Vj)|表示集合中元素的个数。d为阻尼因子,通常取0.85。
对于文本摘要的提取,算法也有如下公式:

式(2)中节点V所代表的不再是词语,而是文本中的句子。其中,WS(Vi)为句子i的权重,求和表示与句子i相邻的句子对句子i的贡献程度,wji表示句子j与句子i的相似度。In(Vi)、Out(Vi)及d与式(1)意义相同。
对于句与句之间相似度的计算,公式如下:

式(3)左侧是句子i和j的相似度,即式(2)中的wji,右侧分子是同时属于两个句子的词语数量,分母表示两个句子所含词语的数量分别取对数再求和。
该算法将收集的文本语料整合成文本数据,通过句子分割、分词、向量表示,构成相似度矩阵,并转换为以词/句子为节点、相似度为边的图结构,用于计算TextRank值,最后通过排序将得分在前几位的词/句子输出。本文使用TextRank算法选取排名前6的关键词,出现频率超过3次的词组和排名前3的关键句子作为算法的输出。通过算法处理后,实现长篇文本数据的关键词/词组以及文本摘要的提取,简化本体实例的选取。算法具体流程如图3所示。

图3 TextRank算法Fig.3 TextRank algorithm
1.3 非遗本体构建思路与方法
本体构建流程如图4所示,分为7个步骤:(1)确定本体领域和构建目标。由于非物质文化遗产种类多、数量多、知识繁杂,直接构建非物质文化遗产知识的完整本体是困难的,所以本文选择中国传统木结构建筑营造技艺这一建筑营造类的非遗项目,构建非遗知识本体。(2)尝试复用现有知识本体。目前,在文化遗产领域已经出现了一些有影响力的本体模型,例如CIDOC CRM、ATT(the art & architecture thesaurus,艺术和建筑叙词表)等。根据非遗知识的特点,本文基于CIDOC CRM部分结构构建非遗领域本体。(3)列出领域重要术语。本体构建之前,要收集相关的领域知识,从多个数据源提取中国传统木结构建筑营造技艺这一非遗领域的重要信息和术语。主要数据来源为中国非物质文化遗产网站,如国家或各个省份的非物质文化遗产网站,其他数据源来自百度、官网相关文献和资讯等[17]。(4)定义类及其层次体系。CIDOC CRM具有一定的灵活性,对文化遗产具有强大的描述能力。通过对CIDOC CRM定义的实体概念类的研究,选取与非遗领域相符的概念类作为本文所构建本体的核心概念类,以保证本体框架的规范性,再将概念类进行层次划分和扩充。(5)定义类属性。本体概念类属性包含对象属性和数据属性[18]。对象属性描述类与实例之间的关系,其定义域和值域都是概念类或实例;数据属性描述类或实例与数值之间的关系,其定义域是概念类或实例,值域是不同的数据类型。本体通过属性的定义实现概念类的语义化描述。(6)定义属性约束条件。例如,定义函数型特性(functional properties)、反向函数型特性(inverse functional properties)和传递型特性(transitive properties)等。(7)创建实例。

图4 本体构建流程Fig.4 Ontology construction process
在定义了本体的概念类及其属性后,使用TextRank算法在大量的语料库中提取与领域本体相关的实例,扩展本体内容。
1.4 非遗本体数据存储与可视化
基于1.3节的思路和方法,结合非遗资源本身特点,项目采用Protégé本体编辑工具构建非遗知识本体。该软件是基于Java语言开发的本体编辑软件,它可以创建概念类、关系、属性和实例,对领域本体进行构建。在构建工作完成后,通过可视化插件OntoGraf查看本体所生成的语义关系图,并将已构建的非遗本体数据经过数据映射保存为RDF格式。标准资源描述框架(resource description framework,RDF)是机器可读的数据模型,用于描述Web资源特性以及各资源之间的关系。RDF是知识图谱的基础,它由节点和边组成。节点表示实体/属性,边则表示实体与实体及实体与属性之间的关系。之后将RDF本体数据存入Neo4j图数据库中,以知识图谱的形式做出可视化展示[19]。图5为知识图谱构建流程。使用Protégé完成本体概念、对象属性、数据属性和实例等的建立,本体创建完成后,将本体导入Neo4j图数据库中。RDF的存储使用N-Triples格式。
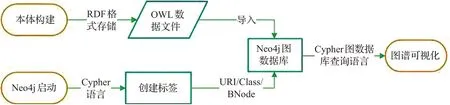
图5 知识图谱构建流程图Fig.5 Knowledge graph construction process
2 中国传统木结构建筑营造技艺本体构建
2.1 中国传统木结构建筑营造技艺概述
非遗项目中国传统木结构建筑营造技艺由徽派传统民居营造技艺与香山帮传统建筑营造技艺、北京四合院传统营造技艺和闽南民居营造技艺组成[20]。这种营造技艺延承了七千年,遍及中国全境,并传播到日本、韩国等东亚各国,是东方古代建筑技术的代表。因此,构建中国传统木结构建筑营造技艺本体,将资源进行有序整合,对非遗资源的保护和共享具有重要意义。
2.2 中国传统木结构建筑营造技艺概念类建立
本文在构建中国传统木结构建筑营造技艺本体时,借鉴成熟的CIDOC CRM模型,选用其部分概念类结构作为本文所建本体的核心概念类,并根据非遗领域特性对概念类进行扩充和分层管理。表2为本体核心概念类及子类的选取和描述。

表2 中国传统木结构建筑营造技艺本体概念类及描述Table 2 Ontological concept and description of building construction techniques for Chinese traditional wooded structure architecture
利用表3所描述的本体概念类信息,使用Protégé本体创建工具将顶层概念类命名为中国传统木结构建筑营造技艺,并建立其子类非遗项目类。非遗项目类含有从CIDOC CRM中选取的参与者、时间、地点、类型和事物5个子类。其中,参与者包含传承人和项目保护单位两个子类,时间为项目的公布时间,地点包含技艺分布地区和申报地区或单位两个子类,类型包含非遗类别、级别、题材、技法、材质5个子类。本体的概念类及其层次关系如图6所示。

表3 中国传统木结构建筑营造技艺本体对象属性(部分)Table 3 Ontological object attribute of building construction techniques for Chinese traditional wooded structure architecture(parts)

图6 本体概念类及其层次结构Fig.6 Ontological concept class and hierarchy
2.3 中国传统木结构建筑营造技艺属性建立
在确定了本体的概念后,需要确定本体的概念属性。概念属性包括对象属性和数据属性。对象属性描述概念与概念或者实例与实例之间的关系,将原本独立的概念或实例语义化地联系起来。本文所构建的本体对象属性一部分来源于CIDOC CRM本体模型,另一部分根据传统木结构建筑营造技艺的特殊性进行扩充。表3展示了从CIDOC CRM中选取的部分属性。表中第一列为从CIDOC CRM模型中选取的对象属性名称,如“P2 has type”描述非遗项目的类别,“P4 has timespan”描述非遗项目所公布的时间,“P5 consists of”描述非遗项目及其所含子项等;表中第二列是本项目中用于构建本体的对象属性;表中第三列、第四列分别是对属性定义域和值域的描述,用于添加属性约束,组成如“非遗项目-属于……类型-项目类别”“非遗项目-公布-公布时间”“非遗项目-包含-非遗子项”等三元组。图6为本体概念类及其层次结构。图7(a)为使用Protégé本体编辑工具创建的本体的对象属性及其层次结构。使用对象属性分别表示非遗项目与事物、参与者、地点、时间、类型之间的关系。一方面使本体概念类与对象属性的关系对应起来,另一方面对本体属性的扩充和完善提供了分组式的管理。

图7 本体概念属性及其层次结构Fig.7 Ontological concept attributes and hierarchy
数据属性描述概念类或者实例与数据之间的关系。根据传统木结构建筑营造技艺特点,结合相关资料定义的本体数据属性如图7(b)所示。其中,数据属性采用了与本体概念类相类似的分组方式,主要包括事物属性、参与者属性以及项目属性。事物属性包含对项目代表作品和文献/资讯的描述,其中,代表作品又包含名称、所属地区及所属时代;文献/资讯包含创建时间、来源等信息。参与者属性包含非遗项目传承人信息和保护单位信息。项目属性包含非遗项目编号、类别、申报地区等记录项目的基本信息。至此,本体的概念类及属性都已经确定。根据表2属性的定义域和值域的约束条件,在Protégé软件中添加约束,以实现语义关联,将原本独立的概念类联系起来。图8(a)为本体所建立的概念类及对象属性的关联关系,其连线对应图7(a)所建立的对象属性,图8(b)对(a)图中不同颜色的线对应的关系做出说明。

图8 本体概念类及关系模型Fig.8 Ontological concept class and relational model
2.4 中国传统木结构建筑营造技艺实例添加
在定义了本体的概念类和属性之后,需要对传统木结构建筑营造技艺这一非遗项目的实例进行添加。通过中国非遗网获取非遗项目的基本信息,再使用TextRank算法从官网相关文献和资讯、百度词条等文本语料中,获取文本语料的关键词、关键词组及关键句子,扩充本体实例,通过对象属性构建实例之间的联系,最终实现项目实例的语义化描述。
下面以中国传统木结构建筑营造技艺名录下的“徽州三雕(婺源三雕)”这一非遗项目为例,对本体进行实例化构建。图9为从中国非遗网中提取的项目基本信息。
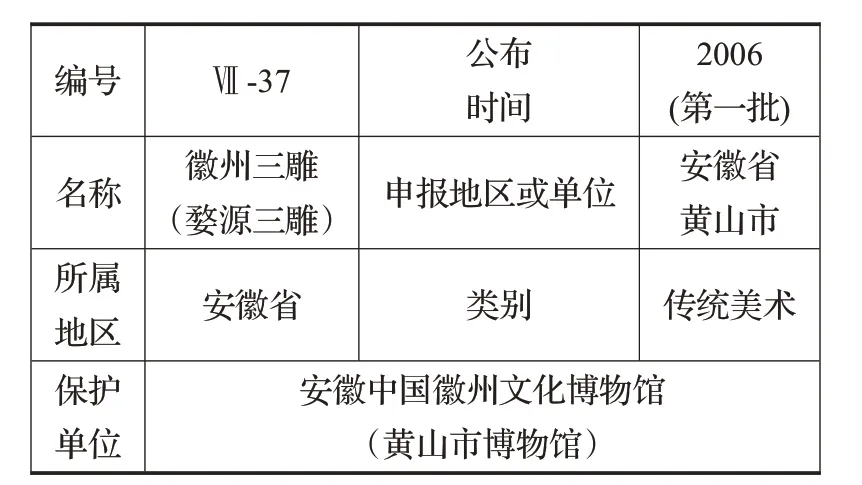
图9 徽州三雕(婺源三雕)基本信息Fig.9 Basic information of Huizhou three carvings(Wuyuan three carvings)
本体实例除了包含非遗项目的基本信息,还应包含在文本语料中提取的详细信息。图10为使用TextRank算法之前有关徽州三雕的文本语料。相比之下,图11为使用TextRank算法之后提取的有关徽州三雕文本语料的关键词、关键词组和关键句子。
对比图10与图11可知,运用TextRank算法可以将大篇幅的文本语料进行缩减。算法从文本中抽取关键词、关键短语和关键句子,并通过使用关键词、关键短语和关键句子对本体进行实例扩充。在获得了实例信息后,使用Protégé软件创建实例,并添加其相应的数据属性和对象属性。

图10 徽州三雕(婺源三雕)文本原始语料(部分)Fig.10 Original corpus of Huizhou three carvings(Wuyuan three carvings)tex(tpart)

图11 TextRank算法处理后的语料Fig.11 Corpus processed by TextRank algorithm
图12是“徽州三雕(婺源三雕)”实例化界面。图中红色边框内是建立的与本体概念类相关的实例。所建立的实例通过对象属性(图12蓝色边框)和数据属性(图12绿色边框)实现非遗项目与本体概念类之间的关联。图13为利用Protégé软件中OntoGraf插件对“徽州三雕(婺源三雕)”实例进行可视化的展示。
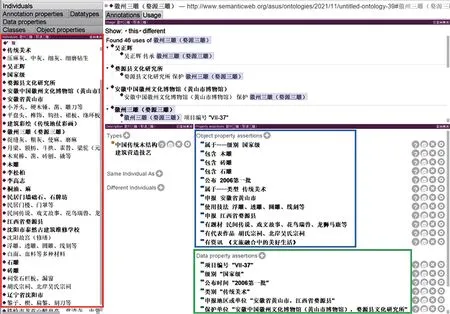
图12 徽州三雕(婺源三雕)实例化界面Fig.12 Instantiation interface of Huizhou three carvings(Wuyuan three carvings)
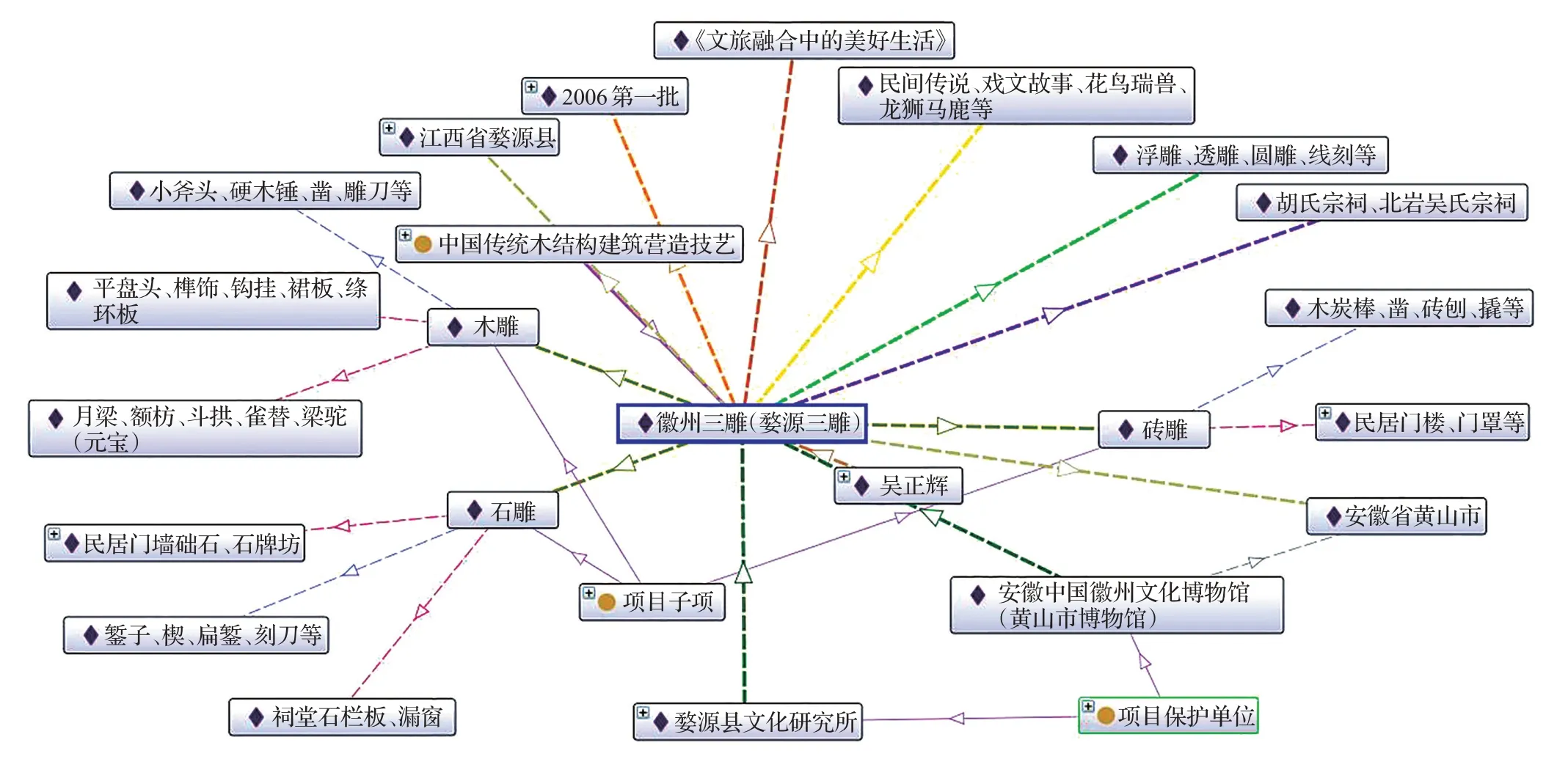
图13 徽州三雕(婺源三雕)实例可视化Fig.13 Visualization example of Huizhou three sculptures(Wuyuan three sculptures)
2.5 中国传统木结构建筑营造技艺本体的存储与可视化
使用上述方法完成了中国传统木结构建筑营造技艺知识本体的构建,并在领域内形成了结构化的数据。在此基础上,利用本体模型进行数据映射,将本体结构数据转换为RDF数据格式,存入Neo4j图数据库中,实现关联关系的可视化展示。图14展示了中国传统木结构建筑营造技艺名录下“徽州三雕(婺源三雕)”和“建筑彩绘(传统地仗彩画)”两个非遗实例的知识图谱。
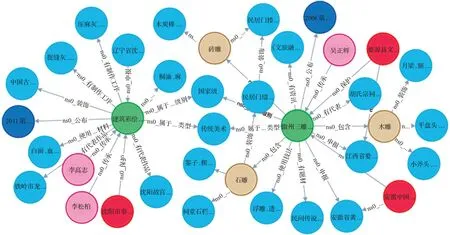
图14 中国传统木结构建筑营造技艺本体知识图谱(节选)Fig.14 Ontological knowledge graph of building construction techniques for Chinese traditional wooden structure architecture(parts)
3 结语
非物质文化遗产作为传承传统文化和民族风俗的动态载体,在几千年的历史长河中发挥着重要的纽带作用。对加强非物质文化遗产的保护、开发和利用,传承民族文化,弘扬民族精神,增强文化交流具有重要意义。中国古建筑有着自身独有的特征,如:屋顶造型、台基、屋身、装饰部件、木装修,构件、色彩、自由多变的样式、布局模式、立柱和横梁等。由于地域、年代变化,形成了大量各种形式的非遗信息。因此,建筑领域非遗知识本体的构建有其特殊性。本文首先介绍了CIDOC概念参考模型应用于文化领域、非物质文化领域的国内外研究现状,就此提出创建非遗领域本体,实现非遗知识的数字化存储,解决我国传统建筑非遗领域知识半结构化、碎片化的问题,并以中国传统木结构建筑营造技艺这一类非遗项目为例,使用CIDOC CRM模型,构建非遗核心本体,引入该领域的相关概念和关系。添加相关实例,扩展现有本体。通过TextRank算法实现建筑领域非遗知识本体实例的扩充,使得所建本体与建筑领域密切融合。随着研究的不断深入,未来将对该领域本体继续进行扩充,并通过自然语言处理、深度学习等知识抽取方法,对非遗项目文本语料进行信息提取,为非遗保护方法的信息化提供有效途径。所提出的方法对于传统舞蹈、戏剧、民间文学、民俗等非遗项目的结构化数据资源的建立和共享具有参考意义。
猜你喜欢
建材发展导向(2022年20期)2022-11-03
建材发展导向(2021年9期)2021-07-16
哈哈画报(2021年10期)2021-02-28
现代装饰(2019年11期)2019-12-20
制造业自动化(2017年2期)2017-03-20
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
振动、测试与诊断(2014年1期)2014-03-01
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
