针对全球储油罐检测的TCS-YOLO 模型
2023-02-14 12:22李想特日根仪锋徐国成
光学精密工程 2023年2期
李想,特日根*,仪锋,徐国成
(1.长光卫星技术股份有限公司,吉林 长春 130000;2.吉林省卫星遥感应用技术重点实验室,吉林 长春 130000;3.吉林大学 材料科学与工程学院,吉林 长春 130000)
1 引言
随着高分辨率光学遥感卫星的迅速发展,对自然或人造物体目标进行目标检测的大量应用逐渐进入研究团队的视野[1],其中关于储油罐的目标检测因具有挑战性的而备受关注。储油罐是用于短期或长期存储石油和天然气等液体或压缩气体的容器,通常呈圆柱形,顶部直径从6.1 m 至91.5 m 不等[2]。根据存储的材料不同,储油罐分为固定顶罐(也称拱形罐)和浮顶罐,本文的主要研究内容为全球固定顶储油罐和浮顶储油罐的目标识别。
标准圆形霍夫变换(Standard Circular Hough Transform,SCHT)是图像中检测圆形形状的开创性方法[3],后续有对其的修改,包括使用不变性内核和滤波器对SCHT 参数空间的搜索[4]优化等。对于高分辨率遥感影像储油罐检测的研究,Ok 提出基于阴影信息的储油罐检测方法,通过储油罐阴影区域的代表性边界推断圆形罐顶的位置信息[5],通过圆形储油罐的对称性,使用单半径方法计算径向对称性,进而推断圆形罐顶的位置信息[6]。在合成孔径雷达(Synthetic Aperture Radar,SAR)图像中,Wang等[7]应用提取明亮区域的方式获得储油罐候选区域,在光学图像中将对应的候选区域进行形状检测。Xu等[8]提出一种将储油罐的准圆形阴影和高亮弧相结合的方法来检测储油罐。
随着机器学习技术和卷积神经网络(Convolutional Neural Network,CNN)[9-10]的发展,其在遥感影像目标检测中得到广泛应用。Li等[11]使用显著性检测技术和GIST 特征[12]对遥感影像的候选区域进行识别,Huang等[13]应用支持向量机(Support Vector Machines,SVM)分类器,在像素和对象级别结合多个光谱和空间特征对遥感影像进行分类。在储油罐检测领域,Zhu等[14]使用一种从粗略到精细的策略,从遥感影像中基于概率潜在语义分析模型提取储油罐的图像块,进而使用霍夫变换和模板匹配检测圆形区域的储油罐顶部。Zhang等[15]使用椭圆和线段检测器(Ellipse and Line Segment Detector,ELSD)选择候选对象,方向梯度直方图(Histogram of Oriented Gradients,HOG)[16]和CNN 进行局部和周边的特征提取,SVM 分类器进行输出。Cai等[17]通过基于多尺度直方图对比度的数学形态学提出一种新的视觉显著性模型,使用霍夫变换进行储油罐检测,利用SVM 算法来确定储油罐的位置信息。
随着GPU 的普及和计算机储存容量的无限拓展,深度学习技术近些年得到了前所未有的发展。在深度学习的目标检测领域主要分为onestage 和two-stage 检测算法,其 中two-stage检测算法分为两个阶段:用相应的Region Proposal 算法从输入图片中生成建议目标候选区域;将所有的候选区域送入分类器进行分类[18]。代表算法有SPP-net[19],Fast R-CNN[20]和Faster R-CNN[21]等。One-stage 算法无需Region Proposal 阶段,直接生成物体的类别概率和位置坐标,具有更快的检测速度,但精度与two-stage 相比较低。代表算法有SSD[22]和YOLO 系列,包括YOLO[23],YOLO9000[24-25],YOLOv3[26-27],YOLOv4[28]和YOLOv5。在基于深度学习的储油罐研究中,Zalpour等[29]采用two-stage 检测方法,使用Faster RCNN 提取油库作为感兴趣区域(Region of Interest,ROI),最大程度地减少误报与处理时间,进而从ROI 中通过圆形检测方法选择多个候选对象,通过CNN 与HOG 方式进行特征提取,最后将储油罐的特征信息通过SVM 进行分类。Xu等[30]通过在backbone 部分使用DenseNet,增加检测尺度和用卷积层替换残差单元的方式对YOLOv3 网络进行优化,可在遥感影像中对储油罐进行识别。
上述储油罐检测研究均在各自领域取得了令人瞩目的成功,尽管如此,在此类研究的具体应用中还是存在着较为严重的问题:
(1)一些研究的关注对象为具有标准尺寸和形状的储油罐,当储油罐较小、有阴影或罐顶形状特殊时,应用普适性较差;
(2)一些研究为了消除颜色特征而保留亮度特征,使用灰色强度图像代替真彩色图像。与此同时,由于SAR 影像的特性,图像颜色趋近于灰色。此类情况在处理多种颜色储油罐(如灰色、棕色等)分类的场景下,适用性较差;
(3)一些研究使用的方式为检测候选区域选择后的图像块,而在高分辨率大尺寸遥感影像中,由于图像复杂度较高,会导致候选误报率大幅提升。同时,当图像与储油罐目标尺寸差距很大时,侧重于图像局部区域的图像块检测也不再适用;
(4)一些基于深度学习的研究使用two-stage算法,目标的训练速度和识别速度均较慢,且误报率较高;
(5)一些基于YOLO 模型的储油罐识别模型,网络模型较为简单,使用的优化技巧较为落后,导致识别精度低。
上述问题使得该类研究无法达到全球储油罐识别的工程化标准,本文提出一种基于优化YOLOv5 的全球储油罐检测模型TCS-YOLO,该模型的特点如下:
(1)使用较新的科研成果Transformer[31]架构,与传统CNN 进行互补;
(2)使用CBAM[32]代替传统的CONV 层,添加网络的注意力机制;
(3)优化YOLOv5 的损失函数,使用SIoU loss[33]代替CIoU loss 作为定位损失bbox_loss。
2 改进的YOLOv5 模型
2.1 YOLOv5
YOLOv5 是2020 年5月由Ultralytics 公司提出的one-stage 目标检测模型,包括YOLOv5n,YOLOv5s,YOLOv5m,YOLOv5l以及 YOLOv5x 5 个版本,他们的主要区别在于模型的深度和卷积核的个数,分别用depth_multiple 和width_multiple 参数控制。模型的尺寸与GFLOPs 和mAP 成正比,与推理速度成反比。YOLOv5 网络结构主要由backbone 和head 组成,其中head 中包括特征增强部分和预测部分。
YOLOv5 的backbone 主要由Focus 层、CONV 层、C3层和SPP(Spatial Pyramid Pooling)层组成。如图1 所示,其中Focus 层与普通卷积下采样相比具有更少的层数、参数和FLOPS值,同时减少了CUDA 内存,在保证了mAP 的前提下,提升了向前传播和向后传播速度。CONV层由Conv2d 卷积函数、BatchNorm2d 归一化函数和SiLU(Sigmoid Linear Units)激活函数[34]组成。C3 层是CSPBottleneck层[35]的改进版本,包含3 个卷积层和若干个bottleneck 模块,具有更快速且简便的特性。SPP 层位于backbone 层中最后一个CONV 层后,是一种采用空间金字塔池化方式来去除网络固定大小约束的卷积神经结构,将特征池化并生成固定长度的输出。
Head 层中的特征增强部分由PANet(Path Aggregation Network)[36]构成,旨在整合不同层级的特征,通过自下而上的路径增强,在较低的层次上增强了精确的定位信号,从而缩短了较低层和最顶层特征之间的信息路径。Head 层的预测部分与YOLOv4 和YOLOv3 版本的预测部分相同,包括3 个输出头,卷积步长分别是8,16 和32,大尺寸输出特征图检测小物体,小尺寸输出特征图检测大物体。

图1 YOLOv5 的backbone 层各结构示意图Fig.1 Schematic diagram of each structure of the backbone layer of YOLOv5
YOLOv5 的损失函数如式(1)所示。其定位损失bbox_loss 采用了CIoU loss,如式(1)第1 行所示;目标置信度损失obj_loss 和分类损失cls_loss 采用了BCEWithLogitsLoss 损失函数,如式(1)第2~4 行所示:
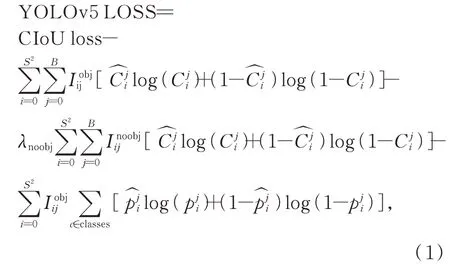
其中,CIoU loss 如式(2)~式(4)所示:

与其他定位损失函数相比,CIoU loss 在边界框与目标框不相交、完全包含和完全包含且中心点重合的情况下均有更优表现。
尽管YOLOv5 是当下速度最快、性能最佳和最易于训练的目标检测框架之一,但当应用到全球储油罐检测的任务中,在识别效率和准确率方面仍有一定的提升空间。
2.2 Transformer
Transformer 架构在许多NLP(Natural Language Processing)[37]任务中取得了最先进的结果,而在计算机视觉领域,CNN 一直作为最主要的模型在视觉任务中被广泛使用。随着深度学习的体系结构越来越高效,计算机视觉与NLP逐渐趋同。因此,为了降低架构的复杂度,探索可扩展性与训练效率,将Transformer 应用于计算机视觉领域成为一个新的研究方向。Facebook AI 团队提出的DETR 框架[38]是第一个成功使用Transformer 作为核心模块的目标检测框架。商汤科技团队提出的Deformable DETR[39]结合了可变形卷积的稀疏空间采样和Transformer 的关键能力建模的优点,缓解了DETR 的收敛缓慢和复杂性高的问题。Google 团队推出ViT 模型[40],将图像分为固定大小的块,在图像块上采用类似Transformer 的架构,完成对图像的分类和预测。微软推出的Swin Transformer 模型[41]通过合并更深层的图像块来构建分层特征图,与ViT 不同的是,Swin Transformer 模型的输入是图像的原始尺寸,最大程度地保留图像信息;Swin Transformer 模型的最大贡献是提出了一个可以广泛应用到所有计算机视觉领域的backbone,并且支持对大多数CNN 网络中出现的超参数进行调整。
Transformer 的结构主要分为encoder 和decoder 两部分,其中encoder 由positional encoding,multi-head attention,add&normalize 和feed forward 组成。其中muti-head attention 即多头注意力机制,是encoder 中最重要的组成部分,由scaled dot-product attention 并行化组成,其中scaled dot-product attention 的描述如式(5)所示。

其中:Q(Query)是一个包含查询的矩阵,即查询向量;K(Key)是序列中所有词的向量表示,内容为被查询信息与其他信息的相关性的向量;V(Value)表示被查询信息的向量;通过Q与K的转置的点积计算出注意力矩阵QKT,在经过softmax 归一化后给V加权,生成最终的结果。
Decoder 与encoder 结构相似,主要区别在于在自注意力层只被允许处理输出序列中更靠前的位置,即masked multi-head attention。同时,decoder 中的注意力机制并非自注意力机制,其Q矩阵由上一位置的decoder 输出中取得,K和V矩阵由encoder 的输出中取得。
在计算机视觉领域,Transformer 与传统CNN 方法相比,在训练效率方面表现出较明显的优势;Transformer 架构可以单独使用,也可以与CNN 混合使用,具有良好的扩展性。
2.3 CBAM
CBAM(Convolutional Block Attention Module)是卷积神经网络的注意力模块。给定一个中间特征图,该模块沿着两个独立的维度(通道和空间)依次推断注意力图,然后将注意力图与输入特征图相乘以进行自适应特征细化。
CBAM 包含两个模块,分别是通道注意力模块(Channel Attention Mudule,CAM)[42]和SAM(Spartial Attention Module,空间注意力模块)。其中,CAM 将输入的特征图通过平均池化和最大池化生成的特征送入多层感知器(Multilayer Perceptron,MLP)中,然后将各自的输出特征的对应位置求和,再经过sigmoid 激活操作后,与输入特征图做乘法操作,输出至SAM。SAM 将CAM 输出的特征图作为输入,基于通道应用平均池化和最大池化操作后,将各自的输出特征的对应位置做concat 拼接操作,再经过sigmoid 激活操作后,与输入特征图做乘法操作,生成最后的输出结果。总体来说,CAM 可以关注到更有意义的特征,而SAM 是对CAM 的补充,其注意力聚焦在这些有意义特征的所在位置。
CBAM 作为轻量的注意力模块,可以在所有常规的卷积层中使用,通过对CNN 网络添加多维度的注意力机制,可以有效提升网络性能。
2.4 SIoU loss
回归损失函数是深度学习算法的核心内容,在目标检测中同样起到关键作用,更合适的损失函数会生成更好的深度学习模型。SIoU loss 在CIoU loss 的基础上解决了目标区域尺度变化很大导致优化减慢的过程,如式(6)所示:

其中:SIoU loss 从面积差异方面对CIoU loss 进行修正,目的为解决CIoU loss 大损失值点周围梯度趋于平缓的问题,在CIoU loss 中的(1-IoU)项上引入面积调整系数γ,如公式(7)和公式(8)所示:

其中:s代表边界框面积,sgt代表目标框面积,当sgt为1 600(即40×40)时,γ值随边界框面积s的变化如图2 所示,γ可以平衡不同区域的边界框的损失值;当s=sgt时,γ=0,SIoU loss 退化为CIoU loss,当训练开始时,损失值较大,SIoU loss 为主要影响因素,随着损失值减少,边界框和目标框具有相似的区域大小,其中γ 的值变小,整体损失值更容易受到CIoU loss 的影响。
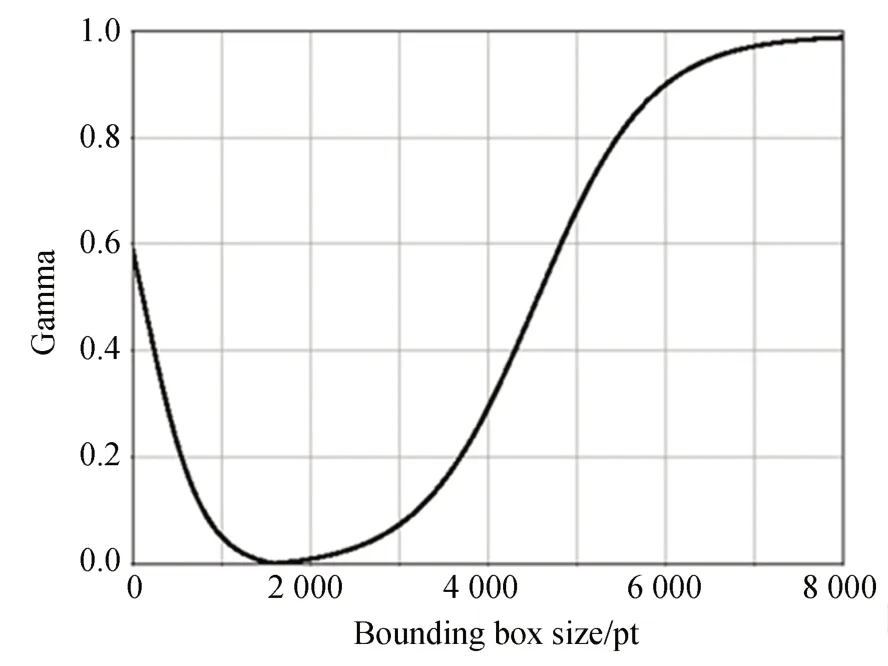
图2 目标框尺寸为1 600(40×40)时γ 变化情况Fig.2 Variation of γ with target frame size 1 600(40×40)
2.5 改进的YOLOv5
2.5.1 C3TR 优化
C3TR层即C3 层与Transformer 架构的 结合,该层仅使用Transformer 架构的encoder 部分,主要实现方式参考DETR 和ViT,步骤如下:
Step1 将输入的图像特征进行维度压缩后转化为序列化数据;
Step2 序列化数据与位置编码相加;
Step3 将全部数据送入Transformer 架构的encoder 中,进行多头注意力机制的处理,并进行残差连接;
Step4 通过全连接层得到最后的输出结果。
YOLOv5 网络 中共有8 个C3 层,其中有4 个位于backbone,在提取图像特征的过程中同时起到下采样的作用;另外4 个位于head,用于加强网络特征融合的能力。如表1 所示,就C3TR 层替换C3 层的位置对预测准确率的影响进行了对比实验。
以YOLOv5l 模型为例,在backbone 的最浅层(C3TR Position=1)、backbone 的最深层(C3TR Position=4)、head 的预测部分(C3TR Position=6,7,8)与全部head 层(C3TR Position=4,5,6,7,8)的C3 层分别替换C3TR 层,结论如下:
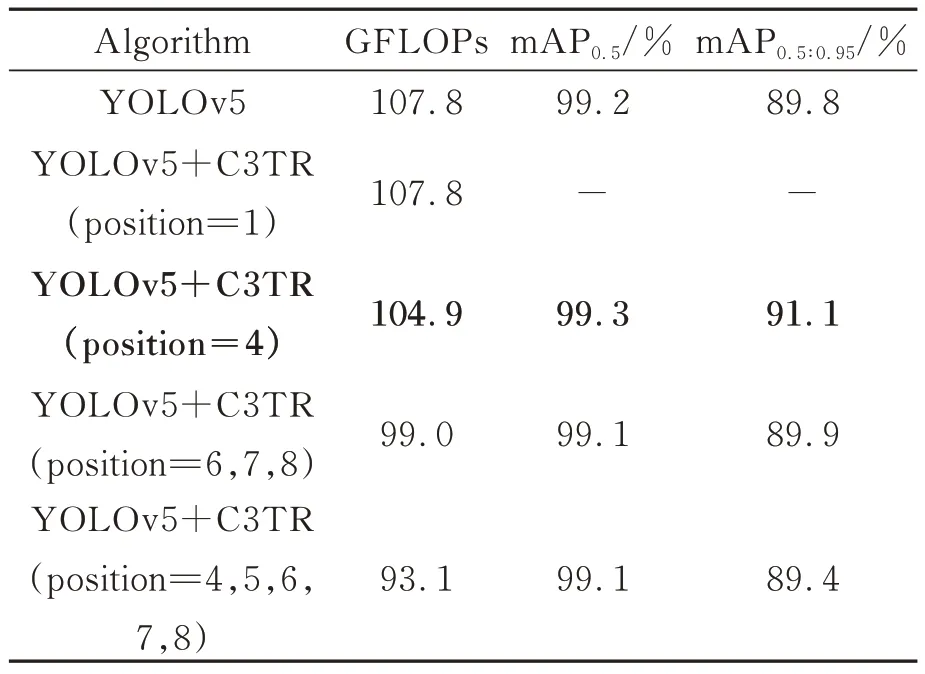
表1 C3TR 层替换位置对模型性能的影响Tab.1 Impact of C3TR layer replacement position on model performance
(1)在backbone 的最浅层替换C3TR 层,输入的图像尚未进行下采样,导致encoder 内存溢出,模型训练过程无法进行;
(2)在backbone 的最深层替换C3TR 层,获得最佳结果。与原模型相比,GFLOPs 降低2.9,mAP0.5提升0.1%,mAP0.5∶0.95提升1.3%;
(3)在head 的预测部分替换C3TR 层,获得结果不佳;
(4)在全部head 层替换C3TR 层,获得结果不佳。
与原始的Transformer 架构不同,由于层归一 化(Layer Normalization,LN)与批归一化(Batch Normalization,BN)相比更耗费内存资源,因此C3TR 取消了Step3 和Step4 之间的LN部分并进行对比实验,实验结果如表2 所示。

表2 LN 对C3TR 的影响Tab.2 Effects of LN on C3TR
(1)在模型复杂度方面,取消LN 的模型,其GFLOPs 降低2.9,模型复杂度更低;
(2)在识别准确率方面,取消LN 的模型mAP0.5和mAP0.5∶0.95分别提升了0.1%和1.3%,性能更优。
综上所述,由于Transformer 架构消耗的内存过大,因此将C3TR 层放置于backbone 与head的连接处,同时取消其中的LN 步骤,可以最大程度地节约GPU 和内存资源消耗,并作用到全部head 网络,获得最优识别结果。
2.5.2 CBAM 优化
CBAM 层是CONV 层与空间注意力模块和通道注意力模块的结合。在YOLOv5 网络中,共有8 个CONV 层,其中有4 个位于backbone,另外4 个位于head,就CBAM 层替换CONV 层的位置对预测准确率的影响进行了对比实验,实验结果如表3 所示。

表3 CBAM 层替换位置对模型性能的影响Tab.3 Effect of CBAM layer replacement position on model performance
以YOLOv5l 模型为例,在backbone 的最浅层(CBAM Position=1)与最深层(CBAM Position=4),backbone 的最浅层和最深层(CBAM Position=1,4),全部backbone 层(CBAM Position=1,2,3,4),全部head 层(CBAM Position=5,6,7,8)和全部层(CBAM Position=1,2,3,4,5,6,7,8)的CONV 层分别替换CBAM 层,结论如下:
(1)在backbone 的最浅层的CONV 层替换CBAM 层,与原模型相比,GFLOPs 相同,mAP0.5提升0.1%,mAP0.5∶0.95提升1.0%;
(2)其余替换情况均无法获得性能提升。
综上所述,将CBAM 放置于backbone 的最浅层时,其输出内容将作用到全部网络,同时模型复杂度最低,识别结果最优。
2.5.3 SIoU loss 优化
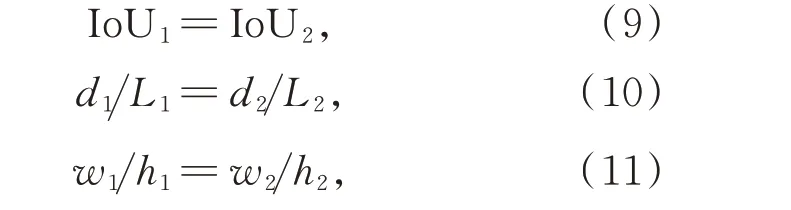
其中:d为两框中心点坐标的欧式距离,L为包含两框的最小矩形框的对角线距离。即在每种场景中,两幅影像预测框的IoU 相同,两框中心点坐标的欧式距离与包含两框的最小矩形框的对角线距离的比例相同,两框的长宽比相同。
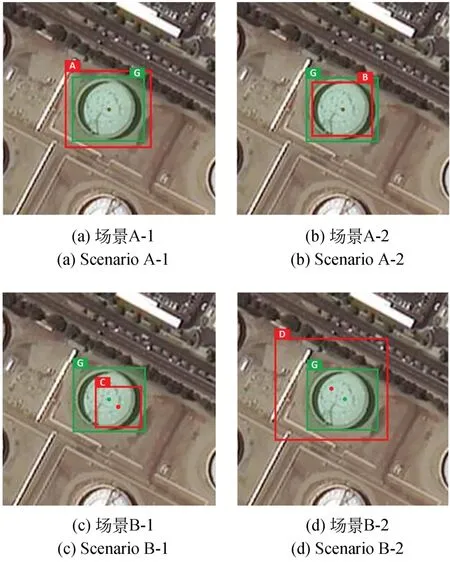
图3 同一储油罐对象的真实边框与多种预测边框Fig.3 Ground-truth and multiple predicted bounding boxes for the same tank object
在此情况下,现有的3 种几何因素(IoU,d和w/h)将失去效力,如表4 所示。

表4 不同的IoU 方式与结果Tab.4 Different IoU methods and results
(1)对于场景A,真实边框与预测边框中心重合,d=0,d/L=0,w/h=1.12,此时ℒIoU=ℒGIoU=ℒDIoU=ℒCIoU=0.3,CIoU 退化到IoU,此时IoU,GIoU,DIoU 和CIoU 均无法提供优化方向;ℒSIoU(A,G)=0.306,ℒSIoU(B,G)=0.31,此时仅SIoU 可以提供优化方向;
(2)对于场景B,真实边框与预测边框中心不重合,d/L=0.11,w/h=1.12,此时ℒIoU=ℒGIoU=0.6,ℒDIoU=ℒCIoU=0.624,CIoU 退化到DIoU,此时IoU,GIoU,DIoU 和CIoU 均无法提供优化方向,而ℒSIoU(C,G)=0.721,ℒSIoU(D,G)=0.862,此 时仅SIoU 可以提供优化方向。
应用到储油罐检测实验中,通过不同IoU 方式作为定位损失函数,研究损失函数对预测准确率的影响,其实验结果如表5 所示。
以YOLOv5l 模型为例,分别使用IoU loss,GIoU loss,DIoU loss,SIoU loss 作为定位损失函数,与原模型默认的CIoU loss 进行对比,结论如下:
(1)当使用IoU loss 作为定位损失函数时,mAP0.5和mAP0.5∶0.95降低0.1% 和0.9%,性 能下降;
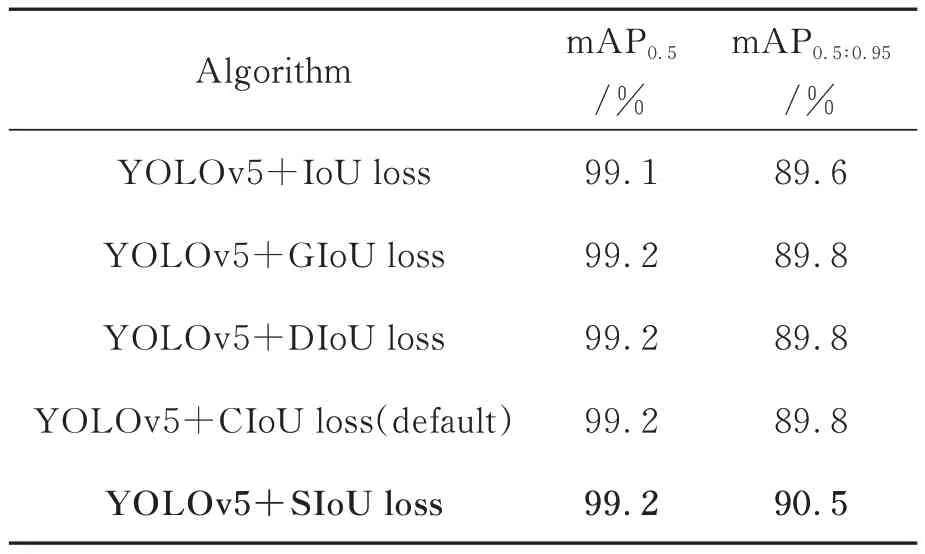
表5 不同IoU 方式的定位损失函数对实验结果的影响Tab.5 Influence of different IoU methods of localization loss functions on experimental results
(2)当使用GIoU loss 和DIoU loss 作为定位损失函数时,与原模型性能相同;
(3)当使用SIoU loss 作为损失函数时较原模型mAP0.5∶0.95提升0.7%,性能优于原模型。
综上所述,使用SIoU loss 可调整不同区域尺度的预测边框的损失值,增加损失函数的梯度,可以解决CIoU loss 在损失值较大的点周围梯度趋于平缓的问题,提高目标检测的精度。
2.5.4 TCS-YOLO
为了提升基于深度学习的全球储油罐目标检测模型的性能,结合上述章节内容,对YOLOv5 网络进行改进,得到TCS-YOLO 网络。如图4 所示,其中第1 层使用CBAM 层代替原CONV 层,在第9 层使用C3TR 层代替原C3 层,其余网络结构与YOLOv5 相同。
与此同时,在模型训练中使用的定位损失函数由CIoU loss 改为SIoU loss,TCS-YOLO损失函数如式(12)所示,其中α,ν和γ 如式(3)、式(4)和式(7)所示:
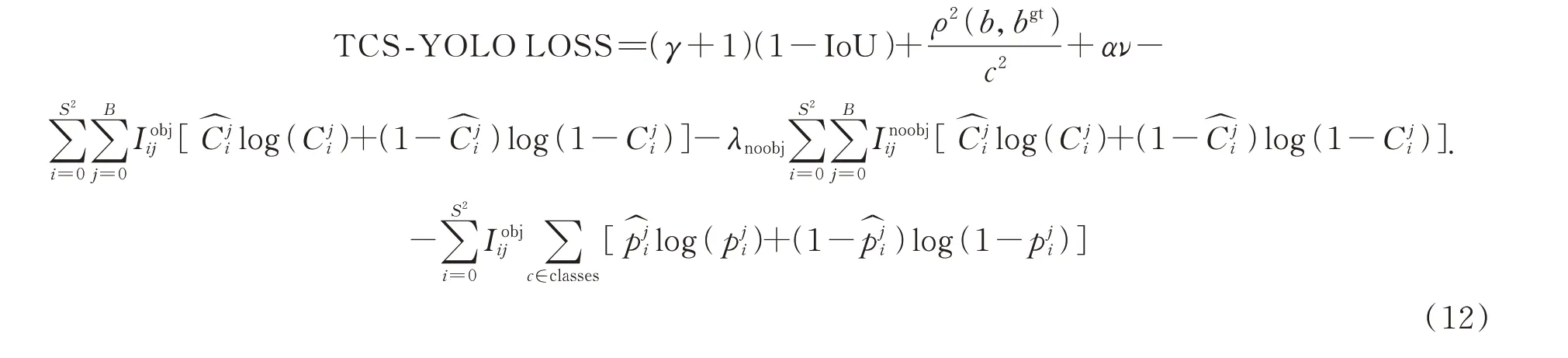

图4 TCS-YOLO 网络结构Fig.4 TCS-YOLO network structure
3 实验设置与结果分析
3.1 储油罐遥感影像数据集
储油罐遥感影像数据集使用43 幅吉林一号光学遥感影像,如表6 所示,影像涵盖来自全球六大洲(除南极洲)的具有代表性的20 个石油和天然气公司,其储油罐分布如图5 所示。通过对遥感影像的预处理,制作成3 658 张尺寸为416×416 的有效图像,经过图像旋转扩容(90°,180°和270°)后得到14 632 张图像,共包含91 884 个固定顶储油罐,23 688 个外浮顶储油罐。同时,为了减少误报,添加了150 张无标签的背景图片。随机选取数据集中的80% 作为训练集,其余20%为测试集。
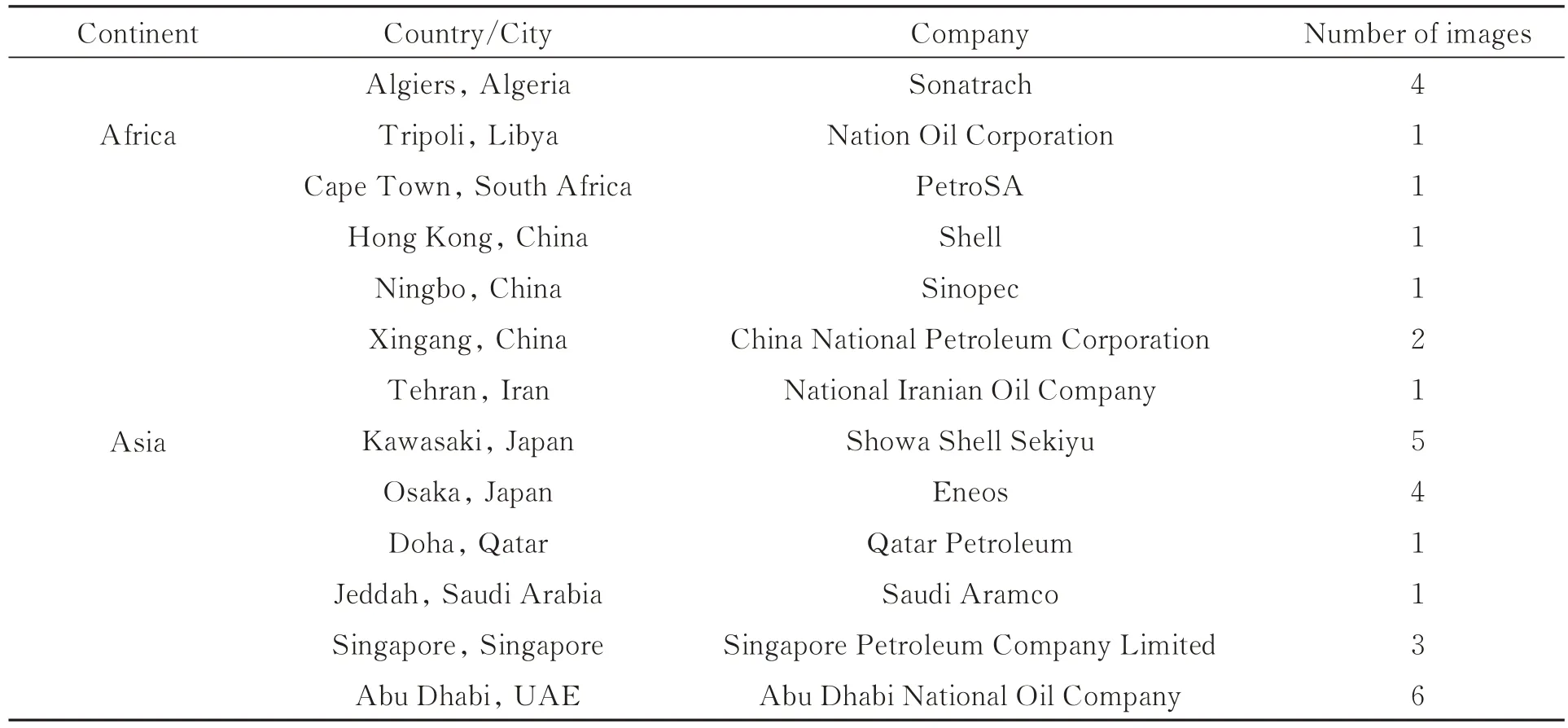
表6 全球储油罐数据集数据来源Tab.6 Global oil storage tank dataset data source

续表6 全球储油罐数据集数据来源Tab.6 Global oil storage tank dataset data source
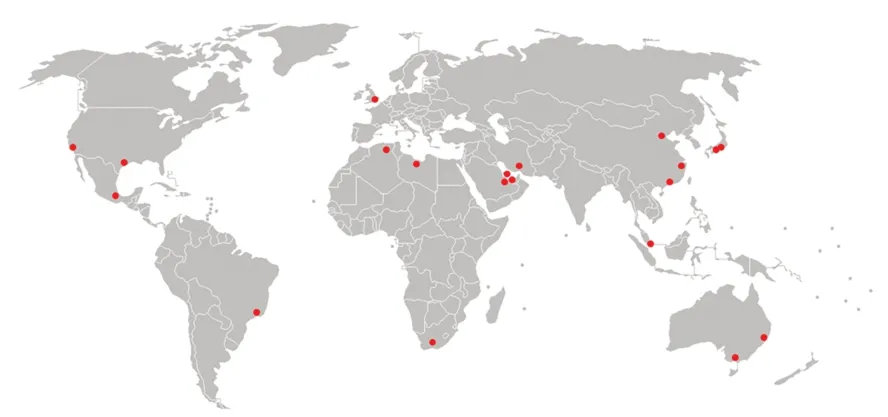
图5 全球储油罐数据集分布Fig.5 Global oil storage tank dataset distribution
如图6 所示(彩图见期刊电子版),带有红、绿色阴影的储油罐A 和储油罐B 中均为数据集中阿布扎比地区某处的同一储油罐的遥感影像,其中红色部分代表储油罐内阴影,绿色部分代表储油罐外阴影。如表7 所示,图7(a)与图7(b)拍摄时间、太阳高度角等均不同,确保了数据集的多样性。

图6 数据集多样性示意图Fig.6 Dataset diversity diagram

表7 数据集图像参数对比Tab.7 Data set image parameter comparison
此外,使用LabelImg 图像标注工具在416×416 有效图像上标记储油罐对象区域轮廓,生成的带标注的储油罐数据集如图7 所示,储油罐的尺寸、颜色、密集程度、阴影长度和阴影方向等均有不同程度的区别。
3.2 实验设置
本实验所使用的处理器为Intel(R)Core(TM)i7-6700,内存32 GB;GPU 为NVIDIA Ge-Force RTX 3090;操作系统为Ubuntu 18.04,CUDA 11.2,cuDNN 8.2.0;深度学习框架为Py-Torch 1.9.0。为了获得更好的训练结果,对TCS-YOLO 网络训练的超参数进行设置,如表8所示,输入图像大小为416×416 pix,初始学习率(Initial Learning Rate)为0.01,训练次数epochs为300 次,动量(Momentum)为0.937,权重衰减(Weight Decay)为0.000 5。实验部分其余超参数设置均为默认设置。

图7 带标注的储油罐数据集Fig.7 Annotated oil storage tank dataset
为了利用GPU 的并行性提高计算速度,同时避免Batch-size 值较小时造成的较差的Batch-Norm 结果,对5 种不同大小的模型分别使用更合适的Batch-size 值进行训练,对应关系如表9所示。

表8 TCS-YOLO 模型训练超参数设置Tab.8 TCS-YOLO model training hyperparameter settings

表9 不同模型的Batch-size 值设置Tab.9 Batch-size value settings for different models
为了验证模型的性能,本实验采用mAP0.5,mAP0.5∶0.95、推理时间(Inference Time)、参数量(Parameters)和模型复杂度(GFLOPs)5 个指标进行评价,其中mAP 计算方式如式(13)所示:

其中:APi为每个类别的平均精度,由于检测类别分别为固定顶储油罐(类别序号为0,标签为“Fixed_Roof_Tanks”)和外浮顶储油罐(类别序号为1,标签为“Floating_Roof_Tanks”),因此在本文中N为2。本实验对测试集数据进行推理,设 置img值为416,conf-thres值为0.001,iouthres值为0.7,half 值为True,即使用FP16半精度推理。
3.3 对比实验
为了验证TCS-YOLO 模型的有效性,本实验将TCS-YOLO 系列的5 种尺度模型与4 种最前沿的目标检测模型YOLOv3,YOLOv4,YOLOv5 和Swin Transformer 的多种尺度的模型进行对比实验,实验结果如表10 和图8 所示,在图8中,X轴表示模型推理速度,X值越小性能越优;Y轴代表模型平均精度,Y值越大性能越优,即越靠近左上角的模型性能越优。
可得到如下结论:
(1)TCS-YOLO 模型的平均mAP0.5为99.28%,平均mAP0.5∶0.95为89.68%,平均推理时间为2.48 ms;
(2)在与YOLOv3 系列模型的比较中,TCSYOLO-n 与YOLOv3-tiny 推理速度接近,相差0.1 ms,但mAP0.5∶0.95优势较大,高7.5%;YOLOv3 和 YOLOv3-spp 比 TCS-YOLO-n 的mAP0.5∶0.95分别高0.7%和2.5%,但推理速度相差较大,分别慢3.6 ms;TCS-YOLO 其余4 个较大模型均在精度上有较大优势;
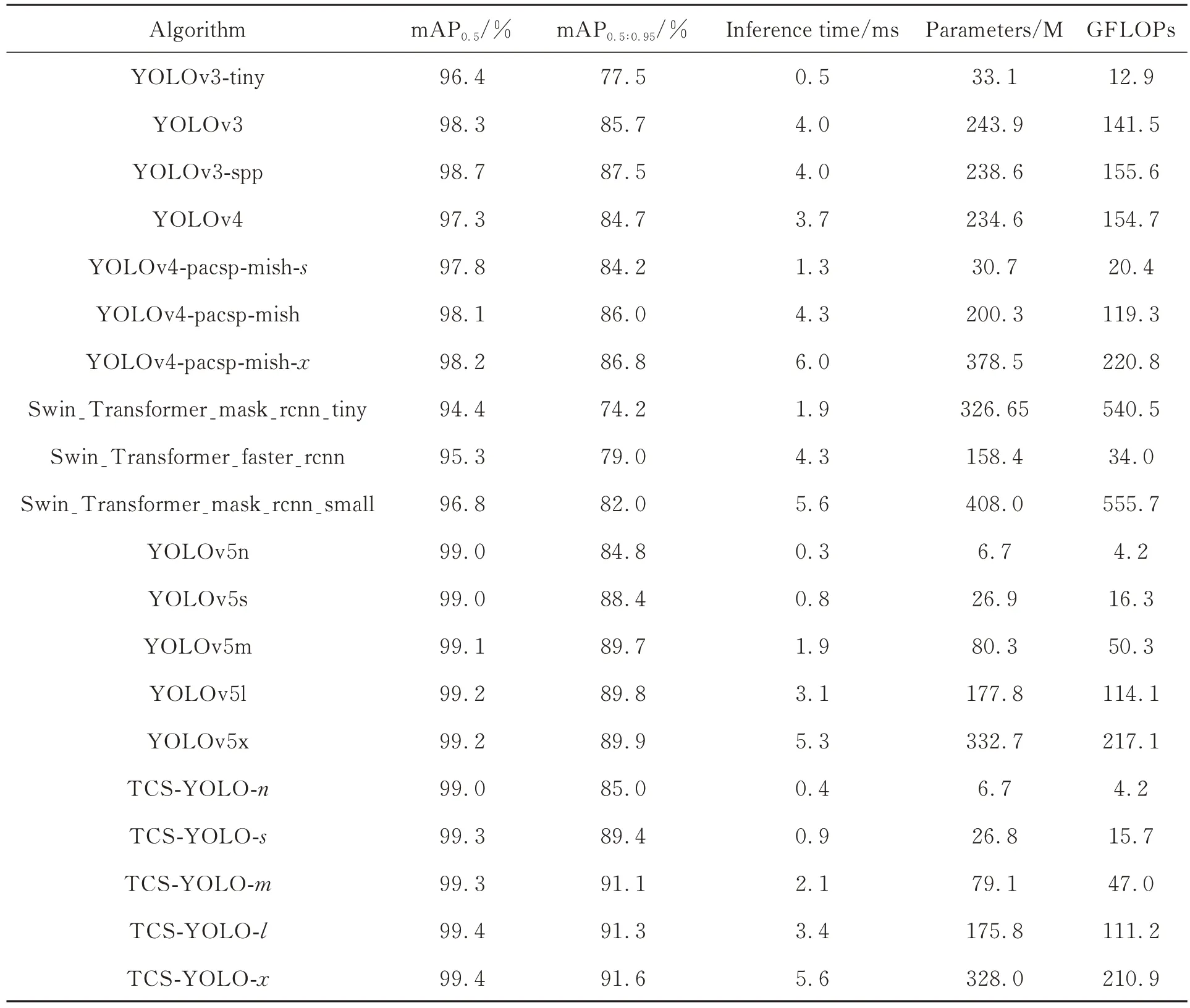
表10 不同的目标检测模型实验结果Tab.10 Experimental results of different object detection models

图8 不同的目标检测模型实验结果Fig.8 Experimental results of different object detection models
(3)在与YOLOv4 系列模型的比较中,YOLOv4-pacsp-mish 和 YOLOv4-pacsp-mish-x比TCS-YOLO-n的mAP0.5∶0.95分别高1.0% 和1.8%,但推理速度相差较大,分别慢3.9 ms 和5.6 ms;其余YOLOv4 系列模型的推理速度和精度均劣于TCS-YOLO-n模型,与TCS-YOLO 其余4 个较大模型均在精度上有较大优势;
(4)在与YOLOv5 系列模型的比较中,各尺度推理速度相近,YOLOv5 系列占优,分别快0.1 ms,0.1 ms,0.2 ms,0.2 ms 和0.3 ms,平均差距为0.2 ms;识别精度TCS-YOLO 模型占优,mAP0.5分别高0.0%,0.3%,0.2%,0.2% 和0.2%,平均差距为0.2%;mAP0.5∶0.95分别高0.2%,1.0%,1.4%,1.5% 和1.8%,平均差距为1.5%;各尺度模型参数量相近,TCS-YOLO模型平均参数量少0.88%;各尺度模型复杂度相 近,TCS-YOLO 模型平均 GFLOPs 低3.13%;
(5)在与Swin Transformer 系列模型的比较中,TCS-YOLO 系列模型在精度上均具有较大优 势,TCS-YOLO-n 模型的mAP0.5∶0.95值较Swin Transformer 性能最优的模型Swin_Transformer_mask_rcnn_small 高3.0%;
3.4 消融实验
为了验证C3TR 层、CBAM 层和SIoU loss对模型性能的提升,本实验对TCS-YOLO 进行消融研究,实验结果如表11 所示。

表11 不同优化方式对模型性能的影响Tab.11 Impact of different optimization methods on model performance
以YOLOv5l 模型为例,可得到结论:
(1)应 用SIoU loss 优化时,mAP0.5∶0.95提升0.7%;应 用CBAM 层优化时,mAP0.5提升0.1%,mAP0.5:0.95提升1.0%;应 用C3TR 层优化时,mAP0.5提升0.1%,mAP0.5∶0.95提升1.3%;
(2)同时应用SIoU loss 优化与CBAM 层优化 时,mAP0.5提升0.1%,mAP0.5∶0.95提升1.4%;同时应用SIoU loss 优化与C3TR 层优化时,mAP0.5提升0.2%,mAP0.5∶0.95提升1.4%;同时应用C3TR 层优化与CBAM 层优化时,mAP0.5提升0.2%,mAP0.5∶0.95提升1.4%;
(3)同时应用C3TR 层优化、CBAM 层优化和SIoU loss 优化的TCS-YOLO 模型,mAP0.5提升0.2%,mAP0.5∶0.95提升1.5%;性能提升最高。
综上所述,TCS-YOLO 与YOLOv5 相比,在保证了运行效率的前提下,在不同尺寸的模型上对于储油罐检测均有准确率的提升,具有一定的现实意义,TCS-YOLO 模型的识别结果示例如图8 所示,在储油罐的尺寸、颜色、密集程度、阴影长度和阴影方向等均有差异的情况下,仍有较好的识别效果。

图9 TCS-YOLO 模型的储油罐目标识别示意图Fig.9 Schematic diagram of oil storage tank target recognition by TCS-YOLO model
4 结论
为了实现对全球储油罐准确、实时地进行目标检测,本文提出了一种基于优化YOLOv5的目标检测模型TCS-YOLO,并对其在吉林一号光学遥感影像数据集上进行实验,主要结论如下:
(1)在采用YOLOv5 模型进行储油罐检测的基础上,以YOLOv5l 模型为例,在特征提取网络的backbone 中的第1 层使用注意力机制的CBAM 层替换CONV 层,mAP0.5∶0.95提升1.0%;在第4 层使用基于Transformer 架构的C3TR 层代替默认CNN 架构的C3 层,mAP0.5∶0.95提升1.3%;在训练过程中使用SIoU loss 代替CIoU loss 作为损失函数中的定位损失函数,mAP0.5:0.95提升0.7%。3 种优化方式均可提升模型的性能。
(2)TCS-YOLO 模型将3 种优化方式结合,与YOLOv5相比,在5 种模型下mAP0.5∶0.95分别提升0.2%,1.0%,1.4%,1.5% 和1.8%,平均提升1.5%;同时,5 种模型下TCS-YOLO 的参数量平均减少0.88%;模型复杂度GFLOPs 平均减少3.13%;推理速度平均慢0.2 ms。TCSYOLO 模型在与YOLOv5 模型运行效率相近的前提下,具有更优的识别精度。
(3)在对比实验中,将TCS-YOLO 模型与当前主流目标识别模型YOLOv3,YOLOv4,YOLOv5 和Swin Transformer 进行对比,结果 表明:TCS-YOLO 模型具有相对最高的准确率,最快的训练速度和检测速度,以及较小的模型尺寸,在能准确检测全球储油罐的前提下,满足实时性的要求。
在快速准确地识别全球遥感影像中储油罐的前提下,进而通过区域内原油储量的计算和回归分析,可以挖掘出遥感数据在能源期货领域的巨大的应用价值,更早做出合理投资决策,为交易者和策略制定者提供信息优势。
猜你喜欢
全面腐蚀控制(2022年11期)2023-01-11
九江职业技术学院学报(2022年1期)2022-12-02
全面腐蚀控制(2021年10期)2021-12-31
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化·中考版(2021年3期)2021-07-22
数学小灵通·3-4年级(2021年5期)2021-07-16
新世纪智能(数学备考)(2020年9期)2021-01-04
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
全面腐蚀控制(2019年10期)2019-02-08
今日农业(2019年15期)2019-01-03