
基于Ghost卷积和通道注意力机制级联结构的车辆检测方法研究
2023-02-15 01:25梁继然董国军许延雷
天津大学学报(自然科学与工程技术版) 2023年2期
梁继然,陈 壮,董国军,陈 琦,许延雷
基于Ghost卷积和通道注意力机制级联结构的车辆检测方法研究
梁继然1, 2,陈 壮1,董国军3,陈 琦1,许延雷1
(1. 天津大学微电子学院,天津 300072;2. 天津市成像与感知微电子技术重点实验室,天津 300072;3. 天津七一二通信广播股份有限公司,天津 300462)
为了降低YOLOv3算法的计算量和模型体积,提高对小目标的检测能力,本文提出一种基于Ghost卷积和通道注意力机制级联结构,将其作为YOLOv3算法的特征提取网络,以减少网络计算量;在小目标预测支路引入S-RFB模块,扩大模型的感受野,更好地利用上下文信息,以提高对小目标的检测能力;使用CIOU损失作为边界框位置损失项,以加速模型的收敛.利用高斯噪声对训练样本进行数据增强,提高模型的鲁棒性.在UA-DETRAC数据集上进行实验,实验结果表明,相比于YOLOv3算法,基于Ghost卷积和通道注意力机制级联结构的G-YOLO算法的平均精度提高了2.7%,模型体积减小了67%,在复杂道路交通环境中具有良好的检测效果.
车辆检测;卷积神经网络;轻量化
智能交通系统对于未来城市交通的规划、交通事故的降低具有重要意义.而车辆检测是智能交通系统[1](intelligent traffic system,ITS)的基础和核心.目前车辆检测技术已经成为交通事故检测、车辆智能分流、辅助驾驶功能、车辆违法行驶等领域的研究热点.
传统的目标检测方法采用人工设计的特征算子进行特征提取,通过分类器对目标进行分类判断,通常存在检测速度慢且难以精准定位目标[2]的问题.近年来,随着深度学习理论的快速发展,卷积神经网络(convolution neural network,CNN)在目标检测方面取得了突破性进展,在解决目标的特征提取和表达的问题上具有很强的优势.虽然基于卷积神经网络的目标检测算法得到了广泛的应用,但是训练后的模型一般有数以千万计的权重参数,对硬件的计算能力要求很高,在给定的物理空间和平台上,算法的部署会受到限制[3].在车辆检测任务中,图像大多由监控摄像头等嵌入式设备拍摄,而基于卷积神经网络的目标检测模型通常需要图形处理单元(graphics processing unit,GPU)的加速支持才能达到检测效果,但嵌入式设备计算能力有限,无法满足高实时性的车辆检测任务需求.目前对卷积神经网络的压缩方式和加速途径有知识蒸馏、网络剪枝、参数量化、低秩分解、轻量化网络设计等[4].Jhong等[5]采用知识蒸馏和深度可分离卷积的方法在Jetson TX2上实现了实时的自动驾驶任务.Zhao等[6]采用特征金字塔增强的策略提高检测精度,并通过逐层裁剪的方式对网络瘦身,得到了轻量高效的神经网络,在快速车辆检测任务中取得了较好的结果.Ye等[7]对Darknet-53网络进行了优化,设计了多分支卷积模块来替换原来的卷积,减少了通道数和参数计算,并在嵌入式系统上实现了应用.此外,一些轻量化网络也逐渐被学者提出,例如2017年Howard等[8]提出了以深度可分离卷积为基础的MobileNet算法,但其特征提取能力略有不足;2020年Tan等[9]提出了基于神经架构搜索设计的EffcientDet算法,具有更高的准确性和效率;2020年Han等[10]提出了使用线性变换生成冗余特征图的GhostNet算法,在保证准确率的同时具备轻量化的结构.
本文针对基于卷积神经网络的车辆检测算法存在的参数量多、计算量大的问题,提出一种基于Ghost卷积和注意力机制级联的结构,并以残差结构的方式进行跳跃连接,以降低网络的参数量和计算量;在小目标预测支路引入改进后的RFB[11]结构以扩大模型的感受野,充分利用上下文信息以提高对小目标车辆的检测能力;使用CIOU[12]损失作为损失函数的边界框预测损失项,促进模型收敛;最终构建了基于Ghost卷积和通道注意力机制的G-YOLO车辆检测算法.实验表明本文所提算法大幅度减少了网络的计算量,缩减了模型体积,在复杂交通场景下对车辆检测具有良好的效果,并且满足车辆检测任务的实时性需求.
1 模型结构
YOLOv3[13]算法是典型的一阶段目标检测算法,在目标检测领域得到了广泛的应用,通过多尺度特征融合对不同大小的目标进行预测,但存在体积大、参数冗余、对小目标检测效果差的问题.为解决上述问题,本文提出一种基于Ghost卷积和注意力机制级联的车辆检测算法,网络结构包括特征提取网络、多尺度融合支路和预测支路3个部分.模型的网络结构如图1所示,特征提取网络基于Ghost卷积构成残差结构,使用一半的标准卷积生成部分特征图,对部分特征图采用注意力机制进行权重分配,然后使用3×3卷积对部分特征图进行通道卷积生成另一半特征图,将两部分特征图进行拼接,为了不增加网络的复杂度,将特征提取网络的深层设计为Ghost卷积与注意力机制级联的结构,浅层只以Ghost卷积的方式实现;为扩大浅层特征图的感受野,增强对小目标检测能力,在小目标预测支路中加入S-RFB结构,随后经过多尺度融合将深层特征与浅层特征进行拼接,将拼接后的特征图送入预测支路,完成目标的检测.
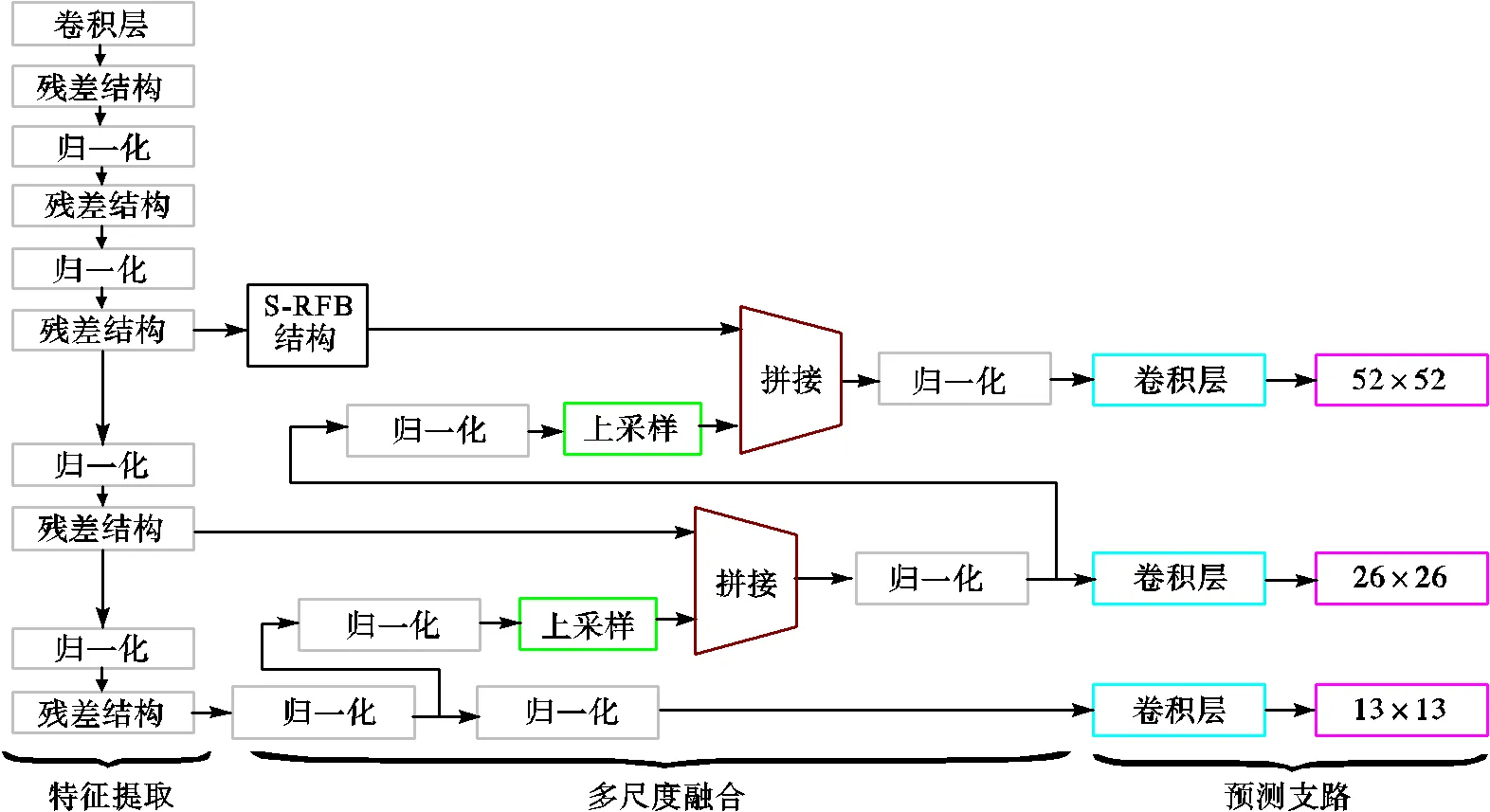
图1 模型结构
1.1 Ghost卷积与注意力机制级联结构
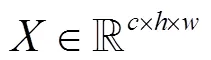
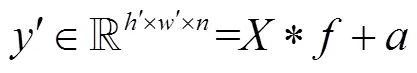
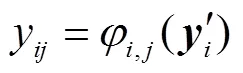
最后将两部分特征图进行拼接,得到最终的特征图.图2为Ghost卷积实现过程.
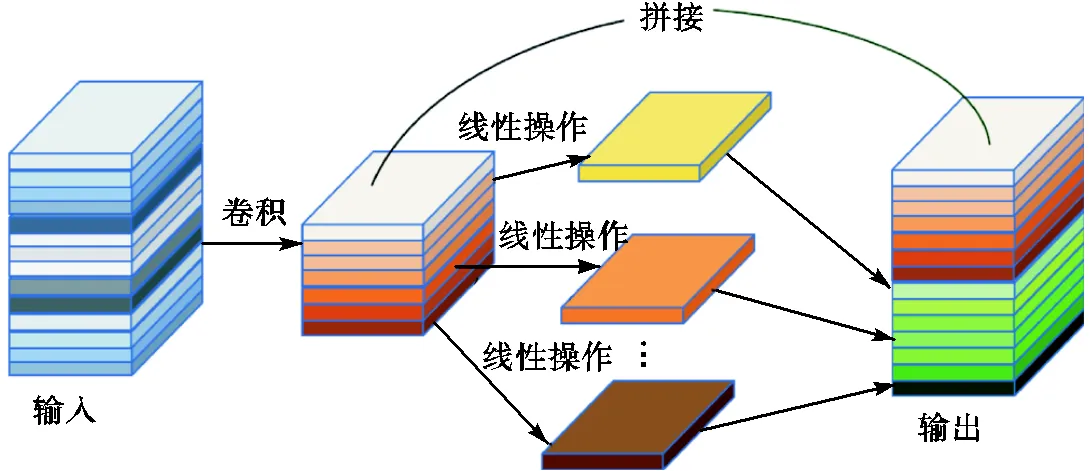
图2 Ghost卷积实现过程

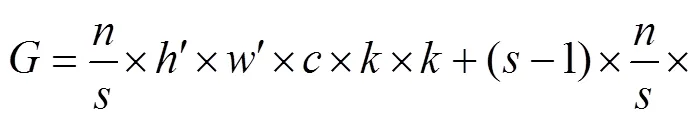

运算量压缩比为
虽然Ghost卷积节省了大量的浮点型运算,但是无法保证得到与标准卷积操作完全一致的特征图.为了提高最终生成的特征图质量,笔者设计了Ghost卷积与通道注意力机制级联的结构,如图3所示,利用轻量化通道注意力机制ECA-Net[14]对标准卷积操作得到的部分特征图进行通道域加权,具体实现方式为特征图进行全局平均池化,整合得到1×1×C维度的特征图,通过Sigmoid函数生成新的权重参数,最后将生成的权重参数与原通道特征图相乘.有效筛选对最终目标预测结果贡献程度较大的关键信息,使经过线性操作输出的特征图也对最终目标预测贡献关键信息,以获取高质量的原始特征图.
Ghost卷积与注意力机制级联的结构有效结合了Ghost卷积和注意力机制的优势.首先,Ghost卷积使模型减少了大量的浮点型运算,保证了最终特征图通道数不变;其次,在部分原始特征图进行线性操作生成其余特征图的过程中采用通道注意力机制保证了其余部分特征图的质量,使全部特征图尽可能对目标预测做贡献.
1.2 S-RFB结构
在复杂道路环境下,目标车辆易受到建筑物、植被等障碍物遮挡,神经网络只能提取到不完整的部分特征信息,当拍摄距离较远时,待检测车辆在图像中所占像素较少,细节信息难以被利用,误检和漏检的概率随之增加.感受野是输出特征图上的像素点对应输入图片区域的大小.YOLOv3算法通过52×52的特征图对小目标进行预测,其感受野较小,难以有效利用上下文信息,RFB结构利用不同尺寸的标准卷积和不同扩张率的空洞卷积模拟感受野和离心率的关系.本文对RFB结构进行了改进,得到了S-RFB结构,如图4所示,S-RFB利用1×1卷积进行通道降维,使用不同大小的标准卷积核和不同扩张率的空洞卷积进行多支路级联,使用两个3×3卷积核代替原来5×5的卷积核,另新增一条支路对原始特征图进行SoftPool[15]池化操作,经1×1卷积进行通道变换与不同空洞率的空洞卷积相连,与原始特征图进行短路连接进行通道融合,输出最终的输出特征图.
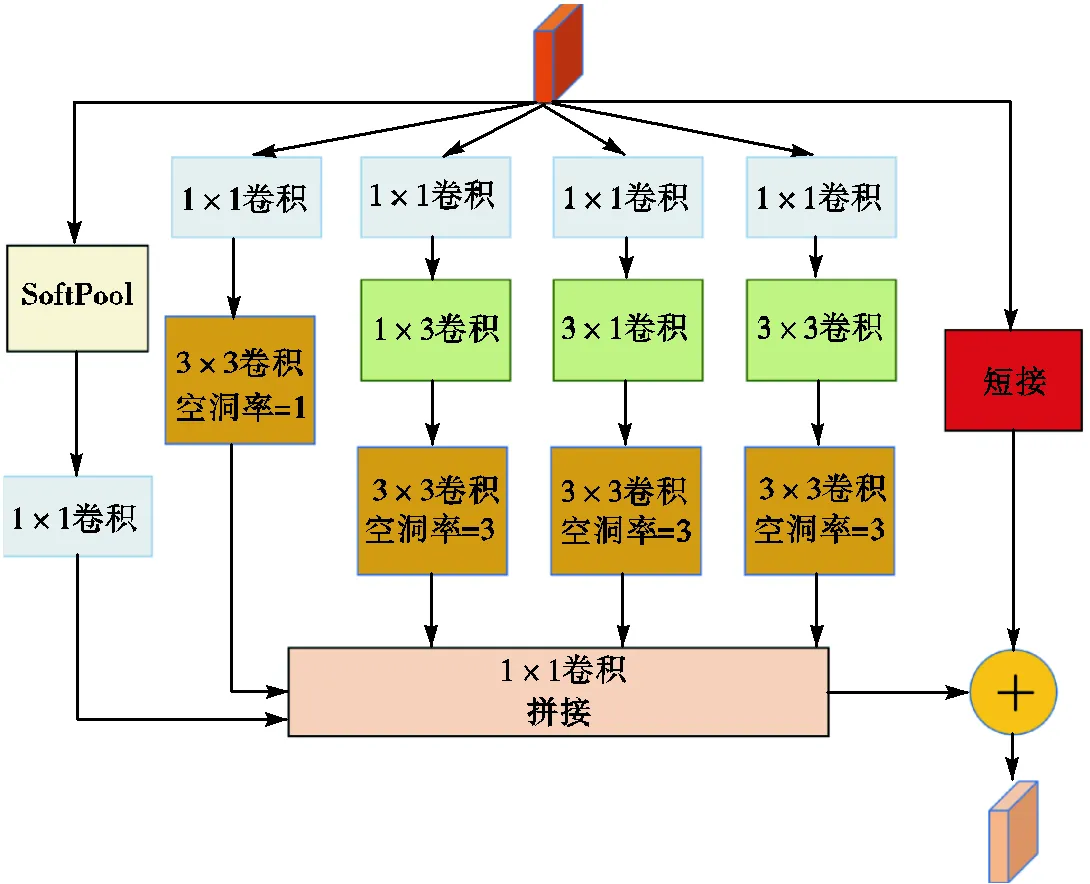
图4 S-RFB结构
1.3 损失函数
损失函数可以反映模型的预测值和真实值之间的不一致程度,其值越小,模型的鲁棒性越好,良好的损失函数有助于降低损失值,同时可以加快网络的收敛速度.本文引入CIOU损失作为边界框预测损失项,YOLOv3算法使用IOU loss(交并比损失)来评估模型的边界框预测损失,但是可能会出现梯度为零或者无法表示预测框和实际框对齐的问题,CIOU损失将预测框和真实框的中心点距离考虑在内,通过增加预测框和真实框的长宽比一致性的衡量参数使损失函数朝着区域重叠增加的方向前进,CIOU函数可表示为


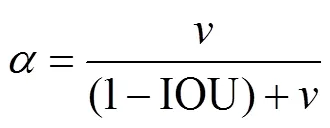
2 数据集和实验平台
实验所选数据集为车辆公开数据集UA-DETRAC[16],使用Cannon相机在北京和天津的城市道路24个地点拍摄而成,数据集场景丰富,包括不同的车辆类型和行车条件,并根据遮挡程度分为无遮挡、部分遮挡和严重遮挡3类,除此之外该数据集还对晴天、雨天、多云、夜晚4种天气场景进行了标注,综合遮挡、尺度变化和光照影响等因素分为简单、中等和困难3个部分,贴近真实交通场景下道路车辆情况,数据集示例如图5所示.

图5 UA-DETRAC数据集示例
此外,使用高斯噪声处理的方法对数据集进行数据增强,提高模型的泛化能力.本实验基于PyTorch框架,操作系统为Ubuntu 16.04,Nvidia Tesla V100显卡,训练过程中初始学习率设置为0.001,批量大小为64,训练周期为45,在训练过程中记录每个训练周期的损失值.
3 实验分析
3.1 对比实验
为评估所提算法的性能,与当前主流算法进行了实验对比,包括二阶段目标检测算法Faster R-CNN[17]、一阶段目标检测算法SSD[18]、基于Anchor-Free的目标检测算法CenterNet[19],采用平均精度值(average precision,AP)、每秒处理帧数(frame per second,FPS)和模型体积(Mbyte,兆字节)对算法的检测精度、检测速度进行定量分析,结果如表1所示.可以看出,G-YOLO算法在平均精度值方面虽然不如YOLOv4算法,但在检测速度和模型体积两方面都具有一定优势,更适合在嵌入式设备中部,与YOLOv3算法相比,G-YOLO算法的平均精度值提高了2.7%,模型体积仅为YOLOv3算法的33%.与SSD算法相比,平均精度值提高了4.7%,模型体积仅为SSD算法的57.3%,与CenterNet相比,平均精度值提高了5.6%,检测速度是CenterNet的1.5倍,模型体积仅为CenterNet的27%,与一阶段算法Faster R-CNN相比平均精度值虽不能及,但是检测速度远超Faster R-CNN,能够满足实时性要求高的任务需求;相比于以上4种算法,在满足车辆检测任务检测精度的同时模型体积被大大压缩,降低了对高性能硬件的依赖性,在车辆检测任务中有较高的应用价值.
表1 对比实验结果

Tab.1 Results of comparative experiments
3.2 消融实验
为了更好地表征各模块对模型的贡献,评估各个模块的对网络性能的影响,本文以YOLOv3为基准设计了消融实验,并对实验结果进行分析,实验结果如表2所示.
表2 消融实验结果

Tab.2 Results of ablation experiments
从表2可以看出S-RFB结构能有效利用感受野,有助于提升目标的检测精度,虽然检测速度有所下降,但检测速度仍在30 帧/s以上,可以满足实时性任务的要求,且模型体积几乎没有增加,所以添加RFB模块并未过大增加网络负担.实验2是利用Ghost卷积实现标准卷积,检测精度虽略有下降,检测速度却高达55 帧/s,且模型体积仅有原来的31.6%,说明使用Ghost卷积减少了网络的参数量和运算量;实验3是在原始特征提取网络中加入通道注意力机制,可以看出ECANet是一种轻量化的通道注意力机制(ECANet),使用一维卷积模型体积仅增加了4Mbyte,平均精度值提高了1.5%,说明ECA机制使网络能够更好地利用不同通道间的关联关系,有效增强有效特征信息的表达.表3为SENet和ECANet两种注意力机制的对比,可以看出ECANet体积更小且能够实现更高的检测精度提升,性能更加优越.
表3 不同注意力机制对比

Tab.3 Comparison between different attention mechanisms
本文所提的G-YOLO算法是在神经网络的深层中使用了Ghost卷积和通道注意力机制级联模块的网络结构,同时在小目标预测支路加入S-RFB结构,可以看出,在平均精度值、每秒处理帧数和模型体积三者之间取得了较好的平衡.从表2还可以看出,采用Ghost卷积与注意力机制级联的结构,保证了最终输出特征图的质量,与原算法相比,在压缩体积、缩减运算量的同时没有出现检测精度下降的情况,在小目标预测支路加入S-RFB结构后,模型的精度进一步提高,说明小目标的漏检和误检问题得到缓解.综上所述,G-YOLO的检测精度高、体积小,可以满足嵌入式设备进行车辆检测任务的要求.
3.3 G-YOLO在不同条件下的检测结果
按照不同的天气条件,UA-DETRAC数据集可划分为晴天、夜晚、多云和雨天4个子集,同时根据车辆目标的尺度大小、光照强度、不同遮挡率分为简单、中等、困难3个部分.为进一步评估算法对车辆目标的检测能力,表4展示了本文所提算法对不同天气条件下和不同困难程度下对车辆检测的结果.
从表4可以看出,相比于原YOLOv3算法,G-YOLO对困难部分、夜间部分的检测有明显的提高,原算法对于小目标或者被遮挡目标的检测效果并不理想,通过加入S-RFB结构和通道注意力机制提高了算法对小尺寸目标、被遮挡目标的检测能力.综上所述,改进后的算法鲁棒性较好,适合复杂交通场景下的车辆检测.
表4 YOLOv3和G-YOLO在不同条件下的检测结果

Tab.4 Detection results of YOLOv3 and G-YOLO under different conditions %
3.4 车辆检测效果展示
图6是在复杂道路环境下G-YOLO对车辆的检测结果,主要包括车辆高速移动的情况(图6(a))、由于阳光直射图像偏暗的情况(图6(b))、待检测目标数量较多且尺度变化较大的情况(图6(c))、被绿色植被遮挡时的情况(图6(d)).可以看出本文所提算法能够对道路交通车辆进行很好地检测,在光照影响、目标密集、障碍物遮挡等干扰条件下可以取得良好的检测效果.

图6 复杂道路环境下的车辆检测效果
4 结 语
本文提出了一种基于Ghost卷积和通道注意力机制级联结构的车辆检测算法,提高了Ghost卷积生成部分特征图的质量;并在小目标预测支路加入改进的RFB结构,增大了模型的感受野,提高了小目标车辆的检测能力;再结合CIOU损失优化损失函数,促进了模型收敛;在UA-DETRAC数据集上进行实验,在检测精度、检测速度和模型大小方面均优于原算法;与目前主流算法相比也具备体积小、速度快的优势,在表现出良好检测性能的同时,其抗干扰能力较强、鲁棒性较好,对智能城市交通系统的建设有较好的借鉴意义.
[1] Li R D. Research on the industrial development of intelligent transportation system in China[C]//2020 5th International Conference on Electromechanical Control Technology and Transportation(ICECTT). Nanchang,China,2020:622-627.
[2] Dalal N,Triggs B. Histograms of oriented gradients for human detection[C]//2005 IEEE Conference on Computer Vision and Pattern Recognition. San Diego,USA,2005:886-893.
[3] Chen L,Ding Q,Zou Q,et al. DenseLightNet:A light-weight vehicle detection network for autonomous driving[J]. IEEE Transactions on Industrial Electron-ics,2020,67(12):10600-10609.
[4] 孟宪法,刘 方,李 广,等. 卷积神经网络压缩中的知识蒸馏技术综述[J]. 计算机科学与探索,2021,15(10):1812-1829.
Meng Xianfa,Liu Fang,Li Guang,et al. Review of knowledge distillation in convolutional neural network compression[J]. Journal of Frontiers of Computer Science and Technology,2021,15(10):1812-1829(in Chinese).
[5] Jhong S Y,Chen Y Y,Hsia C H,et al. Nighttime object detection system with lightweight deep network for internet of vehicles[J]. Journal of Real-Time Image Processing,2021,18(4):1141-1155.
[6] Zhao M,Zhong Y,Sun D,et al. Accurate and effi-cient vehicle framework based on SSD algorithm[J]. IET Image Processing,2021,15(13):3094-3104.
[7] Ye T,Ren C,Zhang X,et al. Application of lightweight railway transit object detector[J]. IEEE Transactions on Industrial Electronics. 2021,68(10):10269-10280.
[8] Howard A G,Zhu Menglong,Chen Bo,et al. MobileNets:Efficient convolutional neural networks for mobile vision applications[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:6738-7438.
[9] Tan Mingxing,Pang Ruoming,Le Quoc V. EfficientDet:Scalable and efficient object detection[EB/OL]. https://arxiv. org/pdf/1911. 09070v1. pdf,2020-06-27.
[10] Han K,Wang Y,Tian Q,et al. GhostNet:More fea-tures from cheap operations[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Seattle,USA,2020:1577-1586.
[11] Liu S,Huang D,Wang Y. Receptive field block net for accurate and fast object detection[C]//2018 European Conference on Computer Vision(ECCV). Munich,Germany,2018:404-419.
[12] Zheng Z,Wang P,Liu W,et al. Distance-IOU loss:Faster and better learning for bounding box regression[C]// 34th AAAI Conference on Artificial Intelligence. New York,USA,2020:12993-13000.
[13] Redmon J,Farhadi A. YOLOv3:An incremental improvement[EB/OL]. https://arxiv.org/abs/1804.02767,2018-04-08.
[14] Wang Q,Wu B,Zhu P,et al. ECA-Net:Efficient channel attention for deep convolutional neural networks[C]//Proceedings of the Conference on Computer Vision and Pattern Recognition. Piscataway,USA,2019:1-12.
[15] Alexandros S A,Ronald P,Grigorios K. Refining activation downsampling with SoftPool[C]// Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:10357-10366.
[16] Wen L Y,Du D W,Zhao W,et al. UA-DETRAC:A new benchmark and protocol for multi-object detection and tracking[J]. Computer Vision and Image Understanding,2020,193:1-27.
[17] Ren S,He K,Girshick R,et al. Faster R-CNN:Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[18] Liu W,Anguelov D,Erhan D,et al. SSD:Single shot multibox detector[C]// 2016 European Conference on Computer Vision. Amsterdam,The Netherlands,2016:21-37.
[19] Zhou Xingyi,Wang Dequan,Krähenbühl P. Objects as points[EB/OL]. https://arxiv.org/pdf/1904.07850.pdf,2019-04-25.
Research on the Vehicle Detection Method Based on the Cascade Structure of Ghost Convolution and Channel Attention Mechanism
Liang Jiran1,2,Chen Zhuang1,Dong Guojun3,Chen Qi1,Xu Yanlei1
(1. School of Microelectronics,Tianjin University,Tianjin 300072,China;2. Tianjin Key Laboratory of Imaging and Sensing Microelectronics Technology,Tianjin 300072,China;3. Tianjin 712 Communication and Broadcasting Limited Corporation,Tianjin 300462,China)
To reduce the computational complexity and model size of the YOLOv3 algorithm and improve the detection ability of small targets,we proposed a structure based on the cascade of Ghost convolution and the channel attention mechanism,which was used as the feature extraction network of the YOLOv3 algorithm to reduce network computation. The S-RFB module was introduced in the small-target-prediction branch to expand the receptive field of the model,thus optimally using the context information and improving the detection ability of small targets. The CIOU loss was used as the bounding box position loss term to accelerate the model convergence. The training samples were enhanced by the Gaussian noise to improve the model robustness. The experimental results based on the UA-DETRAC dataset demonstrated that the average precision of the G-YOLO algorithm based on the cascade structure of Ghost convolution and channel attention mechanism was increased by 2.7%,and the model volume was reduced by 67% compared to the YOLOv3 algorithm. The improved YOLOv3 algorithm exhibited a remarkable detection effect in a complex road traffic environment.
vehicle detection;convolutional neural network(CNN);lightweight
10.11784/tdxbz202112039
TP391.4
A
0493-2137(2023)02-0193-07
2021-12-25;
2022-05-14.
梁继然(1978— ),男,博士,副教授.
梁继然,liang_jiran@tju.edu.cn.
天津市科技重大专项与工程资助项目(19ZXZNGX00060).
Supported by the Science and Technology Program Project of Tianjin,China(No. 19ZXZNGX00060).
(责任编辑:孙立华)
猜你喜欢
核安全(2022年3期)2022-06-29
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
系统工程与电子技术(2016年2期)2016-04-16
电测与仪表(2016年8期)2016-04-15
