
基于虚拟现实的英语发音校准实验仿真分析
2023-02-20 13:42郑瑞珺
实验室研究与探索 2023年11期
郑瑞珺
(四川外国语大学国际关系学院,重庆 400031)
0 引言
英语口语是英语国家人民普遍应用的口头交流语言形式。英语发音的准确和流利决定了英语口语的效果,目前有很多英语发音校准方式。文献[1]中设计了一种改进动态特征参数的话者语音识别校准系统,该系统容易被语音环境干扰,对英语发音的识别准确性低;文献[2]中设计的嵌入式实时英语语音识别系统,缺乏虚拟语言学习环境以及学生和教师间的交互沟通,存在校准准确率低、学生学习英语发音效果差的弊端;文献[3]中设计的伦敦英语口语语料库发音校准系统,只能校准伦敦口语发音,局限性大。根据以上的问题,设计基于虚拟现实(Virtual Reality,VR)的英语发音校准仿真系统,提升英语发音校准准确性,提高学生的英语发音水平。
1 基于虚拟现实的英语发音校准仿真系统
1.1 总体结构
基于VR的英语发音校准仿真系统的总体结构用图1 描述。采用Client/Server 体系结构构建VR 的发音校准仿真系统,系统主要由客户端和服务器端模块构成,用户在互动界面、获取用户命令、与用户进行互动都通过客户端模块完成[4];服务器端模块用于收集用户命令同时对命令响应、防止虚拟场景异常运行、有效处理虚拟仿真场景业务[5]。基于TCP/IP 协议的JavaSocket通信技术支撑系统客户端模块和服务器端模块间的信息通信[6]。
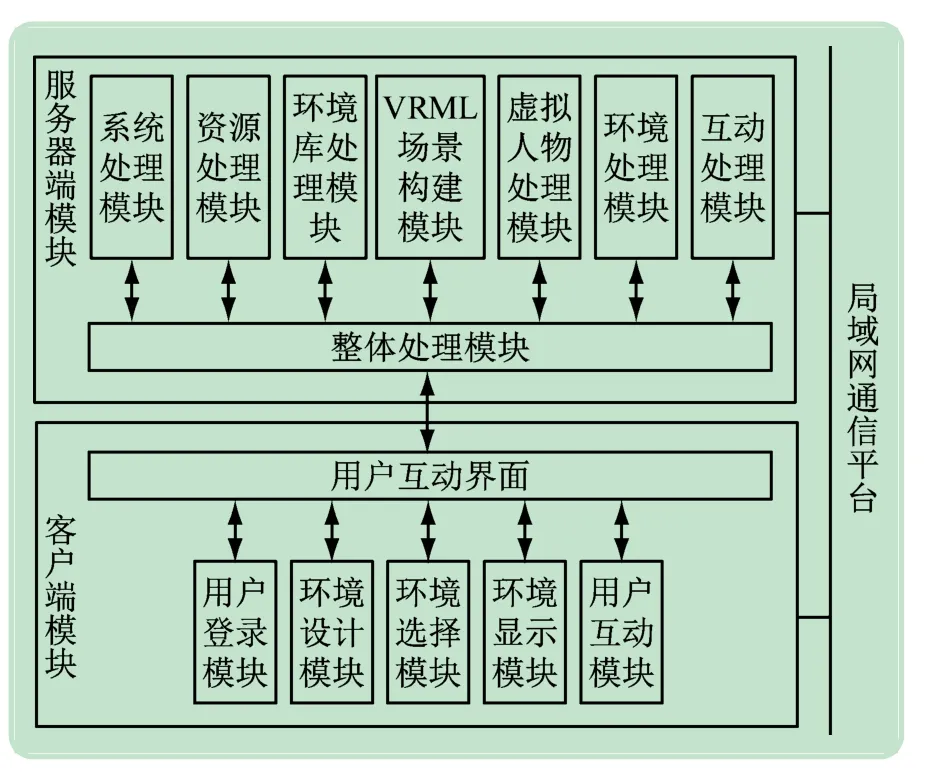
图1 系统总体结构
1.2 客户端模块
由图1 可见,客户端模块包含:
(1)用户登录模块。实现用户登录操作,将虚拟仿真形象提供给用户挑选,让用户成为虚拟人物加入虚拟环境练习英语发音[7]。
(2)环境设计模块。教师端可操作该模块[8],教师设计英语对话环境的时间、地点、人物等内容,这些功能由服务器端的环境库处理模块实现。
(3)环境选择模块。用户想加入的环境在环境列表挑选,私人方式和共享方式组成了加入方式[9]。环境中除用户的人物外,其他全部为虚拟人物为私人方式,此方式可让学生在一个安全的环境学习和校正英语发音。环境中除用户的人物与虚拟人物还有其他用户的人物,具有共享特征,可让不同用户分享英语发音知识[10]。
(4)环境显示模块。用户进行英语发音学习的环境通过虚拟现实建模语言(Virtual Reality Modeling Language,VRML)的浏览器解释产生。
(5)用户互动模块。输入、输出接口通过本模块提供给用户[11]。本模块拥有图形化的浏览器界面与多媒体交互界面,虚拟环境里的场景、道具、模拟人物和用户的人物通过以上2 个界面传递给用户。用户进行英语发音学习的模式分为观看、试验和向导3 种。
1.3 服务器端模块设计
由图1 可见,服务器端模块包含:
(1)整体处理模块。该模块可对数据库后台进行处理,如处理系统后台的资料库、场景库、用户库等。客户端模块获取的指令与脚本通过此模块解析,整体处理模块控制服务器端每个模块间的通信,并发送环境虚拟现实建模语言(Virtual Reality Modeling Language,VRML)文件[12]。
(2)环境库处理模块。对建成的环境素材实施管理。素材使用3DMAX 等建模工具构建,构建后通过VRML文件存储为VRML格式文件[13]。
(3)VRML场景构建模块。采用环境库处理模块获取用户挑选的英语发音学习场景素材,将素材放在合适的控制节点,构建用户英语发音学习的VRML场景。
(4)虚拟人物处理模块。虚拟人物的创建、注销和基础动作掌控通过此模块实现,外界刺激时虚拟人物发出相对动作。
(5)环境处理模块。环境里每个要素的逻辑关系、时间关系、空间关系的准确性和统一性通过此模块完成[14]。
(6)互动处理模块。系统传输的用户控制命令通过此模块获取,事件采用VRML提供的检测器节点发生[15]。人物的状态变化和动作变化通过虚拟人物处理模块和环境处理模块完成,实现用户和场景及虚拟人物的互动。
2 系统软件
2.1 校准流程
基于VR的英语发音校准仿真系统进行英语发音校准的流程用图2 描述。
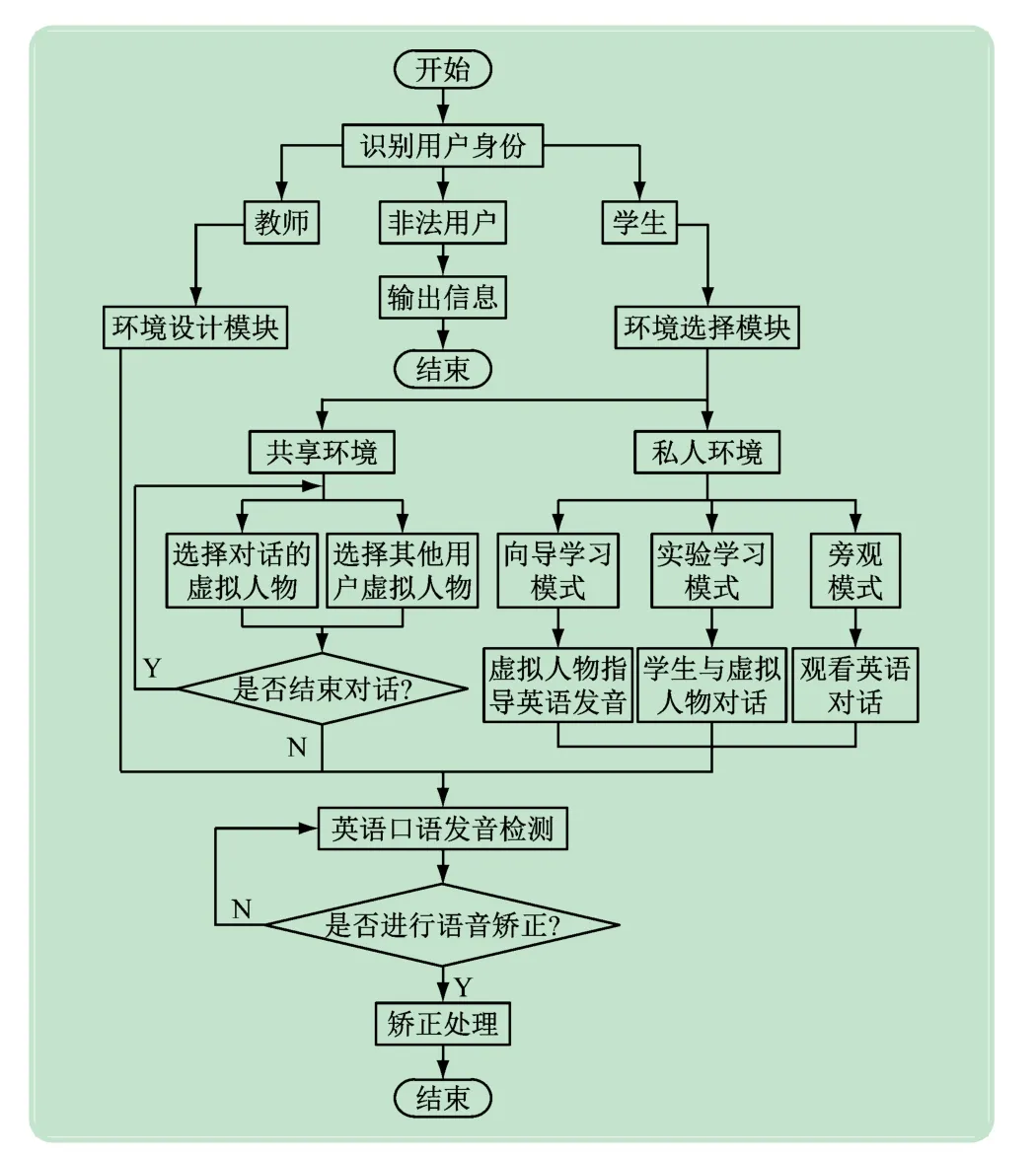
图2 发音校准流程
由图2 可知,发音校准的具体流程:首先识别用户的登录身份,如果是教师则进入环境设计模块;如果是学生则进入环境选择模块;如果是非法用户则将用户信息输出并结束运行。学生选择环境后根据自己的意愿选择想要练习英语发音的人物和参与方式,如果选择环境里的旁观学习模块,则学生以旁观的形式观看虚拟人物之间的英语对话;如果选择私人环境里的实验学习模块,则学生选择对话里的一个人物与其他虚拟人物对话;如果选择私人环境里的向导学习模块,则学生学习英语发音时会由一个虚拟人物指导英语发音;如果选择共享环境,则让学生选择对话的虚拟人物或其他用户虚拟人物;对话完成后如果不想继续对话则结束对话,如果想继续对话则重新选择英语发音人物和参与方式;用户每次发送英语发音时实施发音校准,由虚拟人物提示的方式将发音校准信息发送给用户。
2.2 英语发音校准方法
系统将后验概率算法引入英语发音识别系统,对英语音素段强制对齐切分,采用因素后验概率验证本文算法的准确度。后验概率是系统在接收音素片段后,其接收的片段内容信息与发送片段信息的完整概率,与信息似然度成正比。当音素后验概率为1 时,则证明算法能够准确判断算法具有较高准确性,强制对齐切分后的英语音素段后验概率
式中:qi为i时刻的给定音素;qj为j时刻的给定音素,j=1,2,…,M;yj为时刻的观察量;P(qi)为其概率分布;M为总音素的数目。假设在i时刻到j时刻之间,所有音素模型出现的概率均相等,即P(qj)=P(qi),则切分后的英语音素段的后验概率
因为P(qi)=P(qj),所以
但仅仅依靠判断音素来对学生英语发音进行分析的方法存在单一性,效果并不精准。本文设计的系统在进行语音识别的过程中,会受到各种因素的影响造成英语语音识别不准确。如果严格按照对数似然度进行英语发音识别,其效果并不能达到最优。
本文对上述情况进行了改进,由于音素对数似然度的范围为-∞~+∞,过大的范围造成了英语语音识别的不稳定性,为此,采用最终置信度来判断输出数据的真实性。最终置信度是指在置信数据样本区间内的音素信息是否真实,也用于验证语音矫正系统数据输出的可信度,对数似然度最终置信度值
式中:PLLRrank1(ot)为针对音素模型ER 的对数似然度值;PLLRrankER(ot)为所测语音段与音素模型分别求取PLLR(ot)中排名第1 的PLLR(ot)值;RankER为观测序列ot与音素模型ER 的PLLR(ot)值在因素模型中的排名;α为常数,与音素排名和音素模型的PLLR(ot)值有关。如果存在一个参数的值,使得其函数值达到最大的话,那么这个值就是最为“合理”的参数值。本文α取值为0.09。观测序列与音素模型ER 的Confc为1,其他情况下小于1。通过式(3),使每一个音素模型的置信度值限定在[0,1]之间,可通过为每个音素设定门限值,对语音矫正系统输出数据进行辨别,通过音素最终置信度的值来确定每个英单词所涉及的元音音素和辅音音素的发音是否准确。
系统对数据进行填充处理和属性规划后可采用灭错计算校准发音,对英语发音语言进行规范化处理
式中:W、b分别为英语发音的震动音频和震动的波峰极值;P、qj分别为震动的波谷极值和音频的有效周期律;A、NG分别为声音在介质中传播的振幅和英语发音的规范振幅;M、Q分别为音频总时长和发音期间的震动时长。当A固定,音频总时长大于震动时长时,英语发音的振动音频达到最大极值。音调与响度逐渐趋于固定时,音准也逐渐趋于稳定。英语发音语音通过以上方式实施规范处理后实施口语数据填充。口语数据填充量是系统中的口语数据在外界信号干扰下出现离散现象,系统需要对离散数据进行补偿,还原初始的口语数据量,口语数据填充量
式中:βi离散值越大,反映变量值越分散,发音越不稳定;ω′、D分别为填充最大化的权值函数差和两个音频节点之间的跳数;音频里节点x和节点y之间的最短路线为λxy。
属性规划在填充处理数据后实施,填充过程为
式中,Sx、m分别为评定音频的标准和恒定音频固定周期的参量。灭错校准运算对属性实施标定:
式中:Bij、R分别为相对音频的匹配系数和进阶音频拥有的高程权值;当R 越大,AT和U-1越小时,V 越大,拥有高的校准率结果。量度音符通过音频的固定斜动性AT完成,使用音频属性的合集熵U-1对音频校准,音频灭错校准最大值为V,通过音频灭错校准值来判断英语发音的准确性,由V 值的变化确定学生发音的校准率变化情况。
3 实验分析
3.1 准确率分析
使用本文系统和嵌入式实时英语发音校准系统校准某校2020 级1、2 班共30 名学生的英语发音,对两种系统的鲁棒性实施对比,结果显示如图3 所示,分析该图可得,本文系统的鲁棒性比嵌入式实时英语发音校准系统平均高0.2。可知,本文系统鲁棒性高,系统稳定性强。基于上述公式的计算,本文系统对英语语音发音校准准确率为95.36%,使用该系统对英语语音发音的流利度与正确性进行校准的准确率较高,效果较好。
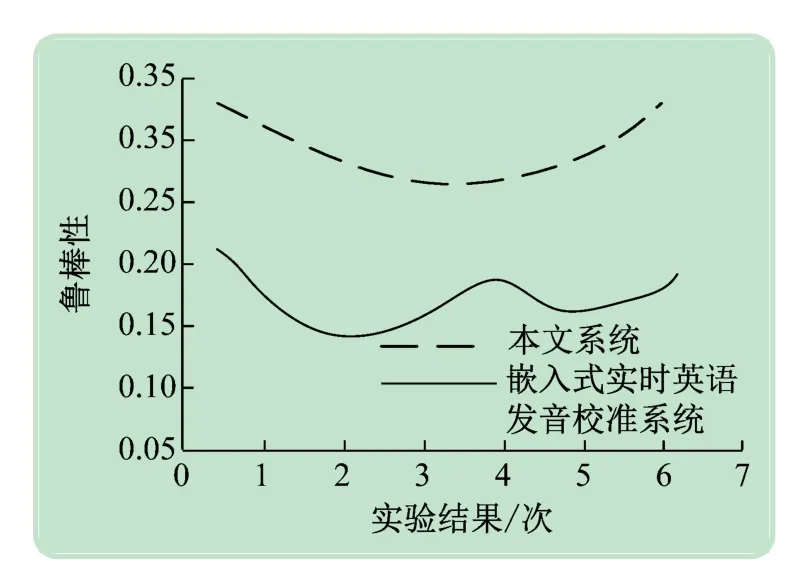
图3 两种系统的鲁棒性对比
3.2 成绩分析
实验利用spss13.0 软件统计使用本文系统校准英语发音的实验班(1 班)和采用嵌入式实时英语发音校准系统校准英语发音的对照班(2 班)的英语考试成绩,两个班级的人数都是15 人,统计结果见表1。

表1 最高与最低分数对比
结果显示,实验班各项考试的最高分数都在96 分以上,英语对话的最高分数为98 分,而对照班各项考试的最高分数在72 分以上,短篇口语的最高分数是74 分;实验班各项考试的最低分数都在84 分以上,而对照班各项考试的最低分数在40 分以上;数据结果说明,使用本文系统校准英语发音的实验班成绩明显高于对照班,本文系统能够显著提高学生的英语发音能力。
3.3 教师评价结果分析
教师对采用本文系统和嵌入式实时英语发音校准系统学习的实验班和对照班学生英语发音学习效果进行评价,评价结果如图4 所示。

图4 教师评价结果
图4 结果显示,教师认为采用本文系统进行英语口语发音校准后的实验班学生的自信心、发音流利度以及语法正确性等指标的评分都达到90 分以上,而对照班的各项指标评分都低于60 分,说明本文系统的能够多方位提升学生英语发音的学习效果,教师满意度高。
4 结语
实验对本文系统和嵌入式实时英语发音校准系统的实际使用情况进行问卷调查,问卷调查内容是试验学生对两个系统的满意度打分情况。本文系统明显比嵌入式实时英语发音校准系统好,能显著提高学生学习英语发音的积极性,具有较高的满意度。
本文设计的基于VR 的英语发音校准仿真系统,并通过实验仿真对本文系统英语发音校准的准确率、学生学习效果和老师评价效果进行了全面检测分析。实验结果显示,本文系统对英语语音发音校准准确率高达95.36%,系统的鲁棒性比嵌入式实时英语发音校准系统平均高0.2;实验班考试最高成绩平均都在92 分以上,并且教师认为本文系统能够多方位提升学生英语发音的学习效果。实验结果说明,本文系统具有较高的英语发音校准率,显著提高学生的英语学习能力,达到了学生和教师的期待效果。
猜你喜欢
阅读(快乐英语中年级)(2023年9期)2023-10-24
中学生英语·阅读与写作(2023年9期)2023-10-19
北京教育·普教版(2020年9期)2020-10-09
校园英语·中旬(2019年11期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
疯狂英语·新策略(2018年7期)2018-08-29
电子制作(2017年9期)2017-04-17
人间(2015年8期)2016-01-09
小学生时代·大嘴英语(2015年12期)2016-01-07
