
基于HDF5 的煤矿地质三维层叠网格模型分布式存储研究
2023-02-21 08:05郭军
工矿自动化 2023年1期
郭军
(1.煤炭科学研究总院有限公司 矿山大数据研究院,北京 100013;2.煤炭资源高效开采与洁净利用国家重点实验室,北京 100013)
0 引言
三维地质模型在表达煤矿所辖范围内地下资源禀赋情况的同时,还可为矿井采掘部署、地质保障、安全生产管理提供科学的辅助决策,对推进煤矿智能化建设具有非常重要的现实意义和战略意义[1]。当前三维地质模型的地质结构特征大多采用基于边界表达的方法,利用不规则三角网进行数据组织和管理。三角网组织地质模型的优势在于可视化展示方面,但对于局部空间分析和查询则难以处理,尤其针对智能开采需要进行单点查询和多属性分析等高效处理时,三角网组织地质模型的不足更加明显。所以,煤矿三维地质结构及地质属性场的表达需要突破传统三角网等表达策略,要向统一描述地质结构和属性分布的真三维网格模型转变,通过综合探测手段及煤矿地下空间作业场景变化,不断更新三维地质网格,以提高模型的精度,适应智能开采和安全保障的应用要求[2]。在当前大数据背景下,利用真三维地质网格模型实现地下环境的多分辨率表达,多源数据、多参数的融合建模,模型局部更新及实现煤矿地下空间任意点多源数据综合分析,将是研发新一代煤矿地学信息系统的基础。
然而三维地质网格模型由于对地下空间进行网格化离散,数据量随着离散精度或者网格分辨率增加而呈指数级增加,一方面影响数据访问和调度效率,另一方面由于存在大量数据冗余,即局部网格的属性值相同,影响查询性能。因此,地质网格模型的组织策略和存储管理是当前亟需解决的主要问题。通过组织策略主要解决地质网格模型的数据冗余问题,降低数据量并提升查询性能;采用高效的数据存储和管理解决数据查询和调度问题。
三维地质网格模型及网格化数据组织的研究和应用非常丰富[3]。从空间位置和网格拓扑关系的显式和隐含表达角度来看,三维地质网格模型可划分为以四面体网格、角点网格[4]、广义三棱柱[5]等为代表的显式表达模型和以规则网格、八叉树[6]、层叠网格[7]等为代表的隐含表达模型。显式表达模型主要刻画复杂地质构造,网格生成及处理难度大,主要应用于油气领域进行数值模拟[4]。隐含表达模型生成简单,在模型局部查询、空间分析和可视化展示方面更加高效,在地质各领域应用广泛[6-8]。本文的三维地质网格模型主要采用隐含表达模型,适应地学大数据简单、易用需要。
由于煤矿沉积地层地质结构具有层状叠置及横向相对连续等特征,在实际应用中地层(岩层)的边界和断层等构造是主要查询和分析的对象。规则网格或者体素模型及八叉树模型需要对网格进行标记才能区分边界特征,检索过程需要遍历网格单元,造成查询性能降低。层叠网格则是在空间Z方向直接近似地质边界或者对规则化网格单元进行归并压缩,因此,层叠网格单元的顶面或底面可以精确或者近似描述地质边界。
在三维地质网格模型的数据存储方面,结合云计算等分布式存储是主要研究和发展方向。分布式存储技术利用网络技术在多台机器的磁盘空间中分散存储地质数据,通过分布式数据库系统和分布式文件系统,有效解决集中式存储技术将数据放在某个特定节点上管理和查询效率低下的问题[9]。分布式数据库系统一般能提供完整的数据库设计和数据管理查询接口,易于实现和维护,如使用关系型数据库MySQL 和非关系型数据库MongoDB 等[10]。分布式文件系统通过文件管理及分布式管理组件实现,如Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)[11]。分布式文件系统较灵活,适用于非结构化数据和空间数据的分布式存储。分布式文件系统中文件格式和操作的灵活性、稳定性及通用性是空间数据存储需要重点考虑的。针对大规模网格数据管理和频繁调度需求,HDF5(Hierarchical Data Format Version5)[12]已成为一种层次化多级网格数据存储的通用格式之一,在科学计算及地球科学领域应用广泛,可高效地对网格化和多维度化数据进行存储、管理、获取和分发等操作,具有简单易用、自描述、跨平台和读取方式灵活等优点。然而,HDF5 属于单文件集中式存储模式,无法满足分布式文件系统的分布管理和数据调度要求。
通过以上分析,考虑煤矿地层特征,为解决煤矿三维地质网格模型的网格数据冗余造成的数据规模和存储方式对空间查询性能影响等问题,提出了基于HDF5 的煤矿地质三维层叠网格模型分布式存储方案,采用层叠网格对煤矿三维地质模型数据进行数据压缩和分块组织,通过数据分块解决大规模地质网格模型数据的组织问题,数据分块同时将空间相近的数据集中在相邻的硬盘扇区或存储设备中,有利于提高数据调度效率。结合HDF5 文件存储优势实现了煤矿三维地质网格数据的分布式文件存储管理。
1 基于三维层叠网格的煤矿地质模型表达
三维地质网格模型将煤矿地质构造、岩层结构及内部地质属性等多参数信息统一表达在一个模型中,一般采用空间均匀划分方式表达岩层结构和属性分布,这样不仅利于数据更新,而且便于煤矿基于空间位置的多属性查询,如巷道设计、掘进或者开采中的实时地质数据获取等。
1.1 三维层叠网格模型数据组织
三维规则网格或者体素模型将地下空间离散为网格单元或者体素来描述地下空间复杂的结构和地质属性分布。网格化表达地质模型的数据量会随着模型分辨率提升呈指数级增加。一般的沉积岩层具有很好的纵向分层性,A.Graciano 等[7]利用这一特性提出了层叠网格模型,不仅可解决体素网格化造成的数据量问题,而且网格单元的顶底直接描述了地层或者岩层的顶(底)面。层叠网格模型在横向(X-Y坐标)方向保持与体素网格相同的划分方法,在纵向(Z坐标)方向按岩层进行属性归并堆叠,实现了数据压缩,从而降低了数据量,比八叉树模型具有更好的压缩效果。总的来说,层叠网格模型是一种横向上无需构建网格间关联及类似于游程编码压缩的规则网格模型。基于层叠网格模型表达的三维地质模型如图1 所示。层叠网格可形式化表达为StackGrid=

图1 基于层叠网格模型表达的三维地质模型Fig.1 3D geological model expressed by stackgrid model
对于断层面等地质构造及地质异常体,将面和体进行网格化嵌入到层叠网格或者单独用层叠网格存储。采用网格化表达断层面时,断层面会填充到网格单元内,使其具有网格单元大小的“厚度”。
1.2 三维地质网格模型分块组织
针对三维地质模型所表达的地质空间范围大及单一数据体数据量多等问题,三维地质网格模型一般采用分级组织、分块存储的策略,将整体数据划分成较小的数据块,如图2 所示。数据分块采用规则网格对某一分辨率数据进行划分并进行数据块索引。根据目前常用的HDF5 与MySQL 和MongoDB等文件或数据库管理存储块特点,一般来说,数据块的大小应该保持在0.5~4 MB 之间[9],对应32×32×32或 64×64×64 分辨率的网格化模型。数据分块后,对每一个数据块分别采用层叠网格、体素网格、线性八叉树进行组织对比。
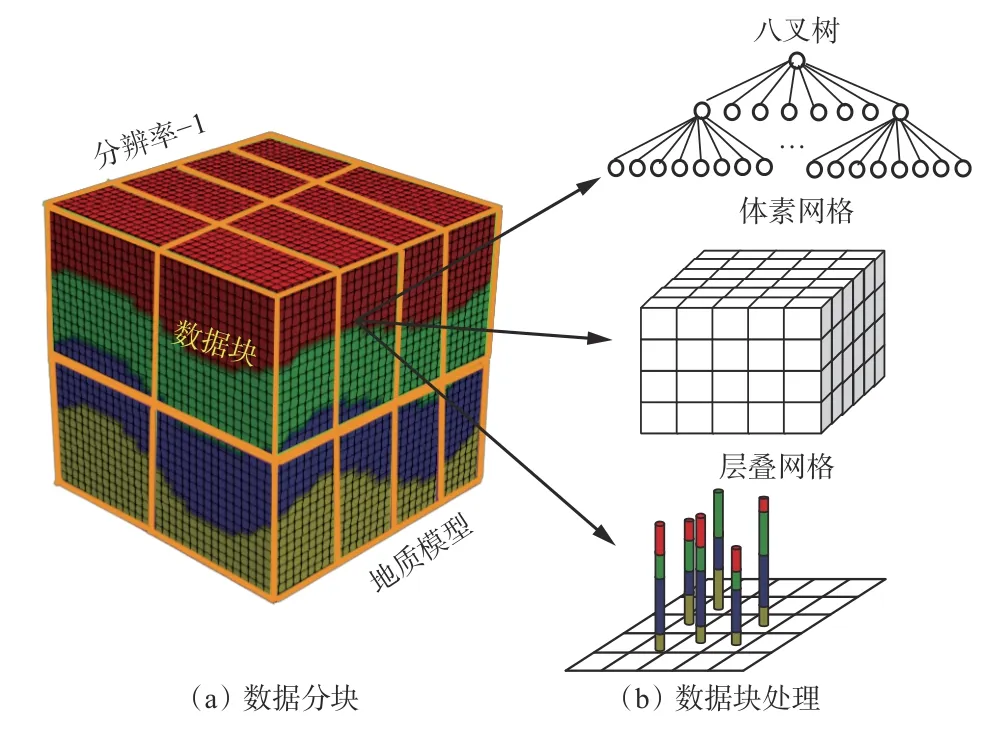
图2 三维地质网格模型数据组织Fig.2 Data organization of 3D geological grid model
2 三维地质模型数据存储设计
2.1 HDF5 数据存储设计
在一个存储节点上,HDF5 将三维地质模型作为一个整体文件存储,不同分辨率的数据块作为一个数据集(DataSet)存储,利用HDF5 特有的层级存储管理格式可以实现网格模型不同分辨率及数据分块的层级组织结构,如图3(a)所示。数据块的存储结构由数据集DataSet 完成。层叠网格由于Z方向是非均匀网格划分,因此,其存储结构对比体素模型要复杂。如图3(b)所示,体素模型X,Y和Z三个方向均匀划分,可以用三维数组结构存储,其维度(Dim)为3,存储数据data 的类型是基本数据类型,本文默认为整型。八叉树模型X,Y和Z三个方向都是非均匀划分,只能是一维数组结构存储,采用线性八叉树的Morton 码进行组织,只存储叶子节点,每个节点是一个复合数据类型(CoumpoundDataType),需要存储索引index 和数据data。层叠网格模型XY方向均匀划分,Z方向非均匀划分或者按地质边界划分,XY方向规则网格用二维数组结构存储,其维度(Dim)为2,复合数据类型(CoumpoundDataType)作为层叠柱的索引index,存储分层个数layernum 和该层叠柱的数据位置datapos;所有层叠柱存储在data 中,每个分层点是复合数据类型,用于存储地质界面的id 和z值。

图3 HDF5 数据存储Fig.3 HDF5 data storage
从以上存储结构可以看出,层叠网格模型相对于体素模型和八叉树模型存储复杂一点,主要原因在于XY方向和Z方向的划分方式不同。对于单点查询,层叠网格模型需要进行2 次数据集DataSet 访问。
2.2 MySQL 和MongoDB 数据存储设计
数据库存储的库表结构一般无法直接存储网格单元,需要将数据块整体作为一个字段进行处理。采用MySQL 和MongoDB 的数据库表设计如图4 所示。Model 表主要用于描述模型的元数据及存储信息,LodGrid 表用于存储分级和分块信息。Block 表用于存储具体数据块,分别给出了体素网格(GridBlock)、线性八叉树(OctreeBlock)及层叠网格(StackGridBlock)的数据块存储表。在数据块Block 中,类似HDF5 中的数据集DataSet,包括ID、DATA 和LAYERID 三个字段。ID 表示数据块在数据库表的唯一标志码;DATA 表示具体数据,采用Blob 二进制块存储;LAYERID 表示所在层级或者分辨率。体素网格数据块(GridBlock)的地质数据由一个Blob 存储即可,八叉树和层叠网格的DATA 需要2 个Blob 字段,一个是索引块(INDEXDATA),一个是地质数据块(BLOCKDATA)。

图4 MySQL,MongoDB 数据存储结构Fig.4 Data storage structure of MySQL and MongoDB
从图3 和图4 可看出,HDF5 中的数据集DataSet类似数据库中的Blob 字段。但是,DataSet 的意义明确,维度清晰,而数据库Blob 字段是不明确的,需要元数据进行说明,查询时只能自行解析。同时,数据库难以表达分级结构。单点查询方面,HDF5 中的数据集DataSet 可以通过文件跳转直接定位到所查询位置,而数据库Blob 字段一般需要先将数据全部读出后再进行解析,所以会对查询性能造成一定影响。
3 基于HDF5 的分布式存储
3.1 整体架构
分布式存储和管理是解决大规模海量数据调度的主要手段,可以通过负载均衡将数据访问的压力分散到集群中的各个节点,提高数据读写的性能与稳定性[13-16]。关系型数据库MySQL 和非关系型数据库MongoDB 等提供了较为完整的分布式存储管理方法,遵循使用规范即可完成数据的分布存储和管理调度。然而,HDF5 作为单一结构化文件格式,存储数据多维度、多变量且结构紧凑,如果将HDF5 采用类似HDFS[8,15]分布式存储技术分块存储,势必会破坏原生格式的紧凑型,降低I/O 性能。为此,本文重点讨论基于HDF5 的分布式存储管理架构,提出了一种直接针对原始结构化HDF5 文件进行分布式存储的技术方案。HDF5 分布式数据存储管理和查询的整体架构如图5 所示。①在数据存储方面,HDF5 作为存储的持久化层,用来存储所有的原始数据,采用内存数据库Redis 存储热点数据、HDF5 元数据等相关信息。② 在Web 服务方面,使用H5Serv 发送和接收HDF5 数据。③在HDF5 实现分布式方面,利用网络文件系统(Network File System,NFS)实现HDF5 数据在不同节点服务器之间的共享;利用远程同步(Remote Synchronize,Rsync)[17]和Inotify 实现HDF5 数据在不同节点服务器的数据实时同步;通过Nginx 服务器实现访问时反向代理和数据服务节点的负载均衡。④ 应用Docker[18]容器技术将数据节点服务和Nginx 服务进行统一部署,通过JupyterLab 交互式数据管理平台实现实时数据资源的调度和管理。
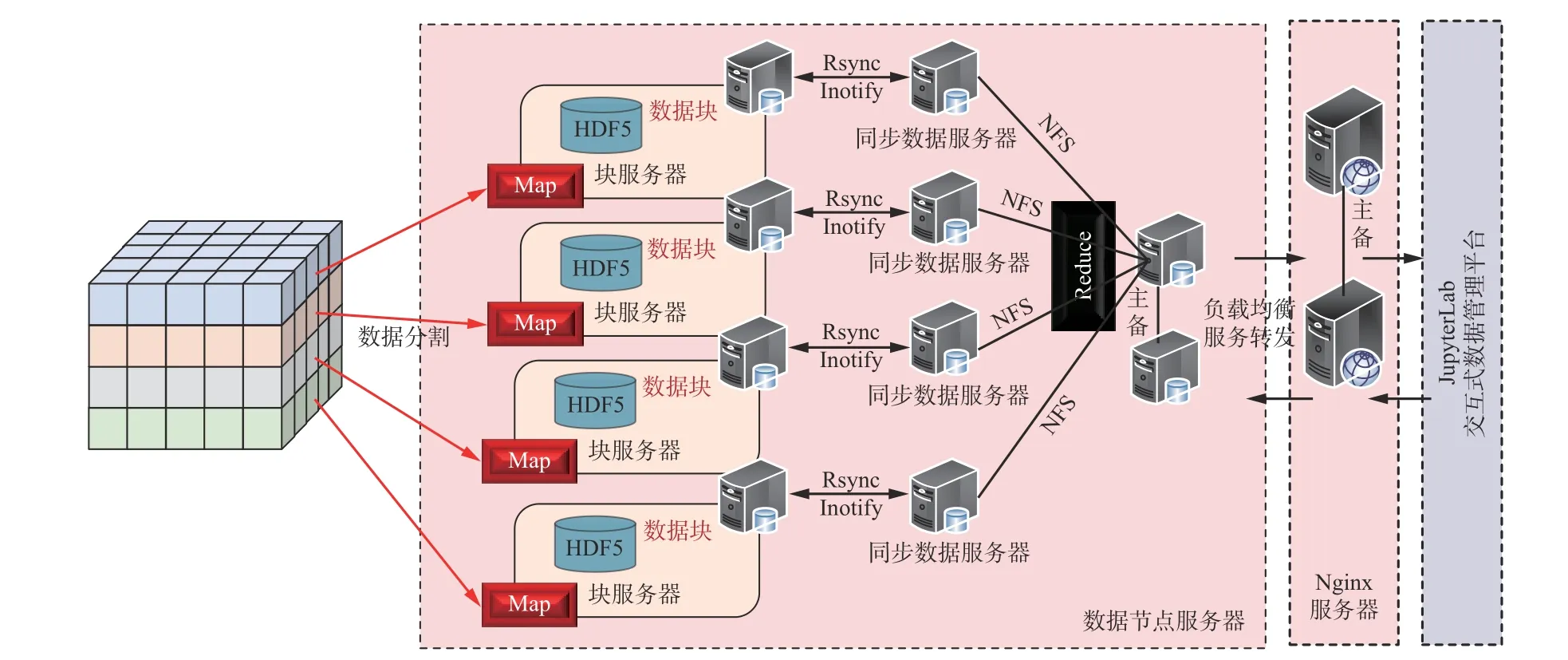
图5 基于HDF5 的分布式存储管理系统架构Fig.5 Architecture of distributed storage management system based on HDF5
3.2 基于NFS 的 HDF5 文件共享
NFS 依赖远程过程调用(Remote Procedure Call,RPC)机制,允许网络中的计算机之间通过TCP/IP 网络共享资源[19]。在NFS 的应用中,本地NFS 的客户端应用可以透明地读写位于远端NFS 服务器上的文件,就像访问本地文件一样,如图6 所示。使用NFS 实现HDF5 文件共享,可以减少本地存储HDF5文件的空间,提供HDF5 透明文件访问及文件传输。通过配置NFS 共享HDF5 文件,作为分布式存储HDF5 文件统一访问的入口。

图6 HDF5 数据共享Fig.6 HDF5 data sharing
3.3 基于Rsync+Inotify 的HDF5 文件实时同步
Rsync 的任务是远程同步和数据备份,使HDF5文件在2 台服务器间实现数据快速同步镜像和远程备份。HDF5 实时同步更新如图7 所示,同步HDF5文件的同时可以保持原来文件的权限、时间、软硬链接等附加信息。Inotify 作为Linux 文件系统的变化通知机制,一台服务器上HDF5 文件增加、删除等事件可以立刻通知另一台服务器,结合Rsync 实现HDF5 数据实时监控和同步更新。

图7 HDF5 实时同步更新Fig.7 HDF5 real-time synchronization update
3.4 基于Nginx 的 HDF5 访问负载均衡实现
针对并发请求HDF5 数据带来的服务过载问题,需要搭建服务器集群解决单一服务器无法实现的负载均衡分发。HDF5 访问负载均衡实现如图8 所示,使用Nginx 服务器内置的负载均衡策略[20]将并发访问转发至不同的服务器进行处理,减少单服务器的压力,解决数据传输响应慢、连接丢失、甚至无法访问的问题。
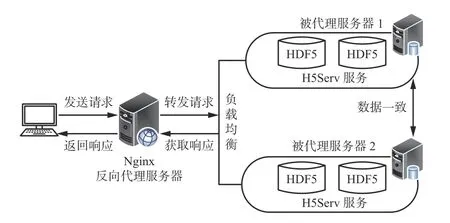
图8 HDF5 负载均衡Fig.8 HDF5 load balancing
3.5 基于JupyterLab 的数据管理和调度实现
JupyterLab 作为交互式分析典型的Web 架构应用,可以在其中记录代码和运行代码、可视化数据、查看输出结果。使用JupyterLab 可统一管理使用分布式存储框架,且能以实时代码和结果可视化集成展示的形式应用于大数据分析[21]。
4 实验分析
通过实验对比,验证层叠网格模型对比体素模型和八叉树模型在降低数据量及不同存储方式下空间查询的优势;验证基于HDF5 的分布式文件存储管理比数据库分布式存储具有更好的空间查询优势。
4.1 实验数据
实验数据选用某煤矿三维地质模型,如图9 所示,主要构建了煤岩岩性结构分层。以该煤矿三维地质模型构建网格化地质结构模型,网格划分横向分辨率为10 m,纵向分辨率为0.5 m。网格规模为640×320×1 200,地质属性类型为整型(4 byte)。该实验网格数据分别采用体素模型、八叉树模型及层叠网格模型进行数据组织,存储方案分别采用基于HDF5 的分布式文件存储与MySQL 和MongoDB分布式数据库存储。3 种数据组织模型和3 种存储方式所使用的存储空间对比见表1。

图9 某煤矿三维地质模型Fig.9 3D geological model of a coal mine
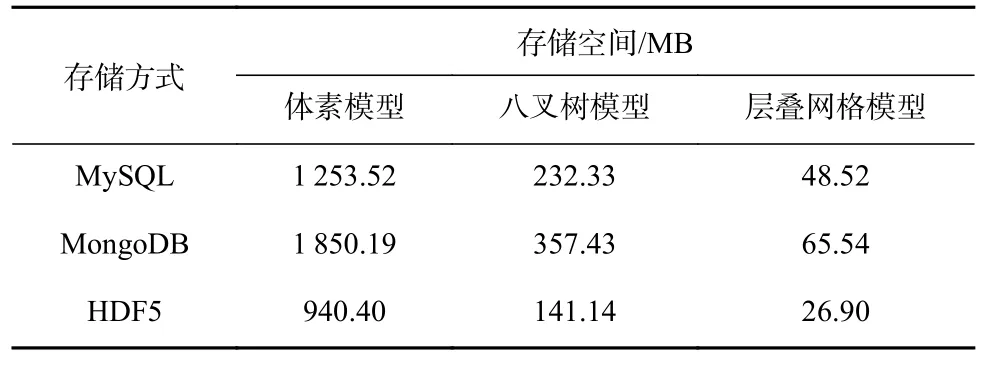
表1 网格数据存储空间使用量对比Table 1 Comparison of griddata storage space
从表1 可看出:体素模型需要对网格划分分辨率下所有位置进行存储,数据量与网格规模有关,数据量达到GB 级别;由于进行了单元合并冗余处理的数据压缩,基于八叉树和层叠网格的存储方式可有效减少数据量,且层叠网格相对于八叉树只存储了界面位置的格子,对于层状地质结构能更有效降低数据量。基于HDF5 的文件存储明显比MySQL 和MongoDB 数据库存储更加节省空间,主要原因在于HDF5 的DataSet 可直接存储数据块,不需要额外存储信息,而数据库存储在Blob 字段存储数据,为了查询优化,需要对Block 表构建索引,而这些索引属于数据库性能优化方面的额外空间。因此,对于层叠网格模型等有一定空间规则的数据,基于HDF5 的文件方式比数据库方式更加节省存储空间。
4.2 测试环境
测试环境选用阿里云Linux 系统Ubuntu 服务器进行测试,操作系统为Ubuntu16.04 64 位,CPU 为2 核,内存为2 GB,SSD 云盘为40 GB,带宽峰值为5 MB,测试平台为JupyterLab 及测试语言为Python。
4.3 单存储节点测试
在相同测试环境和相同的负载下,针对4.1 节中实验数据,在同一个数据服务节点提取指定单网格空间位置、虚拟钻孔的属性值及提取岩层界面。检索单网格位置是给定空间位置得到该位置的地质属性id,选择3 个不同位置的检索结果见表2。虚拟钻孔是给定井口位置xy坐标,提取该位置z方向所有单元属性,选择3 个不同井口位置的检索结果见表3。提取岩层界面是指提取指定岩层id,提取其顶面全部煤矿范围内的空间位置,由于体素模型需要逐个单元查询,没有检索优势,只比较八叉树模型和层叠网格模型,选择3 个岩层的检索结果见表4。

表2 单网格位置查询时间Table 2 Single grid node query time

表3 虚拟钻孔查询时间Table 3 Vitural drill query time
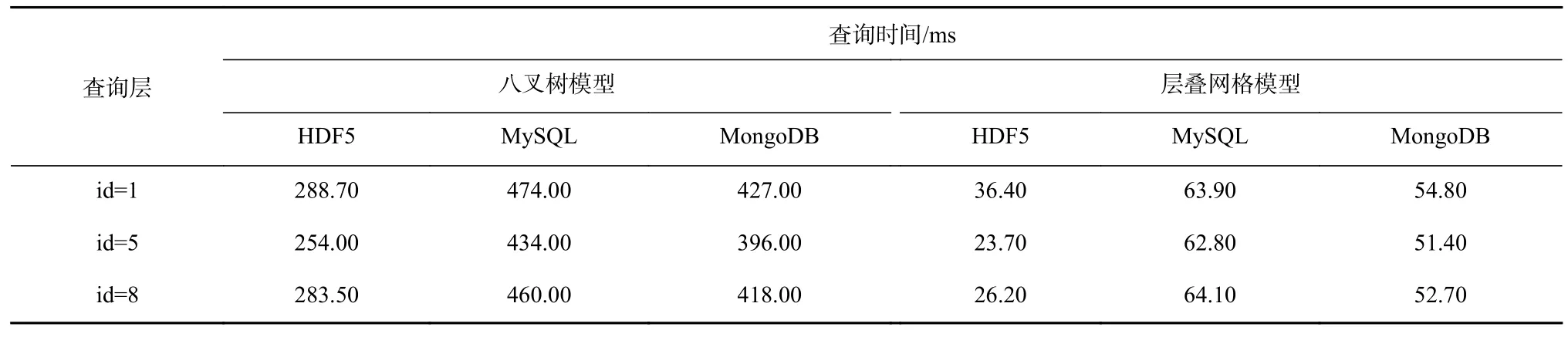
表4 提取岩层顶面查询时间Table 4 Time for extracting stratum top surface
从表2-表4 可看出:在网格模型的数据组织方面,在单网格位置查询测试中,体素模型具有优势,主要原因在于数据模型和存储结构方面,体素模型只需要一次定位就可以得到该位置属性,而层叠网格模型和八叉树模型需要遍历网格点找到相应空间位置。但是对于虚拟钻孔和层面提取,由于主要涉及地质界面信息,层叠网格模型的查询性能具有明显优势,体素模型和八叉树模型都需要逐一遍历判断地质界面所在网格单元。在数据存储方式上,基于HDF5 的查询性能明显高于数据库,HDF5 可在DataSet 中直接读取数据,而数据库一般都需要读取整个Blob 字段并进行解析,需要处理事务及查询索引优化操作,相对比文件系统降低了查询性能。
4.4 分布式存储测试
对于单网格点测试和虚拟钻孔数据操作基本还是在单存储节点进行。分布式测试主要对比地层顶面提取方法的差异。分布式测试使用6 台服务器分别搭建分布式存储管理集群,其测试结果见表5。
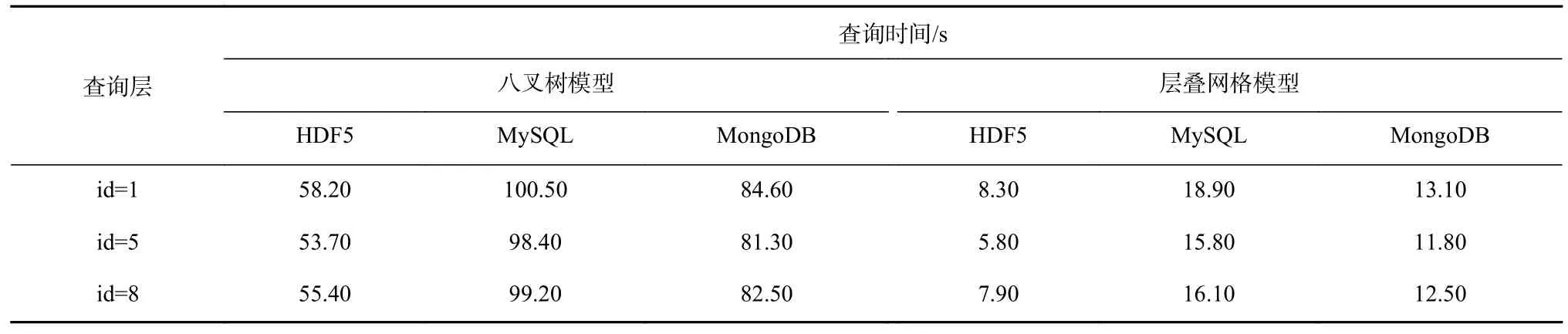
表5 提取岩层顶面的分布式查询时间Table 5 Distributed query times of stratum top surface
从表5 可看出:HDF5 分布式查询性能优于MySQL 和MongoDB 等分布式数据库,主要原因在于单节点的查询性能HDF5 优于数据库,同时基于HDF5 的分布式存储管理架构可以弥补HDF5 不支持分布式查询的不足,实现了大规模网格数据的分布式管理和高性能查询处理。数据组织方面,层叠网格模型在岩层界面查询方面明显优于八叉树模型。因此,基于层叠网格和HDF5 的数据组织和存储方案可以为煤矿三维地质网格模型的有效存储管理提供借鉴。
5 结论
针对煤矿三维地质网格模型的分布式存储和查询性能问题,提出了基于HDF5 的煤矿地质三维层叠网格模型分布式存储方案,该方案在网格数据组织方面采用层叠网格对三维地质模型进行分块组织,在分布式存储和查询方面实现了基于HDF5 的分布式文件存储管理。基于层叠网格的地质模型数据组织和基于HDF5 的分布式存储可以实现煤矿三维地质网格模型的有效存储管理和空间查询。
(1)层叠网格模型在XY方向上规则划分,Z方向通过单元合并冗余处理的数据压缩对地质界面进行近似或者精确描述,更加适合煤系沉积地层结构的网格化表达,相对于体素模型和八叉树模型数据量更小,便于实现地质界面的快速查询。
(2)基于HDF5 文件和数据库表的层叠网格模型存储结构相对于体素模型和八叉树模型要复杂。单点查询操作比体素模型次数多,性能低。
(3)设计和实现了基于HDF5 的分布式存储管理框架,通过Docker 容器将HDF5 的H5ServWeb 服务、NFS 文件共享及Rsync 实时同步、Nginx 技术和负载均衡处理进行统一部署,基于JupyterLab 的终端实现,解决了单一HDF5 无法实现分布式存储和查询的问题。基于HDF5 的分布式存储管理框架在层叠网格模型、体素模型和八叉树模型3 种数据组织下空间查询性能优于非关系型数据库MongoDB 和关系型数据库MySQL。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05
家庭医学(2022年3期)2022-04-07
计算机集成制造系统(2020年4期)2020-05-08
中国惯性技术学报(2019年1期)2019-05-21
能源(2017年10期)2017-12-20
电子制作(2017年13期)2017-12-15
能源(2017年5期)2017-07-06
科学与财富(2016年29期)2016-12-27
软件导刊(2016年11期)2016-12-22
科教导刊·电子版(2016年11期)2016-06-03
