
基于多变量光谱数据分析方法的乳腺癌血清拉曼光谱特征研究
2023-02-22 06:42张宝萍张富荣陈一申张占琴
光谱学与光谱分析 2023年2期
张宝萍, 宁 甜, 张富荣, 陈一申, 张占琴, 王 爽*
1. 西北大学光子学与光子技术研究所, 陕西 西安 721710 2. 西安交通大学第一附属医院, 陕西 西安 710061
引 言
乳腺癌是乳腺上皮细胞在多种致癌因子作用下, 发生增值失控的现象[1]。 乳腺癌发病率和致死率虽位于女性恶性肿瘤首位, 但如在早期得到诊断治疗, 约90%的病例可以治愈[2]。 临床常采用影像学(钼靶和超声相结合)和体格检查, 结合穿刺或切除活检的方式, 开展乳腺癌早期筛查与病理诊断。 准确的组织学病理诊断, 对制定恰当的临床治疗方案及预后评估意义重大, 这要求检测人员具有深厚的专业知识背景与临床经验。 相比于细胞、 组织等其他临床病理样品, 血液更容易采集, 且其生化构成变化信息在医学影像学中常检测到的临床症状出现之前, 就会出现较为明显的变化[3-4]。 研究血液样品生化分析技术, 有望发展一种针对乳腺癌早期筛查与诊断技术。
振动光谱[包括红外光谱和拉曼光谱(Raman spectroscopy, RS)]技术能够以快速、 无损、 非侵入式的方式特异性阐释生物构成信息, 已被研究证明具有提供检测及诊断信息的能力[1], 其在研究恶性疾病病理演进、 早期诊断和预后评估等方面具有重要应用价值。 红外光谱根据入射光频率被分为近红外(near-IR, NIR)、 中红外(mid-IR, MIR)和远红外光谱(far-IR, FIR), 其中, MIR是分析生物材料的主要技术, 因为它涵盖了重要生物分子的基本振动模式。 NIR光谱也可以作为生物光谱分析工具, 但由于其主要由MIR泛音组成, 使得该信号非常复杂且包含许多重叠的特征, 例如: 使用NIR进行生物标志物识别比MIR更困难、 更模糊。 而拉曼散射可以用于光谱的紫外光、 可见光或NIR区域, 因而可以在本质上提供更高的空间分辨率[5]。 相对于红外光谱, 水的O—H振动在拉曼光谱中极弱, 使得拉曼光谱更适合于某些生物医学应用, 特别是体液样本(血浆、 血清、 唾液或尿液)的分析测量[6]。 在基于血液样本(血浆、 血清)拉曼光谱恶性肿瘤诊断方面, 许多研究团队已开展了多项实验探索。 其中, Lin等通过血浆表面增强拉曼光谱技术建立了鼻咽癌肿瘤病理分期方法[7]; Li等[8]结合多变量光谱数据分析方法, 探索了基于血浆共振拉曼光谱分析技术的食道癌检测方法; Wang等[9]通过血清激光拉曼光谱技术探讨了该技术在非小细胞肺癌早期筛查和临床分期中的作用; Bilal等[10]结合偏最小二乘回归分析, 通过血清拉曼光谱技术表明了乳腺癌从健康到癌变过程中的生化变化。
采用显微拉曼光谱检测, 分析不同病变阶段(健康, 早期癌变和晚期癌变)乳腺癌血清样品生化特征信息, 采用主成分分析(principal component analysis, PCA)与线性判别分析(linear discriminant analysis, LDA)、 支持向量机(support vector machines, SVM)和偏最小二乘算法(partial least squares discriminant analysis, PLS-DA)等多种光谱分析手段, 构建多种光谱数据归类鉴别模型。 进而, 采用留一交叉验证方法(leave-one-out cross-validation, LOOCV)评估、 比较这些模型的灵敏度、 特异性和准确率, 最终, 阐释血清拉曼光谱分析技术在乳腺癌早期筛查与病理分期分级中的应用基础。
1 实验部分
1.1 样品
血清样品来源于西安交通大学第一附属医院。 根据临床诊断, 样品包括健康(healthy, H)、 早期癌症(early cancer, EC)和晚期癌症(advanced cancer, AC)三种类型, 其中, 10名健康志愿者经检查没有任何疾病, 早期癌症由20例浸润性导管癌组成[临床TNM分期分别为三期一级(s3g1)和三期二级(s3g2)], 晚期癌症包括20例浸润性导管癌[临床TNM分期分别为三期三级(s3g3)和二期三级(s2g3)]。 早期和晚期癌症组均在临床通过病理学方法确诊, 其中, 健康组年龄36~69岁, 平均53岁, 早期癌症组的年龄为49~68岁, 平均为62岁, 晚期癌症组的年龄为46~79岁, 平均为69岁。 禁食12 h后抽血采集的新鲜血液, 不添加任何抗凝剂, 用高速离心机(4 000 r·min-1)在4 ℃下离心20 min后, 提取上清液即血清, 用于拉曼光谱实验分析。 将获得的血清分装于离心管中并储存在温度为-80 ℃的冰箱中以备实验所需要。
1.2 方法
使用532 nm半导体激光器作为激发光源, 与显微拉曼光谱系统(Alpha 500R, WITec GmbH, Germany)进行拉曼光谱检测。 血清样品室温解冻10 min后, 放置在内径0.5 mm、 外径0.8 mm、 5 μL量的石英毛细管中, 以减小在实验过程中空气对血清成分的影响, 降低激光对血清样品的灼伤(样品表面的最大激光功率约10 mW), 然后将其置于载物平台用于光谱测量。 采用20倍显微镜激发样品光谱, 并由拉曼光谱仪(UHTS300, WITec GmbH, Germany)采集600~3 000 cm-1范围内的光谱信息。 单个血清样品每次光谱采集时间为5 s, 每种类型样品获取100条光谱。 实验测量前使用标准钨灯(RS-3, EG&G Gamma Scientific, USA)校准系统光谱响应, 并采用硅片520.7 cm-1光谱特征峰校准系统波长。
1.3 数据处理
采用本团队自行开发的NWU-Spectral-Analysis(NWUSA)Toolbox[11], 对实验所采集的原始光谱依次进行去宇宙射线、 扣除荧光背景、 九阶多项式拟合, 以及五阶Savitzky-Golay平滑等预处理。 预处理之后, 对每条光谱作曲线下面积归一化, 以消除如激光功率不稳定等外界因素的干扰; 然后将所有光谱特征峰的强度值矩阵进行均值中心化, 以消除样品内和/或样品间光谱变异性对多变量分析的干扰; 随后采用主成分分析方法(PCA)降低光谱数据集维度, 并结合单因素方差分析(one-way ANOVA)提取、 识别显著差异主成分信息(principal components, PCs,p<0.01)。 最后, 将所提取的PCs作为线性判别函数(LDA)的输入变量, 生成PCA-LDA光谱特征鉴别模型, 并采用LOOCV方法验证此模型的分类鉴别能力。 此外, 将主成分信息输入支持向量机(SVM)算法, 采用三种核函数(线性式、 多项式和RBF)构建PCA-SVM模型。 该模型的分类鉴别性能主要受到误差惩罚参数C, 以及核函数形式和参数影响。 对于线性SVM内核只需要优化一个误差惩罚参数C, 在确定的特征子空间中C的取值小时, 表明机器学习的复杂度小且经验风险值较大; 当C取无穷大时, 满足所有约束条件, 意味着训练样本必须准确地分类; 当C超过一定值时, SVM的复杂度达到了特征子空间允许的最大值, 其经验风险值和泛化性能几乎不再变化。 对于多项式和RBF核函数, 除需优化参数C外, 还需要分别对多项式阶数(d)和RBF核函数宽度(γ)进行优化, 其中d值越大, 多项式核矩阵元素值与核函数维度越大, 计算也越复杂, 对数据的分类能力更好, 但易出现过拟合现象; RBF核函数中的参数γ定义了单个样本对整个分类超平面的影响, 当γ比较小时, 单个样本对整个分类超平面的影响比较小, 反之, 当γ比较大时, 单个样本对整个分类超平面的影响比较大, 更容易被选择为支持向量[12]。 研究以80%实验数据构造训练数据集, 采用网格搜索结合LOOCV来优化每个核的参数, 获取分类精度最高的参数作为构建最终SVM模型的最佳参数, 并将其应用于验证测试集数据(其他20%光谱数据)。 在构建PCA-LDA和PCA-SVM模型后, 进一步通过均值中心化后的强度矩阵构建偏最小二乘分类(PLS-DA)模型。 最终, 采用LOOCV方法评估、 比较三种判别模型光谱鉴别分析性能。
2 结果与讨论
2.1 乳腺癌血清样品的拉曼光谱
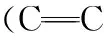

表1 血清拉曼光谱特征峰位及其生化分配Table 1 Raman spectral characteristic peaks of serum and their biochemical assignments
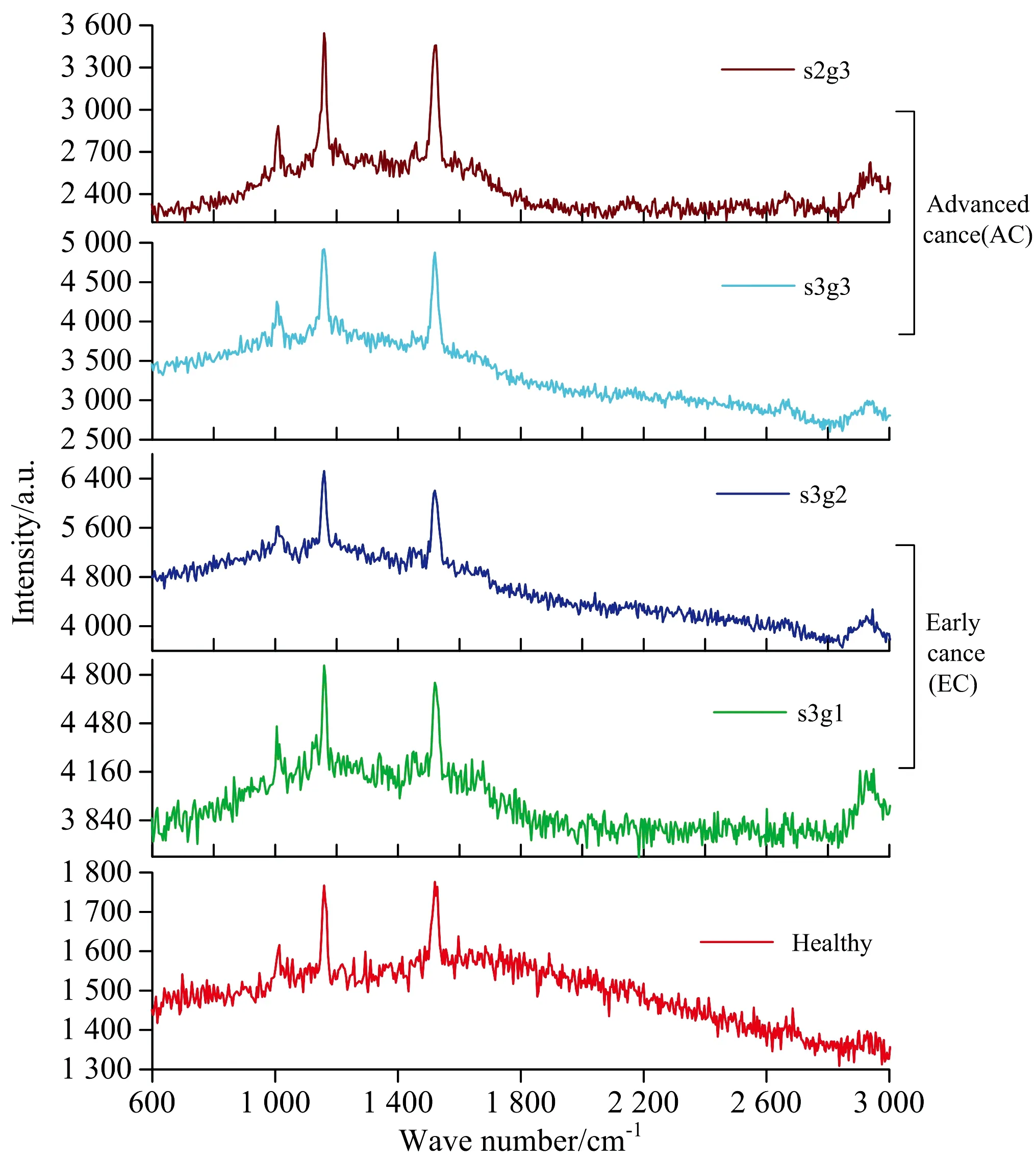
图1(a) 健康(H)、 早期乳腺癌变(EC, s3g1, s3g2)和晚期乳腺癌变(AC, s3g3, s2g3)血清原始拉曼光谱Fig.1(a) Original serum Raman Spectra from Healthy (H), Early Breast Cancer (EC, s3g1, s3g2), and Advanced Cancer (AC, s3g3, s2g3) groups
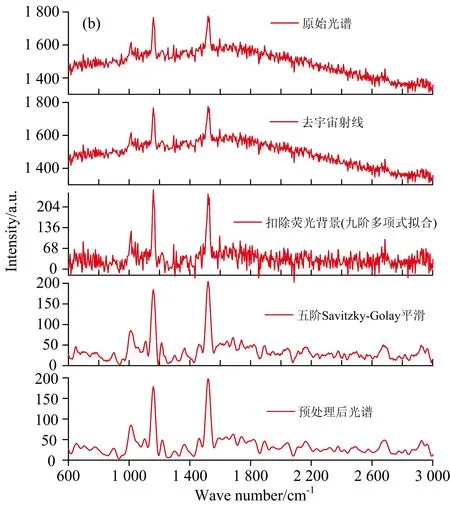
图1(b) 每一步预处理后的数据图(以健康组为例)Fig.1(b) Plot of data after each step of pre-processing (healthy)
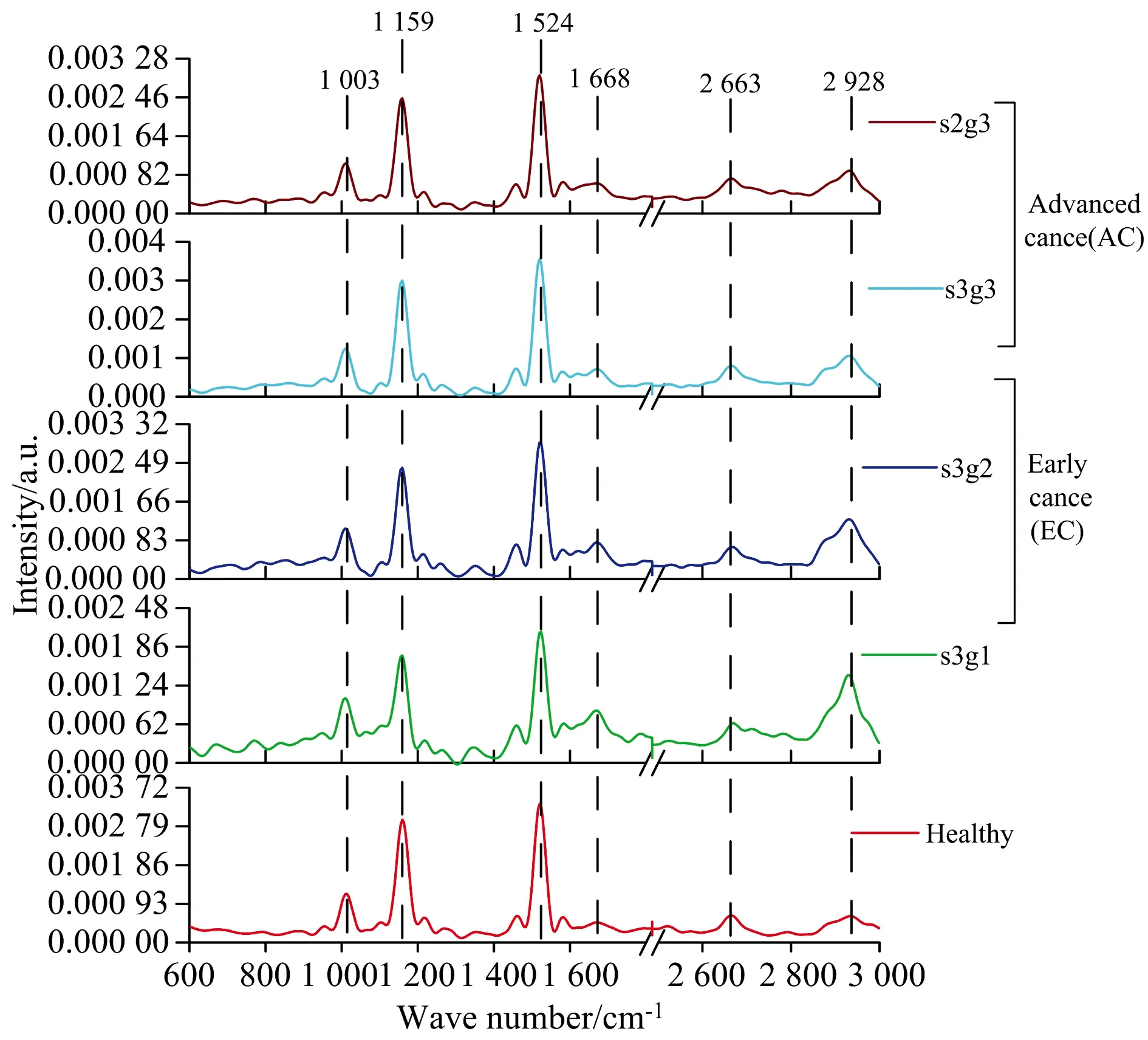
图2 健康(H)、 早期乳腺癌变(EC, s3g1, s3g2)和晚期乳腺癌变(AC, s3g3, s2g3)血清平均拉曼光谱Fig.2 Mean serum Raman spectra from Healthy (H), Early Breast Cancer (EC, s3g1, s3g2), and Advanced Cancer (AC, s3g3, s2g3) groups
2.2 PCA-LDA模型
从图2可以看出, 不同血清样品表现出较为相似的光谱特征, 如果仅从个别拉曼峰位、 峰值、 峰强等光谱参量特征分析, 无法准确反映样品所隐含的组织癌变信息。 为了获取更具代表性的分子光谱特征信息, 在有效剔除光谱背景干扰后, 采用多模数据归类分析方法, 将大量的光谱数据约化为可管理且含有丰富信息的形式, 将主成分(PCA)和线性判别分析方法(LDA)相结合, 建立PCA-LDA分析方法, 分别对实验光谱数据的低波数(600~1 800 cm-1)和高波数区域(2 800~3 000 cm-1)的特征信息进行分析计算, 并通过One-way ANOVA(p<0.01)识别前三个最具显著差异的PC值(PC1, PC2和PC3), 其主成分载荷分布及其光谱如图3所示。 PC1在光谱数据集中占总方差(52.37%)最大, 而PC2和PC3分别占总方差的18.42%和5.18%。 如图3(a)—(c)所示, 对于不同血清样品而言, PC1的正半轴上主要分布EC组, 负轴上分布H组与AC组; 而PC2正半轴上的载荷分布只有H和EC组中的s3g1血清样品, 负半轴部分则分布着AC与EC组中的s3g2血清样品载荷; PC3正半轴分布着AC组s2g3和EC组s3g1血清样品, 负半轴则分布着EC组s3g2, AC组s3g3和H组。 图3(d)所示为PC1, PC2和PC3载荷光谱, 与图2中血清特征光谱相对比, 可以发现每个主成分载荷中的正负特征均来源于血清中生化光谱特征变化。 具体而言, PC1载荷光谱主要表现为, 苯基丙氨酸(1 003 cm-1)、 β型类胡萝卜素(1 159与1 524 cm-1)和蛋白质(2 663 cm-1)成分的负向光谱贡献, 以及脂类成分(2 928 cm-1)的正向光谱贡献; PC2与PC1载荷光谱之间的载荷光谱差别主要表现为, β型类胡萝卜素(1 159, 1 524 cm-1)、 蛋白质(2 663 cm-1)和脂质(1 668, 2 928 cm-1)的负向光谱贡献; PC3的载荷光谱噪声相对较大, 但其与PC1和PC2的主要差别为正向的β型类胡萝卜素(1 524 cm-1)光谱特征。 结合图2所示血清特征光谱分析, PC1所提取的负特征主要来自H和AC组血清光谱贡献, 而其正特征主要来自EC组患者血清光谱; PC2所提取的负特征主要来自EC组(s3g2)和AC组患者血清光谱贡献, 而其正特征主要来自H组和EC(s3g1)患者血清的光谱贡献; PC3所提取的负特征则主要来自EC组(s3g2)、 AC组(s3g3)和H组血清光谱贡献, 而其正特征主要来自AC组(s2g3)和EC组(s3g1)血清光谱贡献。 这与图3(a), (b)和(c)图中所显示的分布结果一致, 表明通过主成分差异光谱信息可以来描述不同血清之间潜在的生化差异。
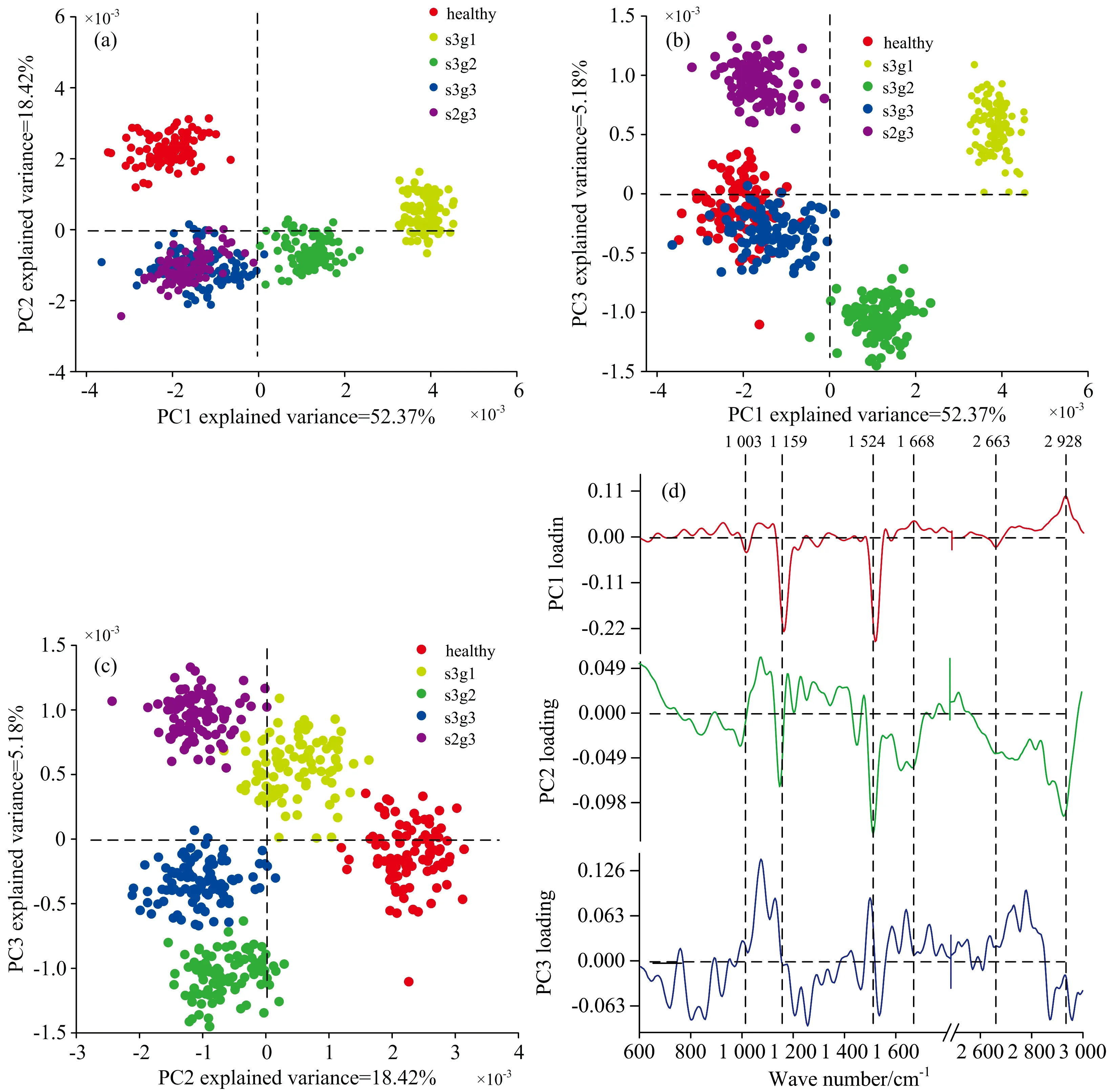
图3 健康(H)、 早期乳腺癌变(EC, s3g1, s3g2)和晚期乳腺癌变(AC, s3g3, s2g3)组血清主成分载荷分布图(a): PC1与PC2; (b): PC1与PC3; (c): PC2与PC3; (d): PC1, PC2和PC3载荷光谱Fig.3 Scatter plots of the main components of the healthy (H), early cancer (EC, s3g1, s3g2) and advanced cancer (AC, s3g3, s2g3) groups(a): PC1 versus PC2; (b): PC1 versus PC3; (c): PC2 versus PC3; (d): The PCA loading of PC1, PC2 and PC3
把所提取的最显著差异主成分光谱信息, 用于H, EC(s3g1, s3g2)和AC(s3g3, s2g3)组血清的光谱特征鉴别分类, 即, 采用PC1, PC2 和PC3作为LDA的输入变量, 构建生成PCA-LDA分类诊断模型, 如图4所示。 H, EC和AC组不同病理阶段的血清之间分离明显, 分别被第一和第二个判别函数区分。 第一判别函数的正半轴分布着EC组s3g2与AC组s3g3血清光谱, 负半轴主要分布着H, EC组s3g1和AC组s2g3血清光谱; 第二判别函数的正半轴则分布的是H组、 AC组(s2g3, s3g3)血清光谱, 负轴上则分布的是EC组(s3g1, s2g3)血清光谱。 通过LOOCV交叉验证, 如表2所示的混淆矩阵中, 绝大部分血清光谱特征被准确诊断分类, 只有s2g3和s3g1患者的血清光谱出现较小的错误分类结果, 这可能来源于两者相似的光谱参量特征。 以上结果表明, 基于PCA-LDA算法鉴别灵敏度分别为100%, 100%, 100%, 100%和99%, 特异性分别为100%, 99.75%, 100%, 100%和100%, 总体分类准确率为99%。
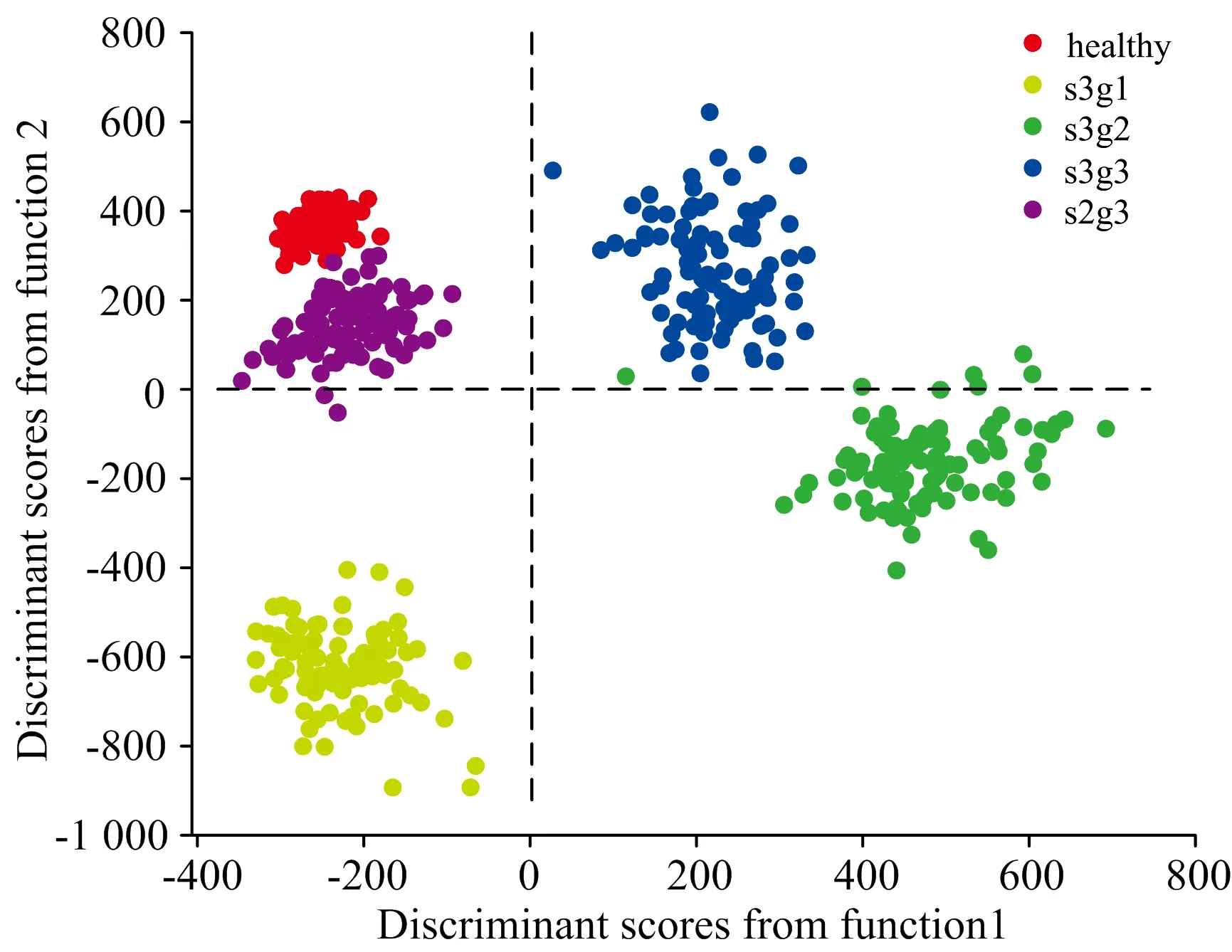
图4 健康(H)、 早期乳腺癌变(EC, s3g1, s3g2)和晚期乳腺癌变(AC, s3g3, s2g3)组血清的PCA-LDA分数散点图Fig.4 Scatter plots of the PCA-LDA scores of the serum in the healthy(H), early cancer (EC, s3g1, s3g2) and advanced cancer (AC, s3g3, s2g3) groups
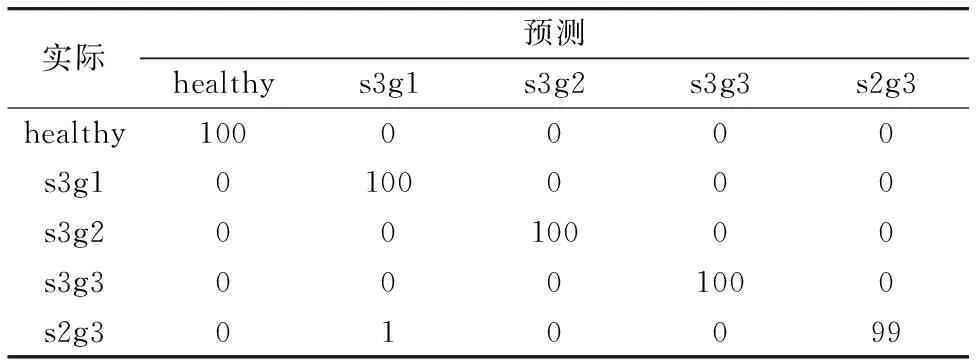
表2 PCA-LDA结合LOOCV对五种血清的拉曼光谱进行分类的结果Table 2 Results of classifying the Raman spectra of the five sera based on the PCA-LDA algorithm combined with LOOCV
2.3 PCA-SVM模型
采用PCA对光谱数据集进行降维并提取其特征信息后, 把最显著特征变量PC1和PC2输入至SVM算法, 建立PCA-SVM诊断模型, 筛选实验所获H、 EC和AC组血清光谱数据的特征信息。 在此基础上, 利用网格搜索方法结合交叉验证从训练集光谱(占数据总量的80%)中确定线性核、 多项式核与RBF的最优参数, 用以观察PCA-SVM模型训练过程中不同参数对分类精度的影响。 如图5(a)和(b)所示为不同参数对分类精度影响的三维曲面图。 在图5(a)中, RBF内核PCA-SVM 模型中参数C在2-8~210的范围内变化, 参数γ在2-10~210的范围内变化; 并且随着C和γ在这一变化范围内增大, RBF核的精度逐渐提高。 实验结果表明, 当C=0.125,γ=256时, 模型的准确率达到了最高95.625%。 当构建多项式内核PCA-SVM模型时, 同样需要对两个参数(参数C和多项式阶数d)进行优化, 如图5(b)中所示。 当C值逐渐增大、 多项式阶数d相应减小时, 光谱鉴别准确率也逐渐提高; 参数C=0.003, 多项式阶数d=1时, 模型的分类准确率最高, 可以达到95.625%。 对于线性核PCA-SVM模型, 只需要优化一个参数C, 如图5(c)显示了分类精度与参数C的关系, 当C=0.003时, 分类准确率达到最高值95.625%。
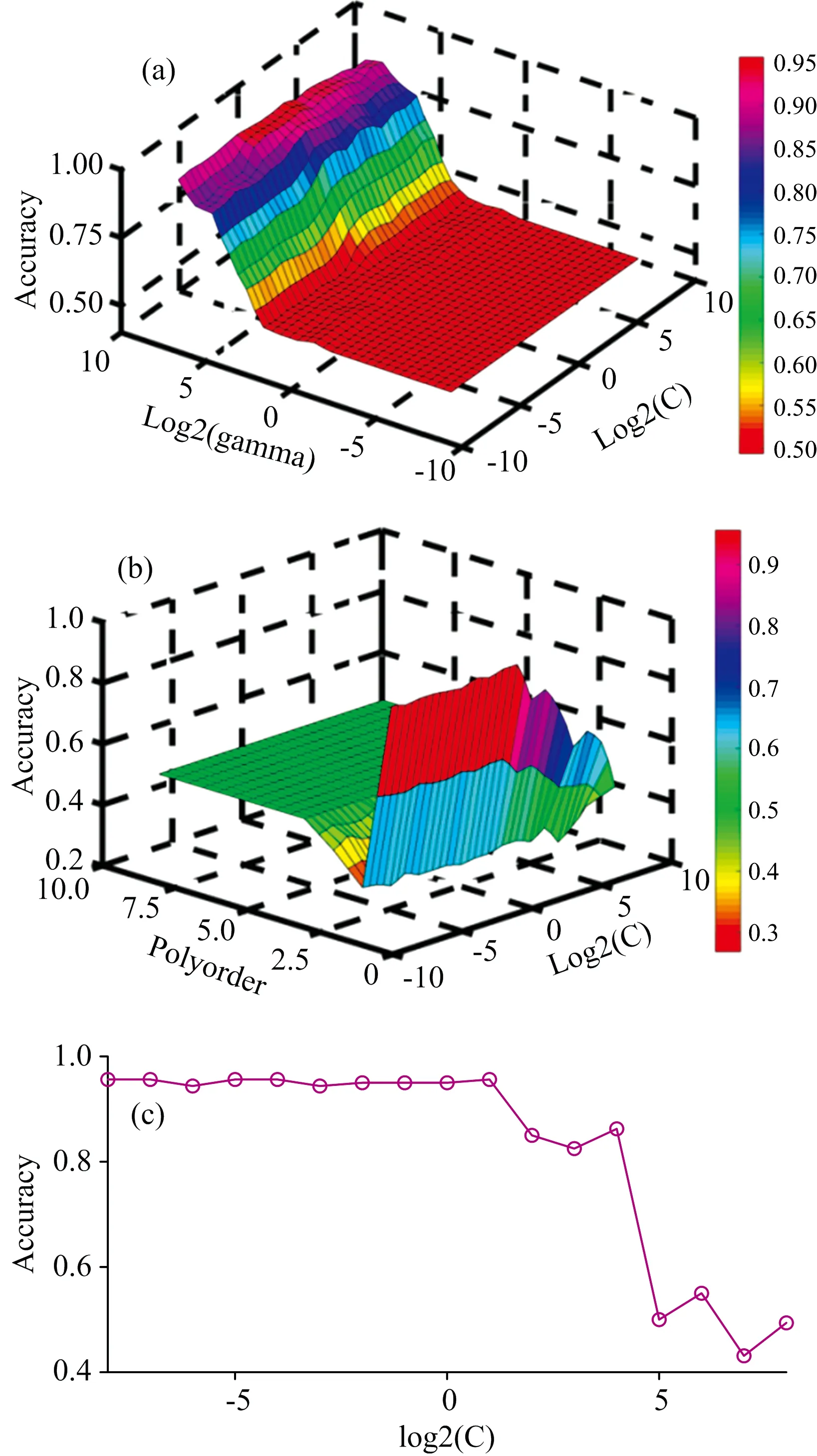
图5 (a)RBF内核PCA-SVM模型分类准确率随参数C和γ变化关系; (b)多项式内核PCA-SVM模型分类准确率随参数C和多项式阶数d的变化关系; (c)线性核函数PCA-SVM算法分类准确度与参数C的关系Fig.5 (a) 3D classification accuracy plot of parameters C and γ in RBF kernel PCA-SVM model; (b) 3D classification accuracy plot of C and polynomial order d in polynomial kernel PCA-SVM model; (c) The classification accuracy of linear kernel function PCA-SVM algorithm with parameter C
在优化SVM算法核参数后, 对测试集光谱特征进行鉴别分析, 如表3所示。 RBF核PCA-SVM模型在测试集中的分类准确率为94%, 而线性核PCA-SVM模型和多项式核PCA-SVM模型的分类准确率均为92%。 比较三种内核函数PCA-SVM模型的准确率, RBF核函数PCA-SVM模型明显高于线性核函数和多项式核。 由于RBF核函数PCA-SVM算法所具有的简单性, 以及对任意复杂度数据的建模能力, RBF核函数PCA-SVM模型被认为是SVM中更合理的选择[19]。 此外, 三种内核函数的PCA-SVM模型性能与训练集相比略有差异, 但差异在允许范围内, 说明三种SVM分类模型没有出现明显的过拟合现象。
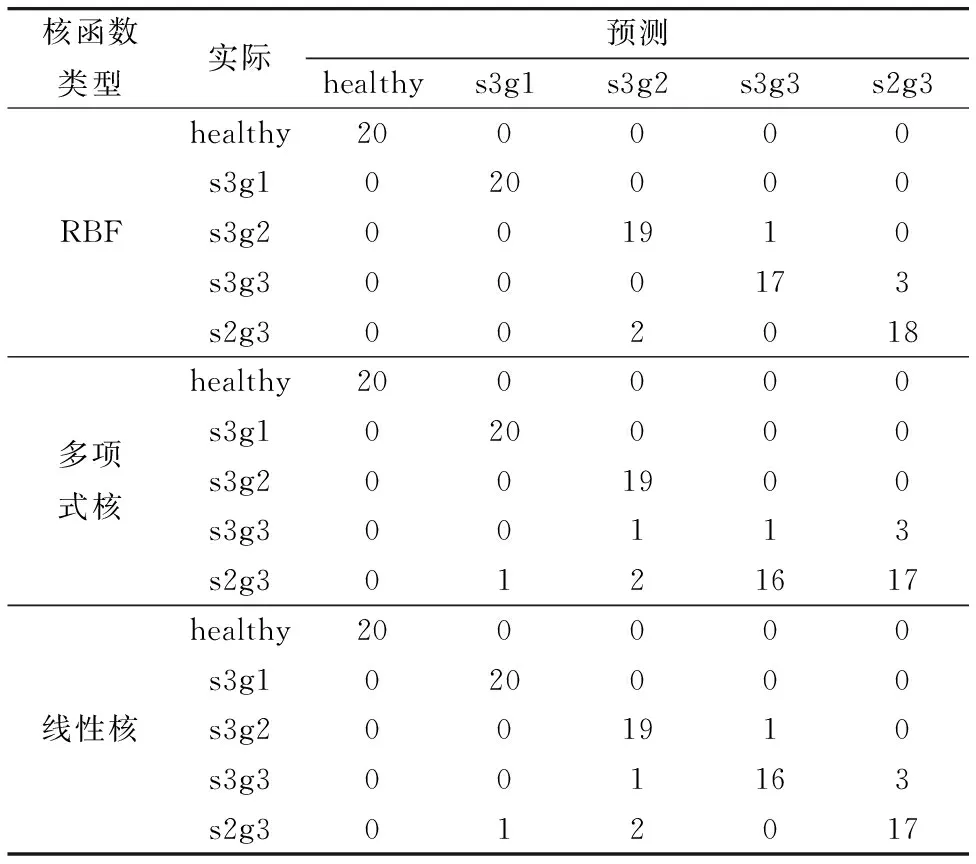
表3 基于RBF、 多项式与线性核函数的PCA-SVM诊断模型对血清测试集的光谱进行分类Table 3 The spectra of the serum test set were classified based on the PCA-SVM diagnostic models of the RBF, polynomial, and linear kernel functions, respectively
2.4 PLS-DA模型
分别讨论PCA-LDA和PCA-SVM诊断模型对于不同血清样品的鉴别分析性能后, 均值中心化所有光谱特征峰的强度矩阵, 构建PLS-DA模型, 并将该模型的性能与上述两类鉴别手段进行比较。 对H, EC和AC组光谱数据进行PLS-DA算法, 计算LVs, 构建来自不同血清样本的数据集之间的关系, 并将其显示在评分散点图中。 图6(a), (b)和(c)分别显示了数据集的前三个LVs(LV1和LV2, LV1和LV3及LV2和LV3)的散点分布。 在图6(a)和(b)中, H组与EC组的s3g1完全分布在LV1正半轴部分, AC组分布在LV1负半轴部分。 根据图6(a)和(c), LV2的零线将H组与EC组和AC组明显区分。 在图6(b)与(c)中, AC组的s2g3分布于LV3正半轴部分, EC组、 H组和AC组的s3g3均分布在LV3的负半轴部分, 分布差异不明显。 如图6(d)所示, 通过分析LV1, LV2与LV3载荷光谱, 提取不同病理阶段乳腺癌血清中的分子特征信息。 LV1载荷光谱特征主要为正向加载, 主要表现为苯基丙氨酸(1 003 cm-1)、 β型类胡萝卜素(1 159和1 524 cm-1)及蛋白质(2 663 cm-1)的光谱特征成分; 在LV2载荷光谱中, 脂质(2 928, 1 668 cm-1)为正向特征, 苯基丙氨酸(1 003 cm-1)和β型类胡萝卜素(1 159和1 524 cm-1)为负向特征; LV3载荷光谱噪声较大, 主要表现为LV1和LV2混合光谱特征, 即, β型类胡萝卜素(1 524 cm-1)正向和脂质(2 928 cm-1)负向特征。 结合图2所示特征光谱, LV1正向特征主要来自H与EC组s3g1光谱贡献, 负向特征则主要来自AC组的光谱贡献; LV2的正向特征来自H组光谱贡献, 负向特征则来自EC和AC组的光谱贡献。 以上结果再次表明, 乳腺癌不同病理阶段的苯丙氨酸、 蛋白质和脂质等成分含量差异。
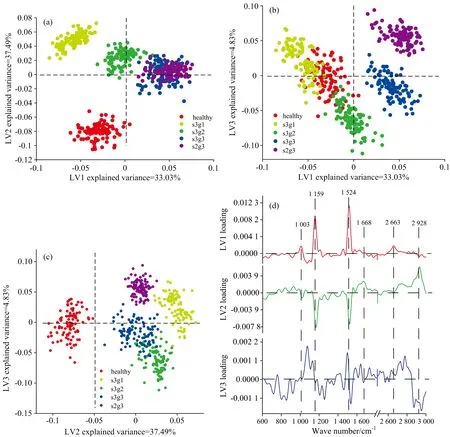
图6 健康(H)、 早期乳腺癌变(EC, s3g1, s3g2)和晚期乳腺癌变(AC, s3g3, s2g3)组血清主成分载荷分布图(a): LV1与LV2; (b): LV1与LV3; (c): LV2与LV3; (d): LV1, LV2和LV3的载荷光谱Fig.6 Scatter plots of the main components of the healthy (H), early cancer (EC, s3g1, s3g2) and advanced cancer (AC, s3g3, s2g3) groups(a): LV1 versus LV2; (b): LV1 versus LV3; (c): LV2 versus LV3; (d): The LVs loading of LV1, LV2 and LV3
表4为LOOCV混淆矩阵表, EC(s3g1, s3g2)和AC(s3g3, s2g3)存在错误分类结果, 可能与这两组血清的光谱特征差异较小有关, 也有可能是PLS-DA诊断模型的性能问题。 PLS-DA诊断模型的灵敏度分别为100%, 92%, 72%, 65%和71%, 特异性分别为99.75%, 94.25%, 97.25%, 91.75%和92%, 总体准确率为80%。 与本文中所构建的另两种诊断模型(PCA-LDA, PCA-SVM)相比较, PLS-DA模型鉴别准确率最低。 PCA-LDA和PCA-SVM分类准确率相对较高, 可见PCA对光谱数据集进行降维并提取更具代表性的特征信息, 有助于提高诊断分类结果。 对于PCA-SVM, 对光谱数据的分类精度可以达到很高, 但是当它在处理大规模数据时耗时较长且参数选择困难, 如何进一步提高该算法的计算速度和泛化性能, 还需要进一步通过积累光谱数据进行论证; 对于PLS-DA, 该算法易受类(所含数据量大小)的影响[5]。 相对而言PCA-LDA模型更适用于分类诊断。
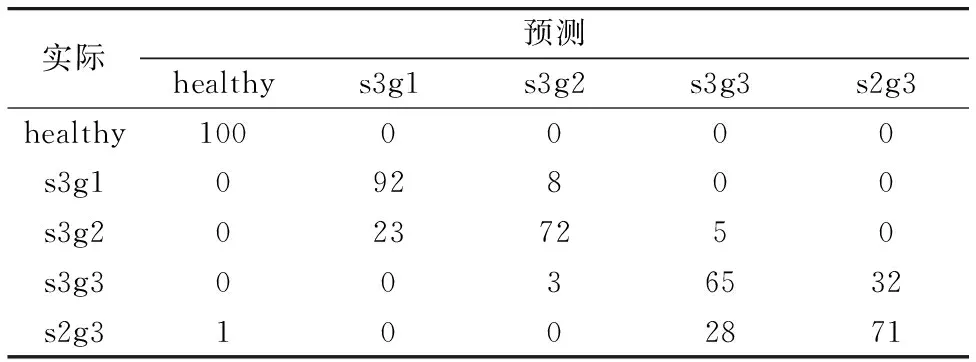
表4 基于PLS-DA算法结合LOOCV对血清的拉曼光谱进行分类的结果Table 4 Discrimination results obtained by Raman spectroscopy of serum using PLS-DA algorithms with the LOOCV method
3 结 论
采用拉曼光谱分析手段, 在研究多种乳腺病变(健康、 早期和晚期癌变)血清生化构成的基础上, 采用多模数据分析手段构造多个光谱特征分类鉴别模型(PCA-LDA, PCA-SVM和PLS-DA), 进一步挖掘光谱信息中所暗含的生物组成差异信息。 由于选用了与类胡萝卜素的π—π*电子跃迁耦合能量符的532 nm激光作为激发光源, 研究观察到了血清β型类胡萝卜素成分的共振拉曼光谱峰(1 159与1 524 cm-1), 在此基础上, 分析了乳腺癌病理演变过程中的生化构成变化; 采用多种多变量光谱分析手段, 建立光谱数据分类鉴别模型(PCA-LDA, PCA-SVM和PLS-DA), 用于进一步提取更具代表性的分子光谱特征信息。 其中, PCA-LDA模型的分类准确率达99%; PCA-SVM(三个内核函数: 线性核、 多项式核及RBF核)模型中, 当线性核函数PCA-SVM模型误差惩罚参数C为0.003时, 其分类准确率可达95.625%; 当RBF核函数PCA-SVM模型参数C和参数γ分别为0.125和256时, 模型的准确率达到了最高95.625%; 当多项式核函数PCA-SVM参数C为0.003、 多项式阶数d等于1时, 其模型分类准确率为95.625%最高; 选择此时的参数值构建模型, RBF核PCA-SVM模型在测试集中的分类准确率为94%, 而线性核PCA-SVM模型和多项式核PCA-SVM模型的分类准确率均为92%。 PLS-DA模型的分类准确率为80%。 以上结果, 不但以光谱特征的角度描述了不同病理条件下血清的物质构成信息, 更为拓展血清拉曼光谱分析技术在乳腺癌早期筛查与病理分期分级中的应用范畴, 奠定了一定实验与理论基础。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
中国粮油学报(2018年12期)2018-03-19
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
原子能科学技术(2014年3期)2014-02-28
无机化学学报(2014年1期)2014-02-28
