
发动机油中水分的近红外光谱分析
2023-02-22 06:25商芷萱全宇轩
光谱学与光谱分析 2023年2期
刘 阁, 陈 彬, 商芷萱, 全宇轩
1. 河北省危险化学品安全与控制技术重点实验室, 华北科技学院化学与环境工程学院, 河北 燕郊 065201 2. 华北科技学院机电工程学院, 河北省矿山设备安全监测重点实验室, 河北 燕郊 065201
引 言
发动机润滑油用于减少移动部件的摩擦, 并保持不同部件的清洁, 可以用作清洁剂和分散剂。 发动机在正常工作中极易在机油中产生污垢、 盐、 水、 燃烧的不完全产物等污染物, 不但影响发动机油理化性能, 而且加速了添加剂、 基础油的化学反应, 产生腐蚀性酸和水分等其他有害物质[1]。 机油在发动机中的搅动、 热和压力会随着时间的推移使水污染乳化。 因而发动机油中的水分主要以溶解或乳化状态存在, 会导致腐蚀、 添加剂消耗、 氢致开裂和微点蚀等问题[2], 因此对发动机油中的水分进行监测和量化是至关重要的。
国内外采用不同的技术对发动机油的水污染进行了大量的研究[3]。 开发了多种测定油中水分含量的方法。 由于添加剂会干扰卡尔-费歇尔法对这类油中水分的测定, 会导致高估水分含量。 核磁共振波谱用于发动机油的降解, 检测水中的油污染[4]等各种研究, 对发动机油中区分相对较低的水浓度(0%, 1%, 2%V/V)之间有显著的统计学差异[5]。
由于在红外光的作用下水的偶极矩发生变化, 氢原子具有最大的振动, 红外光谱测试油中水分可能是传统测水的有效替代方法, 得到了极大的关注。 虽然O—H健的光谱信号可能与其他功能基团的信号重叠, 但使用化学计量信号处理技术可以获得准确的结果。 特别是自布格-兰伯特-比尔提出光谱吸收定量评价的数学规律以来, 光谱分析已应用于润滑油性能检测方面[6-7], 得到了迅速的发展。 Liu等[8]开发了一种基于可见-近红外光谱的小型含水率监测系统, 采用反射光学探头, 具有实现润滑油状态实时监测的潜力。 采用偏最小二乘法(partial least squares, PLS)和反向传播神经网络(back-propagation neural network, BPNN)算法建立处理模型。 采用马尔滕斯不确定性检验、 区间偏最小二乘(iPLS)和遗传算法(genetic algorithm, GA)变量选择技术选择最显著的预测变量。 Holland等[9]采用傅里叶变换红外光谱(Fourier transform infrared spectroscopy, FTIR)研究了SAE 15W-40柴油机润滑油在不同污染水平的水分含量, 用方差分析建模和检测极限计来预测区分污染水平随时间变化的能力。 近红外光谱的信息源是分子内部原子间振动的倍频与合频, 不同物质在近红外区域有丰富的吸收光谱, 每种成分都有特定的吸收特征, 采用近红外光谱对含水润滑油光谱特征的分析也取得了一些进展[10], Holzki等[11]研发了一种用于润滑油含水率原位测定的光纤倏变场吸收传感器, 测量无包层光纤周围消光场在约2 950 nm光谱范围内的吸光度。 并采用了介质电泳技术来提高消失场区域内水滴的浓度, 检测灵敏度平均提高了1.7倍。 陈彬等[12]分析了含水汽轮机油的近红外光谱, 在1 200, 1 400和1 700 nm波长附近有明显的吸收峰存在, 其中1 400 nm附近是对应O—H键的1倍频; 结合连续投影算法(successive projections algorithm, SPA), 建立油中含水量预测的全波段偏最小二乘法(PLS)模型, 实现了油中含水量的定量分析。 并采用无信息变量消除法提取了光谱的有效波长, 选择的波长主要集中在O—H键的合频附近1 600~1 700 nm、 1倍频1 400~1 600 nm和2倍频900~1 000 nm处, 具有含水油液光谱的物理特征意义。
因而拟采用近红外光谱结合偏最小二乘回归的方法检测发动机油中水分, 在水分分析建模过程中, 基于油液近红外光谱复杂、 非线性和难以用明确数学模型表达的特点, 采用正交信号校正和几种传统的光谱预处理方法去除光谱的基线偏移、 仪器误差和测试噪声。 为了保障所建模型的鲁棒性和普适性, 根据回归系数的重要程度, 进行了关键光谱波长的选择。 将决定系数R2、 相对预测性能(relative prediction performance, RPP)、 均方根误差(root mean squared error, RMSEP)作为模型优劣评判的性能指标。 根据这些指标对所建模型进行比较分析, 获取发动机油中水分的近红外检测的可靠有效的方法, 为发动机的安全高效运行提供理论研究和技术支撑。
1 实验部分
1.1 仪器与油样
实验采用海洋光学NIRQUEST近红外光谱仪(型号512-1.9, 波长范围900~1 700 nm, InGaAs检测器), 选用SAE10W-30型发动机油(适用于外部环境温度范围为-25~30 ℃, 壳牌(中国)有限公司生产)作为原始油样, 用移液管将10 mL原始油样放入70个直径15 mm、 高度150 mm的玻璃试管中, 配置不同的含水比例(0~2.5%V/V)污染油样。 配置方法是通过使用移液管用等量的蒸馏水代替适当体积的油, 如除去10 μL的机油, 添加10 μL的蒸馏水, 从而得到0.1%的水污染样品。 分别用10~250 μL的蒸馏水得到0.1%~2.5%共34个污染级别的油样, 每个污染级别油样配置2个样品和2个0%污染的原始油样共70个样品。 每个油样采用超声震荡器进行充分搅拌2 h(50 Hz, 25 ℃), 以保证油水有效的混合。 混合均匀后的油样采用831型库仑水分仪(瑞士万通)进行水分的精确检测, 作为油样的最终含水量, 并将它们储存在一个封闭的试管中, 并直立放置在一个封闭的盒子中, 以防止光降解。
1.2 光谱测试方法
近红外光谱仪是基于比尔-朗伯定律获取油样的光谱, 光谱的波长范围为900~1 700 nm, 光学分辨率(FWHM)为3.1 nm, 波长重复性为0.1 nm。 采用光源为50 W石英卤素灯, 使用的检测器类型为InGaAs, 色散原件为25 μm光栅, 所有样品均在室温下(25 ℃)加入1 cm比色皿中进行测试。 光谱采集软件为OCEANVIEW, 扫描次数为20次。 化学计量学分析中使用的光谱为每个样品的三次重复的平均值。
然后将光谱仪采集的各个油样光谱数据采用UnscramblerX化学计量学软件进行光谱预处理和化学计量学分析, 采用MATLAB软件对光谱数据根据波长回归系数进行重要性分析和选择。 光谱的预处理采用Savitzky-Golay(15点平滑窗, 二阶多项式)、 标准正态变量变换(standard normal variable transformation, SNV)、 多元散射校正(multiplicative scatter correction, MSC)、 正交信号校正(orthogonal signal correction, OSC)以及使用(Savitzky-Golay, SG)算法的一阶或二阶导数等方法, 采用非线性迭代偏最小二乘(non-iterative PLS, NIPALS)算法构建不同油样和光谱的非线性关系, 以消除近红外光谱中不相关或正交变量。 再进行主成分分析(principal component analysis, PCA)选择并消除对回归模型产生干扰的离群油样。 并将70个油样划分为训练集和验证集, 训练模型采用完整交叉验证(留一法)进行构建。 将不同含水量的油样与相应的光谱数据作为回归模型的输入输出量, 同样采用交叉验证的最小均方根(RMSECV)确定回归模型的最佳因子数。 采用预测决定系数(R2)、 预测均方根误差(RMSEP)和RMSECV对所建立的PLS回归模型进行评价。 采用残差预测比(RPD)表示拟合优度。 RPD是一种用于确定模型预测精度的无量纲统计量, 为数据集的标准偏差与RMSECV的比率。 一般地, RPD小于1.5表示校正模型不适合预测, 1.5~2表示有可能区分高低水平, 2.0~2.5表示有可能进行近似定量预测, 在2.5~3以及3以上表示预测效果是好的和较优的模型[13]。
最后为了降低回归模型的运算量, 以及获取光谱数据中的重要波长变量, 根据所建模型的回归系数选择不相关的波长, 降低模型的维数, 重新建立重要波长变量的回归模型, 并与全波长的回归模型进行比较。
2 结果与讨论
2.1 油样光谱的特征以及异常值的处理
配置的油样经过超声震荡器充分混合处理后, 油中的水分会发生微小变化, 因而采用库仑水分仪进行精确测定含水量, 有助于在获取分析发动机油中近红外光谱数据后, 采用化学计量分析中回归模型的响应具有稳健型和可靠性。 配置了经过水分仪检测后的含水量的油样70个, 所配置的油样可分为35个级别。 其中34个0.1%~2.5%水污染级别的油样中, 每个污染级别有2个相同含水量级别的油样, 共68个油样。
2.1.1 油样光谱的特征
所有油样的原始光谱如图1(a)所示, 在波长931, 1 195~1 212和1 391~1 430 nm处出现了较强的吸收峰, 对应于O—H键伸缩振动频率引起的2倍频、 伸缩振动和扭转振动的合频、 伸缩振动1倍频光谱[8]。 在1 391, 1 413和1 430 nm处观察到三个峰值, 在1 195和1 212 nm处有两个峰值, 在931 nm处有一个小峰。 这些峰值的强度随含水量的增加而有明显的增加。
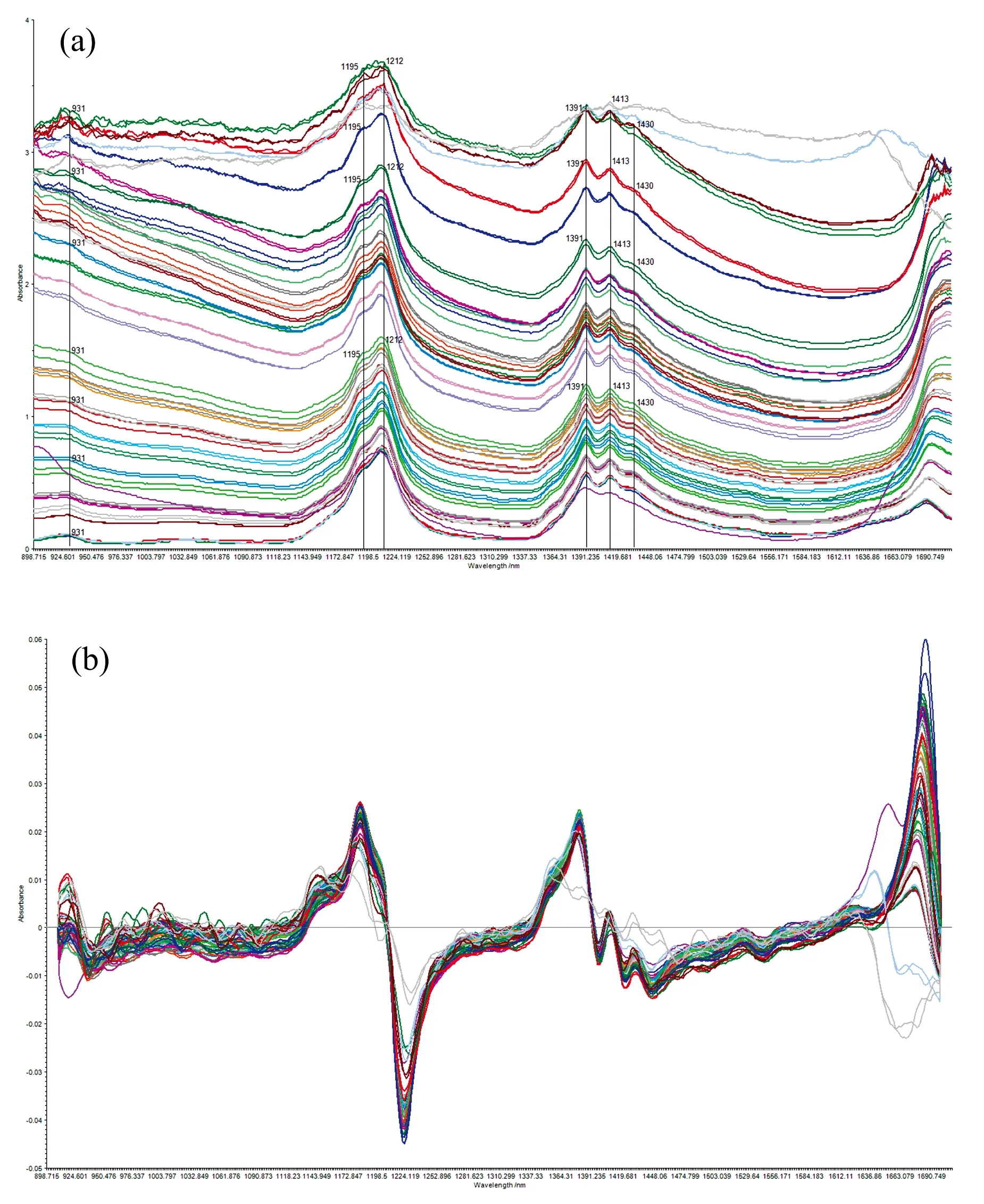
图1 不同含水量油样的原始光谱和预处理后光谱(a): 原始光谱; (b): SG一阶导数处理后的光谱Fig.1 Original and pretreated spectra of oil samples with different water contents(a): Original spectrum; (b): Spectra after SG first derivative processing
采用SG卷积求取光谱的一阶导数如图1(b)所示, 消除了原始光谱的基线漂移以及背景干扰的影响后, O—H键的伸缩振动和扭转振动的合频、 伸缩振动1倍频光谱引起峰值的导数幅值非常明显, 可见采用近红外光谱分析发动机油中水分具有较强的分辨能力。 由图1的原始光谱和预处理后光谱可见, 有两条光谱曲线的变化明显与其他光谱曲线存在差异, 可能是异常油样, 在建立回归模型前需要进行油样异常值的剔除。
2.1.2 异常值的剔除
由于油样在近红外测试过程中会存在漏光、 光源强度发生变化以及异常油样干扰等因素, 影响光谱数据的异常, 将对发动机油的含水量回归模型的预测性能、 鲁棒性与适用性产生较大地影响。 因而在建立回归模型前需要对异常光谱进行检测和剔除。
首先对所有油样进行PCA分析, 得到图2(a)所示的两个主成分分数图, 可以看到随着油中水分的增加, 油样从左到右分布在主成分PC1的两侧, 即含水量相近的油样对两个主成分的相关性相似, 低含水量的油样(<0.30%)和高含水量(>0.80%)在两个主成分的相关性方面具有较大的差异。 表明配置的油样用于预测具有有效性。 然后用置信度为97%的Hotelling’s T2统计椭圆检测油样, 发现有1.00%和2.50%两个污染级别的4个油样位于椭圆外, Hotelling’s T2统计量是通过测量在主成分方向上的变化到模型中心的距离来反应油样在主成分子空间中偏离模型的程度, 说明这两个污染级别的油样是异常值(图中以圆圈表示)。
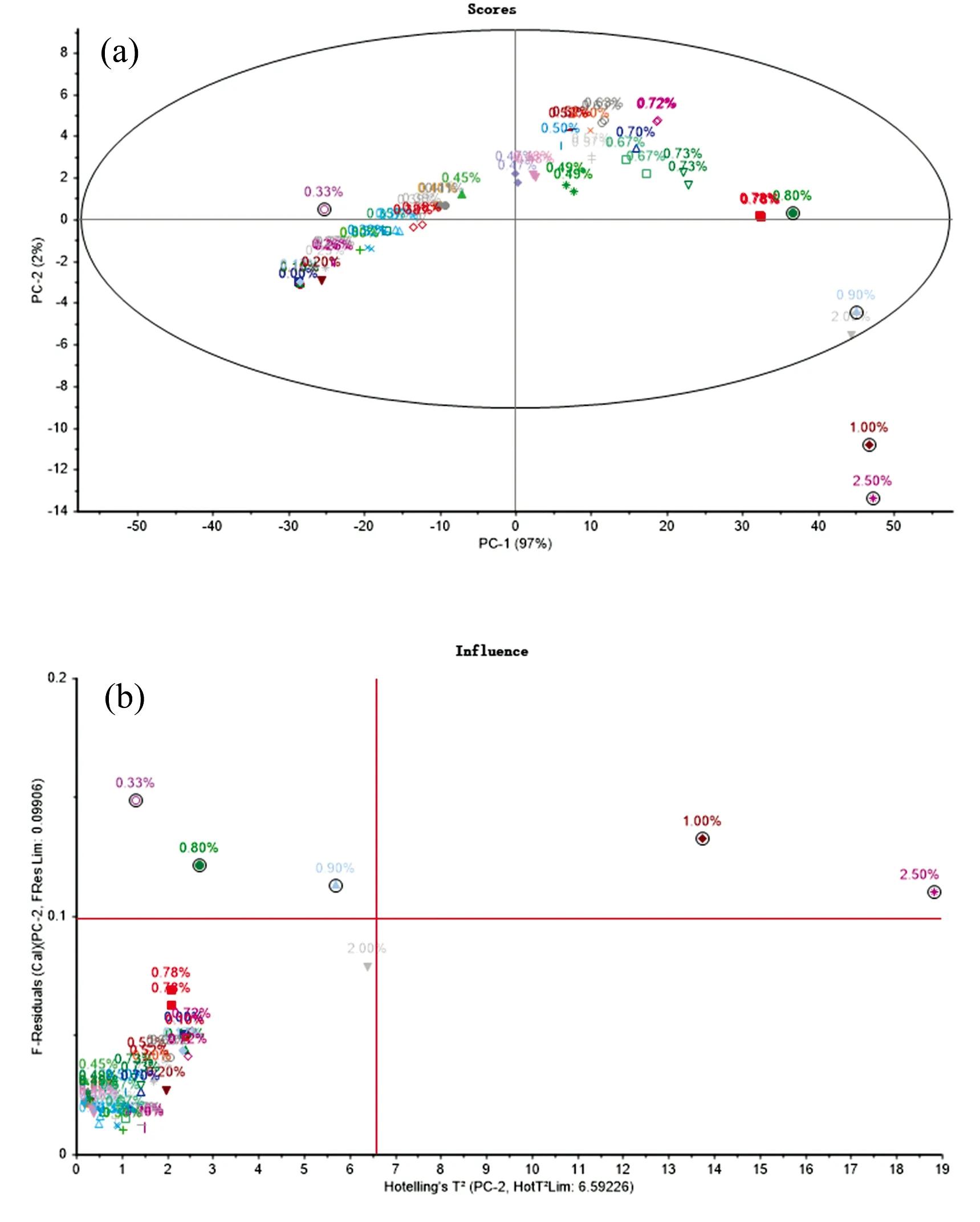
图2 原始光谱PCA分析的分数图(a)和影响图(b)Fig.2 Fraction diagram (a) and influence Diagram (b) of PCA analysis of original spectrum
在PCA分析的影响图[图2(b)]中, 表示的是油样的F残差和Hotelling’s T2统计量的控制限情况, 其中F残差(置信度为97%)表示油样在残差子空间中偏离主成分模型的程度。 可见1.00%和2.50%两个污染级别的4个油样位于两个控制限的右上方, 表示这4个油样的F残差较大、 且Hotelling’s T2统计量也较大, 是需要剔除的异常值。 另外在图2(b)F残差控制限的左上方出现了0.80%, 0.90%和0.33%三个污染级别的6个油样, 表明这三个级别的油样F残差较大, 在主成分方向上的变化到模型中心的距离较小。 在实验中基于发动机油中水分含量一般情况下较小, 因而为了所建模型的鲁棒性以及预测的准确性, 将这三个污染级别的油样不作为异常值剔除(图中以圆圈表示)。
剔除1.00%和2.50%两个污染等级的油样异常值后, 剩余的66个油样中52个油样用于构建回归模型的训练集, 剩余的14个油样作为回归模型的验证集。
2.2 构建回归模型
偏最小二乘回归(partial least squares regression, PLSR)结合了多元线性回归、 典型相关分析和主成分分析的特点, 是最常用的化学计量学方法, 在光谱建模分析中得到广泛应用。 将剔除异常值后不同含水量的油样近红外光谱数据与含水量构建 PLSR进行光谱分析。 PLSR数据矩阵X(n,m)由光谱仪器采集的油样的近红外光谱组成, 响应变量y(n, 1)是水分含量的值, 其中n为训练数据集中的样本数52个;m为近红外光谱的波长数为512个。
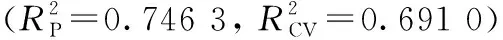
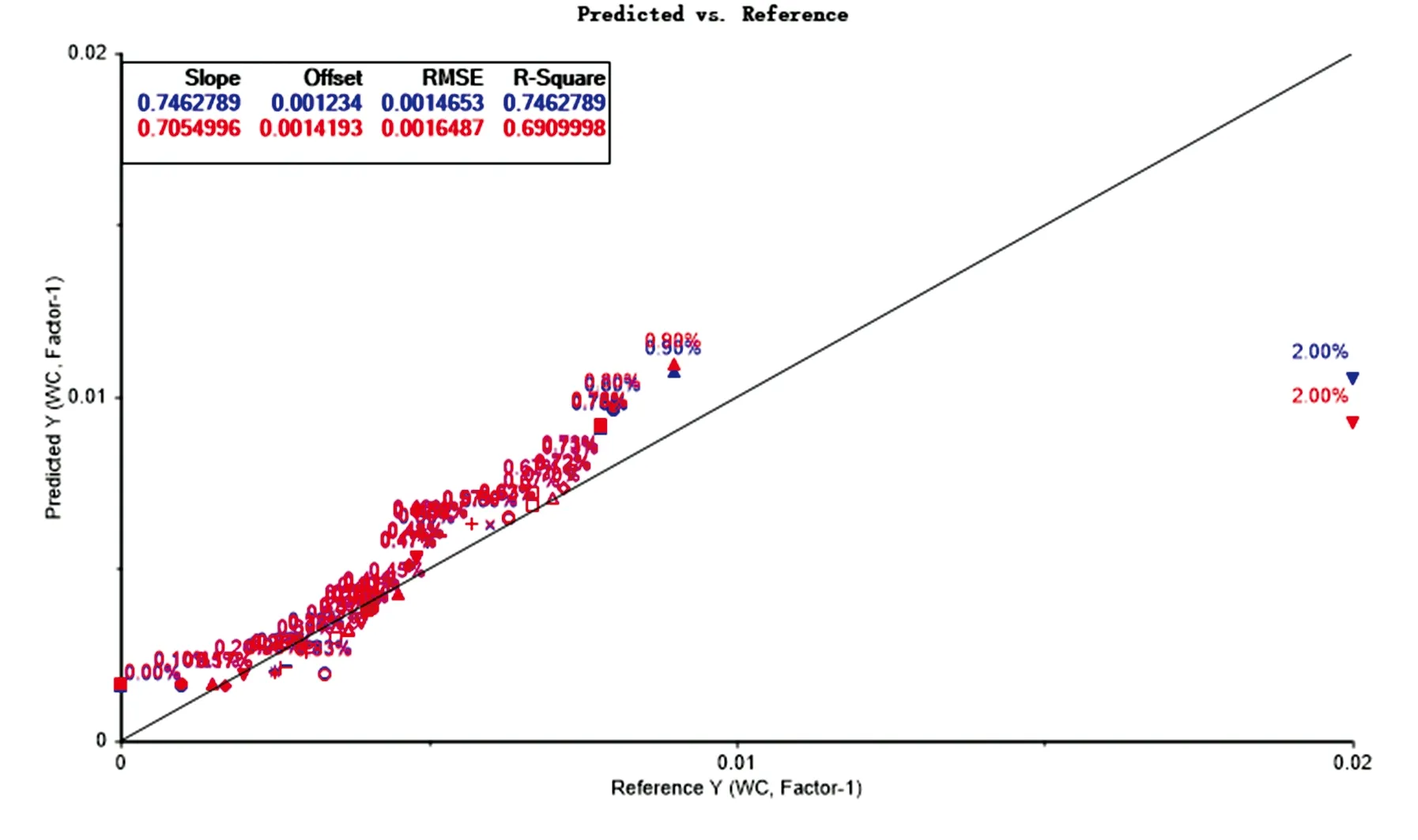
图3 原始光谱的预测值和实测值的相关图Fig.3 Correlation between predicted and measured values for the original spectrum
2.2.1 光谱的预处理
原始光谱的光散射、 噪声和基线漂移等影响因素对原始近红外光谱的叠加或相乘效应, 致使一些不相关的信息添加到构建的预测模型中, 减弱了由于样品的物理特性造成的一些差异, 因而在构建回归模型前需要采用不同的光谱预处理方法对光谱的数据进行处理, 以消除干扰信息, 提高模型的稳定性。
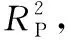

表1 光谱数据不同预处理后的PLS结果Table 1 PLS modeling results of spectral data after different pretreatments
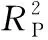

图4 OSC预处理后全光谱的预测值和实测值的相关图Fig.4 Correlation between predicted and measured values for full spectrum after OSC pretreatment
2.2.2 光谱特征波长的选择
虽然全近红外光谱经过OSC预处理后的模型预测效果较好, 但是模型中包含了大量的不相关信息, 这会增加模型变量的数量和复杂性, 同时降低PLS模型的泛化性能。 因此, 很有必要对建模中的近红外光谱波长变量进行选择, 提取特征波长, 代表原始光谱信息中有用的部分, 有效地消除冗余变量, 进一步简化模型, 从而提高PLS模型的稳健性。
根据PLS模型回归系数是回归模型光谱波长变量的权重系数, 表征了所建模型的x变量和给定y响应之间的关系。 通过将归一化的回归系数与回归模型的预测值进行复杂的数学处理, 所得的系数矩阵中大于等于1的系数对应的波长为模型影响较大的变量, 以此就可以对OSC预处理光谱进行特征波长的选择。
2.3 油样的预测
根据所建的OSC预处理后的全谱PLS模型以及特征波长选择的PLS模型, 对油样的预测集进行验证, 得到如图5所示的特征波长选择前后的预测结果比较。 可见基于近红外全谱的PLS模型以及特征波长选择后的PLS模型都能较好地对训练集以外的油样预测。 其中全谱PLS模型的预测集中14个油样的预测的最大标准差为0.000 7, 主要是0.9%和2%两个油样偏离引起的; 通过特征波长选择后的PLS模型对14个油样的预测的最大标准差为0.000 6, 也是0.9%和2%两个油样引起; 这主要是由于两个PLS模型的训练集中的油样含水量主要分布在较低水平上, 含水量较大的油样训练样本较少, 从而造成PLS模型对较高含水量的预测能力下降。 另外由图5可见, 特征波长选择后的PLS模型对预测集的预测效果较优, 每个油样的预测值更接近实测值。 说明经过特征波长选择后建立的PLS模型不仅没有降低模型的精度和预测能力, 反而由于消除了不相关变量的信息, 更具有泛化性能。
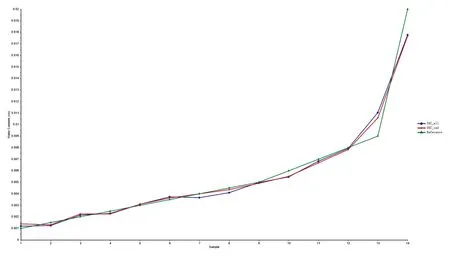
图5 特征波长选择前后的预测比较Fig.5 Comparison of predicted values before and after characteristic wavelength selection
3 结 论
猜你喜欢
特产研究(2022年6期)2023-01-17
石油炼制与化工(2022年12期)2022-12-15
西安石油大学学报(自然科学版)(2022年4期)2022-07-28
石油学报(石油加工)(2019年2期)2019-03-22
森林工程(2018年4期)2018-08-04
石油化工(2018年2期)2018-04-02
时代农机(2018年11期)2018-03-17
实用口腔医学杂志(2017年6期)2017-09-19
中国照明(2016年4期)2016-05-17
电源技术(2016年9期)2016-02-27
