
基于XDP 的高速流量采集技术研究
2023-02-23 03:30储苏红
电子设计工程 2023年4期
储苏红,刘 磊
(1.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190;2.中国科学院大学,北京 100049)
信息技术的快速发展推进了网络服务的广泛普及,越来越多的网络设备和应用程序造成流量爆发式增长,日益复杂的网络环境中存在着巨大的安全隐患。传统的安全设备如防火墙、漏洞扫描设备、网络监控程序等很难有效防范新型安全威胁[1]。网络回溯分析系统通过捕获留存网络流量可精准定位攻击的发生点,对网络威胁进行全方位、深层次、可反复回溯的检测分析[2-3],从而更容易检测出潜在的攻击行为。
在高速网络下实现高性能网络流量捕获是网络回溯分析系统的基本功能。针对已有的基于DPDK的网络回溯分析系统,已经实现了较高性能的数据包捕获功能,然而在实际使用中经常遇到DPDK 不支持原生网卡的问题,需要替换成支持DPDK 的网卡或者加载DPDK 专用驱动程序才能使用。为了解决上述问题,需要研究新的高性能数据包捕获技术应用于网络回溯分析系统,使其能够达到现有的性能指标并解决硬件依赖性问题。
该文对XDP 的原理和数据包处理机制进行了深入分析和研究,实现了基于Linux 平台的数据包采集功能。利用Spirent 网络测试仪和DELL 服务器分别对基于XDP 和DPDK 的网络流量采集性能进行测试。实验结果表明,XDP 在多队列下与DPDK性能相似,并能与现有内核网络协议栈更好地配合。相比于DPDK,XDP 具有独立于硬件设备,支持任何带有Linux 驱动程序的网卡,无需满足特定网卡供应商的要求。
1 高性能报文采集技术
传统Linux 架构下,网卡队列接收到数据包后产生硬件中断,从而触发CPU 中断,应用程序处理网络报文,整个过程中不断地进行中断处理、上下文切换,带来巨大的CPU 开销,严重降低了网络应用程序的性能[4]。为了实现在高速网络下能够捕获数据包,目前研究人员已经设计出一些高性能数据包捕获架构。
1.1 Libpcap技术
Libpcap(Library of Packet Capture)是由伯克利实验室开发的可用于Unix、类Unix(Linux、BSD 等)和Windows 等多种操作系统的开源C/C++函数库,现已成为网络数据包捕获的标准接口[5],很多常用的数据包捕获应用程序如Wireshark、Tcpdump、Snort 等都是基于Libpcap 实现的。
Libpcap 捕获数据包流程:在网卡为混杂模式下,Libpcap 首先复制数据包进行前置处理。然后将复制的数据包传送到BPF(Berkeley Packet Filter)过滤器,根据设置的规则对流量进行筛选,只将用户所需要的数据包继续传输到内核缓冲区,从而有效减少对无效数据包的处理开销。最后,应用程序通过系统调用读取内核缓冲区的数据包,以进行后续处理。
如上所述,Libpcap 从网卡捕获数据包传送到用户空间过程中同样需要经过内核协议栈进行处理,与传统Linux 构架下的数据包捕获方式类似。同样存在需要多次拷贝数据包和频繁进行上下文切换的问题,其性能并没有得到太多优化。
1.2 PF_RING技术
PF_RING 是由Luca Deri 为优化流量捕获过程中存在的多次数据拷贝和频繁触发硬件中断等问题而研发的高速数据包捕获库。PF_RING 通过共享内存避免数据包从内核空间到用户空间的拷贝,并结合设备轮询(NAPI)技术,减少了CPU 中断次数,极大地提高了数据包传输速率[6]。
PR_RING实现机制:首先在内核中添加PF_RING协议簇和具有环形缓冲区的socket,提供两个标准接口供网卡向缓冲区写入数据包和应用程序,并从中读取数据包;网卡接收到数据包后,PF_RING 将数据包拷贝到环形缓冲区,由于这块环形缓冲区内存由内核和用户空间共享,应用程序就可直接读取数据包,简化了拷贝过程[7]。但是通过PF_RING 的数据包捕获过程中并没有实现零拷贝。另外,在一个时间点只有一个应用能够分发数据包,无法满足多队列的实现需求。
1.3 Netmap技术
Netmap 是由Luigi Rizzo 等人基于零复制技术开发实现的高性能I/O 框架,不需要依赖特定硬件或修改应用程序就能以较高性能实现用户应用与网卡间的数据包传递,在900 MHz 单核CPU 下就能实现10 G 网卡下线速数据包转发[8]。
在共享内存中,Netmap 使用两对环形队列进行数据传输。网卡接收到数据包之后直接将其放入Netmap 环形队列,应用程序检测到已有数据包传入就通过调用Netmap API 直接获取环形队列里的数据,这个过程实现了零拷贝从而能有效提高数据传输性能[9]。另外,Netmap 也有较好的安全性保证。虽然使用共享内存方式实现了数据传输,但是内核和网卡寄存器的关键内存区域没有暴露给应用程序,因此不会因为运行应用程序而导致内核崩溃。然而Netmap 只能使用中断通知机制,并没有完全解决性能瓶颈。
1.4 DPDK技术
DPDK 是Intel 公司开发的用于多核CPU 的数据包处理套件,可提供丰富的数据包快速处理开发函数库和网卡驱动库,已成为目前主流的高性能网络报文处理架构[10]。DPDK 使用内核旁路技术、用户空间程序完全控制网络硬件,大大减少了由于上下文切换、中断等事件引起的内核开销,具有较高的数据包捕获效率。
DPDK 架构图如图1 所示。

图1 DPDK架构图
缓冲区管理:负责创建、释放报文缓存;
内存池管理:负责分配管理内存中的对象池,能够快速分配、释放缓冲区;
环管理:采用生产者消费者模式的无锁环形队列进行资源的分配与释放,也能实现核间或处理单元间的通信;
轮询驱动模块:实现在轮询方式下进行网络报文收发,通过UIO(Userspace I/O)驱动技术拦截中断,避免因中断产生的响应时延,极大提高了网卡收发性能;
环境抽象层:提供一个通用接口获得对底层资源的访问,主要负责系统初始化、PCI 设备初始化、内存资源以及驱动程序初始化工作[11]。
DPDK 支持run-to-complete 报文处理模型,应用程序执行之前需先分配好所有的资源,并作为执行单元运行在逻辑核上。数据面处理程序执行时,结合自身需求调用相应的DPDK API,然后运行网卡驱动程序,将数据包直接转发到用户空间,这个过程中实现了内核旁路。应用程序通过轮询报文到达标志位,监测是否有新的报文需要处理,通过轮询的方式极大地提高了报文处理能力。另外,DPDK 可以通过HUGEPAGE 和CPU Affinity 机制来提高网络流量的处理性能。
DPDK 在提供了极高的数据包处理性能的同时,也存在一定的缺陷。其采用的内核旁路技术完全绕开操作系统,因此操作系统提供的较为成熟的配置、部署和管理工具都将停止运行,应用程序隔离和安全机制也将被绕开,带来了重大的管理、维护和完全缺陷。另外,在实际使用中,网卡需要加载专门的DPDK 驱动程序才能与硬件交互,目前DPDK 只支持部分网卡,并非所有的网卡都能使用DPDK 实现数据包捕获。
2 基于XDP的报文采集技术
XDP 驱动挂钩:位于网卡驱动程序中,是XDP 程序的主要入口点,在网卡接收到数据包时执行;
eBPF(extended BPF)虚拟机:eBPF 程序的执行环境,编译并执行XDP 程序的字节码;
BPF 映射:键/值存储方式,用于与系统其余部分进行通信;
BPF 程序校验器:加载程序之前对其进行安全检查,判断其是否符合规范,确保程序能安全执行不会引发内核崩溃等安全问题。
XDP 处于网络驱动程序内部的RX 路径上,如图2 所示,当网卡收到数据包时,甚至在内核为数据包分配sk_buff 和解析数据包之前,XDP 程序就可对数据包进行处理[13]。用户空间将数据包处理规则写入BPF 映射中,XDP 程序读取执行判决,对数据包进行相应的操作,如直接丢弃数据包(XDP_DROP),将数据包从接收端口转发(XDP_TX),通过零拷贝套接字AF_XDP[14-15]将它们重定向到另一个接口或用户空间(XDP_REDIRECT),或者允许数据包进入网络堆栈进行进一步处理(XDP_PASS)。

图2 XDP架构图[13]
为了提高数据包捕获能力,可采用Linux 4.18中新引入的套接字AF_XDP,以零拷贝的方式将数据包直接从内核空间重定向到用户空间。如图3所示,每个AF_XDP 套接字涉及两个队列:RX_RING和TX_RING。RX_RING 位于AF_XDP 套接字接收端,用于接收数据包;TX_RING 位于AF_XDP 发送端,用于发送数据包。数据包存储区域UMEM 也有两个队列:FILL_RING 和COMPLETION_RING。在接收数据包过程中,应用程序首先在FILL_RING 中填充接收数据包的地址,通知内核该区域用以存储数据包;XDP 程序将接收到的数据包放入该地址后,内核在RX_RING 中填入对应的文件描述符;应用程序通过检查RX_RING 就能判断是否接收到了数据包。在发送数据包过程中,应用程序在TX_RING 中填充指向要发送的数据包的文件描述符,通知内核该数据包需要被发送。数据包发送结束后,内核在COMPLETION_RING 中填入已发送数据包的地址。

图3 AF_XDP UMEM和RING结构图
XDP 程序可以通过图4 所示的三种模式附加到网络接口上。若可编程网卡硬件支持,则XDP 程序可使用Offloaded XDP 模式直接挂载在可编程网卡上,不需使用主机CPU,以极低的成本直接在网卡上处理数据包;若网卡驱动程序支持,则XDP 程序可使用Native XDP 模式运行在网络驱动的早期接收路径;对于网卡和驱动程序都不支持XDP 的环境,XDP程序可使用Generic XDP 模式运行在网络协议栈中,将XDP 程序作为常规网络路径的一部分加载到内核中,不需要对硬件和驱动程序进行修改[16]。
王国维:“其(罗)说是也,始以地名为国号,继以为有天下之号,其后确不常厥居,而王都所在,仍称天邑商,讫于失天下而不改。……且《周书·多士》云:‘肆予敢求尔于天邑商。’是帝辛、武庚之居,犹称商也。”

图4 XDP程序附加位置示意图
3 流量采集模块设计
网络回溯分析系统是为了应对日益严峻的网络安全形势而设计的能够对数据包进行采集留存和分析检索的系统。通过采集存储网络链路流量,可对网络数据进行深度检测和回溯分析,是对网络进行监控和管理的有效手段。网络回溯分析系统结构如图5 所示,主要由流量采集、流量分析、流量存储和流量展现四个模块组成。

图5 网络回溯分析系统结构图
流量采集模块:是整个网络回溯分析系统的基础,负责捕获传入网卡的流量。
流量分析模块:对采集的流量进行分析,确定当前流量是否存在威胁;
流量存储模块:负责存储网络数据包,以供后续取证分析;
流量展现模块:展现数据采集和分析的结果,并能根据用户需求展现回溯分析结果。
以上四个模块相辅相成共同组成网络回溯分析系统,该文的研究内容主要针对流量采集模块,基于XDP 技术实现高速网络下的流量采集,主要包括以下几个步骤[17-18]:
1)创建AF_XDP 套接字:通过socket()系统调用创建AF_XDP 套接字,并生成指向数据包存储区的文件描述符;
2)映射队列:将与AF_XDP 套接字和UMEM 相关 的RX_RING、TX_RING、FILL_RING 和COMPLE TION_RING 通过_RING setsockopt()系统调用进行配置和创建,使用mmap()进行映射;
3)绑定AF_XDP 套接字到接口:在传输流量之前必须使用bind()调用将AF_XDP 套接字绑定到一个设备和该设备指定的队列上;
4)转发数据包到XDP 套接字:首先创建BPF 映射来关联队列和AF_XDP 套接字,然后汇编BPF 程序,最后将BPF 程序附加到目标接口。应用程序通过bpf()系统调用将AF_XDP 套接字放到BPF 进行映射,XDP 程序根据映射索引将报文重定向到该套接字。在该过程中会校验套接字是否确实绑定到该设备和指定队列上,如果没有成功绑定设备则会丢弃报文;
5)接收数据包:通过FILL_RING 和RX_RING 转移指向内存缓冲区地址的文件描述符来实现数据包的接收;
6)停止数据包传输:在XDP 程序执行到最后需要停止数据包传输时,使用close()系统调用停止数据流并释放XDP 套接字,使用munmap()取消环形队列的映射。
4 实验分析
在该文范围内很难对所有高性能报文采集技术进行实验测试,DPDK 是可获得的现有的高性能的主流解决方案,并且现有网络回溯分析系统基于DPDK 技术来实现,因此该文重点通过实验对比XDP 和DPDK 对原始数据包的接收性能。
实验环境由Spirent 网络测试仪SPT-C50 和Dell PowerEdge R740xd 服务器构成,以Spirent 网络测试仪作为流量产生器,服务器作为被测设备。服务器使用Intel(R) Xeon(R) Silver 4216 CPU @ 2.10 GHz 处理器,内存大小为128 GB,操作系统版本为CentOS Linux release 8.3.2011,系统内核为4.18.0-193.el8.x86_64。被测设备的网卡端口直接连接到流量产生器端口,在被测仪器端分别执行XDP 和DPDK 程序,统计零丢包下的流量吞吐率。该实验分别使用1、2、4、8 个接收队列对Intel X710、Intel X520、NetXtreme II BCM57810 和ConnectX-3Pro 等10 G 网卡进行不同数据包大小下的收包性能测试。
图6 为XDP 和DPDK 在Intel X710 网卡下的测试结果,由图6 可明显看出XDP 在一个队列下收包速率最多只能达到5.89 Mpps,而DPDK 在一个队列下就可以达到64 B帧大小下的线速为14.88 Mpps,在单队列下DPDK 的性能明显高于XDP。但增加队列数可以提高XDP 的性能,基本上使用四个队列就能够达到DPDK 的性能。

图6 Intel X710网卡测试结果
图7 为XDP 和DPDK 在Intel X520 网卡下的测试结果,与Intel X710 网卡测试结果类似,单队列下XDP 性能明显低于DPDK,使用多队列能提高XDP收包性能。不过在Intel X520 网卡下,XDP 使用四个队列达到最高性能时仍没有到达64 B 帧大小的线速,DPDK 使用单队列就能够达到,说明XDP 性能略低于DPDK。
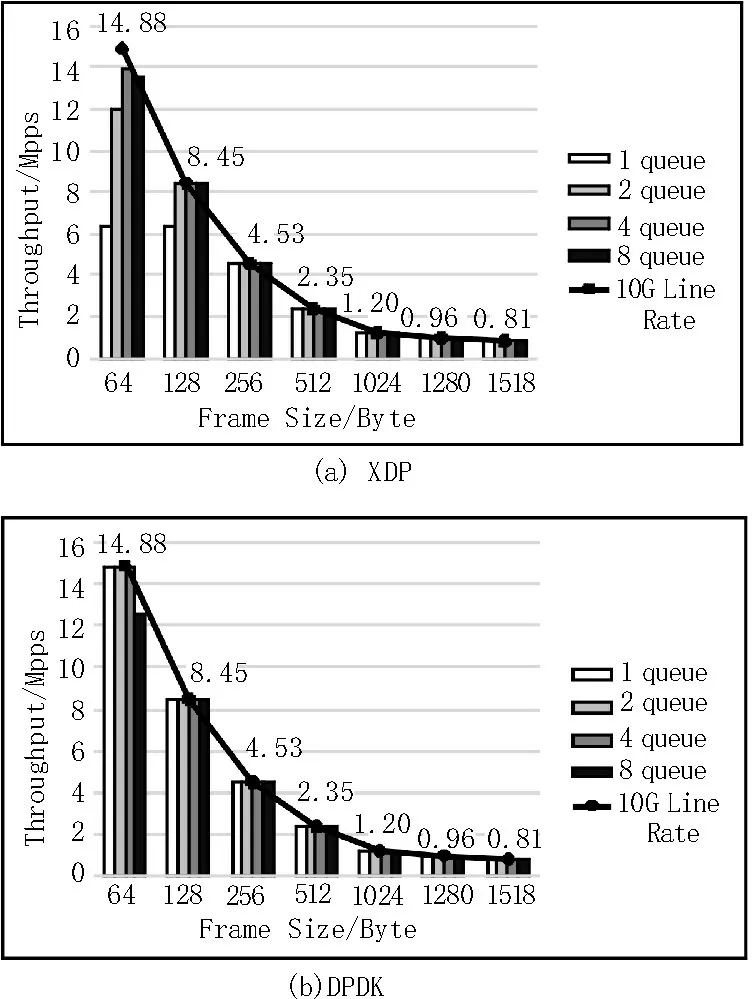
图7 Intel X520网卡测试结果
图8 为XDP 和DPDK 在NetXtreme II BCM57810网卡下的测试结果,相比于Intel X710 和Intel X520网 卡,XDP 和DPDK 使 用NetXtreme II BCM57810 网卡的性能都显著降低,说明XDP 和DPDK 的收包性能针对不同网卡具有一定的差异性。此时NetXtreme II BCM57810 网卡使用的驱动程序bnx2x 不支持XDP,XDP 程序只能使用Generic XDP 模式运行,数据包需要经过内核协议栈进行处理,因此导致性能降低。

图8 BCM57810网卡测试结果
图9 为XDP 和DPDK 在ConnectX-3Pro 网卡下的测试结果,DPDK 不支持ConnectX-3Pro 网卡,故无法实现收包,XDP 可使用Generic XDP 模式不需修改硬件和原生驱动程序就可以实现收包,在满足零丢包条件下最多能达到线速为4.46 Mpps。
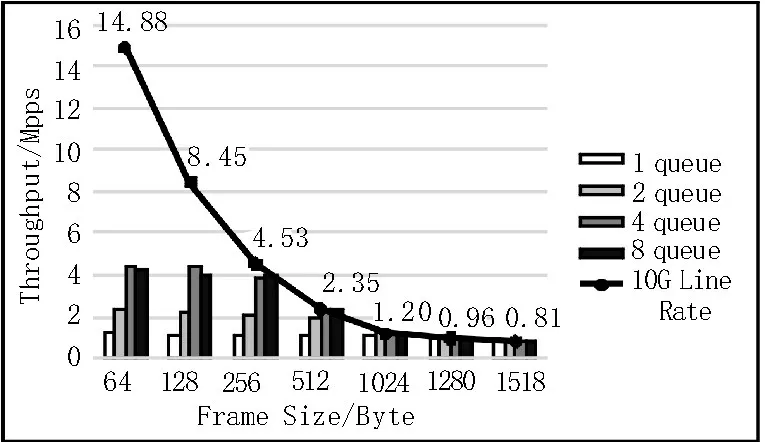
图9 ConnectX-3Pro网卡测试结果
根据实验数据可分析出:
1)尽管在单队列时XDP收包性能明显低于DPDK,但通过增加队列数来提高性能,在多队列下XDP 与DPDK 收包性能相差不大;
2)XDP 和DPDK 的收包性能针对不同网卡具有一定的差异性;
3)对于DPDK 不支持的网卡硬件,XDP 也能完成收包功能,不需依赖专门的网卡硬件。
5 结束语
该文针对XDP 技术原理、数据包处理流程进行了详细的分析和研究。XDP 将高性能数据包处理与操作系统内核进行集成,通过提供安全的执行环境并受到内核社区的支持,显著降低了应用程序处理数据包的成本。针对XDP 技术和网络回溯分析系统目前正在使用的DPDK 技术进行实验对比,分析得出,虽然XDP 在单队列下数据包捕获性能低于DPDK,但是在多队列下XDP 能达到DPDK 的性能;另外XDP 有三种模式供用户选择,基本能适应所有带有Linux 驱动程序的网卡而不需修改原生驱动程序,有效减少了对网卡的依赖性。将XDP 技术应用于网络回溯分析系统能够在保证其性能的基础下,增加系统的兼容性和安全性,具有重要意义。
猜你喜欢
计算机系统应用(2022年5期)2022-06-27
今日农业(2021年9期)2021-07-28
网络安全和信息化(2020年3期)2020-04-20
电脑报(2019年10期)2019-09-10
网络安全和信息化(2019年1期)2019-02-15
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
电子制作(2018年17期)2018-09-28
电脑爱好者(2015年15期)2015-09-10
网络与信息(2009年7期)2009-07-11
