
基于对比学习的弱监督时序动作定位
2023-02-25 05:17侯永宏李岳阳郭子慧
天津大学学报(自然科学与工程技术版) 2023年1期
侯永宏,李岳阳,郭子慧
基于对比学习的弱监督时序动作定位
侯永宏,李岳阳,郭子慧
(天津大学电气自动化与信息工程学院,天津 300072)
弱监督时序动作定位旨在于仅在视频级标签的监督下,定位未剪辑视频中的动作时间边界,并识别定位结果所对应的动作类别.由于缺少动作在时间上的标注信息,目前大多数弱监督时序动作定位方法通过聚合具有高激活值的显著动作特征来优化分类损失函数的方式训练动作定位网络,这会导致网络过度关注动作片段的关键部分,忽视了视频中部分难以分类的模糊动作片段,难以保证定位结果的完整性.基于上述问题,提出了一种具有多分支注意力机制的网络框架,分别对视频中的显著动作片段、显著背景片段和难以分类的模糊动作片段进行建模.同时,基于上述的多分支注意力权重,构建了3个相应的时域类激活序列优化动作分类损失函数,使网络能够分离视频中的显著动作特征与显著背景特征.为了使网络捕获更加完整的动作片段,基于对比学习设计了模糊动作对比损失函数,在显著特征的引导下细化视频中的模糊动作特征,使网络能够感知精确的动作时间边界,以避免完整动作的截断现象发生.所提方法在2个主流的弱监督时序动作定位数据集THUMOS-14和ActivityNet-1.2上的定位性能均超过了之前的方法.具体而言,所提方法的定位性能相比于之前的方法在上述两个数据集中分别提升了1.6%和1.3%,充分体现了所提方法的有效性.
弱监督学习;时序动作定位;对比学习;类激活序列
近年来,随着深度学习的发展,视频理解领域取得了极其显著的突破.时序动作定位作为视频理解领域中的研究热点,在多种现实场景下有很大的应用潜力,例如视频监控、异常检测、视频检索等.其主要任务是从持续时间较长的未剪辑视频中精确定位感兴趣动作发生的开始和结束时间,并对该动作正确分类.目前,时序动作定位大多采用全监督方式训练,关键是要收集足量的逐帧标注的未剪辑视频.然而在现实世界中,逐帧标注海量的视频数据需要消耗大量的人力物力.此外由于动作的抽象性,人为标注动作的时间标签容易引入人的主观因素影响,导致标注信息错误.由此衍生出了基于弱监督学习的时序动作定位,在网络训练过程中仅使用视频级的动作类别标签作为监督信息.与精确的动作时间标签相比,动作类别标签更容易获取,并且能有效避免人工标注引入的偏差.
现有的弱监督时序动作定位方法可分为两种:一种受语义分割[1]的启发,将弱监督时序动作定位映射为动作分类问题,并引入动作-背景分离机制[2]构建视频级特征;另一种将时序动作定位表述为多示例学习(MIL)任务[3],通过分类器获取时域类激活序列(T-CAS)[4]进而描述动作在时间上的概率分布.
以上两种方法均通过学习有效的分类损失函数解决未剪辑视频中的定位问题,但与大多数弱监督学习方法类似,由于缺少时间标签,网络难以建模完整的动作发生过程,会过于关注动作中最显著的部分,而忽略一些特征不明显的次要区域.此外,由于视频没有经过人为剪辑,一个完整的动作中经常会存在镜头转换、动作慢放等模糊帧,它们与动作呈语义相关,属于该动作的一部分,但运动特征并不明显,导致这些时间位置上的激活值较低,与同样激活值较低的显著背景片段难以进行区分,会被错误地检测为背景帧.因此,找到并细化视频中的模糊动作特征,使网络捕获更完整的动作片段,对于提高弱监督时序动作定位性能有着重要意义.
针对以上问题,本文借助对比学习[5]的思想,设计动作定位网络,细化视频特征并提高动作定位精度.对比学习能够通过构建正样本对和负样本对训练一个表示学习框架,使正样本对在特征空间中的距离比较接近,负样本对在特征空间中的距离比较远.基于此,本文合理假设,如果能够准确找到视频中的模糊动作片段并与显著动作片段构建正样本对,与显著背景片段构建负样本对,即可通过对比学习的方法获取动作-背景区分性更强的视频特征.为此,本文设计了多分支注意力网络,其中一个支路生成原始时域类激活序列,另外一个支路为多分支注意力模型,分别生成显著动作注意力、显著背景注意力和模糊动作注意力.同时基于上述注意力权重构建3个相应的时域类激活序列,并通过多示例学习,使网络获得分离动作特征和背景特征的能力.此外,本文设计了模糊动作对比损失函数,构建相应的正负样本对,进一步细化模糊动作特征,保证定位动作片段的完整性.
以对比学习为基础,本文设计实验在3个弱监督时序动作定位数据集上验证所提方法的有效性.结果显示,所提方法能解决视频中模糊动作的误分类问题,从而定位更加完整的动作片段.特别地,在THUMOS-14和ActivityNet-1.2数据集上分别取得了1.6%和1.3%的性能提升,超过了之前的方法.
1 弱监督时序动作定位方法
本节首先介绍弱监督时序动作定位的定义,然后介绍多分支注意力网络,最后介绍模糊动作对比损失函数和训练过程.网络结构如图1所示.
1.1 问题定义
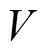
1.2 视频特征提取
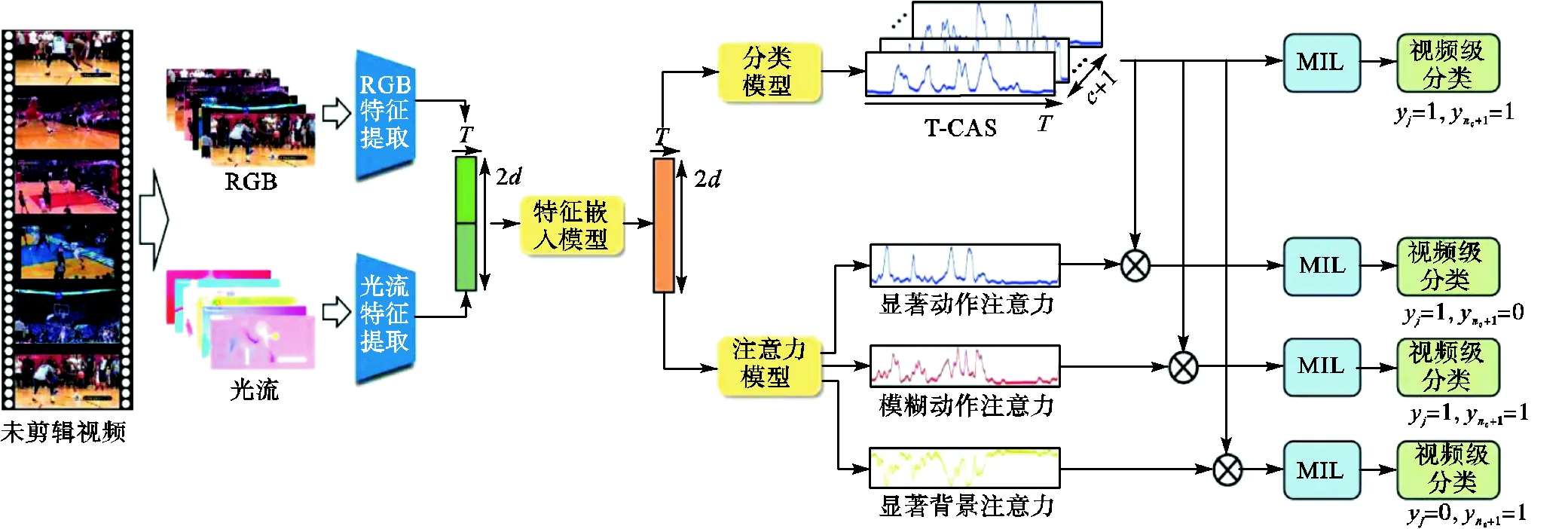
图1 多分支注意力网络结构
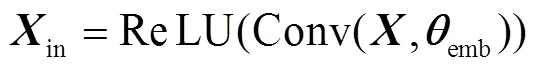
1.3 多分支注意力网络
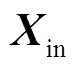
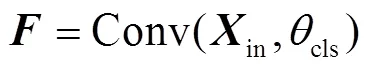
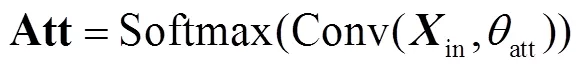
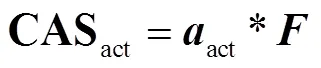
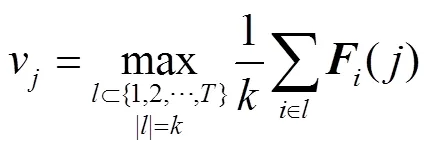
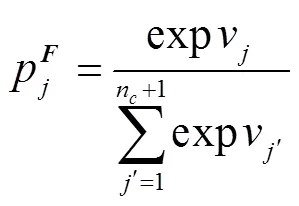
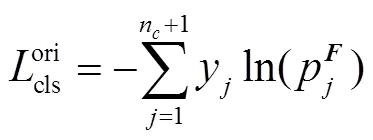
1.4 模糊动作对比损失函数
虽然所提网络能够通过多分支注意力实现动作-背景的分离,但是由于缺少时间标签,难以直接定位模糊动作片段.通过先验知识可知:模糊动作片段往往在时间上位于显著动作片段的相邻位置并远离显著背景片段.此外,其注意力权重会稍低于显著动作注意力权重,但明显大于显著背景注意力权重.基于上述思想,本文提出一种简单有效的方法定位模糊动作片段,并利用InfoNCE损失函数[7]细化其特征,使网络定位到更加完整的动作.
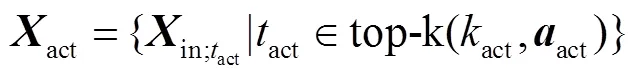
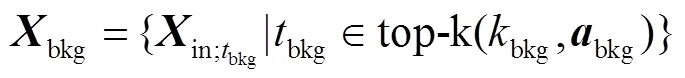
式中参数与式(8)类似.
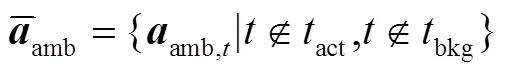
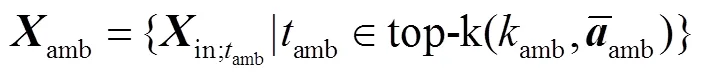
式中参数与式(8)类似.
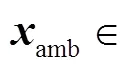
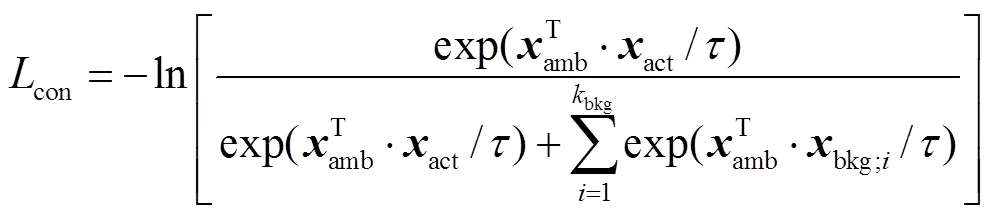
1.5 网络训练
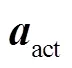
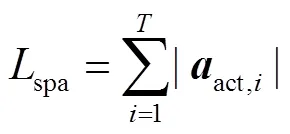
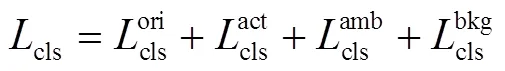
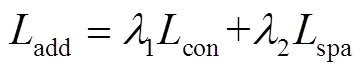
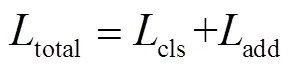
1.6 动作分类和定位
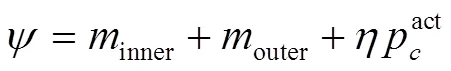
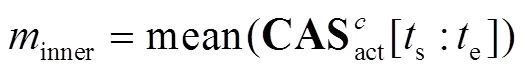
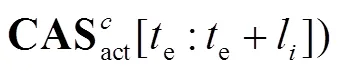
2 实 验
本节首先展示所提方法在2个弱监督时序动作定位数据集THUMOS-14和ActivityNet-1.2上的测试结果,随后介绍本文的消融实验和可视化结果.
2.1 THUMOS-14
THUMOS-14数据集[9]包含20类动作,每条视频平均包含15.4个动作片段.视频长度从几十秒钟到几十分钟不等,是对于时序动作定位任务挑战性较大的一个数据集.与主流算法划分数据集的方法相同,本文采用其中具有时间标注的200条验证视频作为训练集,212条测试视频作为测试集.
表1展现了所提方法在THUMOS-14数据集上与之前主流方法的对比实验.Avg表示IoU阈值为[0.3∶0.7∶0.1]时mAP的平均值.从表1中得知,所提方法在IoU阈值为0.3、0.4、0.5、0.6的情况下均取得了最佳性能.与之前的最佳方法HAM-Net相比,在IoU=0.5时mAP提高了2.2%,mAP的平均值提高了1.6%.这表明所提方法在包含动作较多且长度不断变化的视频数据上能表现出良好的性能.
2.2 ActivityNet-1.2
ActivityNet-1.2为Caba等[10]提出的大型时序动作定位数据集,总共包含100类动作.其中4819条视频用于训练,2382条视频用于测试,数据集划分方法与之前的主流算法保持一致.平均每条视频包含1.5个动作片段和36%的背景,相比于THUMOS-14,动作的出现频率明显减少.
表1 THUMOS-14数据集测试结果
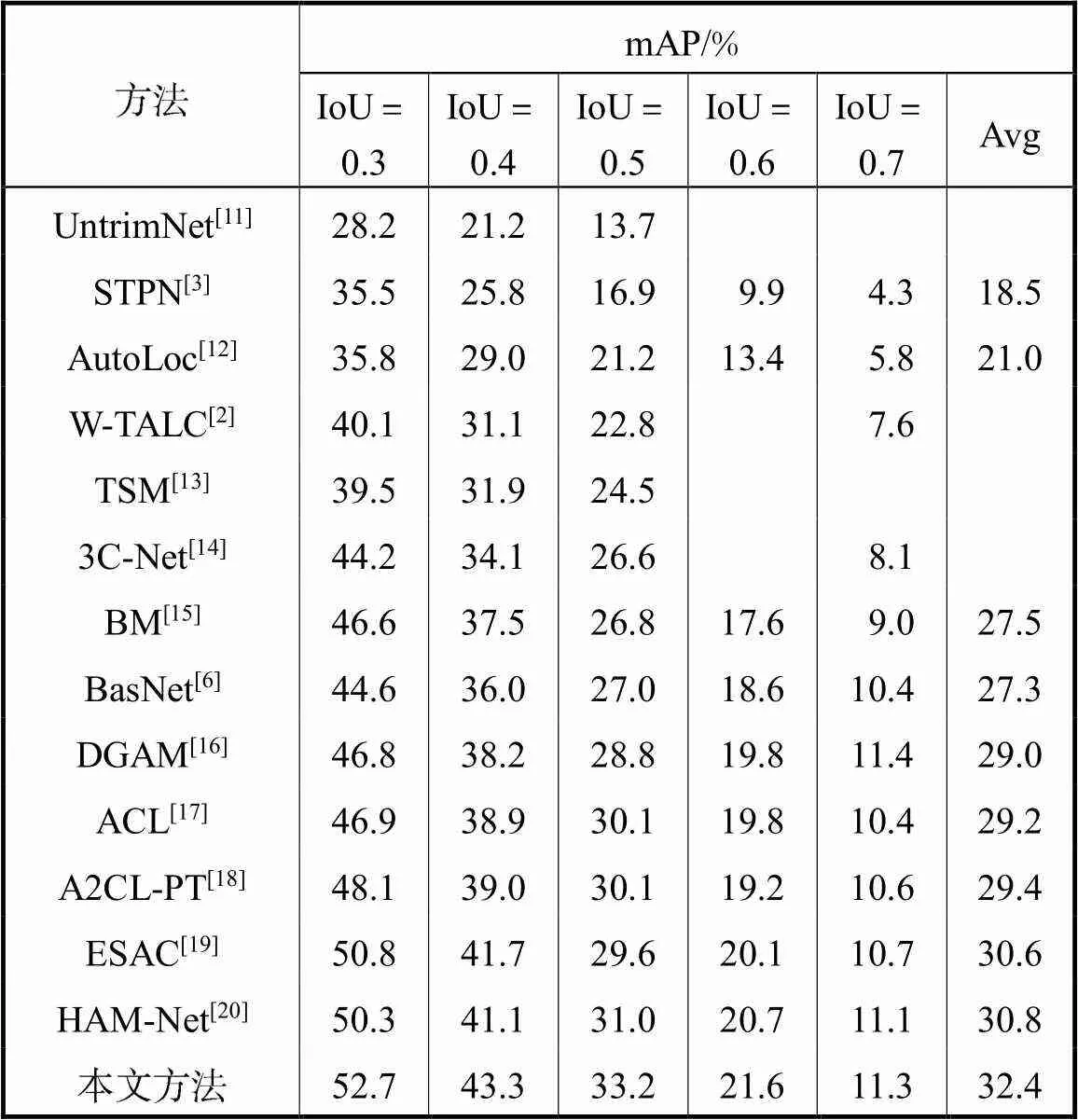
Tab.1 Test results of THUMOS-14 dataset
表2为所提方法在ActivityNet-1.2上的测试结果.Avg表示IoU阈值为[0.50∶0.95∶0.05]时mAP的平均值.所提方法在IoU阈值为0.50下的mAP达到了42.6%,相比于之前的最佳方法ESAC提升了3.4%,并且平均mAP达到了26.8%,取得了1.3%的提升.
表2 ActivityNet-1.2数据集测试结果
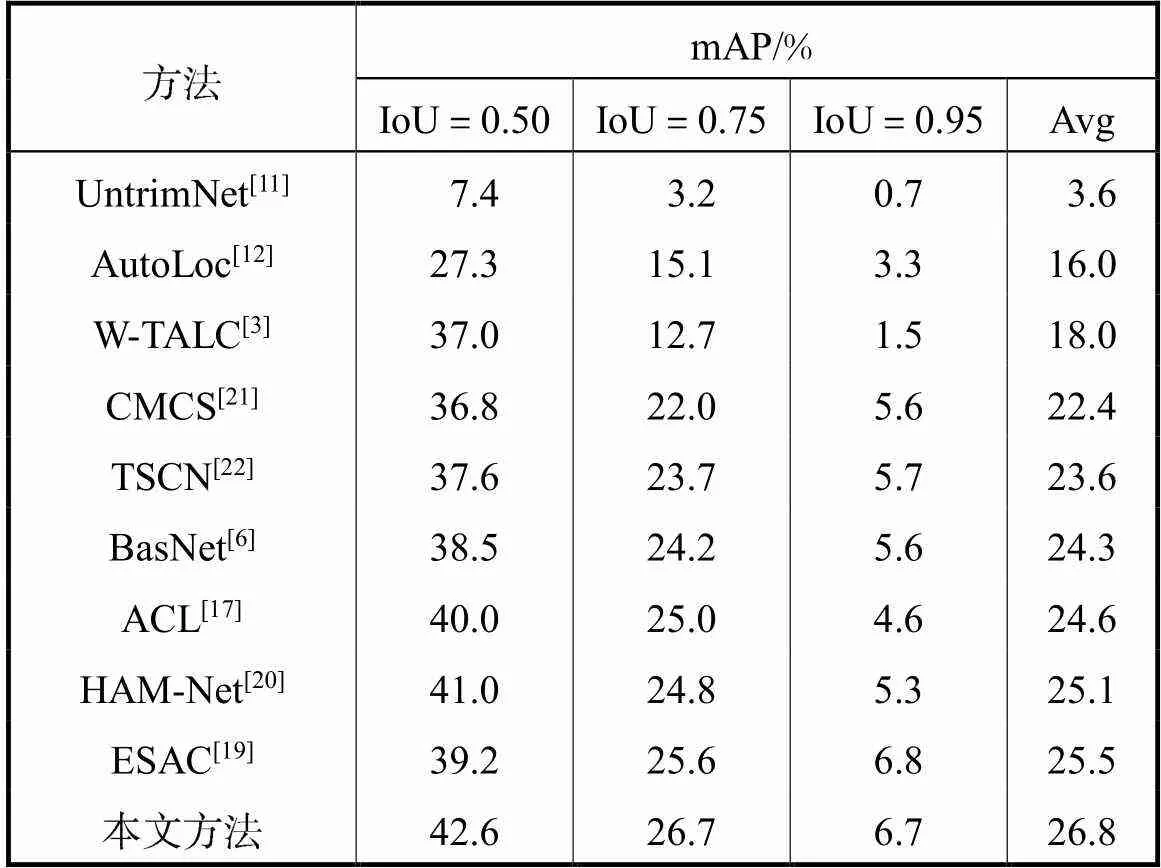
Tab.2 Test results of ActivityNet-1.2 dataset
2.3 消融实验
为了验证所提多分支注意力机制和模糊动作对比损失函数的有效性,本文在THUMOS-14数据集下进行了消融实验,具体数据如表3和表4所示.
2.3.1 分类损失项
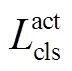
表3THUMOS-14中不同分类损失函数的性能比较
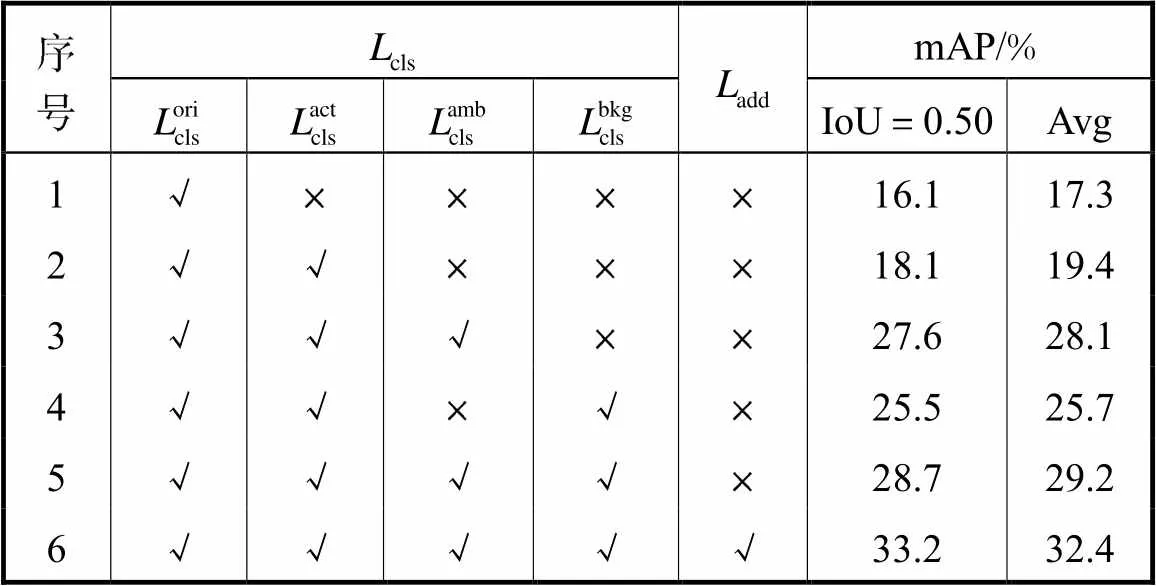
Tab.3 Performance comparison of different classification loss functions on THUMOS-14
2.3.2 约束损失项
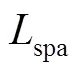
表4THUMOS-14中不同约束损失函数的性能比较
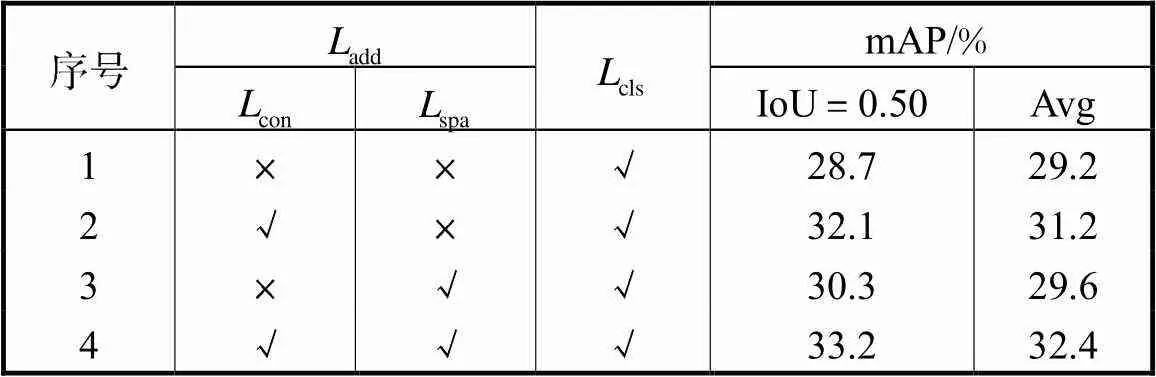
Tab.4 Performance comparison of different constraint loss functions on THUMOS-14
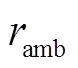
表5THUMOS-14中不同模糊动作特征采样率的性能比较
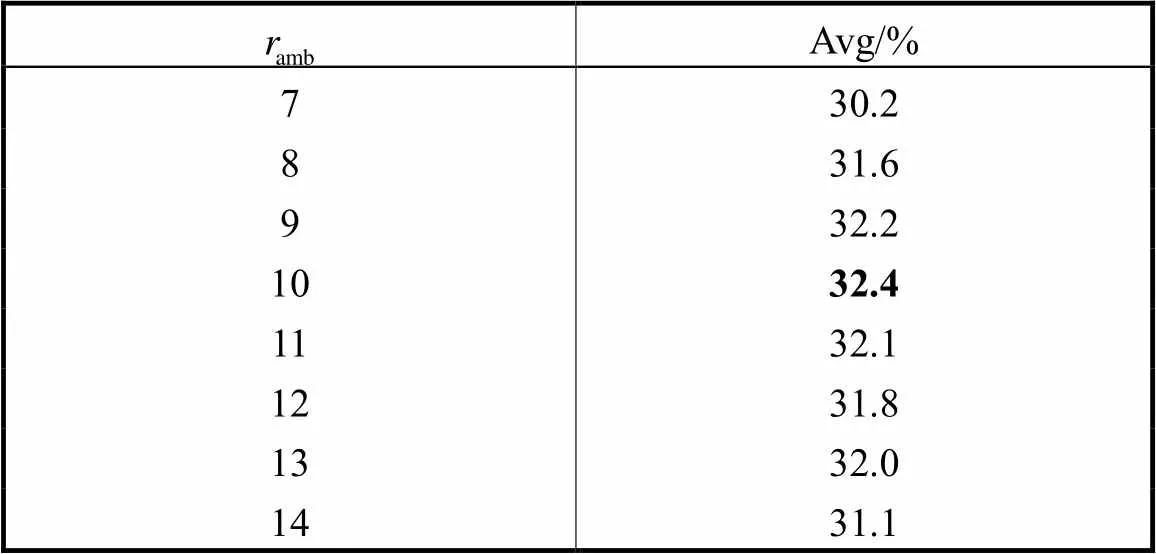
Tab.5 Performance comparison of different ambiguous action feature sampling rate on THUMOS-14
2.4 可视化结果
本节以先前的最佳方法HAM-Net为基准,展示所提方法的可视化结果,如图2所示.图2中黄色框对应视频中的显著动作,蓝色框对应视频中的显著背景,红色框为相应的模糊动作.图2(a)中的动作对应运动员的举重过程,在运动员从地上拿起杠铃(图片1)和将杠铃挺举到头顶(图片4)的两个阶段,运动的幅度较大,运动特征较明显;并且背景(图片5)存在明显的场景切换,它们能被基准方法轻松地定位出来.然而在举重过程中,运动员会将杠铃挺举并停顿在胸口位置(图片2),而且此过程发生了明显的镜头切换(图片3).该过程在没有时间监督信息的情况下难以捕捉,但本文方法能将之完整地定位出来.图2(b)视频包含多条打高尔夫动作,第3个动作片段整体进行了慢放,基准方法能够检测出部分打高尔夫球的过程.但在球杆位于最高点和最低点时,运动员往往会进行蓄力停顿(图片1、3、5),并且因为进行了慢放,这些时间位置的运动特征更加模糊,难以与静态背景区分.而本文方法能解决该问题,在完整定位第3段动作的同时没有影响其他动作的定位结果,充分体现了所提方法的有效性.
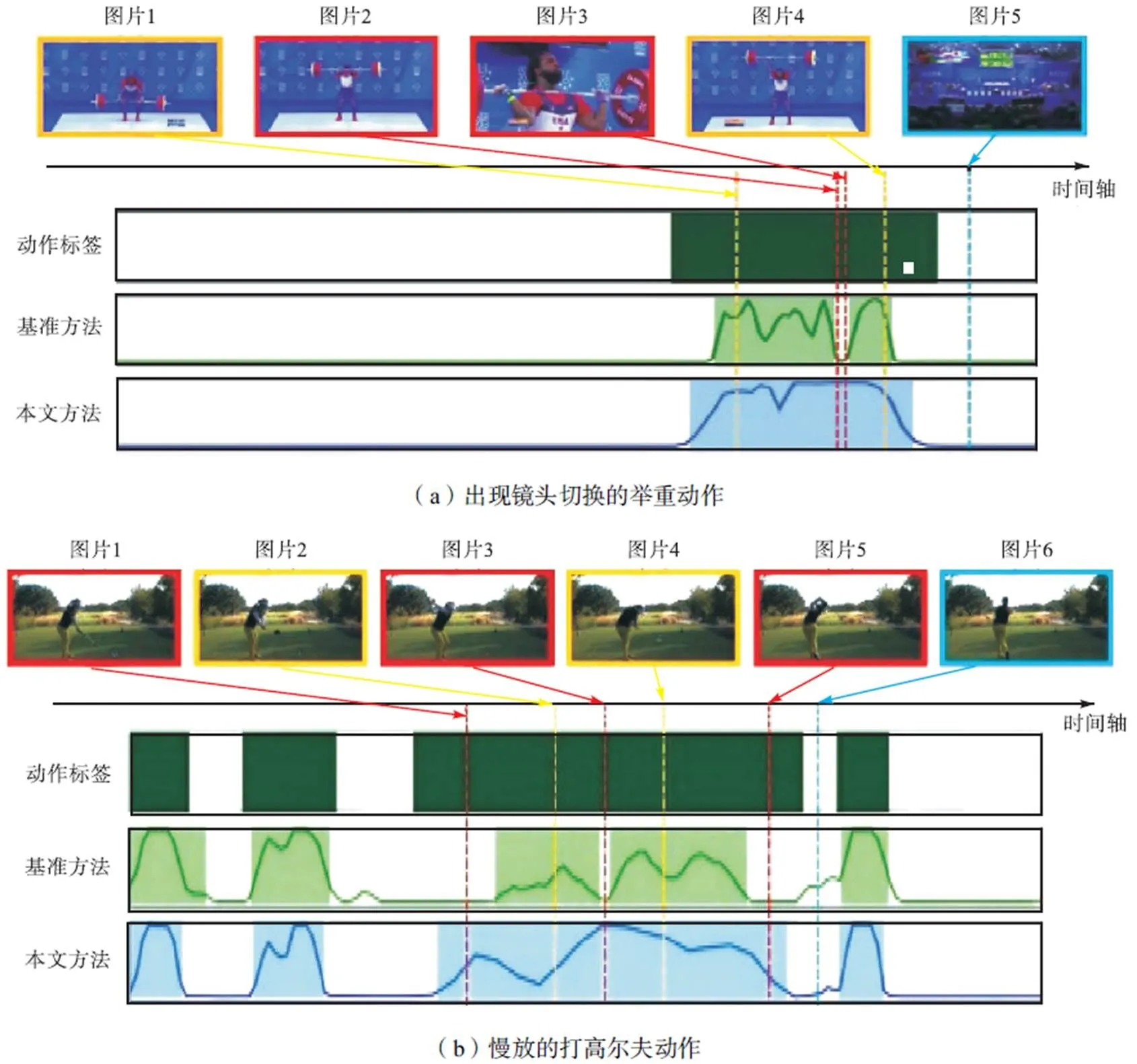
图2 可视化结果
3 结 语
为了解决未剪辑视频中模糊动作片段引起的误分类问题,本文提出了多分支注意力网络,能够进行动作-背景特征分离的同时,对视频中的模糊动作进行建模.同时基于对比学习的思想设计了模糊动作对比损失函数细化视频特征,学习更具可鉴别性的特征分布,从而定位更加完整的动作片段.实验结果表明,所提方法在2个主流的弱监督时序动作定位数据集上均取得了显著的性能提升,超过了之前的方法,证明了本方法的有效性.
[1] 庞彦伟,修宇璇. 基于边缘特征融合和跨连接的车道线语义分割神经网络[J]. 天津大学学报(自然科学与工程技术版),2019,52(8):779-787.
Pang Yanwei,Xiu Yuxuan. Lane semantic segmentation neural network based on edge feature merging and skip connections[J]. Journal of Tianjin University(Science and Technology),2019,52(8):779-787(in Chinese).
[2] Huang L,Huang Y,Ouyang W,et al. Relational prototypical network for weakly supervised temporal action localization[C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York,USA,2020:11053-11060.
[3] Paul S,Roy S,Roy-Chowdhury A K. W-TALC:Weakly-supervised temporal activity localization and classification[C]// Proceedings of the European Conference on Computer Vision. Munich,Germany,2018:563-579.
[4] Nguyen P,Liu Ting,Prasad G,et al. Weakly supervised action localization by sparse temporal pooling network[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles,USA,2018:6752-6761.
[5] Chen T,Kornblith S,Norouzi M,et al. A simple framework for contrastive learning of visual representations[C]// International Conference on Machine Learning. Vienna,Austria,2020:1597-1607.
[6] Lee P,Uh Y,Byun H. Background suppression network for weakly-supervised temporal action localization[C]// Proceedings of the AAAI Conference on Artificial Intelligence. New York,USA,2020:11320-11327.
[7] He Kaiming,Fan Haoqi,Wu Yuxin,et al. Momentum contrast for unsupervised visual representation learning[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:9729-9738.
[8] Carreira J,Zisserman A. Quo vadis,action recognition? A new model and the kinetics dataset[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii,USA,2017:6299-6308.
[9] Idrees H,Zamir A R,Jiang Y G,et al. The THUMOS challenge on action recognition for videos “in the wild” [J]. Computer Vision and Image Understanding,2017,155:1-23.
[10] Caba H F,Escorcia V,Ghanem B,et al. Activitynet:A large-scale video benchmark for human activity understanding[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston,USA,2015:961-970.
[11] Wang L,Xiong Y,Lin D,et al. Untrimmednets for weakly supervised action recognition and detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii,USA,2017:4325-4334.
[12] Shou Z,Gao H,Zhang L,et al. Autoloc:Weakly-supervised temporal action localization in untrimmed videos[C]// Proceedings of the European Conference on Computer Vision. Munich,Germany,2018:154-171.
[13] Yu T,Ren Z,Li Y,et al. Temporal structure mining for weakly supervised action detection[C]// Proceedings of the IEEE International Conference on Computer Vision. Seoul,Korea,2019:5522-5531.
[14] Narayan S,Cholakkal H,Khan F S,et al. 3C-net:Category count and center loss for weakly-supervised action localization[C]// Proceedings of the IEEE International Conference on Computer Vision. Seoul,Korea,2019:8679-8687.
[15] Nguyen P X,Ramanan D,Fowlkes C. Weakly-supervised action localization with background modeling[C]// Proceedings of the IEEE International Conference on Computer Vision. Seoul,Korea,2019:5502-5511.
[16] Shi B,Dai Q,Mu Y,et al. Weakly-supervised action localization by generative attention modeling[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:1009-1019.
[17] Gong G,Wang X,Mu Y,et al. Learning temporal co-attention models for unsupervised video action localization[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle,USA,2020:9819-9828.
[18] Min K,Corso J J. Adversarial background-aware loss for weakly-supervised temporal activity localization[C]// Proceedings of the European Conference on Computer Vision. Glasgow,UK,2020:283-299.
[19] Liu Z,Wang L,Tang W,et al. Weakly supervised temporal action localization through learning explicit subspaces for action and context[EB/OL]. https://arxiv. org/abs/2103.16155,2021-03-30.
[20] Islam A,Long C,Radke R. A hybrid attention mechanism for weakly-supervised temporal action localization[EB/OL]. https://arxiv.org/abs/2101.0545,2021-01-03.
[21] Liu D,Jiang T,Wang Y. Completeness modeling and context separation for weakly supervised temporal action localization[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Seattle,USA,2019:1298-1307.
[22] Zhai Y,Wang L,Tang W,et al. Two-stream consensus network for weakly-supervised temporal action localization[C]// Proceedings of the European Conference on Computer Vision. Glasgow,UK,2020:37-54.
Weakly Supervised Temporal Action Localization Based on Contrastive Learning
Hou Yonghong,Li Yueyang,Guo Zihui
(School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China)
Weakly supervised temporal action localization aims to localize the temporal boundary of actions and identify the corresponding action categories in untrimmed videos with only video-level labels. Owing to the lack of temporal labels for action segments,most weakly supervised temporal action localization methods aggregate distinguishable action features with high activation values to optimize the classification loss for the training of action localization networks. As a result,the networks would pay a lot of attention to the most critical parts of the action segments while ignoring the ambiguous action segments,which are difficult to classify,making it difficult to ensure the completeness of the localization results. To solve this issue,a neural network with a multi-branch attention mechanism was proposed,and it managed to model the distinguishable action,distinguishable background,and ambiguous action segments in the untrimmed videos. Based on the multi-branch attention weights,three temporal class activation sequences were constructed to optimize the action classification loss so that the network could separate the distinguishable action and background features. Moreover,to capture the full extent of action segments,an ambiguous action contrastive loss was designed based on contrastive learning. Specifically,the ambiguous action features were refined under the guidance of distinguishable features so that the network could perceive precise action temporal boundaries to avoid the temporal interval interruption. The proposed method outperforms previous methods on two weakly supervised temporal action localization datasets,THUMOS-14 and ActivityNet-1.2. Specifically,compared with those of the previous methods,the performance of the proposed method is respectively improved by 1.6% and 1.3% in the two datasets,which fully reflects its effectiveness.
weakly supervised learning;temporal action localization;contrastive learning;class activation sequence
TP391
A
0493-2137(2023)01-0073-08
10.11784/tdxbz202107045
2021-07-31;
2021-10-27.
侯永宏(1968— ),男,博士,教授,houroy@tju.edu.cn.
李岳阳,liyueyang@tju.edu.cn.
国家自然科学基金资助项目(61906173).
Supported by the National Natural Science Foundation of China(No. 61906173).
(责任编辑:王晓燕)
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
小猕猴智力画刊(2022年3期)2022-03-28
汽车工程师(2021年12期)2022-01-17
当代陕西(2020年14期)2021-01-08
奥秘(创新大赛)(2020年7期)2020-07-27
铁道建筑技术(2020年11期)2020-05-22
电子制作(2017年13期)2017-12-15
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
自动化学报(2016年5期)2016-04-16
