
加权动态时间扭曲的不平衡结构转子故障诊断
2023-02-27 12:39许伟红周金宇
机械设计与制造 2023年2期
许伟红,周金宇
(1.南京城市职业学院栖霞校区,江苏 南京 210046;2.金陵科技学院,江苏 南京 211169)
1 引言
工业4.0的出现导致了更复杂的工业系统的发展,该系统要求具有更高的自动化和高精度的健康预测管理。旋转机械约占该行业所有机械的40%,其中的转子故障研究是故障诊断领域的重要部分[1]。结构转子故障(Structural Rotor Fault,SRF)包括不平衡(Unbalance,不平衡)、不对中和松动故障等,上述故障不仅会对受影响设备的结构属性和性能造成影响,而且可能会对周围部件造成二次故障[2]。因此如何实现结构转子故障诊断成为了研究的热点。
对于转子的故障诊断研究,已经公布了一系列卓有成效的方法。文献[3]提出了一种深度学习多通道卷积神经网络结构,该结构能有效地处理原始时域数据,并能识别各种单标签故障。文献[4]提出了一种基于加权贡献遍历指数准则的转子故障诊断方法,以考虑在宽范围的谐波激励下的系统响应,从而提高识别碰摩故障的灵敏度和稳定性。文献[5]为了充分应用多传感器异构监测数据,提出了一种基于多模残差网络和判别相关分析的转子故障诊断方法。上述方法均是基于时域或者时频域信息实现的故障诊断,取得了一定的效果,但是然而,时域或时频域特征处理缺少数据中的时间信息,这限制了使用顺序学习模型的范围。另外相关的研究对象主要是单一转子原件的故障诊断,未考虑结构转子的特征。
结构转子特征是旋转频率及其谐波频率的频谱变化,称为独特频率分量(Distinctive Frequency Component,DFC)。文献[6]通过引入最小所需长度的概念,提出了一种基于实例的早期故障分类方法,此外,还引入了一种基于特征的早期识别方法。文献[7]通过学习可靠性阈值并随时间区分类别,有效结合了时域特征与时频域特征与独特频率分量,实现了结构转子的故障分类与识别。文献[8]引入了一种加权特征支持向量数据描述的结构转子故障诊断方法,有效将结构转子的故障特征进行了分类加权,取得了较好的故障诊断效果。然而上述方法中SRF的数据源是转子试验台,但大多数转子试验台无法反映各种实时工业情况,例如不同的速度和负载条件、采样数据不均匀以及异常或噪声读数。
为解决上述问题,这里提出了一种基于加权动态时间扭曲的不平衡结构转子故障诊断。该框架提出了一种顺序数据表示形式,以弥补实际工业数据和实验实验室数据之间的差距。此外,它还处理采样不均匀或未命中数据、不同的运行速度条件,并抑制与原始数据相关的其他传感器问题,引入了一种基于加权软动态时间扭曲的数据增强方案,并用故障信息内容进行了增强。实验结果证明了提出方法的有效性。
2 这里的方法
2.1 下采样和数据预处理
在本节中,介绍了这里SRF诊断框架,如图1所示。

图1 SRF诊断框架Fig.1 SRF Diagnostic Framework
该方法思想是通过从连续的数据流中对数据点进行下采样,而不是直接从原始数据中学习,从而以固定的间隔利用振动信息。每个数据点都将时域信号和故障DFC结合到时序特征空间中,以利用这两个域的优势。然后,为每个样本分配足够数量的与实际工业场景监控周期相关的顺序汇总数据点。这种在子采样特征空间中创建的样本具有数据点的时间特性和足够的鉴别信息内容的优点。基于两个约束选择原始数据采样间隔(St),首先,确保原始数据点的数量最少,从而可以提取正确的DFC。其次,它提供了一个合适的下采样频率,它更接近于工业数据库解决方案的单位观察期。设rs为转速,单位为rpm,fr为旋转频率,fs为感应频率,然后,每次旋转的采样点数量(sr)为sr=60fs/rs或。每段的最小采样点数量(s)l应满足以下条件:si≤sr≤sl,其中si是样本之间的间隔点数。因此,条件sr≤sl确保每个段包含一个或多个旋转数据。同样,根据工业振动监测解决方案的数据采样率确定最大值点。因此,在本实验中,一秒的下采样持续时间是fs点的片段长度。
为了提取DFC,首先,在每个分段上评估FFT频谱。由于本实验考虑了工业的波动速度和不断变化的操作条件,因此需要对数据进行标准化处理,以减少不同操作条件下的速率差。该过程表达式为:
式中:Sf—有效频带的数量—类似于fiX频率的振幅;μampl—对
应于有效频带的振幅平均值;N(fiX)—归一化振幅值。
那么,对于i=1,2,...,hf,由Ni=N(fiX) 给出DFC,其中hf是旋转频率分量的数量。这些是通过fiX-Δf到fiX+Δf范围修正中的多通道过滤器提取的,其中Δf是波动频率范围。此外,还观察到转速变化小于10%,且Δf对振幅的影响相对较小。类似地,还提取与这些频率对应的相位信息。从表1可以看出,旋转频率的前三次谐波(1X、2X、3X)及其与径向和轴向相位的组合足以区分不同的SRF。通过查找sr数据点大小的最大值并对fsfr取平均值的数量来生成时域中的汇总数据,如图1的粉红色圆圈中的数字“i”和“ii”。这个阶段创建了一个新的均匀下采样有序数据集,表示为X=[X1,X2,...,XN],其中每个和L是时间序列的长度,每个时间序列在子采样空间中的维数为M。
2.2 改进软动态时间扭曲
为了避免过拟合,提高训练样本的质量和多样性,这里采用了一种基于软动态时间扭曲的数据扩充方案。该方案基于DTW权重平均算法,该算法使用近似方法从一组序列中找到一致序列。Forestier等人改变了DTW权重平均算法的目标函数,在每个序列中加入一个权重因子,以生成平均序列。这里已通过以下方式修改此方法,以在子采样空间中增强时间序列信号。
(1)所提出的增广方案将SRF的DFC合并到权重分布中,从而使其更具有领域特定性。它利用FIC选择有效样本,合成质量更高的样本,提高分类精度。
(2)采用软动态时间扭曲权重方法实现更平滑的权重,以实现有效学习。
该增广方案保留了合成样本的序列特性和类判别能力,处理的参考样本较少,并且能够处理不同长度的序列。软动态时间扭曲权重生成见算法1和图2,包括两个主要过程:第一个是权重分配过程,第二个是使用这些权重生成软动态时间扭曲权重。
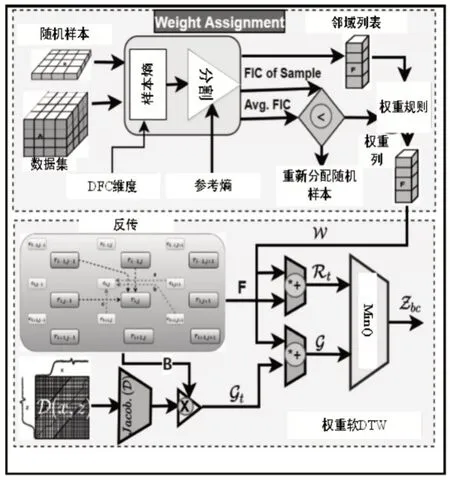
图2 软动态时间扭曲权重生成Fig.2 Soft Dynamic Time Warp Weight Generation
对样本中DFC 柱的熵进行平均,以找到样本的代表熵。然后计算故障样本和正常样本的代表熵比率,以确定特定样本的FIC。算法1的步骤1到步骤9描述了该过程,然后,为了分配权重,最初,从特定故障的数据集中随机选择时间序列Xi。然后,将其FIC与整个数据集的平均FIC进行比较。如果较小,则选择一个新的随机样本,并重复该过程。算法1的步骤10-13和图2的第一部分描述了该过程。
权重分配过程如算法1的第15步所示,在此过程中,满足最低FIC标准的随机样本的权重为0.3。然后,选择其N× 0.1最近的索引邻居,并基于样本FIC对其进行排序。FIC最高的前两个邻域的权重分别为0.15,后两个邻域的权重分别为0.1。为了确保权重的标准化和,相邻子集中的其余样本平均共享剩余的0.2权重,以创建权重数组。确定这些权重值是为了在两个目标之间保持平衡,即多样性和合成样品的鉴别特性。此外,Fawaz等人的方法也进行了一些修改,以增加前四个邻域的权重。所述方案有助于选择最重要的参与样本,从而按照一定比例降低了计算成本。
权重分配过程服从DTW 权重平均算法,DTW 使用顺序计算。然而,由于最小算子在DTW中不是连续的,它限制了梯度或次梯度计算。因此,DTW函数的可微性是通过一个广义最小算子β来实现的,表示为:
那么,β的软动态时间扭曲可以定义为:
式中:D(x,y) —成对距离矩阵;P∈Pm×n—基本DTW计算中的路径对齐矩阵。文献[9]定义的全局对齐内核(K)也可以比较两个时间序列:
随后,用链式法则描述软动态时间扭曲的梯度,表示为:

算法1:基于FIC的加权软DTW
输入:Xf是一组故障类型为f的Nf时间序列,z=Xf[k],其中k是一个随机数1 ≤K≤Nf,z∈R(L×M)。
输出:Zbc:最佳平均序列
初始化:
将Wf∈RNf初始化为0的权重向量是Xf的第i个样本的difDFC列,εh是参考样本的熵,d是距离函数,令S=0,G=0,Rt=0。

2.3 初期分类模型
初期分类是通过观察部分信息对序列数据进行分类的过程,具有可接受的准确度。在这项工作中,这里提出的初期分类模型故障诊断遵循两个过程。在第一种情况下,仅通过将精度作为目标来搭建基本分类器F,类似于传统分类方法,在该方法中,一旦时间序列可用,就进行类别预测。在第二步中,通过考虑预测的可靠性和早期性来定义分类置信阈值。
(1)序列分类器:常用的顺序深度学习模型,如简单递归神经网络(RNN)、长短时记忆(LSTM)和选通递归单元(GRU),在它们的节点之间具有顺序连接,使他们能够学习输入时间序列的时间动态行为。简单的RNN代替整个激活过程,而LSTM和GRU调节每个单元中的信息,这有助于后一种模型处理消失/爆炸梯度问题。基于这一动机,这里提出了一个深度学习体系结构,由L个循环层组成,这些网络层从信号中捕获时间信息及其长期关系。然后,添加了全连接层,提供了更高级别的数据表示,也有助于更好地分类。最后一层执行故障分类,分别基于LSTM和GRU体系结构开发了两个分类器M1和M2。通过将分类交叉熵作为损失函数和Adam作为优化器来确定分类模型M1和M2的超参数。参数集合包括:循环层L∈{1,2,3},隐藏节点HN∈{16,32,64,128},学习速率η∈{0.1,0.01,0.001},搜索了300 个迭代周期。最后,最佳参数设为L=2和η=0.001。
(2)置信阈值:这里提出的初期分类模型定义了类置信阈值(θ),以便对传入的时间序列进行早期决策。置信阈值用于测量类预测的可靠性,分析观察到的序列是否足以进行类预测。基本上,初期分类模型在每个时间步t处理传入的X,并计算预测类=F(Xt)的置信度,用表示。此外,只有当计算的高于预定义的置信阈值θ时,初期分类模型才会预测类标签。
(3)训练阶段:在这个阶段中,首先是基本分类器F∈{M1,M2}使用全部采样数据进行训练。为了学习更精确的模型,通过使用所提出的方法增加训练集。通过仅将精度作为目标,使用完整的训练集对分类器F进行训练。然后,初期分类模型学习置信阈值{θ1,θ2,...,θk}。然而,所提出的初期分类模型学习分类阈值,这更适用于SRF诊断。算法2中给出了初期分类模型的完整学习过程。
为了学习置信阈值,将F作为一个预训练模型,并计算在每个时间步长t的分类器F的性能,用表示。基本上度量类预测y的可能性,而预测的类标签是。正式定义是:
因此,单时间点t的预测置信度()的表达式为为了计算,使用部分数据Dt,其中每个Xt∈Dt只包含t个数据点。由于分类器F不能接受Xt,为了解决这个问题,每个Xt都以前缀的方式填充当前均值。首先,可以令预先训练的模型接受输入。其次,它捕获了未观测序列的电流信号的平均分布。
随着时间的推移收集时间序列数据,可以得到每个时间步长t的类别预测。因此,利用到t的所有预测来计算类别预测的复合置信度,定义为:
最后,定义了支持早期等级预测每一类SRF最佳θc。在这个过程中,计算训练集所有可能候选阈值,i∈[1,N],t∈[1,T)]。其次,通过平衡预测的可靠性得分和提前性之间的权衡,选择最佳分类阈值。该过程见算法2的第10-38步。
(4)预测阶段:在预测过程中,初期分类模型处理每个时间点t的X,并计算类标签=F(Xt)。进一步用式(8)计算的置信度,如果t时刻的X满足可靠性阈值条件,初期分类模型将预测类别标签;否则,初期分类模型将等待在时间序列中添加更多的数据点,并重复这个过程。算法3 描述了初期分类模型的完整预测过程。
算法2:初期分类模型训练过程

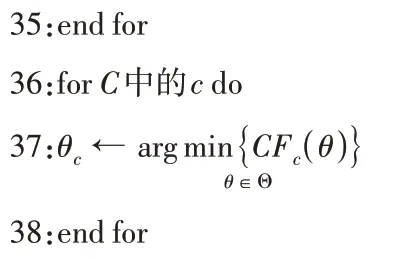
算法3 初期分类模型预测过程
输入:X;TS,F:训练分类器;{θ1,θ2,...,θk}:置信阈值。

3 实验与讨论
3.1 实验设置和数据收集
为了评估这里框架的有效性,从转子套件装置Meggitt Mi 19003收集数据,该装置模拟真实的电厂变速工作环境。此外,使用公开可用数据集,机械故障数据库(MaFaulDa),对上述方法进行实验。MaFaulDa是一组广泛的SRF多元时间序列,利用Sp初期分类traQuest的机械故障模拟器进行数据生成过程。
(1)Meggitt数据集(DS-1):数据采集设置包含转子试验台、信号调节单元(SCU)和监测与分析单元(MAU)等元件。它由一个由变频驱动器(VFD,负责改变频率和电压供应)控制的电动机和一个带有挠性联轴器的旋转轴组成,由轴承箱支撑。接触式通用加速计(CA202压电加速计)沿径向放置在轴承箱中,以测量壳体振动。非接触式涡流接近传感器(TQ 402/EA 402)位于轴附近,用于感应轴振动和转速。数据集包括六种不同的故障类别:正常工作、静态不平衡、耦合不平衡、动态不平衡、未对准和松动故障,试验台设置和数据收集条件,如表1所示。

表1 试验台配置Tab.1 Test Bench Configuration
(2)MaFaulDa 数据集(DS-2):MaFaulDa 数据集的故障模拟器主要配备两套加速度计,按三个正交(轴向、径向和切向)方向布置。它还包含一个转速表和一个麦克风,分别用于测量系统旋转频率和工作声音,该机器能够在正常和不平衡条件下捕获七种不同重量的数据。在数据收集过程中,考虑了不同移位距离的水平和垂直偏差。它包括总共1951个不同的场景,在5s的时间间隔内以50kHz采集的八个信号描述了每个场景。测试设置的详细说明,如表2所示。
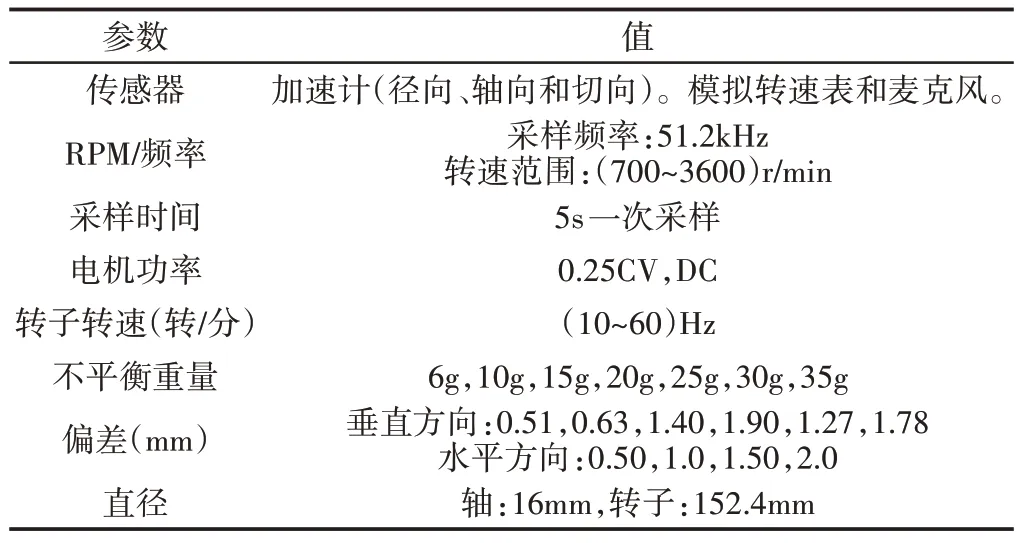
表2 测试设置条件:MAFAULDA数据集Tab.2 Test Setting Conditions:MAFAULDA Dataset
从转子试验台收集的原始数据以1s的持续时间在子采样空间中汇总,数据集包含六个具有五种不同速度的类别,每个样本的持续时间为5min。然后,对其进行扩充以改进训练数据集的大小,从而使原始数据和扩充数据合并为整个训练样本。在Ma‐FaulDa数据集上执行相同的子采样,但是重叠的,选择DS-1在所有负载条件下最接近的匹配速度。
这里评估了该框架的有效性,通过在准确度上保持适当的折中来实现故障分类的早期性。为了挖掘SRF的有用故障模式信息,使用序列模型分析了时域和DFC特征在子采样空间中的单独和组合效应。此外,使用PL-2表示的单独管道检查框架处理实际电厂数据的能力。该模型在PL-2上的性能与PL-1规定的标准数据进行了比较,PL-2数据集设计用于通过从子采样空间随机移除几个数据点来模拟采样不均匀或丢失数据的情况。
3.2 性能评估
每个数据集最初分别以(70~30)%的比例进行划分,用于训练和测试。此外,为了评估初期分类模型的性能,这里使用以下指标。
(1)准确率:测量正确分类的样本占测试样本总数的百分比,定义为:
(2)提前度:用于测量初期分类模型在时间序列上的性能,初期分类模型通过观察部分时间序列来预测类别标签。因此,测试时间序列的提前度指的是用于类别预测数据点的数量(t∗≤T)。因此,初期分类模型的提前度定义为:
3.3 下抽样和数据集增广的影响
表3说明了在顺序下抽样特征空间中表示原始数据的影响以及数据集增广对总体性能的影响,此外,两个数据集上的模型的学习效果,如图3所示。为组合特征提供精度结果,作为性能基准。表3表明M1和M2在这两个数据集上都取得了令人满意的性能,并规定了下采样特征空间提高故障诊断结果的能力。在两个数据集中比较两个模型的训练和验证精度,证实了模型不存在数据过拟合的事实,表明了数据集扩充的有效性。此外,与M1相比,M2在两个数据集上的性能稍好。还观察到,对于每个数据集,能够以较少的时间段实现良好性能的模型,且M2的学习曲线比M1相对平滑。添加高度区分性的增强数据增加了数据多样性,这有助于改进模型的参数训练,并且,顺序学习模型的准确性有所提高。
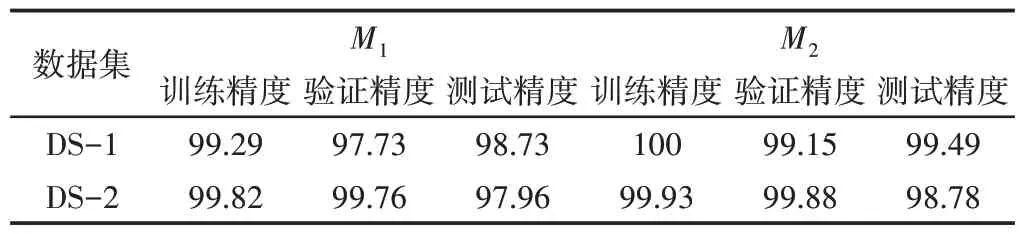
表3 训练性能Tab.3 Training Performance
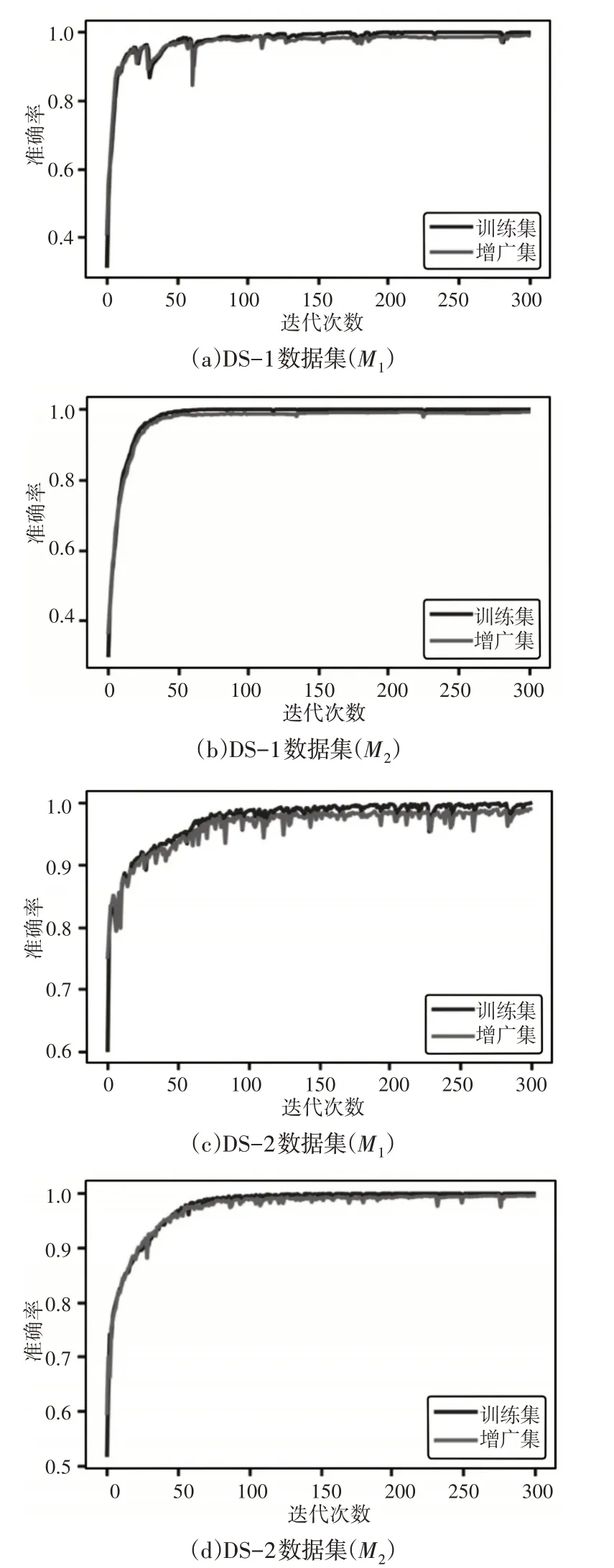
图3 两个模型的准确率Fig.3 Accuracy of Two Models
3.4 序列模型的性能分析
两个数据集的具有时域、DFC和组合特征的分类器的性能比较,如图4所示。随着模型结构复杂性的增加,在具有时域、DFC和组合特征的两个数据集中,两个分类器的准确度都相应提高。组合特征具有良好的性能,DFC本身能够标记其在获得显著精度方面的重要性。相比之下,DS-1的时域性能较差,而DS-2的时域的最低精确度为80%。DS-1结果中最重要的观察结果是,具有64HN的两个序列模型足以提供接近100%的适当精度。结果表明64HN 的M2模型优于128HN 的M2模型,因此,可以得出结论,具有64HN的分类器在不牺牲更高复杂度的情况下具有可接受的性能,从而可以忽略DS-1的性能改善。与DS-1相比,随着模型复杂度的增加,DS-2在准确性方面表现出一致的改进。即使是具有16个隐藏层和时域特征的最简单模型,使用这两种分类器也可以产生约80%的准确率。与DS-1一样,M2对M1的优势以及组合特征对时域或FD特征的优势也在DS-2中得以体现。关于模型选择,与两种分类器的32-HN模型相比,64-HN模型的性能略有提高,其中128-HN模型仅对M1的性能提升可以忽略不计。因此,这里比较分析了128 HN的模型。
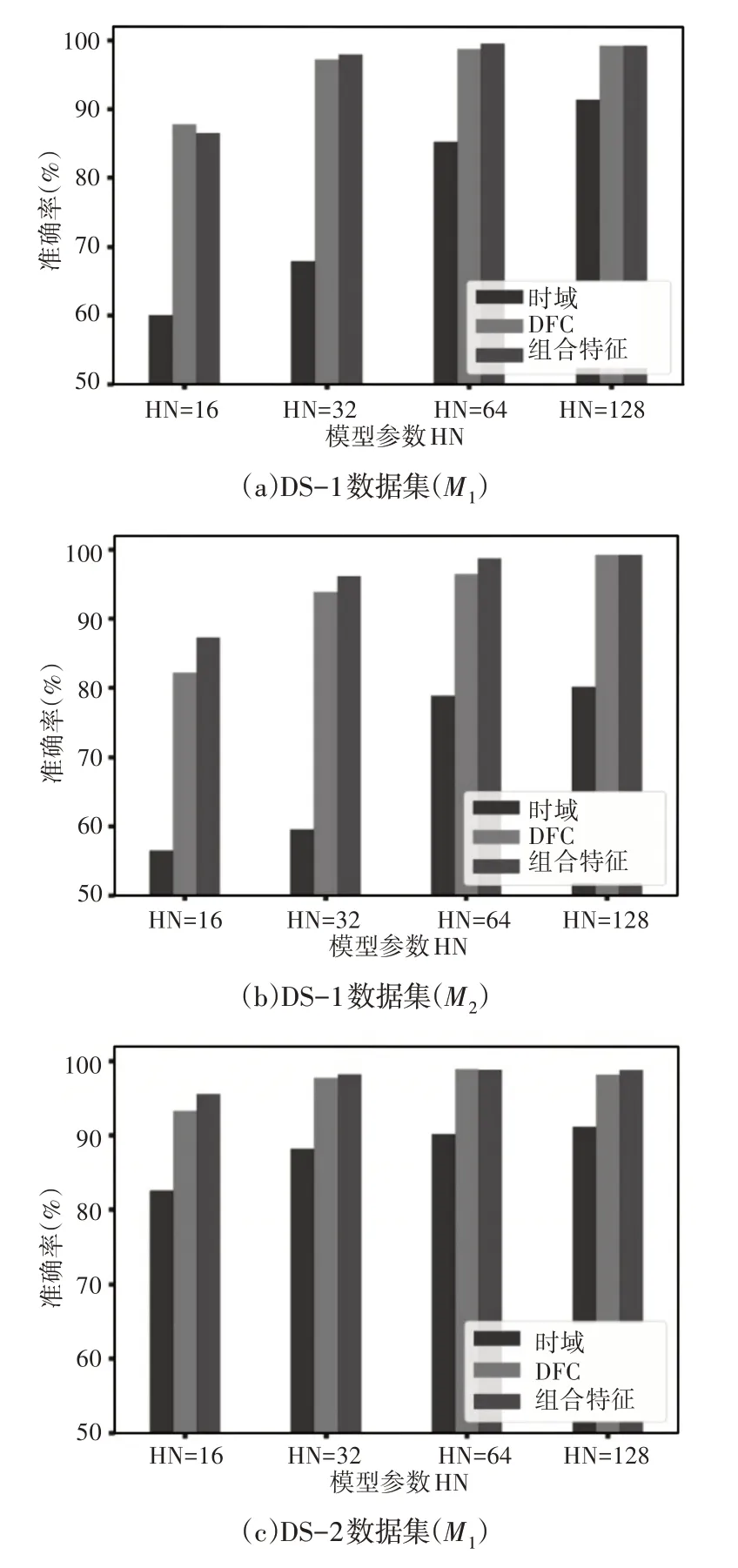
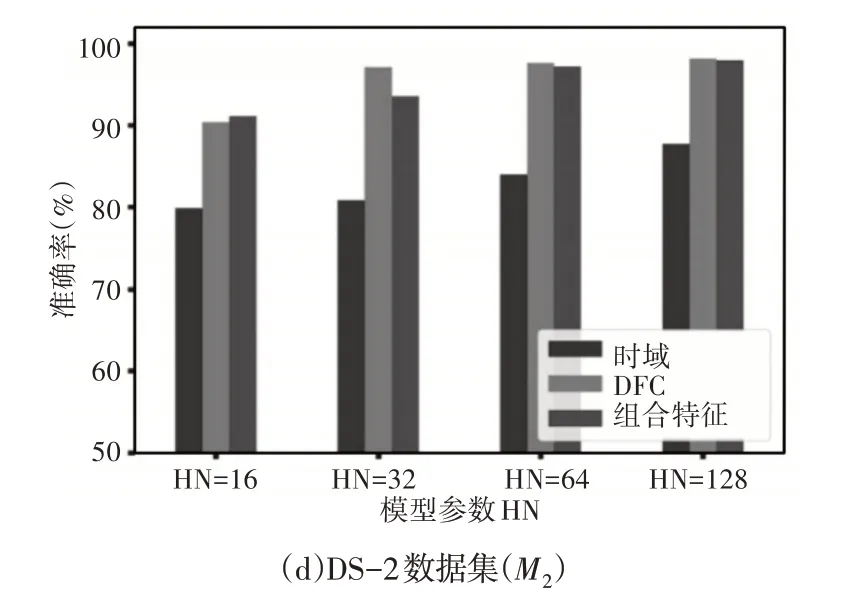
图4 不同节点的模型比较Fig.4 Model Comparison with Different Nodes
数据集上两个分类器的DFC在SRF诊断中的重要性,如图5所示。故障分析有助于理解DFC在故障诊断中的重要性。对于不同类型故障的时域特征,观察到了明显的波动。对于DS-1的正常工作状态和成对不平衡类标签,这两个分类器的性能均较差。此外,对于使用M1模型的未对准和松动等级,也观察到类似的结果。然而,DFC和组合模型提供了可接受的性能,无论两种型号的故障类型如何。此外,M2在精确度方面略优于M1。可以观察到,DS-2 中DFC 和组合特征的分类行为几乎与DS-1 相似,在不同故障类型之间不会产生显著波动。然而,时域特征在两个分类器中都表现出不可接受的性能;同时,M2能够弥补水平失调等级的性能退化。但是,与DS-1一样,M2在所有类中的性能都优于M1。
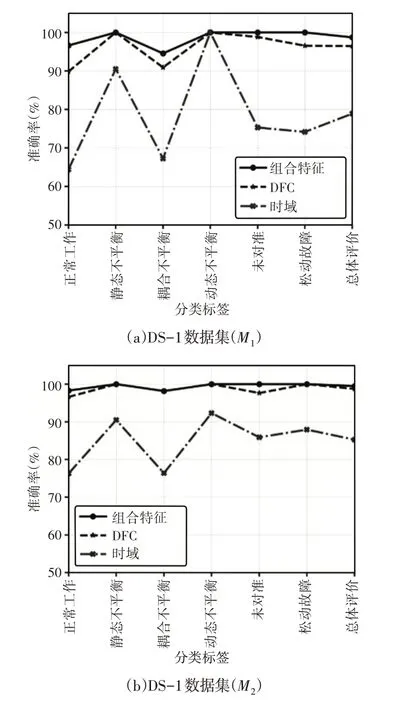
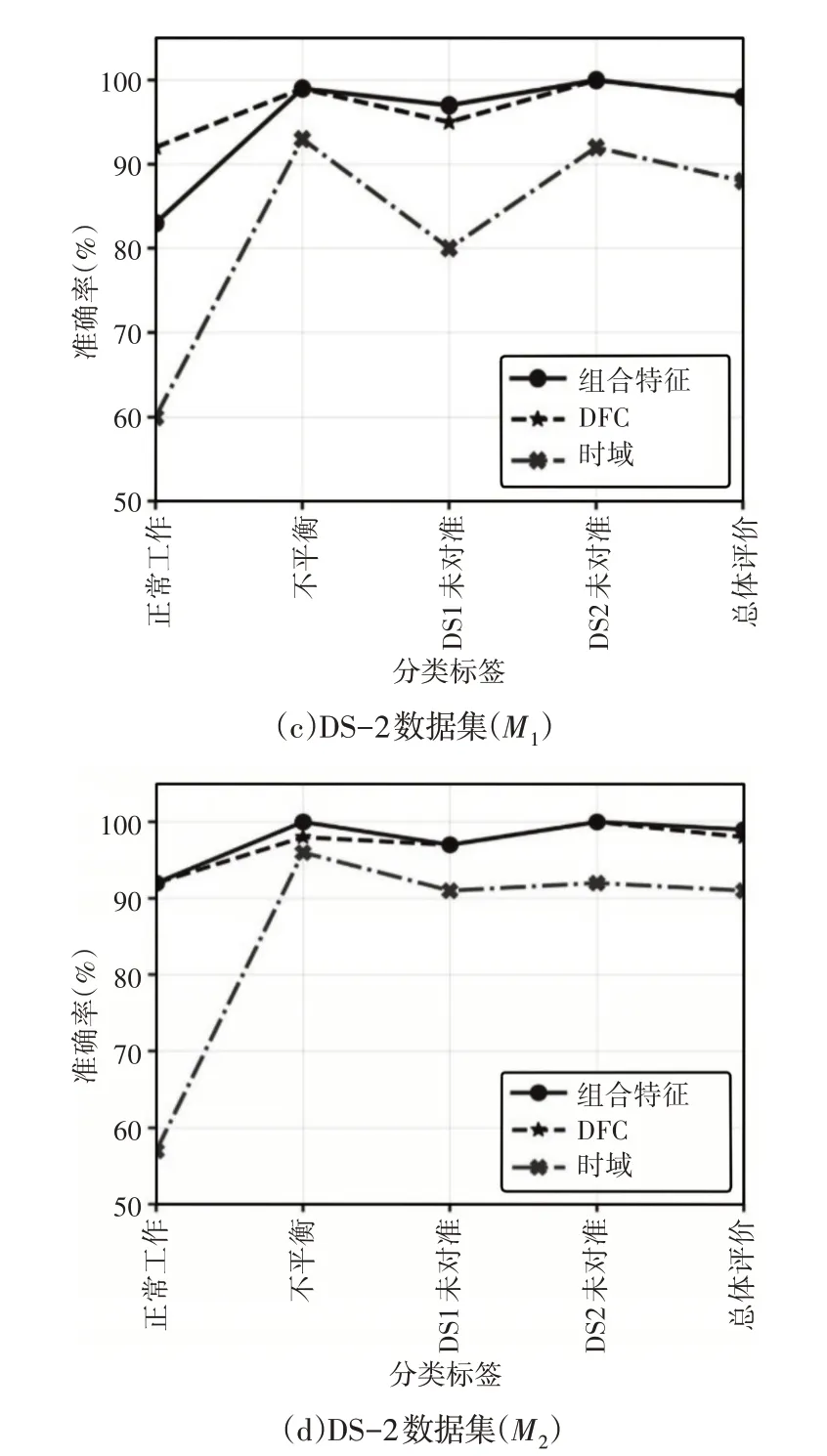
图5 对比分析Fig.5 Comparative Analysis
3.5 性能分析
(1)初期分类模型中α参数的影响:在所提出的模型中,参数α决定准确性和提前度之间的折衷,其值介于0 和1 之间。α∈{0.5,0.6,0.7,0.8,0.9} 的变化趋势,如图6所示。观察到准确度和提前度随着α的增加而显著增加。此外,还发现α的变化趋势取决于数据集的特性。例如,对于数据集DS-1 和DS-2,α从0.6 到0.7 的变化精度分别提高了4%和2%,而对于相应的数据集,提前度分别提高了2%和9%。在这项实验工作中,将α的值设为0.9,因为在两个数据集的准确性和提前性方面都表现出足够的性能。但是,可以根据系统的要求选择任何α值。
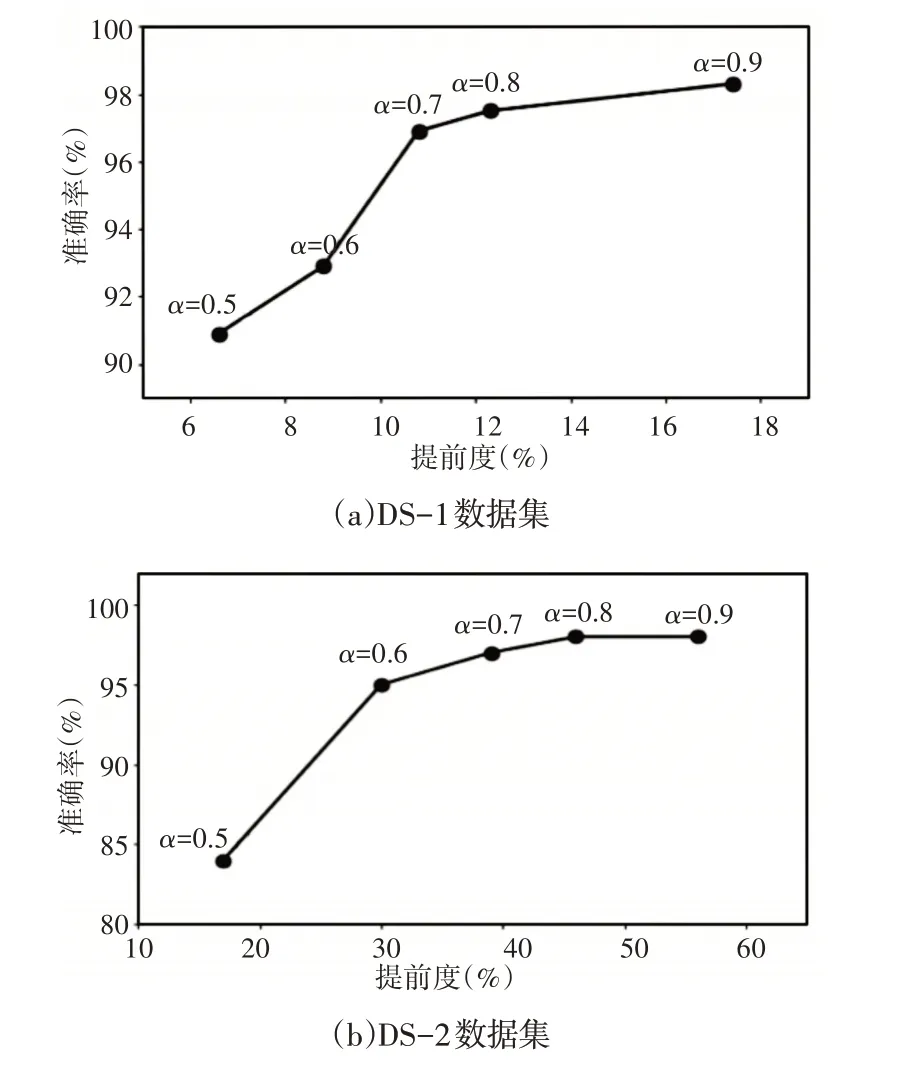
图6 参数的影响Fig.6 Effect of Parameters
(2)初期分类模型在两个数据集上的性能:表4、表5分别提供了这里提出的初期分类模型在DS-1和DS-2数据集上的性能分析。此外,还比较了PL-2数据集的性能。在表4中,可以观察到,对于组合特征,初期分类模型-M2达到了99.50%的最高精度,而带有DFC特征的初期分类模型-M1达到了12.70%的最佳早期性。由于时域信号的识别能力最低,因此需要更长的序列才能获得可接受的精度,而DFC和组合信号可以在不影响精度的情况下以小于20%的提前度快速得出结论。与M1相比,M2能够在短序列内捕获信息。因此,初期分类模型M2在准确性和早期性
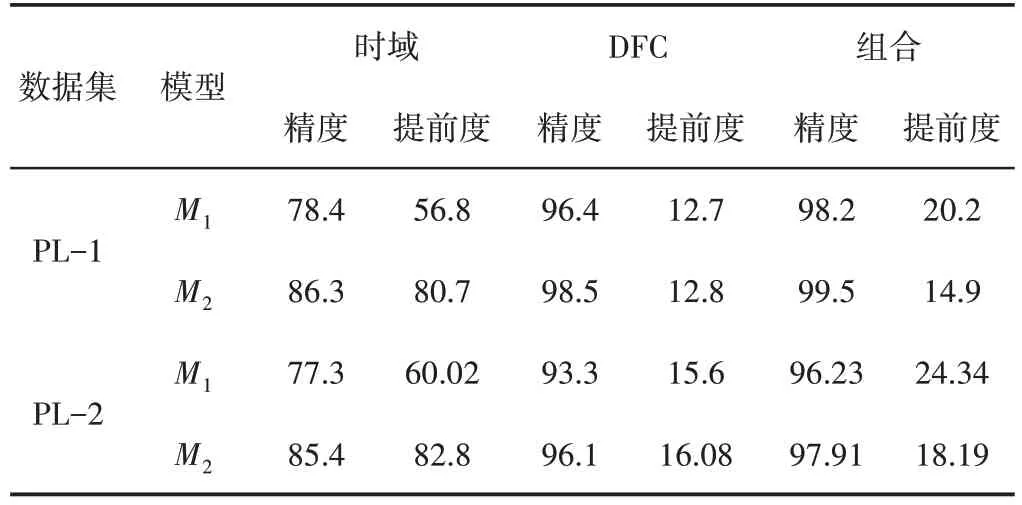
表4 分类模型在DS-1数据集上的性能Tab.4 Performance of Classification Model on DS-1 Dataset
这两个目标上都优于初期分类模型M1,对于DS-2也得出了类似的结论,如表5所示。然而,由于速度和负载条件的多样性,DS-2数据集需要更多长序列来进行可靠分类。因此,DS-2的提前度约为60%。然而,在这里框架中,DS-2的总体精度略高于DS-1。
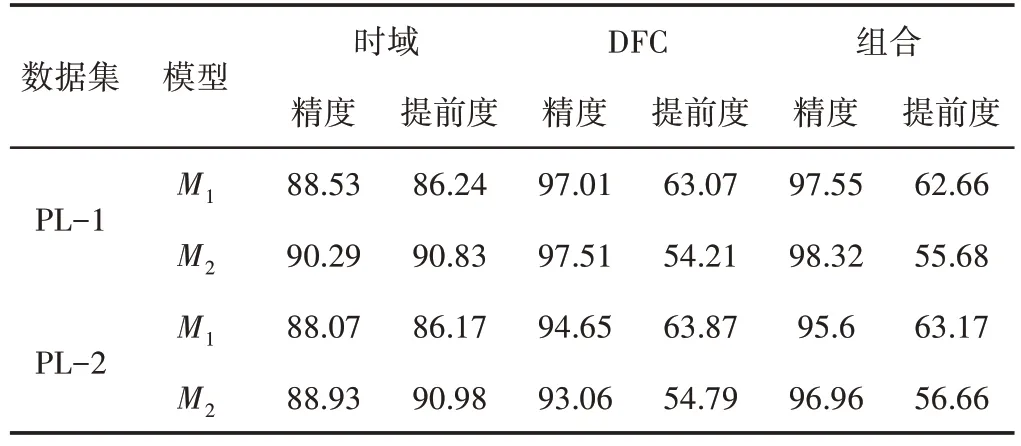
表5 分类模型在DS-2数据集上的性能Tab.5 Performance of Classification Model on DS-2 Dataset
考虑到具有PL-2数据的模型的性能,从第一次观察中可以明显看出,与PL-1相比,两个数据集中的精度都有下降的趋势,提前值也有增加的趋势。由于是通过随机移除样本而产生数据采集的不规则性,并且由平均值填充数据丢失的时间戳,因此在时域数据中,这种趋势并不显著。也就是说,由于操作上进行平均,子采样空间中的时域数据点几乎与PL-1数据相似。然而,PL-2的子采样空间中的DFC提取值与PL-1中生成的DFC数据序列略有不同,这证明了准确性的降低是合理的,并且在DFC和组合功能场景中都需要更长的模式。然而,由于使用所提出的增强方法进行训练,PL-2的整体模型精度和提前性可以保持与PL-1几乎相似。
此外,混淆矩阵,如图7所示。以分析初期分类模型使用组合特征对正常和故障部件进行分类的性能。如图7(a)、图7(b)所示,所提出的初期分类模型对正常和故障部件表现出良好的性能。观察到这种效应是因为静态不平衡和动态不平衡的性质几乎相似,这会在分类中造成不利影响。对于DS-2数据集,初期分类模型表现出良好的性能,能够准确地对不平衡和垂直偏差进行分类,如图7(c)、图7(d)所示。初期分类模型-M1将17%的正常样品误分类为水平偏差,然而,初期分类模型-M2的准确率高达97%,仅将3%的正常样本误分类为水平偏差。总体而言,这里初期分类模型能够为SRF分类提供异常结果。
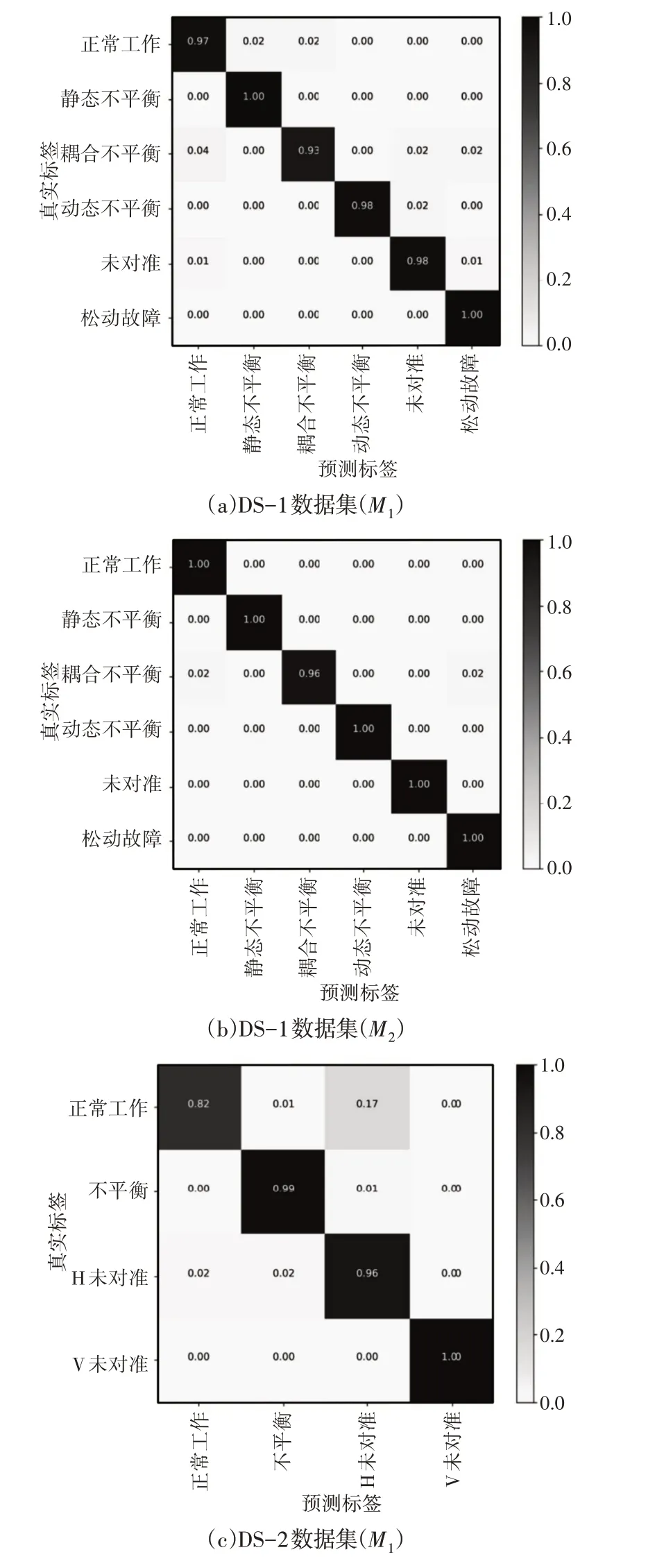
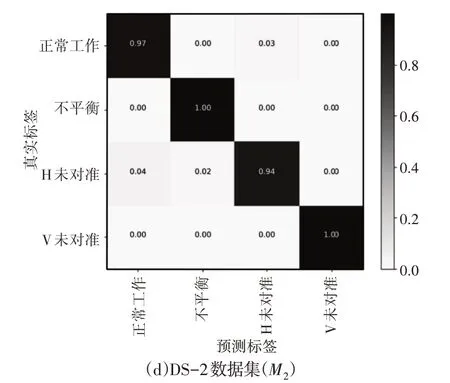
图7 混淆矩阵Fig.7 Confusion Matrix
(3)初期分类模型(EC)与传统方法(TC)的比较分析:将提出的初期分类模型与SRF 的传统分类方法进行了比较,如图8 所示。传统分类方法考虑用于分类的完整数据序列,而这里初期分类模型能够使用部分数据序列预测故障。如图8(a)、图8(b)所示,初期分类模型-M1仅利用5.19%的数据点对动态不平衡故障进行了100%准确的分类。此外,初期分类模型-M1 仅使用25.19%的全长数据对不平衡进行分类,而传统分类方法的准确度约为1.8%。还可以观察到,在正常工作条件下,初期分类模型比传统分类方法获得了更好的精度,如图8(a)、图8(c)所示。此外,与初期分类模型-M1相比,初期分类模型-M2的提前性较好,但动态不平衡类除外。对于DS-2数据集,初期分类模型-M2通过利用85.9%的数据点,证明了与DS-1相比,在正常等级下具有相似甚至更高的精度,如图8(g)、图8(h)所示。由于数据集的多样性,与DS-1相比,这两种模型都使用了更长的DS-2序列。还观察到,对于所考虑的故障,M1和M2两种分类器的准确度和提前模式都不同。然而,M2的提前度和准确度总是优于M1。因此,基于上述观察,可以得出结论,与传统方法相比,所提出的用于SRF的初期分类方法的性能是高效的。
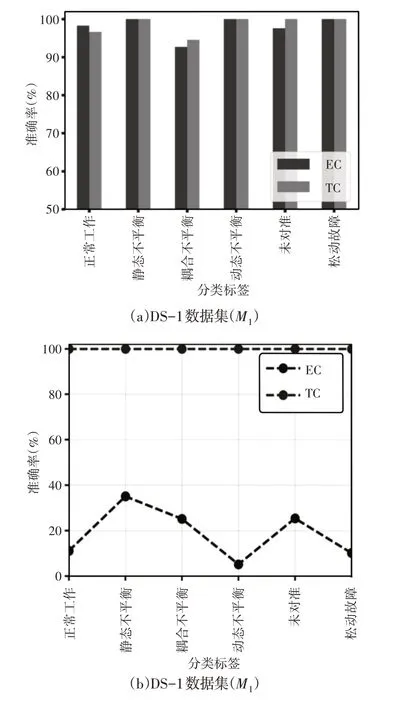
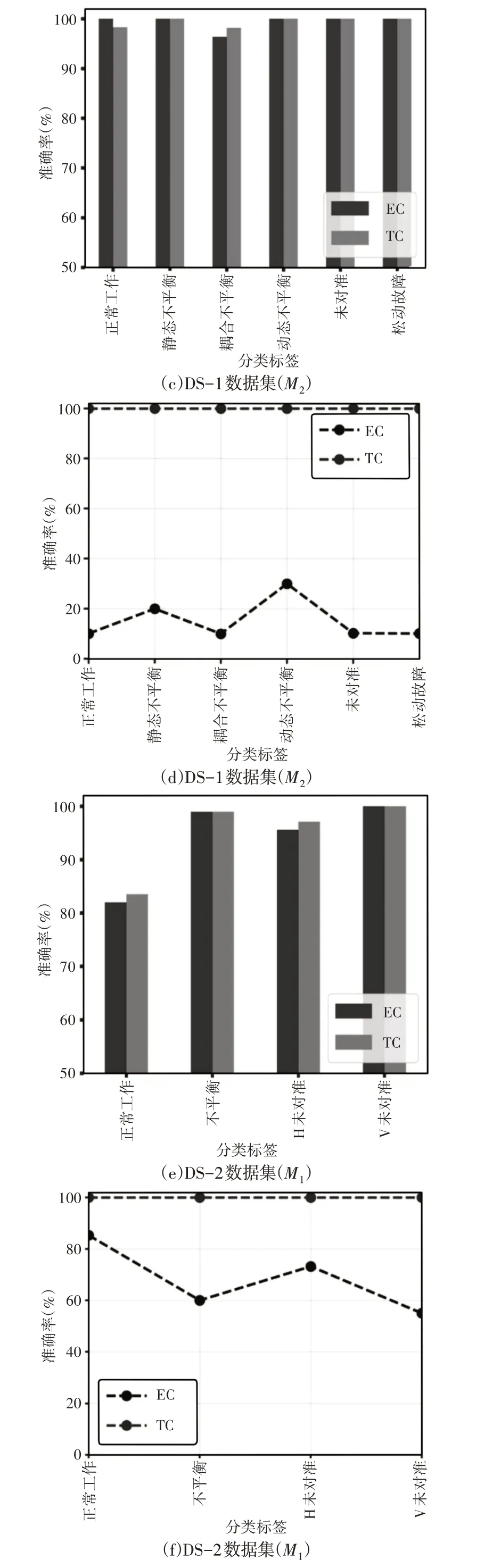
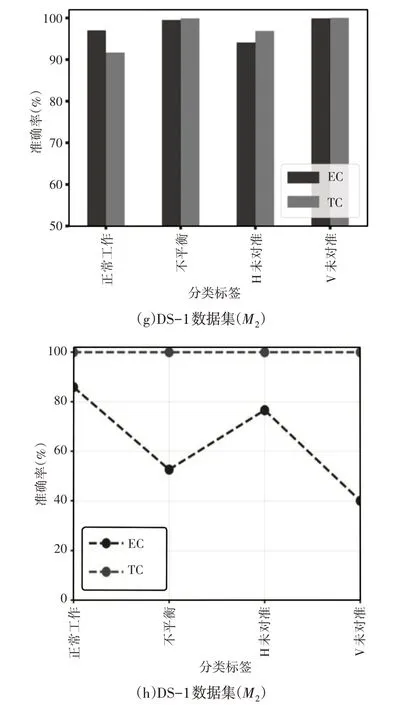
图8 该模型与TC方法的对比分析Fig.8 Comparative Analysis Between the Model and TC Method
(4)与深度学习方法的比较:所提出的模型与旋转机械故障诊断中表现出色的最新深度学习模型的比较,如表6所示。由于旋转机械故障分析中的大多数深度学习使用的是卷积神经网络(CNN),因此这里从文献[10]与文献[11]中选择了两种经典的CNN模型,它们从一维原始振动中自动提取特征,并着重处理传感器信号。从结果来看,文献[11]中的方法性能更好,与文献[10]中的方法相比,精度达到95%左右,甚至更高,因为其更深层次的CNN架构和特征融合策略。由于DS-2 原始振动信号的采集频率较高,因此DS-2上CNN模型的性能始终优于DS-1。
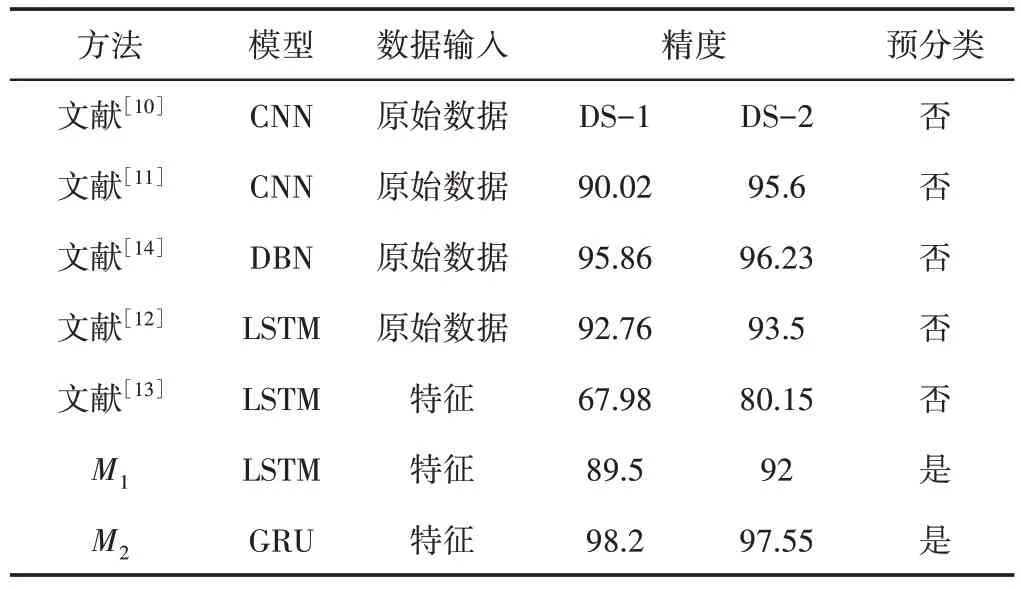
表6 与其他基于深度学习方法的比较Tab.6 Comparison with Other Depth Based Learning Methods
这里进一步在原始数据上测试了模型,并提取了频率特征,从而与长短期记忆网络(LSTM)的性能进行比较[12-13]。与预期的原始数据输入相比,具有频率特征的LSTM 表现出更好的性能。深度置信网络(DBN)模型是在每个传感器数据上使用独立的DBN进行信息融合,这里数据集较合适该模型,精度达到93%左右[14]。和这些方法相比,这里提出的方法在选择DFC特征和增强的全长数据上达到99%或更高的精度。
此外,采用初期分类策略,通过所提出的模型,DS-1的数据长度仅为25%左右,DS-2的数据长度为60%左右,准确率达到96%或更高。
4 结论
为了弥补实际工业数据和实验实验室数据之间的差距,提出了一种基于加权动态时间扭曲的不平衡结构转子故障诊断方法。在试验台数据集上产生的结果可以证明如下结论:(1)该模型使得该框架能够在实时环境中基于部分观测序列检测各种故障,有效提升结构转子故障诊断的精度,并且有效同化数据之间的差异。(2)与传统的故障诊断方法相比,提出的方法为维护活动提供了大量的时间,决策策略是初期分类的核心,通过控制早期参数在提供检测分类可靠性能方面起着至关重要的作用。(3)添加高度区分性的增强数据增加了数据多样性,这有助于改进模型的参数训练,并且,顺序学习模型的准确性有所提高。
猜你喜欢
一重技术(2021年5期)2022-01-18
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年10期)2018-08-04
中国港湾建设(2017年11期)2017-12-19
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
系统工程与电子技术(2016年7期)2016-08-21
西北工业大学学报(2015年4期)2016-01-19
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
航天返回与遥感(2014年5期)2014-07-31
