
遗传算法优化神经网络整包电池SOC估计模型
2023-02-27 12:40张利东牛志刚
机械设计与制造 2023年2期
张利东,牛志刚,刘 瑛
(1.太原理工大学机械与运载工程学院,山西 太原 030024;2.江铃重型汽车有限公司技术开发研究院,山西 太原 030032)
1 引言
在目前节能环保的大环境下,新能源汽车在处理化石能源枯竭和尾气排放中拥有着独一无二的战略地位,其中纯电动汽车和氢电混动汽车作为新能源汽车的重要组成部分而备受关注。在大部分的新能源汽车中,动力电池作为不可缺少的储能元件,对其进行精确的荷电状态(State of Charge,SOC)估计是动力电池续航里程和健康状态评估(State of Healthy,SOH)以及各种工况下行驶状态分析等环节中的关键任务[1]。
目前有很多用于SOC估计的模型,其中使用较多的是使用安时积分法和卡尔曼滤波估计法建立的模型[2]。安时积分法建立的模型主要是使用对时间的积分来计算电池在充电或者放电阶段的电量,进而与额定容量进行比较来估算电池的SOC,忽略其它的影响因素,比如温度,电池衰变等,所以该模型很难有很高的估算精度。卡尔曼滤波法在建模时需要先建立一个精确的蓄电池模型,该模型基于电池内部复杂的物理化学反应[3],但是由于蓄电池具有高度非线性的特性,使得建立精准的数学模型成为一个复杂的问题[4]。人工神经网络算法(ANN)具有良好的非线性输出能力,同时鲁棒性和学习能力都比较好[5],非常适合处理动力电池的SOC估计问题。
BP 神经网络是一种可以用于SOC 估计的人工神经网络算法,文献[6]采用启发式BP神经网络建立了铅酸电池的SOC估计模型,初步实现了使用BP神经网络对单体电池充放电过程中剩余容量的估计,估计的相对误差缩小到1.892%。文献[7]基于贝叶斯正则化算法BP神经网络建立了对钒电池SOC估计的模型,进一步提高了SOC实时估计精度。
虽然已经有对BP神经网络SOC估计模型的改进,但是在精度和稳定性上存在一定问题,其算法的计算量偏大,同时大部分模型输入参数只考虑到放电倍率和输出电压,缺乏对环境温度的控制。这里依据一种使用轮盘赌算法和最佳个体保存法作为选择算法的遗传算法[8],对SOC估计BP算法的权值阈值进行优化,选择环境温度,放电倍率和输出电压作为输入参数,以提高稳定性和精度。现阶段大多数算法的建立都是使用单体锂电池作为实验对象,而使用单体电池作为实验对象,不能完全代表工业应用中的各种需求和工况。这里使用L100T06电池包作为实验对象。与单体电池相比,选用整车电池包作为实验对象,能放大局部特征,减少实验误差,使实验结果更有代表性,同时能提高算法运算结果的可靠性。
2 原始测试数据获取
2.1 实验平台搭建
这里选用的动力电池为磷酸铁锂电池包(20.48kWh Li-ion Batteay Pack),产品型号为L100T06,是新能源氢电混动重卡4X2/6X2T FCV的辅助动力电池,其功能是在低功率的工况下,将氢反应堆的富余能量存储到动力电池中;在其他工况下,配合氢反应堆提供足够的动力;在特殊工况下,也可以关闭氢反应堆,由动力电池单独提供动力,该车整车属性,如表1所示。该电池包的标称容量为100Ah,标称电压为204.8V,具体参数,如表2所示。
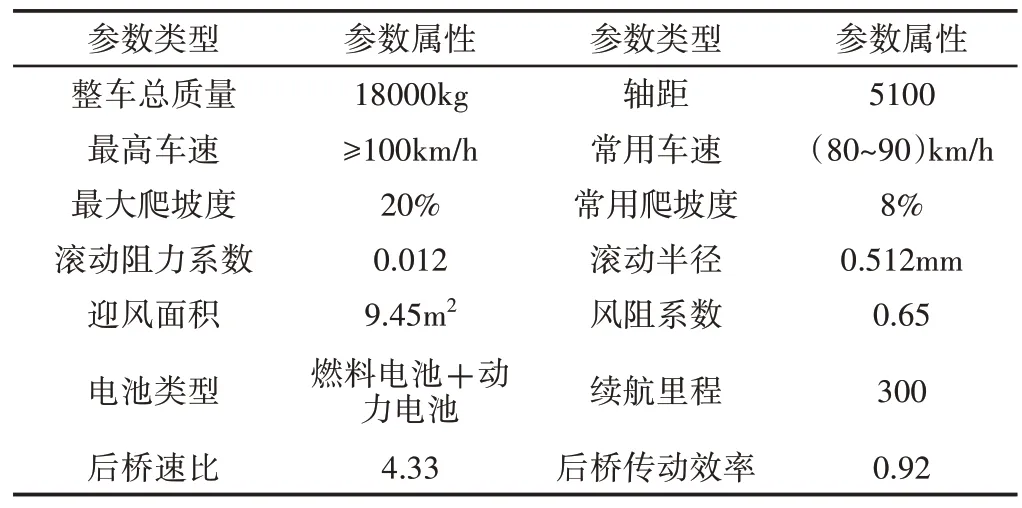
表1 氢能源重卡整车属性Tab.1 Hydrogen Energy Heavy Truck Vehicle Attributes
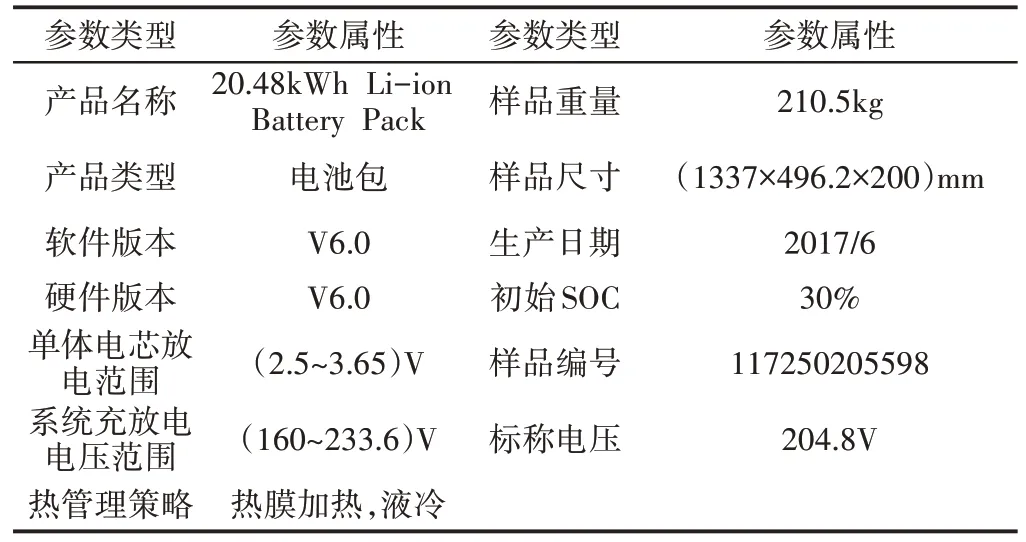
表2 电池包具体参数Tab.2 Specific Parameters of Battery Pack
实验使用高低温湿热试验箱对环境温度进行控制,保证实验时处于相对恒温状态,使用充放电机对磷酸铁锂电池进行充放电实验,自动记录电池的电压、电流、步骤容量、时间等参数的变化情况。实验平台照片,如图1所示。

图1 实验平台Fig.1 Experiment Platform
2.2 实验步骤
使用搭建的测试平台进行实验,获取各种环境温度以及放电倍率下,恒流放电的放电电压、直流内阻(简称DCR)以及当前电池包SOC。具体步骤如下:
(1)将磷酸铁锂电池包与高压箱进行连接,然后使用高压线束和高压闭锁开关将高压箱与宽域充放电机连接。
(2)将连接好的磷酸铁锂电池包和高压箱置于高低温湿热试验箱,调整高低温湿热试验箱温度为25℃,湿度为50R.H,静置2h。
(3)对磷酸铁锂电池包进行标准充电,然后进行不同放电倍率的放电,至最小单体电芯Ucell-min小于等于当前温度规定最小电压停止放电,记录放电过程的SOC、放电电压以及直流内阻(DCR)。实验的放电倍率有1/3C、1/2C、1C、2C,每一倍率结束后,都需要进行标准充电,并静置1h。
(4)使用高低温湿热试验箱调整环境温度,分别调整至-20℃、-10℃、0℃、25℃、40℃,静置2h后进行实验,重复步骤(3),记录实验数据。
不同温度条件下,单体电芯最小放电电压规定不同,根据厂商提供的技术资料,在0℃以上(不包括0℃)时,单体电芯的截止放电电压为2.5V,在0℃以上(包括0℃)时,单体电芯的截止放电电压为2.0V。
部分实验数据,如表3所示。
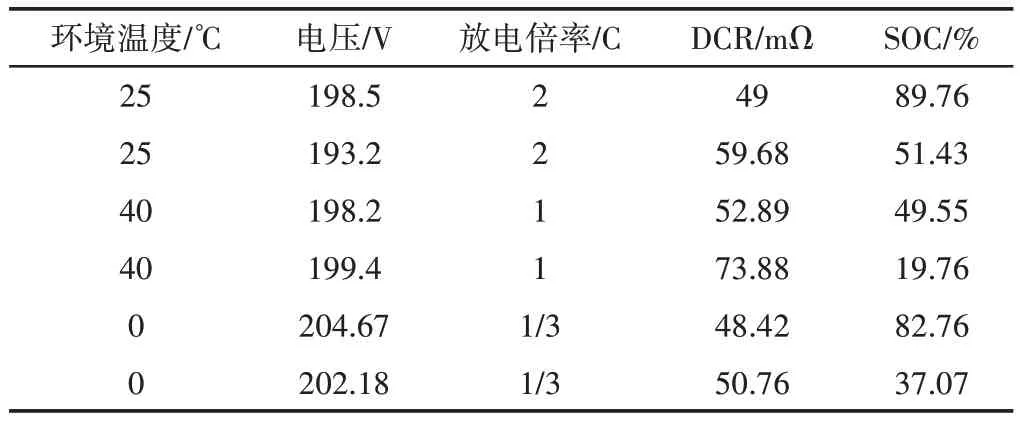
表3 部分实验数据Tab.3 Some Experimental Data
2.3 生成数据库
为了提高使用算法计算时的收敛速度和寻找最优解的效率,将采集来的数据进行归一化处理,使输入和输出的数据在[-1,1]之间。公式如下:
式中:X—进行归一化处理后的数据,它可以直接输入到估计网络模型中;text—实验采集的真实数据;textmin、textmax—采集的该组数据中的最小值和最大值。
使用归一化处理后的数据组成这里模型的数据库,先使用randperm函数打乱数据,然后随机抽取70%数据作为训练数据,剩余数据作为测试数据。
3 BP神经网络SOC估计模型
3.1 BP神经网络模型搭建
BP(Back Propagation)神经网络,这种由误差反向传播训练的多层前馈网络,由数个非线性变换单元组成,是当前应用较为广泛的神经网络模型[9]。
BP神经网络由两部分组成,分别是信息流在网络进行正向传播以运算输出结果与此同时误差流不断向前反馈进行反向传播修正输出结果[10]。BP神经网络的结构,如图2所示。输入层在接收到归一化处理后的训练数据后,使用硬极限函数进行处理,信息由输入神经元经隐含层神经元层层处理后流向输出层。误差反向传播主要体现在训练过程中,当训练信号传到输出层进行输出后,估计结果与真实值对比然后计算误差,利用该误差来估计输出层前导层的误差,再利用前导层误差估计更前一层的误差,这样循环到获得所有其他各层的误差,最后使用所得误差对各层节点进行修正,来提高整个网络的精度[11]。
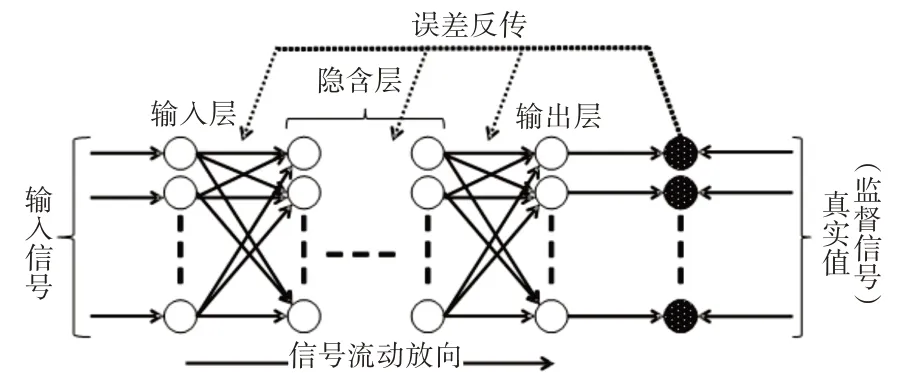
图2 BP神经网络结构图Fig.2 BP Neural Network Structure Diagram
在本模型中,输入为三维向量,包括实时放电倍率,实时环境温度和实时电压,输出为当前状态下的SOC值。隐含层及输出各节点输出模型为:
式中:f—传递函数;Wij—各神经元权值矩阵;bj—各神经元对应隐含层的阈值向量。为了让输出规整在(0,1)区间内,传递函数选择为双曲正切函数(1,2)。
BP算法的误差计算模型通常有mas和mse两种,这里选用均方误差mse模型,计算公式为:
式中:E(k)—第k次迭代的网络输出总误差;t—真实值,在训练过程中;t—当前实际的SOC值。
BP网络的学习算法选用梯度最速下降法,这是一种有监督的学习方式。因BP学习算法是LMS算法的推广,为了方便计算,与LMS算法相同,F(W)来近似表示权值矩阵为W时网络的误差。F(W)计算公式如(2.4)。
定义敏感度为:
使用链法则,通过网络将敏感性进行反向传播:
式中:M—总隐含层数;m—当前隐含层数。
最后推导出权值和阈值的学习公式为:
式中:α—学习速率,这里选用0.01。
3.2 BP神经网络SOC估计模型分析
为了测试未经过遗传算法优化的BP神经网络性能以及其估计误差与隐含层之间的关系,以及模型的效果,将数据库中的训练数据导入建立的BP 网络中进行训练,分别设置隐含层为(1~100),并使用测试数据对训练好的网络进行测试。由于网络训练有一定的随机性,先后进行了3次测试。测试结果,如图3所示。
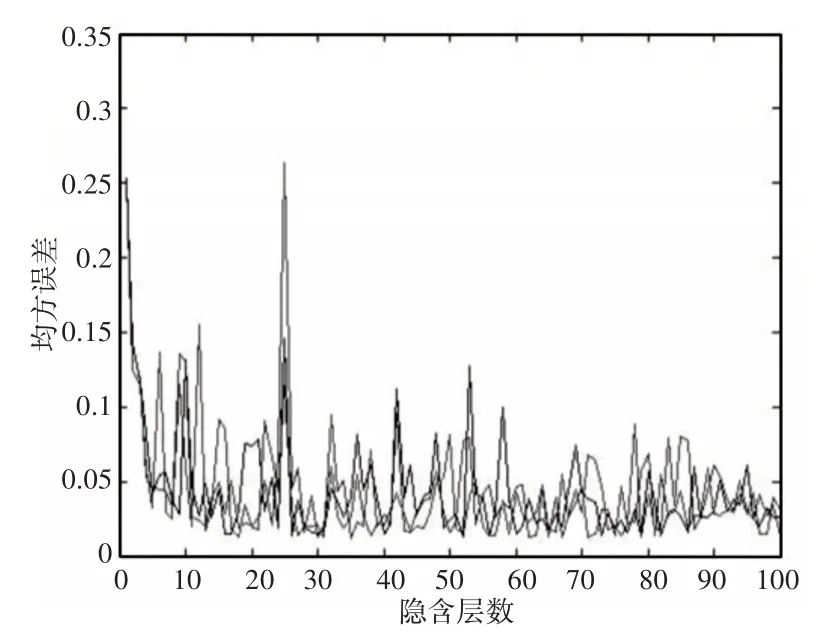
图3 隐含层数对网络精度的影响Fig.3 Influence of Hidden Layers on Network Accuracy
由图可知,在(1~30)之间,随着隐含层数目的增加,测试误差大体呈减少趋势,在隐含层数达到30以后测试误差在一定范围内波动,随隐含层数的增加,波动范围呈减小趋势。
总体来说,该系统误差跳动较大,即使在隐含层数为100时,波动范围依旧超过0.01。以隐含层为30 时为例,如图4 所示。100 次训练测试结果的平均误差为0.0433,上下波动范围为0.188,最小误差为0.131。由此可见,该系统在实际应用中稳定性较差,网络优劣有很大随机性,需要进行改进。
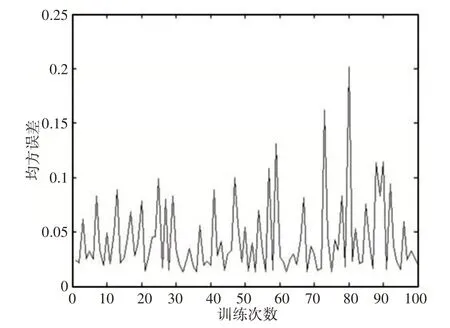
图4 隐含层为30时100次训练的误差图Fig.4 Error Graph of 100 Trainings when the Hidden Layer is 30
4 GA优化模型建立
遗传算法(Genetic Algorithm,GA)是由美国教授J.Holland于1975年提出的一种智能优化算法,它是一种仿照生物界中的进化理论,以选择和遗传,变异等为搜索机制的算法。它可以从任一解出发,模拟生物界遗传规则,以一定的概率寻求整个网络拓扑结构的最优解。它具有全局优化性能、通用性强等优点,且适用于并行处理[12]。
4.1 遗传算法搜索机制
遗传算法模拟自然界基因遗传学说的原理中发生的选择繁殖、基因交叉和基因变异等现象,在每次迭代中首先保留一组最优候选解不被淘汰,然后按适应度函数的值从解群中选取恰当的个体,最后利用遗传算子对这些个体基因进行重组,组成新的种群,这样新一代的种群中包含有大量上一代的信息,但是优于上一代种群,这样周而复始,直到达到了目标要求即可终止迭代[13]。
4.2 初始种群创建
首先对染色体进行定义。针对SOC 估计的BP 神经网络模型,取网络所有权值阈值,组成N维向量,作为一个个体的染色体。选择种群规模为M,随机生成一个M*N的矩阵作为初始种群。其中:
适应度函数选择:遗传算法对于个体的优劣性是用适应度函数值来评估的,个体基因的质量越高,其适应度函数的值就越大,表明该个体更加契合所求的最优网络需求。这里将各个个体基因按照事先约定的分组进行分类,其数值分别作为权值和阈值代入到SOC估计的BP神经网络模型中,计算其估计的均方误差,以该误差的倒数作为适应度函数值。
在本模型中,输入向量维度为4,包括实时放电倍率,实时环境温度,实时电压以及直流内阻,输出向量维度为1,为当前SOC值。
4.3 遗传迭代
这里提出轮盘赌算法与最佳个体保存法相结合的方法作为GA算法的选择算子。选择算子是遗传算法进化过程的主要驱动力。轮盘赌算法的主要思想是各个个体的选择概率与其适应度函数值大小成正比[14]。种群大小为M时,第i个个体适应度函数值为Fi,则该个体顺利通过选择并遗传到新的种群中的概率为:
该算法一方面将适应度高的个体高效地遗传到下一代,又避免了在搜索最优解的过程中陷入局部最优,但是有一定概率会丢失上一代种群中适应度最佳的个体,因此通过与最佳个体保存法相结合的方式解决这一问题。在模型设计时,设计一个预留空间,用来保存当前种群中适应度最佳的个体。每一次迭代时,首先计算当前种群中每个个体的适应度,然后将适应度最佳的个体和适应度最差的个体复制到预留空间。其次依次计算种群各个个体的选择概率。最后依各个个体的选择概率对个体进行选择,使用选中的个体替换原种群的个体。在完成后续的交叉和变异操作后,计算当前种群所有个体的适应度,使用预留空间中上一代适应度最佳的个体替换当前种群适应度最差的个体。
因个体染色体的长度较短,交叉算子选用单点交叉的方式。交叉算子是种群产生新的个体最主要的方法,通过实验对比最终选择交叉概率为0.7。交叉方式,如图5所示。交叉个体A、B以及交叉位i都是依概率随机选择的。
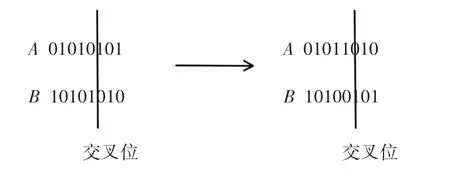
图5 交叉示意图Fig.5 Schematic Cross
遗传算法中还有一种辅助产生新个体的方法,变异运算。经过实验发现使用单重均匀变异进行测试时,收敛速度较快且变异后个体废除率较低,选用该算法作为变异算法。
4.4 遗传算法优化SOC估计模型流程
使用遗传算法对BP 神经网络SOC 估计模型进行优化的流程,如图6所示。
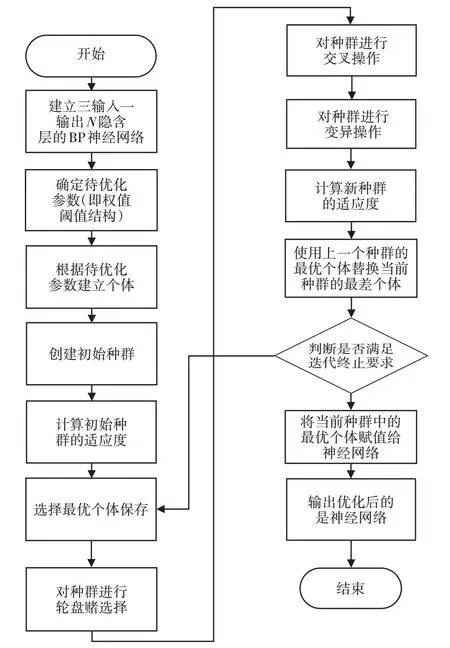
图6 遗传算法优化流程图Fig.6 Genetic Algorithm Optimization Flow Chart
5 遗传优化结果分析
分别设定隐含层为3-15,使用数据库中训练数据对优化后的模型进行训练,并使用测试数据进行测试。测试结果如下:
其中,散点是遗传算法优化后的网络测试结果,其余为隐含层为3-15时未进行优化的3次未优化BP网络测试结果,如图7所示。在隐含层为3-15区间内,GA算法优化后的网络有很高的稳定性,同时其误差随隐含层的增加而逐步减少。在达到相同精度的条件下,优化后的网络使用了数目更少的隐含层,在一定程度上简化了估计模型的网络拓扑结构。
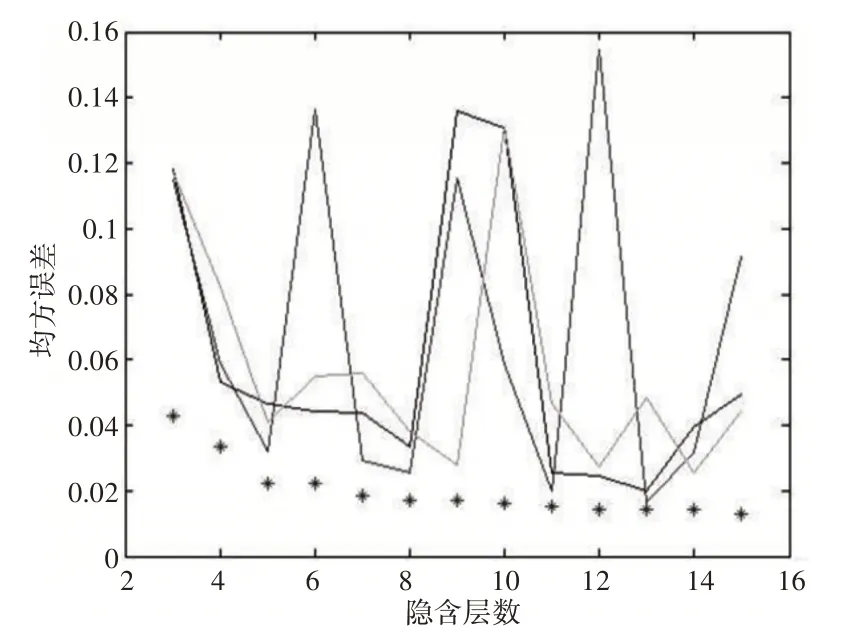
图7 GA优化效果对比Fig.7 GA Optimization Effect Comparison
同时,优化算法有效减少了网络误差。经过优化后的网络测试结果相对于原网络而言,误差减少了约0.05,精度提高了约50%,如表4所示。
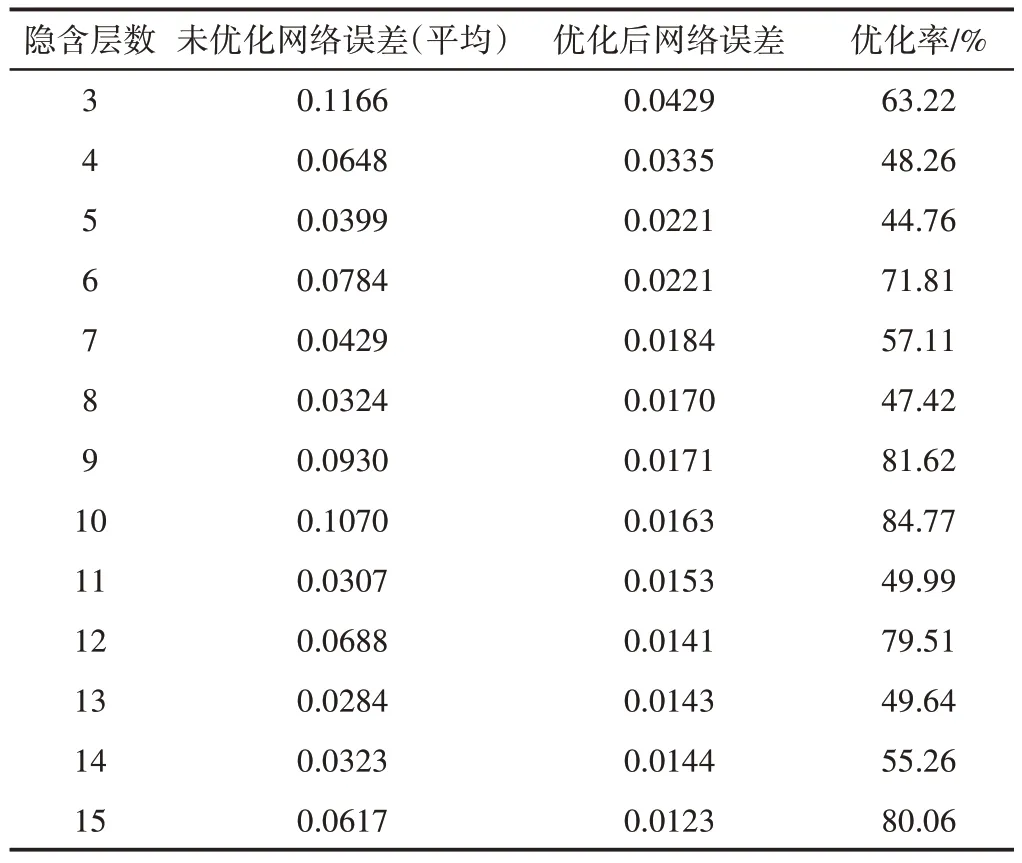
表4 优化测试结果Tab.4 Optimize Test Results
为进一步验证优化模型的效果,使用变电流工况对磷酸铁锂电池包进行实验,测得一组数据,测试工况,如图8所示。以隐含层为15时为例进行分析,分别使用未优化的网络、优化后的网络进行估计。测试结果,如图9所示。其中,散点代表优化后的网络估计结果。从图中可以明显看出,优化后模型最大误差0.023,未优化模型最大误差0.049,优化后的网络更接近真实值,且误差波动较未优化网络明显减小。
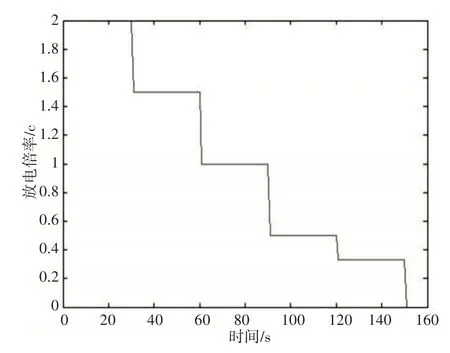
图8 测试工况Fig.8 Test Conditions

图9 未优化的网络、优化后的网络误差比较Fig.9 Comparison of Unoptimized Network and Optimized Network Error
6 结论
这里使用新能源氢电混动重卡4X2/6X2T FCV 的辅助动力电池作为实验对象,获得磷酸铁锂电池在不同环境温度、不同放电倍率下的SOC数据。使用输出电压,放电倍率,环境温度三个参数作为SOC估计的输入参数,建立了基于遗传算法优化BP神经网络整包电池的SOC估计模型,设计了综合轮盘赌算法与最佳个体选择法相结合的选择算法。测试结果表明,该模型有效改进了传统BP神经网络SOC估计模型精度随机性强,精度不足,稳定性差的不足,同时有效降低了网络拓扑结构的复杂程度,为整包动力电池的SOC估计提供了一定的参考。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
郑州大学学报(工学版)(2018年2期)2018-04-13
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
中国塑料(2016年11期)2016-04-16
重型机械(2016年1期)2016-03-01
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
汽车科技(2015年1期)2015-02-28
